



هوش مصنوعی چیست؟ – به زبان ساده + مسیر یادگیری
هوش مصنوعی یکی از شاخههای پیشرفته علوم کامپیوتری است. هدف از این شاخه، ساخت مجموعهای از سیستمهای کامپیوتری است که بتوانند کارهایی مانند استدلال، تصمیمگیری، یادگیری و حل مسئله را تا حدی شبیه انسان، حتی گاهی حتی دقیقتر از او، انجام بدهند. لازم است اشاره کنیم که تا همین چند سال پیش، بسیاری از مواردی که به آنها اشاره شد، تنها توسط انسان انجام میشدند و سیستمهای کامپیوتری در انجام آنها کم توان یا ناتوان بودند. این موضوع یکی از جدیدترین حوزههای تکنولوژی است. بنابرین افراد زیادی میخواهند بدانند که هوش مصنوعی چیست و چطور کار میکند. برای درک این موضوع در این مطلب به جنبههای مختلف هوش مصنوعی پرداختهایم.
- با کمک مثالهای ساده، مفهوم هوش مصنوعی را درک میکنید.
- رابطه بین هوش مصنوعی، یادگیری ماشین و یادگیری عمیق را متوجه خواهید شد.
- با کاربردهای هوش مصنوعی در صنعت آشنایی پیدا میکنید.
- با انواع زبانهای برنامه نویسی تخصصی برای هوش مصنوعی، آشنا میشوید.
- دروس دانشگاهی مربوط به هوش مصنوعی در مقطع کارشناسی و کارشناسی ارشد را میشناسید.
- تکنیکهای مختلفی مانند تشخیص گفتار، بینایی ماشین و رباتیک را درک میکنید.




در سالهای اخیر نوآوریها و پیشرفتهای بسیاری در زمینه هوش مصنوعی پدید آمده که در گذشته تنها در حوزه فیلمهای علمی تخیلی مورد تصور بودند، اما اکنون کمکم به وسیله رباتهای هوش مصنوعی به واقعیت تبدیل شدهاند. در این مقاله از مجله فرادرس ابتدا به طور جامع به این سوال پاسخ داده شده است که هوش مصنوعی چیست و سپس به مهمترین مباحث و مفاهیم مرتبط با هوش مصنوعی پرداخته میشود.
هوش مصنوعی چیست؟
هوش مصنوعی یا همان Artificial Intelligence به شاخهای از علوم کامپیوتر گفته میشود که هدف آن ساخت سیستمهای هوشمندی است که قادر به شبیهسازی رفتارهای انسانی هستند. این فناوری به ماشینها اجازه میدهد تا از طریق تجزیه و تحلیل دادهها، الگوها را شناسایی کنند و وظایفی مانند یادگیری، استدلال، حل مسئله و تصمیمگیری را به صورت خودکار و بدون نیاز به برنامهنویسی مستقیم انجام دهند. مهمترین قابلیتهای هوش مصنوعی در فهرست زیر آورده شده است:
- یادگیری ماشین (Machine Learning): بهبود عملکرد با استفاده از تجربه
- پردازش زبان طبیعی (NLP): درک و تحلیل زبان انسان
- بینایی ماشین (Computer Vision): تشخیص تصاویر و ویدیوها و درک «محتوای بصری» (Computer Vision)
- استدلال منطقی: توانایی نتیجهگیری از دادههای موجود
بنابراین به زبان ساده، هوش مصنوعی به توانایی تفکر یا یادگیری کامپیوتر یا ماشین گفته میشود. برای اینکه فردی هوشمند و دارای هوش تلقی شود، باید یادگیری اتفاق بیوفتد و فرد آموزش ببیند. در واقع انسانها هم از روز اولی که به دنیا میآیند هوشمند نیستند و برای تبدیل شدن به فردی هوشمند و باهوش باید تحت آموزش قرار بگیرند.
وقتی که انسانها یاد میگیرند، در واقع مواردی را به خاطر میسپارند و اطلاعاتی را در مغزشان ذخیره میکنند. سپس از این اطلاعات ذخیره شده در مغز برای تصمیمگیری هوشمندانه استفاده میشود. در خصوص ماشینها و هوش مصنوعی هم شرایط یکسان است و درست مشابه انسانها کامپیوترها هم باید ابتدا یاد بگیرند و نمیتوانند تا زمانی که آموزش ندیدهاند هوشمند شوند. بهتر است برای درک بهتر اینکه هوش مصنوعی چیست مثالی ساده ارائه شود.

مثالی ساده برای درک بهتر مفهوم هوش مصنوعی
برای مثال اگر فردی بخواهد رانندگی کند و اتومبیلی را براند، پیش از هر چیز باید موارد لازم را در مورد آن ماشین یاد بگیرد. فرد باید حتماً نحوه روشن کردن اتومبیل را بیاموزد؛ باید یاد بگیرد چگونه از دنده و پدالها استفاده کند و ماشین را به جلو براند. همچنین علائم رانندگی بسیار مهم هستند و فرد باید بتواند مفهوم هرکدام از آنها را درک کند و آنها را در مغز خود حفظ کرده باشد. به این ترتیب در حین رانندگی فرد میتواند براساس آموختههای خود تصمیمگیری کند.

کامپیوترها هم به همین شکل عمل میکنند. یادگیری در کامپیوترها با استفاده از دادهها اتفاق میافتد. ماشینها و کامپیوترها الگوهای موجود در دادهها را درک میکنند و سپس مدلهایی را میسازند و این مدلها برای تصمیمگیری مورد استفاده قرار میگیرند. بنابراین انجام کارهایی هوشمندانه توسط ماشین و کامپیوترهای ساخته شده توسط انسان را هوش مصنوعی مینامند.

هوش مصنوعی به انگلیسی
معادل اصطلاح هوش مصنوعی به انگلیسی «Artificial Intelligence» است که به صورت «آرتیفیشال اینتلیجنس» تلفظ میشود. مخفف یا سرنام «AI» نیز به طور گستردهای در زبان انگلیسی و حتی فارسی به جای Artificial Intelligence یا هوش مصنوعی استفاده میشود. همچنین سایر عبارتهایی که به نوعی در ارتباط با هوش مصنوعی به کار میروند و تقریباً در برخی موارد مترادف هوش مصنوعی به انگلیسی هستند در ادامه فهرست شدهاند:
- Robotics (رباتیک | ساخت ربات هوشمند)
- Development of 'Thinking' Computer Systems (توسعه سیستمهای کامپیوتری)
- Expert System یا Expert Systems (سیستمهای خبره)
- Intelligent Retrieval (بازیابی هوشمندی)
- Knowledge Enginerring (مهندسی دانش)
- Machine Learning (یادگیری ماشین)
- Natural Language Processing (پردازش زبان طبیعی)
- Neural Network یا Neural Networks (شبکههای عصبی)
در ارتباط با این سوال که هوش مصنوعی چیست همواره بحث یادگیری ماشین هم مطرح میشود و همیشه سوالاتی پیرامون ارتباط یادگیری ماشین با هوش مصنوعی وجود دارد. بنابراین در ادامه به این موضوع پرداخته شده است.
هوش مصنوعی و یادگیری ماشین
یادگیری ماشین (Machine Learning) که قبلا در مجله فرادرس راجع به آن صحبت کردیم در واقع بخشی از هوش مصنوعی به حساب میآید و کاربردی از AI است. فرایند استفاده از مدلهای ریاضی ساخته شده براساس دادهها توسط ماشینهای کامپیوتری را یادگیری ماشین مینامند. هدف ماشین لرنینگ توسعه و ساخت سیستمی است که بتواند بدون دریافت دستورالعملهای دقیق و خط به خط، خودش یاد بگیرد و بیاموزد. در یادگیری ماشین سیستمی طراحی و ساخته میشود که به یادگیری ادامه میدهد و رفته رفته خودش را بر اساس تجربه بدست آمده بهبود میدهد.

به قابلیت سیستمهای کامپیوتری برای تقلید از عملکردهای شناختی انسان مانند یادگیری، حل مسئله و سایر موارد هوش مصنوعی گفته میشود. هوش مصنوعی از یادگیری ماشین استفاده میکند تا دانش مربوطه و مورد نیاز را بدست آورد. سپس هوش مصنوعی دانش بدست آمده را به وسیله شبیهسازی منطق و استدلال انسانگونه برای توصیه یا تصمیمگیری به کار میگیرد. در حالی که هوش مصنوعی علم گسترده تقلید از تواناییهای انسان است، یادگیری ماشین زیرمجموعه خاصی از هوش مصنوعی به حساب میآید که به ماشین آموزش میدهد چگونه یاد بگیرد.

یکی دیگر از سوالات رایج پیرامون اینکه هوش مصنوعی چیست این است که هوش مصنوعی چه کارهایی انجام میدهد؟ بنابراین بهتر است در ادامه به این بحث پرداخته شود.
هوش مصنوعی چه کارهایی انجام می دهد؟
تقلید از ساختار مغز انسان، درک متقابل و کمک دوطرفه، خودآموزی و بازاندیشی در مورد گونههای مختلف حیات بیولوژیکی، جایگزینی افراد در مشاغل مختلف و تقلب در بازیهای کامپیوتری همگی تنها برخی از کارهایی هستند که امروزه هوش مصنوعی انجام میدهد. در این بخش سعی شده است تا به برخی کاربردهای هوش مصنوعی پرداخته شود.

هوش مصنوعی در پزشکی
آلفابت (Alphabet) شرکت مادر گوگل، اخیراً آزمایشگاههایی یکدست و همسان ساخته است که برای یافتن داروهای جدید با استفاده از هوش مصنوعی شرکت DeepMind (از شرکتهای زیرمجموعه گوگل) تاسیس شدهاند. هدف این سازمان بازتعریف فرایند کشف دارو از صفر و یافتن راههایی جدید برای درمان بیماریها با استفاده از هوش مصنوعی است. این آزمایشگاهها نه تنها دادهها را تجزیه و تحلیل خواهند کرد بلکه مدلهایی قدرتمند، پیشبینی کننده و مولد را از پدیدههای پیچیده بیولوژیکی خواهند ساخت.

در حالی که هنوز هیچ کس در تلاش برای یافتن درمان بیماریهای مختلف با استفاده از شبکههای عصبی به پیشرفت قابل توجهی دست پیدا نکرده است، شرکت DeepMind در حال حاضر در هوش مصنوعی حرف اول را میزند و سیستم یادگیری الگوریتم این شرکت انطباقپذیرترین سیستم موجود است که میتوان آن را برای اهداف و مقاصد مختلف به کار گرفت.
آموزش ربات ها با هوش مصنوعی برای انجام کارهای مختلف
امروزه از هوش مصنوعی یا همان شبکههای عصبی برای آموزش رباتها نیز به طور گسترده استفاده میشود. برای مثال با استفاده از مدلی جدید بر اساس هوش مصنوعی، مهندسان دانشگاه MIT موفق شدهاند تا رباتها را برای حمل و نگه داشتن هزاران شی مختلف با استفاده از بازوهای مکانیکی خود آموزش دهند. این کار با استفاده از یادگیری تقویتی و بدون شبیهسازی انجام شده و نتیجه کار ساخت شبیهسازی دست انسان گونه است که میتواند بیش از ۲ هزار شی مختلف را بردارد و آنها را با استفاده از بازوهای مکانیکی خود لمس کند و حرکت دهد.

علاوه بر آن جالب اینجاست که این سیستم برای بلند کردن شی و نگه داشتن آن در دستانش حتی نیازی نداشت بداند دقیقاً چه چیزی را قرار است بردارد. تا اینجا نرخ موفقیت رباتی که از این سیستم استفاده میکند بسته به نوع شی متفاوت است اما در طول زمان الگوریتم خودش را ارتقا خواهد داد و باعث میشود رباتها مهارت بیشتری پیدا کنند و تطبیقپذیرتر شوند.

آموزش مهارت های اجتماعی به ربات ها با استفاده از هوش مصنوعی
الگوریتم دیگری به وسیله محقان دانشگاه MIT ساخته شده است که به رباتها مهارتهای اجتماعی و به طور خاص همکاری دوجانبه را آموزش میدهد. مدلهای ریاضی جدید به گونهای طراحی شدهاند که به ماشینها درکی از رفتارهای فیزیکی و اجتماعی رباتهای دیگر را میآموزند. بنابراین اگر رباتی قرار است رفتاری منطقی و با معنی را به لحاظ اجتماعی انجام دهد، چون رفتار خوبی است، ربات دیگر باید در انجام آن کار به این ربات کمک کند. یا اگر رباتی بخواهد عمل بدی را انجام دهد، ربات فرضی دیگر باید مانع از آن شود.
محققان در تلاشند تا رباتها را به شبکه عصبی مخصوصی مجهز کنند که فرایند تجربه اجتماعی را سرعت میبخشد. علاوه بر این، آنها در حال کار روی سیستم حسگر ۳ بعدی هستند که به رباتها امکان میدهد تا عملیات پیچیدهتری را به تنهایی انجام دهند. مثلاً بتوانند از لوازم خانگی استفاده کنند. تمام اینها به رباتها امکان خواهد داد تا تعاملاتشان را نه تنها بین خودشان، بلکه میان انسانها و رباتها هم افزایش دهند.

شبیه سازی ساختار مغز انسان با هوش مصنوعی
یکی از اکتشافات شگفتآور دیگر هم در دانشکده تحقیقات مغزی موسسه فناوری ماساچوست یا همان MIT محقق شده است. دانشمندان به این مهم دست یافتند که در حین طبقهبندی رایحهها، شبکههای عصبی مصنوعی ساختاری را به کار میگیرند که بسیار شبیه به ساختار بویایی مغز انسان است. انسانها و سایر حیوانات اطلاعات بویایی را به طور مشابهی در مغزشان انجام میدهند.
با وجود اینکه در فرایند آموزش الگوریتمهایی برای طبقهبندی رایحهها، دانشمندان قصد کپیبرداری از مغز موجودات زنده را نداشتند، اگرچه در روند حل این مسئله شبکه عصبی مصنوعی به میل خود شبکه بیولوژیکی بویایی را بازتولید کرد.

از طرفی این رویداد شگفتانگیز طراحی بهینه سیستمهای بیولوژیکی را نشان میدهد. از طرف دیگر، این مسئله امکان مدلسازی کل مغز انسان را هم فراهم میکند. تخصص در یکی دیگر از مهمترین کارکردها و قابلیتهای مغز نیز اخیراً به وسیله هوش مصنوعی بدست آمده است. این دستاورد جدید شناسایی رابطههای علت و معلولی را انجام میدهد.
جهت یابی خودرو در محیط های مختلف با هوش مصنوعی
محققان MIT ثابت کردهاند که نوع خاصی از شبکههای عصبی قابلیت یادگیری ساختار تصادفی و واقعی کاری را دارند که برای انجام آن آموزش دیده است. این تحقیقات روی شبکههای عصبی مختص جهتیابی صورت گرفتهاند و بهگونهای طراحی شدهاند تا بتوانند اتومبیل بدون سرنشین را در جاده برانند یا مسئولیت جهتیابی پهبادها را بر عهده بگیرند.
هدف این است که وقتی یک شبکه عصبی آموزش داده میشود، نمیتوان به طور قطعی اطمینان حاصل کرد که مدل ساخته شده آیا محدوده جاده را خط کشیهای روی آسفالت در نظر گرفته است یا بر اساس بوتههای اطراف جاده عمل میکند.
اگر الگوریتم دادههای اشتباهی را برای آموزش انتخاب کرده باشد، در صورت تغییر محیط، امکان انجام وظیفه محوله را نخواهد داشت. محققان از چیزی به نام شبکههای عصبی سیال (Liquid Neural Network) استفاده میکنند که میتوانند معادلات پایهای خود را تغییر دهند تا خود را به طور مداوم با دادههای ورودی جدید تطبیق دهند.
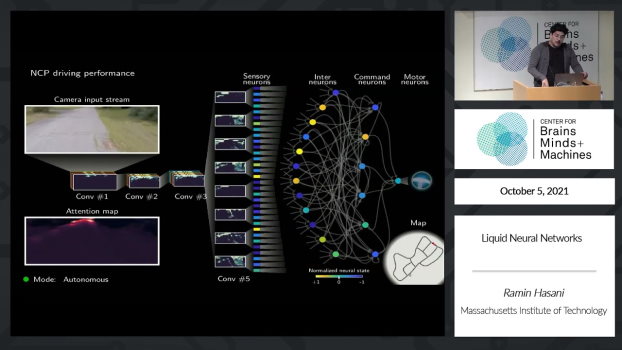
یک سیستم یادگیری عمیق (Deep Learning) با اقتباس از مغز انسان که برپایه چنین شبکههایی ساخته شده است نتیجه یکسانی را نسبت به الگوریتمهای استاندارد تحت شرایط استاندارد از خود نشان داده است. اما برخلاف شبکههای عصبی رایج، این سیستم جدید تحت شرایط مختلفی مثل جهتیابی در مه، باران شدید یا سایر تغییرات آب و هوایی به خوبی عمل میکند.
همانطور که تا اینجا شرح داده شد، کارهای بسیاری را میتوان با استفاده از هوش مصنوعی انجام داد و این حوزه پتانسیل بسیار بالایی دارد و دستاوردهای بسیار اعجابآوری به وسیله هوش مصنوعی قابل تحقق هستند. اما شرح تمام کارهایی که هوش مصنوعی انجام میدهد بسیار طولانی، غیرممکن و از حوصله این مقاله خارج است. اکثر افرادی که سوال دارند هوش مصنوعی چیست معمولاً به دنبال دوره هوش مصنوعی هم هستند. بنابراین در ادامه به معرفی مجموعه دورههای آموزش هوش مصنوعی پرداخته شده است.
شرکت هوش مصنوعی
امروزه در حدود ۵۰ درصد شرکتهای سراسر دنیا حداقل در یکی از عملکردهای کسب و کار خود از هوش مصنوعی استفاده میکنند. این مسئله باعث شده است میزان تقاضا برای به کارگیری روشهای هوش مصنوعی از سوی برترین شرکتهای فناوری در جهان به میزان زیادی افزایش داشته باشد.
ارزش بازار جهانی هوش مصنوعی در سال ۲۰۲۰ تقریباً حدود ۶۲ درصد تحمین زده شده است و انتظار میرود این میزان در ۶ سال آینده ۴۰ درصد رشد داشته باشد. هوش مصنوعی و فناوریهای مربوط به آن مثل یادگیری ماشین، پردازش زبان طبیعی، تشخیص شی و صدا و سایر موارد میتوانند تعداد زیادی از مشکلات کسب و کارها را با میزان زیادی از بهینگی و دقت رفع کنند.

در اکثر شرکتهای بسیار بزرگ مثل آمازون، اپل و مایکروسافت بخشی از شرکت یا یکی از شرکتهای زیر مجموعه آنها به توسعه قابلیتهای عملکردی هوش مصنوعی اختصاص دارد. مثلاً شرکت DeepMind که یکی از پیشتازان هوش مصنوعی به حساب میآید، زیرمجموعه شرکت مادر گوگل یعنی آلفابت است. برخی شرکتهای مستقل کوچکتر هم وجود دارند که تمرکز اصلی آنها هوش مصنوعی محسوب میشود. در ادامه تعدادی از برترین شرکتهای هوش مصنوعی معرفی شدهاند.
- DeepMind
- آمازون
- C3.ai
- H2O.ai
- IBM
- متا (Meta)
- NICE
- OpenAI
- SenseTime
- Salesforce
بسیاری از افراد علاوه بر سوال هوش مصنوعی چیست سوال مهم دیگری هم در ذهنشان وجود دارد و آن سوال این است که برنامه نویسی هوش مصنوعی چیست و چطور انجام میشود؟ لذا ادامه این مقاله به این مسئله اختصاص دارد.

برنامه نویسی هوش مصنوعی
برنامه نویسی نقش بسیار مهم و پررنگی در پیادهسازی کارکردها و عملکردهای هوش مصنوعی دارد. برنامه نویسی هوش مصنوعی میتواند معنیهای مختلفی داشته باشد. از ایجاد برنامههایی برای اجرای عملیات تشخیص الگو (با استفاده از یادگیری ماشین) گرفته تا «سیستمهای خبره» که حوزهای بسیار تخصصی است همگی جز برنامه نویسی هوش مصنوعی به حساب میآیند.

معمولاً برنامه نویسی هوش مصنوعی شامل برنامه نویسی کارکردهایی نظیر جستجو در فضای جواب، استفاده از برخی روشها (ساده یا پیچیده) و سایر مواردی میشود که برای رسیدن به پاسخی که با برخی از شرطهای خاص مطابقت دارد مورد استفاده قرار میگیرد.

درست مثل توسعه و ساخت نرمافزارهای سفارشی، در برنامه نویسی هوش مصنوعی هم انواع زبانهای مختلفی مورد استفاده قرار میگیرد. اما هیچ چیزی با عنوان بهترین زبان برای برنامه نویسی هوش مصنوعی وجود ندارد. در واقع فرایند توسعه به قابلیتهای عملکردی هوش مصنوعی بستگی دارد که مورد نیاز هستند و باید پیادهسازی شوند.
با استفاده از هوش مصنوعی میتوان قابلیتهای زیادی را اجرا کرد و مثلاً هوش زیستسنجشی (بیومتریک)، کنترل خودروهای خودران و بسیاری از موارد دیگر را میتوان در این خصوص نام برد. برای هر یک از این قابلیتهای مختلف نیاز به زبانهای برنامه نویسی هوش مصنوعی متفاوتی برای پروژه توسعه آنها وجود دارد. در ادامه برخی از محبوبترین و پراستفادهترین زبانهای برنامه نویسی هوش مصنوعی فهرست شدهاند:
نکته: برای استفاده از هوش مصنوعی لازم نیست که حتما خودمان آن را بسازیم یا اینکه از سرویسدهندههای اینترنتی استفاده کنیم. نسخههایی از بعضی مدلها وجود دارند که با دانلود و نصب آنها میتوان از هوش مصنوعی به صورت آفلاین استفاده کرد.
برنامه نویسی هوش مصنوعی با پایتون
الگوریتمهای اساسی هوش مصنوعی مثل رگرسیون (Regression) و دستهبندی (Classification) به صورت تخصصی با استفاده از کتابخانه scikit-learn در پایتون قابل پیادهسازی هستند. همچنین با کتابخانههای Caffe ،Keras و TensorFlow نیز میتوان یادگیری عمیق را با ظرافت بالا اجرا کرد.
بسیاری از کتابخانههای دیگر هم وجود دارند که باعث شدهاند پایتون به عنوان یکی از دسترسپذیرترین و بهترین زبانهای برنامه نویسی هوش مصنوعی تبدیل شود؛ برخی از این کتابخانهها در ادامه فهرست شدهاند:
حتی وقتی سخن از «پردازش زبان طبیعی» به میان میآید که امروزه برای تجربه کاربری بسیار ضروری است، به کمک ابزارهایی مثل SpaCy و NTLK زبان برنامه نویسی پایتون همچنان دارای برتری باقی میماند.
برنامه نویسی هوش مصنوعی با جاوا
برنامه نویسی هوش مصنوعی به اجرای سریع و زمان اجرای پرسرعت بسیار وابسته است. زبان جاوا این ویژگیها را دارد؛ به همین سبب با استفاده از این زبان برای برنامه نویسی هوش مصنوعی ارزش تولیدی بسیار مطلوبی فراهم میشود و امکان یکپارچهسازی عالی و بیعیب و نقص با استفاده از تمام چارچوبهای تحلیلی کلیدی در جاوا فراهم شده است.

به لطف فناوری ماشین مجازی جاوا، عملیات پیادهسازی با استفاده از این زبان در پلتفرمهای بسیاری امکانپذیر است. این یعنی وقتی اپلیکیشن هوش مصنوعی مربوطه نوشته میشود و کامپایل آن روی یک پلتفرم خاص صورت میگیرد، میتوان به سادگی با استفاده از شیوه یک بار نوشتن و اجرای چندین باره، آن را روی پلتفرمهای دیگر هم اجرا کرد. به همین دلیل است که بسیاری از پشتههای متنباز کلان داده بر بستر ماشین مجازی جاوا نوشته میشوند.
از جمله بزرگترین مزیتهای جاوا به عنوان زبان برنامه نویسی هوش مصنوعی میتوان به سادگی استفاده از آن، عیبیابی سریع، مدیریت حافظه، قابل حمل بودن و تطبیقپذیری مطلوب آن اشاره کرد. جاوا میتواند برای توسعه بسیاری از کاربردهای هوش مصنوعی از تجزیه و تحلیل دادهها گرفته تا پردازش زبان طبیعی، یادگیری عمیق، یادگیری ماشین و بسیاری از موارد دیگر مورد استفاده قرار بگیرد.
تعداد زیادی از کتابخانههای یادگیری ماشین برای زبان جاوا وجود دارند که از جمله میتوان Weka را نام برد که برای الگوریتمهای یادگیری ماشین، مدلسازی پیشگویانه و بسیاری از موارد دیگر استفاده میشود. همچنین تعدادی زیادی نرم افزار تحلیل آنلاین و ابزارهای متن باز داده کاوی مبتنی بر جاوا وجود دارند. بسیاری از ابزارهای محبوب پردازش کلان دادهها مثل Apache Hadoop ،Apache Hive و Apache Spark نیز با زبان جاوا نوشته شدهاند که این مسئله باعث میشود با استفاده از زبان جاوا امکان ادغام تمیز و بینقص با استفاده از این فریمورکهای تحلیل داده فراهم شود.
برنامه نویسی هوش مصنوعی با R
زبان برنامه نویسی R به صورت اختصاصی برای محاسبات آماری ساخته شده است. زبان R زبانی قدرتمند به حساب میآید که برای کاربردهای یادگیری ماشین و هر نوع دیگری از عملکردهای هوش مصنوعی استفاده میشود که در آنها باید محاسبات گسترده یا تحلیل داده انجام شود.
- مقاله مرتبط: ساخت شبکه های عصبی در نرم افزار R
در زبان برنامه نویسی R تعداد زیادی از کتابخانههای مرتبط با هوش مصنوعی را پشتیبانی شده است که از جمله آنها میتوان به MXNet ،TensorFlow ،Keras و بسیاری از موارد دیگر اشاره کرد. در زبان R از CARAT برای تمرین برنامه نویسی هوش مصنوعی در کاربردهای زیر استفاده میشود:
- دستهبندی (Classification)
- رگرسیون
- randomForest برای تولید درخت تصمیم

یکی از بزرگترین نقاط قوت زبان R محیط تعاملی این زبان است که شبیهسازی سریع و انتخاب مدل کاوشگرانه را بسیار آسان میکند. تعداد زیادی از زبانهای دیگر هم برای برنامه نویسی هوش مصنوعی استفاده میشوند که معرفی و ارائه توضیحات پیرامون همه زبانهای برنامه نویسی از حوصله این مقاله خارج است. در خصوص برنامه نویسی هوش مصنوعی پیشتر مقالهای مختص این موضوع در مجله فرادرس منتشر شده است که مطالعه آن برای کسب اطلاعات بیشتر پیرامون این موضوع به علاقهمندان پیشنهاد میشود:
- مقاله مرتبط: برنامهنویسی هوش مصنوعی چیست؟ + مسیر شروع و یادگیری
در ارتباط با اینکه برنامه نویسی هوش مصنوعی بسیاری از دانشجویان کامپیوتر میخواهند راجع درس هوش مصنوعی عهم نکات لازم را دریابیند. بنابراین بخش بعدی مقاله هوش مصنوعی چیست به این موضوع اختصاص داده شده است.
درس هوش مصنوعی
درس هوش مصنوعی یکی از درسهای تخصصی رشتههای علوم کامپیوتر، مهندسی کامپیوتر و مهندسی فناوری اطلاعات به حساب میآید. در این درس، مفاهیم مقدماتی و مباحث پایه هوش مصنوعی پوشش داده شدهاند. آشنایی با مفاهیم پایهای علوم کامپیوتر مثل طراحی الگوریتم، ساختمان داده و نظریه محاسبات پیش از انتخاب، مطالعه و یادگیری درس هوش مصنوعی لازم است. همچنین، کسب آشنایی با بعضی از مباحث ریاضی از جمله حساب دیفرانسیل و جبر خطی هم به درک و فهم بهتر برخی از مباحث مطرح شده در درس هوش مصنوعی بسیار کمک میکنند.

دانشجویان کامپیوتر اکثراً درس هوش مصنوعی را در سال دوم (نیمسال چهارم) یا سوم (نیمسال پنجم یا ششم) مقطع کارشناسی به عنوان یکی از واحدهای درسی خود انتخاب میکنند. درس هوش مصنوعی یکی از منابع تخصصی آزمون کارشناسی ارشد کامپیوتر گرایش هوش مصنوعی محسوب میشود. این درس برای آن دسته از دانشجویان و فارغالتحصیلان مقطع کارشناسی بسیار مهم است که قصد ادامه تحصیل و شرکت در کنکور کارشناسی ارشد گرایش هوش مصنوعی را دارند. درس هوش مصنوعی برای کنکور ارشد کامپیوتر (گرایش هوش مصنوعی) ۱۶۶ امتیاز دارد.
در مورد درس هوش مصنوعی پیش از این مقالهای جامع و کاربردی در مجله فرادرس منتشر شده است که مطالعه آن برای کسب اطلاعات کاملتر و آشنایی بیشتر با درس هوش مصنوعی به علاقهمندان پیشنهاد میشود:
پس از درس هوش مصنوعی، موضوع رشته هوش مصنوعی هم ذهن بسیاری از دانشجویان کامپیوتر را به خود مشغول کرده است. بنابراین ادامه مقاله هوش مصنوعی چیست به این موضوع اختصاص یافته است.
رشته هوش مصنوعی
رشته هوش مصنوعی در ایران گرایشی از رشته مهندسی کامپیوتر در مقطع کارشناسی ارشد و دکتری به حساب میآید. رشته هوش مصنوعی شامل درسهای نظری، عملی و تحقیقاتی در حوزه هوشمندسازی کامپیوترها و سیستمهای مبتنی بر کامپیوتر است. تحقق اهداف هوش مصنوعی با الهامگیری و شبیهسازی ویژگیهای موجودات زنده و به خصوص انسانها انجام میشود.

بنابراین ایجاد قابلیتهای عملکردی تجزیه و تحلیل اطلاعات، استدلال، یادگیری و رفتار هوشمندانه، حس بینایی، درک و تولید زبان و گفتار در کامپیوترها از اهداف اصلی این رشته به حساب میآیند.

در دوره ارشد هوش مصنوعی، دانشجویان با موضوعهایی مثل شبکههای عصبی، هوش مصنوعی پیشرفته، منطق فازی و سایر موارد آشنا میشوند. در گرایش هوش مصنوعی به طور عمده به ساخت سیستمهای هوشمند و رباتهای هوشمند (هم جنبههای نرم افزاری و هم سختافزاری) پرداخته میشود. در رشته هوش مصنوعی دانشجویان با موضوعهایی از قبیل موارد زیر آشنا میشوند:

- یادگیری ماشین
- شبکههای عصبی
- محاسبات تکاملی
- رباتیک (طراحی ربات هوشمند)
- منطق فازی
- سیستمهای خبره
- پردازش تصویر
- بینایی ماشین
- بازشناسی گفتار
- سایر موارد
دروس ارشد رشته هوش مصنوعی
در رشته هوش مصنوعی مقطع کارشناسی ارشد کامپیوتر با توجه به گرایشها، لازم است دانشجویان از ۳ گروه مختلف دروس ارائه شده را انتخاب کنند. هر یک از این گروهها در ادامه فهرست شدهاند:
- درسهای جبرانی
- درسهای اصلی
- درسهای اختیاری
دروس اصلی شامل ۹ واحد، دروس اختیاری ۱۲ واحد و همچنین ۲ واحد سمینار و ۶ واحد هم مختص پروژه است. البته این مقادیر ممکن است در دانشگاههای مختلف متفاوت است و اعداد بیان شده به رشته هوش مصنوعی شریف مربوط میشوند.
در ادامه دروس هر یک از این گروهها به طور مجزا معرفی شده است:
درس های جبرانی گرایش ارشد هوش مصنوعی
درسهای جبرانی رشته کامپیوتر در گرایش هوش مصنوعی در مقطع ارشد به شرح زیرند:
- سیگنالها و سیستمها (Signals and systems)
- درس هوش مصنوعی (Artificial Intelligence)
- طراحی الگوریتم (Design of Algorithms)
- ریاضیات مهندسی (Engineering Mathematics)
- جبر خطی (Linear Algebra)
درسهای جبرانی رشته هوش مصنوعی در واقع به نوعی پیشنیازهای این رشته به حساب میآیند و به این ترتیب دانشجویان مقطع کارشناسی میتوانند با تقویت دانش و مهارت در این درسها خود را برای وارد شدن به رشته هوش مصنوعی آماده کنند.
درس های اصلی گرایش ارشد هوش مصنوعی
انتخاب حداقل ۳ درس (یعنی ۹ واحد) از درس های اصلی اجباری است. در ضمن درسهایی را که دانشجویان قبلاً در دوره کارشناسی گذراندهاند را نمیتوان دوباره اخذ کرد. دروس اصلی رشته هوش مصنوعی (گرایش هوش ارشد) در ادامه فهرست شدهاند:

- برنامهریزی در هوش مصنوعی (Planning in Artificial Intelligence)
- هوش مصنوعی پیشرفته (Advanced Artificial Intelligence)
- یادگیری ماشین (Machine Learning)
- پردازش تصویر (Image Processing)
- فرآیندهای تصادفی (Stochastic Processes)
- پردازش گفتار (Speech Processing)
- پردازش زبان طبیعی (Natural Language Processing)
- پردازش علائم دیجیتال (Digital Signal Processing)
درس های اختیاری گرایش ارشد هوش مصنوعی
درسهای اختیاری رشته هوش مصنوعی (گرایش ارشد هوش رشته کامپیوتر) به شرح زیرند:
- بینایی ماشین (Machine Vision)
- نظریه یادگیری ماشین (Machine Learning Theory)
- یادگیری عمیق (Deep Learning)
- مدلهای احتمالاتی گرافی (Probabilistic Graphical Models)
- هوش محاسباتی (Computational Intelligence)
- پردازش پیشرفته علائم دیجیتال (Advanced Digital Signal Processing)
- روباتیک (Robotics)
- بازشناسی گفتار (Speech Recognition)
- پردازش پیشرفته تصویر (Advanced Image Processing)
- پردازش سیگنالهای ویدئویی (Video Signal Processing)
- بهسازی گفتار (Speech Enhancement)
- نظریه الگوریتمی بازیها (Algorithmic Game Theory)
- هوش مصنوعی توزیع شده (Distributed Artificial Intelligence)
- مفاهیم پیشرفته در هوش مصنوعی (Advanced Topics in Artificial Intelligence)
- شبکههای دینامیکی پیچیده (Complex Dynamical Networks)
- یادگیری ماشین آماری (Statistical Machine Learning)
- بینایی پیشرفته سهبعدی کامپیوتر (Advanced 3uoD Computer Vision)
- بهینهسازی محدب (Convex Optimization)
- نظریه اطلاعات و کدینگ (Information Theory and Coding)

حال که میدانیم هوش مصنوعی چیست ممکن است در خصوص آینده آن ابهاماتی در ذهن ما ایجاد شوند. بنابراین در بخش بعدی مقاله هوش مصنوعی چیست به طور مختصر پیرامون آینده هوش مصنوعی از زبان اندرو اینگ دانشمند سرشناس در این حوزه پرداخته شده است.
آینده هوش مصنوعی
اینکه دقیقاً در آینده هوش مصنوعی چه اتفاقی خواهد افتاد هنوز مشخص نشده است. به گفته «اندرو اینگ» (Andrew Ng) دانشمند محبوب علوم کامپیوتر و کارآفرین فناوری، در خصوص تعریفهایی برای اینکه چه چیزی هوش مصنوعی است و چه چیزی نیست توافق نظر قطعی وجود ندارد. به عقیده اندرو اینگ هوش مصنوعی یعنی انسان در تلاش مداوم برای واداشتن ماشینها به رفتار هوشمندانهتر باشد و از آن برای کمک به بشریت استفاده کند.

اندرو اینگ باور دارد که تاثیرات اصلی و مهم هوش مصنوعی هنوز مشاهده نشدهاند و وظیفه همگان است که نقش خود را در آینده هوش مصنوعی ایفا کنند. یکی از باورهای رایجی که در خصوص آینده هوش مصنوعی وجود دارد این است که رباتهای قاتل شیطانی جهان را به تسخیر خود در خواهند آورد، اما بسیاری از دانشمندان و صاحبنظران هوش مصنوعی با این عقیده مخالف هستند و این باور را بیش از حد مبالغهآمیز میدانند.
این امید وجود دارد که شاید روزی بتوان تقریباً هر کاری را با استفاده از هوش مصنوعی انجام داد یا حتی کارهای بیش از آنچه یک انسان معمولی میتواند انجام دهد را به انجام رساند. به باور اندرو اینگ، هوش مصنوعی نمیتواند یک نوشدارو باشد که با استفاده از آن بتوان همه مشکلات روی زمین را حل کرد، اما آنهایی که به این فناوری دسترسی دارند در قبال ایفای نقش در این حیطه مسئول هستند و تا جایی که میتوانند باید کمک کنند تا آینده روشنی برای هوش مصنوعی رقم بخورد.

در دنیای هوش مصنوعی زمان بسیار زیادی برای مهندسی نرم افزار صرف شده و اکنون زمان آن فرا رسیده است تا در آینده هوش مصنوعی در زمینه مهندسی دادهها هم پیشرفتهایی حاصل شوند. به عقیده اندرو اینگ این امکان در آینده هوش مصنوعی دیده میشود که به وسیله AI فناوری مردم نهادتر و عمومیتر شود و کنترل آن در اختیار جامعه قرار بگیرد و توسعه آن به نفع جامعه و بشریت پیشرفت داشته باشد.
بسیاری دوست دارند بدانند وضعیت هوش مصنوعی در ایران چگونه است و آیا بازار کار مناسبی دارد؟ بنابراین در ادامه مقاله هوش مصنوعی چیست به این مسئله پرداخته میشود.
هوش مصنوعی در ایران
به طور قطع هوش مصنوعی در ایران نسبت به کشورهای پیشتاز در این حوزه نیاز به پیشرفتهای بسیار بیشتری دارد. در زمینه هوش مصنوعی در ایران پیشرفتهایی حاصل شده است و فعالیتهایی در حال انجام هستند. در هر صورت هوش مصنوعی در ایران هم در حال حرکت رو به جلو است و در حوزههایی مثل بازاریابی، بازارهای مالی و سایر موارد از آن استفاده میشود.

به همین دلیل نیاز به متخصصان هوش مصنوعی در ایران هم وجود دارد و فرصتهای شغلی مختلفی در این حوزه پدید آمده است. بنابراین بهتر است در ادامه به وضعیت بازار کار هوش مصنوعی در ایران پرداخته شود.
بازار کار هوش مصنوعی در ایران چه وضعیتی دارد؟
در سالهای اخیر بازار کار هوش مصنوعی در ایران بیشتر رونق گرفته و در برخی از شرکتها چند سالی است که فعالیتهایی مرتبط با هوش مصنوعی بهطور مستقیم یا غیرمستقیم انجام میشود. با توجه به اینکه هوش مصنوعی زمینهای بسیار تاثیرگذار و مهم در صنایع و کسب و کارهاست و آینده روشنی دارد، پیشبینی میشود بازار کار آن هم رشد وسیعی در ایران و جهان داشته باشد.
بنابراین انتظار میرود تقاضا برای استخدام متخصصینی که در زمینه هوش مصنوعی فعالیت میکنند هم با گذشت زمان افزایش یابد. در ادامه با استفاده از وب سایتهای مطرح کاریابی در ایران برخی از موقعیتهای شغلی حوزه هوش مصنوعی در ایران فهرست شدهاند. سعی شده است ترتیببندی این فهرست براساس میزان تقاضا و تعداد آگهیها انجام شود.
- کارشناس هوش تجاری (BI)
- کارشناس هوش مصنوعی
- کارشناس تحلیل داده و هوش تجاری
- پژوهشگر هوش مصنوعی
- سرپرست هوش تجاری
- برنامه نویس هوش مصنوعی
- مهندس هوش مصنوعی
- برنامه نویس پردازش تصویر و هوش مصنوعی
- تحلیلگر داده
- کارشناس پردازش تصویر
- کارشناس ارشد پردازش تصویر
- دانشمند داده
- کارشناس تحول دیجیتال - تخصص هوش مصنوعی
- مدرس دورههای هوش مصنوعی
- کارآموز رباتیک
یکی از مباحث مهم در ارتباط با اینکه هوش مصنوعی چیست میتوان تاریخچه آن باشد. لذا در ادامه سعی شده است به طور مختصر و کاربردی به تاریخچه هوش مصنوعی پرداخته شده است.

تاریخچه هوش مصنوعی
اگرچه امروزه هوش مصنوعی یا به اختصار AI تقریباً برای همگان تبدیل به اصطلاحی رایج و ورد زبانها شده است، ارائه شرحی خلاصه اما کاربردی و دقیق از تاریخچه هوش مصنوعی نشان میدهد که هوش مصنوعی چندان مفهوم جدیدی نیست. در واقع پیدایش هوش مصنوعی به زمان اختراع کامپیوترهای شخصی باز میگردد که بیش از ۲ دهه پیش اتفاق افتاده است. پیشرفتها در زمینه AI به طور قابل توجهی در حال رخ دادن هستند و این پیشرفتهای گسترده به واسطه توان محاسباتی سریعتری حاصل شده که در فناوری ساخت کامپیوترها بدست آمده است.

علاوه بر این، انفجار دادههای دیجیتال و افزایش سرعت پیشرفت ساختارهای ارتباطی نیز تاثیری عمیقی در رشد هوش مصنوعی داشته است. از جهتهای بسیار، تجاریسازی هوش مصنوعی تنها در آغاز راه قرار دارد و عمیقاً دنیا را تحت تاثیر خود قرار خواهد داد. درست همانطور که اینترنت و گوشیهای هوشمند تحولات عظیمی را به وجود آوردهاند، هوش مصنوعی هم بیشتر از همه، تاثیرهای شگرفی را در طول تاریخ داشته است و در آینده نیز این روند به گونهای پر رنگتر ادامه خواهد داشت.
خط سیر تاریخچه هوش مصنوعی
در این بخش فهرستی از روند پیشرفت هوش مصنوعی از ابتدا تا کنون به صورت زیر ارائه شده است:
- ۱۹۵۰:
- آلن تورینگ (Alan Turing) ایده «آزمون تورینگ» را مطرح کرد.
- در همان سال «ایساک عظیموف» (Issac Asimov) ۳ قانون رباتیک را پیشنهاد داد.
- ۱۹۵۱: اولین برنامه مبتنی بر هوش مصنوعی نوشته شد.
- ۱۹۵۹: اولین برنامه خودآموزی ساخته شد که بازی کامپیوتری انجام میداد.
- ۱۹۵۹: آزمایشگاه هوش مصنوعی MIT راهاندازی شد.
- ۱۹۶۱: اولین ربات در خط تولید شرکت جنرال موتور به کار گرفته شد.
- ۱۹۶۴: نمونه پیشتولید اولین برنامهای اختراع شد که میتوانست زبان طبیعی را بفهمد و درک کند.
- ۱۹۶۵: اولین چتبات جهان به نام «الایزا» (Eliza) خلق شد.
- 1974: اولین وسیله نقلیه خودران در آزمایشگاه هوش مصنوعی دانشگاه استنفورد ساخته شد.
- ۱۹۸۸: «آندره گرِی» (Andre Gray) اولین بات خزنده اینترنت را به نام «Inkling» خلق کرد.
- ۱۹۸۹: اولین وسیله نقلیه خودران با استفاده از شبکههای عصبی توسط دانشگاه کارنگی ملون (Canegie Mellon) ساخته شد.
- ۱۹۹۴: آندره گری فناوری برتری ذهن بر ماده را اختراع کرد.
- ۱۹۹۷: هوش مصنوعی Deep Blue که توسط شرکت IBM ساخته شده، «گری کسپر» (Garry Kasper) را در بازی شطرنج شکست داد.

- ۱۹۹۹:
- شرکت سونی ربات «آیبو» (AIBO) را معرفی کرد.
- در همین سال آزمایشگاه هوش مصنوعی MIT اولین ربات هوش مصنوعی احساسی را به نمایش گذاشت.
- ۲۰۰۴: «دارپا» (DARPA) چالش وسیله نقلیه خودران را معرفی کرد.
- ۲۰۰۹: گوگل ساخت خودروهای خودران را آغاز کرد.
- ۲۰۱۰: هوش مصنوعی Quill شرکت Narative Science معرفی شد که میتواند گزارشنویسی کند.
- ۲۰۱۱:
- هوش مصنوعی واتسون شرکت IBM در مسابقه تلویزیونی Jeopardy پیروز میشود.
- در همین سال «سیری» (Siri)، Google Now و Cortana به جریان اصلی هوش مصنوعی تبدیل شدند.
- ۲۰۱۵: ایلان ماسک و سایرین یک میلیارد دلار به شرکت «Open AI» کمک کردند.
- ۲۰۱۶:
- هوش مصنوعی DeepMind گوگل قهرمان بازی Go را شکست داد.
- در همین سال دانشگاه استنفورد گزارش AI 100 را صادر کرد.
- دانشگاه برکلی کالیفرنیا مرکز هوش مصنوعی سازگار با انسان را تاسیس کرد.
- ۲۰۱۷:
- حلکننده مسئله رضایتپذیری بولی منطق گزارهای (SAT) یک فرضیه دیرینه ریاضی را در مورد سهگانه فیثاغورث بر مجموعه اعداد صحیح به اثبات رساند.
- یک بات ساخته شده با یادگیری ماشین در OpenAI در مسابقات بین المللی Dota 2 سال ۲۰۱۷ بازی کرد. این بات در بازی هیجانانگیزی در برابر بازیکن حرفهای Dota 2 به نام دندی برنده شد.
- DeepMind شرکت گوگل هوش مصنوعی AlphaGo Zero را که نسخهای بهبود یافته از AlphaGo به حساب میآمد را آشکار کرد.
- هوش مصنوعی پردازش زبان طبیعی شرکت Alibaba بر برترین انسانها در آزمون خواندن و درک مطلب دانشگاه استنفورد چیره شد.

- ۲۰۱۸: معرفی Google Duplex، سرویسی که به دستیار هوش مصنوعی اجازه میدهد قرار ملاقات را از طریق تلفن رزرو کند.
- ۲۰۱۹: AlphaStar از DeepMind به سطح استادبزرگی در بازی StarCraft II رسید و عملکردش از 99.8 درصد بازیکنان انسانی بهتر بود.
- ۲۰۲۰: توسعه کتابخانه بهینهسازی DeepSpeed ساخته شده توسط شرکت مایکروسافت برتی PyTorch انجام شد.
آزمون تورینگ چیست ؟
آزمون تورینگ (Turing Test) توسط دانشمند کامپیوتر، آلن تورینگ ساخته شده است که به نوعی آغازگر هوش مصنوعی در تاریخچه آن به شمار میرود و در فرهنگ علمیتخیلی و بحثهای مربوط به رباتهای هوشمند زیاد از آن نام برده میشود. اما آزمون تورینگ یا همان تست تورینگ دقیقاً چیست؟ و اگر یک کامپیوتر آزمون تورینگ را با موفقیت بگذراند به چه معناست؟ آلن تورینگ اولین بار آنچه تست تورینگ نامیده میشود را در مقالهای به سال ۱۹۵۰ توصیف کرده است. تورینگ قصد داشت به این سوال پاسخ دهدد که آیا ماشینها هم میتوانند تفکر کنند؟ برای رسیدن به پاسخ این سوال او آزمونی فرضی را طراحی کرد که در ادامه شرح داده شده است.

برای درک آزمون تورینگ باید بازیای را در نظر گرفت که ۳ بازیکن دارد. یکی از بازیکنان بازجو است که در شرایطی ایزوله شده از ۲ بازیکن دیگر جدا است. یکی دیگر از بازیکنان انسان و دیگری یک کامپیوتر است.

وظیفه بازجو این است که سعی کند با پرسیدن سوالاتی از هر یک از ۲ بازیکن دیگر بفهمد کدام انسان و کدام بازیکن کامپیوتر است؟ برای سختتر شدن بازی، کامپیوتر باید سعی کند بهگونهای پاسخ دهد تا بازجو انتخاب اشتباهی انجام دهد. به بیان دیگر در این آزمون کامپیوتر باید سعی کند تا جایی که میتواند دقیقاً مانند انسان عمل کند و بازجو را فریب دهد. در واقع در تست تورینگ اگر بازجو نتواند انسان را از کامپیوتر تشخیص دهد، آنگاه ممکن است آن کامپیوتر دارای قدرت تفکر باشد.
تلاشها برای ساخت کامپیوترهایی که بتوانند انسانها را فریب دهند، دارای چالشهای شگفتانگیزی هستند. مثلاً ساخت کامپیوتری که بتواند در لطیفهگویی تبحر داشته باشد کار بسیار دشواری به حساب میآید. تست تورینگ برای ارزیابی هوشمندی رباتها آزمون چندان بینقصی نیست. برای نمون آزمون تورینگ مشوق حیلهگری است. مثلاً در گذشته تلاشی توسط برنامهای صورت گرفته بود که وانمود میکرد پسر جوانی است و زبان انگلیسی زبان اولش نیست و هر گونه لغزش زبانی را از این طریق پوشش داده بود.

علاوه بر این آزمون تورینگ را نمیتوان برای هوشمندی غیرانسانی به کار گرفت. امروزه برخی از هوشمندترین کامپیوترها هرگز فرصتی برای تظاهر به انسان بودن ندارند. اما این مسئله به هیچ عنوان نشان دهنده این موضوع نیست که چنین سیستمهایی اصلاً تاثیرگذار نیستند و قابل تحسین نیستند. به همین صورت اگر ربات یا کامپیوتری آزمون تورینگ را پاس کند، این هم به این معنا نخواهد بود که میتوان آن را به عنوان ربات هوشمند در نظر گرفت. اما به هر ترتیب آزمایش تورینگ اطلاعات زیادی را برای تفکر پیرامون نحوه تعریف رفتار هوشمندانه و اینکه از رباتهای هوشمند چه انتظاری میرود در اختیار دانشمندان قرار میدهد.
یکی دیگر از موضوعات مهمی که پیرامون سوال هوش مصنوعی چیست مطرح میشود، بحث شاخههای مختلف این حوزه یعنی هوش مصنوعی است که به همین خاطر در ادامه به آن پرداخته شده است.
شاخه های هوش مصنوعی
هوش مصنوعی خود شاخهای از علوم کامپیوتر است. «یادگیری ماشین» و «یادگیری نمادین» (Symbolic Learning) شاخههای اصلی هوش مصنوعی به حساب میآیند. یادگیری ماشین را میتوان به دو شاخه یادگیری آماری (Statistical Learning) و یادگیری عمیق تقسیم کرد. «بینایی ماشین» و «رباتیک» نیز دو شاخه منشعب شده از یادگیری نمادین محسوب میشوند. در ادامه، هر یک از شاخههای هوش مصنوعی به بیان ساده و کوتاه شرح داده شدهاند. پیش از آن فهرستی از تمام شاخههای هوش مصنوعی ارائه شده است:
- تشخیص گفتار
- پردازش زبان طبیعی
- بینایی ماشین
- رباتیک
- تشخیص الگو
- شبکههای عصبی مصنوعی
- یادگیری عمیق
- شبکه عصبی پیچشی
- شبکه عصبی بازگشتی
- یادگیری ماشین
- یادگیری تقویتی
تشخیص گفتار در هوش مصنوعی
جهت برقراری ارتباط، انسانها میتوانند به زبانهای گفتاری مختلف حرف بزنند و بشنوند. معادل این مهارت در هوش مصنوعی، حوزه تشخیص گفتار (Speech Recognition) است. بخش وسیعی از تشخیص گفتار مبتنی بر علم آمار به حساب میآید که به آن یادگیری آماری (Statistical Learning) میگویند. تشخیص گفتار به توانایی ماشین در درک کلمات بیان شده گفته میشود. یک میکروفن صدای فردی را ضبط میکند و سختافزار سیگنال مربوطه را از امواج صدای آنالوگ به صوت دیجیتال تبدیل میکند. سپس، داده صوتی به وسیله نرمافزار پردازش میشود تا تفسیر صدا را به صورت کلمات مجزا انجام دهد.

پردازش زبان طبیعی در هوش مصنوعی
انسانها میتوانند به زبانهای گوناگونی متن را بخوانند و بنویسند. این مهارت در هوش مصنوعی با شاخه پردازش زبان طبیعی (Natural Language Processing) مرتبط است. پردازش زبان طبیعی که با سرنام NLP از آن یاد میشود، حوزهای در هوش مصنوعی به حساب میآید که با تعامل بین کامپیوترها و انسانها از راه زبان طبیعی سر و کار دارد. هدف نهایی NLP در خواندن، دریافت، درک و فهمیدن زبانهای انسانی و استفاده از این توانایی در موارد استفاده ارزشآفرین خلاصه میشود.

بینایی ماشین در AI
انسانها میتوانند با چشمان خود ببینند و آنچه را میبینند تجزیه و تحلیل کنند. چنین مهارتی در هوش مصنوعی با بینایی ماشین (بینایی کامپیوتر | Computer Vision) محقق میشود. بینایی ماشین بخشی از شیوههای یادگیری نمادین جهت پردازش اطلاعات به وسیله کامپیوترها محسوب میشود. انسانها صحنههای اطراف را از طریق چشمهای خود تشخیص میدهند. این کار منتج به شکلگیری تصاویری از آن جهان میشود. به کارگیری حوزه پردازش تصویر با وجود اینکه مستقیماً جزئی از هوش مصنوعی به حساب نمیآید، اما در هر صورت برای بینایی ماشین ضروری است.

رباتیک در Artificial Intelligence
انسانها میتوانند درکی از محیط اطراف خود داشته باشند و به راحتی در محیط نقل مکان کنند. به این شاخه هوش مصنوعی رباتیک (Robotics) میگویند. رباتیک نقطه تلاقی علم، مهندسی و فناوری است که برای تولید ماشینهایی به نام ربات استفاده میشود. یک ربات رفتار انسان را تقلید میکند و میتوان ار آن به جای انسان در کاربردهای مختلف استفاده کرد.

ربات ماشینی است که میتوان به وسیله آن برای انجام برخی اقدامات پیچیده برنامهریزی کرد. سه محور اصلی رباتیک، تفکر (Think)، حس (Sense) و عمل (Act) است. یعنی تنها در صورتی میتوان یک ماشین را ربات نامید که بتواند حس کند، تفکر کند و اعمالی را انجام بدهد.
تشخیص الگو در هوش مصنوعی
انسانها توانایی تشخیص الگوها را دارند. مثلاً میتوانند اشیاء مشابه را طبقهبندی کنند. به این حوزه در هوش مصنوعی بازشناسی الگو (تشخیص الگو | Pattern Recognition) میگویند. در حوزه تشخیص الگو، ماشینها مهارت بیشتری دارند، زیرا میتوانند دادهها و ابعاد داده بیشتری را در زمان کمتر پردازش کنند. تشخیص الگو بخشی از حوزه یادگیری ماشین محسوب میشود.

شبکه های عصبی مصنوعی در AI
مغز انسان از شبکهای از نورونها (Neuron) تشکیل شده است. انسانها این شبکه نورونها را برای یادگیری به کار میگیرند. اگر امکان بازتولید کارکرد و ساختار مغز انسان وجود داشته باشد، ممکن است بتوان در ماشینها به قابلیتهای هوشمندانه دست پیدا کرد. به این حوزه در هوش مصنوعی شبکههای عصبی مصنوعی (Artificial Neural Networks) میگویند.
یادگیری عمیق در Artifitial Intelligence
در صورتی که شبکههای عصبی پیچیدهتر و عمیقتر شوند و از آنها برای یادگیری مسائل پیچیده استفاده شود، به آن یادگیری عمیق (Deep Learning) گفته میشود. یادگیری عمیق دارای انواع و روشهای مختلفی برای بازتولید عملکرد مغز انسان است.

شبکه عصبی پیچشی در هوش مصنوعی
وقتی از شبکههای عصبی مصنوعی برای مرور تصاویر (مثلاً از بالا به پایین یا از چپ به راست) استفاده میشود، آن را شبکه عصبی پیچشی (شبکه عصبی کانولوشن | Convolutional Neural Network) مینامند که مخفف آن هم CNN است. از CNN برای شناسایی اشیا (Object Recognition) در صحنه استفاده میشود. بنابراین، بینایی ماشین با استفاده از CNN نیز قابل انجام است. در ادامه به این موضوع پرداخته شده است که شاخه شبکه عصبی بازگشتی در هوش مصنوعی چیست ؟
شبکه عصبی بازگشتی در AI
انسانها میتوانند گذشته را به خاطر بسپارند. مثلاً یک فرد میتواند به یاد بیاورد که شام دیشب چه بوده است. میتوان یک شبکه عصبی را به یادآوری گذشته به میزان محدود وا داشت. به این شاخه هوش مصنوعی، شبکه عصبی بازگشتی (Recurrent Neural Network) میگویند. اینجا میتوان به این نتیجه رسید که هوش مصنوعی به دو روش عمل میکند. یک روش به صورت نماد محور و شیوه دیگر به صورت داده محور است. در شیوه داده محور، که به آن یادگیری ماشین گفته میشود، لازم است دادههای زیادی را برای یادگیری در اختیار ماشین گذاشت.

یادگیری ماشین در Artificial Intelligence
یادگیری ماشین کاربردی از هوش مصنوعی به حساب میآید که امکان یادگیری خودکار و بهبود تجربه یادگیری را بدون برنامهریزی دقیق در ماشین (کامپیوتر) فراهم میسازد. تمرکز یادگیری ماشین روی ساخت برنامههای کامپیوتری قرار دارد که میتوانند به دادهها دسترسی داشته و از آنها برای یادگیری به صورت خودکار استفاده کنند. به عنوان مثال، اگر دادههای زیادی وجود داشته باشند که نسبت فروش به هزینه تبلیغات را نشان دهند، میتوان این دادهها را در فضای دوبُعدی رسم کرد و به نوعی الگو رسید.
اگر ماشین بتواند چنین الگویی را یاد بگیرد، آنگاه میتواند بر اساس آنچه آموخته پیشبینی انجام دهد. در حالی که درک و یادگیری فضاهای یک، ۲ یا ۳ بُعدی برای انسانها آسان است، ماشینها میتوانند در ابعاد بسیار بالاتری یادگیری انجام دهند. ماشینها میتوانند حجمهای زیادی از دادهها را پردازش کنند و الگوهایی را در آن ها پیدا کنند. وقتی ماشین چنین الگوهایی را یاد بگیرد، میتواند پیشبینیهایی را انجام دهد که انسان هرگز قادر به انجام آنها نخواهد بود.
فنون یادگیری ماشین چه هستند ؟
میتوان از هر یک از فنون یادگیری ماشین برای حل مسائل استفاده کرد. از جمله این فنون میتوان دستهبندی (Classification) یا پیشبینی (Prediction) را نام برد. به عنوان مثال، وقتی از دادههای مشتریان برای تخصیص آنها به یک گروه خاص (مثل بزرگسالان جوان) استفاده شود، آنگاه عملیات دستهبندی یا همان طبقهبندی انجام شده است. در صورتی که از دادهها جهت پیشبینی نرخ از دست دادن مشتریها استفاده شود، از روش پیشبینی در یادگیری ماشین استفاده شده است.
یادگیری نظارت شده و نظارت نشده چیست ؟
رویکرد دیگری برای دستهبندی الگوریتمهای یادگیری در هوش مصنوعی وجود دارد. در این نگرش، الگوریتمها به دو دسته کلی نظارت شده (Supervised) و نظارت نشده (Unsupervised) تقسیمبندی میشوند. در ادامه این بخش از مطلب درس هوش مصنوعی، هر یک از این دو دسته شرح داده شدهاند:
- یادگیری نظارت شده: در صورتی که الگوریتمی با دادههایی آموزش داده شود که دارای جواب هستند، این الگوریتم در دسته یادگیری نظارت شده (Supervised Learning) قرار میگیرد. برای مثال، وقتی یک ماشین برای شناسایی افراد به وسیله نام آنها آموزش داده میشود، باید اسامی آنها را برای کامپیوتر تعیین کرد.
- یادگیری نظارت نشده: در صورتی که الگوریتمی با دادههایی برای تشخیص الگوها آموزش داده شود، به آن یادگیری غیر نظارت نشده (unsupervised Learning) گفته میشود. مثلاً در یادگیری نظارت نشده، دادههای مربوط به اجرام آسمانی در جهان هستی به ماشین خورانده میشوند و از ماشین این انتظار وجود دارد که به تنهایی الگوهایی را در دادهها بیابد.

یادگیری تقویتی در هوش مصنوعی
اگر برای هر الگوریتمی یک هدف تعیین شود و این انتظار از ماشین وجود داشته باشد که از طریق آزمون و خطا به آن هدف دست یابد، آنگاه به این کار یادگیری تقویتی (Reinforcment Learning) گفته میشود. بنابراین، معرفی شاخههای مختلف هوش مصنوعی در اینجا به پایان میرسد. در ادامه مقاله درس هوش مصنوعی ، چکیدهای از این درس ارائه شده است.
حالا که تقریباً به طور جامع دریافتهایم هوش مصنوعی چیست باید راجع به کاربردهای آن هم اطلاعات لازم را بدست آورد. بنابراین در ادامه به این مسئله پرداخته شده است که هوش مصنوعی چه کاربردی دارد؟
هوش مصنوعی چه کاربردی دارد؟
کاربرد و محبوبیت هوش مصنوعی روزبهروز در حال اوج گرفتن بیشتر است. کاربردهای هوش مصنوعی در طول سالهای اخیر بهطور قابل ملاحظهای پیشرفت داشتهاند و امروزه تقریباً در تمام بخشهای صنایع و کسب و کارهای مختلف از AI به طور گسترده استفاده میشود. در این بخش به شرح کاربردهای هوش مصنوعی در دنیای واقعی پرداخته شده است. هر یک از حوزهها و صنایع مختلفی که هوش مصنوعی در آنها کاربرد دارد در ادامه فهرست شدهاند:
- پزشکی
- تجارت الکترونیک
- آموزش
- سبک زندگی
- حمل و نقل
- رباتیک
- منابع انسانی
- کشاورزی
- بازیهای کامپیوتری
- شبکههای اجتماعی
- بازاریابی
- بانکداری و بازارهای مالی
حال در ادامه این مطلب از مجله فرادرس به شرح برخی از کاربردهای هوش مصنوعی در دنیای واقعی پرداخته شده است.
کاربردهای هوش مصنوعی در پزشکی
در حال حاضر از یادگیری ماشین به وسیله کسب و کارها برای تولید پیشبینیهایی بهتر و سریعتر نسبت به انسان استفاده میشود. پزشکان میتوانند با استفاده از هوش مصنوعی و یادگیری ماشین سرطان را پیش از آنکه خیلی دیر شود شناسایی کنند. هوش مصنوعی میتواند باعث شود کیفیت درمان و امنیت بیماران به وسیله بهبود پیشبینی، ثُبات بیشتر و افزایش قابلیت اطمینان ارتقا یابد.

یکی از فناوریهای هوش مصنوعی که به طور گسترده از آن استفاده میشود IBM Watson است. واتسون قابلیت درک و پردازش زبان طبیعی را دارد و به پرسوجوها پاسخ میدهد. این سیستم گزارشی را براساس دادههای مربوط به بیمار و سایر مجموعههای داده تولید میکند و در نهایتطرح درجهبندی اطمینان را ارائه می کند.
کاربردهای هوش مصنوعی در بانکداری و بازارهای مالی
امروزه فناوریهای هوش مصنوعی متنوع و گوناگونی به وسیله بسیاری از بانکها برای شناسایی فعالیتهای مجرمانه و سایر مقاصد استفاده میشوند. بسیاری از بانکها شروع به استفاده از راهکارهای مبتنی بر هوش مصنوعی برای فراهم کردن خدمات مشتریان، شناسایی ناهنجاریها و جلوگیری از کلاهبرداریهای مربوط به کارتهای اعتباری کردهاند.
ماشینها در چنین زمینههایی بسیار بینقص عمل میکنند، زیرا میتوانند حجم زیادی از دادهها را در مدت زمانی بسیار اندکی پردازش کنند. علاوه بر این، ماشینها ممکن است بیاموزند چگونه الگوها را در دادههای تاریخی شناسایی کنند و حدس بزنند که این الگوها در آینده چگونه ممکن است دوباره اتفاق بیوفتند. دادههای شخصی جمعآوری و توصیههای مالی از طریق اپلیکیشنهای هوش مصنوعی ارائه میشوند.
کاربردهای هوش مصنوعی در آموزش
در گذشته نیز از هوش مصنوعی در آموزش، بیشتر در قالب ابزاری استفاده میشد که به توسعه مهارتها و سیستمهای ارزیابی کمک میکنند. با پیشرفت راهکارهای آموزشی در هوش مصنوعی ، هدف این است که AI بتواند برای شکافهای موجود بین آموزش و یادگیری پُلهایی بزند و از این طریق بتوان به مدارس و مدرسان کمک کرد تا تلاش بیشتر و کارهای موثرتری را انجام دهند.
به وسیله هوش مصنوعی میتوان تاثیرگذاری، شخصیسازی و مسئولیتهای مدیریتی را به وسیله ایجاد زمان و انعطافپذیری بیشتر برای مدرسان بهبود داد تا تمرکز بیشتر بر درک و سازگاری استعدادهای انسانی معطوف شود که هوش مصنوعی و کامپیوترها فعلاً در تشخیص آنها مشکل دارند.

به وسیله ترکیب کردن بهترین قابلیتهای رباتها و مدرسان، هدف هوش مصنوعی در آموزش این است که این دو با یکدیگر همکاری کنند تا دانشآموزان نتایج بهتری بگیرند و خروجی کارشان بهبود پیدا کند. به دلیل اینکه دانشآموزان امروزی ناچارند در دنیایی کار کنند که هوش مصنوعی هنجار و معیار به حساب میآید، بسیار حیاتی است که موسسهها آنها را برای استفاده از این فناوری و تطبیق با آن آماده کنند. در ادامه به این سوال پاسخ داده شده است که در کشاورزی کاربرد هوش مصنوعی چیست ؟
کاربرد هوش مصنوعی در کشاورزی
اقدامات لازم برای بهکارگیری هوش مصنوعی در کشاورزی هم در خصوص کالاهای زراعی و هم پیرامون شیوههای کشاورزی در مزرعه به سرعت در حال انجام است. محاسبات شناختی در مسیر تبدیل شدن به انقلابیترین فناوری در زمینه خدمات کشاورزی است، زیرا میتواند شرایط و موقعیتهای مختلفی را برای بهبود کارایی درک کند، بیاموزد و به آنها پاسخ دهد. به کمک هوش مصنوعی میتوان کشاورزان را در خصوص استخراج ارزش بیشتر از زمینشان در عین حفاظت از منابع هدایت و راهنمایی کرد. در ادامه به این سوال پاسخ داده شده که در بازیهای کامپیوتری کاربرد هوش مصنوعی چیست ؟
کاربرد هوش مصنوعی در بازی های کامپیوتری
در طول سالهای متمادی، هوش مصنوعی به جنبهای کلیدی در کسب و کار بازیهای کامپیوتری تبدیل شده است. در بازیهای کامپیوتری AI بیشتر برای تصمیمگیری در خصوص چگونگی رفتار کاراکترهای غیر بازیکن (Non-Player Characters | NPC) استفاده میشود. در تولید بازیهای کامپیوتری بیشتر کارکردهای هوش مصنوعی برای تعیین نحوه رفتار حریف کامپیوتری به کار میروند. این رفتار میتواند از الگوهای ساده در بازیهای اکشن گرفته تا سیستمهای شطرنجی را شامل شود که میتوانند قهرمانان جهان و بازیکنان حرفهای را شکست دهند.
کاربرد هوش مصنوعی در اکتشافات فضایی
هوش مصنوعی در حوزه اکتشافات فضایی هم به میزان زیادی در حال پیشرفت است. ماموریتهای فضایی و اکتشافات جدید به تجزیه و تحلیل حجم عظیمی از دادهها نیاز دارند. هوش مصنوعی و یادگیری ماشین موثرترین روشها برای مدیریت و پردازش حجمهای بزرگ دادهها به حساب میآیند. در ادامه به این سوال پاسخ داده شده است که در منابع انسانی کاربرد هوش مصنوعی چیست ؟

کاربرد هوش مصنوعی در مدیریت منابع انسانی
هوش مصنوعی و یادگیری ماشینتحولاتی عظیم را در نحوه مدیریت منابع انسانی و جذب نیرو در بسیاری از شرکتها به وجود آورده و این مسئلهای است که باید بسیار مورد توجه قرار بگیرد. به دو دلیل انتظار میرود منابع انسانی اولین بخشی از سازمانها باشد که از کاربرد هوش مصنوعی بهرهمند میشود. اولین دلیلش این است که منابع انسانی ثروتی از دادههای با کیفیت بالا را در اختیار دارد. دوم اینکه منابع انسانی یکی از معدود بخشهایی از هر سازمان به حساب میآید که هم وجودش الزامی است و هم تحت فشار زمانی بالایی قرار دارد.
کاربرد هوش مصنوعی در بازاریابی
به نظر میرسد بازاریابان و فروشندگان در سراسر دنیا در حال روی آوردن به هوش مصنوعی به عنوان دست راست خود هستند. در سالهای اخیر، SMEها (شرکتهای کوچک و متوسط) شروع به استفاده از هوش مصنوعی و کاربردهای یادگیری ماشین در قیفهای فروش خود کردهاند. اکنون بازاریابان میتوانند با کمک تحولهای پدید آمده در کلان دادهها و راهکارهای تجزیه و تحلیل پیشرفته دادهها بیش از پیش درک واضحتری را از مخاطب هدف بدست آورند. بازاریابی مبتنی بر هوش مصنوعی خط مقدم پیشرفت در این حوزه به حساب میآید.
کاربرد هوش مصنوعی در تجارت الکترونیک
تمایلات شخصی، الگوهای خرج کردن پول و مدلهای مورد علاقه مشتریان هیچ یک در زمان خرید آنلاین مد نظر قرار داده نمیشوند. فناوریهای پیشرفتهای مثل هوش مصنوعی و یادگیری ماشین توسط سازمانهای کلیدی تجارت الکترونیک مورد استفاده قرار میگیرند. در هر وب سایت تجارت الکترونیک میتوان از هوش مصنوعی برای ارائه اقلامی استفاده کرد که به طور خاص برای یک مشتری مشخص مناسب هستند. همچنین افراد میتوانند از گفتگو یا تصویر بهگونهای برای ارتباط با هوش مصنوعی استفاده گنند که گویی در حال ارتباط با یک انسان واقعی هستند.
کسب و کارها میتوانند از یادگیری ماشین در حوزههای مختلف تجارت الکترونیک از جمله پیشبینی تقاضا، نتایج پیشنهاد خرید محصول، توصیههایی در مورد محصولات و قیمتها، محل قرار دادن خردهفروشیها، تایید هویت، ترجمه و بسیاری از موارد دیگر کمک بگیرند. در آخر به این سوال پاسخ داده شده که در تجارت الکترونیک کاربرد هوش مصنوعی چیست ؟
کاربرد هوش مصنوعی در مسیریابی و سفر
کسب و کارها در زمینه سفر و گردشگری هم از هوش مصنوعی برای کنترل تعداد زیادی از مشاغل مدیریتی و پشتیبانی مشتریان استفاده میکنند. حتی وقتی اپلیکیشنهایی مثل نقشه گوگل ترافیک و ساخت و سازها را برای محاسبه کوتاهترین مسیرها برای رسیدن به موقعیت مکانی مورد نظر دخالت میدهند، در پشت صحنه از هوش مصنوعی استفاده میشود. اکنون در انتهای مقاله هوش مصنوعی چیست به جمعبندی پرداخته شده است.
جمعبندی
در این مقاله از مجله فرادرس ابتدا به این سوال پاسخ داده شد که هوش مصنوعی چیست و پس از آن هم تقریباً تمام مباحث داغ پیرامون آن هوش مصنوعی شرح داده شدند. امید است این مقاله مفید واقع شده باشد.
گپ جیپیتی یک سرویس هوش مصنوعی فارسی است که سرویسی مشابه چت جی پی تی را در اختیار کاربران فارسی زبان قرار میدهد. شما در گپ جیپیتی به مدلهایی مانند GPT-4o ،ChatGPT ،Midjourney ،Gemini ،Claude 3.5 و DALLE-3 دسترسی خواهید داشت.
- دسترسی رایگان به مدل پیشرفته GPT-4o تا ۵ پیام در روز
- دسترسی به مدل پیشرفته Claude 3.5 Sonnet و GPT-4o
- ایجاد عکس با DALLE-3 و Midjourney
- امکان آپلود و گفتوگو با فایلهای متنی مانند pdf و تصاویر
- امکان گفت و گوی صوتی با مدل GPT-4o









خیلی جامع و مفید بود . ممنون
خداوند شمارا ازجمیع بلیات محفوظ ومصون نگهدارد .دستتون بالاتر ازطلا باشد……ممنون
مرسی مهندس. دیدگاه کاملا کامل و جامعی رو نسبت به دنیای هوش مصنوعی انتشار کرده بودین.
خدا قوت.
درود و هزاران درود،مدت کمی است با سایت شما اشنا شده ام،،میخواهم بگویم،،،این سایت فوق العاده است،و شما خدمت بسیار بزرگی به دوستداران یاد گیری نموده اید.افرین و صد افرین،دیگر واژه ای نمی یابم که سپاس گویم.با ارزوی موفقیت و خدمت به مردم ایران زمین.شادزی
با سلام خدمت شما؛
از همراهی و توجه شما به مجله فرادرس سپاسگزاریم.
با سلام واحترام بسیار جالب ومفید وعمومی قابل استفاده برای همه رشته های مهندسی بحث شده است. اگرچه نظراتی دارم که دراینده وبتدریج باشما درمیان خواهم گذاشت.با تشکر
عالی بود
عالی دست طلا
واقعا عالی بود دست شما درد نکنه
کامل و خواندنی بود
اطلاعاتی که در مورد هوش مصنوعی گفته شده قابل درک برای همه است که یک قابلیتی است که اگر طرح و نبوغی در هر رشته تحصیلی چه الکترونیک یا زمین شناسی یا پزشکی یا رشته تحصیلی دیگر آموزش می بینند .راهکار ارزشمند است .چون وقتی استعداد و نبوغ آن شخص درحافظ قرار گیرد .آن هوش مصنوعی به انشعاب دیگر فکر او را در هدفی دارد زودتر به هدف میرسد . در زمان کم.ونبوغ علمی او را زیادتر می کند.واگر در محیط بسته مثل خانه باشد .زیاد کار آیی ندارد بهتر است .در طبیعت خدایی هم لذت ببرد .و با روحیه زیاد در آن علم به مقصودش برسد.
بسیار عالی بود ممنون که این مقاله رو نوشتین با سپاس فراوان
مقاله نگو طلا بگو. فوق الاده جامع و مفید بود. سپاس
بسیار اموزنده برامن بود چون اطلاعات اکادمی کم داشتم
با سلام
بهترین زبان برای هوش مصنوعی
میشه بفرمایید
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس، دقت نظر و ارائه بازخورد سپاسگزاریم.
در حقیقت، پایتون از جنبههای مختلف بهترین زبان برنامه نویسی برای هوش مصنوعی به حساب میآید. البته اگر نیاز باشد با زبانی سطح پایینتر (یعنی نزدیکتر به زبان ماشین) برنامه نویسی هوش مصنوعی انجام دهیم یا روالهای نیازمند عملکرد بالا را توسعه دهیم، میتوان از زبان برنامه نویسی C++ استفاده کرد. برای شروع یادگیری برنامه نویسی هوش مصنوعی با پایتون، استفاده از دوره آموزشی زیر پیشنهاد میشود.
همچنین برای شروع یادگیری برنامه نویسی پایتون، بهتر است ابتدا از دوره آموزشی زیر استفاده شود.
برای شما آرزوی سلامتی و موفقیت داریم.
بسیار عالی فقط این قسمت :
“۱۹۹۵: اولین برنامه خودآموزی ساخته شد که بازی کامپیوتری انجام میداد.”
1959 به اشتباه 1995 نوشته شده
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس، دقت نظر و ارائه بازخورد سپاسگزاریم.
این مورد اصلاح شد.
برای شما آرزوی سلامتی و موفقیت داریم.
بسیار عالی .تشکر
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
از اینکه این مطلب مورد توجه شما قرار گرفته است بسیار خرسند و مفتخریم.
برای شما آرزوی سلامتی و موفقیت داریم.
توضیحات تکمیل و دقیق با مفهومی روان برای درک هوش طبیعی ما از هوش مصنوعی
خیلی جامع و کامل
خیلی ممنون
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
از اینکه دیدگاه و نظر خود را با ما به اشتراک میگذارید بسیار خوشنود و مفتخریم.
برای شما آرزوی سلامتی و موفقیت داریم.
عالی بود. مرسی