



تشخیص اشیا در پایتون – راهنمای کاربردی
در چند سال اخیر، فناوریهای مبتنی بر «تشخیص اشیا» (Object Detection) به سرعت در حال یکپارچه شدن با دستگاههای الکترونیکی نظیر تلفنهای همراه، دوربینهای دیجیتال و فرایندهای صنعتی هستند. همچنین، الگوریتمهای تشخیص اشیا به بخش جداناپذیری از فناوریهای پیشرفتهای نظیر «اتومبیلهای خوران» (Self-Driving Automobiles | Autonomous Vehicle)، «احراز هویت بیومتریک» (Biometric Authentication) و سایر موارد تبدیل شدهاند.




فناوریهای مبتنی بر تشخیص اشیا، در حال محکم کردن جای پای خود در دنیای فناوری و «گجتهای» (Gadgets) دیجیتال هستند. اگر شما جزء آن دسته از کاربرانی هستید که برای باز کردن گوشی تلفن همراه خود از دوربین تلفن و امکاناتی نظیر Face Unlock استفاده میکنید، در واقع در حال استفاده از فناوریهای مبتنی بر تشخیص اشیا هستید. در صورتی که کاربران شبکههای اجتماعی برای گرفتن «سلفی» (Selfie) یا تماس تصویری، از «جلوههای» (Effect) خاصی نظیر قرار دادن عینک آفتابی روی صورت استفاده کنند، فناوریهای مبتنی بر تشخیص اشیا را در تعاملات روزمره خود مورد استفاده قرار دادهاند.
فناوریهای پیشرفته دیگری نظیر «واقعیت افزوده» (Augmented Reality) نیز به طور مستقیم از تشخیص اشیا، جهت فراهم آوردن «تجربه همه جانبه» (Immersive Experience) از «واقعیت مجازی» (Virtual Reality)، برای کاربران خود استفاده میکنند. شاید بسیاری از کاربران با این واقعیت آشنا نباشند که ویژگیهای جالبی که توسط فناوری تشخیص اشیا امکانپذیر میشوند، در اصل، توسط دسته خاصی از الگوریتمهای «شبکههای عصبی مصنوعی» (Artificial Neural Networks) امکانپذیر شدهاند که نه تنها قادر به تشخیص چهره در تصویر یا ویدئو هستند، بلکه این توانایی را دارند که اجزای مختلف چهره و جایگاه هر کدام از آنها در چهره را نیز تشخیص دهند.
به عبارت دیگر، فناوری تشخیص اشیا، به سیستم اجازه میدهد تا، به معنای واقعی کلمه، ورودیها را حس کند؛ یعنی، با استفاده از تشخیص اشیا، سیستم به معنای واقعی قادر به دیدن کاربران، درک فرم ظاهری چهره آنها و از همه مهمتر تشخیص اجزای چهره آنها است.
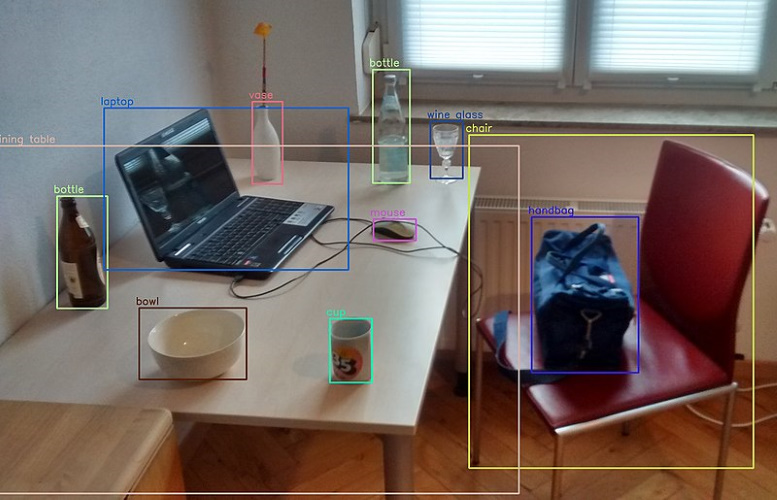
در این مطلب، ابتدا با مفاهیمی نظیر «تشخیص اشیا» (Object Detection) و «بینایی کامپیوتر» (Computer Vision) آشنا خواهید شد. سپس، مراحل لازم برای پیادهسازی یک سیستم تشخیص اشیا ارائه خواهد شد. برای پیادهسازی سیستم تشخیص اشیا در «زبان برنامهنویسی پایتون» (Python Programming Language)، از چالش Google AI Open Image که به میزبانی Kaggle برگزار میشود استفاده شده است. هدف این چالش، توسعه یک سیستم تشخیص اشیا است که بتواند اشیاء مختلف را در تصاویر مختلف و بعضا پیچیده تشخیص دهد.
تشخیص اشیا
اگر قرار باشد یک تعریف مشخصی از فناوری تشخیص اشیا ارائه شود، این دسته از فناوریها را میتوان در قالب فناوریها و سیستمهای کامپیوتری تعریف کرد که مجموعهای از وظایف مرتبط با حوزههای بینایی کامپیوتر (پردازش کامپیوتری تصاویر و ویدئو و درک محتوای آنها) و «پردازش تصویر» (Image Processing) را «خودکارسازی» (Automate) میکنند. به این دسته از فناوریها که کامپیوترها را قادر به «دیدن» میسازند، «بینایی کامپیوتر» (Computer Vision) گفته میشود. به عبارت دیگر، تشخیص اشیا زیر مجموعه فناوریها و سیستمهای کامپیوتری هستند که در حوزه بینایی کامپیوتر و پردازش تصویر فعالیت دارند.
در روشهای تشخیص اشیا، هدف تشخیص نمونهها یا اشیاء مرتبط با یک کلاس خاص (به عنوان نمونه، انسان، ساختمان، اتومبیلها و سایر موارد) در تصاویر و ویدئوهای دیجیتالی است. تشخیص اشیا حوزه تحقیقاتی بسیار بزرگی است و تحقیقات بسیار زیادی در این زمینه انجام شده است؛ دامنههایی نظیر «تشخیص چهره» (Face Detection) و «تشخیص عابر پیاده» (Pedestrian Detection) از جمله دامنههای تحقیقاتی پرطرفدار در حوزه تشخیص اشیا محسوب میشوند. سیستمهای تشخیص اشیا کاربردهای فراوانی در حوزههای مختلف بینایی کامپیوتر نظیر «بازیابی تصویر» (Image Retrieval) و «نظارت ویدئویی» (Video Surveillance) دارند.

مفاهیم مهم در سیستمهای تشخیص اشیا
در سیستمهای تشخیص اشیا، هدف «دستهبندی» (Classify) اشیاء موجود در تصویر، در مجموعهای از «کلاسهای» (Classes) از پیش تعیین شده است. هر کدام از کلاسهای تعریف شده، مجموعهای از «ویژگیهای» (Features) مختص به خود دارند که به سیستم در دستهبندی اشیاء متعلق به این کلاسها کمک میکنند. به عنوان، شکل هندسی دایرهها گرد است. بنابراین، هنگامی که سیستم به دنبال تشخیص دایره در ویدئو است، اشیائی که در فاصله خاصی از یک نقطه (مثلا مرکز) قرار دارند، جستجو میشوند. به طور مشابه، زمانی که سیستم به دنبال تشخیص مربع در تصویر است، اشیائی را جستجو میکند که در گوشهها عمود هستند و اندازه اضلاع آنها با یکدیگر برابر هستند.
روش مشابهی برای شناسایی چهره در کاربردهای مختلف بینایی کامپیوتر مورد استفاده قرار میگیرد؛ در شناسایی چهره، نقاط یا ویژگیهای کلیدی سطح بالا در تصویر نظیر چشم، گوش، بینی و لبها شناسایی میشوند. این دسته از ویژگیها، Landmark یا ویژگیهای شاخص نام دارند. در شناسایی چهره، برای تشخیص اشیا (نظیر چشم) در تصویر، ویژگیهای دیگری نظیر رنگ پوست و فاصله میان چشمها نیز شناسایی و استخراج میشوند.
روشهای مهم تشخیص اشیا در تصاویر و ویدئوهای دیجیتال
مهمترین روشهای تشخیص اشیا، معمولا از رویکردهای مبتنی بر «یادگیری ماشین» (Machine Learning) و یا مدلهای مبتنی بر «یادگیری عمیق» (Deep Learning) استفاده میکنند.

در رویکردهای مبتنی بر یادگیری ماشین، بسیار حیاتی است که ابتدا ویژگیهای مرتبط با اشیاء موجود در تصویر، با استفاده از روشهای خاصی نظیر روشهای زیر استخراج شوند:
- چارچوب تشخیص اشیا Viola–Jones مبتنی بر ویژگیهای Haar
- روشهای تبدیل ویژگی مستقل از ابعاد (Scale-Invariant Feature Transform | SIFT)
- ویژگیهای هیستوگرام گرادیانهای جهتدار (Histogram of Oriented Gradients | HOG)
سپس در مرحله بعد، از یکی روشهای شناخته شده یادگیری ماشین، نظیر «ماشین بردار پشتیبان» (Support Vector Machine)، استفاده میشود تا اشیاء در کلاسهای از پیش تعیین شده دستهبندی شوند. در سمت مقابل، مدلهای یادگیری عمیق امکان «تشخیص اشیا نقطه به نقطه» (ٍEnd-to-End Object Detection) را برای محققان یادگیری ماشین فراهم میکنند. چنین روشهایی از این جهت حائز اهمیت هستند که قابلیت تشخیص اشیا، بدون تعریف صریح ویژگیهای مرتبط با هر کدام از کلاسهای تعریف شده از اشیاء، برای سیستم پدید میآید. این دسته از مدلهای تشخیص اشیا، معمولا مبتنی بر «شبکههای عصبی پیچشی» (Convolutional Neural Network) هستند. مهمترین سیستمهای تشخیص اشیا مبتنی بر یادگیری عمیق عبارتند از:
- روشهای Region Proposals (که نواحی دربرگیرنده اشیاء در تصویر را شناسی میکنند) نظیر R-CNN ،Fast R-CNN و Faster R-CNN.
- روش Single Shot MultiBox Detector یا SSD.
- روشهای شناخته شده You Only Look Once یا YOLO.

بینایی کامپیوتر
بینایی کامپیوتر، یک حوزه «بین رشتهای» (Interdisciplinary) در علوم کامپیوتر و «هوش مصنوعی» (Artificial Intelligence) محسوب میشود. این حوزه با چگونگی ایجاد درک سطح بالا از تصاویر و ویدئوهای دیجیتال، توسط سیستمهای کامپیوتری سر و کار دارد. از دیدگاه مهندسی، هدف نهایی سیستمهای بینایی کامپیوتر، «خودکارسازی» (Automation) وظایف قابل انجام توسط سیستم بینایی انسان است.
به عنوان یکی از شاخههای علمی حوزه علوم کامپیوتر و هوش مصنوعی، وظیفه سیستمهای بینایی کامپیوتر استخراج، تحلیل و درک خودکار اطلاعات مفید از یک تصویر ایستا یا دنبالهای از تصاویر است. حوزه بینایی کامپیوتر با توسعه پایههای نظری و الگوریتم-محور لازم، جهت دستیابی به «درک بصری خودکار» (Automatic Visual Understanding) از تصاویر و ویدئوهای دیجیتال سر و کار دارد.
به عبارت دیگر، از دیدگاه علمی، بینایی کامپیوتر با نظریهها، الگوریتمها و رویکردهای قابل استفاده در سیستمهای هوش مصنوعی جهت استخراج، تحلیل و درک تصاویر دیجیتالی سر و کار دارد. تصاویر دیجیتالی میتوانند فرمهای مختلفی به خود بگیرند؛ دنبالههای ویدئویی، چشمانداز از دید دوربینهای مختلف یا دادههای «چندبُعدی» (Multi-Dimensional) به دست آمده از اسکنرهای پزشکی. با این حال از دیدگاه فناوری، هدف بینایی کامپیوتر به کارگیری نظریهها، الگوریتمهای و مدلهای مطرح شده در حوزه بینایی کامپیوتر (و به طور گستردهتر، حوزه هوش مصنوعی) جهت ساختن سیستمهای بینایی کامپیوتر است.

وظایف سیستمهای بینایی کامپیوتر
از جمله مهمترین وظایف قابل تعریف در سیستمهای بینایی کامپیوتر، میتوان به توسعه روشهایی برای «اکتساب» (Acquire)، «پردازش» (Process)، «تحلیل» (Analyze) و «درک» (Understand) تصاویر دیجیتالی اشاره کرد. همچنین، استخراج دادههای با ابعاد بالا از جهان واقعی جهت تولید اطلاعات عددی یا «نمادین» (Symbolic)، به عنوان نمونه در قالب تصمیم قابل اتخاذ توسط سیستم، از جمله دیگر وظایف قابل تعریف در سیتمهای بینایی کامپیوتر محسوب میشوند.

منظور از درک در سیستمهای بینایی کامپیوتر، تبدیل تصاویر بصری (تصاویر یا ویدئوهای دیجیتالی اکتساب شده) به توصیفاتی از جهان واقعی است که در نهایت، از طریق تعامل با دیگر فرایندها، منجر به اتخاذ تصمیمات مناسب توسط سیستم میشوند.
دامنههای کاربردی سیستمهای بینایی کامپیوتر
از جمله مهمترین دامنههای کاربردی سیستمهای بینایی کامپیوتر، میتوان به موارد زیر اشاره کرد:

- سیستمهای «بازسازی صحنه» (Scene Reconstruction)
- سیستمهای «دستهبندی تصاویر» (Image Classification)
- سیستمهای «تشخیص رویداد» (Event Detection)
- سیستمهای «ردیابی ویدئویی» (Video Tracking)
- سیستمهای «تخمین حالت سهبُعدی» (3D Pose Estimation)
- سیستمهای «تخمین حرکت» (Motion Estimation)
- سیستمهای «ترمیم تصاویر دیجیتالی»
- سیستمهای «بازشناسی و تشخیص اشیا» (Object Detection and Recognition)
- سیستمهای «نظارت بصری» (Visual Surveillance)
- سیستمهای «ناوبری» (Navigation) در اتومبیلهای خودران یا «روباتهای متحرک» (Mobile Robot)
- سیستمهای «شاخصگذاری تصاویر و ویدئوهای دیجیتالی» (Digital Image and Video Indexing)
در سالهای اخیر، به دلیل جهش بیسابقه در قدرت محاسباتی سیستمهای کامپیوتری (به ویژه سیستمهای محاسبات مبتنی بر «واحدهای پردازش گرافیکی» (Graphical Processing Units | GPUs)) و امکانپذیر کردن توسعه مدلهای یادگیری عمیق جهت پیادهسازی سیستمهای بینایی کامپیوتر، استفاده از مدلهای بینایی کامپیوتر به امری معمولی تبدیل شده است. بسیاری از شرکتهای معروف حوزه فناوری نظیر آمازون، گوگل، تسلا، فیسبوک و مایکروسافت، سرمایهگذاریهای هنگفتی در این فناوری و کاربردهای آن انجام دادهاند.
در این مطلب، روی دو وظیفه (دامنه کاربردی) عمده در سیستمهای بینایی کامپیوتر تمرکز خواهد شد؛ دستهبندی تصاویر و تشخیص اشیا در تصاویر.
سیستمهای دستهبندی تصاویر روی دستهبندی (گروهبندی) تصاویر در طبقهها یا کلاسهای از پیش تعیین شده تمرکز دارند. برای پیادهسازی چنین سیستمهایی، ابتدا باید تصاویری که در کلاسهای مورد نظر دستهبندی میشوند، در اختیار سیستم قرار داده شود. سپس، سیستم با استفاده از این تصاویر «آموزش» (Train) داده میشود. مدل آموزش داده شده قادر خواهد بود تا با تحلیل «ویژگیهای» (Features) تصویر، کلاس یا طبقه تصاویر را مشخص کند. به عنوان نمونه، در صورتی که تصویر حاوی گربه وارد سیستم شود، آن را در کلاس گربه دستهبندی میکند.

سیستمهای تشخیص اشیا از مدلهای دستهبندی تصاویر استفاده میکنند تا مشخص کنند چه چیزهایی در یک تصویر و در کجای آن قرار دارند. چنین کاربردهایی از سیستمهای بینایی کامپیوتر، از طریق استفاده مدلهای یادگیری عمیق (شبکه عصبی) نظیر شبکههای عصبی پیچشی امکانپذیر شدهاند. استفاده از چنین مدلهایی برای تشخیص اشیا به سیستمهای بینایی کامپیوتر اجازه میدهند تا یک تصویر را در چندین کلاس دستهبندی کنند؛ وجود چندین شیء را در تصویر تشخیص دهند.

در این مطلب و برای پیادهسازی سیستم تشخیص اشیا، از چالش Google AI Open Image که به میزبانی Kaggle برگزار میشود استفاده شده است. هدف این چالش، تشخیص اشیا گوناگون، در تصاویر مختلف و بعضا پیچیده است. در این چالش، از یک مجموعه داده متشکل از 1٫۷ میلیون تصویر استفاده شده است. اشیاء موجود در تصاویر این مجموعه داده، به وسیله 12 میلیون «کادر محصور کننده» (Bounding Box) در 500 کلاس مختلف دستهبندی شدهاند ( به هر کدام از تصاویر موجود در مجموعه داده، چندین کادر محصور کننده برای تشخیص اشیا مشخص شده است).
از جمله مهمترین ویژگیهای این مجموعه داده، میتوان به موارد زیر اشاره کرد:
- 12 میلیون «کادر محصور کننده» (Bounding Box) برای دستهبندی 1٫۷ میلیون تصویر در 500 کلاس مختلف.
- تصاویر با صحنههای پیچیده که در برگیرنده چندین شیء مختلف هستند؛ به طور متوسط 7 کادر محصور کننده به ازاء هر تصویر.
- تصاویر بسیار متنوع که حاوی اشیاء مختلف و متمایز هستند.
- سلسله مراتبی مناسب برای کلاسها، که منعکس کننده روابط میان کلاسهای این مجموعه داده است.


این مجموعه داده، از طریق لینک [+] قابل دانلود است.
تحلیل اکتشافی دادهها
پیش از پیادهسازی سیستم تشخیص اشیا در تصویر، دادههای تصویری لازم برای آموزش مدل مورد بررسی قرار میگیرند تا کلاسهای قابل تشخیص در تصاویر مشخص شوند.

با بررسی اجمالی تصاویر آموزشی مشخص میشود که تناوب برخی از کلاسهای موجود در مجموعه داده، به مراتب بالاتر از سایر کلاسها است. نمودار بالا، توزیع 43 کلاس متناوب در مجموعه داده Open Image را نشان میدهد. همانطور که مشاهده میشود، توزیع نمونههای موجود در کلاسهای مختلف نابرابر است؛ مشکلی که برای آموزش بهینه سیستم تشخیص اشیا، به نحوی باید برطرف شود. برای متعادل کردن تناوب دادههای آموزشی هر کلاس، رویه زیر اتخاذ شده است:
- برای آموزش سیستم تشخیص اشیا، تنها از دادههای موجود در 43 کلاس متناوب در مجموعه داده Open Image استفاده میشود (در مجموع، 300 هزار تصویر در این 43 کلاس وجود دارند).
- برای متعادل کردن تناوب دادههای آموزشی هر کلاس، از هر کلاس تنها 400 تصویر به طور تصادفی انتخاب و در مجموعه آموزشی قرار داده میشود (در مجموع، 17200 تصویر برای پیادهسازی سیستم تشخیص اشیا استفاده شده است).
انتخاب الگوریتم تشخیص اشیا
الگوریتمهای مختلفی برای پیادهسازی سیستم تشخیص اشیا در نظر گرفته شدند، اما در نهایت، الگوریتم YOLO به عنوان الگوریتم اصلی بر پیادهسازی این سیستم در نظر گرفته شد. دلیل انتخاب الگوریتم YOLO، سرعت بالا و قدرت محاسباتی آن و همچنین، وجود منابع آموزشی زیاد برای راهنمایی کاربران هنگام پیادهسازی این الگوریتم است.
به دلیل محدودیتهای محاسباتی و زمانی، تصمیمات زیر جهت طراحی و پیاده شبکه عصبی (برای کاربرد تشخیص اشیا) اتخاذ شد:
- از یک مدل YOLO V2 که پیش از این برای شناسایی اشیاء خاصی آموزش دیده شده است، استفاده میشود (یک مدل یادگیری عمیق از پیش آموزش داده شده).
- از قدرت مفهوم «یادگیری انتقال» (Transfer Learning) استفاده میشود و لایه کانولوشن (پیچشی) آخر مدل YOLO دوباره آموزش داده میشود تا سیستم تشخیص اشیا بتواند اشیائی را که پیش از با آنها برخورد نداشته است (Unseen Objects)، نظیر گیتار، خانه، مرد، زن، پرنده و سایر موارد، تشخیص دهد.
مشخصات ورودیهای مدل YOLO برای تشخیص اشیا
الگوریتم YOLO برای اینکه بتواند اشیاء موجود در تصویر را تشخیص دهد، ورودیهای خاصی را میپذیرد:
- ابعاد تصاویر ورودی: شبکه YOLO به گونهای طراحی شده است تا با تصاویری که ابعاد مشخصی دارند آموزش ببیند. ابعاد تصویر استفاده شده برای آموزش شبکه YOLO، برابر با 608x608 است.
- تعداد کلاسها: برابر 43 کلاس است. تعداد کلاسها، پارامتری است که برای تعریف ابعاد خروجیهای شبکه YOLO مورد نیاز است.
- پارامترهای Anchor Box: تعداد کادرهای محصور کننده یا Bounding Box و همچنین ابعاد بیشینه و کمینه آنها؛ به مجموعه این اطلاعات، پارامترهای Anchor Box گفته میشود.
- حد آستانه برای معیارهای IoU (معیار Intersection over Union) و ضریب اطمینان (Confidence): این حد آستانه به این دلیل تعریف شده است تا مشخص شود کدام یک از کادرهای محصور کننده، باید به عنوان کادرهای در بر گیرنده اشیاء موجود در تصویر انتخاب شوند (انتخاب میان کادرهای محصور کننده).
- اسامی تصاویر به همراه اطلاعات پارامترهای Anchor Box: به ازاء هر تصویر، نیاز است تا اطلاعاتی همانند اطلاعات تعبیه شده در شکل زیر در اختیار شبکه YOLO قرار گرفته شود.

قطعه کد لازم برای تولید ورودیهای شبکه YOLO در ادامه نمایش داده شده است:
معماری شبکه YOLO V2
معماری شبکه YOLO V2 در شکل زیر نمایش داده شده است. این شبکه، از 23 لایه کانولوشن (پیچشی) تشکیل شده است؛ هر کدام از این لایهها، واحد «نرمالسازی دستهای» (Batch Normalization)، تابع فعالسازی Leaky RELU و واحد Max Pooling مختص به خود را دارد.

هدف لایههای تعریف شده، استخراج چندین ویژگی مهم از تصاویر دیجیتالی است تا از این طریق، سیستم تشخیص اشیا قادر باشد اشیاء مختلف موجود در تصویر را تشخیص دهد و آنها در کلاسهای متناظر دستهبندی کند. با هدف تشخیص اشیا موجود در تصویر، الگوریتم YOLO تصویر را به یک گرید (Grid) متشکل از سلولهای 19x19 تقسیمبندی میکند؛ به ازاء هر سلول تشکیل شده در گرید، پنج کادر محصور کننده با ابعاد متفاوت تعریف میشود. سپس شبکه YOLO تلاش میکند تا کلاس اشیاء موجود در سلولهای گریدی را تشخیص دهد؛ به عبارت دیگر، احتمال تعلق هر کدام از اشیاء شناسایی شده (درون کادرهای محصور کننده هر سلول) به کلاسهای موجود در مجموعه داده محاسبه میشود.
هر کدام از کادرهای محصور کننده، ابعاد و اشکال متفاوتی نسبت به یکدیگر دارند و در اصل ، برای تشخیص دادن اشیاء گوناگون (با شکلها و ابعاد مختلف) در هر یک از سلولهای گریدی طراحی شدهاند. خروجی الگوریتم YOLO ماتریسی به شکل زیر است؛ به ازاء هر کدام از کادرهای محصور کننده تعریف شده (در هر کدام از سلولهای گریدی)، ماتریسی مشابه شکل زیر تولید خواهد شد.

از آنجایی که شبکه YOLO با استفاده ار تصاویر 43 کلاس آموزش داده میشود، ابعاد ماتریس خروجی به شکل زیر محاسبه میشود.

این ماتریس اطلاعات بسیار مهمی نظیر «احتمال مشاهده شدن یک شیء در هر یک از کادرهای محصور کننده» (Probabilities of Observing an Object for Each Anchor Box) و احتمال تعلق شیء شناسایی شده در کارد محصور کننده، به هر کدام از کلاسهای از پیش تعریف شده را، در اختیار قرار میدهد. برای اینکه کادرهای بدون شیء (کادرهایی که هیچ شیء خاصی در آنها وجود ندارد)، کادرهایی که شیء شناسایی شده در آنها در هیچ کلاسی دستهبندی نمیشود یا کادرهایی که شیء شناسایی شده در آنها با کادرهای دیگر همپوشانی دارند، فیلتر شوند ار دو حد آستانه زیر استفاده میشود:
- حد آستانه IoU: برای فیلتر کردن کادرهایی به کار میرود که یک شیء واحد و یکسان در آنها شناسایی شده است.
- حد آستانه ضریب اطمینان (Confidence): برای فیلتر کردن کادرهایی به کار میروند، احتمال تعلق آنها به کلاسهای مختلف بسیار پایین است.
قطعه کد زیر، نحوه تعریف لایههای مختلف شبکه YOLO جهت تشخیص اشیا را نشان میدهد:
یادگیری انتقال
یادگیری انتقال، مفهومی است که در آن از یک شبکه عصبی از پیش آموزش داده شده (جهت دستهبندی تصاویر)، برای مقاصد دیگر (نظیر دستهبندی و تشخیص اشیا که در این مطلب آموزش داده میشود) استفاده میشود. روش کار بدین صورت است که جهت یادگیری انتقال، مدل از پیش آموزش داده شده توسط دادههای جدید و به وسیله پارامترهای متناسب با این دادهها، «آموزش دوباره» (Re-Train) داده میشود (تعدادی از پارامترهای وزن شبکه عصبی در نتیجه چنین فرایندی، از دوباره تنظیم میشوند). از آنجایی که در انتقال یادگیری نیاز به یادگیری و تنظیم تعداد زیادی پارامتر وزن وجود ندارد، چنین کاری باعث صرفهجویی بسیار زیاد در زمان و قدرت محاسباتی لازم برای آموزش شبکه عصبی میشود.

به عنوان نمونه، شبکه عصبی از پیش آموزش داده شده که در این مطلب استفاده شده است، چیزی حدود 50 میلیون پارامتر وزن دارد. یادگیری چنین مدلی در پلتفرمهای قدرتمند محاسبات ابری نظیر Google Cloud، حداقل به 4 الی 5 روز زمان نیاز دارد. برای اینکه از مفهوم یادگیری انتقال، با موفقیت، برای آموزش دوباره شبکه عصبی (روی دادههای جدید) استفاده شود، لازم است که برخی از پارامترها و تنظیمات مدل بهروز رسانی شوند تا مدل آموزش از پیش داده شده بتواند خود را با دادههای جدید وفق دهد:
- ابعاد تصاویر ورودی: ابعاد تصاویر ورودی در مدل YOLO از پیش آموزش داده شده، برابر با 416x416 است. از آن جایی که تصاویر استفاده شده در این مطلب، ابعاد بزرگتری نسبت به تصاویر استفاده شده در مدل YOLO از پیش آموزش داده شده دارند و همچنین، ابعاد برخی از اشیائی که قرار است شناسایی شوند بسیار کوچک است (نظیر کفش، پرنده و سایر موارد)، منطقی نیست که ابعاد تصاویر جدید تا ابعاد 416x416 کاهش پیدا کنند. به همین خاطر، ابعاد تصاویر جدید برای آموزش دوباره مدل YOLO، برابر با 608x608 در نظر گرفته شده است.
- اندازه گرید (Grid): در مدل YOLO از پیش آموزش داده شده، ابعاد سلولهای گرید برابر با 13x13 است. در این مطلب، ابعاد سلولهای گرید، جهت آموزش دوباره مدل YOYO، به 19x19 تغییر پیدا کرده است.
- لایه خروجی: تعدادکلاسها در مدل YOLO از پیش آموزش داده شده، برابر با 80 است. در حالی که برای آموزش دوباره مدل، از دادههای 43 کلاس استفاده شده است. بنابراین، لازم است تغییراتی در ابعاد لایه خروجی ایجاد شود تا سیستم بتواند خود را با کلاسهای جدید، دادههای آنها و الگوهای موجود در آنها وفق دهد.
برای اینکه بتوان مدل YOYO را روی دادههای تصویری جدید آموزش داد، نیاز است تا پارامترهای وزن لایه کانولوشن (پیچشی) آخر از دوباره مقدار دهی اولیه شوند؛ چنین کاری به سیستم اجازه میدهد تا تصاویر متعلق به کلاسهای خاص (و جدید) را به درستی دستهبندی کند. قطعه کد زیر، برای آموزش دوباره شبکه عصبی YOLO مورد استفاده قرار میگیرد.
تابع «هزینه» (Cost) یا «زیان» (Loss)
در مسائل مرتبط با تشخیص اشیا در تصویر، هدف شناسایی درست کلاس اشیاء، با بیشترین احتمال یا ضریب اطمینان (Confidence) ممکن است.
تابع هزینه برای یک سیستم تشخیص اشیا از سه مؤلفه تشکیل شده است:
- زیان دستهبندی (Classification Loss): در صورتی که یک شیء در تصویر تشخیص داده شده باشد، این مؤلفه، «مربع خطای» (Squared Error) احتمال شرطی کلاس را محاسبه میکند. بنابراین، تابع زیان تنها در صورتی که یک شیء در یک سلول گریدی وجود داشته باشد، برای خطای انجام شده در دستهبندی، جریمه در نظر میگیرد.
- زیان محلیسازی (Localization Loss): این مؤلفه، در صورتی که کاردهای محصور کننده مسئول تشخیص شیء در تصویر باشند، مربع خطای مرتبط با «اندازه و مکان کادر محصورسازی مسئول تشخیص شیء» را نسبت به «اندازه و مکان کادر محصور کننده در «پاسخهای صحیح مبنا» (Ground Truth)» محاسبه میکند. جهت مشخص کردن جریمه خطاهای حاصل از مختصات مکانی کاردهای محصور کننده، از یک پارامتر regularization استفاده میشود.
- زیان ضریب اطمینان (Confidence Loss): این مؤلفه، مربع خطای ضریب اطمینان کادر محصور کننده را محاسبه میکند. از آنجایی که تمامی کادرهای محصور کننده تعریف شده، در تشخیص یک شیء در تصویر دخالت ندارند، معادله محاسبه زیان در این مؤلفه به دو بخش تقسیم میشود؛ بخش اول، برای کادرهای محصور کنندهای که مسئول تشخیص اشیا موجود در تصویر هستند و بخش دوم، برای بقیه کادرهای محصور کننده.
مزیت عمده مدل YOLO نسبت به مدلهای مشابه تشخیص اشیا این است که خطاهایی توسط این مدل محاسبه میشوند که به راحتی توسط «توابع بهینهسازی» (Optimization Functions) معروف نظیر «گرادیان کاهشی تصادفی» (Stochastic Gradient Descent | SGD)، گرادیان کاهشی تصادفی با پارامتر Momentum و بهینهساز Adam قابل بهینهسازی هستند.
قطعه کد زیر برای محاسبه تابع هزینه یا زیان استفاده میشود:
قطعه کد زیر نیز، پارامترهای استفاده شده برای بهینهسازی تابع هدف را نشان میدهد.
دقت خروجی: mean Average Precision (امتیاز mAP)
معیارهای زیادی برای ارزیابی مدلهای تشخیص اشیا ارائه شده است. در این مطلب، جهت ارزیابی سیستم تشخیص اشیا پیادهسازی شده از معیار «میانگین دقت متوسط» (mean Average Precision | mAP) استفاده شده است؛ این معیار، متوسط بیشینه مقادیر صحت (Precision) به ازاء مقادیر حساسیت (Recall) متفاوت را اندازهگیری میکند (برای تمامی مقادیر حد آستانه IoU). برای درک بهتر معیار mAP، ابتدا معیارهای صحت (Precision)، حساسیت (Recall) و IoU (معیار Intersection over Union) مورد بررسی قرار گرفته میشود.
معیارهای صحت (Precision) و حساسیت (Recall)
معیار صحت، درصد پیشبینیهای مثبتی که به درستی به عنوان مثبت پیشبینی شدهاند را محاسبه میکند. معیار حساسیت نیز نسبت «مثبتهای صحیح» (True Positives) به تمامی خروجیهای ممکن را محاسبه میکند. این دو معیار، ارتباط معکوسی با یکدیگر دارند.

معیار Intersection over Union یا IOU
این معیار، میزان همپوشانی میان دو «ناحیه» (Region) را اندازهگیری میکند؛ این مقدار برابر با، ناحیه حاصل از همپوشانی این دو ناحیه، تقسیم بر، ناحیه حاصل از اجتماع این دو ناحیه است. این معیار در اصل، کیفیت پیشبینیهای تولید شده توسط سیستم تشخیص اشیا را نسبت به پاسخهای صحیح مبنا (Ground Truth) نشان میدهد و آنها را با یکدیگر مقایسه میکند.
نتایج حاصل از تست سیستم تشخیص اشیا
در ادامه، نتایج حاصل از تست سیستم تشخیص اشیا روی تصاویر نمونه نمایش داده شده است.




کدهای کامل پیادهسازی روش پیادهسازی سیستم تشخیص اشیا، با استفاده از مجموعه داده Open Images، از طریق لینک [+] قابل دسترسی است.
جمعبندی
تشخیص اشیا متفاوت از دیگر کاربردهای بینایی کامپیوتر است. این امکان برای محققان و علاقهمندان به این حوزه وجود دارد تا یک مدل از پیش آموزش داده شده را مورد استفاده قرار دهند و تغییرات متناسب با کاربرد مد نظرشان روی این مدل اعمال کنند تا برای تشخیص اشیا و دستهبندی آنها استفاده شود. برای آموزش چنین مدلهایی، دادههای آموزشی بسیار زیاد و زمان و قدرت محاسباتی قابل توجهی مورد نیاز است. بنابراین توصیه میشود که از پلتفرمهای محاسبات ابری نظیر Google Cloud Platform برای آموزش مدلهای تشخیص اشیا استفاده شود.

در هنگام پیادهسازی چنین سیستمهایی، ابتدا از تمامی دادههای موجود در 500 کلاس مجموعه داده Open Images استفاده شد. با این حال، پس از پایان مرحله آموزش مدل و در جریان تست مدل تشخیص اشیا مشخص شد که مدل آموزش داده شده قادر به پیشبینی کلاس صحیح بسیاری از تصاویر تست نبود. دلیل این امر این بود که فراوانی نمونههای موجود در کلاسهای مختلف نابرابر بود؛ به عبارت دیگر مجموعه داده استفاده شده «نامتعادل» (Imbalance) بود.
بنابراین، برای اینکه تعادل میان نمونههای مختلف موجود در کلاسها برقرار شود، تصمیم بر این شد تا از دادههای 43 کلاس متناوب در مجموعه داده Open Images، برای آموزش مدل استفاده شود. با اینکه این رویکرد، رویکرد مناسبی برای متعادل کردن دادههای آموزشی نیست، ولی به سیستم اجازه میدهد تا روی مجموعه دادهای آموزش ببیند که در آن، تعداد نمونههای برابری از کلاسهای مختلف حضور دارند.
تشخیص اشیا یکی از موضوعات چالشبرانگیز در حوزه هوش مصنوعی و بینایی کامپیوتر محسوب میشود. با این حال، به دلیل جذابیت بالای این حوزه برای محققین و ملموس و قابل حس بودن نتایج آن (درک خروجی سیستم و نتایج حاصل از آن، حتی برای کاربران عادی، بسیار راحت است)، توجه محققان حوزه بینایی کامپیوتر را به خود معطوف کرده است.
از همه مهمتر، سیستمهای تشخیص اشیا یکی از مؤلفههای اساسی در فناوریهای نوظهور نظیر اتومبیلهای خودران و احراز هویت بیومتریک توسط دوربین به حساب میآید. همچنین، با توجه به اینکه منابع آموزشی بسیار زیادی برای یادگیری و تحقیق در این حوزه در اختیار علاقهمندان قرار گرفته شده است، یادگیری مفاهیم این حوزه و به دست آوردن تخصص در این زمینه، فرصتهای شغلی جذابی را در اختیار علاقهمندان به این حوزه قرار میدهد.
سیستم تشخیص اشیا پیادهسازی شده، در مرحله تست نتایج خوبی از خود نشان میدهد. با این حال، این امکان وجود دارد که ویژگیهای جدیدی به این سیستم اضافه کرد و یا اینکه، ویژگیهای آن را بهبود ببخشید. در ادامه، برخی از ویژگیهایی که میتوان به سیستم اضافه کرد و یا بهبودهایی که میتوان در سیستم ایجاد کرد، ذکر شده است:
- آموزش دادن مدل روی کلاسهای بیشتر جهت تشخیص اشیا بیشتر و متنوعتر در تصویر. برای رسیدن به این هدف نیاز است تا ابتدا مشکل نامتعادل بودن دادههای آموزشی حل شود. یک راه حل محتمل برای رفع چنین نقیصهای، جمعآوری یا تهیه تصاویر بیشتر از کلاسهای نادر است (کلاسهایی که تعداد نمونههای موجود در آنها کم است).
- «افزودن داده» (Data Augmentation): در این روش، تصاویر موجود اندکی تغییر پیدا میکنند تا تصاویر جدیدی شکل بگیرد.
- «نسخهبرداری از تصاویر» (Image duplication): میتوان از یک تصویر، چندین بار برای آموزش یک مدل استفاده کرد. چنین کاری، به سیستم کمک میکند تا بتواند رفتار دادههای یک کلاس خاص را به شکل بهتری مدل کند.
- روشهای ترکیبی (Ensemble): یک روش دیگر این است که یک مدل تشخیص اشیا روی کلاسهای متناوب در مجموعه داده آموزش داده شود و یک مدل دیگر، برای تشخیص اشیا خاص موجود در تصاویر (اشیائی که تشخیص آنها سخت است و یا دادههای کمی برای یادگیری تشخیص آنها وجود دارد) مورد استفاده قرار بگیرد.
- علاوه بر این، این امکان وجود دارد تا مدلهای مختلفی نظیر MobileNet ،VGG و سایر موارد (مدلهای شبکه عصبی پیچشی که برای تشخیص اشیا مورد استفاده قرار میگیرند) را آموزش داد و سپس، آنها را با یکدیگر ترکیب کرد (مدلهای Ensemble).
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای داده کاوی و یادگیری ماشین
- آموزش اصول و روشهای داده کاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- نقشه دانش فناوریهای هوش مصنوعی و دستهبندی آنها — راهنمای جامع
- تفسیر مدلهای یادگیری عمیق در بینایی کامپیوتر — راهنمای جامع
- بینایی کامپیوتر چیست؟ — به زبان ساده
- پیادهسازی سیستم تشخیص و ردیابی خودرو در پایتون — راهنمای جامع
ساناسِت، وبسایتی جامع در زمینه طراحی و توسعه، سرورینگ و همچنین خدمات سوشال است؛ سرورهای مجازی و اختصاصی مخصوص وبینار، بورس و فارکس، رباتها و … از خدمات اصلی ساناست هستند که با پلنهای اقتصادی و پشتیبانی تخصصی ارائه میشوند.
همچنین تمامی خدمات مرتبط با شبکههای اجتماعی و پیامرسانها با امکان تست پیش از خرید و پشتیبانی پس از خرید، قابل سفارش است. شما میتوانید با مراجعه به وبسایت ساناست از طریق این آدرس از مطالب و خدمات ساناست استفاده کنید.
^^









بسیار عالی و مفهومی توضیح داده شد. تیتر مربوط به معیار دقت و صحت را از نظر انگلیسی اشتباه نوشته شده. در واقع recall یعنی نرخ یادگیری و precision هم نرخ صحت است و دقت هم می شود accuracy
با سلام و احترام؛
این مورد اصلاح شد.
از همراهی شما با مجله فرادرس سپاسگزاریم
عالی بود
وزن ها رو برای این کد خاص باید از کجا دانلود کرد و کدوم ورژن???
این دوتا احتمالا کمک کنه:
https://colab.research.google.com/drive/1e4zvS6LyhOAayEDh3bz8MXFTJcVFSvZX?usp=sharing#scrollTo=zog_lDxCd0dg
https://colab.research.google.com/drive/1e4zvS6LyhOAayEDh3bz8MXFTJcVFSvZX?usp=sharing#scrollTo=zog_lDxCd0dg