



مفاهیم کلان داده (Big Data) و انواع تحلیل داده – راهنمای جامع
روزانه حجم عظیمی از دادهها توسط «سیستمهای اطلاعاتی» (information systems) مدرن، فناوریهای دیجیتال مانند «اینترنت اشیا» (Internet of Things)، «رایانش ابری» (cloud computing) و دیگر موارد تولید میشود. تحلیل این دادههای انبوه که به آنها «کلانداده» (Big Data) گفته میشود نیازمند تلاشهای زیاد در سطوح گوناگون، جهت استخراج دانش به منظور کمک به تصمیمسازی بهتر است. بنابراین، «تحلیل کلان داده» (تحلیل مِه داده | Big Data Analytics) یک حوزه علمی و صنعتی روز محسوب میشود که پژوهشهای زیادی پیرامون آن در جریان است و همچنان نیازمند تحقیقات بیشتر نیز هست.




از این رو قصد بر آن است تا در یک مجموعه نوشتار به مفهوم کلانداده، انواع تحلیلها و ارتباط رایانش ابری با کلانداده، چالشها، فناوریهای مرتبط، موضوعات نیازمند پژوهش در این حوزه و ابزارهای گوناگون مرتبط با آن پرداخته شود. در نتیجه، این مجموعه مطلب مبنایی برای بررسی کلانداده در سطوح گوناگون فراهم میکند. علاوه بر این، افقهای جدیدی را پیش روی پژوهشگران قرار میدهد تا به توسعه راهکارهای مبتنی بر چالشها و موضوعات نیازمند پژوهش در این حوزه بپردازند. نکته قابل توجه آن است که کلانداده ترجمه متداول و پرکاربرد عبارت Big Data محسوب میشود، در حالیکه معادل فارسی برگزیده شده توسط فرهنگستان زبان و ادب پارسی «مِهداده» است. در این متن از هر دو معادل استفاده خواهد شد. بخشهای مختلف این مجموعه مطلب به صورت زیر هستند.
- مفاهیم کلان داده (Big Data) و انواع تحلیل داده -- راهنمای جامع
- تحلیل کلان داده (Big Data)، چالش ها و فناوری های مرتبط — راهنما به زبان ساده
- تحلیل های کلان داده (مِه داده) — بخش سوم: ابزارها (به زودی)

مقدمه
در دنیای دیجیتال، دادهها از منابع گوناگونی تولید میشوند و رشد سریع فناوریهای دیجیتال منجر به افزایش نرخ تولید و ایجاد حجم انبوهی از دادهها شده است. وجود این حجم انبوه از دادهها امکان وقوع پیشرفتهای تکاملی را در زمینههای گوناگون علمی و صنعتی فراهم کرده است. به طور کلی، مساله کلانداده به مجموعه دادههای بزرگ و پیچیدهای باز میگردد که پردازش آنها با استفاده از سیستمهای پایگاه داده یا نرمافزارهای پردازش داده سنتی کاری دشوار است.
این دادهها در قالبهای «ساختار یافته» (structured)، «ساختار نیافته» (unstructured) و «نیمه ساختار یافته» (semi-structured) در اندازه پتابایت (PB)، اگزابایت (EB)، زتابایت (ZB) و حتی بیشتر وجود دارند. کلانداده (مِهداده) را به طور رسمی با سه یا چهار کلمه که در انگلیسی با حرف «V» آغاز میشوند تعریف میکنند. سه V به «حجم» (volume)، «سرعت» (velocity) و «تنوع» (variety) اشاره دارد. حجم، در واقع مقدار دادههایی است که هر روز تولید میشوند، در حالیکه سرعت، به نرخ رشد دادهها و سرعتی که برای تحلیل گردهم میآیند اشاره دارد.
تنوع اطلاعاتی را انواع دادههای موجود از جمله دادههای ساختار یافته، ساختار نیافته و نیمه ساختار یافته ایجاد میکنند. در تعریف چهار V، ویژگی چهارم «صحت» (veracity) است که شامل دسترسیپذیری و پاسخگو بودن میشود. آنچه در تعریف کلانداده بیان شد کامل نیست. در در ادامه این مطلب (سرفصل تعریف کلان داده) مفهوم کلانداده بیان شده است. نخستین هدف تحلیلهای کلانداده (تحلیلهای مِهداده) پردازش حجم عظیم، با نرخ رشد بالا، متنوع و همراه با صحت دادهها با بهرهگیری از روشهای هوشمند محاسباتی و سنتی متعدد است. این امر به تصمیمسازی ارتقا یافته، کشف بینش و بهینهسازی در عین نوآوری و مقرون به صرفه بودن کمک میکند.
برخی از روشهای استخراج اطلاعات در مقالهای با عنوان «فراتر از هیجان: مفاهیم، روشها و تحلیلهای کلانداده» (Beyond the hype: Big data concepts, methods, and analytics) که توسط «گندمی» (Gandomi) و «حیدر» (Haider) ارائه شده مورد بررسی قرار گرفتهاند. شکل ۲ مربوط به یکی از تعاریف اولیه کلانداده است. اگرچه، تعریف دقیقی برای کلانداده (مِهداده) ارائه نشده و در میان پژوهشگران باوری مبنی بر این وجود دارد که تعریف این مفهوم کاملا مبتنی بر مساله است.

از چشمانداز فناوری اطلاعات و ارتباطات، کلانداده (مِهداده) انگیزهای قدرتمند برای نسل بعدی صنایع فناوری اطلاعات محسوب میشود که به طور گسترده بر فراز «پلتفرمهای سوم» (Third platforms) که معمولا مربوط به کلانداده، «رایانش ابری» (Cloud Computing)، «اینترنت اشیا» (Internet of Things) و «کسبوکارهای اجتماعی» (Social Business) هستند، ساخته خواهند شد. انبارهای داده معمولا برای مدیریت مجموعه دادههای بزرگ مورد استفاده قرار میگیرند. در این شرایط، استخراج دانش دقیق از دادههای کلان موجود مساله اول است.
اغلب رویکردهای ارائه شده در «دادهکاوی» (Data Mining) قادر به مدیریت موفق مجموعه دادههای بزرگ نیستند. مساله کلیدی در تحلیل کلانداده فقدان هماهنگی بین سیستمهای پایگاه داده و ابزارهای تحلیل مانند دادهکاوی و «تحلیلهای آماری» (statistical analysis) است. این چالشها عموما هنگامی پدید میآیند که قصد کشف دانش و ارائه آن برای کاربردهای عملیاتی وجود داشته باشد. یک مساله اساسی در همین راستا آن است که چگونه میتوان به طور کمی مشخصههای اصلی کلانداده را توصیف کرد.

بنابراین نیاز به یک مفهوم «معرفتشناختی» (epistemological) در توصیف «انقلاب دادهها» (Data Revolution) وجود دارد. به علاوه، مطالعه در نظریه پیچیدگی کلاندادهها به درک مشخصههای اساسی و شکلگیری الگوهای پیچیده، سادهسازی ارائه دادهها، دریافت چکیده اطلاعات بهتر و کسب راهنمایی جهت طراحی مدلها و الگوریتمهای محاسباتی ویژه این مبحث کمک میکند. تاکنون، پژوهشهای زیادی در زمینههای بیان شده پیرامون کلانداده (مِهداده) و گرایشهای آن توسط پژوهشگران گوناگون انجام شده است، ولیکن همچنان نیاز به مطالعات بیشتری در این حوزهها و دیگر زمینههای مرتبط وجود دارد.

لازم به ذکر است همه مجموعه دادههای موجود با ویژگیهای کلانداده الزاما برای فرآیند تحلیل یا تصمیمگیری مناسب نیستند. این مجموعه نوشته که در سه بخش منتشر میشود بر مفاهیم، کلیدواژههای مرتبط، چالشها و راهکارهای موجود برای کلانداده متمرکز شده است. علاوه بر این، دیگر مباحث نیازمند پژوهش در این حوزه عنوان شدهاند. در بخش اول از این مجموعه مطلب دو سرفصل اصلی وجود دارد که طی آنها تعاریف کلانداده (42 واژه معرف) و کلیدواژههای مرتبط با آن تشریح شدهاند.
تعریف کلانداده (42 واژه معرف)
درک یک مفهوم و برقراری ارتباط موثر با آن اغلب نیازمند ساخت یک مدل اولیه ذهنی است. برای مثال، چگونگی آموزش قوانین فیزیک به دانشآموزان یک مدرسه را در نظر بگیرید. این قوانین ابتدا و پیش از ورود به حساب، به استفاده از جبر خطی کمک میکنند. چنین مدلهایی با حذف جزئیات غیر لازم توانایی مورد نیاز برای درک یک تصویر بزرگتر را فراهم میآوردند.
در سال ۲۰۰۱، «گارتنر» (Gartner) در مقالهای با پیشبینی گرایشهای صنعت در آینده کولاکی در فناوریاطلاعات و دیگر حوزهها برپا کرد. در این مقاله، این گرایشها با عناوین «حجم داده» (Data Volume)، «سرعت داده» (Data Velocity) و «تنوع داده» (Data Variety) معرفی شده بودند. البته توسعه این عناوین همچنان ادامه داشت و بالغ بر یک دهه بعد چهار V، سپس هفت V و در ادامه یازده V معرفی شدند (منظور آن دسته از واژگانی است که در انگلیسی با حرف V آغاز میشوند و از جمله خصوصیات کلانداده محسوب میشوند. این موارد در ادامه بیان میشوند).

اما اکنون که بشر در سال ۲۰۱۸ قرار دارد، پیچیدگی جهان تحلیل روز به روز در حال افزایش است. برای همگام بودن با زمان، لیست تعداد واژگان (Vهایی) که برای تعریف کلان داده به کار میروند به روز رسانی شده و در مجموع شامل ۴۲ واژه است (این لیست تا پایان سال ۲۰۱۷ است و ممکن است پس از آن در آخرین مقالات ارائه شده در این حوزه واژگان دیگری مطرح شده باشند) که هر یک در ادامه تشریح شدهاند. شایان ذکر است که واژگان به ترتیب حروف الفبا آمدهاند.
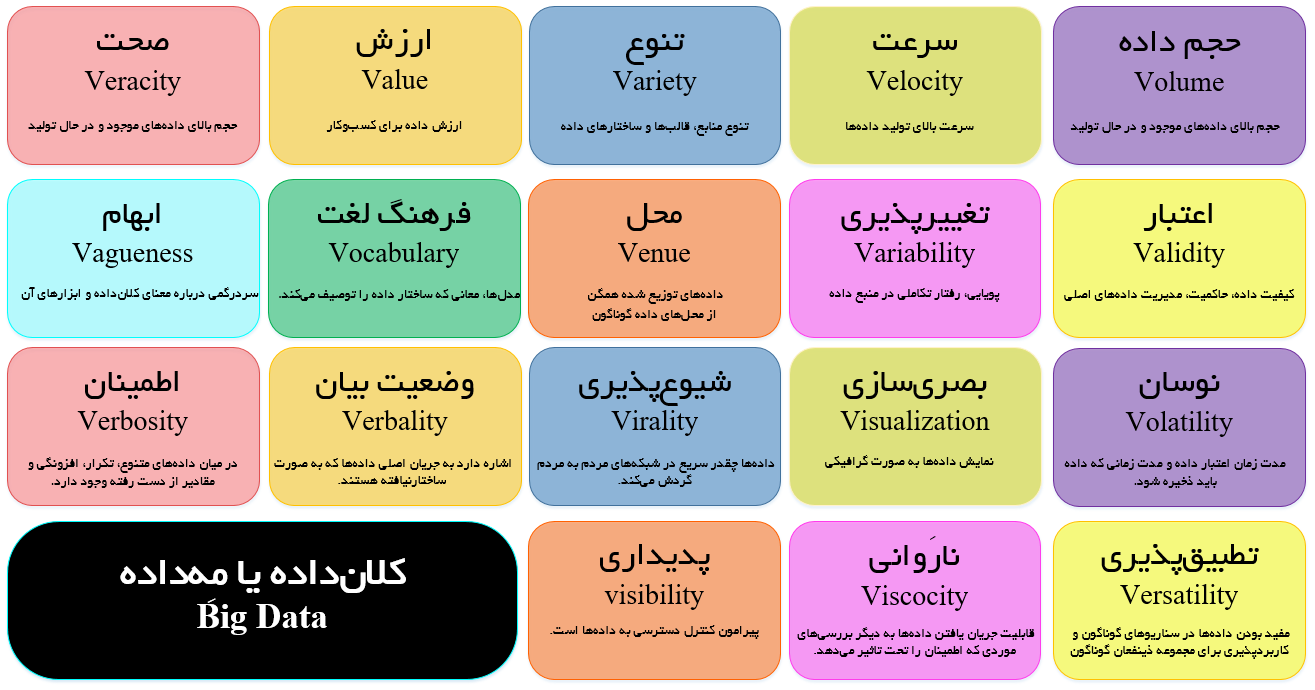
- ابهام (Vagueness): معنای داده یافت شده صرفنظر از حجم داده موجود، معمولا غیرشفاف و دارای ابهام است.
- اعتبار (Validity): انجام تحلیل دقیق به منظور داشتن پیشبینیهای معتبر امری ضروری است.
- شجاعت (Valor): در مواجهه با کلانداده، تحلیلگر باید همچون یک بازی از سد چالشهای پیش روی خود بگذرد.
- ارزش (Value): علم داده با افزایش دادههای موجود و توسعه روشهای جدید، ارزش روز افزونی برای کاربران فراهم میکند.
- تیغه (Vane): علم داده میتواند به جهت صحیح تصمیمگیری اشاره کند.
- متداول (Vanilla): حتی سادهترین و معمولترین مدلها اگر با دقت ساخته شوند میتوانند ارزش فراهم کنند.
- مزیت (Vantage): کلانداده به کاربران یک دیدگاه ممتاز از سیستمهای پیچیده میدهد.
- تغییرپذیری (Variability): تغییرپذیری به ناسازگاری مجموعههای داده اشاره دارد که ممکن است مانع مدیریت فرآیند تحلیل شوند. این امر از آن رو به وقوع میپیوندد که علم داده اغلب منابع داده متغیر را مدل میکند. ممکن است مدلهایی که در فرآیند تولید قرار میگیرند با دادههای رامنشدهای مواجه شوند.
- تنوع (Variety): پژوهشگران در علم داده، با قالبهای داده گوناگون (فایلهای مسطح، پایگاهدادههای رابطهای، شبکههای گراف) و سطح پیچیدگی متفاوت دادهها مواجه هستند. تنوع همچنین در ساختار یافته، ساختار نیافته و نیمه ساختار یافته بودن دادهها نیز مطرح است. از سوی دیگر، منابع دادهای که دادهها از آنها برای تحلیل گردآوری میشوند نیز اغلب متنوع است و همین تنوع منابع، ارزش تحلیلها را افزایش میدهد. به بیان دیگر، تنوع به نوع و ماهیت دادهها باز میگردد که به پژوهشگر جهت تحلیل و استفاده موثر از بینش نتیجه شده کمک میکند.
- تمرکز متغیر (وریفوکال | Varifocal): کلانداده و علم داده در کنار یکدیگری امکان دیدن جنگل (کل) و درخت (جز) را به طور همزمان فراهم میکنند.
- ناخواسته (Varmint): هر چه کلانداده بزرگتر شود، باگهای ناخواسته بیشتری ظهور میکنند.
- صیقلی (Varnish): چگونگی تعامل کاربر با خروجی کار پژوهشگر حائز اهمیت است.
- گستردگی (vastness): با ظهور اینترنت اشیا، «بزرگی» کلانداده در حال افزایش است.
- پیشبینی (Vaticination): تحلیلهای پیشبین، توانایی پیشبینی را فراهم میکنند (البته این پیشبینیها میتوانند بسته به سطح دقت و پیچیدگی مساله صحیح یا غلط باشند).
- گاوصندوق (Vault): با توجه به تعداد زیاد کاربردهای کلانداده که اغلب با استفاده از مجموعه دادههای کلان و حساس میتوان به آنها دست یافت، امنیت دادهها بسیار مهم است.
- انحراف (Veer): با ظهور تحلیل داده چابک، پژوهشگر باید قادر به حرکت در مسیر خواستههای کاربر باشد و هرگاه از او درخواست شد سریعا تغییر جهت دهد.
- پرده (Veil): علم داده ظرفیت نمایانسازی آنچه پشت پرده است را فراهم کرده و تاثیر متغیرهای پنهان در دادهها را مورد بررسی قرار میدهد.
- سرعت (Velocity): نه تنها حجم دادهها همواره در حال افزایش است بلکه نرخ تولید داده نیز به طور مداوم در حال رشد است (از اینترنت اشیا، شبکههای اجتماعی و دیگر موارد تولید کننده داده). سرعت به تندی که دادهها تولید و برای برآوردن تقاضاها پردازش میشوند اشاره دارد.
- محل (Venue): تلاشهای کلانداده در موقعیتهای گوناگون و با سازماندهیهای متفاوت به وقوع میپیوندند. این فعالیتها به طور محلی در ایستگاه کاری مشتری و یا در ابر (Cloud) انجام میشود.
- صحت (Veracity): صحت به کیفیت دادههای ثبت شده که ممکن است به شدت متنوع باشند و درستی تحلیلها را دستخوش تغییر کنند اشاره دارد. در همین راستا، تکرارپذیری امری حیاتی برای انجام تحلیلهای صحیح است.
- حکم (Verdict): با افزایش افرادی که تحت تاثیر تصمیمهای مدل قرار میگیرند، صحت و اعتبار اهمیت بیشتری پیدا میکنند.
- نظم (Versed): دانشمندان داده اغلب نیاز به داشتن دانستههای کم پیرامون چیزهای بسیار دارند که از این جمله میتوان به ریاضیات، آمار، برنامهنویسی، پایگاهداده و دیگر موارد اشاره کرد.
- کنترل نسخه (Version Control): کنترل و پیگیری تغییرات واحد اطلاعاتی در فرآیندهای تحلیل همواره لازم است.
- موشکافی (Vet): علم داده امکان موشکافی فرضیات و تقویت بینش با بهرهگیری از شواهد را برای پژوهشگر فراهم میکند.
- جدال (Vexed): برخی از هیجانات حول محور کلانداده بر پایه توانایی آن برای جدال با مسائل پیچیده و بزرگ و حل آنها است.
- پایداری (viability): ساخت یک مدل مستحکم کار دشواری است و ساخت سیستمی که در تولید پایدار باشد از آن هم سختتر محسوب میشود.
- پر جنبوجوش (vibrant): یک جامعه علم داده پر رونق نیازی حیاتی است و بینشها، ایدهها و پشتیبانی لازم برای تلاشهای پژوهشگران را فراهم میکند.
- خوراکرسان (Victual): کلانداده چیزی است که به علم داده سوخترسانی میکند.
- شیوعپذیری (Viral): دادهها چقدر سیع میان کاربران و نرمافزارهای گوناگون شیوع پیدا میکنند.
- تخصص (Virtuosity): در عین اینکه دانشمند داده نیاز به داشتن دانش اندک پیرامون مباحث زیاد دارد، باید در فرآیند رشد، دانش خود را در هر یک از موارد ارتقا دهد.
- نارَوانی (Viscosity): مرتبط با سرعت است و در پاسخ به این سوال که «کار با دادهها چقدر دشوار است؟» مطرح میشود. به عبارت دیگر، قابلیت جریان یافتن دادهها به دیگر بررسیهای موردی که اطمینان را تحت تاثیر میدهند چقدر است.
- پدیداری (Visibility): علم داده امکان پدیداری در مسائل کلانداده پیچیده را فراهم میکند.
- بصریسازی (Visualization): بصریسازی با نمودارها و گرافیکها، اغلب تنها راهی محسوب میشود که مشتریان با مدل ارتباط برقرار میکنند.
- روحبخشی (Vivify): علم داده پتانسیل روح بخشیدن به همه جنبههای تصمیمسازی و فرآیندهای کسبوکار را از تبلیغات گرفته تا کلاهبرداری دارد.
- فرهنگ لغت (Vocabulary): علم داده، فرهنگ لغتی برای حل مسائل گوناگون فراهم میکند. رویکردهای مدلسازی گوناگون به حل مسائل در دامنههای مختلف میپردازند و روشهای اعتبارسنجی متفاوت این رویکردها را در دامنههای گوناگون دشوارتر میسازند.
- رواج (Vogue): یادگیری ماشین به طور رو به رشدی به عنوان بخش متداولی از کسبوکار مشاهده خواهد شد و دیگر به عنوان چیزی غیرمعمول نخواهد بود، این امر به ویژه با کسب مزایای سیستمهای یادگیری ماشین برای ارزش کسبوکار واقعی محقق میشود. هوش مصنوعی به موضوع باب روز مبدل خواهد شد، و البته مجموعه وسیعتری از رویکردهای یادگیری ماشین که بینش ارزشمندی را در بخشهای گوناگون کسبوکارها و سازمانها فراهم میکنند مطرح میشوند.
- صدا (Voice): علم داده توانایی سخن گفتن همراه با دانش را در گستره وسیعی از مباحث فراهم میکند (البته نه همه دانش).
- نوسان (Volatility): به ویژه در سیستمهای تولیدی، پژوهشگر همواره باید برای نوسان دادهها آماده باشد. دادهها نباید به طور ناگهانی ناپدید و یا اعداد حاوی کاراکتر شوند (بحث مقادیر از دست رفته و نویز مطرح میشود).
- حجم (Volume): با افزایش دستگاههای دارای قابلیت اتصال به اینترنت، افراد بیشتری از دستگاههای تولید و گردآوری داده استفاده میکنند. از همین رو، حجم دادهها همواره در حال افزایش است. حجم به کمیت دادههای تولید و ذخیرهسازی شده اشاره دارد. اندازه دادهها نشانگر ارزش و بینش بالقوه نهفته در آن دادهها است و همچنین در کلان در نظر گرفته شدن یا نشدن آنها نیز تاثیر دارد.
- جادو (Voodoo): علم داده و کلانداده جادو نیستند، اما پرسشی که برای پژوهشگران به وجود میآید آن است که چگونه میتوان مشتریان بالقوه ارزش علم داده را برای انتقال نتایجی با تاثیر جهان واقعی متقاعد کرد.
- سفر (Voyage): پژوهشگر هر چه بیشتر با مسائلی که علم داده فراهم میکند مواجه میشود، بیشتر میآموزد.
- حیلهگری (Vulpine): تقاطع علم داده و روزنامهنگاری یکی از موضوعات مهم است. برای درک چرایی این امر مطالعه این مطلب توصیه میشود.
نمودار تعداد Vهای معرفی شده در هر سال در شکل زیر قابل مشاهده است.

رایانش ابری و کلانداده
رایانش ابری یا آنچه گاهی به آن ابر گفته میشود را میتوان به عنوان یک مدل محاسباتی مبتنی بر اینترنت برشمرد که امکان دسترسی گسترده به منابع محاسباتی را فراهم میکند. این منابع شامل چیزهای زیادی میشوند که از این جمله میتوان به نرمافزارها، منابع محاسباتی، سرورها و مراکز داده اشاره کرد.
ارائهدهندگان سرویسهای ابری معمولا از یک مدل «پرداخت به ازای مصرف» (pay-as-you-go) استفاده میکنند که به شرکتها امکان مقیاس دادن به هزینهها بر اساس نیزاهایشان را میدهد. همچنین، به کسبوکارها امکان دور زدن هزینههای راهاندازی زیرساختها را میدهد که پیش از ظهور رایانش ابری امری اجتنابناپذیر بود.

انواع تحلیلها
تحلیلهای گوناگونی در حوزه کلانداده قابل انجام است که هر یک در ادامه شرح داده شدهاند.

تحلیلهای پیشبین (Predictive Analytics): فناوری است که از تجربه (داده) میآموزد رفتار آینده افراد را به منظور اتخاذ تصمیمات بهتر پیشبینی کند (منظور از افراد الزاما انسانها نیست. بنابراین، الزاما رفتار انسانی پیشبینی نمیشود و امکان انجام انواع پیشبینیها بر اساس دادههای کنونی موجود وجود دارد). تحلیلهای پیشبین از «مدلهای پیشبین» (predictive models) استفاده میکنند. مدل پیشبین، مکانیزمی است که رفتار یک فرد مانند کلیک، خرید، دروغ یا مرگ را پیشبینی میکند. این مدل، ویژگیهای (مشخصهها) افراد (موجودیتها) را به عنوان ورودی دریافت کرده و یک امتیاز پیشبینی به عنوان خروجی فراهم میکند. هرچه امتیاز پیشبینی بالاتر باشد، احتمال آنکه آن موجودیت رفتار پیشبینی شده را از خود بروز دهد بیشتر است).

تحلیلهای توصیفی (Descriptive Analytics): این نوع از تحلیلها همانگونه که از نام آنها بر میآید ذاتا توصیفی هستند. تحلیلهای توصیفی دادهها را خلاصهسازی کرده و کمتر بر جزئیات دقیق هر بخش از اطلاعات تمرکز میکنند و در عوض بر روایت کلی متمرکز میشوند.

تحلیلهای تجویزی (Prescriptive Analytics): تحلیلهای تجویزی عموما به دنبال جنسی از پیشبینی هستند که بر اساس خروجی مدل پیشبین بتوان اقداماتی را تجویز کرد.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای پایگاه داده و سیستمهای مدیریت اطلاعات
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
موسسه توسعه، به صورت تخصصی به آموزش علم داده میپردازد. کسانی که صلاحیت ورود به دوره را پیدا کنند، زیر نظر اساتید طی یک دوره شش ماهه با صبر و تمرین زیاد به یک دانشمند علم داده تبدیل میشوند.
اساتید توسعه در زمینه علم داده، سالها در امریکا این موضوع را آموختهاند، پیادهسازی کردهاند و درس دادهاند. برای آشنایی بیشتر با این دوره و مدرسین آن به این آدرس مراجعه کنید.
^^











دست شما درد نکنه.
با سلام
مقاله از بار اطلاعاتی بالایی برخوردار بود . خیلی عالی
فقط می خواستم ببنیم اگر در زمینه بیگ دیتا و هادوپ و… بخوام مشاوره بگیرم از شما چطور میشه ارتباط گرفت!
بنده مالکی هستم دانشجو ارشد امنیت شبکه