



آزمون آماری مناسب در SPSS | راهنمای کاربردی
برای کسانی که با آمار و تحلیلهای آماری آشنایی کاملی ندارند، انتخاب روش تحلیل مناسب، کاری مشکل محسوب میشود. از طرفی نرمافزار کاربردی SPSS، بسیاری از آزمونها و محاسبات آماری را به راحتی در اختیار کاربر قرار داده است. به همین علت در این نوشتار از مجله فرادرس به شیوه انتخاب آزمون آماری مناسب در SPSS پرداختهایم. به این ترتیب با مراجعه به این متن میتوانید در بیشتر مواقع، آزمون آماری مطابق با خواسته خود را مشاهده و به کار ببرید.
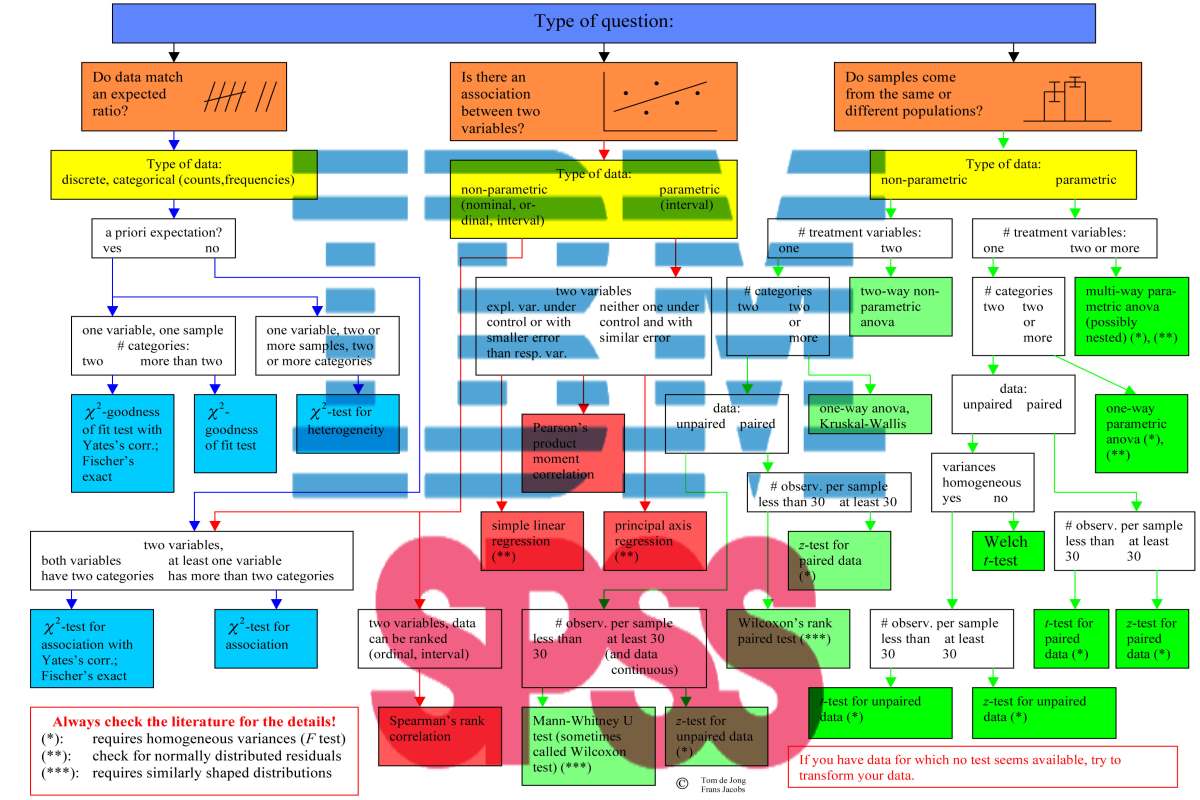


برای آشنایی بیشتر با اصطلاحات مرتبط با آزمونهای آماری نوشتار استنباط و آزمون فرض آماری — مفاهیم و اصطلاحات و مقدار احتمال (p-Value) در آزمون فرض آماری — به زبان ساده را مطالعه کنید. همچنین خواندن مطالب آزمون فرض میانگین جامعه در آمار — به زبان ساده و تحلیل واریانس (Anova) — مفاهیم و کاربردها نیز خالی از لطف نیست.
آزمون آماری مناسب در SPSS
همانطور که گفته شد، انتخاب روش آزمون مناسب برای دادهها و تحلیل آنها، همیشه با سردرگمی همراه است. در این متن، آزمونها و روشهای تحلیلی را به شش بخش تقسیم کردهایم و برای هر یک از آنها، نحوه دستیابی به آزمون آماری مناسب در SPSS را شرح خواهیم داد.
در ادامه لیست شش گانه را مشاهده میکنید.
- آزمونهای تک متغیره (Univariate Test)
- آزمونهای درون آزمودنیها (Within-Subjects Tests)
- آزمونهای بین آزمودنیها (Between-Subjects Test)
- اندازههای وابستگی (Association Measures)
- تحلیلهای پیشگو (Prediction Analyses)
- تحلیلهای طبقه یا ردهبندی (Classification Analyses)
یکی از عواملی که در تشخیص نوع آزمون آماری مناسب در SPSS تاثیر گذار است، تعیین یا تشخیص نوع دادهها است. به منظور آشنایی بیشتر با انواع دادهها بهتر است، نگاهی به مطلب جامعه آماری – انواع داده و مقیاسهای آنها بیاندازید. البته توجه داشته باشید که در انتخاب آزمون آماری مناسب در SPSS، عوامل زیر تاثیر گذار و مطرح هستند.
- شناخت اساسی از عملکرد آزمونهای آماری و پیشفرضهای اولیه برای اجرای آنها.
- تشخیص مقیاسهای اندازهگیری دادهها و نوع متغیرهای مجموعه داده در SPSS و ثبت آنها در ویرایشگر داده (Data Editor).
برای تحلیل دادهها، انتخاب آزمون آماری مناسب کلید نتیجهگیری صحیح است. با یادگیری آزمونهای پرکاربرد مانند t-test، ANOVA و کایدو میتوانید دادههای خود را دقیقتر بررسی کنید. اگر میخواهید نحوه انتخاب آزمون و تحلیل دادهها را گام به گام یاد بگیرید، فیلم آموزشی رایگان ما را مشاهده کنید.
آزمون آماری مناسب برای تحلیل تک متغیره
از آزمونهای تک متغیره برای تحلیلهای زیر استفاده میکنیم.
- آزمون فرض مربوط به برابری پارامتر جامعه (معمولا میانگین یا میانه) با یک مقدار ثابت.
- آزمون فرض در مورد شکل توزیع جامعه آماری. در این حالت معمولا مطابقت با توزیع نرمال- Normal Distribution مورد سوال است.
یکی از مسائلی که توسط گروه اول از آزمونهای تک متغیره، مورد تحلیل قرار میگیرد، «آزمون تی تک نمونهای» (One sample t -test) است. این آزمون آماری، برابری میانگین جامعه را با یک مقدار مشخص، مورد بررسی قرار میدهد.

جدول زیر چند آزمون پرکاربرد از گروه آزمونهای تک متغیره در SPSS را معرفی کرده است.
جدول ۱: آزمونهای تک متغیره در SPSS
| نوع یا مقیاس داده | فرض صفر | آزمون مورد نظر |
| میانگین جامعه = X? | ||
| توزیع جامعه = f(x)? | ||
| میانگین جامعه = X? | ||
| میانه جامعه = X? | ||
| توزیع جامعه = f(x)? |
با کلیک کردن روی هر یک از لینکهای مربوط به ستون آزمون مورد نظر، به صفحه خاصی از مجله فرادرس خواهید رسید که حاوی توضیحات و نحوه اجرای آزمون در SPSS یا نرمافزارهای محاسبات آماری دیگر است.
نکته: مسیر دسترسی به آزمونهای این قسمت، در بخش بعدی معرفی شدهاند.
آزمون آماری مناسب برای تحلیل درون آزمودنیها
اگر قرار است آزمونی برای مقایسه دو یا چند متغیر از یک جامعه آماری صورت گیرد، آزمونهای «درون آزمودنیها» (Within-Subject Test) صورت میگیرد. نکته مهم در آن آزمونها آن است که متغیرها برای هر آزمودنی اندازهگیری شده و به نوعی وابستگی درونی بین مقادیر متغیرها در هر سطر از مشاهدات وجود دارد. منظور از آزمودنی، همان مشاهدات حاصل از نمونهگیری از جامعه آماری است.
به عنوان یک مثال میتوان به «آزمون تحلیل واریانس با مقادیر تکراری» (Repeated measures ANOVA) اشاره کرد. در تصویر ۲، یک نمونه از چیدمان دادهها در پنجره ویرایشگر داده SPSS را مشاهده میکنید. واضح است که متغیرها در ستونها قرار گرفتهاند و نتیجه اندازهگیریهای مختلف یک یا چند ويژگی روی یک فرد را مشخص کردهاند.

نکته: برای نشان دادن وابستگی بین مشاهدات، مشاهدات مربوط به یک فرد خاص را در ستونهای مختلف قرار دادهایم تا نشانگر وابستگی بین مقادیر آن باشد. به یا دارید که هر سطر از دادهها، در حالت عمومی، نشانگر یک مشاهده یا یک نمونه آماری است.
در جدول ۲، نمونهای از آزمونهای درون آزمودنی قابل استفاده در SPSS مورد اشاره قرار گرفته است. آزمونهای مربوط به درون آزمودنیها در شرایط مختلف به صورت زیر در SPSS به کار میروند.
- آزمونهای مبتنی بر زوج مشاهدات (برای مثال آزمون نمونهای زوجی تی - Paired Samples T-test)
- آزمونهای نمونههای وابسته (Related Sample Tests)
جدول ۲: آزمونهای مربوط به روشهای تحلیل درون آزمودنیها در SPSS
| نوع یا مقیاس داده | حالت دو متغیره | حالت سه متغیر |
در تصویر ۳، نحوه دسترسی به بعضی از این گونه دستورات برای تحلیلهای ناپارامتری را در نرمافزار SPSS مشاهده میکنید.

به منظور دسترسی به دیگر آزمونهای پارامتری از مسیر زیر اقدام کنید.
Analyze > Compare Means
آزمون آماری مناسب برای تحلیل بین آزمودنیها
به کمک آزمونهای این گروه، میتوانیم مقایسه بین دو یا چند زیر جامعه (یا جوامع مستقل) را صورت دهیم. در این بین میتوان مقایسه را وابسته به دو محور طبقهبندی کرد.
- مقایسه پارامتر جامعهها (مانند میانگین، انحراف معیار یا درصد)
- مقایسه توزیع جوامع با توزیع دلخواه

معروفترین آزمون در این گروه، «تحلیل واریانس یک طرفه» (One-way ANOVA) است که توسط آن مقایسه بین میانگین چند گروه یا جامعه مستقل صورت میگیرد. نمونهای از چیدمان دادهها برای انجام این تحلیل را در تصویر ۴، مشاهده میکنید.

همانطور که مشخص است، مقادیر مربوط به متغیر برای هر جامعه در ستون واحدی نوشته شده (Outcome) ولی متغیر یا ستون (group)، تعلق هر مشاهده را به هر یک از جوامع (A, B , C) نشان میدهد.
نکته: هنگام کار با SPSS به این موضوع توجه داشته باشید که سطرها (یا مشاهدات) مستقل از یکدیگر فرض میشوند. به همین علت برای نمایش دادن جوامع مستقل، مقادیر متغیر کمی را در سطرهای مختلف ولی در یک ستون ثبت کردهایم. به این ترتیب مشاهدات باید فقط به یک جامعه تعلق داشته باشند و هیچ همپوشانی در مشاهدات نسبت به جوامع وجود ندارد.
جدول ۳، نمونهای از آزمونهای مربوط به بین آزمودنیها را مورد بررسی قرار داده است.
جدول ۳: آزمونهای پر کاربرد در SPSS برای تحلیل بین آزمودنی
| نوع یا مقیاس داده | حالت دو متغیره | حالت سه متغیر |
|
داده دو وضعیتی (Dichotomous) | ||
|
دادههای اسمی (Nominal) | ||
|
دادههای ترتیبی (Ordinal Measurement) |
Mann-Whitney test (mean ranks) | آزمون کروسکال والیس
Kruskal-Wallis test (mean ranks) |
|
دادههای کمی (Quantitative) |
آزمونهایی که مربوط به دادههای دو وضعیتی، اسمی و ترتیبی هستند در گروه تحلیلهای ناپارامتری گنجانده شده و از طریق مسیر زیر در SPSS در اختیار کاربران قرار میگیرند.
Analyze > Nonparametric Tests
ولی اگر تحلیل مورد نظر، روی دادههای کمی صورت گیرد، مسیر دسترسی مناسب به شکل زیر خواهد بود.
Analyze > Compare Means
آزمون آماری مناسب برای تحلیل اندازههای وابستگی
شاخصهای عددی مرتبط با وابستگی بین دو متغیر، «اندازههای وابستگی» (Association Measures) نامیده میشوند. معروفترین شاخصهای اندازهگیری وابستگی، «ضریب همبستگی پیرسون» (Pearson Correlation) است که برای دو متغیر کمی و نمایش رابطه خطی بین آنها به کار میرود. نحوه دسترسی به تحلیل همبستگی در SPSS برای دادههای کمی از طریق مسیر زیر امکانپذیر است.
Analyze > Correlation
البته اگر دادهها از نوع کیفی باشند، معمولا شاخصهای حاصل از جدول توافقی برای نمایش وابستگی به کار رفته و از مسیر زیر قابل دستیابی هستند.
Analyze > Descriptive Statistics > Crosstabs
در تصویر ۵، ماتریس همبستگی بین سه متغیر توسط «نمودارهای نقطهای» (Scatter Plot) نمایش داده شده است. همانطور که مشخص است، هرچه رابطه خطی بین متغیرها بیشتر باشد، نمودار به خط راست شبیهتر است.

با توجه به نوع داده، شاخص و ضرایب وابستگی متفاوتی تعریف و به کار برده میشود. جدول ۳ به معرفی هر یک از آنها پرداخته است.
جدول ۳: ضرایب و شاخصهای وابستگی بین دو متغیر
| نوع متغیرها | کمی | ترتیبی | اسمی | دو وضعیتی |
| کمی | - | - | - | |
| ترتیبی | - | - | ||
| اسمی | - | |||
| دو وضعیتی | ضریب همبستگی دو سریالی |
آزمون آماری مناسب برای تحلیلهای پیشگو
آزمونهای پیشگو یا پیشبینی، چگونگی روند تغییرات یک پدیده را برحسب یک یا چند متغیر مشخص میکنند. سادهترین مثال در این حوزه مرتبط با تکنیک «رگرسیون خطی ساده» (Simple Linear Regression) است. مسیر دسترسی به روشهای تحلیل رگرسیونی در SPSS به صورت زیر است.
Analyze > Regression
در تصویر ۵، یک نمونه از تحلیل رگرسیون خطی ساده را براساس چند نقطه مشخص کرده است. محور افقی در این نمودار، امتیاز هوش (IQ test score) و محور عمودی نیز امتیاز کارایی (Job performance test score) در شغل مورد نظر است. به این ترتیب به کمک مدل رگرسیونی میتوانیم میزان کارایی افراد در شغلشان را به کمک امتیاز هوش (IQ) پیشگویی کنیم. واضح است که با افزایش میزان هوش، کارایی نیز طبق نمودار و تحلیل رگرسیونی، افزایش مییابد.
معادله معرفی شده در این تحلیل رگرسیونی به صورت زیر است:
Predicted job performance = 34.3 + 0.64 * IQ
که در آنها 34.3 را عرض از مبداء و 0.64 را شیب خط میگویند. از آنجایی که شیب خط مثبت است، رابطه بین این دو متغیر در یک راستا است. به این معنی که با افزایش یکی، دیگری نیز افزوده خواهد شد.
به این ترتیب میتوانیم به واسطه رابطه ذکر شده، متوجه شویم اگر میزان نمره هوش فردی نسبت به فرد دیگر، ۱۰ واحد افزایش داشته باشد، کارایی او نیز 6.4 واحد بیشتر خواهد بود. این موضوع در نمودار مربوط به تصویر ۶، به خوبی نمایش داده شده است و نقش ضریب یا شیب خط رگرسیونی را روشنتر میکند.

البته گاهی ارتباط بین متغیر وابسته (معرفی شده در محور عمودی) و مستقل (محور افقی) به علت وجود «رابطه علّی» (Causality) است و هدف از اجرای رگرسیون خطی، کشف این رابطه علّی محسوب میشود.

جدول ۴: تکنیکهای مختلف تحلیلهای پیشگویی
| نوع متغیر وابسته | تحلیل |
| کمی (Quantitative) | |
| ترتیبی (Ordinal) | |
| اسمی (Nominal) | |
| دو وضعیتی (Dichotomous) |
آزمون آماری مناسب برای تحلیلهای ردهبندی و خوشهبندی
در تجزیه و تحلیل طبقهبندی (Classification Analysis) هدف، شناسایی و گروههای مشخصی از مشاهدات یا متغیرها است. روشهای تجزیه و تحلیل طبقهبندی معمولا به دو گروه زیر دستهبندی میشوند.
- تحلیل عاملی (Factor Analysis) برای یافتن گروه متغیر یا عاملها (Factors).
- تحلیل خوشهبندی برای یافتن خوشههایی (Clusters) از مشاهدات که بیشترین شباهت را با یکدیگر و بیشترین فاصله را بین خوشهها داشته باشند.
توجه داشته باشید که تحلیل عاملی، مبتنی بر همبستگیها است. فرض بر این است که گروههایی از متغیرها که به شدت همبستگی دارند، میتوانند یک عامل قابل اندازهگیری به نام «سازه» (Constructs) را شکل دهند.
در تصویر 7، نمونهای از دادهها و عواملی که توسط آنها قابل شناسایی است، نمایش داده شده. واضح است که متغیرهای اول تا سوم، عامل A یا (Factor A) و به همین ترتیب متغیرهای بعدی عوامل B و C را میسازند. نامگذاری این عوامل یا سازهها، بستگی به حوزه تحقیق و موضوع مورد بررسی دارد. به همین علت اغلب این عوامل بوسیله حروف الفبا نامگذاری میشوند تا یک محقق، برای هر یک از آنها نام مناسب انتخاب کند.
مسیر دسترسی به تحلیل عاملی در SPSS به صورت زیر است.
Analyze > Dimension Reduction

برعکس روش تحلیل عاملی، در «خوشهبندی» (Clustering) سعی میشود گروههای همسان براساس مشاهدات تشکیل شوند. تصویر 8، یک نمایش از تحلیل خوشهای برای مشاهدات را نمایش میدهد که آنها را به سه خوشه مجزا از یکدیگر تفکیک کرده است. این کار براساس حداکثر شباهت درون خوشهای و بیشترین فاصله بین خوشهها صورت گرفته و به هر مشاهده یک برچسب برای عضویت در خوشه نسبت داده میشود. دسترسی به دستورات مربوط به خوشهبندی از مسیر زیر امکانپذیر است.
Analyze > Classify

خلاصه و جمعبندی
در این نوشتار به بررسی نحوه انتخاب آزمون مناسب در SPSS براساس نوع داده و همچنین تعیین نوع تحلیل با توجه به هدف مورد نظر پرداختیم. همانطور که دیدید، بعضی از تحلیلها به صورت پارامتری (با در نظر گرفتن توزیع مشخص برای جامعه آماری) انجام گرفته و بعضی نیز بدون آگاهی از توزیع جامعه، و به شکل ناپارامتری (Non-Parameteric) مورد استفاده قرار میگیرند. خوشبختانه بسیاری از آزمونهای قابل استفاده، در نرمافزار SPSS نیز گنجانده شده و برای کاربران قابل دسترس است. رگرسیون و تحلیل دادههای زمانی نیز از امکانات دیگری است که در SPSS وجود دارد. به این ترتیب کاربران این نرمافزار میتوانند تقریبا همه نوع دادهای را مورد تحلیل قرار داده و نتایج حاصل را دریافت و تفسیر کنند.










