



مهندسی داده با پایتون و Django – راهنمای کاربردی
در این مطلب، با مبحث مهندسی داده آشنا خواهید شد. بدون شک، «مهندسی داده» (Data Engineer) یکی از سختترین جنبههای «علم داده» (Data Science) محسوب میشود. اگرچه مهندسی داده نقش زیادی در بخش «تحلیل داده» (Data Analysis) در حوزه علم داده ندارد، با این حال، به عنوان Back-End سیستمهای تحلیل داده و علم داده محسوب میشود. منظور از Back-End در تعریف مهندسی داده به عنوان بخشی از علم داده، «سیستمهای پایگاه دادهای» (Database Systems) است که تمامی «دانشمندان علم داده» (Data Scientists) به نحوی با آن سر و کار دارند.




در این مطلب، برای روشنتر شدن مفهوم مهندسی داده برای خوانندگان و مخاطبان، مباحث زیر مورد بررسی قرار میگیرند:
- تولید یک برنامه کاربردی مبتنی بر Django با «سیستمهای مدیریت پایگاه داده رابطهای» (Relational Database Management System | RDBMS).
- نمایش چگونگی استفاده از پایگاه داده PostgresSQL متصل به برنامه کاربردی مبتنی بر Django.
- چگونگی جابجا کردن دادهها میان «قالبها» (Formats) و «پلتفرمهای» (Platforms) مختلف.

با اینکه برای درک مفاهیم موجود در این مطلب نیازی به دانش اولیه در مورد پلتفرم Django وجود ندارد، با این حال ذکر این نکته حائز اهمیت است که بسیاری از اقدامات مرتبط با جمعآوری دادهها، از طریق بسترها یا برنامههای کاربردی مبتنی بر وب انجام میگیرد. در نتیجه، آشنایی با پلتفرمی نظیر Django، فرایند جمعآوری و مدیریت دادهها در برنامههای کاربردی تحت وب را به مراتب سادهتر میکند.
پلتفرم Django برای بسیاری از دانشمندان داده که با مبحث مهندسی داده سر و کار دارند، ابزاری بسیار محبوب و آشنا محسوب میشود. پلتفرم Django، چارچوبی برای ساختن «برنامههای کاربردی تحت وب» (Web Applications) فراهم میآورد که از فلسفه «وارونگی کنترل» (Inversion of Control) در «مهندسی نرمافزار» (Software Engineering) تبعیت میکند.
وارونگی کنترل، یک اصل در مهندسی نرمافزار است که «جریان کنترل» (Flow of Control) را در برنامههای کاربردی، در مقایسه با کنترل جریان مرسوم، معکوس میکند. به عبارت دیگر، پلتفرم Django اسکلت (Skeleton) برنامه کاربردی تحت وب را فراهم میکند و کاربر یا برنامهنویس وظیفه دارد محتویات اصلی و لازم برای عملکرد صحیح برنامه کاربردی تحت وب را فراهم آورد. به بیان سادهتر، پلتفرم Django امکانات زیرساختی، نرمافزاری و برنامهنویسی لازم برای مهندسی داده در برنامه کاربردی تحت وب را فراهم میآورد.

مهندسی داده در Django
برای اینکه مکانیزم مهندسی داده توسط Django در پایتون آموزش داده شود، نحوه کدنویسی برنامهای به نام DoubleBagger نمایش داده خواهد شد. این برنامه کاربردی، یک «وبلاگ» (Blog) ویژه مسائل سرمایهگذاری است که مردم، نظر خود را در مورد خرید یا فروش سهام شرکتهای عرضه شده در بازار بورس نظیر اپل (APPLE | AAPL) یا مایکروسافت (MICROSOFT | MSFT) با دیگر افراد به اشتراک میگذارند.

همچنین، در این مطلب به جای استفاده از «محیطهای توسعه یکپارچه» (Integrated Development Environments | IDEs) نظیر PyCharm و Jupyter Notebook، از یک واسط خط دستور (Command Line Interface) و یک «ویرایشگر منبع کد» (Source Code Editor) به نام Sublime Text استفاده میشود.
علاوه بر این، از آنجایی که برنامه کاربردی مرتبط با علم داده است، از محیط Conda برای نصب کتابخانهها و بستههای نرمافزاری و همچنین، ایجاد «محیطهای مجازی» (Virtual Environment) استفاده میشود.
برای ساختن برنامه کاربردی مورد نظر، نیاز است تا دو کتابخانههای مهم زبان پایتون توسط Conda نصب شوند؛ کتابخانه Django و کتابخانه psycopg2 برای متصل شدن به پایگاههای داده PostgreSQL. استفاده از SQLite برای بسیاری از نیازهای سازمانی شرکتها و یا کسانی که به شکل سرگرمی برنامهنویسی انجام میدهند، مناسب است. با این حال، در این برنامه کاربردی، برای استفاده از قابلیت پایگاه داده از پایگاههای داده PostgreSQL استفاده میشود. علاوه براین، برای پیادهسازی برنامه کاربردی و توسعه پروژه مهندسی داده، از نسخه 1.9.6 کتابخانه Django استفاده میشود.
پس از اطمینان از این موضوع که علاوه بر کتابخانههای برنامهنویسی، «وابستگیهای» (Dependencies) آنها نیز به درستی روی سیستم نصب شدهاند، یک دایرکتوری به نام src ایجاد میشود تا تمامی کدهای منبع و کدهای جانبی مرتبط با برنامه Doublebagger در این دایرکتوری ذخیره شوند.
در مرحله بعد، از قطعه کدهای زیر برای ایجاد یک پروژه Django و شروع کد نویسی برنامه کاربردی Doublebagger استفاده میشود:
دستور django-admin startproject command همان دستوری است که به وسیله آن، اسکلت یا چارچوب لازم برای برنامه کاربردی تحت وب فراهم میشود. با دقت به ساختار پوشهبندی برنامه کاربری ایجاد شده، پوشه src ساختاری مشابه با شکل زیر خواهد داشت:
- پوشه doublebagger_blog: تنظیمات مرتبط با پروژه از جمله فایل settings.py، در این پوشه قرار دارد.
- پوشه manage.py: در این پوشه، فایلهای مرتبط با utility function پروژه ذخیره میشود.
پس از انجام مراحل فوق، کاربر یا برنامهنویس قادر خواهد بود تا پروژه مهندسی داده ایجاد شده با نام DoubleBagger را درون Sublime Text یا هر ویرایشگر کد دیگری باز کند. ساختار دایرکتوری ایجاد شده برای پروژه DoubleBagger، باید به شکل زیر باشد:
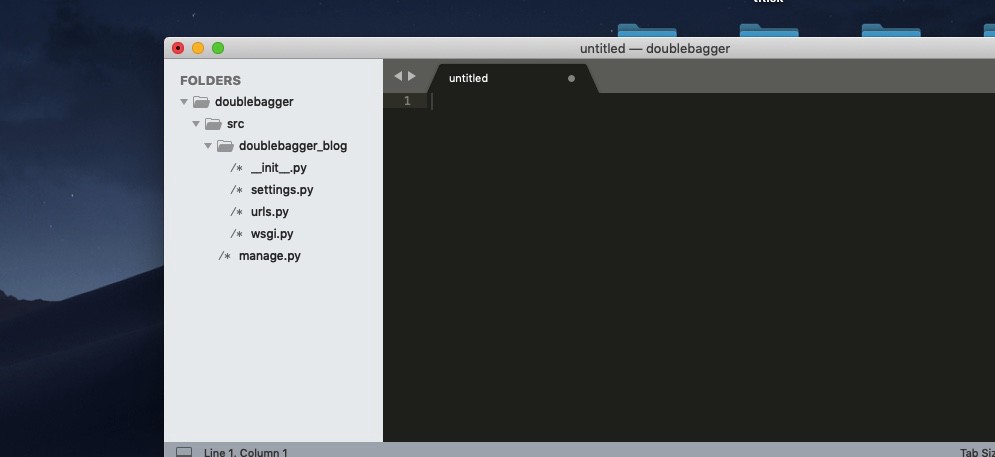
با فرض اینکه، نرمافزار مدیریت پایگاه داده PostgreSQL روی سیستم کاربر یا برنامهنویس نصب شده باشد، در مرحله بعد لازم است تا یک پایگاه داده PostgreSQL برای پروژه مهندسی داده (DoubleBagger) ایجاد شود:
در ادامه نیاز است تا فایل settings.py توسط کاربر یا برنامهنویس در نرمافزار ویرایشگر کد Sublime Text باز شود. پس از باز کردن فایل، محتویات آن به شکل زیر خواهد بود:
برای اینکه بتوان پروژه مهندسی داده ایجاد شده را به پایگاه داده تولید شده متصل کرد، لازم است تا محتویات پیشفرض موجود در فایل settings.py را با محتویات زیر تغییر داد و تغییرات انجام شده را نیز در ویرایشگر کد ذخیره کرد:
در مرحله بعد، برای متصل کردن پروژه مهندسی داده و برنامه کاربردی تحت وب به پایگاه داده PostgreSQL، لازم است تا قطعه کدهای زیر در واسط خط دستوری اجرا شوند:
اگر اجرای تمامی کدهای نمایش داده شده در مراحل بالا با موفقیت انجام شود، پیغامهایی مانند شکل زیر در خروجی نمایش داده خواهد شد:

سپس، در همان واسط خط دستوری، دستور زیر اجرا میشود:
با اجرای دستور بالا، آدرس یک «سرور محلی» (Local Server)، همانند آدرس زیر، نمایش داده خواهد شد:
با باز کردن آدرس سرور محلی نمایش داده شده در «مرورگر وب» (Browser)، کاربر یا برنامهنویس، با پیغامی همانند پیغام زیر روبرو خواهد شد:

صفحهای که در نتیجه باز کردن آدرس سرور محلی باز خواهد شد، در اصل «صفحه نخست» (Homepage) برنامه کاربردی تحت وب است. این صفحه در «سرورهای توسعه محلی» (Local Development Server) کتابخانه Django اجرا میشود و هدف آن، همانند سازی اجرای برنامه کاربردی تولید شده در «وب سرور» (Web Server) واقعی است. برای خارج شدن از حالت سرورهای توسعه محلی Django، از فشار دادن همزمان کلیدهای control-C استفاده میشود.
مهندسی داده در برنامههای کاربردی تحت وب
دلیل استفاده از Django و پایگاه داده PostgreSQL در پروژههای مهندسی داده این است که مدلهای Django، قابلیتی تحت عنوان «نگاشت کننده مدل اشیاء به مدل رابطهای» (Object Relational Mapper | ORM) در اختیار برنامهنویسان و توسعه دهندگان برنامههای کاربردی تحت وب قرار میدهد. این قابلیت به برنامهنویسان و توسعهدهنگان اجازه میدهد تا «اشیاء» (Objects) مدل را با استفاده از زبان پایتون و زمانی که برنامه کاربردی تحت وب به پایگاه داده PostgreSQL متصل است، دستکاری کنند.
ویژگی ORM، یکی از لایههای پیچیده پایتون و Django در تعریف و مدیریت «اکوسیستمهای علم داده» (Data Science Ecosystems) محسوب میشود. از این مرحله به بعد، ساختار دادهها در برنامه کاربردی تحت وب و پروژه مهندسی داده در حال توسعه تعریف میشوند. برنامه کاربردی تحت وب در حال توسعه، دو «مؤلفه» (Component) یا «کلاس مدل» (Model Class) خواهد داشت:
- مؤلفه Post: نمایش دهنده پستهایی از وبلاگ است که در رابطه با خرید یا فروش سهام یک شرکت خاص بحث میکنند.
- مؤلفه Company: نمایش دهنده اطلاعات مرتبط با شرکتهایی است که در پستهای وبلاگ از آنها نام برده میشود.
مؤلفه Post، اطلاعات زیر را شامل خواهد شد:
- عنصر title: عنوان پست منتشر شده در وبلاگ.
- شناسه slug: شناسه یکتا برای هر کدام از پستهای وبلاگ، که بر اساس عنوان پستها ساخته میشود.
- عنصر text: متن واقعی پستهای وبلاگ.
- عنصر pub_date: زمان انتشار پستهای وبلاگ را نشان میدهد.
مؤلفه Company نیز، اطلاعات زیر را شامل خواهد شد:
- عنصر name: نام شرکتی که پستهای وبلاگ، اطلاعات خاصی در مورد سهام آنها منتشر میکند.
- عنصر slug: شناسه یکتا برای شرکت.
- عنصر description: اطلاعات مرتبط با حیطه وظایف شرکت را نمایش میدهد.
- عنصر PE Ratio: ارزشگذاری شرکتها نسبت به قیمت بازار را نشان میدهد.
پیش از اینکه بتوان کدهای لازم برای پیادهسازی مؤلفههای Post و Company و عناصر موجود در هر کدام از این مدلهای Django را نمایش داد، لازم است تا ابتدا یک برنامه کاربردی تحت وب Django، با استفاده از دستورات زیر تولید شود:
پس از اجرای دستورات فوق، پوشه مرتبط با یک برنامه کاربردی به نام post، مانند شکل زیر، در وایشگر کد قابل مشاهده خواهد بود:

در مرحله بعد لازم است تا برنامه post به قسمت INSTALLED_APPS در فایل settings.py الحاق و تغییرات انجام شده ذخیره شود:
پس از انجام مراحل فوق، وقت آن فرا میرسد تا ساختار دادهها، از طریق اضافه کردن قطعه کدهای زیر به فایل models.py در پوشه post مشخص شود:

یکی از مهمترین جنبههای مدلهای تولید شده که باید مد نظر قرار داده شود این است که دو مدل (مؤلفه) تولید شده چگونه با یکدیگر ارتباط دارند. اگر با دید SQL به کدهای بالا و مؤلفههای تولید شده توسط آنها نگاه شود، مشخص میشود که مؤلفههای Post و Company، ساختار «جدولی» (Tabular) دارند و «فیلدهایی» (Fields) نظیر title ،pub_date و slug، «ستونهای» (Columns) موجود در دو جدول را نمایش میدهند.

بنابراین، اگر با دید SQL به دو مدل یا مؤلفه تولید شده نگاه شود، لازم است تا رابطه میان آنها نیز مشخص شود:
- رابطه «یک به چند» (One-to-Many) یا «چند به یک» (Many-to-One)
- رابطه «چند به چند» (Many-to-Many)
با در نظر گرفتن جمله زیر، به راحتی مشخص میشود که رابطه چند به یک میان مدلهای (مؤلفههای) Post و Company وجود دارد.
One blog post can only be an investment thesis about one company, but one company can have many blog posts written about it.
در نتیجه، برای مدلسازی ساختار دادهها توسط پایگاههای داده رابطهای نیاز است تا مدل Post، یک «کلید خارجی» (Foreign Key) به مدل Company داشته باشد. ویژگی مهم کتابخانه Django، سادگی استفاده از آن است. کتابخانه Django، غالب عملیات لازم جهت ساختن یک مدل پایگاه داده را مدیریت میکند؛ لازم نیست تا «کلیدهای اصلی» (Primary Keys) به طور صریح تعریف شوند و نیازی به تعریف «شاخصها» (Indexes) یا «جداول اتصالی» (Junction Tables) در روابط چند به چندی وجود ندارد.
با استفاده از پلتفرم Django، کلید خارجی به شکل زیر به مدل Post اضافه میشود:
اضافه کردن برخی پارامترهای اضافی و «توابع رشتهای» (String Methods)، به سیستم اجازه میدهد تا به «اشیاء مدل» (Model Objects) توسط نام رشتهای آنها ارجاع دهد. بنابراین، مدل Post بهروزرسانی شده و نهایی، در پروژه مهندسی داده در حال توسعه، به شکل زیر خواهد بود:
در مرحله بعد و از طریق اجرای دستورات زیر در واسط خط فرمان، کتابخانه Django یک پایگاه داده postgreSQL برای پروژه مهندسی داده در حال توسعه ایجاد میکند.
با اجرای دستورات بالا، خروجیهایی مانند شکل زیر تولید میشود:

مهندسی داده با استفاده از نگاشت کننده مدل اشیاء به مدل رابطهای در Django
در این مرحله و پس از مقدمهسازیهای انجام شده، دانشمند داده، برنامهنویس یا توسعهدهنده وب قادر خواهد بود با پایگاه داده postgreSQL، تنها با استفاده از زبان پایتون، تعامل داشته باشد.
برای چنین کاری کافی است تا با استفاده از واسط خط دستوری، مجموعه دستورات زیر، خط به خط اجرا شوند:
با اجرای این دستور، واسطی مانند واسط shell در مفسر پایتون در اختیار کاربر قرار داده میشود؛ با این تفاوت که چنین واسطی، امکان انجام عملیات و دستکاری پایگاههای داده Django را در اختیار کاربر و برنامهنویس قرار میدهد.
در مرحله بعد با استفاده از دستور زیر، شیء مرتبط با مدل (مؤلفه) Company ساخته خواهد شد:
پس از اجرای دستور بالا، با پیغامی مانند پیغام زیر مواجه خواهید شد:
به عبارت دیگر، با استفاده از دستور بالا و به کمک کتابخانه Django، مدلی برای شرکت APPLE ساخته شد؛ بدون اینکه نیازی به استفاده از دستورات زیر (دستورات دستکاری پایگاههای داده رابطهای) وجود داشته باشد:
در ادامه و با استفاده از مجموعه دستورات نمایش داده شده، مدلهای مرتبط با شرکتهای بیشتری در پایگاه داده تولید میشود:
- مقاله پیشنهادی: MongoDB چیست ؟ — راهنمای شروع با دیتابیس مانگو دی بی
بنابراین، تا اینجا پایگاه داده برنامه کاربردی در حال توسعه توسط رکوردها یا مدلهای مرتبط با شرکتهای مختلف بهروزرسانی شده است. علاوه بر امکان دستکاری و بهروزرسانی رکوردهای پایگاه داده، امکاناتی نظیر «پرس و جو» (Query) در پایگاه داده توسط دستورات زبان پایتون برای دانشمندان داده، برنامهنویسان و توسعهدهنگان فراهم شده است:
همچنین، امکان نمایش رکوردهای پایگاه داده در قالب «چندتایی» (Tuples) نیز وجود دارد:
با استفاده از مجموعه دستورات زیر، شیء مرتبط با مدل (مؤلفه) Post ساخته خواهد شد:
برای اینکه بتوان اطمینان حاصل کرد که اشیاء مرتبط با مدلهای Post و Company در پایگاه داده postgreSQL وجود دارند، میتوان از دستورات زیر استفاده کرد:
با اجرای دستورات بالا، خروجی مانند شکل زیر در واسط خط دستوری نمایش داده خواهد شد:

همچنین، امکان استفاده از پرس و جوهای پیشرفتهتری با استفاده از دستورات SQL Join وجود دارد:

مهندسی داده در پایگاههای داده postgreSQL با کتابخانه Pandas
با استفاده از کتابخانه sqlalchemy (مجموعهای از ابزارها برای دستکاری پایگاههای داده رابطهای و نگاشت کننده مدل اشیاء به مدل رابطهای)، امکان دسترسی به اشیاء زبان SQL از طریق کتابخانه Pandas برای برنامهنویسان و توسعهدهندگان وب فراهم شده است.

با باز کردن یکی از «محیطهای توسعه یکپارچه» (Integrated Development Environment) زبان پایتون نظیر Jupyter Notebook و اجرای دستورات زیر، میتوان به راحتی به مدلهای پایگاه داده رابطهای دسترسی پیدا کرد:

بنابراین، با استفاده از کتابخانه sqlalchemy و امکانات بسیار پیشرفته و قدرتمند کتابخانه Pandas، هر نوع عملیاتی که برای تحلیل و مهندسی داده نیاز است، میتوان انجام داد. اگرچه دانش اولیه از پلتفرم Django برای توسعه تحت وب لازم نیست، با این حال، مسلط شدن به سازوکارهای تعریف شده در کتابخانه Django برای توسعه برنامههای کاربردی تحت وب و استفاده از کتابخانههای Pandas و sqlalchemy جهت دستکاری و دسترسی به مدلهای پایگاه داده postgreSQL، میتواند نقش مهمی در تثبیت جایگاه برنامهنویس به عنوان یک دانشمند داده مسلط به مفاهیم مهندسی داده داشته باشد.
کلام آخر
کتابخانه Django، یک کتابخانه تمام عیار برای توسعه برنامههای کاربردی تحت وب محسوب میشود که مجموعهای از کاملترین ابزارها و امکانات را برای توسعه مؤلفههای اساسی برنامههای کاربردی تحت وب در اختیار کاربران قرار میدهد.

همچنین، کتابخانه Django یک «واسط مدیریتی» (Administration Interface) در اختیار برنامهنویسان و توسعهدهندگان قرار میدهد که عملا نقش «واسط گرافیکی کاربری» (Graphical User Interface | GUI) برای پایگاه داده postgreSQL را ایفا میکند. تنها کاری که لازم است انجام شود این است که مجموعه کدهای زیر به فایل admin.py مدل Post اضافه شود:
و در مرحله بعد، یک superuser در واسط خط دستوری ایجاد شود:

بنابراین، قالب نهایی فایل settings.py در پوشه doublebagger_blog، به شکل زیر خواهد بود:
همچنین، قالب نهایی فایل models.py در پوشه post، بدین شکل نمایش داده خواهد شد:
کدهای کامل برنامه کاربردی تحت وب توسعه داده شده (DoubleBagger) از طریق لینک [+] قابل دسترسی است.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامهنویسی پایتون Python
- گنجینه آموزشهای برنامهنویسی پایتون (Python)
- مجموعه آموزشهای برنامهنویسی
- چگونه برنامهنویسی وب را شروع کنیم؟
- برنامه نویسی وب با پایتون — راهنمای کاربردی
- ترفندهای برنامهنویسی در پایتون — از صفر تا صد
- آموزش پایتون (Python) — مجموعه مقالات جامع وبلاگ فرادرس
^^










