


پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون
در مطلب پیاده سازی شبکه عصبی SOM در پایتون – راهنمای گام به گام به پیادهسازی شبکه عصبی SOM یا Self-Organizing Map پرداختیم که یک روش نظارتنشده (Unsupervised) بود و برای استخراج ویژگی استفاده میشود. در این مطلب قصد داریم پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون را بررسی کنیم. این شبکه یک الگوریتم نظارتشده (Supervised) است که میتواند برای اهداف مختلف از جمله رگرسیون (Regression) و طبقهبندی (Classification) استفاده شود.
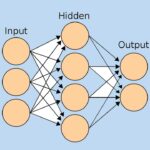


دانلود فایل پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون
با توجه به دشوار بودن مراحل پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون و امکان بروز خطا، فایلهای آماده آن در لینک زیر قابل دریافت هستند.
- برای دانلود فایل پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون + اینجا کلیک کنید.
پرسپترون چیست؟
پرسپترون (Perceptron) یک واحد مصنوعی است که براساس نورونهای (Neuron) مغز انسان طراحی شده است. در شکل زیر نمای کلی یک نورون طبیعی را مشاهده میکنید:
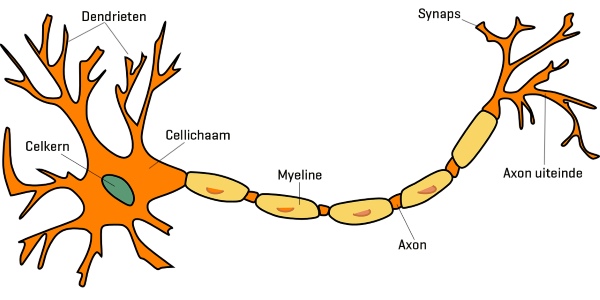
یک نورون دارای 3 بخش است:
- دندریتها (Dendrite): در این بخش، نورون سیگنال و پیامهایی را از نورونهای دیگر دریافت میکند.
- آکسونها (Axon): در این بخش، نورون سیگنال و پیام خود را به نورونهای دیگر انتقال میدهد.
- هسته (Nucleus): این بخش و سایر بخشهای موجود بین دندریت و آکسون در پردازش سیگنالها و پیامها نقش دارند.
ارتباط بین دو نورون توسط «سیناپس» (Synapse) برقرار میشود. این ارتباط، سیگنال نورون «پیشسیناپسی» (Pre-Synaptic) را به نورون «پسسیناپسی» (Post-Synaptic) انتقال میدهد.
براساس این موارد، نورونهای مصنوعی با الهام از نورونهای طبیعی در محیط کامپیوتر ایجاد شدند. در شکل زیر یک نورون مصنوعی یا پرسپترون را مشاهده میکنید:
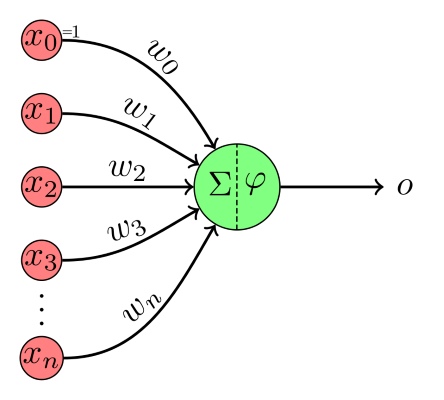
این پرسپترون به شکل زیر عمل میکند:
- در ورودی یک بردار از لایه قبل دریافت میشود.
- بردار در بردار که شامل وزن هر ورودی است، ضرب میشود. این وزنها نقش سیناپسها را ایفا میکنند.
- مقدار حاصل با یک عدد ثابت به نام بایاس که با نماد b نشان داده میشود، جمع میشود. توجه داشته باشید که در برخی موارد، بایاس را با نام در نظر میگیرند و ورودی متناظر با آن یعنی را همواره برابر با ۱ در نظر میگیرند.
- خروجی حاصل تا این مرحله را Z مینامیم و آن را وارد تابع میکنیم. این تابع با نام Activation Function یا تابع فعالسازی شناخته میشود.
- در نهایت مقدار به عنوان خروجی به لایه بعد داده میشود.
فرآیند گفته شده را میتوانیم به زبان ریاضی نیز بنویسیم:
در این رابطه، بردار وزنهای بین لایه قبل و نورون موجود در لایه فعلی است. بردار نیز بردار خروجی لایه قبل را نشان میدهد. b یک عدد بوده و بایاس را نشان میدهد. توجه داشته باشید که برآیند سیگنال ورودی به نورون را نشان میدهد یک ترکیب خطی از سیگنال خروجی لایه قبلی است.
به این ترتیب میتوان نورونهای مصنوعی را به کمک روابط ریاضیاتی توصیف کرد. یک پرسپترون به تنهایی دارای ظرفیت یادگیری (Learning Capacity) محدودی است. از این رو شبکهای از پرسپترونها را ایجاد میکنیم تا به ظرفیت یادگیری مورد نیازمان دست یابیم.
نورونها میتوانند به صورت موازی در کنار هم قرار گیرد و یک لایه را ایجاد کنند. در حالت دیگر نیز نورونها میتوانند به صورت متوالی پشت سر هم در لایههای مختلف قرار گیرند. بسته به ماهیت مسئله، به هر کدام از این حالتها نیاز داریم.
پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون
برای پیادهسازی شبکه، وارد محیط برنامهنویسی میشویم و کتابخانههای مورد نیاز را فراخوانی میکنیم:
کتابخانه Numpy به منظور محاسبات ریاضیاتی شبکه و ذخیره وزنها مناسب است.
کتابخانه Matplotlib نیز برای مصورسازی (Visualization) مجوعه داده (Dataset) و نمایش نتایج شبکه عصبی استفاده خواهد شد.
ایجاد کلاس
برای پیادهسازی مدل، از کلاسها (Class) استفاده خواهیم کرد. کلاس مربوط به پرسپترون تک لایه را ایجاد میکنیم:
متد سازنده
در اولین قدم از پیادهسازی کلاس مورد نظر، متد (Method) سازنده را تعریف میکنیم. این متد در ورودی تعداد نورون لایه پنهان (Hidden Layer) و تابع فعالسازی این لایه را دریافت میکند:
توجه داشته باشید که چون در این مطلب قصد داریم از شبکه برای رگرسیون استفاده کنیم، تابع فعالسازی لایه آخر حتماً خطی (Linear) خواهد بود، بنابراین نیاز نیست برای این لایه نیز متغیری جداگانه تعریف کنیم.
حال تعداد نورونهای لایه مخفی را در شی ذخیره میکنیم:
حال باید تابع فعالسازی را بررسی کنیم. برای این شبکه قصد داریم تو تابع فعالسازی ReLU یا Rectified Linear Unit و Leaky-ReLU یا Leaky Rectified Linear Unit را اضافه کنیم. این دو تابع فعالسازی به شکل زیر تعریف میشود:
برای Leaky-ReLU اغلب ضریب برابر با تنظیم میشود. نمودار این دو تابع به شکل زیر است:
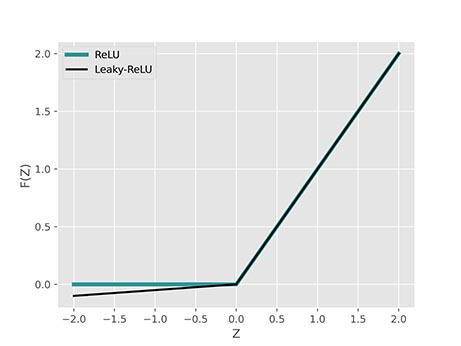
توجه داشته باشید که تابع Leaky-ReLU به دلیل داشتن مشتق غیرصفر برای ورودیهای منفی، میتواند باعث یادگیری سریعتر شبکه شود.
دو تابع فعالسازی را میتوانیم با اندکی تغییر در صورت معادله، به شکل زیر نیز تعریف کنیم:
به این ترتیب با یک ضابطه نیز میتوانیم آنها را توصیف کنیم. حال تابع فعالسازی را نیز با استفاده از lambda تعریف میکنیم:
برای آموزش شبکه عصبی، نیاز به مشتق توابع فعالسازی نیز داریم. به این منظور میتوانیم مشتق هر تابع را نیز محاسبه کنیم. در این صورت روند محاسبه به شکل زیر خواهد بود:
توجه داشته باشید که تنها معلوم موجود یعنی خروجی نورون است. به دلیل هزینهبر بودن محاسبه ورودی و تبدیل آن به مشتق، از یک تکنیک استفاده میکنیم. تابعی را تعریف میکنیم که با گرفتن در ورودی، مقدار را در خروجی برگرداند:
به این ترتیب حجم محاسبات کاهش خواهد یافت. برای دو تابع فعالسازی گفته شده در فوق، تابع به شکل زیر است:
به این ترتیب این دو تابع میتوانند مشتق خروجی نورون را با داشتن مقدار خروجی محاسبه کنند. این دو تابع را نیز به متد سازنده اضافه میکنیم:
به این ترتیب متد سازنده کامل میشود.
متد ایجاد پارامترها در پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون
در شروع آموزش مدل برای پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون، نمیتوانیم در مورد مقادیر پارامترها (Parameter) اظهار نظر کنیم، به همین دلیل در ابتدای مسئله از مقادیر تصادفی به عنوان مقادیر پارامترها استفاده میکنیم. این متد بعد از فراخوانی، 4 آرایه برای وزنها و بایاسها ایجاد خواهد کرد:
توجه داشته باشید که بین لایه ورودی (Input Layer) و لایه پنهان (Hidden Layer) یک مجموعه وزن وجود دارد که با نام آنها میشناسیم. بین لایه پنهان و لایه خروجی (Output Layer) نیز مجموعه دیگری از وزنها وجود دارد که با نام میشناسیم. به جز وزنها، دو آرایه برای بایاسها نیز داریم. برای هر دو لایه پنهان و خروجی، دو آرایه با نامهای و خواهیم داشت که مقادیر بایاس را در خود ذخیره خواهند کرد.
برای مقداردهی اولیه (Initialization) همه این پارامترها، از اعداد تصادقی (Random) با توزیع یکنواخت (Uniform) در بازه استفاده میکنیم. مقداردهی اولیه وزنهای شبکههای عصبی، مقوله مفصلی بوده و در این زمینه مطالعات فراوانی انجام شده است. بسته به نوع مدل (Model) و پیچیدگی آن، میتوان از روشهای مختلفی استفاده کرد.
در مورد ابعاد این آرایهها نیز باید به نکات زیر توجه کرد:
- آرایههای وزن ارتباط بین دو لایه از شبکه را توصیف میکنند، بنابراین باید دو بُعدی باشند.
- آرایههای بایاس مربوط نورونهای یک لایه هستند، بنابراین باید یک بُعدی باشند.
- سایز اولین بُعد هر آرایه وزن برابر با تعداد نورون لایه مبدأ است.
- سایز دومین بُعد هر آرایه وزن برابر با تعداد نورون لایه مقصد است.
- سایز هر آرایه بایاس برابر با تعداد نورون لایه مربوط است.
توجه داشته باشید که تعداد ورودیهای شبکه برابر با تعداد خروجیهای لایه ورودی است و داخل کد با مقدار self.nX نشان داده خواهد شد. تعداد خروجیهای شبکه نیز برابر با تعداد خروجیهای لایه خروجی است و داخل کد با مقدار self.nY نشان داده خواهد شد. این دو متغیر داخل متد Fit تعریف خواهند شد.
متد انتشار رو به جلو
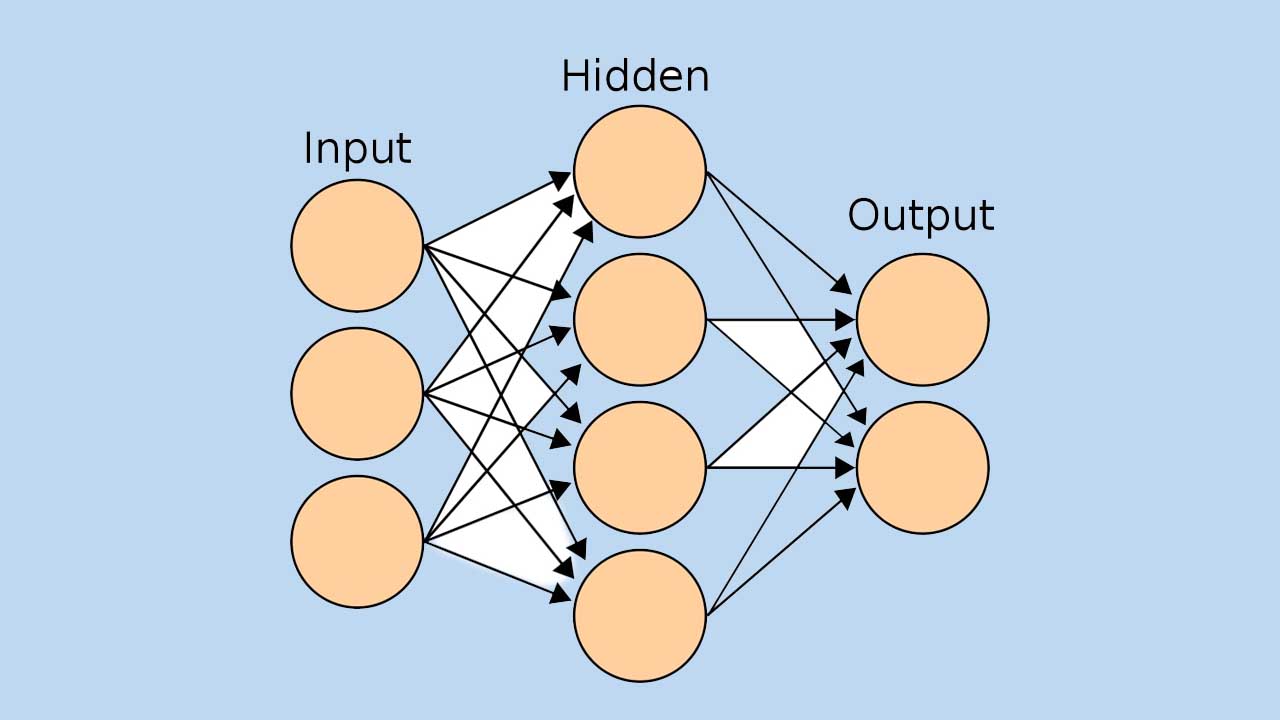
شبکه عصبی، با دریافت یک بردار در لایه ورودی، به ترتیب مقدار خروجی هر لایه را تا انتها به ترتیب محاسبه میکند تا خروجی نهایی مدل حاصل شود. به عبارتی اطلاعات ورودی رو به جلو حرکت میکنند. به این فرآیند انتشار رو به جلو (Forward Propagation) گفته میشود. در شکل زیر مسیر انتشار اطلاعات نشان داده شده است:
حال متدی برای انجام این فرآیند ایجاد میکنیم. این متد در ورودی بردارهای داده را دریافت خواهد کرد:
حال میتوانیم سیگنال ورودی به هر نورون لایه پنهان را محاسبه کنیم:
با اعمال تابع فعالسازی به Z1 میتوانیم خروجی لایه پنهان را به دست آوریم:
حال میتوانیم سیگنال ورودی به نورونهای لایه خروجی را محاسبه کنیم:
لایه خروجی، از تابع فعالسازی خطی استفاده میکند که همانی (Identity) است. بنابراین ورودی دریافت شده را بدون تغییر در خروجی برمیگرداند. بنابراین خواهیم داشت:
توجه داشته باشید که برای فرآیند آموزش مدل، نیاز به خروجی تمامی لایهها داریم، بنابراین خروجی هر دو لایه را در خروجی برمیگردانیم. توجه داشته باشید که این متد در خروجی دو آرایه برمیگرداند که هر دو داخل یک تاپل (Tuple) قرار گرفتهاند.
به این ترتیب این متد میتواند انتشار رو به جلو را انجام دهد.
متد پس انتشار خطا
پس از ایجاد مدل، نیاز داریم تا آن را بر روی مجموعه داده آموزش دهیم. به این منظور از «قانون دلتا» (Generalized Delta Rule | GDR) استفاده میکنیم. این روش خطای حاصل در خروجی شبکه را در عکس جهت انتشار میدهد. (Error Backpropagation) و به این وسیله میزان و جهت تغییرات هر پارامتر را محاسبه میکند. اگر بردار در ورودی شبکه وارد شود و خروجی هدف بردار باشد، برای یک پرسپترون تک لایه، خواهیم داشت:
در این روابط نشاندهنده «نرخ یادگیری» (Learning Rate) است.
روابط فوق مقدار بهروزرسانی هر وزن را نشان میدهد. توجه داشته باشید که فرم کلی عبارت مشابه یکدیگر است و از مفاهیم یکسانی استنباط شدهاند.
شمارنده نشاندهنده نورون شماره در لایه ورودی است. شمارندههای و نیز به ترتیب شماره نورون در لایه پنهان و لایه خروجی را نشان میدهند.
با توجه به اینکه ورودی بایاسها همواره 1 است، مقادیر بهروزرسانی آنها نیز به شکل زیر است:
به این ترتیب تمامی روابط مورد نیاز برای بهروزرسانی پارامترها را داریم.
حال متد پس انتشار خطا را پیادهسازی میکنیم. در ورودی این متد دو بردار و را دریافت میکنیم:
حال با فراخوانی متد fPropagate خروجی هر لایه را محاسبه میکنیم:
حال روابط گفته شده را در 4 بخش پیادهسازی میکنیم:
به این ترتیب این متد خواهد توانست با دریافت و متناظر با یکدیگر، پارامترهای شبکه را برای یک گام بهروزرسانی کند.
توجه داشته باشید که عبارت که در کد با نام dj شناخته میشود را با استفاده از numpy.inner محاسبه میکنیم که همان عمل Summation موجود در فرمول را انجام میدهد.
متد آموزش مدل
متد bPropagate تنها برای یک داده و یک مرحله مدل را آموزش میدهد. باید متد دیگری تعریف کنیم که با دریافت کل مجموعه داده، به دفعات مشخص مدل را آموزش دهد. این متد در ورودی مجموعهای از بردارهای ورودی، مجموعهای از بردارهای خروجی، تعداد مراحل آموزش مدل و نرخ یادگیری را دریافت خواهد کرد:
حال در اولین قدم، تعداد مراحل و نرخ یادگیری را در شی ذخیره میکنیم:
حال باید تعداد ورودی و تعداد خروجی شبکه را ذخیره کنیم:
به این ترتیب ابعاد شبکه ذخیره خواهد شد.
در طول آموزش مدل، خطای مدل کاهش مییابد، به منظور نمایش این فرآیند در قالب یک نمودار، آرایهای خالی برای ذخیره خطاها در انتهای هر مرحله ایجاد میکنیم:
با توجه به اینکه قصد داریم قبل از شروع آموزش مدل نیز خطای آن را ذخیره کنیم، طول آرایه به اندازه 1 واحد بیشتر از تعداد کل مراحل خواهد بود. حال مقداردهی اولیه وزنها را انجام میدهیم:
قبل از شروع آموزش مدل، یک بار پیشبینی مدل را دریافت میکنیم و خطای NRMSE یا Normalized Root Mean Squared Error را محاسبه میکنیم. این معیار به شکل زیر محاسبه میشود:
برای آشنایی با NRMSE و سایر معیارهای ارزیابی رگرسیون، میتوانید به مطلب بررسی معیارهای ارزیابی رگرسیون در پایتون – پیاده سازی + کدها مراجعه کنید.
به این منظور خواهیم داشت:
حال خطای حاصل را ذخیره میکنیم و آن را در خروجی نمایش میدهیم:
حال میتوانیم حلقه مربوط به آموزش مدل را ایجاد کنیم. این حلقه به تعداد nEpoch تکرار خواهد شد:
در هر مرحله از آموزش، به ازای هر داده یک بار متد bPropagate را فرامیخوانیم:
به این ترتیب آموزش مدل کامل خواهد شد. برای بررسی خطا در انتهای هر مرحله نیز بار دیگر NRMSE را محاسبه میکنیم:
به این ترتیب مقادیر خطا در طول آموزش نمایش داده خواهد شد، همچنین در آرایه self.Log نیز ذخیره میشود.
متد پیش بینی
تا به اینجا توانستیم متدهای مورد نیاز برای ایجاد و آموزش مدل را پیادهسازی کنیم. متد دیگری نیز نیاز داریم تا پس از آموزش مدل، با وارد کردن مجموعه داده جدید، خروجی را برای آن مجموعه داده نیز داشته باشیم. این متد را با نام Predict میشناسیم و در ورودی آرایه X را دریفات خواهد کرد و در خروجی تنها خروجی نهایی مدل را برخواهد گرداند:
توجه داشته باشید که متد fPtopagate نیز کار مشابهی را انجام میدهد اما به دلیل سهولت در استفاده کاربر، از این حالت استفاده میکنیم.
به این ترتیب تمامی متدهای مورد نیاز برای شبکه عصبی پیادهسازی شده و آماده استفاده هستند.
ایجاد مجموعه داده
برای بررسی عملکرد شبکه عصبی پیادهسازی شده، نیاز به یک مجموعه داده داریم. به این منظور ابتدا تنظیمات زیر را در ابتدای کد اعمال میکنیم:
حال یک مجموعه داده مصنوعی (Synthetic Dataset) با ضابطه زیر ایجاد میکنیم:
برای ایجاد مقادیر را به صورت تصادفی از بازه انتخاب میکنیم:
مقادیر نیز مطابق با ضابطه آورده شده، به شکل زیر محاسبه میشود:
حال میتوانیم مجموعه داده ایجاد شده را نمایش دهیم. به این منظور از Scatter Plot موجود در کتابخانه Matplotlib استفاده میکنیم:
در خروجی کد فوق، نمودار زیر حاصل میشود:
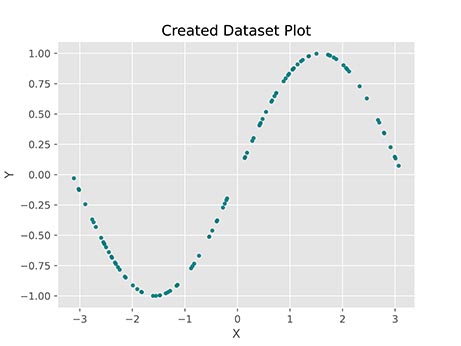
مشاهده میکنیم که نقاطی تصادفی از نمودار سینوسی انتخاب میشود.
ایجاد و آموزش مدل
حال میتوانیم یک شی از کلاس نوشته شده ایجاد کنیم:
به این ترتیب یک پرسپترون تک لایه با 20 نورون ایجاد میشود. تابع فعالسازی این نورونها Leaky-ReLU است.
حال میتوانیم مدل را بر روی مجموعه داده ایجاد شده آموزش دهیم:
به این ترتیب مدل با نرخ یادگیری برابر با 0.001 به تعداد 300 مرحله بر روی مجموعه آموزش میبیند.
پس از اجرای کد فوق، نتایج به شکل زیر نمایش داده میشود:
به این ترتیب مشاهده میکنیم که مدل قبل از شروع آموزش و با وزنهای تصادفی انتخاب شده، دارای خطای ۵۰۷ درصد بوده و تنها با یک مرحله آموزش توانسته این خطا را به ۴۱ درصد کاهش دهد. اغلب بهبود عملکرد مدل، برای گامهای ابتدایی آموزش بیشتر است. در مراحل انتهایی، خطای مدل از ۳٫۲۶ درصد به ۳٫۲۴ درصد کاهش یافته است که نشان از همگرایی مدل و بهبودهای اندک دارد.
بررسی خطا در طول آموزش
در طول آموزش مدل، آرایه self.Log نیز کامل میشود. برای مشاهده این خطاها میتوانیم کد زیر را بنویسیم:
در خروجی کد فوق یک آرایه به شکل زیر نمایش داده خواهد شد:
به این ترتیب این آرایه نیز به درستی پر شده است. حال میتوانیم نمودار این آرایه را رسم کنیم:
توجه داشته باشید که آرایه T شامل شماره مراحل است و به دلیل اینکه اولین خطا مربوط به خطای قبل از آموزش است، بهتر است اولین مقدار این آرایه 0 باشد. پس از اجرای کد فوق، نمودار زیر حاصل میشود:
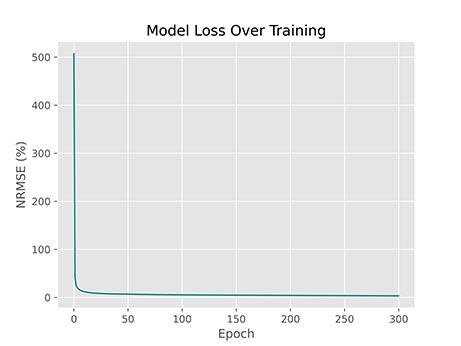
به این ترتیب نمودار حاصل میشود. اما این نمودار مشکلاتی دارد. برای مثال بهبود عملکرد از مرحله 10 به بعد چندان واضح مشاهده نمیشود. این مشکل حاصل از تغییرات شدید در مراحل اولیه آموزش است. میتوان با لگاریتمی کردن مقیاس محور عمودی، این مشکل را رفع کرد. به این حالت، نمودار نیمه-لگاریتمی (Semi-Logarithm) گفته میشود. به این منظور از matplotlib.pyplot.yscale استفاده میکنیم:
حال پس از اجرای دوباره، نمودار به شکل زیر خواهد بود:
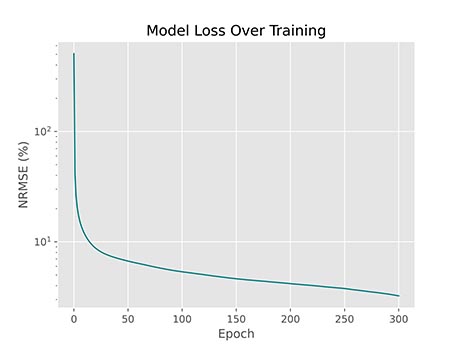
به این ترتیب مشاهده میکنیم که این نمودار بهبود خطا را بهتر نشان میدهد. در بازه بین مراحل 50 تا 250، یک خط صاف داریم. با توجه به اینکه محور افقی لگاریتمی است، میتوان گفت سرعت بهبود برابر با لگاریتم است. در بازه مراحل 0 تا 50 نیز نمودار کاهشی شدیدتر از خط صاف دارد بنابراین میتوان گفت در این بازه، سرعت بهبود مدل بیشتر از لگاریتم است.
رسم نمودار پیشبینی
میتوانیم خروجی حاصل را در مقابل نمودار سینوسی رسم کنیم و شباهت این دو نمودار به یکدیگر را بررسی کنیم. به این منظور ابتدا 201 نقطه با فاصله یکسان در بازه انتخاب میکنیم و مقدار تابع سینوسی برای این نقاط را محاسبه میکنیم:
حال میتوانیم با استفاده از متد Predict، پیشبینیهای مدل برای این نقاط را نیز محاسبه کنیم:
در نهایت میتوانیم نقاط داده، تابع سینوسی و پیشبینی مدل برای این تابع را رسم کنیم:
به این ترتیب دو منحنی و یک مجموعه نقطه در نمودار نهایی خواهیم داشت. پس از اجرای کد فوق، نمودار زیر حاصل میشود:
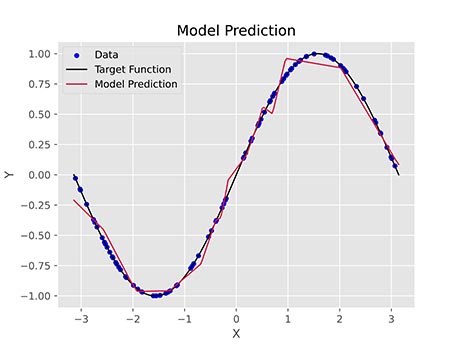
به این ترتیب مشاهده میکنیم که مدل توانست در اغلب موارد پیشبینی نزدیک به واقعیت داشته باشد. در برخی بازهها نیز عملکرد مدل چندان خوب نبود است. با تنظیم هایپرپارامترهای (Hyperparameter) مدل و تغییر شرایط ابتدایی مسئله، میتوان این مشکل را حل کرد.
اگر همین مدل را با 15 نورون، به تعداد 1000 مرحله با نرخ یادگیری 0.002 آموزش دهیم، خطای مدل به ۱٫۰۱ درصد کاهش مییابد و نمودار نهایی به شکل زیر خواهد بود:
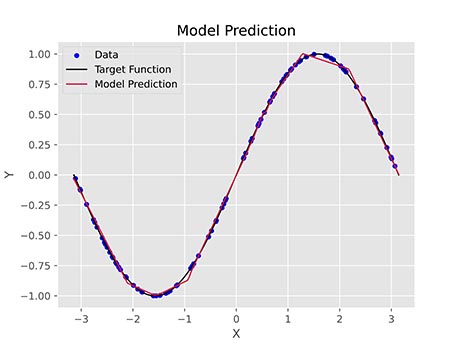
به این ترتیب مشاهده میکنیم که مدل به نتایج بهتری دست یافته است.
اگر همین مسئله را با 15 نورون ReLU به تعداد 1000 مرحله با نرخ یادگیری 0.002 آموزش دهیم، خطای نهایی ۱٫۹۱ درصد خواهد بود و نمودار زیر حاصل خواهد شد:
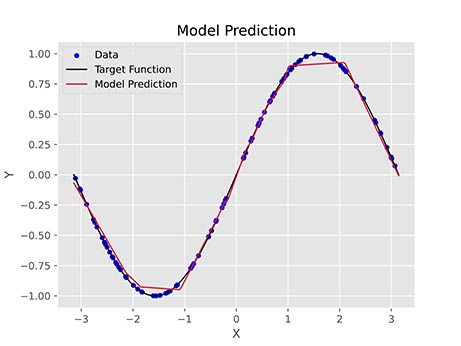
مشاهده میکنیم که در شرایطی یکسان، تابع فعالسازی ReLU عملکرد بدتری نسبت به Leaky ReLU داشته است که با توجه به توضیحات گفته شده، قابل توجیه است.
توجه داشته باشید که نرخ یادگیری هایپرپارامتر بسیار مهمی است و تنظیم آن در بسیاری از مسائل نیاز است. مقدار کم آن باعث میشود مدل نتواند به نقاط بهینه بهتر دست یابد. مقادیر بالای آن نیز باعث میشود مدل واگرا (Diverge) شود که هر دو مورد از این حالات مناسب نیست. برای مثال شکل زیر خطای مدلی با 15 نورون Leaky ReLU است که با نرخ یادگیری 0.03824 آموزش دیده است:
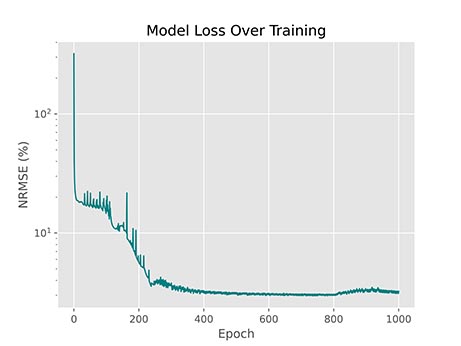
مشاهده میکنیم که روند آموزش این مدل پرنوسان بوده و دارای ثبات نیست.
به این منظور بهتر است نرخ یادگیری در ابتدای یادگیری مدل از یک مقدار بزرگ شروع شود و در طول مراحل آموزش مقدار آن کاهش یابد.
به این ترتیب آموزش مدل و تاثیر پارامترهای مختلف را بر روی آن مشاهده کردیم.
آموزش مدل با ورودی و خروجیهای دارای ابعاد بالاتر
مجموعه داده ایجاد شده، دارای تنها یک ورودی و یک خروجی بود. کد نوشته شده قابلیت پشتیبانی از چندین ورودی و چندین خروجی را دارد. به این منظور در کد دیگری، مجموعه داده جدیدی با ضوابط زیر تولید میکنیم:
به این ترتیب سه ورودی و دو خروجی خواهیم داشت. 300 داده به این ضوابط تولید میکنیم:
حال میتوانیم نمودار این مجموعه داده را رسم کنیم. با توجه به اینکه 3 متغیر مستقل و 2 متغیر وابسته داریم، 6 نمودار قابل رسم خواهد بود:
پس از اجرای این کد، نمودار زیر حاصل خواهد شد:

به این ترتیب توزیع دادهها و همبستگی بین آنها مشخص میشود.
حال یک شبکه عصبی ایجاد میکنیم و آن را آموزش میدهیم:
در اجرای کد فوق، خطای برگردانده میشود. این خطا به دلیل روش محاسبه NRMSE است. با توجه به اینکه در کد قبلی تنها یک خروجی داشتیم، مقدار NRMSE نیز یک عدد بود اما با افزایش تعداد خروجیهای مدل، باید به یک بردار تبدیل شود، به همین دلیل، کد مربوط به متد Fit را به شکل زیر تغییر میدهیم:
نکاتی از کد که باید توجه شود:
- با توجه به اینکه به تعداد self.ny خروجی وجود دارد، آرایه self.Log را به شکل دوبعدی با ابعاد تعریف میکنیم.
- ماتریس خطا و ماتریس مربعات خطا دو بعدی است. برای میانگینگیری از این ماتریس، از تابع mean استفاده میکنیم، اما این عملیات باید برای هر خروجی یا ستون جداگانه انجام شود. به همین دلیل ورودی axis=0 را برای این تابع در نظر میگیریم.
- برای محاسبه NRMSE باید RMSE بر Range متغیر هدف تقسیم شود. این فاصله برابر با اختلاف بزرگترین و کوچکترین مقدار است. به همین دلیل متدهای min و max استفاده شود. اما به دلیل اینکه ماتریس Y دارای بیشتر از 1 ستون است، باید برای این متد نیز ورودی axis=0 تعیین شود.
- در انتهای هر مرحله نیز مقدار خطا نمایش داده شد. با توجه به اینکه مقدار NRMSE آرایه است، باید از تابع numpy.round برای گرد کردن مقادیر استفاده کنیم.
با تغییر کد و اجرای دوباره، خطا رفع شده و به درستی اجرا میشود.
حال میتوانیم نمودار خطا را برای هر دو خروجی به صورت جداگانه رسم کنیم:
در خروجی این کد، نمودار زیر حاصل میشود:
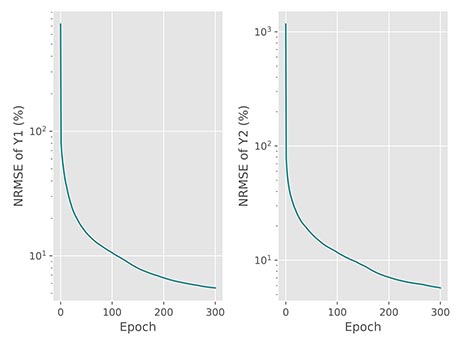
به این ترتیب مشاهده میکنیم که برای هر خروجی یک نمودار ایجاد شده است و هر دو نمودار نزولی است. مدل در انتهای آموزش، برای هر دو خروجی خطایی نزدیک به ۵٫۵ درصد دارد که مقدار مناسبی است. برای مدلهایی با خروجیهای بیشتر، میتوان میانگین NRMSE ها را بررسی کرد.
برای رسم عملکرد مدل نیز میتوانیم دو نمودار دیگر رسم کنم. به این منظور از Scatter Plot استفاده میکنیم و مقادیر پیشبینی را در مقابل مقادیر واقعی نمایش میدهیم:
در خروجی این کد نمودار زیر حاصل میشود:
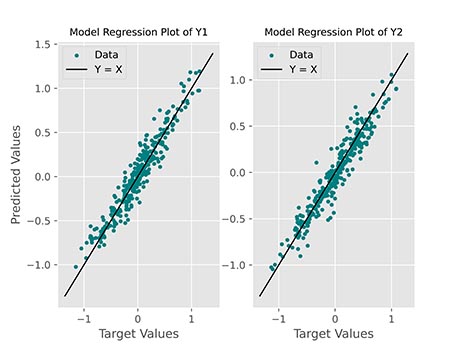
مشاهده میکنیم که برای هر دو خروجی، مقادیر به خوبی در اطراف خط قرار گرفتهاند.
میتوان مقادیر یا ضریب تعیین را نیز محاسبه و در این نمودار نمایش داد:
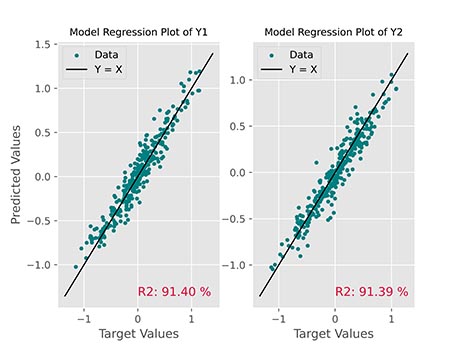
به این ترتیب نمودار اطلاعات جامعتری در رابطه با عملکرد مدل انتقال خواهد داد. برای رسم نمودار فوق، از کد زیر استفاده شده است:
برای محاسب امتیاز از رابطه زیر استفاده شده است:
پارامترهایهای نهایی در پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون
در انتهای آموزش مدل، میتوان پارامترهای نهایی را نیز مورد بررسی قرار داد، با کد زیر میتوانیم تعداد و ابعاد هر مجموعه پارامتر را بررسی کرد:
در خروجی کد فوق نتایج زیر را خواهیم داشت:
به این ترتیب مشاهده میکنیم که بایاسها دارای یک بُعد و وزنها دارای دو بُعد هستند. عدد 3 موجود در ابعاد از 3 ورودی شبکه، مقدار 2 از 2 خروجی شبکه و مقدار 40 نیز از 40 نورون لایه مخفی نشأت میگیرد.
مصورسازی وزنها در پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون
میتوان مقادیر وزنها را نیز به شکل نمودار هسیتوگرام (Histogram) نمایش داد. به این منظور تعداد داده را به 500 افزایش میدهیم، سپس یک شبکه عصبی با 60 نورون Leaky ReLU ایجاد میکنیم و آن را 1000 مرحله با نرخ یادگیری 0.0002 آموزش میدهیم. سپس کد زیر را اجرا میکنیم:
توجه داشته باشید که آرایه Parameters شامل تمامی پارامترها است. در نتیجه اجرای کد فوق، نمودار زیر حاصل میشود:
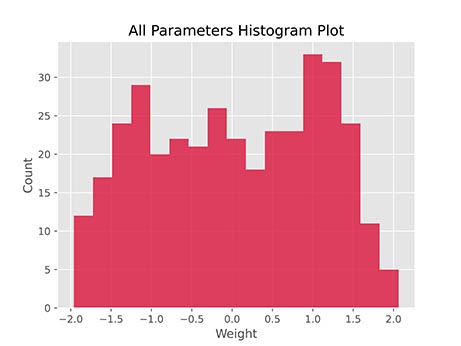
به این ترتیب مشاهده میکنیم که توزیع مقادیر با توزیع یکنواخت متفاوت است، بنابراین میتوان از این اطلاعات برای مقداردهی اولیه وزنها نیز استفاده کرد. این نمودار قبل از شروع آموزش مدل، به شکل زیر بوده است:
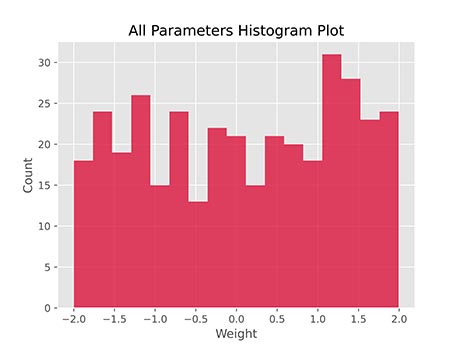
بنابراین میتوان به این نتیجه رسید که این تغییر در توزیع معنادار است.
جمعبندی پیاده سازی شبکه عصبی پرسپترون یک لایه در پایتون
به این ترتیب پیادهسازی شبکه عصبی پرسپترون تک لایه به اتمام میرسد. برای مطالعه بیشتر میتوان موارد زیر را بررسی کرد:
- چگونه میتوان تعداد نورون بهینه را پیدا کرد؟
- چگونه میتوان از بیشبرازش (Overfitting) مدل پیادهسازی شده مطلع شد؟
- اگر به جای استفاده از توزیع یکنواخت برای مقداردهی اولیه وزنها، از توزیع نرمال (Normal Distribution) استفاده کنیم، سرعت همگرایی و نتایج چگونه تغییر خواهد کرد؟
- تابع سیگموئید (Sigmoid) را نیز به توابع فعالسازی کلاس ایجاد شده اضافه کنید. تابع برای این تابع به چه شکل خواهد بود؟
- اگر بخواهیم پرسپترون دو لایه (Double Layer Perceptron) پیادهسازی کنیم، معادلات بهروزرسانی وزنها به چه شکل خواهد بود؟
- قانون دلتا (Delta Rule) چیست؟ این قانون چه مفهومی را نشان میدهد؟
- اگر بخواهیم کد نوشته شده را برای طبقهبندی استفاده کنیم، چه تغییراتی باید در آن اعمال کنیم؟
- حلقههای نوشته شده در متد bPropagate را با استفاده از محاسبات برداری سادهتر کنید. این فرآیند هزینه محاسباتی را تا چه اندازه کاهش میدهد؟
- در کتابخانههای آماده برای یادگیری عمیق، از مفهومی به نام Batch برای هر بار بهروزرسانی وزنها استفاده میشود. این مفهوم چه مزیتی دارد؟
- برای مجموعه داده ابتدایی، در طول آموزش مدل، برای هر مرحله نمودار رگرسیون را رسم و ذخیره کنید. با ایجاد GIF روند بهبود عملکرد مدل را نمایش دهید.








