
ماشین لرنینگ چیست؟ – راهنمای یادگیری تخصص یادگیری ماشین
امروزه «هوش مصنوعی» (Artificial Intelligence | AI) در بیشتر حوزههای صنعت و حتی زندگی روزمره کاربرد دارد و یادگیری آن میتواند کمک بسزایی در پیشرفت فناوریهای جدید داشته باشد. «ماشین لرنینگ» یا «یادگیری ماشین» (Machine Learning | ML) یکی از بخشهای هوش مصنوعی به حساب میآید که باید برای کار در این حوزه فراگرفته شود. ماشین لرنینگ به سیستم توانایی یادگیری خودکار و بدون برنامهریزی صریح را میدهد. به عبارت دیگر، هدف ماشین لرنینگ ساخت سیستمهای هوشمندی است که با استفاده از مجموعهای از دادهها و تجربیات به دست آمده، به یادگیری بپردازند و بتوان از آنها برای هوشمندسازی سیستمها استفاده کرد. در این مطلب ابتدا به این سوال پاسخ داده میشود که ماشین لرنینگ چیست و سپس به سایر مباحث مهم پیرامون یادگیری ماشین پرداخته شده است.




فرآیند یادگیری در ماشین لرنینگ با دادههایی به عنوان ورودی آغاز میشود، تا ماشین با بهرهگیری از آنها به الگوهای موجود در آن مجموعه داده دست پیدا کند و بر اساس کشف الگوهای آنها و بینش حاصل شده، تصمیمات بهتری بگیرد. در واقع، هدف اصلی در این علم، این است که به ماشین امکانی داده شود که بدون دخالت و کمک انسان، به طور خودکار یادگیری داشته باشد و بتواند اقدامات خود را مطابق با آن تنظیم کند. همچنین، ماشین لرنینگ به عنوان یک واحد درسی اصلی در گرایش هوش مصنوعی کارشناسی ارشد مهندسی کامپیوتر و برخی دیگر از گرایشهای مرتبط به آن تدریس میشود و از اهمیت بالایی برخوردار است.
ماشین لرنینگ چیست ؟
ماشین لرنینگ شاخهای از هوش مصنوعی و «علوم کامپیوتر» (Computer Science) است که در استفاده از دادهها و الگوریتمها برای تقلید از روشهای یادگیری انسانها تمرکز دارد و به تدریج دقت خود را بالا میبرد. یادگیری ماشین یکی از موًلفههای مهم حوزه رو به رشد علم داده به حساب میآید. ماشین لرنینگ توسط «Arthur Samuel»، یک دانشمند کامپیوتر در شرکت IBM و پیشگام در هوش مصنوعی و بازیهای کامپیوتری اختراع شده است. در این حوزه، دادهها از طریق استفاده از روشهای آماری، الگوریتمهای یادگیری ماشین برای «دستهبندی» (Classification) و «پیشبینی» (Prediction) «آموزش» (Train) داده میشوند و روشهای کلیدی را در پروژههای «داده کاوی» (Data Mining) به وجود میآورند.
پیش از ادامه این مبحث لازم است یادآور شویم که میتوانید Machine Learning را با استفاده از مجموعه آموزش یادگیری ماشین یا ماشین لرنینگ، مقدماتی تا پیشرفته فرادرس یاد بگیرید.

روشهای یادگیری ماشین روی تصمیمگیری در برنامهها، کسب و کارها و معیارهای رشد کلیدی تاًثیر بسزایی میگذارند. از آنجا که روشهای مختلف ماشین لرنینگ روز به روز در حال افزایش هستند، موقعیتهای شغلی بسیاری نیز برای متخصصین آن ایجاد میشوند و یادگیری این حوزه کمک بسیاری در یافتن یک شغل ایدهآل به افراد میکند. الگوریتمهای ماشین لرنینگ از دادههای قدیمیتر به عنوان ورودی برای پیشبینی مقدار خروجی جدید استفاده میکنند. در یادگیری ماشین میتوان با استفاده از الگوریتمهای مختلف با هدف شناسایی الگوها و آموزش سیستم با استفاده از حجم زیادی از دادهها در طی یک فرایند تکراری اطلاعات مفیدی را بدست آورد.
الگوریتمهای ماشین لرنینگ از روشهای محاسباتی و آماری برای یادگیری مستقیم از دادهها به جای استفاده از معادله از پیش تعیین شدهای استفاده میکنند که ممکن است مانند یک مدل عمل کند. کارایی الگوریتمهای ماشین لرنینگ با افزایش تعداد نمونهها و دادهها در طول فرآیند یادگیری بهبود مییابند. برای مثالی در این زمینه، «یادگیری عمیق» یا همان «یادگیری عمیق» (Deep learning) زیرمجموعهای از یادگیری ماشین است که کامپیوترها را برای تقلید از ویژگیهای انسان آموزش میدهد. یادگیری عمیق پارامترهای عملکردی بهتری را نسبت به الگوریتمهای ماشین لرنینگ معمولی ارائه داده است.
اگرچه یادگیری ماشین مفهوم جدیدی نیست و خلق «ماشین انیگما» (Enigma Machine) در دوران جنگ جهانی دوم را هم میتوان به نوعی یادگیری ماشین تلقی کرد، اما ماشین لرنینگ به عنوان توانایی انجام محاسبات پیچیده ریاضی به صورت خودکار برای انواع دادههای مختلف پیشرفتی نسبتاً جدید به حساب میآید.
مثال های کاربردی ماشین لرنینگ چیست؟
امروزه با افزایش «کلان دادهها» (Big Data)، «اینترنت اشیا» (Internet of Things | IoT)، «محاسبات فراگیر» (Ubiquitous Computing) و سایر موارد مشابه، ماشین لرنینگ به امری ضروری برای حل مسائل در بسیاری از زمینهها تبدیل شده است. در ادامه برخی از زمینههای کاربردی ماشین لرنینگ فهرست شدهاند:
- «محاسبات مالی» (Computational Finance): این حوزه به مسائلی از جمله «رتبهبندی اعتبار» (Credit Scoring) و «معاملات الگوریتمی» (Algorithmic Trading) ارتباط دارد.
- «بینایی ماشین» (Computer Vision): در این حوزه به زمینههایی مانند «تشخیص چهره» (Facial Recognition)، «ردیابی حرکت» (Motion Tracking) و «تشخیص شیء» (Object Detection) پرداخته میشود.
- «زیستشناسی محاسباتی» (Computational Biology): به عنوان مثالهایی از این حوزه میتوان به «توالییابی دیانای» (DNA Sequencing)، «تشخیص تومور مغزی» (Brain Tumor Detection) و «دارو پژوهی» (Drug Discovery) اشاره کرد.
- «خودروسازی» (Automotive)، «هوافضا» (Aerospace) و «تولید» (Manufacturing ): در این حوزه به مواردی مانند «نگهداری و تعمیرات قابل پیشبینی» (Predictive Maintenance) پرداخته میشود.
- «پردازش زبان طبیعی» (Natural Language Processing | NLP): به عنوان مثالی در این زمینه میتوان به «تشخیص صدا» (Voice Recognition) پرداخت.

در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی علت مهم بودن ماشین لرنینگ پرداخته میشود.
چرا ماشین لرنینگ مهم است؟
ماشین لرنینگ به این دلیل مهم است که باعث میشود سازمانها در پروژههایشان بینشی از روند رفتار مشتری و الگوهای عملیاتی خود به دست آورند و همچنین میتوان از یادگیری ماشین برای توسعه محصولات جدید استفاده کرد. همچنین از توسعه محصولات جدید پشتیبانی میکند. بسیاری از شرکتهای موفق امروزی از جمله فیسبوک، گوگل و اوبر، ماشین لرنینگ را به بخش اصلی و مرکزی عملیات خود تبدیل کردهاند. ماشین لرنینگ به یک حوزه رقابتی مهم برای شرکتها و کسب و کارها تبدیل شده و بسیار ارزشمند است؛ زیرا میتواند مسائلی را با سرعت و مقیاسی حل کند که توسط ذهن انسان به تنهایی قابل حل نیستند.
با استفاده از تواناییهای زیادی جهت انجام حجم بالایی از محاسبات برای یک کار واحد یا چندین کار خاص، میتوان ماشینها را برای شناسایی الگوها، روابط بین دادههای ورودی و خودکارسازی فرایندهای معمول آموزش داد. الگوریتمهایی که در یادگیری ماشین مورد استفاده قرار میگیرند، برای موفقیت در روند کار ماشین لرنینگ بسیار مهم هستند. این الگوریتمها یک مدل ریاضی را بر اساس دادههای نمونه میسازند تا بیشبینیها و تصمیمگیریها را بدون برنامه نویسی مستقیم انجام دهند. این دادهها به عنوان «دادههای آموزشی» (Training Data) شناخته میشوند.

الگوریتمهای ماشین لرنینگ میتوانند رویکردهایی را روی دادهها اعمال کنند. کسب و کارهایی که حجم دادههای زیادی دارند میتوانند از این رویکردها برای بهبود تصمیمگیریها، بهینهسازی کارکردها و دریافت اطلاعات عملپذیر در هر مقیاسی بهرهمند شوند. ماشین لرنینگ پایه و اساس سیستمهای هوش مصنوعی را برای خودکارسازی فرایندها و حل مسائل مرتبط با کسب و کار به صورت خودکار فراهم میکند.
همچنین ماشین لرنینگ این امکان را برای شرکتها فراهم میکند تا تواناییهای انسانی خاصی را جایگزین یا تقویت کنند. برخی از برنامههای بسیار رایج ماشین لرنینگ که در دنیای واقعی امروز کاربرد زیادی دارند، شامل «چتباتها» (Chatbot)، «اتومبیلهای خودران» (Self-Driving Car) و «بازشناسی گفتار» (Speech Recognition) میشوند. در بخش بعدی یاد میگیریم که روش کارکرد ماشین لرنینگ چیست.
ماشین لرنینگ چگونه کار می کند؟
الگوریتمهای یادگیری ماشین بر روی یک مجموعه داده برای ایجاد یک مدل یادگیری ماشینی مدلسازی میشوند. سپس، میتوان دادههای ورودی جدید را وارد الگوریتم ماشین لرنینگ کرد و برای توسعه مدل با هدف پیشبینی، آنها را مورد استفاده قرار داد. در تصویر زیر سناریویی برای روش کارکرد سطح بالا ماشین لرنینگ مشاهده میشود. با این حال، مثالهای دیگر مسائل ماشین لرنینگ معمولی ممکن است شامل بسیاری از عوامل، فاکتورها، «متغیرها» (Variable) و سایر مراحل باشند.
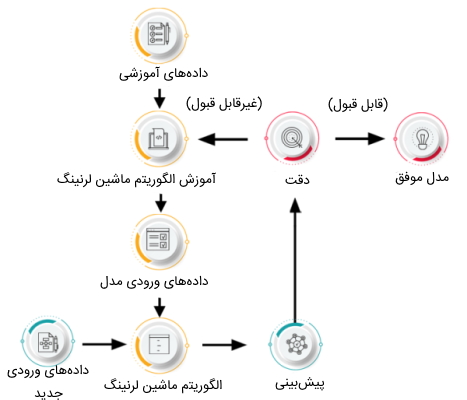
در تصویر فوق، پیشبینی مدل برای موفقیت یا عدم موفقیت آن بررسی میشود. بر اساس دقت نهایی، ممکن است مدل انتخاب شود یا تا زمانی که مدل به دقت مورد انتظار برسد بر اساس مجموعه دادههای ورودی به صورت مکرر آموزش میبیند. به طور کلی، روند یادگیری الگوریتمهای ماشین لرنینگ را میتوان به سه مجموعه زیر تقسیم کرد:
- «فرایند تصمیم» (Decision Process): بر اساس دادههای ورودی و مسائلی از جمله اینکه برچسبدار باشند یا بدون برچسب، الگوریتم ماشین لرنینگ تخمینی درباره یک الگو در دادهها ایجاد میکند. در این مرحله باید نسبت به نوع دادهها، درباره روش اجرای الگوریتم تصمیم گرفته و رویکرد حل مسئله انتخاب شود.
- «تابع خطا» (Error Function): یک تابع خطا ارزیابی خروجی مدل و نتیجه حاصل شده استفاده میشود. اگر مدلهای شناخته شدهای دیگری نیز درباره یک مسئله وجود داشته باشند، تابع خطا میتواند مقایسهای برای ارزیابی دقت مدل با آنها انجام دهد.
- «فرایند بهینهسازی مدل» (Model Optimization Process): اگر مدل به خوبی بتواند با دادههای مجموعه داده آموزشی ارتباط برقرار کند، وزنها برای کاهش اختلاف دقت بین مدلهای شناخته شده قبلی و تخمین مدل ایجاد شده جدید تنظیم میشوند. الگوریتم ماشین لرنینگ این فرایند بهینهسازی و ارزیابی را تکرار میکند و وزنها را به صورت خودکار تا رسیدن به هدف موردنظر بروزرسانی میکند.
بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی انواع روشهای ماشین لرنینگ پرداخته شده است.
انواع روش های ماشین لرنینگ کدامند؟
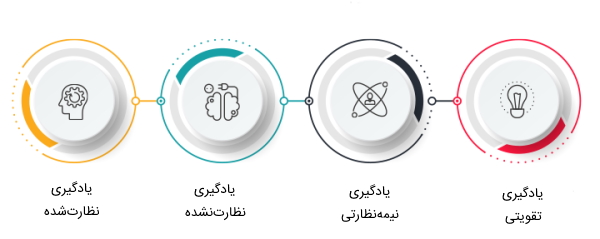
برای انواع مجموعه دادههای مختلف لازم است از مسیر یادگیری و روشهای متفاوتی استفاده شود. الگوریتمهای ماشین لرنینگ با استفاده از روشهای مختلفی میتوانند آموزش داده شوند که هر کدام از این روشها مزایا و معایب خاص خود را دارند. به این ترتیب انواع روشهای ماشین لرنینگ را میتوان به صورت زیر دستهبندی کرد:
- «یادگیری نظارت شده» (Supervised Learning)
- «یادگیری نظارت نشده» (Unsupervised Learning)
- «یادگیری نیمه نظارتی» (Semi Supervised Learning)
- «یادگیری تقویتی» (Reinforcement Learning)
ابتدا در بخش بعدی به بررسی یادگیری نظارت شده پرداخته شده است.
- مطلب پیشنهادی: مفاهیم یادگیری نظارت شده، نظارت نشده و نیمه نظارت شده
یادگیری نظارت شده چیست؟
این نوع از ماشین لرنینگ دارای نظارت است یعنی مدلها با استفاده از مجموعه دادههای برچسبدار آموزش داده میشوند و قابلیت پیشبینی خروجی را بر اساس آموزش انجام شده فراهم میکنند. در مجموعه دادههای برچسبدار برخی از پارامترهای ورودی و خروجی مشخص هستند. از اینرو، مدل با ورودی و خروجی مربوطه آموزش داده میشود. در نهایت مدلی برای پیشبینی نتیجه برای مجموعه دادههای تست در مرحله بعدی ایجاد خواهد شد. مدل آموزش دیده قادر خواهد بود خروجی را برای نمونه دادههای جدید با یک ضریب خطای مشخص، پیشبینی کند.

این الگوریتم میتواند خروجی خود را با خروجی صحیح و از قبل تعیین شده مقایسه کند و خطاهای موجود را بیابد تا بر اساس آن، مدل را اصلاح کند. برای مثال اگر مجموعه دادههای ورودی تصاویری از طوطیها و کلاغها باشند، ابتدا ماشین آموزش میبیند تا تصاویر را از جهتهای مختلف از جمله رنگ طوطی و کلاغ، چشمها، شکل و اندازه درک کند. پس از آموزش، تصویر ورودی یک طوطی جدید که ماشین تاکنون ندیده است به مدل داده میشود و از ماشین انتظار میرود که شی را شناسایی کرده و خروجی را پیشبینی کند.
ماشین آموزش دیده انواع ویژگیهای شی از جمله رنگ، چشمها، شکل و سایر موارد را در تصویر ورودی بررسی میکند تا پیشبینی نهایی را ارائه دهد. این پروسه تشخیص شیء در ماشین لرنینگ نظارت شده است. هدف اصلی روش یادگیری نظارت شده نگاشت متغیر ورودی a روی متغیر خروجی b به حساب میآید. یادگیری ماشین نظارت شده به دو دسته کلی زیر تقسیمبندی میشود. ابتدا در بخش بعدی به بررسی روش دستهبندی یا همان Classification پرداخته شده است.
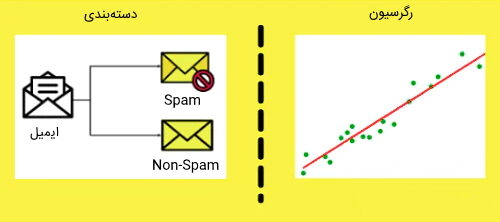
در ماشین لرنینگ نظارت شده روش دسته بندی یا Classification چیست ؟
این نوع از الگوریتمها مسائلی را مورد بررسی قرار میدهند که هدف آنها دستهبندی متغیرهای خروجی به چندین گروه است. برای مثال، گروههای بله یا خیر، درست یا غلط، زن یا مرد و سایر موارد را میتوان نام برد. به عنوان مثالی از دنیای واقعی برای این الگوریتمها میتوان به تشخیص ایمیلها و قرار دادن آنها در دو گروه ایمیلهای صحیح و ایمیلهای «هرزنامه» (Spam) اشاره کرد. به عنوان مثالهایی برای الگوریتمهای دستهبندی میتوان به موارد زسر اشاره کرد:
- «جنگل تصادفی» (Random Forest)
- «درخت تصمیم» (Decision Tree)
- «رگرسیون لجستیک» (Logistic Regression)
- «ماشین بردار پشتیبان» (Support Vector Machine | SVM)
- «دسته بند بیز ساده» (naïve Bayes Classification)
در بخش بعدی مطلب «ماشین لرنینگ چیست» روش «رگرسیون» (Regression) شرح داده شده است.
در ماشین لرنینگ نظارت شده روش رگرسیون چیست ؟
الگوریتمهای رگرسیون مسائل رگرسیونی را مدیریت میکنند. مسائل رگرسیونی یک نوع مدل آماری هستند و برای پیشبینی یک متغیر با استفاده از یک یا چند متغیر دیگر مورد استفاده قرار میگیرند. متغیرهای ورودی و خروجی این مسائل با یکدیگر رابطه خطی دارند. این الگوریتمها برای پیشبینی متغیرهای خروجی پیوسته شناخته شدهاند. به عنوان مثال میتوان به پیشبینی آب و هوا، تجزیه و تحلیل روند بازار و سایر موارد اشاره کرد. برخی از الگوریتمهای معروف رگرسیون شامل موارد زیر میشوند:
- «رگرسیون خطی ساده» (Simple Linear Regression)
- «رگرسیون چند متغیره» (Multivariate Regression)
- درخت تصمیم
- رگرسیون لاسو (Lasso Regression)
در بخش بعدی به بررسی روش دستهبندی مجموعه دادهها در روشهای نظارت شده پرداخته شده است.
روش دسته بندی داده ها در یادگیری نظارت شده
مجموعه دادهها برای استفاده در مدل باید به دو یا سه بخش «آموزش» (Train)، «اعتبارسنجی» (Validation) و «تست» (Test) تقسیم شوند. در برخی از پروژهها نیازی به مجموعه اعتبارسنجی نیست؛ زیرا تفاوت زیادی بین دقت تست و اعتبارسنجی وجود ندارد و نیازی نیست که حتما در هر دوره دقت مشاهده شود و میتوان دادههای مجموعه داده را در بخشهای دیگری مورد استفاده قرار داد. مجموعه آموزش که معمولاً بزرگترین مجموعه در نظر گرفته میشود، برای آموزش مدل مورد استفاده قرار میگیرد. مجموعه اعتبارسنجی برای تست هر دوره از آموزش در زمان پیادهسازی مدل مورد استفاده قرار میگیرد.
هر دوره از آموزش را به اصطلاح «Epoch» خطاب میکنند. همچنین مجموعه تست نیز پس از پیادهسازی کامل مدل، برای تست و ارزیابی مدل نهایی کاربرد دارد. همچنین، هیچ کدام از این مجموعهها نباید باهم همپوشانی داشته باشند. در پروژههای هوش مصنوعی هنگام آموزش دادهها چندین بار (چندین دوره) این کار انجام میشود تا در نهایت بتوان به نتیجه موردنظر رسید به هر کدام از این دورهها Epoch گفته میشود. در ادامه این بخش از مطلب، هر کدام از انواع یادگیری در ماشین لرنینگ به طور جامع مورد بررسی قرار میگیرند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی و تعریف یادگیری نظارت نشده پرداخته شده است.
یادگیری نظارت نشده چیست؟
در این نوع از الگوریتمها مجموعه دادههای مسئله، دارای دادههای برچسبدار نیستند و الگوریتم توانایی پیشبینی مسائل را بدون هیچ نظارتی دارد، یعنی قبل از «یادگیری» (Learning) هیچ بررسی و نظارتی روی دادهها انجام نشده است و مجموعه داده بدون هیچ نظارت و برچسبی مورد استفاده قرار میگیرد. هدف الگوریتمهای یادگیری نظارت نشده، گروهبندی مجموعه داده مرتب نشده بر اساس شباهتها، تفاوتها و الگو دادههای ورودی است. در واقع، در این نوع مسائل یادگیری ماشین، هدف ارتباط ورودی و خروجی نیست؛ بلکه الگوریتم یادگیری ماشین به دنبال تابعی برای توصیف ساختار پنهان و خاص موجود در دادهها است.
برای مثال میتوان در نظر گرفت که مجموعه دادههای ورودی تصویرهای ظرفهای پر از میوه باشند. در این مسئله تصاویر برای مدل ماشین لرنینگ شناخته شده نیستند. زمانی که ورودی مجموعه داده وارد مدل یادگیری ماشین میشود، وظیفه مدل شناسایی الگو اشیا از جمله رنگ، شکل یا تفاوتهای مشاهده شده در تصاویر ورودی یا گروههای آنها است. پس از گروهبندی و آموزش کامل مدل، ماشین، خروجی را با مجموعه داده تست پیشبینی میکند. یادگیری نظارت شده در ماشین لرنینگ دارای دو نوع دستهبندی زیر است. ابتدا به بررسی روش «خوشهبندی» (Clustering) پرداخته شده است.
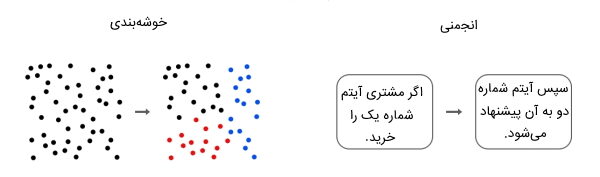
در ماشین لرنینگ بدون نظارت روش خوشه بندی یا Clustering چیست ؟
روشهای خوشهبندی به گروهبندی اشیا به خوشهها بر اساس پارامترهایی از جمله شباهت و تفاوت میان اشیا بستگی دارد. برای مثال میتوان به گروهبندی مشتریها بر اساس محصولاتی اشاره کرد که خریداری کردهاند. برخی از الگوریتمهای معروف خوشهبندی شامل موارد زیر میشوند:
- الگوریتم خوشهبندی «K-Means»
- خوشهبندی «Mean-Shift»
- الگوریتم «DBSCAN»
- «تحلیل مؤلفه اصلی» (Principal Component Analysis | PCA)
- «تحلیل مؤلفههای مستقل» (Independent Component Analysis)
در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی روش بدون نظارت «انجمن» (Association) پرداخته شده است.
در ماشین لرنینگ بدون نظارت روش انجمنی یا Association چیست ؟
یادگیری انجمنی با استفاده از شناسایی روابط معمولی بین متغیرهای یک مجموعه داده بزرگ انجام میشود. این روش وابستگی انواع دادههای مختلف و نگاشت متغیرهای انجمنی را بررسی و تعیین میکند. برخی از کاربردهای معمولی این نوع از گروهبندی، شامل استخراج موارد از وب و تجزیه و تحلیل دادههای بازار است. به عنوان الگوریتمهایی معروف از روش انجمنی میتوان به الگوریتمهای زیر اشاره کرد:
- الگوریتم «اپریوری» (Apriori)
- الگوریتم «Eclat»
- الگوریتم «FP-Growth»
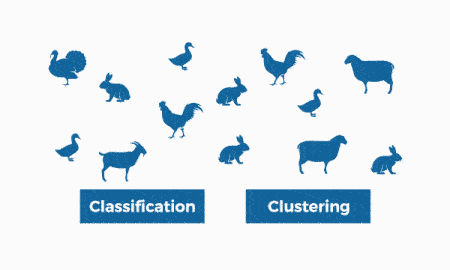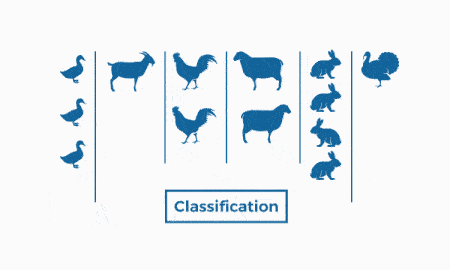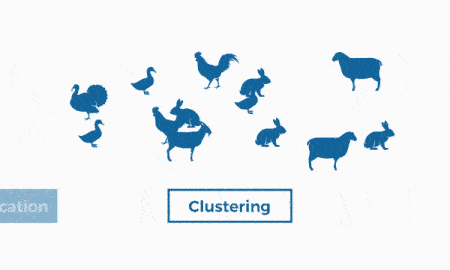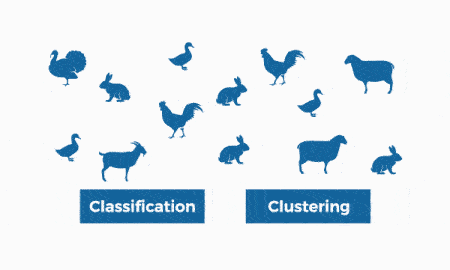
بخش بعدی از یاد میگیریم که یادگیری نیمهنظارتی در ماشین لرنینگ چیست و آن را بررسی میکنیم.
یادگیری نیمه نظارتی چیست؟
یادگیری نیمه نظارتی به نوعی از یادگیری گفته میشود که هم شامل ویژگیهای یادگیری نظارت شده و هم شامل ویژگیهای یادگیری نظارت نشده باشد. مجموعه داده این نوع از یادگیری شامل مجموعه کوچکی از دادههای برچسبدار و مجموعه بزرگی از دادههای بدون برچسب میشود. با استفاده از هر دو نوع مجموعه داده، یادگیری نیمه نظارتی بر اشکالات دو نوع یادگیری ذکر شده در بخشهای فوق غلبه میکند.
میتوان تصور کرد که مجموعه بزرگی از دادههای بدون برچسب جمعآوری شدهاند و نیاز است که مدلی با استفاده از آنها آموزش داده شود، همچنین برچسب زدن دستی آنها ممکن است که زمان زیادی یا حتی ماهها به طول بینجامد. بنابراین برای حل چنین مسائلی استفاده از روشهای نیمه نظارتی مناسب خواهد بود. اصول استفاده از روش یادگیری نیمه نظارتی بسیار ساده است، یعنی به جای برچسب زدن کل مجموعه داده، فقط بخشی از آن به صورت دستی برچسب زده میشود و پس از آموزش آن به وسیله یک الگوریتم نظارت شده، دادههای بدون برچسب به آن اضافه خواهند شد.
برای مثال، یک دانشجوی سال آخر دبیرستان در نظر گرفته میشود. زمانی که این دانشآموز مفهومی را تحت نظارت معلم در مدرسه یاد میگیرد، یادگیری نظارت شده اتفاق افتاده است و زمانی که دانشآموز همان مفهوم را در خانه و بدون نظارت معلم فرامیگیرد، یادگیری نظارت نشده رخ میدهد. در همین حال، اگر دانشآموز بعد از یادگیری مفهوم موردنظر در خانه، مجدداً زیر نظر معلم و در مدرسه آن را مطالعه کند، یک نوع یادگیری نیمه نظارتی رخ داده است. در ادامه برای درک بهتر این نوع از یادگیری یکی از روشهای آن به نام «خود نظارتی» (Self Training) مورد بررسی قرار میگیرد.
در ماشین لرنینگ نیمه نظارتی روش خود نظارتی یا Self Training چیست ؟
روش خودنظارتی یکی از سادهترین رویکردهای یادگیری نیمهنظارتی به حساب میآید. این یادگیری، رویهای است که میتوان در آن از هر روش نظارت شدهای با رویکرد رگرسیون یا دستهبندی استفاده کرد و با استفاده از دادههای برچسبدار و بدون برچسب عملکرد آنها را به یادگیری نیمه نظارتی تغییر داد. در تصویر زیر روش کار این الگوریتم به صورت کامل شرح داده شده است:
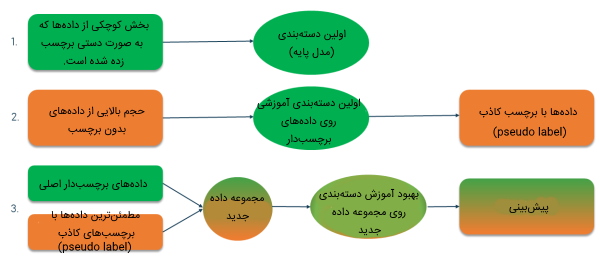
با توجه به تصویر فوق، میتوان بخش کوچکی از دادهها را برای استفاده از روش یادگیری نیمه نظارتی انتخاب کرد، برای مثال تصاویری انتخاب میشوند که نشاندهنده سگها و گربهها با برچسبهای متناظر آنها هستند. از این مجموعه داده برای آموزش «مدل پایه» (Base Model) از روش یادگیری نظارتی استفاده میکند. سپس فرایندی اعمال خواهد شد که با نام «برچسبگذاری کاذب» یا «شبه برچسب زدن» (Pseudo Label) شناخته شده است. این فرایند زمانی استفاده میشود از مدل نیمه آموزش دیده یا همان مدل پایه برای پیشبینی بقیه دادههای مجموعه داده بدون برچسب استفاده شود.
برچسبهایی که با استفاده از این فرایند تولید میشوند «شبه» (Pseudo) نامیده میشون؛ زیرا بر اساس دادههای برچسبگذاری شده اولیه تولید شدهاند که محدودیتهایی دارند، مثلاً ممکن است نمایش ناهمواری از کلاسها در مجموعه وجود داشته باشد که منجر به بایاس (Bias) شود، یعنی برای مثال تصاویر سگها بیشتر از گربهها باشد. (مبحث بایاس در بخشهای بعدی بیشتر توضیح داده شده است.) اگر هر کدام از پیشبینی برچسبهای دادهها دارای اطمینان بالایی باشند؛ یعنی برای مثال به احتمال ۸۰ درصد این فرایند یک تصویر گربه را با برچسب گربه پیشبینی کرده است به مجموعه داده برچسبگذاری شده اضافه خواهد شد.
این فرایند برای یافتن برچسبهایی با اطمینان بالا چندین بار انجام میشوند، برای این روش، در حالت استاندارد ۱۰ تکرار در نظر گرفته شده است و در هر تکرارا تعداد شبه برچسبهای بیشتری به مدل اضافه خواهد شد. این فرایند تا جایی ادامه مییابد که در هر تکرار عملکرد مدل افزایش پیدا کند. بخش بعدی از مطلب «ماشین لرنینگ چیست» به شرح و تعریف یادگیری تقویتی اختصاص دارد.
یادگیری تقویتی چیست؟
یادگیری تقویتی نوعی از ماشین لرنینگ به حساب میآید که دارای فرایندهای مبتنی بر بازخورد است. این نوع یادگیری بر اساس ارزش یا دادن پاداش به اشیا، آنها را دستهبندی میکند. به طور کلی، یک عامل یادگیری تقویتی میتواند محیط خود را درک و تفسیر کند، اقداماتی انجام دهد و از طریق آزمون و خطا آموزش ببیند. به عبارت دیگر، در یادگیری تقویتی، «عامل هوشمند» (Intelligent Agent) با انجام اقداماتی در محیط و دیدن نتایج آنها، با محیط خود ارتباط برقرار میکند. نتیجه ارتباط عامل با محیط میتواند یک خطا یا یک پاداش باشد. هدف در روشهای یادگیری تقویتی، بیشینه کردن پاداش است.
در واقع، عامل در مسیر بیشینه کردن پاداش (امتیاز) اقدام میکند و در غیر این صورت، خطا (مجازات | تنبیه) دریافت خواهد کرد. در یادگیری تقویتی، عامل هوشمند برای انجام تصمیمگیریهای متوالی آموزش میبیند یا به بیان دیگر، عامل میآموزد که در یک محیط نامعلوم و پیچیده به هدف یعنی همان بیشینه کردن پاداش برسد. برخلاف روش یادگیری نظارت شده، دادههای یادگیری تقویتی دارای دادههای برچسبدار نیستند و عاملها در آن فقط از طریق تجربیات آموزش میبینند.
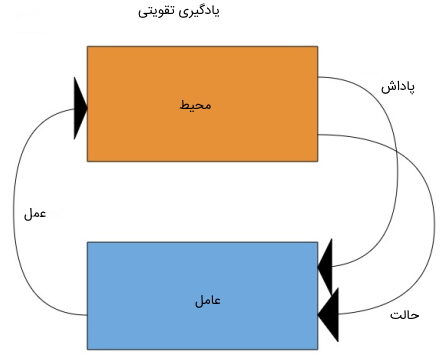
برای مثال میتوان بازیهای ویدیویی را در نظر گرفت. در این مثل بازی همان محیط است و هر حرکت عامل تقویتکننده آن به حساب میآید. عامل میتواند از طریق پاداش یا مجازات بازخورد دریافت کند و نتیجه بر امتیاز کلی بازی تأثیر بگذارد. هدف نهایی عامل، دستیابی به امتیاز بالا است. یادگیری تقویتی در زمینههای مختلفی از جمله نظریه بازیها، نظریه اطلاعات، سیستمهای چند عاملی و سایر موارد کاربرد دارد. یادگیری تقویتی به دو نوع روش یا همان الگوریتم تقسیم میشوند که در ادامه بررسی شدهاند:
- «یادگیری تقویتی مثبت» (Positive Reinforcement Learning): در این روش از یادگیری، یک محرک تقویتکننده پس از رفتار خاص عامل اضافه میشود. این محرک احتمال بروز مجدد رفتار موردنظر در آینده را افزایش میدهد. برای مثال میتوان به اضافه کردن یک پاراش پس از رفتار موردنظر اشاره کرد.
- «یادگیری تقویتی منفی» (Negative Reinforcement Learning): در این رویکرد از یادگیری ماشین لرنینگ، تقویت یک رفتار خاص برای جلوگیری از یک نتیجه منفی انجام میشود.
در بخش بعدی از مطلب «ماشین لرنینگ چیست»، پس از معرفی مجموعه دورههای آموزش داده کاوی و یادگیری ماشین، به بررسی چرخه حیات یک سیستم ماشین لرنینگ پرداخته شده است.
معرفی فیلم های آموزش داده کاوی و یادگیری ماشین فرادرس

دورههای آموزشی ویدیویی وب سایت فرادرس بر اساس موضوع به صورت مجموعههای آموزشی متفاوتی دستهبندی شدهاند. یکی از این مجموعههای جامع مربوط به دورههای آموزش داده کاوی و یادگیری ماشین است. علاقهمندان میتوانند از این مجموعه آموزشی برای مطالعه بیشتر ماشین لرنینگ با انواع روشهای مختلف استفاده کنند. در زمان تدوین این مطلب، مجموعه دورههای داده کاوی و یادگیری ماشین فرادرس حاوی بیش از ۳۲۰ ساعت محتوای ویدیویی و حدود ۴۰ عنوان آموزشی مختلف بوده است. در ادامه این بخش، برخی از دورههای این مجموعه به طور خلاصه معرفی شدهاند:
- فیلم آموزش یادگیری ماشین Machine Learning با پایتون Python (طول مدت: ۱۰ ساعت، مدرس: مهندس سعید مظلومی راد): در این فرادرس سعی شده است، ابتدا بستههای شناخته شده پایتون معرفی و سپس کار با توابع آنها آموزش داده شوند. در انتها نیز مباحث یادگیری ماشین همراه با مثالهای متعدد در پایتون مورد بررسی قرار گرفتهاند. برای مشاهده فیلم آموزش یادگیری ماشین Machine Learning با پایتون Python + کلیک کنید.
- فیلم آموزش یادگیری عمیق با پایتون - تنسورفلو و کراس TensorFlow و Keras (طول مدت: ۲ ساعت و ۵۷ دقیقه، مدرس: دکتر سعید محققی): در این دوره آموزشی، تمرکز بر روی محبوبترین بسترهای نرم افزاری، پرکاربردترین کتابخانه کدنویسی ازجمله تنسورفلو و کراس و رایجترین مدلها و دادهها در زمینه یادگیری عمیق است. برای مشاهده فیلم آموزش یادگیری عمیق با پایتون - تنسورفلو و کراس TensorFlow و Keras + کلیک کنید.
- فیلم آموزش یادگیری عمیق - شبکه های GAN با پایتون (طول مدت: ۵ ساعت و ۶ دقیقه، مدرس: دکتر عادل قاضی خانی): در این دوره آموزشی شبکههای GAN معمولی، شبکههای Deep Convolutional GAN ،Semi-Supervised GAN ،Conditional GAN و CycleGAN بررسی میشوند. علاوه بر این، قبل از ورود به موضوع شبکههای GAN، مفاهیم مقدماتی مورد نیاز یادگیری ماشین و شبکههای عصبی بیان میشود. در این آموزش از زبان پایتون برای آموزش برنامه نویسی شبکههای GAN استفاده شده است. برای مشاهده فیلم آموزش یادگیری عمیق - شبکه های GAN با پایتون + کلیک کنید.
- فیلم آموزش پردازش زبان های طبیعی NLP در پایتون Python با پلتفرم NLTK (طول مدت: ۷ ساعت و ۱۲ دقیقه، مدرس: مهندس احسان یزدانی): در این فرادرس، زبان برنامه نویسی پایتون برای پردازش زبان طبیعی و مهمترین ابزار آن، یعنی NLTK آموزش داده شده است. برای مشاهده فیلم آموزش پردازش زبان های طبیعی NLP در پایتون Python با پلتفرم NLTK + کلیک کنید.
- فیلم آموزش کتابخانه scikit-learn در پایتون - الگوریتم های یادگیری ماشین (طول مدت: ۳ ساعت و ۵۷ دقیقه، مدرس: سید علی کلامی هریس): هدف این دوره آموزشی ویدویی، آموزش بخشی از الگوریتمهای یادگیری ماشین موجود در کتابخانه scikit-learn پایتون است. برای مشاهده فیلم آموزش کتابخانه scikit-learn در پایتون - الگوریتم های یادگیری ماشین + کلیک کنید.
- آموزش شبکه های عصبی پیچشی CNN - مقدماتی (طول مدت: ۲ ساعت و ۱۲ دقیقه، مدرس: سایه کارگری): از آنجا که شبکههای عصبی پیچشی یکی از نیازهای اصلی علاقهمندان به پردازش تصویر و بینایی ماشین به حساب میآید، فراگیری مفاهیم این شبکهها از اهمیت بالایی برخوردار است و در این فرادرس به آنها پرداخته میشود. برای مشاهده آموزش شبکههای عصبی پیچشی CNN - مقدماتی + کلیک کنید.
حال پس از معرفی مجموعه دورههای آموزش داده کاوی و یادگیری ماشین فرادرس، بخش بعدی مطلب «ماشین لرنینگ چیست» به بررسی چرخه حیات یک سیستم ماشین لرنینگ در طول یک پروژه، اختصاص داده شده است.
چرخه حیات سیستم ماشین لرنینگ چگونه است؟
در این بخش به بررسی چرخه حیات یک سیستم یادگیری ماشینی پرداخته شده است. اکثر پروژههای یادگیری ماشین برای حل مسئله این رویکردها را دنبال میکنند. هر یک از مراحل چرخه حیات ماشین لرنینگ در ادامه فهرست شدهاند:
- درک مسئله: اولین مرحله درک صحیح از مسئله ماشین لرنینگ است و بررسی اینکه چرا برای یک مسئله روش ماشین لرنینگ استفاده میشود و چه مواردی برای این مسئله باید انجام و فراگرفته شوند.
- «پیشپردازش دادهها» (Data Preprocessing): مرحله بعدی به «جمعآوری و پاکسازی دادهها» (Data Collection And Cleaning) اختصاص دارد. قبل از استفاده از دادههای موجود بهتر است که آنها مورد بررسی قرار بگیرند و بر اساس مسئله موردنظر پردازش و پاکسازی شوند تا بتوانند اطلاعات مورد نیاز را در اختیار مسئله قرار دهند.
- «استخراج ویژگیها» (Feature Extraction): در این مرحله دادههایی ایجاد خواهند شد که به عنوان ورودی وارد یک مدل یادگیری ماشینی برای ساخت مدل میشوند. روشهای مختلفی بر اساس الگوریتم مورد استفاده برای استخراج ویژگیها وجود دارد. برای مثل ممکن است برای یک مسئله بهتر باشد از الگوریتم درخت تصمیم برای استخراج ویژگی استفاده کرد. پس از انتخاب ویژگیها، تحلیلگر یا ابزار مدلسازی دادههای استخراج شده را بررسی میکنند و مشخص میشود که این دادهها برای استفاده در مسئله موردنظر مناسب هستند یا باید مجدداً پردازش انجام شود.
- انتخاب مدل: در این مرحله باید مدلی برای آموزش دادهها انتخاب شود. هر مدل دارای الگوریتمی است که بتواند با استفاده از رویکرد آن، مسئله را حل کند و نتیجه خوبی برای دادههای تست ارائه دهد.
- «آموزش و تنظیم» (Training And Tuning): مدل با استفاده از دادههای انتخابی و پارامترهای دیگر مورد نیاز در ماشین لرنینگ تنظیم و آموزش داده میشود، تا در نهایت بتواند نتیجه خوبی را ارائه دهد.
- ارزیابی مدل: الگوریتم و مدل در حین یادگیری باید مورد ارزیابی قرار بگیرند تا مشخص شود مسیر درستی را طی کردهاند و به نتیجه خوبی خواهند رسید یا باید مجدداً مورد بررسی قرار بگیرند و الگوریتم و دادههای آنها بازنگری شوند.
- استقرار مدل: پس از اینکه مدل موردنظر با نتیجه مناسب ایجاد شد، باید برای تولید محصول در بخش مخصوص به خود قرار بگیرد.
- بررسی خروجی: پس از استقرار مدل، باید نتایج عملی محصول در خروجی مدل مشاهده و مورد بررسی قرار بگیرند. در صورت نیاز میتوان مدل را مجدداً بهبود داد و اگر نیازی نبود از مدل ایجاد شده استفاده خواهد شد.

در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تفاوت ماشین لرنینگ و یادگیری عمیق پرداخته شده است.
تفاوت ماشین لرنینگ و دیپ لرنینگ
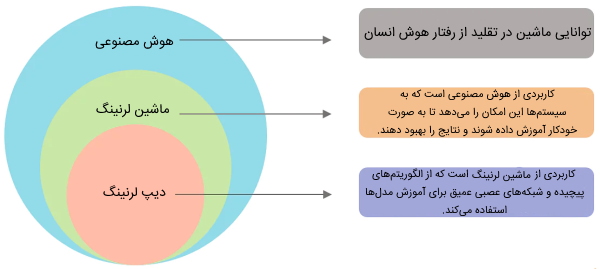
ماشین لرنینگ و «دیپ لرنینگ» یا همان «یادگیری عمیق» (Deep Learning) عملکرد و کاربردهای مشابه بسیاری دارند، از اینرو، در بسیاری از مواقع با یکدیگر اشتباه گرفته میشوند. در این بخش به بررسی تفاوتهای کلیدی و اصلی این دو اصطلاح مهم و کاربردی پرداخته شده است. این تفاوتها به صورت خلاصه در تصویر زیر ارائه شدهاند. اما ابتدا و قبل از بررسی تفاوت ماشین لرنینگ و یادگیری عمیق به بررسی تعریف یادگیری عمیق پرداخته میشود.
یادگیری عمیق چیست؟
همانطور که ماشین لرنینگ به عنوان نوعی از کاربردهای هوش مصنوعی در نظر گرفته میشود، یادگیری عمیق نیز یکی از کاربردها و زیرمجموعه ماشین لرنینگ به حساب میآید. در حالی که در ماشین لرنینگ از مدلهای سادهتری از جمله مدلهای پیشبینی استفاده میشود، در یادگیری عمیق از «شبکههای عصبی مصنوعی» (Artificial Neural Network | ANN) برای تقلید از روش یادگیری و فکر کردن انسان استفاده شده است. مؤلفه سلولی اولیه و عنصر محاسباتی اصلی مغز انسان نورونها هستند و هر اتصال عصبی آنها مانند یک کامپیوتر کوچک عمل میکند. شبکه نورونها در مغز وظیفه پردازش انواع ورودیها از جمله دیداری، حسی، شنوایی و سایر موارد را بر عهده دارند.
در سیستمهای یادگیری عمیق حجم دادههای ورودی آنها بالا است، زیرا این سیستمها برای درک و ایجاد نتایج دقیق به مجموعه دادههای بزرگی نیاز دارند. سپس شبکههای عصبی مصنوعی با استفاده از محاسبات ریاضی پیچیده و ایجاد سوالاتی با پاسخ صحیح و غلط دادهها را پردازش میکنند و دستهبندی آنها را بر اساس هدف مسئله انجام میدهند. بنابراین، اگرچه ماشین لرنینگ و یادگیری عمیق زیرمجموعههایی از هوش مصنوعی هستند و هر دو از دادههای ورودی «یاد میگیرند»، تفاوتهای کلیدی بین آنها وجود دارد که در بخش بعدی از مطلب «ماشین لرنینگ چیست»، مورد بررسی قرار میگیرند.
تفاوت ماشین لرنینگ و یادگیری عمیق در زمینه مداخله انسان چیست؟
در حالی که در سیستمهای ماشین لرنینگ، برنامه نویس باید به صورت دستی ویژگیها را بر اساس نوع دادهها از جمله مقدار پیکسلها، شکل و موقعیت شناسایی کند، سیستمهای یادگیری عمیق سعی دارند که یادگیری ویژگیها را بدون مداخله انسان انجام دهند. برای مثال، در برنامههای تشخیص چهره، برنامه ابتدا میآموزد که چگونه تشخیص و سازماندهی خطها و لبههای چهره را انجام دهد، سپس بخشهای مهمتر چهره و در نهایت نمایش کلی چهره را شناسایی میکند.
حجم دادههایی که باید برای چنین کاری استفاده شوند، بسیار زیاد است و با گذشت زمان و آموزش بیشتر مدل، سطح دقت تشخیص چهره در آن افزایش پیدا میکند. آموزش این مدلها در یادگیری عمیق از طریق شبکههای عصبی و روشی مشابه با کارکرد مغز انسان و بدون نیاز به برنامه نویسی مجدد مدل انجام میشود. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تفاوت ماشین لرنینگ و یادگیری عمیق در سخت افزار آنها پرداخته شده است.
تفاوت ماشین لرنینگ و یادگیری عمیق در سخت افزار چیست؟
به دلیل اینکه سیستمهای یادگیری عمیق از حجم بالایی داده برای پردازشهای خود استفاده میکنند و پردازشهای فرایندهای آنها دارای محاسبات پیچیده و سنگینی هستند، این سیستمها نسبت به ماشین لرنینگ به سخت افزار قدرتمندتری نیاز دارند. یکی از سخت افزارهایی که در یادگیری عمیق مورد استفاده قرار میگیرد «واحد پردازنده گرافیکی» (Graphical Processing Unit | GPU) است. در طرف مقابل، برنامههای ایجاد شده با ماشین لرنینگ میتوانند بر روی پردازندههای سادهتر و رده پایینتر و بدون قدرت محاسباتی بالا نیز پیادهسازی شوند. بخش بعدی مطلب «ماشین لرنینگ چیست» به شرح تفاوت ماشین لرنینگ و یادگیری عمیق در زمان اجرا و آموزش برنامههای آنها اختصاص دارد.

تفاوت ماشین لرنینگ و یادگیری عمیق در زمان پیاده سازی چیست؟
همانطور که انتظار میرود، به دلیل نیاز سیستمهای یادگیری عمیق به مجموعه دادههای بزرگ و از آنجا که این سیستمها دارای پارامترها و معادلات ریاضی و محاسباتی زیادی هستند، زمان بیشتری برای آموزش مدلهای آنها نیاز است. اما ماشین لرنینگ زمان کمتری نسبت به یادگیری عمیق نیاز دارد و برنامههای آن میتوانند در چند ثانیه یا نهایتاً چند ساعت آموزش ببینند. برنامههای یادگیری عمیق ممکن است حدود چند ساعت یا چندین هفته برای پیادهسازی، آموزش دادهها و ایجاد مدلها نیاز به زمان داشته باشند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» تفاوت ماشین لرنینگ و یادگیری عمیق از نظر رویکرد آنها مورد بررسی قرار میگیرد.

تفاوت ماشین لرنینگ و یادگیری عمیق از نظر رویکرد آن ها چیست؟
معمولاً الگوریتمهای ماشین لرنینگ دادهها را به چند بخش تقسیم میکنند، سپس بخشهای مناسب برای رسیدن به نتیجه و هدف موردنظر مسئله با یکدیگر ترکیب میشوند. اما سیستمهای یادگیری عمیق کل مسئله یا سناریو را به صورت کلی و در یک مرحله بررسی میکنند. برای مثال، اگر مسئلهای وجود داشته باشد که هدف آن یافتن یک شی خاص در تصاویر مانند محل قرارگیری یک شی در تصویر یا تشخیص پلاک خودروها در پارکینگ باشد، با استفاده از الگوریتمهای ماشین لرنینگ باید دو مرحله انجام شود. مرحله اول «شناسایی شی» (Object Detection) و مرحله دوم «تشخیص شیء» (Object Recognition) است.
از طرف دیگر در برنامههایی که از یادگیری عمیق استفاده میکنند، تصویر ورودی وارد مدل میشود و با آموزشهای داده شده، برنامه هم شی شناسایی میشود و هم مکان آن را در یک تصویر و به عنوان یک خروجی نشان میدهد و این فرایند تنها در یک مرحله اتفاق میافتد. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تفاوت ماشین لرنینگ و یادگیری عمیق در کاربردهایشان پرداخته شده است.
تفاوت ماشین لرنینگ و یادگیری عمیق در کاربردهای آن ها چیست؟
طبق همه تفاوتهایی که تا این بخش از مطلب مورد بررسی قرار گرفتند، مشخص است که کاربردهای ماشین لرنینگ و یادگیری عمیق نیز با یکدیگر متفاوت هستند. کاربردهای اصلی ماشین لرنینگ در زمینه پیشبینی هستند، برای مثال میتوان به پیشبینی قیمتها در بازار سهام یا پیشبینی مکان و زمان وقوع یک طوفان اشاره کرد. همچنین، شناسایی ایمیلهای هرزنامه و برنامههایی که طرحهای درمانی مبتنی بر مدارک پزشکی بیماران را طراحی میکنند، الگوریتمهای ماشین لرنینگ را مورد استفاده قرار میدهند.
به عنوان کاربردهایی برای الگوریتمهای یادگیری عمیق میتوان به خدمات پخش موسیقی، تشخیص چهره، ساخت خودروهای خودران که شامل مواردی مانند تشخیص چراغهای راهنمایی رانندگی و به دست آوردن زمان مناسب برای افزایش یا کاهش سرعت در رانندگی اشاره کرد، این برنامهها از لایههای زیاد شبکههای عصبی برای ساخت مدلهای خود استفاده میکنند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی مزایا و معایب این حوزه پرداخته شده است.
مزایا و معایب ماشین لرنینگ
همانطور که پیش از این نیز مورد بررسی قرار گرفت، ماشین لرنینگ در مسائلی مانند پیشبینی رفتار مشتری تا ایجاد سیستمهای اتومبیلهای خودران مورد استفاده قرار میگیرد. زمانی که از مزایای این حوزه صحبت میشود میتوان برای بررسی آنها به صورت دقیقتری همین مثالها را توصیف کرد. برای مثال ماشین لرنینگ میتواند به سازمانها کمک کند تا مشتریان خود را در سطح عمیقی و بر اساس رفتارهای آنها درک کنند. سپس با جمعآوری رفتارهای مشتریان، الگوریتمهای ماشین لرنینگ میتوانند به سازمانها در ایجاد ابتکارهایی برای توسعه محصول و بازاریابی بر اساس تقاضای مشتری کمک کنند.

در مثالهای دیگری میتوان به شرکتهایی اشاره کرد که از ماشین لرنینگ به عنوان محرک اصلی در پروژههای خود استفاده میکنند. برای مثال شرکت اوبر از ماشین لرنینگ برای بررسی راننده خودرو و سرنشینان آن استفاده کرده است. در مثالی دیگر میتوان گفت شرکت گوگل برای نمایش تبلیغات خاص در جستجوها از ماشین لرنینگ استفاده میکند. اما با این حال ماشین لرنینگ معایبی هم دارد که در ادامه شرح داده شدهاند:
- اول از همه میتوان گفت که سیستمهای ماشین لرنینگ هزینه بالایی دارند. سیستمهای ماشین لرنینگ معمولاً توسط «دانشمندان داده» (Data Scientist) ایجاد میشوند و این افراد حقوق بالایی دریافت میکنند. همچنین این سیستمها به زیرساختهای نرم افزاری نیاز دارند که ممکن است گران باشند.
- مسئله دیگری که در ماشین لرنینگ وجود دارد، «بایاس» (Bias) است. الگوریتمها روی مجموعه داده مسئله آموزش داده میشوند و امکان دارد گاهی بخشی از مجموعه داده بررسی نشود یا دچار خطا شود. این الگوریتمها میتوانند مدلهای نادرستی بسازند که در بهترین حالت رد میشوند و در بدترین حالت با نتایج اشتباه و تبعیضآمیز مورد استفاده قرار میگیرند. زمانی که یک سازمان فرایندهای اصلی کسب و کار خود را بر اساس مدلهایی اجرا میکند که دارای بایاس هستند، ممکن است مشکلات قانونی برای آن پیش بیاید و به اعتبار آن خدشه وارد شود.
بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی کاربردهای ماشین لرنینگ در صنایع مختلف اختصاص داده شده است.

کاربردهای ماشین لرنینگ در صنایع مختلف
متخصصینی که وظیفه مدیریت حجم زیادی از دادهها را دارند، به اهمیت و ارزش فناوریهای ماشین لرنینگ پی بردهاند. از آنجا که ماشین لرنینگ اطلاعانی را از این دادهها در «زمان واقعی» (Realtime) به دست میآورد، سازمانها میتوانند با استفاده از آن نتایج موًثری داشته باشند و نسبت به رقیبان خود برتری پیدا کنند. در دنیای دیجیتال امروزی که به سرعت در حال پیشرفت است، هر سازمان صنعتی که بهروز باشد از مزایای ماشین لرنینگ استفاده میکند. در این بخش به بررسی برخی از معروفترین این صنایع پرداخته شده است. ابتدا در بخش بعدی «صنعت بهداشت و درمان» (Healthcare Industry) بررسی میشود.
استفاده از ماشین لرنینگ در صنعت بهداشت و درمان
امروزه ماشین لرنینگ در صنایع مختلفی از جمله صنعت مراقبتهای پزشکی در سطح بالایی پذیرفته شده است، برای مثال ماشین لرنینگ در دستگاههایی که برای انجام مراقبتهای پزشکی به صورت پوشیدنی تولید شدهاند و حسگرهایی دستگاههای تناسب اندام، ساعتهای سلامت هوشمند و سایر موارد کاربرد بسیاری دارد. همه این دستگاهها اطلاعات مرتبط با سلامتی افراد را در زمان واقعی و به صورت بلادرنگ ارزیابی میکنند.
علاوه بر این، فناوری ماشین لرنینگ به پزشکان در تجزیه و تحلیل کارها، تشخیص و درمان بیماریها کمک میکند. الگوریتمهای ماشین لرنینگ این امکان را به متخصصین ماشین لرنینگ در پزشکی میدهند تا طول عمر بیماری که از یک بیماری کشنده رنج میبرد را با دقت خوبی تشخیص دهند. ماشین لرنینگ به طور قابل توجهی در دو زمینه زیر فعالیت دارد:
- «دارو پژوهی» (Drug Discovery): معمولاً ساخت و کشف یک داروی جدید اصلا فرایند به صرفهای نیست، زیرا هم گران است و هم زمان زیادی برای این کار صرف میشود. ولی ماشین لرنینگ به افزایش سرعت ساخت و کشف داروها با استفاده از پردازشهای چند مرحلهای کمک میکند. برای مثال، شرکت دارویی فایزر از سازمان «IBM’s Watson» برای تجزیه و تحلیل حجم عظیمی از دادههای متفاوت جهت کشف دارو استفاده میکند.
- «درمان شخصیسازی شده» (Personalized Treatment): معمولاً تولیدکنندگان دارو با چالش اعتبارسنجی تاثیر داروی خاص بر روی مجموعه بزرگی از جمعیت روبهرو هستند. به این دلیل، این اتفاق رخ میدهد که داروها فقط روی گروه کوچکی از افراد و در کلینیک داروسازی تست شدهاند و ممکن است در برخی از افراد جامعه واقعی عوارض جانبی دیگری داشته باشند.
برای حل و رسیدگی به مسائل فوق، شرکتهای زیادی از جمله Genentech با شرکت هوش مصنوعی مانند GNS Healthcare همکاری کردهاند تا از یادگیری ماشین و شبیهسازهای پلتفرمهای هوش مصنوعی استفاده کنند و به درمانهای زیست پزشکی با توجه به نوآوریهای جدید رسیدگی کنند. فناوریهای ماشین لرنینگ با استفاده از تجزیه و تحلیل ژنهای افراد، روشهای منحصربهفردی را برای درمان هر بیمار ارائه میدهند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی استفاده از ماشین لرنینگ در بخشهای مالی پرداخته شده است.
استفاده از ماشین لرنینگ در بخش مالی
امروزه، بسیاری از سازمانها و بانکها از فناوریهای ماشین لرنینگ برای مقابله با فعالیتهای کلاهبرداری و به دست آوردن دیدگاههای ضروری نسبت به حجم وسیعی از دادهها استفاده میکنند. به عبارت دیگر میتوان گفت حوزه «مالی» (Finance) به یکی از حوزههای بسیار پرطرفدار و پرکاربرد هوش مصنوعی و ماشین لرنینگ تبدیل شده است. دیدگاههایی که به وسیله ماشین لرنینگ به دست آمدهاند به شناسایی فرصتهای سرمایهگذاری کمک خواهند کرد و میتوانند برای سرمایهگذران زمان مناسب جهت معامله را پیشنهاد دهند.
علاوه بر این، روشهای دادهکاوی به سیستمهای «نظارت سایبری» (Cyber Surveillance) این امکان را میدهند تا علائم هشداردهنده فعالیتهای تقلبی و کلاهبرداری به صفر برسند و تا جایی که امکان دارد آنها را خنثی کنند. در حال حاضر بسیاری از شرکتهای مالی از فناوریهای ماشین لرنینگ در فعالیتهای خود استفاده میکنند. برای مثال میتوان به دو مورد زیر اشاره کرد:
- بانک Citibank با شرکت تشخیص تقلب Feedzai برای مدیریت و رسیدگی به کلاهبرداریهای بانکی حضوری و آنلاین همکاری میکند.
- شرکت PayPal از ابزراهای ماشین لرنینگ زیادی برای تشخیص تفاوت بین تراکنشهای قانونی و تقلبی فروشندگان و خریداران استفاده میکند.
بخش بعدی از مطلب «ماشین لرنینگ چیست» به شرح استفاده از ماشین لرنینگ در بخش فروشگاهی اختصاص دارد.

استفاده از ماشین لرنینگ در بخش فروشگاهی
معمولاً «وب سایتهای فروشگاهی» (Retail Website) به طور گستردهای از روشهای ماشین لرنینگ برای پیشنهاد دادن خرید اجناس خود در وب سایت بر اساس خریدهای قبلی و جستجوهای کاربران استفاده میکنند. در فروشگاههای اینترنتی از روشهای ماشین لرنینگ برای دریافت دادهها، تجزیه و تحلیل آنها و ارائه پیشنهادات خرید به صورت شخصی و بر اساس تجربیات خرید هر مشتری استفاده میشود.

همچنین آنها از پیادهسازی ماشین لرنینگ برای بازاریابی، دیدگاه مشتریان، برنامهریزی خرید کالا توسط مشتری و بهینهسازی قیمت استفاده میکنند. بر اساس گزارشهای سال ۱۴۰۰ شمسی (۲۰۲۱ میلادی) توسط موسسه «Grand View Research» انتظار میرود که بازار جهانی موتورهای توصیهای تا سال ۱۴۰۷ شمسی (۲۰۲۸ میلادی) به ارزشی معادل با ۱۷٫۳ میلیارد دلار برسد. در ادامه مثالهای رایجی از «سیستمهای توصیهگر» (Recommender | Recommendation System) ارائه شدهاند:
- زمانی که موردی توسط فردی در وب سایت آمازون جستجو میشود، محصولاتی که در نتیجه جستجوی فرد در صفحه نمایش نشان داده شدهاند توسط الگوریتمهای ماشین لرنینگ انتخاب میشوند. شرکت آمازون از شبکههای عصبی مصنوعی برای ارائه توصیههای شخصی و هوشمند مرتبط با هر مشتری بر اساس تاریخچه خریدهای قبلی آنها، نظرات، محصولات نشانهگذاری شده و دیگر فعالیتهای آنلاین استفاده میکند.
- وب سایتهای نتفیلیکس و یوتوب در حد زیادی به سیستمهای توصیهگر برای نشان دادن فیلمها و ویدیوها به کاربران بر اساس سابقه بازدیدهای اخیر آنها متکی هستند.
به علاوه، وب سایتهای فروشگاهی، به «دستیارهای مجازی» (Virtual Assistant) یا چتباتهای مکالمهای مجهز هستند و این سیستمها از ماشین لرنینگ، پردازش زبان طبیعی و «درک زبان طبیعی» (Natural Language Understanding | NLU) برای خودکارسازی تجربه خرید مشتری استفاده میکنند. بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی استفاده از ماشین لرنینگ در صنعت گردشگری اختصاص داده میشود.
استفاده از ماشین لرنینگ در صنعت گردشگری
ماشین لرنینگ نقش گستردهای در گسترش صنعت گردشگری ایفا میکند. سیستمهای مسافربری و گردشگری از جمله Uber ،Ola و حتی خودروهای خودران، سیستمهای ماشین لرنینگ قدرتمندی دارند. برای مثال الگوریتمهای ماشین لرنینگ در نرم افزارهای مسافربری مجازی مانند اوبر جهت محاسبه و مدیریت هزینههای سفر به صورت پویا از الگوریتمهای ماشین لرنینگ استفاده میکنند. اوبر از مدل یادگیری ماشینی به نام «Geosurge» برای مدیریت پویا پارامترهای هزینهها استفاده میکند. این الگوریتم از مدلهای پیشبینی در زمان واقعی بر روی الگوهای ترافیک، عرضه و تقاضا استفاده کرده است.
برای مثال، اگر فردی عجله دارد به مقصدی در مسیری شلوغ برسد، با استفاده از قیمتگذاری پویا برنامه اوبر، باید هزینه بیشتری برای رسیدن به مقصد خود نسب به زمانی بپردازد که مسیر خلوت است. به علاوه، این حوزه از ماشین لرنینگ برای بررسی نظرات کاربران نیز استفاده بسیاری میشود. نظرات کاربران از طریق تجزیه و تحلیل احساسات بر اساس نمرات مثبت و منفی آنها استفاده خواهد شد. نظرات برای نظارت بر سفر، نظارت بر برند، نظارت بر انطباق و سایر موارد توسط شرکتهای صنعت گردشگری مورد استفاده قرار میگیرند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی استفاده از ماشین لرنینگ در شبکههای رسانه اجتماعی پرداخته شده است.

استفاده از ماشین لرنینگ در رسانه های اجتماعی
با استفاده از ماشین لرنینگ، میلیونها کاربر میتوانند به صورت بسیار کارآمد با شبکههای اجتماعی مشارکت داشته باشند. ماشین لرنینگ در هدایت پلتفرمهای رسانههای اجتماعی اعم از شخصیسازی فیلدهای خبری تا ارائه تبلیغات خاص کاربر نقش پر رنگی دارد. برای مثال، ویژگی برچسبگذاری خودکار فیسبوک از روشهای تشخیص تصویر برای شناسایی چهره افراد و برچسبگذاری آنها استفاده میکند. رسانههای اجتماعی از شبکههای عصبی مصنوعی برای تشخیص چهرههای آشنا در فهرست مخاطبیان افراد استفاده میکنند و به صورت خودکار برچسبگذاری انجام میدهند.
در مثالی دیگر، به طور مشابه میتوان گفت در شبکه اجتماعی لینکدین، اینکه در چه زمانی چه درخواستی داده شود، بهتر است با چه کسی ارتباط برقرار کرد و سطح مهارتهای فرد نسبت به افراد مشابه خود را نشان میدهد. همه این ویژگیها با استفاده از ماشین لرنینگ انجام میشوند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تفاوت بین ماشین لرنینگ و داده کاوی پرداخته شده است.
تفاوت داده کاوی و ماشین لرنینگ
مفاهیم داده کاوی و ماشین لرنینگ تفاوتهای مشهودی با یکدیگر دارند، اما به دلیل همپوشانی دادههای آنها، اشتباه گرفتن این دو امری طبیعی است. تعداد تفاوتهای این دو اصطلاح هوش مصنوعی قابل توجه هستند که در این بخش برخی از این موارد مورد بررسی قرار میگیرند. ابتدا پیش از پرداختن به تفاوتهای ماشین لرنینگ و داده کاوی، مفهوم داده کاوی بررسی میشود.

داده کاوی چیست؟
داده کاوی پردازشی است که با استفاده از آن میتوان اطلاعات مفیدی را از حجم وسیعی از دادهها استخراج کرد. این رویکرد برای کشف الگوهای جدید، با دقت بالا و به صورت کارآمد در دادهها استفاده میشود. از داده کاوی برای جستجو معنا اطلاعاتی خاص یا اطلاعاتی استفاده شده است که فردی به آنها نیاز دارد. حال پس از شرح تعریف داده کاوی، در ادامه مطلب «ماشین لرنینگ چیست» برخی از تفاوتهای ماشین لرنینگ و داده کاوی مورد بررسی قرار میگیرند.

تفاوت داده کاوی و ماشین لرنینگ در زمان کشف هر یک از آن ها چیست؟
داده کاوی دو دهه قبلتر از ماشین لرنینگ ارائه شده است. داده کاوی در ابتدای ظهور خود «کشف دانش در پایگاه داده» (Knowledge Discovery In Database | KDD) نامیده میشد و همچنان در برخی از موارد داده کاوی کشف دانش در پایگاه داده نامیده میشود. یادگیری ماشین برای اولین بار در یک بازی شطرنج و در سال ۱۳۲۹ شمسی (۱۹۵۰ میلادی) و داده کاوی برای اولین بار در سال ۱۳۰۹ شمسی (۱۹۳۰ میلادی) ارائه شدند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تفاوت هدف ماشین لرنینگ و داده کاوی پرداخته شده است.
تفاوت داده کاوی و ماشین لرنینگ در هدف آن ها چیست؟
داده کاوی برای استخراج قانون و اطلاعات از حجم زیادی از دادهها طراحی شده است، در حالی که ماشین لرنینگ به کامپیوترها آموزش میدهد که چگونه پارامترهای داده شده را یاد بگیرند. یا به عبارت دیگر، داده کاوی را میتوان به عنوان روشی ساده برای جستجو و تشخیص خروجیهای خاص بر اساس دادههای جمعآوری شده در نظر گرفت و ماشین لرنینگ، برای آموزش سیستمها جهت انجام وظایف پیچیده ایجاد شده است و از دادهها و تجربیات جمعآوری شده برای هوشمند شدن سیستمها استفاده میکند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تفاوت ماشین لرنینگ و داده کاوی در کاربردشان پرداخته شده است.

تفاوت داده کاوی و ماشین لرنینگ در کاربردهایشان چیست؟
داده کاوی از دادههای با حجم بزرگ یا با اصطلاح کلان دادهها استفاده میکند و این دادهها اکثراً برای پیشبینیهای وظایف کسب و کارها و سازمانهای مختلف مورد استفاده قرار میگیرند. اما ماشین لرنینگ معمولاً با استفاده از الگوریتمها کار خود را انجام میدهد و دادههای خام در آن کاربردی ندارند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی عامل انسانی در تفاوت ماشین لرنینگ و داده کاوی پرداخته شده است.
عامل انسانی در تفاوت داده کاوی با ماشین لرنینگ چیست؟
در این بخش یک تفاوت بسیار قابل توجه مورد بررسی قرار میگیرد. داده کاوی به مداخله انسان وابسته است و برای استفاده توسط کاربران ایجاد میشود. در حالی که، همه دلیل وجود ماشین لرنینگ این است که میتواند دادههای مرتبط به خود را آموزش دهد و به تأثیر اعمال انسان وابسته نیست. داده کاوی بدون وجود انسان نمیتواند به تنهایی کاری را انجام دهد. اما ارتباط انسان با ماشین لرنینگ تقریبا در حد تنظیم الگوریتمهای اولیه برای پیادهسازی آنها است. در بخش بعدی از مطلب «ماشین لرنینگ چیست» ارتباط بین داده کاوی و ماشین لرنینگ مورد بررسی قرار میگیرد.
ماشین لرنینگ و داده کاوی چه ارتباطی با یکدیگر دارند؟
میتوان گفت داده کاوی فرایندی به حساب میآید که شامل دو مولفه «مجموعه داده» و «ماشین لرنینگ» است. مجموعه داده روشهای مدیریت داده را انجام میدهد و ماشین لرنینگ روشهای تجزیه و تحلیل دادهها را برای داده کاوی انجام میدهد. بنابراین با استفاده از این موارد میتوان به این نتیجه رسید که داده کاوی به ماشین لرنینگ نیاز دارد، اما ماشین لرنینگ نیاز ضروری به داده کاوی نخواهد داشت. البته مواردی در ماشین لرنینگ نیز وجود دارند که در آنها از داده کاوی برای بررسی ارتباط میان دادهها استفاده میشود.
در نتیجه، اطلاعات جمعآوری شده از طریق داده کاوی میتواند برای کمک به ماشین لرنینگ استفاده شود، اما ضروری نیست. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تفاوت ماشین لرنینگ و داده کاوی در توانایی یادگیری آنها پرداخته شده است.

تفاوت ماشین لرنینگ و داده کاوی در توانایی یادگیری آن ها
در رابطه با توانایی یادگیری، تفاوتهای مشهودی بین ماشین لرنینگ و داده کاوی وجود دارند. مسائل داده کاوی نمیتوانند آموزش ببیند و موردی را فرابگیرند، در حالی که، مهمترین مسئلهای که ماشین لرنینگ انجام میدهد، همین آموزش و یادگیری ماشینها است. داده کاوی از قوانینی استفاده میکند که پیش از این تنظیم شده باشند و این قوانین معمولاً ثابت هستند، در حالی که ماشین لرنینگ، الگوریتمها را بر اساس شرایط مناسب تنظیم میکند.
روشهای داده کاوی فقط به اندازه کاربرانی هوشمند هستند که با آن کار میکنند. اما ماشین لرنینگ به این معنی است که کامپیوترها از کاربران خود هوشمندتر هستند. بخش بعدی مطلب «ماشین لرنینگ چیست» به بررسی تفاوت ماشین لرنینگ و داده کاوی در روشهای استفاده هر یک از آنها اختصاص دارد.

تفاوت ماشین لرنینگ و داده کاوی در روش های استفاده هر یک از آن ها چیست؟
از نظر میزان سودمندی هر دو این مهارتها برای وظایف مربوط به خود مفید هستند. برای مثال، داده کاوی در مواردی استفاده میشود که نیاز است دادههای عادتهای خرید کاربران بررسی شوند تا عادتهای خرید آنها درک و در نتیجه به کسب و کار و روشهای فروش در شرکتها کمک کنند. شبکههای اجتماعی محل مناسبی برای داده کاوی به حساب میآیند؛ زیرا میتوان به راحتی از پروفایل کاربران، پرسوجوها، کلیدها و اشتراکگذاریهای کاربران دادههای مناسب داده کاوی را جمعآوری کرد. یا در مثالی دیگر میتوان گفت که داده کاوی به تولیدکنندگان کمک میکند تا دادههای مرتبط با تبلیغات را جمعآوری کنند و روی آنها تجزیه و تحلیل انجام دهند.

در بخش مسائل مالی نیز میتوان با استفاده از داده کاوی فرصتهای سرمایهگذاری و حتی احتمال موفقیت و عدم موفقیت یک شرکت استارتآپی را مورد بررسی قرار داد. جمعآوری داده و اطلاعات به سرمایهگذاران کمک میکند تا از نظر مالی بررسیهایی برای شروع و یا عدم شروع یک پروژه انجام دهند. اگر علم داده کاوی در اواسط دهه ۱۳۷۰ شمسی (۱۹۹۰ میلادی) تکمیل میشد، به راحتی میتوانست از سقوط استارتآپ اینترنت در اواخر این دهه جلوگیری کند.
با این حال، شرکتها از ماشین لرنینگ برای اهدافی از جمله ساخت ماشینهای خودران، تشخیص تقلب در کارتهای اعتباری، خدمات آنلاین به مشتری، جلوگیری از هرزنامه شدن ایمیلها به اشتباه، بازاریابی شخصی، «هوش تجاری» (Business Intelligence) مانند مدیریت تراکنشها، جمعآوری نتایج فروش و انتخاب طرح تجاری استفاده میکنند. ماشین لرنینگ در برخی از شرکتها از جمله فیسبوک، Yelp، توییتر، Pinterest ،Salesforce و موتور جستجوی گوگل مورد استفاده قرار میگیرد. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی چالشهای ماشین لرنینگ پرداخته شده است.
چالش های یادگیری ماشین
با پیشرفت فناوریهای ماشین لرنینگ، زندگی انسانها نیز سادهتر شده است. با این حال، پیادهسازی ماشین لرنینگ در کسب و کارها چالشهایی درباره فناوریهای هوش مصنوعی به وجود میآورد که در ادامه برخی از آنها مورد بررسی قرار میگیرند. ابتدا فناویهای منحصربهفرد و یکتا در ماشین لرنینگ بررسی میشوند.
منحصر به فرد بودن فناوری های یادگیری ماشین
با اینکه هوش مصنوعی توجه زیادی را به خود جلب کرده است و استفاده از روشهای ماشین لرنینگ روز به روز در حال افزایش هستند. متخصصین هوش مصنوعی اصلا نگرال این موضوع نیستند که تا چند سال آینده هوش مصنوعی یا همان «ابرهوش» (Super Intelligence) جایگزین هوش انسانی شود. این موضوع بسیار دور از واقعیت نیست و فناوریهای منحصربهفرد ماشین لرنینگ در مسیر خودکارسازی مورد استفاده فراوانی قرار میگیرند، برای مثال خودروهای خودران از مواردی هستند که به عنوان یکی از فناوریهای منحصربهفرد هوش مصنوعی میتوان به آنها اشاره کرد. در رابطه با این خودروها، به این موضوع باید توجه شود که این خودروها نیز مانند دیگر وسایل نقلیهای که توسط انسان کنترل میشوند امکان تصادف دارند.
یکی از چالشهای بزرگ این مثال این است که اگر یک خودرو خودران و بدون سرنشین دچار تصادف شود، چه کسی مسئولیت آن را بر عهده خواهد گرفت؟ مسئله این است که با وجود این چالشها هنوز هم باید تولید و پیشرفت خودروهای خودران ادامه داشته باشد یا فقط باید وسایل نقلیه نیمه خودران برای بالا بردن ایمنی رانندگان ایجاد شوند؟ هنوز در این مورد تصمیمات جدی گرفته نشده است، اما با توسعه بسیار هوش مصنوعی این موضوعات در حال بررسی هستند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی تأثیر هوش مصنوعی روی انواع مشاغل پرداخته شده است.

تأثیر هوش مصنوعی بر مشاغل
تصور عموم مردم این گونه است که با پیشرفت هوش مصنوعی و استفاده از آن در صنعت، برخی از مشاغل از دست میروند. اما این موضوع صحیح نیست و هوش مصنوعی باعث به وجود آمدن برخی مشاغل خاص دیگر میشود. در زمینه صنعت خودروسازی، بسیاری از تولیدکنندگان امروزی از جمله جنرال موتورز، روی تولید خودروهای الکترونیکی تمرکز میکنند تا ابتکارات جدیدی به وجود بیاورند. یا در مثالی دیگر میتوان گفت که صنعت انرژی در خودروسازی از بین نمیرود، اما ممکن است از انرژی سوخت به انرژی برق تغییر پیدا کند.
به عبارتی میتوان گفت که هوش مصنوعی نوع مشاغل را تغییر میدهد و تا جایی که امکان دارد، شغلی را حذف نمیکند. همچنین با رشد و تغییر دادهها، باید افرادی وجود داشته باشند که این سیستمهای جدید را مدیریت کنند و مشاغل مدیریتی از این قبیل نیز ایجاد خواهد شد. بنابراین، میتوان گفت که تقریباً هوش مصنوعی به افزایش مشاغل نیز کمک میکند. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی حریم خصوصی در ماشین لرنینگ پرداخته شده است.

تأثیر یادگیری ماشین روی حریم خصوصی
امنیت و حریم خصوصی باید روی مباحث مختلفی از جمله حریم خصوصی دادهها، محافظت از دادهها و امنیت دادهها بررسی شود. این چالشها و اهمیت این موارد باعث شده است که در سالهای اخیر گامهای بیشتری در این باره برداشته شود. برای مثال، در سال ۱۳۹۵ شمسی (۲۰۱۶ میلادی) قانون «GDPR» برای محافظت از دادههای شخصی افراد در اتحادیه و منطقه اقتصادی اروپا ایجاد و به افراد کنترل بیشتری روی دادههای خود داده شد.
در ایالات متحده، هر ایالت به صورت جداگانه در حال ایجاد و توسعه سیاستهایی برای امنیت دادهها است، برای مثال میتوان به قانون «حریم خصوصی مصرفکنندگان کالیفرنیا» (California Consumer Privacy Act | CCPA) پرداخت که مصرف کنندگان را درباره جمعآوری دادههای آنها آگاه میسازد. این قانونهای اخیر، شرکتها و سازمانها را موظف کرده است که در نحوه ذخیره و استفاده از «دادههای شناسایی شخصی» (Personally Identifiable Data | PII) تجدید نظر کنند. در نتیجه، سرمایهگذاری در حوزه امنیت به یکی از اولویتهای مهم کسب و کارها تبدیل شده است.
این حوزه به دنبال حذف هر گونه آسیبپذیری و فرصتهایی برای نظارت، هک و حملات سایبری است. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی «بایاس» (Bias) و «تبعیض» (Discrimination) در ماشین لرنینگ پرداخته شده است.
بایاس و تبعیض در یادگیری ماشین چیست ؟
نمونههای بایاس و تبعیض در سیستمهای هوش مصنوعی، سوالات زیادی را در مورد استفاده از هوش مصنوعی به وجود آورده است. بایاس و تبعیض ممکن است در انواع سیستمهای هوش مصنوعی از جمله سیستمهای منابع انسانی، تشخیص چهره و الگوریتمهای شبکههای اجتماعی رخ دهند. معمولاً تبعیض به همان بایاس مرتبط است، با این حال با وجود نقش تبعیض، بایاس همیشه به وسیله تبعیض ایجاد نمیشود. بایاس به معنی انحراف از استاندارد موردنظر است که گاهی برای شناسایی برخی الگوهای آماری در دادهها یا زبان مورد استفاده، ضروری است.
دستهبندی و یافتن تفاوت بین نمونهها بدون بایاس گاهی ممکن نیست. همچنین میتوان گفت که بایاس مقدار خطای مدل را نشان میدهد. این میزان خطا با استفاده از بررسی مقدار اختلاف بین خروجی پیشبینی شده و خروجی واقعی انجام میشود. در بخش بعدی از مطلب «ماشین لرنینگ چیست» میزان مسئولیت در این زمینه مورد بررسی قرار میگیرد.

میزان مسئولیت در یادگیری ماشین
هیچ قانون خاصی برای روشهای استفاده از الگوریتمهای هوش مصنوعی و ماشین لرنینگ وجود ندارد. اما برای ایجاد یک مسئولیت و روشهای مشخص جهت استفاده از هوش مصنوعی، فریم ورکهایی مختص به آن ایجاد شدهاند، اما هنوز هم این مسئله دارای چالشهایی است. در بخش بعدی از مطلب «ماشین لرنینگ چیست» به بررسی این موضوع پرداخته میشود که یک مهندس ماشین لرنینگ دقیقأ چه کار میکند.
یک مهندس ماشین لرنینگ دقیقاً چه کار می کند؟
میتوان گفت یک مهندس ماشین لرنینگ، هم یک مهندس نرم افزار و هم یک دانشمند داده است. این مهندس میتواند از مهارت خود در جمعآوری، پردازش و تجزیه و تحلیل دادهها استفاده کند. مهندسان ماشین لرنینگ کسانی هستند که الگوریتمهایی را ایجاد میکنند و با استفاده از آنها، مدلها را پیشبینی میکنند تا بتوانند دادههای موجود را سازماندهی کنند. سیستمهای ماشین لرنینگ میتوانند با هر مجموعه داده بزرگ دیگری استفاده شوند که در پردازش وجود دارند.

برای مثال، رباتی که در یک کسب و کار خاص برای اهدافی مانند چت و جمعآوری دادهها استفاده میشود، توسط مهندسان ماشین لرنینگ ساخته شده است. یا استفاده از هر الگوریتمی که برای مرتبسازی دادههای مربوطه مورد استفاده قرار میگیرد، وظیفه مهندس ماشین لرنینگ در نظر گرفته میشود. آنها معمولاً به مقیاسپذیری مدلهای پیشبینی کمک میکنند تا حجم دادههای مرتبط با کسب و کار موردنظر بررسی شود و با هدف مسئله مطابقت داشته باشد. برخی از وظایف یک مهندس ماشین لرنینگ در ادامه ارائه شده است:
- یکی از وظایف مهندسان ماشین لرنینگ، توسعه، آموزش و نگهداری سیستمهای ماشین لرنینگ است.
- انجام تجزیه و تحلیلهای آماری و بررسی نتایج آزمایشها توسط مهندسان ماشین لرنینگ انجام میشوند.
- تلاش برای انجام آزمایشهای ماشین لرنینگ و گزارش دادن نتایجی که در این راستا به دست آمدهاند از وظایف یک مهندس ماشین لرنینگ است.
- توسعه سیستمهای یادگیری عمیق برای روشهای مبتنی بر مواردی که یک کسب و کار به آنها نیاز دارد، توسط مهندسان ماشین لرنینگ در یک شرکت انجام میشود.
- پیادهسازی الگوریتمهای هوش مصنوعی و ماشین لرنینگ از وظایف یک مهندس ماشین لرنینگ است.
در بخش بعدی به بررسی مهارتهایی پرداخته شده است که برای تبدیل شدن به یک مهندس ماشین لرنینگ نیاز هستند.
مهارت های لازم برای تبدیل شدن به یک مهندس یادگیری ماشین
برخی از مهارتهایی فنی که برای تبدیل شدن به یک مهندس ماشین لرنینگ نیاز است، در ادامه فهرست شدهاند:
- مهارتهای مهندسی نرم افزار: برخی از مهارتهای علوم کامپیوتر و نرم افزار که یک مهندس ماشین لرنینگ باید به آنها تسلط داشته باشد، شامل نوشتن الگوریتمهایی است که میتوانند جستجو، «مرتبسازی» (Sorting) و بهینهسازی کنند، آشنایی با الگوریتمهای «تقریبی» (Approximate)، درک ساختمان دادهها از جمله «پشته» (Stack)، «صف» (Queue)، گراف، درخت و آرایههای چند بعدی، درک قابلیت محاسبه، پیچیدگی و علم معماری کامپیوتر از جمله حافظه، «خوشهها» (Cluster)، «پهنای باند» (Bandwidth)، «بنبستها» (Deadlock) و «کَش» (Cache) است.
- مهارتهای دانشمند داده: برخی از مهارتهای علم داده که مهندسان ماشین لرنینگ بهتر است با آنها آشنایی داشته باشند، شامل آشنایی با زبانهایی از جمله «پایتون» (Python)، SQL و «جاوا» (Java)، «تست فرضیه» (Hypothesis Testing)، مدلسازی دادهها، ریاضیات، مفاهیم آمار و احتمال از جمله «دستهبند بیز ساده» (Naive Bayes Classifier)، احتمال شرطی، معیار درستنمایی، قانون بیز، شبکه بیزی، «مدل مارکوف مخفی» (Hidden Markov Model) و سایر موارد است.
در بخش بعدی به بررسی مهارتهای «نرم» (Soft) مورد نیاز برای تبدیل شدن به یک مهندس ماشین لرنینگ پرداخته شده است.
چه مهارتهای نرمی برای فعالیت شغلی در زمینه ماشین لرنینگ مورد نیاز هستند؟
در این بخش به بررسی برخی از مهارتهای نرم برای تبدیل شدن به یک مهندس ماشین لرنینگ پرداخته شده است که در ارتباط با تواناییهای برقراری ارتباط افراد هستند. در ادامه 6 مهارت نرم فهرست شدهاند که هر توسعه دهنده یادگیری ماشین باید آنها را بداند:
- مهارتهای ارتباطی: اینکه مهندسان ماشین لرنینگ با دانشمندان و «تحلیلگران داده» (Data Analyst)، مهندسان نرم افزار، پژوهشگران، تیمهای بازاریابی و محصول ارتباط داشته باشند، اصلا مسئله غیر معمولی به حساب نمیآید. بنابراین توانایی ارتباط برقرار کردن با سهاداران پروژه درباره اهداف، زمان و انتظارات پروژه بخشی مهمی از این موقعیت شغلی را دربرمیگیرد.
- مهارتهای حل مسئله: توانایی حل مسائل برای دانشمندان داده و مهندسان نرم افزار بسیار حائز اهمیت است و برای مهندسان ماشین لرنینگ مسئلهای ضروری به حساب میآید. تمرکز ماشین لرنینگ روی چالشهای بلادرنگ است. بنابراین تفکر انتقادی و خلاقانه در مورد مسائلی که به وجود میآیند و ایجاد راه حلهایی برای آنها یکی از مهارتهای اساسی مورد نیاز مهندسان ماشین لرنینگ است.

- دامنه دانش: برای طراحی نرم افزارهای خودکار و بهینهسازی راه حلهای مورد استفاده توسط کسب و کارها و مشتریان، لازم است که مهندسان ماشین لرنینگ نیازهای کسب و کار و نوع مسئلهای را درک کنند که طراحی و حل میشوند. بدون داشتن دامنه دانش وسیع، توصیههای مهندسان یادگیری ماشین برای یک مسئله ممکن است دقیق نباشند و ویژگیهای مفید نادیده گرفته شوند و همچنین، ارزیابی یک مدل دشوار شود.
- مدیریت زمان: معمولاً مهندسان ماشین لرنینگ همه خواستههای کارفرماهای خود را حل میکنند، اما برای حل این مسائل در بهترین زمان ممکن بهتر است که تحقیقات، سازماندهی، برنامهریزی، طراحی نرم افزار و تست پروژه دارای مدیریت زمانی باشند. توانایی مدیریت زمان یکی از مهارتهای کلیدی است که مهندس ماشین لرنینگ میتواند برای پروژه داشته باشد.
- کار گروهی: در بیشتر اوقات مهندسان ماشین لرنینگ در یک پروژه هوش مصنوعی برای سازمانی کار میکنند، بنابراین میتوان گفت که به طور اجتناب ناپذیری با دانشمندان داده، مهندسان نرم افزار، بازاریابها، طراحهای محصول، مدیران محصول و آزمایش کنندگان در ارتباط هستند. توانایی کمک به دیگران و کار کردن در یک محیط کاری گروهی، مهارتی است که بسیاری از مدیران در هنگام استخدام مهندس ماشین لرنینگ به آن توجه میکنند و به دنبال فردی با روحیاتی اجتماعی همراه با این توانایی هستند.

- تشنه یادگیری: فیلد هوش مصنوعی، یادگیری عمیق، ماشین لرنینگ و علم داده به سرعت در حال تحول است و کسانی که در این زمینه فارغالتحصیل شدهاند یا به عنوان مهندس ماشین لرنینگ کار میکنند، بهتر است که همیشه مسیری را برای بالا بردن دانش خود از طریق بوتکمپها، کارگاهها، مطالعه خودآموز و سایر موارد در نظر بگیرند. این یادگیریها میتوانند شامل یادگیری یک زبان برنامه نویسی جدید، تسلط بر ابزارها و برنامههای جدید، مطالعه آخرین فناوریها و روشهای پیشرفت باشد. بهترین مهندسان ماشین لرنینگ کسانی هستند که دائما جعبه ابزار خود را بروز میکنند و توانایی یادگیری مهارتهای جدید را دارند.
جمعبندی
به طور کلی میتوان گفت که ماشین لرنینگ امکان تجزیه و تحلیل مقادیر حجیمی از دادهها را فراهم میکند. امروزه، ماشین لرنینگ در اکثر صنایع و کسب و کارها مورد استفاده قرار میگیرد و تصمیمات بسیار تاثیرگذار دنیای امروز بر اساس پردازشهای انجام شده روی دادهها و نتایج حاصل از آنها اتخاذ میشود. در سالهای اخیر پیشرفتهای چشمگیری در زمینه یادگیری ماشین به وقوع پیوسته است. بنابراین، باید گفت که این علم، چشماندازی جذاب و جالب توجه را در ذهن جهانیان ایجاد کرده و یادگیری آن موقعیتهای علمی و شغلی فراوانی را به همراه دارد.
در مطلب «ماشین لرنینگ چیست» سعی شد به طور کامل به بررسی مفاهیم ماشین لرنینگ و سایر موارد در ارتباط با آن پرداخته شود. همچنین تفاوت آن با یادگیری عمیق و داده کاوی نیز به طور جامع بررسی شد. در نهایت به چالشها و وظایف یک مهندس ماشین لرنینگ پرداخته شده است. در این مطلب برخی از آموزشهای مرتبط با ماشین لرنینگ هم برای علاقهمندان و دانشجویان این حوزه معرفی شدهاند.








تشکر
با درود واقعا مقاله مفصل و کاربردی بود
عالی, واقعا کاربردی بود