



نقشه دانش فناوری های هوش مصنوعی و دسته بندی آنها – راهنمای جامع
شاید برای بسیاری انسانها، درک این واقعیت که روزانه با انواع مختلفی از فناوری های هوش مصنوعی (روشها، برنامههای کاربردی و دستگاهها) در حال تعامل هستند، کار سختی باشد. اما واقعیت این است که امروزه، بسیاری از کارهایی که انسانها برای فعالیتهای روزمره خود به آنها نیاز دارند، بدون وجود فناوری های «هوش مصنوعی» (Artificial Intelligence) ممکن نیستند. شما، به عنوان کاربر، زمانی که این مطلب را در صفحات موتور جستجوی گوگل پیدا کردید و وارد آن شدید، بدون شک از فناوری های هوش مصنوعی استفاده کردهاید. زمانی که برای یافتن آدرس مورد نظر خود، از نرمافزارهای مسیریاب تلفن همراه خود استفاده میکنید، در اصل از روشهای هوش مصنوعی استفاده میکنید. اگر شما به ویژگیهای یک «ربات انساننما» (Humanoid Robots) علاقهمند باشید، در اصل به ویژگیهای هوش مصنوعی آن علاقه دارید. هر زمان که از سرویس ترجمه آنلاین گوگل یا دیگر سرویسهای مشابه استفاده کنید یا به صورت آنلاین با دوستان خود ارتباط برقرار کنید و یا به جستجو در سطح وب بپردازید، از فناوری های هوش مصنوعی استفاده کردهاید. بنابراین، درک تاثیر فناوری های هوش مصنوعی بر فعالیتهای روزانه انسانها، کار چندان سختی نیست.




در این مطلب، سعی بر این است تا ابتدا تعریفی از فناوری های هوش مصنوعی، دستهبندیهای آن و تعریف مختصری از هر کدام از شاخههای هوش مصنوعی ارائه شود. در ادامه، نقشه دانش فناوری های هوش مصنوعی ارائه خواهد شد.
هوش مصنوعی چیست؟
اگر بخواهیم تعریف سادهای از هوش مصنوعی داشته باشیم، میتوان هوش مصنوعی را در قالب شبیهسازی فرآیندهای هوش انسانی توسط ماشینها، به ویژه سیستمهای کامپیوتری، تعریف کرد. این فرآیندها میتواند شامل «یادگیری» (Learning)، «استدلال» (Reasoning) و «خود اصلاحی» (Self Correction) باشند. منظور از یادگیری، فرآیند تصاحب (یا تغییر) دانش، اطلاعات، قوانین، مقادیر یا ترجیحات جدید (یا موجود) در جهت بهبود تعامل با محیط عملیاتی است.
استدلال، به استفاده از قوانین برای رسیدن به نتایج «تقریبی» (Approximate) یا «قطعی» (Definite) اطلاق میشود. «آلن تورینگ» (Alan Turing)، که به او لقب پدر «علوم کامپیوتر نظری» (Theoretical Computer Science) و هوش مصنوعی داده شود، هوش مصنوعی را به عنوان «علم و مهندسی ساختن ماشینهای هوشمند، به ویژه برنامههای کامپیوتری هوشمند» تعریف کرده است.
انواع فناوری های هوش مصنوعی
انواع فناوری های هوش مصنوعی را میتوان به دو روش مختلف دستهبندی کرد. در روش اول، فناوری های هوش مصنوعی بر اساس قابلیتها، نحوه کاربرد و دامنه مسائلی که میتواند در آن اقدام به حل مسأله کنند، دستهبندی میشوند. در روش دوم، فناوری های هوش مصنوعی بر اساس ویژگیها و قابلیتهای ذاتی به گروههای مختلف دستهبندی میشوند.
دستهبندی نوع اول
در این دستهبندی، فناوری های هوش مصنوعی به دو گروه «هوش مصنوعی ضعیف» (Weak Artificial Intelligence) و «هوش مصنوعی عمومی» (General Artificial Intelligence) یا «هوش مصنوعی قوی» (Strong Artificial Intelligence) دستهبندی میشوند:
- «هوش مصنوعی ضعیف» (Weak Artificial Intelligence): سیستم هوش مصنوعی است که برای انجام وظایف خاصی ساخته شده و آموزش دیده است. بسیاری از سیستمهای کامپیوتری هوشمند کنونی که ادعا میکنند از فناوری های هوش مصنوعی برای انجام وظایف خود استفاده میکنند، در این دستهبندی قرار میگیرند و برای حل مسائل خاص و دامنه بسیار محدود استفاده میشوند. این دسته از فناوری های هوش مصنوعی، در نقطه مقابل هوش مصنوعی قوی یا عمومی قرار دارند. دستیارهای شخصی مجازی نظیر «سیری» (Siri) شرکت «اپل» (Apple) از جمله چنین سیستمهایی هستند.
- «هوش مصنوعی عمومی» (General Artificial Intelligence): سیستم هوش مصنوعی است که که ظرفیت فهمیدن یا یادگیری هر کار فکری را (که توسط انسان قابل انجام است) دارند. به عبارت دیگر، در چنین سیستمهایی، «قابلیتهای شناختی» (Cognitive Abilities) انسانی به ماشینها تعمیم داده شدهاند. چنین سیستمهایی، وقتی که با وظایف ناآشنا روبرو میشوند، بدون دخالت انسانی قادر به یافتن جواب مسأله خواهند بود. این سیستمها، هنوز در مرحله تحقیق قرار دارند و تاکنون، نمونهای از چنین سیستمهایی ساخته نشده است.
دستهبندی نوع دوم
در این دستهبندی، فناوری های هوش مصنوعی بر اساس ویژگیها و قابلیتهای ذاتی به چهار دسته تقسیمبندی میشوند. این دستهبندیها عبارتند از:
- «ماشینهای واکنشگرا» (Reactive Machines): این دسته، ساده ترین شکل فناوری های هوش مصنوعی است. این دسته از فناوری های هوش مصنوعی، حافظه ندارند؛ نمیتوانند یادگیری کنند و قادر به استفاده از اطلاعات گذشته برای انجام وظایف آینده نیستند. این سیستمها، در هر مرحله، تمامی راههای ممکن برای حل مسئله را میسنجند. سپس، بهترین استراتژی ممکن را انتخاب میکنند.
- «ماشینهای با حافظه محدود» (Limited Memory): این دسته از فناوری های هوش مصنوعی قادرند از اطلاعات گذشته، برای تصمیمگیری در مورد وظایف آینده استفاده کنند. برخی از قابلیتهای تصمیمگیری موجود در «اتومبیلهای خودران» (Self-Driving Automobiles)، به این شکل طراحی شدهاند. مشاهدات انجام شده و اطلاعات بهدست آمده از وضعیتهای پیشین، در تصمیمگیریهایی که در آینده اتخاذ میشوند، دخیل هستند (نظیر تعویض خطوط رانندگی توسط اتومبیل). مشاهدات انجام شده، به طور دائم ذخیره نمیشوند.
- «نظریه ذهن» (Theory of Mind): این دسته از هوش مصنوعی، توانایی فهمیدن احساسات، عقاید، افکار و توقعات انسانها را خواهد داشت و میتواند تعاملات اجتماعی با انسانها داشته باشد. اگرچه تاکنون تحقیقات زیادی در این زمینه انجام شده است، اما، تاکنون این دسته از فناوری های هوش مصنوعی، به واقعیت مبدل نشدهاند.
- «هوش خودآگاهی» (Self-Awareness Intelligence): سیستم هوش مصنوعی است که هوشیاری، هوش فوقالعاده، خودآگاهی و احساس داشته باشد؛ به عبارت دیگر، یک انسان کامل باشد. چنین سیستمهایی وجود خارجی ندارند و پیادهسازی آنها، نقطه عطف و مقصد نهایی حوزه هوش مصنوعی محسوب میشوند.
نقشه دانش فناوری های هوش مصنوعی
هدف از ارائه نقشه دانش فناوری های هوش مصنوعی، ایجاد فضایی جدید برای درک عمق و پیچیدگی حوزه فناوری های هوش مصنوعی است. در این راستا، نقشه دانش، یک معماری برای مدلسازی و دسترسی به دانش در حوزه فناوری های هوش مصنوعی و زمینههای کاربردی پویای آن فراهم میکند.
نقشه دانش پیش رو میتواند به عنوان مدخلی برای دسترسی به دانش موجود در حوزه هوش مصنوعی نیز تلقی شود. چنین رویکردی، به خوانندگان و محققان اجازه میدهد تا منابع مختلف را برای دستیابی به اطلاعات اضافی جستجو کنند و در نهایت دانش جدیدی در این حوزه تولید کنند. به همین خاطر، به این مدل، نقشه دانش فناوری های هوش مصنوعی گفته میشود. شکل زیر، نقشه دانش فناوری های هوش مصنوعی را نشان میدهد.
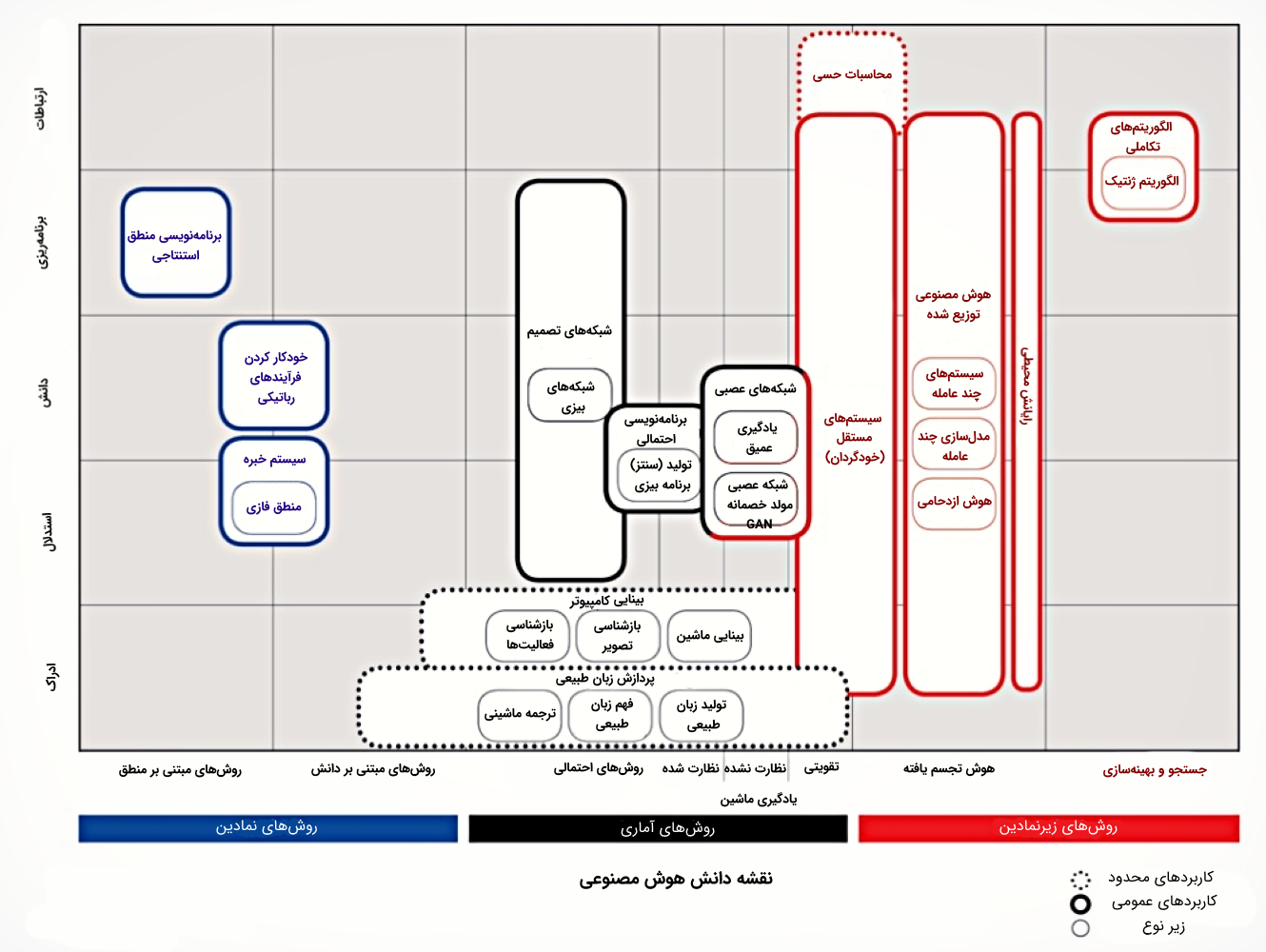
در شکل بالا، گروهبندی کلان فناوری های هوش مصنوعی در محورهای افقی و عمودی نمایش داده شده است. محور افقی، «الگوهای هوش مصنوعی» (Artificial intelligence Paradigms) را نمایش میدهد. الگوهای هوش مصنوعی، رویکردهایی هستند که برای حل مسائل مرتبط با هوش مصنوعی، توسط محققین و فعالان این حوزه مورد استفاده قرار میگیرند. محور عمودی، «دامنه مسائل هوش مصنوعی» (Artificial Intelligence Problem Domain) را نمایش میدهد. دامنه مسائل هوش مصنوعی، انواع مسائلی را نشان میدهد که توسط فناوری های هوش مصنوعی قابل حل هستند. دامنه مسائل هوش مصنوعی، به نوعی، قابلیتهای یک الگوریتم هوش مصنوعی را نیز نمایش میدهد.
دامنه مسائل هوش مصنوعی
محور عمودی، دستهبندی مسائلی را نمایش میدهد که توسط فناوری های هوش مصنوعی قابل هستند. دستهبندی ارائه شده از مسائل هوش مصنوعی، استاندارد این حوزه است.
- «استدلال» (Reasoning): استفاده از قوانین، روابط، مجموعهها و قضایای موجود در علم منطق برای حل مسائل پیچیده در حوزه فناوری های هوش مصنوعی نظیر تشخیص پزشکی و ایجاد زبان طبیعی توسط کامپیوتر
- «دانش» (Knowledge): قابلیت نمایش و فهم محیط پیرامون برای ایجاد چارچوبهای لازم برای حل مسئله
- «برنامهریزی» (Planning): قابلیت تعریف اهداف و انجام مرحله به مرحله فعالیتهای لازم برای رسیدن به آنها
- «ارتباطات» (communication): قابلیت شناختن زبان (منظور، زبان طبیعی انسانها) و ارتباط برقرار کردن از این طریق
- «ادراک» (Perception): قابلیت تبدیل کردن ورودیهای خام حس شده (نظیر تصویر، صدا و سایر موارد) به اطلاعات مفید و قابل استفاده برای حل مسائل.
الگوهای هوش مصنوعی
در این بخش، الگوهای هوش مصنوعی و یا به عبارت دیگر، روشهای حل مسائل در فناوری های هوش مصنوعی، مورد بررسی قرار گرفته و تعریف میشوند. در ابتدا، هر کدام از الگوهای هوش مصنوعی تعریف میشوند.
در بخشهای بعدی، طبقهبندی الگوریتمهای شناخته شده هوش مصنوعی شرح داده شده و هر کدام از الگوریتمها تعریف میشوند.
- ابزارهای مبتنی بر منطق (Logic-based): این ابزارها، برای نمایش دانش در دامنه مسائل هوش مصنوعی و حل مسائل هوش مصنوعی استفاده میشوند.
- ابزارهای مبتنی بر دانش (Knowledge-based): این ابزارها، مبتنی بر «آنتولوژی» ( Ontology | هستانشناسی) و پایگاههای دانش ساخت یافته عظیم (متشکل از مفاهیم، تعاریف، اطلاعات و قوانین) هستند.
- روشهای احتمالی (Probabilistic Methods): روشها و ابزارهایی هستند که به عوامل درگیر در محیط مسأله اجازه میدهند که در سناریوهای حاوی «اطلاعات ناکامل» (incomplete Information)، به حل مسأله بپردازند.
- یادگیری ماشین (Machine Learning): ابزارهایی هستند به الگوریتمهای کامپیوتری اجازه میدهند تا بتوانند الگوها و مدلهای دادهای را یاد بگیرند.
- هوش تجسمیافته (Embodied Intelligence): ابزارهای مهندسی هستند که فرض میکنند شکلگیری یک بدنه (و یا حداقل یک مجموعه جزئی از قابلیتها نظیر حرکت، ادراک، تعامل و بصریسازی) برای تولید یک هوش مصنوعی کامل و یا یک موجودیت با هوش بالاتر الزامی است.
- جستجو و بهینهسازی (Search and Optimization): با استفاده از چنین ابزارهایی، امکان پیادهسازی روشهای هوشمند جستجو در فضای جوابهای مسأله (با قابلیت تولید بیش از یک جواب برای مسأله) فراهم میآید.
تمامی الگوهای شرح داده شده، در یک طبقهبندی دیگر نیز قرار میگیرند:
- رویکردهای نمادین (Symbolic Approaches): این رویکردها در شکل بالا با رنگ آبی نمایش داده شدهاند. این دسته از رویکردها بیان میکنند که هوش انسانی، قابلیتها و عملکردهای آن از طریق روشهای نمادین (مانند نظریه منطق فازی) قابل تعریف و دستکاری هستند.
- رویکردهای زیر-نمادین (Sub-Symbolic Approaches): این رویکردها در شکل بالا با رنگ قرمز نمایش داده شدهاند. در این رویکردها، هیچ نوع خاصی از نمایش دانش دامنه، پیش از پیادهسازی الگوریتمهای هوش مصنوعی در دسترس نیست.
- رویکردهای آماری (Statistical Approaches): در این رویکرد، از روشها و ابزارهای آماری برای حل مسائل حوزه هوش مصنوعی استفاده میشود.
طبقهبندی الگوریتمهای شناخته شده هوش مصنوعی
در این بخش، سعی شده است تا دستهبندیهایی که از الگوریتمهای هوش مصنوعی در ادبیات موضوعی این حوزه وجود دارد، تشریح شوند و در اختیار مخاطبان قرار بگیرند.
همچنین، هر کدام از روشهای موجود در این دستهبندیها تعریف میشوند تا مخاطبان دید بهتری نسبت به این روشها پیدا کنند.

برنامهنویسی منطق استنتاجی
روشهای «برنامهنویسی منطق استنتاجی» (Inductive Logic Programming)، نمونهای از ابزارهای مبتنی بر منطق هستند. الگوریتمهای موجود در این زیر شاخه از حوزه فناوری های هوش مصنوعی، از «منطق فرمال» (Formal logic) برای نمایش حقایق و قوانین موجود در یک پایگاه داده و فرمولبندی کردن «فرضیات» (Hypothesis) مشتق شده از این پایگاه داده استفاده میکنند.
خودکار کردن فرآیندهای منطق استنتاجی (Robotic Process Automation)
در این زیر شاخه از فناوری های هوش مصنوعی، فناوریهایی قرار دارند که از طریق مشاهده عملکرد انسانها در انجام مجموعهای از وظایف خاص، لیستی از قوانین و عملیات مورد نیاز برای انجام این وظایف توسط ماشین را استخراج میکنند. عملکرد ماشین در انجام این وظایف ارزیابی و قوانین استخراج شده، در یک فرآیند بازخوردی، اصلاح میشوند.
سیستمهای خبره
«سیستمهای خبره» (Expert Systems)، نمونهای از ابزارهای مبتنی بر منطق و دانش هستند. این فناوری، مجموعهای از برنامههای کامپیوتری را شامل میشود که با استفاده از قوانین کدبندی شده در پیکره آنها، توانایی همانندسازی فرایند تصمیمگیری خبره انسانی را دارند. این دسته از سیستمها، برای حل مسائل بسیار پیچیده در حوزه هوش مصنوعی طراحی شدهاند. در این دسته از روشها، حقایق و قوانین لازم برای عملیاتی کردن سیستم، توسط قوانین (If-Then) در یک پایگاه دانش مدلسازی میشوند. سیستم خبره روی این پایگاه دانش، استنتاج منطقی انجام میدهد و از این طریق، به حل مسائل هوش مصنوعی میپردازد. مهمترین نمونه سیستمهای خبره، «سیستمهای فازی» (Fuzzy Systems) هستند.

سیستمهای فازی
سیستمهای فازی، نمونهای از سیستمهای مبتنیبر قانون (Rule-based) هستند که مقادیر متغیرهای مسئله را به یک بازه پیوستگی از مقادیر بین 0 و 1 نگاشت میکنند. چنین منطقی، در نقطه مقابل «منطق دودویی» (Binary Logic) قرار دارد که در آن تمامی متغیرها به مقادیر گسسته 1 یا 0 نگاشت میشوند.
سیستمهای فازی، در دسته «سیستمهای کنترلی» (Control Systems) قرار میگیرند. سیستمهای فازی مبتنی بر منطق فازی هستند. در نتیجه، مقادیر متغیرهای کنترلی مسأله میتوانند در قالبی غیر از True یا False نیز نمایش داده شوند. ویژگی مهم سیستمهای فازی در حل مسائل این است که میتوانند جواب ممکن برای یک مسأله خاص را به شکلی نمایش دهند که توسط عاملهای انسانی نیز قابل فهم باشند.
شبکههای تصمیم
«شبکههای تصمیم» (Decision Networks)، تعمیمی بر مدلهای شناخته شده استنتاجی «شبکههای بیزی» (Bayesian Networks) هستند. در چنین سیستمهایی، مجموعه متغیرهای مسأله و روابط احتمالی میان آنها، توسط نقشه خاص نمایش داده میشود. به این نقشه، گراف جهتدار بدون دور (Directed Acyclic Graph) گفته میشود. شبکههای تصمیم، یک نمایش ریاضی و مبتنی بر گراف از متغیرها و مقادیر آنها در یک تصمیمگیری خاص ارائه میدهند. روشهای شبکه تصمیم، علاوه بر حل مسائل استنتاج احتمالی، توانایی مدلسازی و حل مسائل تصمیمگیری (Decision Making Problems) را نیز دارند. مهمترین نمونه شبکههای تصمیم، «شبکههای بیزی» (Bayesian Networks) هستند.

شبکههای بیزی
شبکههای بیزی، «مدلهای گرافی احتمالی» (Probabilistic Graphical Model) هستند که مجموعه متغیرهای مسأله و «وابستگیهای شرطی» (Conditional Dependencies) میان آنها را در قالب یک گراف جهتدار بدون دور نمایش میدهند. شبکههایی بیزی، برای حالتهایی که یک رویداد خاص اتفاق افتاده باشد و سیستم بخواهد احتمال اینکه کدام یک از علتهای ممکن شناخته شده، عامل تاثیرگذار در این رویداد بوده را پیشبینی کند، بسیار ایدهآل هستند. به عنوان نمونه، شبکههای بیزی میتوانند روابط احتمالی میان بیماریها و علائم آنها را نمایش دهند. با داشتن یک دسته از علائم خاص، از شبکه بیزی میتوان برای محاسبه احتمالات وجود بیماریهای مختلف در بیماران استفاده کرد.
برنامهنویسی احتمالی (Probabilistic Programming)
یک الگوی برنامهنویسی است که در آن، مدلهای احتمالی برای حل مسئله تعریف میشوند و استنتاج روی مدلهای احتمالی تعریف شده، به طور خودکار صورت میپذیرد. این دسته از الگوهای برنامهنویسی، با هدف یکپارچهسازی «مدلسازی احتمالی» (Probabilistic Modelling) و روشهای مرسوم برنامهنویسی همه منظوره (General Purpose Programming) طراحی شده است.
با چنین الگوهایی، به راحتی میتوان استفاده از مدلهای احتمالی را در برنامهنویسی رایج کرد. چنین روشهایی، امکان پیادهسازی سیستمهایی را میدهند که میتوانند در شرایط «عدم قطعیت» (Uncertainty) نیز تصمیمگیری کنند. روشهای «تولید (سنتز) برنامه بیزی» (Bayesian Program Synthesis)، از جمله مهمترین الگوهای برنامهنویسی احتمالی هستند.

روشهای تولید (سنتز) برنامه بیزی
در این دسته از الگوهای برنامهنویسی، برنامههای احتمالی بیزی، به طور خودکار، برنامههای بیزی جدید تولید میکنند. در حالت مرسوم روشهای برنامهنویسی احتمالی، برنامهنویس انسانی برای تصمیمگیری در مواجهه با عدم قطعیت، یک برنامه احتمالی بیزی تولید کرده و از ان برای حل مسأله استفاده میکند. در روشهای تولید (سنتز) برنامه بیزی، به جای اینکه برنامهنویس چنین کاری انجام دهد، برنامه احتمالی بیزی اصلی برای تصمیمگیری یا حل مسئله، اقدام به تولید یک برنامه احتمالی بیزی جدید میکند.
یادگیری ماشین
یادگیری ماشین، مطالعه علمی الگوریتمها و مدلهای احتمالی است که کامپیوترها، برای انجام وظایف محول شده، از آنها استفاده میکنند. کامپیوترها برای انجام وظایف محوله، دستورالعملهای صریح در اختیار ندارند و به جای آن، بر الگوهای دادهای و استنتاجات قابل انجام روی آنها برای حل مسأله و انجام وظایف تکیه میکنند. یادگیری ماشین، یکی از مهمترین زیر مجموعههای فناوری های هوش مصنوعی محسوب میشود.

روشهای یادگیری ماشین، برای اینکه قادر باشند بدون داشتن دستورالعمل خاصی از جانب خبره انسانی، وظایف محوله را انجام دهند، یک مدل ریاضی مبتنی بر دادههای نمونه («دادههای آموزشی» (Training Data)) تولید میکنند. یادگیری ماشین، ارتباط بسیار نزدیک و تنگاتنگی با حوزه «آمار محاسباتی» (Computational Statistics) دارد و مانند این حوزه، سعی در پیشبینی آماری با استفاده از الگوریتمهای کامپیوتری دارد. در دستهبندی کلی، الگوریتمهای یادگیری ماشین به سه دسته «یادگیری نظارت شده» (Supervised Learning)، «یادگیری نظارت نشده» (Unsupervised Learning) و «یادگیری تقویتی» (Reinforcement Learning) تقسیمبندی میشوند.

یادگیری نظارت شده
الگوریتمهای یادگیری نظارت شده، برای تصمیمگیری و انجام وظایف، یک مدل ریاضی از مجموعه دادهها تولید میکنند. این مجموعه داده، از دادههای ورودی به سیستم (Input) و خروجیهای مورد انتظار و مطلوب (Target) تشکیل شدهاند. به این دادهها، دادههای آموزشی نیز گفته میشود و از مجموعهای از نمونههای آموزشی تشکیل شدهاند. هر نمونه آموزشی، از یک یا چند داده ورودی و یک خروجی مطلوب تشکیل شده است. به خروجی مطلوب، «سیگنال نظارتی» (Supervisory Signal) نیز گفته میشود.
یک الگوریتم یادگیری نظارت شده، دادههای آموزشی را تحلیل و یک «تابع استنباطی» (Inferred function) تولید میکند. از این تابع استنباطی، برای نگاشت نمونههای (دادههای) جدید به خروجی استفاده میشود. در یک سناریوی ایدهآل، الگوریتم یادگیری نظارت شده قادر خواهد بود تا «برچسبهای کلاسی» (Class labels) یا خروجی «دادههای دیده نشده» (Unseen Data) را به درستی پیشبینی کند. در چنین حالتی، الگوریتم قادر است تا آموزش انجام شده را از دادههای آموزشی به دادههای دیده نشده، به اصطلاح «تعمیم» (Generalization) دهد. مهمترین نمونه الگوریتمهای نظارت شده، الگوریتمهای «دستهبندی» (Classification) و «رگرسیون» (Regression) هستند.
یادگیری نظارت نشده
مجموعه دادههای ورودی در الگوریتمهای یادگیری نظارت نشده، تنها از دادههای ورودی (Input) تشکیل شدهاند. به عبارت دیگر، هر یک از دادهها، خروجیهای مورد انتظار و مطلوب را در کنار خود ندارند. در این دسته از الگوریتمها، هدف پیدا کردن ساختارهایی نظیر گروهها یا خوشههای دادهای در مجموعه دادههای ورودی است. در یادگیری نظارت نشده، به جای اینکه الگوریتم به بازخورد حاصل از خروجیهای مطلوب دادههای ورودی واکنش نشان دهد، سعی میکند تا شباهتهای موجود میان دادههای ورودی را شناسایی کند.
در مرحله بعد، به هر کدام از دادههای ورودی جدید براساس وجود یا عدم وجود چنین شباهتهایی واکنش نشان میدهد. بهعبارت دیگر، الگوریتمهای یادگیری نظارت نشده، بدون اینکه خروجی مطلوب دادههای ورودی را در اختیار داشته باشند، اقدام به شناسایی الگوهای از پیش شناخته نشده در دادههای ورودی میکنند. یکی از ویژگیهای مهم این دسته از الگوریتمها، مدلسازی «چگالیهای احتمال» (Probability Densities) دادههای ورودی است. روشهایی نظیر «تحلیل خوشهها» (Cluster Analysis) و «تحلیل مؤلفه اساسی» (Principal component Analysis)، از جمله مهمترین الگوریتمهای یادگیری نظارت نشده هستند.
یادگیری تقویتی
یادگیری تقویتی، شاخهای از یادگیری ماشین است و هدف آن ارائه استراتژیهای بهینه به «عاملهای نرمافزاری» (Software Agents)، جهت فعالیت و تعامل در محیط عملیاتی است. هدف از این تعامل، بیشینه کردن مفهوم «پاداش تجمعی» (Cumulative Reward) است. در یادگیری ماشین، محیط عملیاتی، معمولا در قالب یک «فرآیند تصمیم مارکوف» (Markov Decision Process) نمایش داده میشود. الگوریتمهای یادگیری تقویتی، برای تعامل با محیط عملیاتی، نه تنها فرضیاتی مبنی بر وجود دانش قابل تحصیل از یک مدل ریاضی دقیق مارکوف انجام نمیدهند، بلکه معمولا زمانی استفاده میشوند که بهکارگیری یک مدل دقیق مارکوف نشدنی است.

بیشتر الگوریتمهای یادگیری تقویتی، از روشهای «برنامهنویسی پویا» (Dynamic Programming) استفاده میکنند. به دلیل عمومیت بالای حوزه یادگیری تقویتی، در شاخههای دیگری نظیر «نظریه بازی» (Game theory)، «نظریه کنترل» (Control theory)، «تحقیق در عملیات» (Operations research)، «نظریه اطلاعات» (Information Theory)، «بهینهسازی مبتنی بر شبیهسازی» (Simulation-based Optimization)، «سیستمهای چند عامله» (Multi-Agent Systems)، «هوش ازدحامی» (Swarm Intelligence)، «آمار» (Statistics) و «الگوریتم ژنتیک» (Genetic algorithm) نیز مورد مطالعه قرار میگیرد.

شبکههای عصبی
شبکههای عصبی (Neural Networks) یا شبکههای عصبی مصنوعی (Artificial Neural Networks)، دستهای از الگوریتمهای یادگیری ماشین هستند که به طور کلی بر پایه ساختارهای عصبی مغز انسان و یا حیوانات مدل شدهاند. این الگوریتمها، این قابلیت را دارند که بدون دریافت دستورالعملهای صریح از جانب برنامهنویس و یا خبره، عملکرد خود را بهبود بخشند. به عنوان نمونه، در «پردازش تصویر» (Image Processing)، شبکههای عصبی قادرند تا از طریق تحلیل تصاویر نمونهای که به طور دستی با کلاسهای «گربه» و «غیر گربه» برچسبگذاری شدهاند، تصاویری حاوی گربه را شناسایی کنند.
شبکههای عصبی مصنوعی، از مجموعهای از واحدهای به هم متصل به نام «نرونهای مصنوعی» (Artificial Neurons) تشکیل شدهاند. نرونهای مصنوعی، مانند نرونهای طبیعی به هم متصل هستند و میتوانند سیگنال (مقدار حقیقی) برای یکدیگر ارسال کنند. خروجی هر کدام از نرونها، از طریق یک واحد خاص به نام «تابع انتقال» (Transfer Function) یا «تابع فعالسازی» (Activation Function) محاسبه میشود. هر کدام از نرونها و لینکهای ارتباطی میان آنها، «وزنی» (Weight) دارند که در طی فرایند یادگیری تنظیم میشود. وزن، قدرت سیگناهای ارتباطی میان نرونها را تقویت یا تضعیف میکند. نرونها، معمولا در واحدهایی به نام «لایه» (Layer) تجمیع میشوند. لایههای مختلف، وظایف متفاوتی بر عهده دارند. سیگنالها، از لایه اول (Input Layer) به سمت لایههای میانی نهان (Hidden Layers) و در نهایت به سمت لایه خروجی (Output Layer) منتشر میشوند. شبکههای عصبی نظیر شبکههای «یادگیری عمیق» (Deep Learning) و «شبکههای عصبی مولد مخاصم یا تخاصمی» (Generative Adversarial Networks)، از جمله مهمترین شبکههای عصبی هستند.

یادگیری عمیق
دستهای از خانواده روشهای بادگیری ماشین هستند که بر پایه شبکههای عصبی مصنوعی بنا نهاده شدهاند. این دسته از الگوریتمها، از فرایند پردازش اطلاعات و نودهای ارتباطی توزیع شده در سیستمهای زیستی الهام گرفته شدهاند. الگوریتمهای یادگیری عمیق، از لایههای متعدد و چندگانه، برای استخراج تدریجی «ویژگیهای سطح بالا» (High Level Features) از دادههای ورودی خام استفاده میکنند.

به عنوان نمونه، در پردازش تصویر، لایههای پایانتر شبکه ممکن است ویژگیهایی نظیر «لبه» (Edge) را در تصویر شناسایی کنند، در حالی که در لایههای بالاتر، ویژگیهای سطح بالاتر نظیر رقم، حروف و یا صورت استخراج میشود. شبکههای عصبی نظیر «شبکههای عصبی پیچشی» (Convolutional Neural networks) و «شبکههای حافظه کوتاه مدتِ بلند» (Long Short-Term Memory Networks)، از جمله مهمترین الگوریتمهای یادگیری عمیق هستند.
این الگوریتمها در حوزههای مختلفی نظیر «بینایی کامپیوتر» (Computer Vision)، «بازشناسی گفتار» (Speech Recognition)، «پردازش زبان طبیعی» (Natural Language Processing)، «ترجمه ماشین» (Machine Translation) و «تحلیل تصاویر پزشکی» (Medical Image Analysis) مورد استفاده قرار گرفته شدهاند. نتایج تولید شده توسط این روشها، قابل مقایسه با خبرههای انسانی و در برخی موارد، بهتر از آنها است.

شبکههای عصبی مولد مخاصم یا تخاصمی
در این دسته از شبکههای عصبی مصنوعی، دو شبکه عصبی مصنوعی در یک بازی با هم به رقابت میپردازند. در نتیجه چنین فرایندی، شبکههای عصبی به طور تدریجی خطاهای سیستم را شناسایی میکند. با در اختیار داشتن یک مجموعه داده آموزشی، این روش یاد میگیرد تا دادههای جدید با «آماره» (Statistics) مشابه دادههای آموزشی تولید کند. به عنوان نمونه، یک شبکه عصبی مولد مخاصم که روی تصاویر آموزش دیده است، میتواند تصاویری تولید کنند که به صورت سطحی، برای انسانها واقعی به نظر بیایند و ویژگیهای واقعگرایانه خوبی از خود نشان دهند.
در این دسته از روشها، دو شبکه عصبی مختلف در کنار هم عمل میکنند؛ «شبکههای مولد» (Generative Networks) و «شبکههای تمایزی یا متمایزگر» (Discriminative Models). شبکههای مولد، دادههای جدید تولید میکنند و شبکههای تمایزی، آنها را ارزیابی میکنند. در این روشها، از تکنیک «پسانتشار» (BackPropagation) برای آموزش هر دو شبکه استفاده میشود؛ از این طریق، شبکه مولد تصاویر بهتری تولید میکند و شبکه تمایزی، عملکرد خود را در شناسایی تصاویر سنتز شده بهبود میبخشد. شبکههای مولد، از نوع «شبکههای عصبی دکانولوشن» (Deconvolutional Neural Network) و شبکههای تمایزی، از نوع شبکههای عصبی پیچشی هستند.

بینایی کامپیوتر
روشهای «بینایی کامپیوتر» (Computer Vision)، روشهایی برای «به دست آوردن» (Acquire) و فهم معنای موجود در تصاویر دیجیتال هستند. بینایی کامپیوتر، یک حوزه میان رشتهای است و روشهای ممکن برای فهم و ادراک سطح بالا از تصاویر و ویدیوهای دیجیتالی را مورد مطالعه قرار میدهد. از دیدگاه مهندسی، این حوزه، بر فرایند خودکار کردن وظایف قابل انجام توسط «سیستم بینایی انسان» به وسیله الگوریتمهای کامپیوتری تمرکز دارد.

بینایی کامپیوتر، فعالیتهایی نظیر به دست آوردن، پردازش و فهم تصاویر دیجیتال و استخراج «دادههای با ابعاد بالا» (High-Dimensional Data) از جهان واقعی را شامل میشود. هدف از چنین فعالیتهایی، تولید اطلاعات عددی یا نمادین برای تصمیمگیری در هنگام حل مسأله است. زیر حوزههایی نظیر «بازشناسی فعالیتها» (Activities Recognition)، «بازشناسی تصویر» (Image Recognition) و «بینایی ماشین» (Machine Vision)، در این حوزه تحقیقاتی از فناوری های هوش مصنوعی طبقهبندی میشوند.

بازشناسی تصویر
بازشناسی تصویر، به فناوریهای اطلاق میشود که برای شناسایی مکانها، افراد، اشیاء، ساختمانها و دیگر مشخصههای موجود در تصویر استفاده میشوند. بازشناسی تصویر زیر مجموعهای از بینایی کامپیوتر است و به فرآیند شناسایی یا تشخیص یک شیء یا ویژگیهای مشخصه موجود در تصاویر دیجیتالی (از طریق روشهای یادگیری ماشین) اطلاق میشود. یکی از مهمترین فناوریهای موجود در حوزه بازشناسی تصویر، «بازشناسی کاراکترهای نوری» (Optical Character Recognition) است.

بازشناسی فعالیتها
یکی از زیر شاخههای حوزه بینایی کامپیوتر است و هدف آن بازشناسی فعالیتها، کنشها و اهداف یک یا چند عامل فعال در محیط، بر اساس مجموعهای از مشاهدات به دست آمده از فعالیت آنها و شرایط محیطی است. فعالیتهای قابل بازشناسی، معمولا در سه دسته فعالیتهای فردی (تک کاربره)، چند کاربره و گروهی دستهبندی میشوند. مهمترین ویژگی چنین سیستمهایی، استفاده از اطلاعات جمعآوری شده از واسطهای سنسوری مختلف (نظیر تلفنهای همراه هوشمند و دوربینهای نظارتی و سایر موارد) برای شناسایی فعالیتها است. به عنوان نمونه، تلفنهای همراه، دادههای سنسوری کافی را برای شناسایی برخی فعالیتهای انسانی نظیر ورزش کردن، از پله بالا رفتن و یا راه رفتن در اختیار دارند.
بینایی ماشین
طبق تعریف انجمن تصویربرداری خودکار (Automated Imaging Association)، بینایی ماشین کلیه کاربردهای صنعتی و غیر صنعتی را شامل میشود که در آنها، از ترکیب سختافزار و نرمافزار، راهنمای عملیاتی لازم برای دستگاهها فراهم میآید تا بتوانند فعالیتهای از پیش تعیین شده خود را انجام دهند.
این دستگاهها، فعالیتهای خود را بر اساس استخراج، پردازش و تحلیل تصاویر دیجیتالی انجام میدهند. از فناوریها و روشهای بینایی ماشین، برای «بازرسی و تحلیل خودکار مبتنی بر تصویربرداری» (Imaging-based Automatic Inspection and Analysis) در کاربردهای صنعتی و غیر صنعتی استفاده میشود.

پردازش زبان طبیعی
«پردازش زبان طبیعی» (Natural Language Processing)، زیرشاخه مهمی از فناوری های هوش مصنوعی است که به جمعآوری، پردازش و تحلیل تمامی واسطهای حاوی «زبان طبیعی» (Natural Language) میپردازد. این حوزه، زیر شاخهای از علوم کامپیوتر (Computer Science)، مهندسی اطلاعات (Information Engineering) و هوش مصنوعی است.

پردازش زبان طبیعی، تعامل میان کامپیوترها و زبانهای طبیعی انسانی را بررسی میکند؛ به ویژه، چگونگی پردازش و تحلیل حجم عظیمی از دادههای زبان طبیعی توسط برنامههای کامپیوتری. به طور کلی، روشهای پردازش زبان طبیعی برای پردازش و تحلیل ویژگیهای «لغوی» (Lexical)، «معنایی» (Semantic)، «نحوی» (Syntactical)، «ساختاری» (Structural) و گفتاری (Speech) مورد استفاده قرار میگیرند. حوزههایی نظیر «فهم زبان طبیعی» (Natural Language Understanding)، «تولید زبان طبیعی» (Natural Language Generation) و «ترجمه ماشینی» (Machine Translation)، از مهمترین زیر شاخههای پردازش زبان طبیعی هستند.

فهم زبان طبیعی
در تعریف، به درک و فهم ساختارها و معانی موجود در زبانهای طبیعی انسانی توسط کامپیوتر و ایجاد امکان تعامل مستقیم میان کامپیوتر و انسان (از طریق زبان طبیعی)، فهم زبان طبیعی گفته میشود. این حوزه، یکی از زیر شاخههای پردازش زبان طبیعی و فناوری های هوش مصنوعی محسوب میشود و با مفهوم «درک مطلب ماشینی» (Machine Reading Comprehension) سر و کار دارد.
روشهای موجود در این حوزه، به سیستمهای کامپیوتری اجازه میدهند تا به طور خودکار، معنا و مفهوم واقعی موجود در دادههای حاوی زبان طبیعی (متن، صوت و سایر موارد) را استنتاج کنند و از این طریق، به تعامل و محاوره با کاربرهای انسانی بپردازند. فهم زبان طبیعی، همان هوش مصنوعی است که توسط نرمافزارهای کامپیوتری استفاده میشود تا بتوانند متون و هر نوع داده غیر ساخت یافته را تفسیر کنند. در فهم زبان طبیعی، زبان طبیعی پردازش، به زبان کامپیوتر ترجمه و در نهایت، به خروجی قابل فهم توسط ماشین تبدیل میشود. پیچیدگی مسائل مرتبط با فهم زبان طبیعی، (AI-Hard) است.

تولید زبان طبیعی
تولید زبان طبیعی، فرایندی نرمافزاری است که داداههای ساخت یافته را به محتوای زبان طبیعی تبدیل میکند. به عنوان نمونه، در شرکتهای تجاری و سازمانها، از چنین روشهایی جهت تولید محتوای زبان طبیعی، برای بهکارگیری در گزارشهای سازمانی تولید شده به صورت خودکار استفاده میشود.
تولید زبان طبیعی، نقطه مقابل فهم زبان طبیعی محسوب میشود. در فهم زبان طبیعی، سیستم باید متن ورودی را «ابهامزدایی» (Disambiguate) و به زبان قابل فهم توسط ماشین تبدیل کند. در حالی که در تولید زبان طبیعی، محتوای دادههای ماشینی باید توسط کامپیوتر به محتوای زبان طبیعی تبدیل شوند. سیستمهای «داده به متن» (Data-to-Text)، از جمله مهمترین نمونه سیستمهای تولید زبان طبیعی هستند.

ترجمه ماشینی
ترجمه ماشینی، زیر شاخهای از «زبانشناسی محاسباتی» (Computational Linguistics)، هوش مصنوعی و پردازش زبان طبیعی است. این حوزه، استفاده از الگوریتمهای کامپیوتری و فناوری های هوش مصنوعی را برای ترجمه دادههای متنی از یک زبان به زبان دیگر، مطالعه و بررسی میکند. ترجمه ماشینی، در سادهترین حالت، از جابجایی کلمات یک زبان با کلمات زبان دیگر، برای ترجمه متون استفاده میکند (در این حالت، ترجمه خوبی حاصل نمیشود). در حال حاضر، سیستمهای «مبتنی بر دانش» (Knowledge-based)، آماری و مبتنی بر شبکه عصبی، جزء بهترین روشهای ترجمه ماشینی هستند. این روشها، در شناسایی اختلافات موجود در توپولوژی زبانها، ترجمه اصطلاحات میان زبانها و شناسایی ناهنجاریهای (Anomalies) ترجمه، به موفقیتهای بسیار خوبی دست یافتهاند. مهمترین نمونه یک سیستم ترجمه ماشین، سرویس ترجمه ماشینی ارائه شده توسط گوگل است.

محاسبات حسی (Affective Computing)
این زیر شاخه از حوزه فناوری های هوش مصنوعی، بازشناسی، تفسیر و شبیهسازی احساسات انسانی توسط دستگاهها و سیستمهای کامپیوتری را مطالعه و بررسی میکند. سیستمهای محاسبات حسی قادر خواهند بود تا وضعیت احساسی یک کاربر را (از طریق سنسورها، میکروفون، دوربینها و سایر موارد) شناسایی کنند و از طریق انجام یک سری فعالیتها و یا ارائه سرویسها و ویژگیهای خاص، به کاربر پاسخ دهند. سیستم محاسبات حسی، از طریق تفسیر وضعیت احساسی کاربران، باید بتوانند رفتار خود را با شرایط کاربر تطابق دهد.
سیستمهای محاسبات حسی میتوانند به عنوان سیستمهای «تعامل انسان-کامپیوتر» (Human-Computer Interactions) نیز عمل کنند؛ یعنی، قابلیت تشخیص شرایط احساسی کاربران انسانی و دیگر محرکها را داشته و از این طریق، به تعامل با کاربران مشغول شوند. تفاوت محاسبات حسی با «تحلیل احساسات» (Sentiment Analysis) این است که مورد اول، انواع مختلف احساسات را شناسایی میکند، در حالی که مورد دوم، فقط «قطبیت» (Polarity) دادههای متنی حاوی زبان طبیعی را میسنجد.

محاسبات تکاملی (ٍEvolutionary Computation)
این حوزه، زیرشاخهای از فناوری های هوش مصنوعی و «محاسبات نرم» (Soft Computing) است. الگوریتمهای این حوزه، برای «بهینهسازی سراسری» (Global Optimization) مورد استفاده قرار میگیرند و از فرآیند «تکامل زیستی» (Biological Evolution) الهام گرفته شدهاند.

از دیدگاه فنی، الگوریتمهای محاسبات تکاملی، خانوادهای از الگوریتمهای حل مسأله به شیوه «آزمون و خطا» (Trial and Error)، مبتنی بر جمعیت و با ویژگی بهینهسازی «فرا اکتشافی» (Metaheuristics) یا «تصادفی» (Stochastic) هستند. در محاسبات تکاملی، یک مجموعه از جوابهای کاندید اولیه برای مسأله تولید و در یک فرایند تکراری به روز رسانی میشوند. در هر نسل، به طور تصادفی، جوابهای نامطلوب حذف میشوند و تغییرات کوچکی در جوابهای دیگر ایجاد میشود. جمعیت جوابهای کاندید، تحث تاثیر فرایندهای «انتخاب طبیعی» (Natural Selection) و «جهش» (Mutation)، به سمت جوابهای بهینه تکامل پیدا میکنند.

الگوریتمهای تکاملی (Evolutionary Algorithms)
زیر شاخهای از محاسبات تکاملی هستند. الگوریتمهایی برای حل مسائل بهینهسازی هستند و شامل تکنیکهایی میشوند که از مکانیزمهای الهام گرفته شده از تکامل زیستی (نظیر «جهش» (Mutation)، «ترکیب» (Recombination)، «تولید مثل» (Reproduction)، «انتخاب طبیعی» (Natural Selection) و «بقای بهترینها» (Survival of Fittest)) برای تولید جوابهای کاندید حل مسأله استفاده میکنند.
به این مکانیزمها، عملگرهای تکاملی نیز گفته میشود. جوابهای کاندید، نقش نمونهها در جمعیت را ایفا میکنند و «تابع هزینه» (Cost Function)، برازندگی محیطی که جواب کاندید در آن قرار دارد را مشخص میکند. پس از تعدادی نسل، جمعیت جوابهای کاندید از طریق عملگرهای تکاملی، به سمت جوابهای بهینه تکامل پیدا میکنند. الگوریتمهایی نظیر الگوریتم ژنتیک، الگوریتم کلونی مورچگان، الگوریتم شبیهسازی تبرید، الگوریتم بهینهسازی فاخته و سایر موارد از جمله الگوریتمهای تکاملی هستند.
در این جا لازم است تفاوت میان دو اصطلاح «اکتشافی» (Heuristics) و فرا اکتشافی شرح داده شود. این دو اصطلاح، برای نامگذاری الگوریتم تکاملی جستجو و بهینهسازی استفاده میشوند. با این حال، تفاوتهای اساسی با یکدیگر دارند که در ادامه به آنها پرداخته میشود.
- الگوریتمهای اکتشافی (Heuristics): این دسته از الگوریتمها، روشهای وابسته به مسأله (Problem-Dependent) هستند. مشخصات این الگوریتمها، بسته به مسألهای که قرار است بهینهسازی کنند، متفاوت خواهد شد. از آنجایی که این الگوریتمها، بسیار حریصانه (Greedy) هستند، بسیار در دام «بهینه محلی» (Local Optimum) قرار میگیرند و نمیتوانند به خوبی به جواب «بهینه سراسری» (Global Optimum) همگرا شوند.
- الگوریتمهای فرا اکتشافی (Meta-Heuristics): در نقطه مقابل الگوریتمهای اکتشافی، الگوریتمهای فرا اکتشافی قرار دارند. این دسته از روشها، مستقل از مسأله (Problem-Independent) هستند و مشخصات آنها برای حل مسائل بهینهسازی مختلف، یکسان خواهد بود. از آنجایی که حریصانه نیستند، تقریب نزدیک از جواب بهینه سراسری را نیز به عنوان جواب بهینه میپذیرند. در نتیجه، میتواند فضای جوابهای مسأله را با دقت بیشتری بسنجند و در بسیاری از موارد، جواب بهینه بسیار خوب و حتی بهینه سراسری را تولید کنند.
سیستمهای مستقل یا خودگردان (Autonomous Systems)
این دسته از سیستمها، زیر شاخهای از فناوری های هوش مصنوعی محسوب میشوند و در تلاقی حوزههای «رباتیک» (Robotics) و «سیستمهای هوشمند» (Intelligent Systems) قرار میگیرند. این دسته از سیستمها، بخشی از سیستمهای نوینی هستند که پا را فراتر از خودکار کردن ساده فرایندها میگذارند. این سیستمها، به جای اینکه چندین فعالیت را بدون کوچکترین تغییر و به طور خودکار انجام دهند، قادر به حس کردن محیط عملیاتی خود هستند و به شکل پویا، به تغییرات محیطی پاسخ داده و اهداف خود را تحقق میبخشند.
هوش مصنوعی توزیع شده (Distributed Artificial Intelligence)
دستهای از فناوری های هوش مصنوعی هستند که از طریق توزیع یک مسأله به «عاملهای مستقل یا خودگردان» (Autonomous Agents) اقدام به حل مسأله میکنند.

عاملهای خودگردان در محیط عملیاتی، همیشه در حال تعامل با یکدیگر هستند.

سیستمهای چند عامله (Multi-Agent Systems)
یک سیستم خود سازمانده کامپیوتری است که از مجموعهای از عاملهای هوشمندی که در حال تعامل با یکدیگر هستند، تشکیل شده است. این سیستمها قادرند مسائلی که حل آنها برای یک عامل، بسیار سخت یا غیر ممکن است، حل کنند. عاملها میتواند نرمافزار یا روبات باشند. عاملها به سه دسته عاملهای غیرفعال (بدون هدف)، فعال (با هدف ساده) و یا شناختی (انجام محاسبات پیچیده) تقسیمبندی میشوند.
مدلسازی چند عامله
«مدلسازی چند عامله» (Multi-Agent Modelling)، تکنیکهای مدلسازی بسیار قدرتمندی هستند. در این مدلسازی، سیستم در قالب مجموعهای از موجودیتهای تصمیمگیرنده خودگردان تعریف میشود. به این موجودیتها، عامل گفته میشود. هر عامل، وضعیت و محیط اطراف خود را ارزیابی میکند. سپس، بر اساس اطلاعات حاصل شده و مجموعهای از قوانین تعریف شده تصمیمگیری و در نهایت، در محیط عملیاتی فعالیت میکند.
هوش ازدحامی
«هوش ازدحامی» (Swarm Intelligence)، به رفتار تجمعی (گروهی) سیستمهای خود سازمانده، غیر متمرکز و مصنوعی (یا طبیعی) گفته میشود. این مفهوم، در هوش مصنوعی بسیار مورد استفاده قرار میگیرد. چنین سیستمهایی از یک جمعیت متشکل از عاملهای ساده تشکیل شدهاند که به صورت محلی و در محیط عملیاتی خود با یکدیگر در حال تعامل هستند. الهامبخش سیستمهای هوش ازدحامی، طبیعت و به ویژه سیستمهای زیستی هستند. عاملها، قوانین سادهای را دنبال میکنند و اگرچه سیستم کنترلی متمرکزی برای مشخص کردن رفتار عاملها وجود ندارد، ما تعامل محیطی و محلی آنها منجر به ظهور «رفتار هوشمند سراسری» میشود. عاملها از وجود چنین ساختار هوشمندی در محیط بیخبر هستند.
محاسبات محیطی
«محاسبات محیطی» (Ambient Computing) که به آن هوش محیطی نیز گفته میشود، اصطلاحی است که مفاهیم متنوع زیادی را شامل میشود. این اصطلاح، به ترکیبی از نرمافزار، سختافزار، تعاملات کاربری، تعاملات انسان-ماشین و یادگیری اطلاق میشود. در چارچوب محاسبات محیطی، تمامی دستگاههای فیزیکی موجود در محیط دیجیتال باید قابلیت حس کردن، درک و پاسخ به محرکهای خارجی محیطی (که معمولا توسط عامل انسانی فعال میشوند) را داشته باشند. محاسبات محیطی، اکوسیستمی از دستگاهها یا کامپیوترهای متصل به اینترنت تعریف میکند که در آن تمامی عناصر این اکوسیستم، به طور مداوم در حال پردازش و به اشتراک گذاری اطلاعات هستند. سیستمهای الکترونیکی تشکیل دهنده این اکوسیستم، به حضور افراد در محیط حساس بوده و به آنها پاسخ میدهند. «اینترنت اشیاء» (Internet of Thing)، مهمترین نمونه چنین سیستمهایی است.

مسائل دیگر در حوزه هوش مصنوعی
در این بخش، برخی از مسائل، تعاریف و الگوریتمهای موجود در حوزه فناوری های هوش مصنوعی که ممکن است در طبقهبندیهای بالا قرار نگیرند، شرح داده و تعریف میشوند. غالب این الگوریتمها یا همپوشانی زیادی با دیگر الگوریتمهای هوش مصنوعی دارند و یا از الگوریتمهای شناخته شده هوش مصنوعی برای حل مسأله استفاده میکنند. با این حال، این الگوریتمها، توجه محققان زیادی در حوزه فناوری های هوش مصنوعی را به خود جلب کردهاند (این بخش، به مرور زمان به روز رسانی خواهد شد).
یادگیری انتقال
«یادگیری انتقال» (Transfer Learning) یکی از مسائل تحقیقاتی و در حال مطالعه در حوزه یادگیری هوش مصنوعی و یادگیری ماشین است. این مسأله، بر ذخیرهسازی دانش حاصل شده در حین حل یک مسأله و استفاده از آن برای حل یک مسأله مختلف ولی مرتبط دیگر تمرکز دارد. به عنوان نمونه، دانش حاصل شده در هنگام بازشناسی ماشینهای سواری، میتواند برای شناسایی کامیونها یا وسایل نقلیه دیگر استفاده شود.

در یادگیری ماشین، از یادگیری انتقال زمانی استفاده میشود که بخواهیم با ایجاد تغییرات در تنظیمات یک مدل از پیش یادگیری شده برای حل یک مسأله خاص، آن را برای حل یک مسأله مرتبط دیگر استفاده کنیم. بهعبارت دیگر، دانش حاصل شده از یک مدل یادگیری، برای حل یک مسأله دیگر استفاده میشود و از این طریق، زمان و منابع کمتری برای حل مسائل مرتبط صرف میشود.
جمعبندی
برای حل مسائل هوش مصنوعی، ممکن است لازم باشد تا از ترکیبی از الگوهای هوش مصنوعی ارائه شده استفاده شود. به عبارت دیگر، از بیش از یک فناوری موجود در حوزه هوش مصنوعی برای حل مسائل (در دامنههای مختلف) استفاده میشود. یاد دادن انجام خودکار فعالیتها (خاص یا عمومی) به کامپیوتر، بدون اینکه دستور العملهای صریحی برای انجام آنها داده شود، کار بسیار سختی است.

چنین کاری نیازمند استفاده از تکنولوزیهای مختلف و طراحی هوشمندانه راه حل، با استفاده از فناوریهای در دسترس است. حوزه فناوری های هوش مصنوعی و چشمانداز آن، با توجه به گستردگی دامنه، بسیار آشفته و در هم ریخته است. با این حال، در این مطلب سعی شده است تا دستهبندی مختصری از این حوزه، فناوریهای موجود در آن و البته دامنه مسائلی که در آن قابل هستند ارائه شود.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای داده کاوی و یادگیری ماشین
- آموزش اصول و روش های داده کاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- روش های تحلیل احساسات در پایتون — راهنمای کاربردی
- هوش مصنوعی و چشم اندازی از آینده پیش رو — آنچه باید دانست
- معرفی منابع آموزش ویدئویی هوش مصنوعی به زبان فارسی و انگلیسی
^^











عالی بود و قشنگ مشخص بود یه فرد خبره این مقاله رو نوشته
سلام
واقعا عالی بود
بی نهایت سپاسگزارم