



دور زدن سیستم کپچا با یادگیری ماشین و شبکه های عصبی
اغراق نیست اگر گفته شود اغلب افراد از «کپچا» (CAPTCHA ) متنفرند. کپچاها، همان تصاویر مزاحم حاوی یک متن کوتاه هستند که باید پیش از ورود به یک سایت آنها را در محل تعبیه شده وارد کرد. در کپچاهای پیچیدهتر، تصاویری وجود دارد که کاربر باید آنها را با یک تصویر اصلی، متناسب با عنصر مد نظر موجود در تصاویر تطبیق دهد. این سیستم برای پیشگیری از پر کردن خودکار فرمها - توسط رباتها - ایجاد شده و روش کار آن بدین صورت است که با پر شدن فرم، اطمینان حاصل میشود که کاربر یک انسان واقعی است. ولیکن با توسعه یادگیری عمیق و بینایی رایانهای، اکنون میتوان کپچاها را نیز به سادگی شکست داد. در کتاب «یادگیری عمیق برای بینایی رایانهای با پایتون» نوشته ادریان روزبروک (Adrian Rosebrock) روش دور زدن کپچا در وبسایت «E-ZPass New York» با استفاده از یادگیری ماشین آموزش داده شده است.
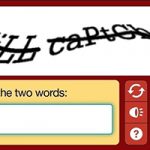
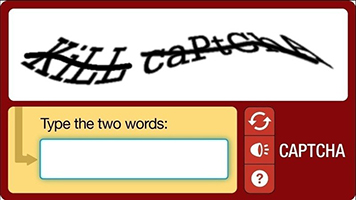



ادریان به کد منبع نرمافزاری که تصاویر کپچای این سایت را آماده میکرد، دسترسی نداشت. او برای شکستن سیستم، مجبور بود هزاران نمونه از تصاویر کپچا را به صورت دستی جهت آموزش دادن برنامه یادگیری ماشین دانلود کند.
اما برای شکستن یک سیستم کپچا متنباز که به کد منبع آن دسترسی وجود دارد، راهکار چیز دیگری است. در WordPress.org Plugin Registry با جستوجوی «کپچا»، نتیجه اصلی «Really Simple CAPTCHA» است. این پلاگین بیش از یک میلیون بار نصب شده.

و بهتر از همه اینکه کد منبع این نرمافزار نیز منتشر شده است. از آنجا که کد منبع تولید کننده کپچاها در دسترس است، شکستن آن بهنوعی سادهتر میشود.
تذکر مهم: این مطلب برای انتقاد از پلاگین «Really Simple CAPTCHA» نوشته نشده. توسعهدهنده این پلاگین خود اذعان کرده که این سیستم کپچا دیگر امن نیست و به کاربران توصیه کرده از نمونههای دیگر استفاده کنند. آنچه در ادامه آمده صرفا با هدف ارائه یک چالش فنی کوچک و جذاب و پاسخگویی به آن نوشته شده و وبلاگ فرادرس مسئولیت هرگونه سو استفاده از آن را نمیپذیرد.
چالش
برای برنامهریزی راهکار، ابتدا باید بررسی کرد که Really Simple CAPTCHA چه نوع تصاویری تولید میکند. در یک وبسایت که از این پلاگین استفاده میکند، میتوان نمونه زیر را مشاهده کرد:

به نظر میرسد کپچاهای تولید شده دارای چهار کاراکتر هستند. با بررسی کد منبع این سیستم که به زبان PHP نوشته شده، میتوان از این امر اطمینان حاصل کرد:
به وضوح مشخص است که این کد، بهطور تصادفی کپچاهایی متشکل از چهار کاراکتر تولید میکند. همچنین، برای پیشگیری از گیج شدن کاربر، از حروف «O» و «I» استفاده نمیکند. در نتیجه ۳۲ حرف و عدد باقی میماند که در کپچاها باید شناسایی شوند.
مجموعه ابزار مورد استفاده
پیش از آغاز بحث اصلی، ابزارهایی که برای حل این مساله مورد استفاده قرار میگیرند در ادامه معرفی میشوند.

پایتون ۳: پایتون یک زبان برنامهنویسی جالب و قدرتمند است که دارای کتابخانههای فوقالعادهای برای یادگیری ماشین و بینایی رایانهای است.
OpenCV: یک چارچوب معروف برای بینایی رایانهای و پردازش تصویر است. بنابراین در این مطلب برای پردازش تصاویر کپچا از OpenCV استفاده میشود. استفاده مستقیم از این چارچوب در زبان پایتون به لطف یک رابط برنامهنویسی کاربردی (API) امکانپذیر شده است.
Keras: یک چارچوب یادگیری عمیق نوشته شده به زبان پایتون است. این چارچوب، تعریف، آموزش و استفاده از شبکههای عصبی عمیق را با استفاده از کدهای کوتاه امکانپذیر میسازد.
TensorFlow: تنسورفلو کتابخانه گوگل برای یادگیری ماشین است. در این مطلب از Keras استفاده شده ولیکن این ابزار منطق شبکههای عصبی را به خودی خود پیاده نمیکند. بلکه، از کتابخانه TensorFlow در پسزمینهاش بهره میبرد.
و اما چالش اصلی ...
ساخت مجموعه داده
برای آموزش دادن هر سیستم یادگیری ماشین، نیاز به یک مجموعه داده است.
برای شکستن سیستم کپچا، نیاز به مجموعه داده آموزشی مانند تصویر زیر است:

از آنجا که کد منبع پلاگین وردپرس موجود است، میتوان کد آن را برای ساخت ۱۰.۰۰۰ تصویر کپچا به همراه پاسخ مورد انتظار هر تصویر اصلاح کرد.
پس از چند دقیقه زمان که صرف اصلاح کد و افزودن یک حلقه for ساده به آن شد، اکنون یک پوشه با مجموعه داده آموزش - که دارای ۱۰.۰۰۰ فایل PNG و پاسخ صحیح برای هر یک است ـ ایجاد شده:

این تنها قسمت از نوشته است که کد آن در اختیار مخاطب قرار نمیگیرد. دلیل این امر، جلوگیری از ارسال هرزنامه در وبسایت اصلی وردپرس است. اگرچه، امکان دسترسی به ۱۰.۰۰۰ تصویری که در آن برای حل مساله ایجاد شده از این مسیر وجود دارد.
سادهسازی مساله
اکنون که مجموعه داده آموزش موجود است، میتوان مستقیما از آن برای آموزش شبکه عصبی استفاده کرد.

با استفاده از میزان کافی دادههای آموزش، این راهکار نیز ممکن است جوابگو باشد، ولیکن قصد داریم مساله را تا حد امکان سادهسازی کنیم. هرچه مساله سادهتر شود، میزان دادههای آموزش کمتر و در نتیجه قدرت پردازش کمتری برای حل آن مورد نیاز است.
خوشبختانه تصاویر کپچا همیشه تنها از کاراکترها ساخته میشوند. اگر بتوان بخشهای موجود در تصویر را از یکدیگر جدا کرد، بنابراین هر کاراکتر یک تصویر جدا خواهد بود. در این حالت تنها کافیست که شبکه عصبی را برای شناسایی یک کاراکتر تنها آموزش داد.

زمان کافی برای شکستن ۱۰.۰۰۰ تصویر در فوتوشاپ وجود ندارد. این کار روزها وقت میگیرد. در عین حال، نمیتوان تصویر را به چهار تکه مساوی شکست زیرا کپچا کاراکترها را بهطور تصادفی در موقعیتهای افقی گوناگون قرار میدهد تا از شکستن آن جلوگیری کند.

خوشبختانه، امکان خودکارسازی این فرآیند وجود دارد. در پردازش تصویر، اغلب نیاز به شناسایی «blob»های پیکسلهای دارای رنگ مشابه است. مرزهای موجود در اطراف بلابهای پیکسلهای ممتد، «خط تراز» (contours) نامیده میشوند. OpenCV دارای یک تابع توکار ()built-in findContours است که میتوان برای شناسایی این نواحی ممتد از آن بهره برد.
اکنون مراحل، با یک تصویر کپچا خام دنبال میشود.

سپس، تصویر را به سفید و سیاه خالص تبدیل کرده (به این کار آستانهگذاری گفته میشود) تا بتوان نواحی ممتد را به سادگی پیدا کرد.

در گام بعد، از تابع ()findContours موجود در OpenCV برای شناسایی نواحی متمایز از هم تصویر استفاده میشود که دارای بلابهای پیکسل با رنگ مشابه هستند.

حال تنها کافی است که هر ناحیه را بهعنوان یک فایل تصویر جدا ذخیرهسازی کرد. از آنجا که هر تصویر دارای چهار کاراکتر است که از چپ به راست آورده شدهاند، میتوان کاراکترها را هنگام ذخیرهسازی آنها برچسب زد. با توجه به اینکه فایلهای تکههای یک تصویر به ترتیب ذخیره میشوند، باید هر کاراکتر تصویر را با نام کاراکتر مناسب ذخیرهسازی کرد.
اما در این مرحله یک مشکل به چشم میآید. گاهی کپچا برخی کاراکترها را روی هم قرار میدهد.

این مشکل موجب میشود تا در فرآیند شکستن یک تصویر کپچا، دو کاراکتر دارای همپوشانی بهعنوان یک ناحیه از تصویر جدا شوند.

اگر این مشکل حل نشود، مجموعه داده آموزش نامناسبی ساخته خواهد شد. یک راهکار ساده برای حل این مساله آن است که اگر طول یک قطعه از تصویر کپچا از عرض آن خیلی بیشتر باشد، آن را به دو بخش تقسیم کرده و هر یک را به عنوان کاراکتر مجزا در فایل جدا ذخیره کند (ترتیب ذخیرهسازی چپ به راست حفظ میشود).

تصویر زیر مربوط به پوشه «W» پس از استخراج کلیه کاراکترها است.

ساخت و آموزش شبکه عصبی
اکنون فقط نیاز به شناسایی تصاویر حروف و اعداد مجزا است و بنابراین نیاز به معماری شبکه عصبی خیلی پیچیدهای نیست. شناسایی کاراکترها نسبت به تشخیص تصاویری مانند سگها و گربهها مساله سادهتری است.

حال از یک معماری شبکه عصبی پیچشی ساده با دو لایه پیچشی و لایههای کاملا متصل (مطابق شکل زیر) استفاده میشود.

تعریف معماری این شبکه عصبی تنها نیازمند چند خط کد است.
اکنون میتوان شبکه را آموزش داد.
پس از گذراندن ده دوره آموزش، صحت نزدیک به ۱۰۰٪ بهدست میآید. در این مرحله دیگر باید بتوان در هنگام نیاز کپچا را بهصورت خودکار دور زد.
استفاده از مدل آموزش داده شده برای حل کپچاها
اکنون یک شبکه عصبی آموزش داده شده موجود است که با استفاده از آن میتوان کپچاهای واقعی را به سادگی شکست.

الگوریتم گامبهگام شیوه استفاده از مدل به شرح زیر است:
- یک کپچای واقعی را از وبسایتی که از این پلاگین وردپرس استفاده میکند دریافت کن.
- کپچا را با رویکردی که پیشتر بیان شد به چهار کاراکتر مجزا بشکن.
- از شبکه عصبی بخواه که برای هر تصویر کاراکتر، پیشبینی خود را ارائه کند.
- از چهار کاراکتر پیشبینی شده برای پاسخ به کپچا استفاده کن.
در تصویر زیر، چگونگی عملکرد مدل روی کپچاهای واقعی نشان داده شده است:

در خط فرمان نیز به صورت زیر است:

اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشود:
- آشنایی با شبکههای عصبی پیچشی (CNN)
- مجموعه آموزش های شبکه های عصبی مصنوعی در متلب
- مجموعه آموزش های کاربردی شبکه های عصبی مصنوعی
- شبکه های عصبی مصنوعی – از صفر تا صد
- ساخت شبکه های عصبی در نرم افزار R
^^










سلام
امکانش هست کد کامل را نیز قرار دهید ؟
ممنونم