



پردازش زبان طبیعی چیست؟ – توضیح و کاربرد به زبان ساده
«پردازش زبان طبیعی» یا به بیان سادهتر «پردازش زبان انسانی» که به اختصار NLP نیز نامیده میشود، این امکان را فراهم میکند تا هوش مصنوعی، توانایی درک و فهم زبان ما انسانها را - که در صحبتها و تعاملهای روزمره خود بهکار میبریم - داشته باشد. این شاخه از هوش مصنوعی، با ایجاد راهی ارتباطی بین انسان و کامپیوتر، در موارد متعددی همچون خلاصهسازی خودکار متن، تحلیل احساسات، برنامههای مترجم و بسیاری موارد دیگر به یاری ما میآید. در مطلب پیشِ رو از مجله فرادرس سعی کردهایم تا بهطور کامل و به زبان ساده توضیح دهیم که پردازش زبان طبیعی چیست و چه کاربردی دارد. همچنین عملکرد و چالشهای آن را نیز بیان کردهایم.
- یاد میگیرید که پردازش زبان طبیعی چیست و چه کاربردهایی دارد.
- میآموزید مراحل اصلی تحلیل زبان طبیعی توسط ماشین چگونه انجام میشود.
- روشهای مدرن ترجمه، تکمیل جمله و تشخیص خطا را با NLP خواهید شناخت.
- نقش یادگیری عمیق، مدلهای پیشرفته و چالشهای NLP را بررسی میکنید.
- نقش NLP در بهبود امنیت، بازاریابی و تحلیل دادههای متنی را خواهید آموخت.
- با روندها و تحولات آینده این فناوری و تاثیر آن بر صنعت آشنا میشوید.




آشنایی با حوزه NPL
پردازش زبان طبیعی - یا زبانی که ما بهطور طبیعی بلد هستیم و برای برقراری ارتباط و تعاملهایمان بهکار میبریم - یکی از مباحث روز و پرطرفدار در حوزه هوش مصنوعی بهشمار میرود. این محبوبیت به لطف وجود اپلیکیشنهایی است نظیر مواردی که در ادامه آوردهایم.
- تولیدکننده متن که برای نگارش مقالات منسجم و معنیدار بهکار میروند.
- رباتهای گفتگو یا به اصطلاح، چَتباتهایی که انسان را - بهدلیل دارا بودن احساس و آگاهی - به فکر وا میدارند.
- برنامههای تبدیل متن به عکس که از آنچه که برایش - در قالب پرامپتها - توصیف کردهایم، تصاویری واقع گرایانه ایجاد میکنند.
در سالهای اخیر، شاهد انقلابی در توانایی کامپیوترها در مورد فهم زبانهای انسانی، زبانهای برنامهنویسی و حتی توالیهای زیستی و شیمیایی - مثل ساختارهای پروتئینی و DNA که همانند زبان هستند - بودهایم. تازهترین مدلهای هوش مصنوعی، راه را برای این حوزهها هموار کردهاند تا معانی متن دریافتی را تحلیل و خروجی معناداری را تولید کنند.

پردازش زبان طبیعی چیست؟
«پردازش زبان طبیعی» (Natural Language Processing | NLP) بهعنوان یکی از فناوریهای هوش مصنوعی، این امکان را برای ماشینها (کامپیوترها) فراهم کرده است تا گفتار انسانها را - در قالب متنی یا صوتی - درک کنند و بدین ترتیب، روشی بهوجود آورده تا ماشینها بتوانند با ما (انسانها) بهوسلیه زبان خودمان ارتباط برقرار کنند.
نخستین سنگبنای NLP بهوسیله آقای «آلِن تورینگ» (پدر علوم کامپیوتر و هوش مصنوعی) در دهه ۳۰ (سالهای ۱۹۵۰ میلادی) بنا نهاده شد. طبق گفته وی، اگر ماشینی توانایی این را داشته باشد که با یک انسان به گفتگو بنشیند، میتوان آن را ماشینی متفکر دانست.
دیری نگذشت که اپلیکیشنهای متفاوتی به وجود آمدند. بهطور مثال میتوانیم به «ELIZA» اشاره کنیم. این برنامه که در سال ۱۳۴۵ (۱۹۶۶ میلادی) بهکار گرفته شد، در واقع اولین «رباتِ گفتگو» یا «چتبات» (Chatbot) در زمینه خدماتدرمانی بود که با بهکارگیری «تطبیق الگو» (Pattern Matching) و «گزینش پاسخ» (Response Selection)، عملکردی - تقلید شده و - شبیه به یک رواندرمانگر داشت.
بعدها در سال ۱۳۵۰ (۱۹۷۱ میلادی)، سازمان پروژههای پژوهشی پیشرفته دفاعی یا «DARPA»، اِناِلپی را در زمینه ترانویسی خودکار (در مقابل اختلال و نویز) گفتار یا «RATS» بهکار گرفت. این سیستم کارهای مربوط به سیگنالهای حاوی گفتاری را انجام میداد که از کانالهای ارتباطی بهشدت نویزی دریافت شدهاند.
کاربردهای این چنینی، الهامبخش مشارکت بین حوزههای علوم کامپیوتر و زبانشناسی بود تا از این راه، زیرشاخه پردازش زبان طبیعی در هوش مصنوعی - که امروزه میشناسیم - ایجاد شود.

نحوه کار پردازش زبان طبیعی چگونه است؟
بهطور کلی، روشهای «پردازش زبان طبیعی» یا «اِن اِل پی»، شامل ۴ گام اصلی هستند که در ادامه، فهرست کردهایم.
- تحلیل لغوی
- تحلیل نحوی
- تحلیل معنایی
- تبدیل خروجی
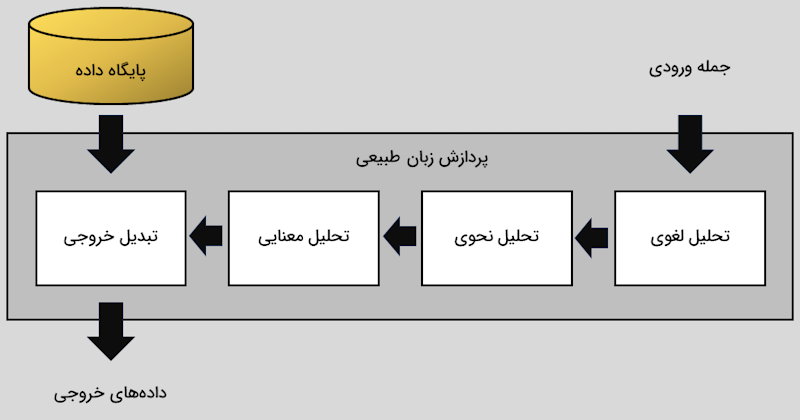
در ادامه هر یک از این موارد را توضیح دادهایم.
تحلیل لغوی در پردازش زبان طبیعی چیست؟
این مرحله که تحلیل Lexical نام دارد، شامل فرایندی است که طی آن یک جمله، به کلمات یا واحدهای کوچکی بهنام «توکنها» یا «نشانهها» (Tokens) شکسته میشود تا معنای آن و رابطهاش با کل جمله تشخیص داده شود.

تحلیل نحوی در پردازش زبان طبیعی چیست؟
مرحله تحلیل «نحوی» (Syntactic)، به فرایندی اشاره دارد که در آن، مورادی که در ادامه بیان شده، صورت میگیرد.
- ارتباط بین عبارات و کلمات گوناگون درون جمله، تشخیص داده میشود.
- ساختار این کلمات استانداردسازی میشود.
- روابط بهصورت ساختار سلسلهمراتبی بیان میشود.
تحلیل معنایی در پردازش زبان طبیعی چیست؟
مرحله تحلیل «معنایی» (Semantic)، فرایندی است که ساختارهای نحوی را به معانی مستقل از زبانشان مرتبط میسازد و این کار از سطوح عبارات و بندها (بخشی از جملات)، جملات و پاراگرافها تا مرحله کلی نوشتار صورت میگیرد.
تبدیل خروجی در پردازش زبان طبیعی چیست؟
گام «تبدیل» (Transformation) خروجی، فرایندی است که در آن، نتیجهای (خروجی) بر مبنای تحلیل معنایی متن یا گفتار، تولید میشود که متناسب با هدف اپلیکیشن است.
با توجه به کاربرد NLP در اپلیکیشن، خروجی میتواند ترجمه یا تکمیل یک جمله، تصحیح گرامری یا حتی پاسخ تولیدشده بر مبنای قوانین - یا دادهای آموزشی - باشد.
در اپلیکیشنهای مدرن NLP بهخصوص در سالهای اخیر، از «یادگیری عمیق» (Deep Learning) بهطور وسیعی استفاده شده است. بهطور مثال، «مترجم گوگل» (Google Translate) در سال ۱۳۹۵ (۲۰۱۶ میلادی) بهخوبی با یادگیری عمیق سازگار شد که پیشرفتهای چشمگیری را در دقت نتایج، بهدنبال داشت.
کاربردهای پردازش زبان طبیعی چیست؟
پردازش زبان طبیعی، این امکان را برای کامپیوترها فراهم میکند تا گفتار انسانها را بفهمند و نمونهای از آن را تولید کنند. بههمین دلیل موارد استفاده زیادی دارند. برخی از کاربردهای NLP را در ادامه توضیح دادهایم.

بررسی گرامر و املا در پردازش زبان طبیعی چیست؟
هدف اولیه ابزارهای «بررسی املاء یا گرامر» (Grammar/Spelling Check) - نظیر Writer’s Workbench - این بود که خطاهای مربوط به شیوه نگارش و همچنین علائم نگارشی را تشخیص دهند. توسعههای صورت گرفته و پیشرفتهای NLP و «یادگیری ماشین» (Machine Learning)، اِشکالهای دستور زبانی - مانند ساختار جمله، املاء، نحو، علائم نگارشی - و همینطور اِشکالهای معنایی را بهصورت دقیقتری تشخیص میدهند.

بررسی گرامر، بهوسیله ۳ روشی انجام میشود که در ادامه آوردهایم.
- «قانونمحور» (Rule-Based): این روش به مهارتهای کارشناسان زبانشناسی متکی است که قوانین دقیقی را طراحی میکنند تا در مواردی همچون جداسازی (تکه تکه کردن) متن، تخصیص تگهای PoS (قسمتی از گفتار) و بررسی قوانین تطبیق برای شناسایی اِشکالها استفاده شود.
- «مبتنی بر یادگیری ماشین» (Machine Learning Based): این تکنیک، بر الگوریتمهای «نظارت شده» (Supervised) یادگیری ماشین استوار است که با دیتاستهای بزرگ آموزش دیدهاند تا بتوانند تحلیل آماری روی جمله داشته باشند و اِشکالها را بر اساس نمونههای پیشین تشخیص دهند.
- «ترکیبی» (Hybrid): این روش در واقع ترکیبی از ۲ تکنیک قبلی، یعنی «قوانین تعیین شده» و «یادگیری ماشین» است تا عملکرد سیستم را بهبود ببخشد. به بیان دیگر در این روش، از قوانین برای اِشکالهای گرامری استاندارد - مثل کاربرد a یا an - و از یادگیری ماشین برای تحلیل معنایی جملات بهره میگیرند.
ترجمه در پردازش زبان طبیعی چیست؟
اپلیکیشنهای مدرن ترجمه این توانایی را دارند تا از هر ۲ روش «یادگیری ماشین» و «قانونمحور» استفاده کنند. روش قانونمحور، امکان ترجمه واژه به واژه را بسیار شبیه به یک دیکشنری انجام میدهد.
از سویی دیگر، یادگیری ماشین، ترجمه کلی یک جمله یا یک پاراگراف را بهبود میبخشد و این کار را با فهمیدن معنی کلی جمله ورودی، تولید ترجمه واژه به واژه و سرعت بخشیدن به خروجی با توجه به دادههای آموزشی به منظور تولید یک ترجمه دقیق انجام میشود.
چت بات در پردازش زبان طبیعی چیست؟
چَتباتها یا «رباتهای گفتگو» (Chatbots)، برنامهای هستند که امکان تعامل ما انسانها با ماشین را فراهم میکنند تا از طریق بتوانیم سوالاتمان را بپرسیم و پاسخ را بهروش مکالمهای طبیعی دریافت کنیم.
چتباتها برای فهم پرسشهای کاربر، به NLP و «تشخیص منظور» (Intent Recognition) وابستهاند. با توجه به نوع چتبات (قانون محور بودن، مبتنی بر هوش مصنوعی، ترکیبی) پاسخهایی را برای پرسش درک شده، تدوین میکنند.
علاقه به چت باتها در طول ۵ سال گذشته، بهطور تقریبی ۵ برابر شده است. بهدلیل مزایای متعدد و کاربردهای متنوعی که ایننوع برنامهها در صنایع گوناگون - همچون هتلداری، بانکداری، مشاور املاک و خرده فروشی - دارند، محبوبیتشان نیز افزایش یافته است.
این نوع برنامهها میتوانند دیگر فناوریهای هوش مصنوعی - همچون فراکاوی برای تحلیل و مشاهده الگوها در گفتار کاربران - و همچنین ویژگیهای غیر مکالمهای، مانند تصاویر یا نقشهها را با هدف بهبود تجربه کاربر، ترکیب کنند.

تکمیل جمله در پردازش زبان طبیعی چیست؟
«تکمیل جمله» (Sentence Completion)، یکی از معروفترین کاربردهای پردازش زبان طبیعی است که بهطور روزانه از آن استفاده میکنیم. در این کاربرد، NLP با برخی از الگوریتمهای یادگیری ماشین ترکیب شده است که در ادامه، آنها را توصیف کردهایم.
«شبکههای عصبی بازگشتی» (Recurrent Neural Networks | RNN):
الگوریتمهای شبکه عصبی RNN بهطور معمول، در اپلیکیشنهای یادگیری عمیق مورد استفاده قرار میگیرند. این شبکهها فعالیت اتصالات نورونی مغز انسان را شبیهسازی میکنند که با استفاده از رویدادهای بازگشتی آموزش میبینند. شبکههای عصبی بازگشتی، ویژگیهای زنجیرهای و زمانی دادهها را تشخیص میدهند و از الگوها و حلقههای بازخورد به منظور پیشبینی سناریوی احتمالی بعدیِ یک کلمه یا جمله استفاده میکنند.
«تحلیل معنایی پنهان» (Latent Semantic Analysis | LSA):
الگوریتمهای LSA، بر تحلیل رابطه بین توکنهای گفتار متکیاند. این الگوریتم، با جداسازی پاراگراف یا جملات در قالب توکنها، «ماتریس رابطه» (Relationship-Matrix) بین آنها را تشکیل میدهد تا الگوی رخداد توکنها با یکدیگر را بفهمد و جمله بعدی را بر مبنای این فرضیه توزیعی پیشبینی کند که میگوید «کلمههایی که معنای مشابهی دارند در بخشهای متنی شبیه بههم قرار میگیرند».
روشهای سادهتر «تکمیل جمله» (Sentence Completion) بر الگوریتمهای یادگیری ماشین نظارت شدهای متکی هستند که با دیتاستهای بزرگی آموزش دیدهاند. با این وجود، این الگوریتمها کلمات تکمیل کننده را تنها بر مبنای دادههای آموزشی - که ممکن است بایاسشده (جانبدارانه)، ناقص یا مختص به موضوع خاصی باشند - پیشبینی میکنند.
مدلهای GPT که بهوسیله OpenAI ساخته شدهاند را میتوان بهعنوان یکی از نمونههای جدید نام برد که میتوانند تکمیل متن شبه انسانی داشته باشند هرچند که از منطق موجود در گفتار انسانی استفاده نمیکند.
فراکاوی داده ها در پردازش زبان طبیعی چیست؟
تحلیل و «فراکاوی» (Analytics) دادهها، فرایند بیرون کشیدن بینش از دادههای ساختارمند و بدون ساختار است که با هدف تصمیمگیریهای دادهمحور در مشاغل یا علوم بهکار میرود. NLP در زمره سایر کاربردهای هوش مصنوعی، قابلیتهای فراکاوی را به مراتب، ارتقا میدهد. NLP بهطور خاص در فراکاوی دادهها بسیار سودمند است چون «استخراج» (Extraction)، «دستهبندی» (Classification) و درک متن یا صدای کاربر را فراهم میکند.

چالش های پردازش زبان طبیعی چیست؟
پرداختن به زبانطبیعی، موضوع بسیار دشواری است. حتی بهعنوان یک انسان، گاهی اوقات ممکن است در تفسیر جملات یکدیگر یا تصحیح اشتباه تایپی متن خود به مشکل بر بخوریم. NLP در مسیر خود با چالشهای بسیاری همراه است که کاربردهایش را در معرض اشتباه و عدم موفقیت قرار میدهد. برخی از چالشهای اساسی NLP را در ادامه بیان کردهایم.
- «طعنه» (Sarcasm)
- تعدد معنایی یا «مبهم بودن عبارت» (Phrase Ambiguity)
- «ادبیات عامیانه یا کوچه بازاری» (Slang or Street Language)
- «ادبیات مربوط به حوزه خاص» (Domain-Specific Language)
- «سوگیری موجود در دادههای آموزشی» (Bias in Training Data)
هرچند که امروزه، با پیشرفتهای صورت گرفته در زمینه «فهم زبان طبیعی» (Natural Language Understanding | NLU) بهعنوان یکی از شاخههای هوش مصنوعی، یادگیری عمیق و دادههای آموزشی جامعه، دریچهای برای الگوریتمها ایجاد شده است تا گفتار و متن واقعی را مشاهده از آن یاد بگیرند. بدین ترتیب به چالشهای NLP رسیدگی شده است.
مزایا و معایب NLP چیست؟
در ادامه برخی از مزیتها و عیبهایی که میتوان برای پردازش زبان طبیعی بیان کرد را آوردهایم.
مزیت های پردازش زبان طبیعی چیست؟
برخی از مزایای NLP را در ادامه فهرست کردهایم.
- پردازش زبان طبیعی به ما امکان میدهد تا دادهها را از منابع ساختارمند و بدون ساختار تحلیل کنیم.
- NLP بسیار سریع و از نظر زمانی مقرون بهصرفه - و کارآمد - است.
- پردازش زبان طبیعی، پاسخهای دقیق و جامعی را برای پرسشها فراهم میکند. بههمین دلیل، در زمان زیادی - که صرف اطلاعات ناخواسته و بی مورد میشود - صرفهجویی میکند.
- NLP به کاربران امکان میدهد تا سوالاتی را در موضوع دلخواه - و گوناگون - بپرسند و در کسری از ثانیه پاسخ خود را دریافت کنند.
معایب پردازش زبان طبیعی چیست؟
در زیر، برخی از عیبهایی که بر NLP وارد است را آوردهایم.
- فرایند آموزش مدلهای پردازش زبان طبیعی نیازمند داده و محاسبات بسیار زیادی است.
- NLP هنگام رویارویی با عبارات غیررسمی، کنایه و اصطلاحات، دچار مشکلات متعددی میشود.
- بعضی وقتها، نتایج حاصل از پردازش زبان طبیعی به اندازه کافی دقیق نیست. به بیان دیگر میتوان گفت که «دقت» (Accuracy) آن بهطور مستقیم با دقت دادهها تناسب دارد.
- NLP برای وظایف مشخص و محدودی طراحی شده است، بنابراین نمیتواند با حوزههای جدید سازگار شود و عملکرد محدودی را در این مورد ارائه میدهد.

انتظاراتمان از آینده پردازش زبان طبیعی چیست؟
پردازش زبان طبیعی یا NLP که زیرمجموعهای از هوش مصنوعی محسوب میشود، این قابلیت را به ماشینها میدهد تا زبان انسانی را ضمن فهمیدن و رمزگشایی، تفسیر کنند. مدلهای NLP میتوانند به منظور درک دادههای متنی و صوتی آموزش ببینند. امروزه، استفاده از فناوری NLP در صنایع متعددی مورد استفاده قرار گرفته است.
بهدلیل پیشرفتهای صورت گرفته در زمینه ساخت تراشهها و پردازندههای مخصوص هوش مصنوعی که تأثیر مطلوبی روی سرمایهگذاریها و نرخ سازگاری فناوری دارند، کسب و کارها در حال حاضر میتوانند مدلهای NLP پیچیدهتری را ایجاد کنند. بهخاطر مدلهای کارآمدتر NLP، موارد استفاده معمول از این فناوری ممکن دچار تغییر شود. در ادامه، برخی از بهترین پیشبینیها در مورد آینده NLP را بیان کردهایم تا کمکی باشد برای مدیران کسب و کارهای گوناگون و بتوانند تصمیمهای درست مربوط به سرمایهگذاری را با اطمینان بیشتری اخذ کنند.
رشد ادامه دار سرمایه گذاری در حوزه NLP
گزارشها نشان میدهد که اندازه بازار NLP طی سالهای آینده رشد بسیار زیادی خواهد داشت و با توجه به تحلیلها، آمریکای شمالی بزرگترین بازار NLP را دارد و از طرف دیگر آسیای شرقی بهطور سنگینی روی کاربردهای NLP سرمایهگذاری کرده است. رشد سریع بازار NLP با ۳ عاملی که در ادامه آوردهایم مرتبط است.
پیشرفت فناوری های یادگیری ماشین
تراشههای هوش مصنوعی را میتوان معادل مغز مدلهای NLP در نظر گرفت. بدین ترتیب، تراشههای قویتر، توان محاسباتی بالاتر را برای ماشینها فراهم میکنند در نتیجه، میتوانند تعاملهای شبهانسانیتری را انجام دهند. تولیدکنندگان تراشههای هوش ممصنوعی، پردازندههایی را طراحی میکنند که میتوانند پارامترهای بیشتری را پردازش کنند و اندازه مدل سیستمهای پردازش زبان طبیعی را افزایش دهند.
بهبود کیفیت و دسترسی پذیری داده ها
دسترسیپذیری و کیفیت دادهها را میتوان عامل دیگری دانست که قابلیتهای سیستمهای پردازش زبان طبیعی را بهبود میدهد.
برای افزایش کیفیت دادههای آموزشی، ابزارهای برچسبگذاری متعددی مخصوص دادهها وجود دارد که میتوانند دادههای صوتی یا متنی را توضیح دهند. این ۲ خصوصیت به کمک هم، بازار NLP را گسترش میدهند.
رشد انتظارات مشتریان
بنابر پژوهشهای صورت گرفته، بسیاری از مدیران کسب و کارها مایلند تا روش مدیریت ارتباط با مشتریان خود را بهکلی تغییر دهند تا از این طریق با نیازهای در حال تغییر مشتری همراه شوند. کسب و کارها ناگزیرند تا مدلهای NLP را بهخاطر انتظارات مشتریان برای تعاملهای سریع با برندها پیادهسازی کنند.

هوشمندتر شدن ابزارهای هوش مصنوعی محاوره ای
یکی از زیربخشهای NLP، «هوش مصنوعی محاورهای» (Conversational AI) نام دارد که منظور کاربر را - از طریق ورودی - فهمیده و به او پاسخ میدهد. لازم است بدانیم که این فناوری در پشت صحنه موارد زیر بهکار میرود.
- چتباتها
- دستیاران مجازی هوشمند یا IVAs
- رباتهای صوتی یا دستیاران صوتی
- کارکنان دیجیتالی یا digeys
به لطف پیشرفتهای صورت گرفته در مدلهای NLP، ابزارهای هوش مصنوعی محاورهای، ظرافت زبان انسانی به طرز بهتری میتوانند تشخیص دهند. افزون بر این، به دلیل ارتقا و بهبود درک زبان طبیعی یا NLU، ابزارهایی که اشاره کردیم با افراد بهشکل بهتری ارتباط برقرار خواهند کرد. با این پیشرفتها انتظار میرود که موارد بیان شده در زیر، در آیندهای نزدیک برای شرکتها اهمیت بیشتری داشته باشد.
- تجارت محاورهای
- بانکداری محاورهای
- اتوماسیون هوشمند
تجارت محاوره ای
«تجارت محاورهای» (Conversational Commerce)، بهعنوان یک استراتژی بازاریابی جدید به فکر افزایش آسودگی مشتریان است. کسب و کارهایی که در تجارت محاورهای شرکت میکنند، از پلتفرمهای فراگیری بهره میگیرند و چتباتها، ابزارهای پیامرسانی انبوه و عاملهای لایو، با مشتریان بهواسطه روشهای مختلفی که در ادامه آورده شده، ارتباط برقرار میکنند.
- واتساپ ویژه کسب و کار
- پیامرسان فیسبوک
- اپلیکیشنهای موبایلی شرکت
- وبسایت شرکت
- مراکز تماس شرکتها و غیره
تجارت محاورهای همچنین استراتژی مناسبی برای بخشهای خردهفروشی، تجارت الکترونیکی و هتلداری (گردشگری) محسوب میشود. تعدادی از موارد استفاده تجارت محاورهای را در ادامه آوردهایم.
- پیشنهاد و توصیه محصول با NLP
- پشتیبانی مشتریان
- ارزیابی صلاحیت روادید (ویزا)

بانکداری محاوره ای
«بانکداری محاورهای» (Conversational Banking) را میتوان یک پیادهسازی از تجارت محاورهای در زمینه خدمات مالی در نظر گرفت. موسسههای مالی برای تعاملهای مشتریان خود از موارد بیان شده در زیر استفاده میکنند.
- چتباتهای بانکی
- چتباتهای تسهیلات
- چتباتهای مدیریت دارایی (سرمایه)
شرکتهای مالی با وجود بانکداری محاورهای میتوانند موارد زیر را اتوماسیون کنند.
- معارفه مشتری
- فرایند جمعآوری و ارزیابی اسناد برای صدور وام
- ارائه پیشنهادهایی در رابطه با سهام
اتوماسیون هوشمند
این امکان وجود دارد که کارکنان با فناوریهای «اتوماسیون هوشمند» (Intelligent Automation)، همچون «کارکنان دیجیتال» (Digital Workers) ارتباط برقرار کنند و به لطف وجود هوش مصنوعی محاورهای، به آنها فرمان انجام فعالیتهای گوناگونی را بدهند. خودکارسازی سراسری از طریق اتوماسیون هوشمند ارائه میشود. آنها میتوانند بهطور پیوسته و «خودمختار» (Autonomously) کارکنند. بههمین دلیل ابزارهای مؤثری برای تقویت کارمندان و افزایش بازدهی آنان محسوب میشوند.
در ادامه، موارد استفاده ابزارهای اتوماسیون هوشمند نظیر کارکنان دیجیتالی را آوردهایم.
- نگارش و ارسال ایمیلها
- بیرون کشیدن دادهها از ابزارهای حسابداری ERP و همچنین CRM
- تفسیر و مصورسازی دادهها
- استخدام (تامین نیروی انسانی)
- گزارشدهی و غیره
استفاده شرکت ها از NLG برای تولید متن
تولید زبان طبیعی یا NLG، بهعنوان یکی از زیرشاخههای NLP، کاربرد سودمندی از هوش مصنوعی برای تولیدکنندگان محتوا و بازاریابها محسوب میشود. با این حال، به نظر میرسد که شرکتهای بیشتری از تولید خودکار متن و ابزارهای ویرایشگر محتوای NLPمحور استفاده خواهند کرد. در ادامه دلایلی را در این زمینه بیان کردهایم.
- شرکتها، سرمایهگذاری بیشتری روی بازاریابی انجام دادهاند.
- در حدود ۶۰٪ ار از شرکتها، جذب مشتریان جدید خود را مدیون بازاریابی محتوا هستند.

NLP این قابلیت را دارد تا وظایف بازاریابها را به دلایل کاربردهای بیان شده در زیر، تسهیل کند.
- ترجمه محتوا
- بازنویسی (پارافرایز کردن) محتوا
- ویرایش محتوا
- تولید محتوا
- ارائه مشورت سئو پسند (SEO-friendly)
اجرای تحلیل احساسات توسط شرکت های بیشتری از حوزه های مختلف
یکی از کاربردهای NLP، «تحلیل احساسات» (Sentiment Analysis) است که از کلاندادهها بهعنوان منبعی برای کشف بیشها استفاده میکند. در این کاربرد، رضایتمندی مصرف کننده از طریق سنجش نگرش گفتار یا متن (منفی، خنثی یا مثبت) تحلیل میشود.
پژوهش احساسات، برای شرکتهای موجود در صنایع گوناگون اهمیت زیادی دارد. به این دلیل که مطالعه رفتار مصرفکننده، بیانگر این است که پیوند نیرومندی بین رضایتمندی مشتری، درآمد و وفاداری آن وجود دارد. بسیار سخت است تا بدون اجرای تحلیل احساست، میزان دقیق خوشنودی مصرفکننده را بسنجیم. به نظر میرسد ۳ صنعتی که در ادامه آوردهایم ار تحلیل احساسات منفعت زیادی خواهند برد.
- «امور مالی» (Finance)
- «تجارت الکترونیک» (E-commerce)
- «منابع انسانی» (HR)
متداول تر شدن به کارگیری بیومتریک صوتی
تشخیص گفتار، کاربردهای متعددی در کسب و کار دارد. با این وجود، کاربرد خاص آن که بهعنوان بیومتریک صدا شناخته شده است، بهدلیل تقویت امنیت هویتسنجی با «اثر صوتی» (Voiceprints) کاربران بهعنوان منبع شناسایی، ممکن است در آینده محبوبتر شود. برخی از مزیتهای بیومتریک صدا را در ادامه آوردهایم.
- صدا، نحوه تلفظ، تون و گام صدای افراد، مشخصههایی منحصر به فرد هستند و تقلید آن تقریباً امکانپذیر نیست. بههمین دلیل، بیومتریک صدا شاید بتواند نسبتبه کلمههای عبور رایج، امنیت بیشتری را فراهم کند.
- خیلی اوقات ممکن است که افراد، کلمه عبور خود را فراموش کنند و این حس ناخوشایندی است.

سوالات متداول
اکنون که یادگرفتیم پردازش زبان طبیعی چیست، برخی از پرسشهای پر تکرار در این زمینه را بههمراه پاسخهای متناظرشان، با هم بررسی میکنیم.
دلیل مهم بودن پردازش زبان طبیعی چیست؟
NLP، بخش مهمی از زندگی روزانه ما را تشکیل میدهد. این فناوریِ مرتبط با زبان، در حوزههای گوناگونی نظیر خردهفروشی - بهعنوان مثال در چتباتهای مربوط به خدمات مشتری - و همچنین پزشکی - در تفسیر یا خلاصهسازی سوابق سلامت الکترونیکی - بهکار میرود.
- عوامل مکالمهای نظیر Alexa در آمازون و Siri در اپل برای درک پرسشهای کاربر و یافتن پاسخها، از NLP بهره میگیرند. یکی از پیچیدهترین نوع این عاملها، یعنی GPT-3 که در حال حاضر برای استفادههای تجاری آزاده شده است، میتواند متون پیچیده - در موضوعات متنوع - و همچنین چتباتهای نیرومندی را تولید کند که میتوانند گفتگوی منسجم و منطقی را داشته باشند.
- گوگل، NLP را به منظور بهبود نتایج موتور جستجوی خود بهکار میبرد.
- شبکههای اجتماعی نیز از NLP برای تشخیص و فیلتر کردن کلام نفرتانگیز یا «نفرتپراکنی» (Hate Speech) استفاده میکنند.
NLU و NLG در پردازش زبان طبیعی چیست؟
NLP را میتوان به ۲ زیر شاخه «فهم زبان انسانی» (Natural Language Understanding) و «تولید زبان انسانی» (Natural Language Generation) تقسیم کرد که این ۲ موضوع، دارای همپوشانی هستند. NLU روی تحلیل معنایی یا تعیین معنای تعیین شده برای متن، متمرکز است. NLG نیز روی تولید متن بهوسیله یک ماشین تمرکز دارد. NLP، موضوعی جدا از «تشخیص گفتار» (Speech Recognition) محسوب میشود، هرچند که بیشتر اوقات در ترکیب با آن بهکار میرود. لازم است بدانیم که تشخیص گفتار، در پی تجزیه زبان گفتاری (شفاهی) به کلمات، تبدیل صدا به متن (و برعکس) است.
موارد استفاده پردازش زبان طبیعی چیست؟
NLP، در حوزه گستردهای از موارد مربوط به زبان، شامل پاسخدهی به پرسشها، طبقهبندی متن به روشهای گوناگون و تعامل با کاربر، مورد استفاده قرار میگیرد.
فرق تشخیص گفتار و NLP چیست؟
فناوری تشخیص گفتار، این قابلیت را به کامپیوتر یا برنامه میدهد تا کلمات و عبارات را از زبان گفتاری تشخیص دهد و درک کند و سپس آنها را به شکلی خوانا برای کامپیوترها تبدیل کند. تشخیص گفتار زیرشاخهای از زبانشناسی محاسباتی محسوب میشود که با فناوریهای وارد کردن گفتار به سیستم (بهعنوان ورودی) سروکار دارند. از سویی دیگر، پردازش زبان طبیعی یا NLP، شاخهای از هوش مصنوعی است که تحقیقاتی در مورد بهکارگیری کامپیوترها برای پردازش یا فهمیدن زبانهای انسانی با هدف اجرای کارهای سودمند، انجام میدهد. NLP در واقع، فناوری مورد استفاده برای سادهسازی پردازشهای تشخیص گفتار است برای اینکه زمان کمتری مصرف کنند.

بهترین زبان برنامه نویسی برای NLP چیست؟
پایتون را میتوان بهعنوان بهترین زبان برنامهنویسی برای تکنولوژی NLP معرفی کرد چون علاوه بر سینتکس ساده و توانایی ادغام آسان با سایر زبانهای برنامهنویسی، کتابخانههای متعددی را در این زمینه برایمان فراهم کرده است.
پیاده سازی NLP چگونه است ؟
این موضوع که NLP حوزه بسیار پیچیدهای از علوم کامپیوتر محسوب میشود بر کسی پوشیده نیست. فریمورکهای بزرگی نظیر SpaCy در پایتون برای پردازش زبان طبیعی به صورت آسان وجود دارند که امکانات زیادی را فراهم میکنند و نیاز دارند تا زمانی را به یادگیری آنها اختصاص دهیم اما با کمک «مدلهای زبانی بزرگ» (Large Language Models | LLMs) اوپن سورس و کتابخانههای مدرن پایتونی، خیلی از این کارها بهآسانی قابل انجام است. حتی میتوان گفت نتایجی که سالهای گذشته تنها در مقالات دیده میشدند را در حال حاضر میتوان با چندین خط کد پایتونی بهدست آورد. منظور از مدلهای زبانی، مواردی همچون BERT و غیره است.
فریمورک های مشهور NLP چیست؟
از کتابخانهها و فریمورکهای محبوب پردازش زبان طبیعی میتوان به NLTK ،spaCy ،Gensim ،CoreNLP ،Transformers و کتابخانه Hugging Face’s Transformers اشاره کرد.
فرق چت جی پی تی و ان ال پی چیست؟
ChatGPT با بهکارگیری تعدادی از فناوریهای پیشرفته کنونی همچون پردازش زبان طبیعی، یادگیری ماشین و یادگیری عمیق ساخته شده است. این فناوریها به منظور ایجاد مدلهای شبکههای عصبی مصنوعی بهکار میروند و به آن امکان میدهند تا از دادههای متنی بیاموزند و همانند آن را تولید کنند.

NLP چگونه ابهامات و تغییرات زبانی را مدیریت میکند؟
NLP این کار را با بهکارگیری روشهایی مانند مدلهای آماری، الگوریتم یادگیری ماشین، تحلیل زمینه و مدلهای زبانی آموزشدیده با حجم زیادی داده به منظور فهم و تفسیر آن، انجام میدهد.
نقش یادگیری ماشین در NLP چیست؟
یادگیری ماشین با فراهم کردن الگوریتمها و روشهایی به منظور آموختن خودکار الگوها، ساختارها و روابط بین دادههای متنی، نقشی کلیدی در پردازش زبان طبیعی بر عهده دارد و مواردی مانند طبقهبندی متن، تشخیص موجودیت نامدار، ترجمه ماشینی و تحلیل احساسات را برایمان امکانپذیر میکند.

تفاوت بین ۲ رویکرد قانون محور و آماری در NLP چیست؟
روشهای قانون محور در NLP، در بر گیرنده ایجاد الگوها و قوانین زبانی بهصورت دستی است تا متن را پردازش و تحلیل کند. از سویی دیگر، رویکردهای آماری NLP، بر الگوریتمهای یادگیری ماشین متکی هستند که الگوها و قوانین را بهصورت خودکار از دادهها میآموزند.
توکن سازی در NLP چیست؟
فرایند تجزیه متن به کلمات، عبارات یا نمادها که به توکن معروفاند را «توکنسازی» (Tokenization) میگویند. این فرایند بهدلیل اینکه اساس تحلیل و پردازشهای بعدی را شکل میدهد، گامی اصلی در NLP محسوب میشود.
جمعبندی
در این مطلب از مجله فرادرس بیان کردیم که NLP شاخهای از هوش مصنوعی بهشمار میرود که تمرکز اصلی آن روی تعامل بین کامپیوتر و انسان بهوسیله زبان طبیعی است. هدف نهایی NLP آن است که کامپیوترها را یاری دهد تا بهخوبی انسانها این زبان را بفهمند. همچنین گفتیم که NLP در کاربردها و اپلیکیشنهای گوناگونی نظیر دستیاران مجازی، تشخیص گفتار، تحلیل احساسات، خلاصهسازی خودکار متن، ترجمه ماشینی و غیره بهکار میرود.

پردازش زبان انسانی، رفته رفته پیچیدهتر میشود و در عین حال کارهای زیادی باقی مانده است که میتوانیم انجام بدهیم. سیستمهای کنونی مستعد «سو گیری» (Bias) و «عدم انسجام» (Incoherence) هستند. همچنین بعضی وقتها رفتار غیر منتظره و نامتناسبی از خود بروز میدهند. با وجود چالشهایی که در این زمینه وجود دارد، مهندسان یادگیری ماشین، هنوز هم فرصتهای زیادی در پیشِ رو دارند تا NLP را بهصورتی پیش ببرند که برای عملکرد جامعه مناسبتر باشد.







