



معماری پایگاه داده چیست؟ – به زبان ساده + انواع
معماران، هنگام طرحریزی و ساخت هر سازهای، ساختار و چیدمان اجزای گوناگونی که برای ایجاد کل سازه لازم است و همینطور روابط بین آنها را توسعه میدهند. این کار با ایجاد یکپارچگیِ ساختاری و پایداری کل مجموعه، بر نحوه عملکرد سازه نیز، تاثیر بسزایی دارد. این مفهوم در مورد سیستمهای پایگاه داده نیز صادق است. در این مطلب از مجله فرادرس، با بیان اینکه «معماری پایگاه داده چیست»، انواع معماریهای معرفی شده برای سیستمهای پایگاه داده، از جمله معماری ۳ لایه «ANSI/SPARC» و همچنین سیستمهای پایگاه داده «متمرکز»، «موازی» و «توزیع شده» را به همراه مزایا و معایب هر کدام، مورد بررسی قرار میدهیم.
- یاد میگیرید که معماری پایگاه داده چگونه ساختاردهی و مدیریت دادهها را بهبود میدهد.
- میآموزید که عناصر پایهای مانند رکورد، فیلد، فایل و کاتالوگ را تشخیص دهید.
- کاربرد فراداده و زبان تعریف داده (DDL) را در توسعه پایگاه داده یاد خواهید گرفت.
- انواع معماریهای متمرکز، توزیعشده، موازی و کلاینت-سرور را خواهید شناخت.
- با مدل سهلایه ANSI/SPARC و تاثیر آن در انتزاع و جداسازی سطوح داده آشنا میشوید.
- خواهید آموخت که مزایا و معایب عملی هر معماری پایگاه داده را تحلیل کنید.




با پیشرفت فناوری و رشد روزافزونِ استفاده از سیستمهای کامپیوتری، سازمانها با سرعتی زیاد از سیستمهای «دستی» (Manual)، به سیستمهای اطلاعاتی کامپیوتری مهاجرت میکنند که دادههای درون سازمان، منبعی اساسی برای آن محسوب میشود. بنابراین، سازماندهی و مدیریت صحیح دادهها، برای اداره کارآمدِ سازمان، امری ضروری است. همچنین، به کارگیری مؤثر دادهها برای برنامهریزی، کنترلِ تولید، بازاریابی، صورتحسابنویسی، حقوق و دستمزد، حسابداری و سایر موارد اینچنینی در سازمان، تأثیر عمدهای بر مزیت رقابتی آن دارد. در ادامه این مطلب، اصطلاحات و مفاهیم مورد استفاده در معماری پایگاه داده را با هم مرور میکنیم.
مقدمات یادگیری معماری پایگاه داده چیست ؟
در این قسمت، برخی از مفاهیم اولیه پیرامون معماری پایگاه داده همچون تعریف «داده» در علوم کامپیوتر، مفاهیم «رکورد»، «فایل»، «کاتالوگ سیستم»، «فراداده»، «زبان تعریف داده» و غیره را بررسی میکنیم.
داده در معماری پایگاه داده چیست ؟
«داده» (Data) در علوم کامپیوتر، به یک یا دنبالهای از چندین نماد اشاره دارد. به بیان دیگر، نمادی از واحدهای اطلاعاتی کوچک و مجزا به حساب میآید و همچنین صورتِ جمعِ آن، واژه «Datum» است. برای اینکه «داده» به «اطلاعات» (Information) تبدیل شود، نیاز است تا اقداماتی به منظور تفسیر آن، صورت گیرد.
دادههای دیجیتالی، دادههایی هستند که بهجای نمایش آنالوگ، به صورت سیستم اعداد «دودویی» (Binary)، یعنی «صِفرها» (۰) و «یکها» (۱) نشان داده میشوند. امروزه در تمام سیستمهای کامپیوتری، دادهها به صورت دیجیتال مورد استفاده قرار میگیرند که میتوان آنها را روی حافظههای الکترونیکی، ذخیره و نگهداری کرد.
علاوه بر این، دادهها را میتوان به عنوان واقعیتی شناخته شده تعریف کرد که قابل ثبت است و معنای ضمنی (غیر صریح) دارد. «اطلاعاتِ» مورد نیاز، از این دادهها تولید میشوند که حقایق خام یا مجزایی به حساب میآیند.

دادهها را میتوان قطعاتی متمایز از اطلاعات در نظر گرفت که معمولاً به روشی خاص قالببندی میشوند. آنها، بازنماییهای کامپیوتریِ باینری، از «موجودیتهای منطقیِ ذخیره شده» هستند. یک تکه داده، واقعیتی را در مورد چیزی که مدنظر ما است، بیان میکند. مواردی که در ادامه آورده شده، میتوانند نمونههایی از قطعات داده در یک کارخانه باشند.
- بزرگترین تامین کننده مواد ریختهگری کارخانه، در شهر «تهران» واقع شده است.
- کد پرسنلی «1452365»، به کارگری خاص به نام «علی هاشمی» اشاره دارد.
- شماره موبایل یکی از مشتریانِ ویژه کارخانه سیمان، «09123456789» است.
به همین ترتیب، «داده»، برای موسسهای آموزشی میتواند این واقعیت باشد که مثلاً، بیشترین ثبت نام در دوره «مدیریت پایگاه داده» صورت گرفته است. بنابراین، یه تکه «داده»، واقعیتی منفرد در مورد چیزی در اطرافمان است که به آن اهمیت میدهیم.
دادهها میتوانند اَشکال مختلفی داشته باشند که دارای معنایی مشخص (در محیط خود) هستند. مانند اعداد یا متنهای نوشته شده روی قطعهای کاغذ، بیتها و بایتهایی که روی حافظه کامپیوتری ذخیره شدهاند یا حقایقی که در ذهن ما وجود دارند. دادهها، همچنین میتوانند اشیایی مانند اسناد، تصاویر، تکههایی از ویدئو و غیره باشند.
آیتم داده در معماری پایگاه داده چیست ؟
«آیتم داده» یا فیلد، کوچکترین واحد «داده»، محسوب میشود که معنی مشخصی را برای کاربر به همراه دارد. گاهی اوقات به آن، «فیلد» (Field) یا «عنصر دادهای» نیز گفته میشود. این عناصر در پایگاه داده، به وسیله «مقداری»، نمایش داده میشوند.

به عنوان مثال، «نامها»، «شماره تلفن»، «مبلغ صورتحساب»، «آدرس» و موارد اینچنینی در «قبض تلفن همراه» یا «نام»، «کمک هزینه»، «کسورات»، «دستمزد ناخالص»، «حقوق خالص» و غیره در «فیش حقوقی کارمند» را میتوان به عنوان نمونهای از «آیتم داده» یا «فیلد» در نظر گرفت. فیلدها را همچنین میتوان به مولکولهای پایگاه داده تشبیه کرد. در این صورت، اتمها و ذرات خُردِ این مولکول، بیتها و بایتها هستند که به تنهایی معنایی را منتقل نمیکنند. یک «آیتم دادهای»، ممکن است برای ایجاد دیگر ساختارهای پیچیدهتر، نیز مورد استفاده قرار گیرد.
رکورد در معماری پایگاه داده چیست ؟
«رکورد» (Record)، مجموعهای از فیلدها یا آیتمهای دادهای است، که از نظر منطقی به هم مرتبط هستند. به هر فیلدِ موجود در رکورد، مقادیری اختصاص داده شده است و دارای «تعداد بایتها» و «نوع داده» (Data Type) ثابتی است. گروهی از آیتمهای دادهای، «رکوردها» را تشکیل دهند. این گروهبندی به روشهای مختلفی انجام میشود تا بتوانیم رکوردهای مختلفی را (برای نیازهای گوناگون) بسازیم. رکوردها را همچنین میتوان با استفاده از برنامههایی خاص، بازیابی یا بهروزرسانی کرد.
برای درک بهتر مفهوم رکورد، در ادامه رکوردی مربوط به اطلاعات ثبت شده دانشجویی خاص، در یک موسسه، ارائه شده است. این رکورد، فیلدهای «شماره دانشجویی»، «نام دانشجو»، «رشته» و «معدل کل» را شامل میشود.
| ۹۹۰۳۵۶ | علی اکبرزاده | مهندسی صنایع | ۱۸٫۷۵ |
فایل در معماری پایگاه داده چیست ؟
«فایل» (File)، مجموعهای از «دنباله رکوردهای مرتبط به هم» است. در بسیاری از موارد، تمام رکوردهای موجود در یک فایل، نوع رکوردِ مشابهی دارند (یعنی رکوردها، فرمت یکسانی دارند). اگر اندازه تمام رکوردهای موجود در فایل دقیقاً یکسان باشد (بر حسب بایت)، گفته میشود که این فایل از رکوردهایی با «طول ثابت» (Fixed-Length) تشکیل شده است. در غیر این صورت، اگر رکوردهای موجود در یک فایل، اندازههای متفاوتی داشته باشند، فایل مورد نظر از رکوردهایی با «طول متغیر» (Variable-Length) نگهداری میکند.

جدولی که در ادامه آورده شده است، نمونه فایلی مربوط به «حقوق و دستمزد» کارمندان یک شرکت را نشان میدهد. در این جدول، دادههای موجود در هر ستون (مانند کد پرسنلی)، «فیلد» (Field) نامیده میشود. مجموعهای از این دادهها برای کارمندی خاص (فیلدهای موجود در یک سطر یا به بیان دیگر تمام فیلدهای همه ستونها در جدول، که به کارمند خاصی اشاره دارد)، یک «رکورد» (Record) به شمار میرود. گروهی از دادههای مربوط به «حقوق و دستمزد»، برای تمام کارمندان (تمامی سطرها و ستونها)، یعنی کل جدول، نمونهای از یک «فایل» را نشان میدهد.
| کد پرسنلی | نام کارمند | پایه حقوق | تاریخ تولد | شهر محل زندگی |
| ۱۴۵۶۷۵ | علی محمودی | ۷٫۳۰۰ | ۱۳۶۵٫۰۳٫۰۱ | تهران |
| ۱۷۸۴۹۴ | جواد رضوی | ۶٫۸۰۰ | ۱۳۶۸٫۱۲٫۱۷ | تهران |
| ۱۶۳۸۲۳ | رضا علیزاده | ۶٫۸۰۰ | ۱۳۷۲٫۰۵٫۱۳ | کرج |
کاتالوگ سیستم در معماری پایگاه داده چیست ؟
«کاتالوگ سیستم» یا «فهرست سیستم» (System Catalog)، مخزنی از اطلاعات است که دادههای موجود را در پایگاه داده توصیف میکند. به این معنا که «فراداده» (Metadata) یا «دادههای مربوط به دادهها» را نگه میدارد. کاتالوگ سیستم، پایگاه دادهای «ایجاد شده توسط سیستم» (System-Created) است که تمام اشیاء پایگاه داده، اطلاعاتِ «دیکشنریِ داده» و اطلاعات دسترسی کاربر را توصیف میکند.
همچنین، دادههای مربوط به جدول، مانند نام جدول، سازندگان یا صاحبان جدول، نام ستونها، «انواع داده» (Data Types)، اندازه دادهها، کلیدهای خارجی و کلیدهای اصلی، فایلهای ایندکس شده، کاربران مجاز (مورد تأیید)، امتیازات دسترسی کاربر و غیره را توصیف میکند.
سیستم مدیریت پایگاه داده، «کاتالوگ سیستم» را میسازد و اطلاعات مربوط به آن را در فایلهای سیستمی ذخیره میکند. اگر کاربر از «مجوزهای دسترسیِ» (Access Privileges) کافی برخوردار باشد، میتواند مانند هر جدول دیگری، فایلهای سیستمی را نیز جستجو کند.

یکی از ویژگیهای اساسیِ رویکرد پایگاه داده، این است که علاوه بر خودِ پایگاه داده، شامل توصیفی کامل از ساختار پایگاه داده و «محدودیتهای» (Constraints) موجود در آن میشود. این تعاریف در «کاتالوگ سیستم» ذخیره میشوند، که حاوی اطلاعاتی مانند ساختار هر فایل، نوع و فرمت ذخیرهسازیِ هر آیتم داده و محدودیتهای مختلف بر روی دادهها است. اطلاعات ذخیره شده در کاتالوگ را فراداده یا «اَبَر داده» (Metadata) مینامند و ساختار پایگاه داده اصلی را توصیف میکند.
فراداده در معماری پایگاه داده چیست ؟
«فراداده» (Metadata)، که با نام «دیکشنری داده» هم شناخته میشود، در حقیقت، اطلاعاتی است که در مورد دادهها وجود دارد. فراداده یا «مِتا دیتا» که به آن «کاتالوگ سیستم» هم میگویند، از ماهیتِ خود توصیفی پایگاه داده ناشی میشود که استقلال «برنامه-داده» را فراهم میکند. کاتالوگ سیستم، با یکپارچهسازیِ ابردادهها، اشیای موجود در پایگاه داده را توضیح میدهد و در نتیجه، دسترسی و مدیریت آن اشیاء آسانتر میشود. فراداده، علاوه بر ساختار پایگاه داده، «محدودیتها» (Constraints)، برنامهها، مجوزها و غیره را نیز توصیف میکند. اینها اغلب به عنوان ابزاری جداییناپذیر برای مدیریت منابع اطلاعاتی به کار گرفته میشوند.
فراداده را میتوان در «اسنادی» (Documentation) پیدا کرد که سیستمهای منبع را توصیف میکنند. از این توصیفها برای تحلیل فایلهایِ منبع انتخابی به منظور پُر کردن «انبار» (Warehouse) دادههای بزرگ استفاده میشود. مدیریت مؤثر یک انبار سازمانی، تا حد زیادی، به جمعآوری و ذخیره ابردادهها متکی است. بنابراین، «فراداده» یکی از محصولات جانبی مهم، از فرایند «یکپارچهسازی دادهها» محسوب میشود. از این اطلاعات، برای درک محتوای منبع و تمام مراحل تبدیلی، که از آن عبور میکند و همچنین، نحوه توصیف نهایی آن در سیستم هدف یا انبار داده، استفاده میشود.

«مِتا دِیتا»، به برنامهنویسانی که از آن استفاده میکنند، کمک میکند تا برنامهها، پرسوجوها، کنترلها و رویهها را برای مدیریت و دستکاری دادههای انباره، توسعه دهند. فراداده همچنین برای ایجاد گزارشها و نمودارها، در ابزارهای کاربر پسند و همچنین برای مدیریت دادههای کل سازمان و گزارش تغییرات برای کاربر نهایی، مورد استفاده قرار میگیرد.
زبان تعریف داده چیست؟
«زبانِ تعریف داده» (Data Definition Language | DDL) که با نام «زبان توصیف داده» نیز شناخته میشود، زبان خاصی است که برای تعیین «طرحواره» (Schema) مفهومی پایگاه داده، با به کارگیری مجموعهای از تعاریف، مورد استفاده قرار میگیرد. این زبان از تعریف (یا اِعلان) اشیاء پایگاه داده، نیز پشتیبانی میکند. DDL به DBA (مدیر پایگاه داده) یا کاربر اجازه میدهد تا موجودیتها، ویژگیها و روابط مورد نیاز برای برنامه را به همراه هرگونه یکپارچگی مرتبط و محدودیتهای امنیتی، توصیف و نامگذاری کند.
از نظر تئوری، DDL-های متفاوتی برای هر طرحواره در معماری ۳ سطحی (مثلاً برای طرحوارههای مفهومی، داخلی و خارجی) تعریف شده است. با این حال، در عمل، تنها یک DDL جامع وجود دارد که اجازه میدهد تا حداقل، طرحوارههای مفهومی و خارجی را مشخص کنیم. روشهای گوناگونی برای نوشتن «زبان تعریف داده» وجود دارد. یکی از پرکاربردترینِ این روشها، نوشتن آن درون «فایل متنی» (Text File) است. درست، شبیه به نوشتن سورس برنامه، که با زبانهای برنامهنویسی دیگر انجام میشود).

در روشهای دیگر، از کامپایلر یا مفسرِ DDL، برای پردازش فایل یا دستورات آن استفاده میکنند. هدف این است که معرفی توصیفهای ساختاری طرحواره و ذخیره توضیحات آن در فهرست DBMS (یا جدولهای) که توسط DBMS قابل درک است، انجام شود. نتیجه کامپایل دستورات DDL، مجموعهای از جدولها ذخیره شده در فایل خاصی است که بهطور جمعی، بهنام «گزارش سیستم» (System Log) یا دیکشنری داده، ذخیره میشود. برای نمونه، دستورات DDL، که در ادامه ارائه شدهاند را در نظر بگیرید.
با اجرای این دستورات، جدولهایSALES،CUSTOMERوPRODUCTساخته میشوند. ساختار این جدولها در تصویری که در ادامه آمده، مشخص است.

پایگاه داده چیست؟
«پایگاه داده» (Database)، مجموعهای سازمانیافته از دادهها است که به راحتی میتوان به محتوای آن دسترسی داشت و آن را مدیریت کرد. با استفاده از «دیتابیس»، میتوانیم دادهها را در قالب جدولها، سطرها و ستونها سازماندهی کنیم و با نمایه (ایندکس) کردن آن، فرایند یافتنِ اطلاعات مرتبط را آسانتر کنیم. پایگاههای داده، بهگونهای ایجاد میشوند که تنها، مجموعهای خاص از برنامههای نرمافزاری، دسترسی به دادهها را برای همه کاربران فراهم میکنند. هدف اصلی پایگاه داده این است که حجم زیادی از اطلاعات را از طریق ذخیره، بازیابی و مدیریت دادهها، به کار ببندد.
امروزه، بخش اعظمی از وبسایتها و اپلیکشنها، به صورت پویا، در محیط وب یا سایر پلتفرمها وجود دارند که از پایگاه داده استفاده میکنند. به عنوان نمونه، وبسایتی پویا را میتوان در نظر گرفت که «موجود بودن اتاقهای یک هتل، برای رزرو» را بررسی میکند.

کسب و کارها با هدف اینکه تصمیمگیریهای مؤثری داشته باشند، نیاز به دادههایی دارند که دقیق و قابل اعتماد باشند. بههمین منظور، رکوردهای مربوط به موارد مختلف و همچنین روابط بین آنها را نگهداری میکنند. به این گونه دادههای جمعآوری شده که با یکدیگر مرتبط هستند، اصطلاحاً «پایگاه داده» گفته میشود.
بنابراین، سیستم پایگاه داده، شامل مجموعهای یکپارچه از فایلهای مرتبطی است که جزئیاتی را برای تفسیر دادههای موجود در آن، به همراه دارد. اساساً، سیستم پایگاه داده چیزی بیش از یک سیستم نگهداری سوابق کامپیوتری نیست که هدف کلی آن ثبت و نگهداری اطلاعات یا دادهها است.
سیستم مدیریت پایگاه داده چیست ؟
«سیستم مدیریت پایگاه داده» (DBMS)، نرمافزاری است که امکان دسترسی به دادههای موجود در پایگاه داده را فراهم میکند. هدف DBMS، ارائه روشی مناسب و مؤثر برای تعریف و ذخیرهسازی اطلاعات روی پایگاه داده، و بازیابیِ اطلاعات از آن است.
نما در معماری پایگاه داده چیست ؟
«نمای» (View) پایگاه داده، زیرمجموعهای از پایگاه داده محسوب میشود و بر مبنای «پرسوجویی» (کوئری) است که روی یک یا چند جدول پایگاه داده اجرا میشود. نماهای پایگاه داده به عنوان پرسوجوهای نامگذاری شده، در پایگاه داده ذخیره میشوند و میتوان از آنها، برای ذخیرهسازی پرسوجوهای پیچیده و پرکاربرد استفاده کرد.
نماهای پایگاه داده، در ۲ نوعِ «نماهای پویا» و «نماهای ایستا» وجود دارند. نماهای پویا میتوانند حاوی دادههایی از یک یا ۲ جدول باشند و بهطور خودکار همه ستونهای جدول یا جدولهای مشخص شده را شامل شوند. هنگام ایجاد یا تغییر اشیاء «مرتبط» یا اشیاء «توسعه داده شده»، نماهای پویا به طور خودکار بهروز میشوند. نماهای ایستا میتوانند حاوی دادههایی از چندین جدول باشند و ستونهای مورد نیاز از این جدولها باید در عبارتهای «SELECT» و «WHERE» از نمای ایستا مشخص شوند. هنگام ایجاد یا تغییر اشیاء، نماهای ایستا باید به صورت دستی بهروز شوند.
طرح واره در معماری پایگاه داده چیست ؟
شِما یا «طرحواره» (Schema) پایگاه داده، نحوه سازماندهی دادهها در پایگاه داده رابطهای را تعریف میکند و محدودیتهای منطقی، مانند نام جدول، فیلدها، «نوع دادهها» (Data Types) و روابط بین این موجودیتها را شامل میشود. طرحوارهها معمولاً از نمایشهای بصری برای برقراری ارتباط با معماری پایگاه داده استفاده میکنند.
انواع معماری های سیستم پایگاه داده کدامند؟
نحوه طراحی یک سیستم پایگاه داده، تا حد زیادی به چارچوب کامپیوتری بستگی دارد که قرار است روی آن اجرا شود. منظور از چارچوب، بخشهایی از معماری کامپیوتر، از جمله، «مدیریتِ» (Administration) شبکه، «موازیسازی» (Parallelism) و «توزیع» (Distribution) است که در ادامه، به شرح هر یک از این موارد میپردازیم.

«مدیریت سیستمِ» (System’s Administration) کامپیوترهای شخصی، امکان اجرای چند «کار» (Job) را روی سیستم سرور و چندین «وظیفه» (Task) را در سیستمهای کلاینت فراهم میکند. این نوع تقسیم کار، منجر به ظهورِ سیستمهای پایگاه داده «کلاینت-سروری» (Client-Server) شده است.
سیستمهای کامپیوتری، میتوانند با انجامِ همزمانِ چندین کار، با به کارگیری «پردازش موازی» (Parallel Processing)، سریعتر کار کنند که در نتیجه، باعث بهبود و تسریع در پاسخگویی به «تراکنشهایِ» (Transactions) موجود در پایگاه داده میشود. نیازِ به رسیدگی و مدیریتِ پرسوجوهای موازی، «سیستمهای پایگاه داده موازی» (Parallel Database Systems) را ایجاد کرده است.
پایگاه داده «توزیع شده» (Distributed)، اشاره به پایگاه دادهای دارد که عناصر ذخیرهسازی در آن، به جای کامپیوتری واحد، ممکن است در مجموعهای از کامپیوترهایِ متصل به هم (چندین کامپیوتر) قرار گرفته باشد که در محلی مشترک (از نظر فیزیکی)، نگهداری میشوند.

اگر به دنبال اطلاعاتی در مورد معماری «سیستم پایگاه داده» (Database System) هستید، مطالعه ادامه این مطلب از مجله فرادرس را به شما توصیه میکنیم. در اینجا با پاسخ این پرسش که «معماری پایگاه داده چیست»، موارد مختلفی از جمله سیستمهای پایگاه داده «متمرکز» (Centralized)، پایگاه داده «موازی» (Parallel) و پایگاه داده «توزیعشده» (Distributed) را مورد بررسی قرار میدهیم. در این قسمت از مطلبِ «معماری پایگاه داده چیست»، با انواع معماریهای معرفی شده برای پایگاه داده، آشنا میشویم. هر یک از انواع معماری پایگاه داده در ادامه فهرست شدهاند و سپس در بخشهایی جداگانه توضیحاتی برای هر یک ارائه میشود.
- معماری ۳ لایه ANSI/SPARC
- پایگاه داده متمرکز
- معماری پایگاه داده توزیع شده
- پایگاه داده موازی
- معماری پایگاه داده سرور
معماری ANSI/SPARC چیست ؟
در سال ۱۳۵۰ (۱۹۷۱ میلادی)، «کارگروهِ پایگاه داده» (Data Base Task Group | DBTG)، طرحی پیشنهادی برای معماری عمومی سیستمهای پایگاه داده ارائه داد. این طرح، معماری ۲ لایهای، شامل نمای سیستمی به نام «Schema» و نماهای کاربری موسوم به «زیر Schemaها» بود.
«موسسه استاندارد ملی آمریکا» (ANSI) و کمیته برنامهریزی استانداردها و الزامات (SPARC)، معماریِ ۳ لایهای را در سال ۱۳۵۴ (۱۹۷۵ میلادی)، به همراه «فهرست سیستم» (System Catalog)، ایجاد کردند. میتوان گفت که امروزه، معماریِ اغلب سیستمهای مدیریت پایگاه داده تجاری، به نوعی، بر مبنای طرح «ANSI/SPARC»، توسعه یافتهاند.
ویژگیهای معماری پایگاه داده ۳ سطحی چیست ؟
برخی از ویژگیهای معماری ۳ سطحی، در ادامه بیان شده است.
- همه کاربران باید بتوانند به دادههای یکسانی دسترسی داشته باشند. این مورد به این منظور اهمیت دارد که پایگاه داده، تمام دادهها را در محلی واحد ذخیره میکند و همه کاربران، روش مخصوص به خود را برای تعامل با داده و استفاده از آن دارند.
- View یا نمایِ کاربر، تحت تأثیر تغییراتِ ایجاد شده در سایر نماها قرار نمیگیرد. به دلیل اینکه، نیازِ هر یک از کاربران، مستقل از کاربر دیگر است و تغییرات صورت گرفته در نمای یک کاربر، نباید سایر نماهای مربوط به کاربرانِ دیگر را تحت تأثیر قرار دهد.
- نیازی نیست که کاربران از جزئیات ذخیرهسازی «پایگاه داده فیزیکی» مطلع باشند. از آنجایی که ممکن است کاربرانِ پایگاه داده، افرادی کم تجربه (کم مهارت) باشند، به همین دلیل، جزئیات فیزیکی و سختافزاری، باید برای چنین کاربرانی مخفی یا اصطلاحاٌ به صورت «جعبه سیاه» باشد.
- «مدیران پایگاه داده» (DBA)، باید بتوانند ساختار ذخیرهسازی پایگاه داده را بدون تاثیرگذاری بر نماهای کاربران دیگر، تغییر دهند. تغییر در سازماندهی فایل یا روش دسترسی به آن، نباید بر ساختار دادهها تأثیر بگذارد که در این صورت، تأثیری بر روی کاربران نیز نخواهد داشت.
- تغییراتی که در جنبههای فیزیکی ذخیرهسازی، مانند تغییر «هارد دیسک» صورت میگیرد، نباید ساختار داخلی پایگاه داده را تحت تأثیر قرار دهد.
- در هر سیستم پایگاه داده، DBA، این امتیاز را دارد که ساختار پایگاه داده را تغییر دهد. منظور، مواردی مانند افزودن جدولها، درج یا حذف «ویژگیها» (Attributes)، تغییر مشخصات اشیا موجود در پایگاه داده و موارد اینچنینی است.
همانطور که اشاره کردیم، ANSI/SPARC، رویکردی ۳ سطحی به همراه «فهرست سیستم» را ارائه میدهد. در ادامه، سطوح موجود در این معماری بیان شده است، که آنها را با هم مرور میکنیم.
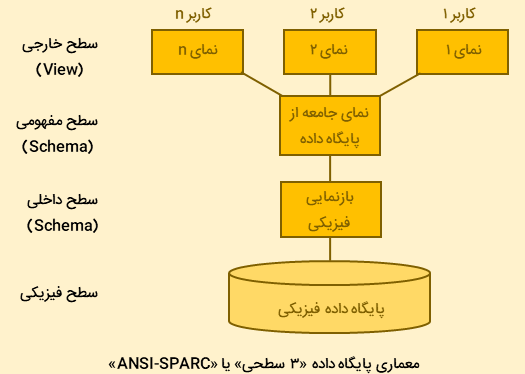
معماری «ANSI/SPARC»، شامل ۳ سطح داخلی (درک دادهها توسط DBMS و سیستم عامل)، خارجی (درک دادهها توسط کاربران) و مفهومی است. نمای هر یک از این سطوح، به وسیله «طرحوارهای» (Schema)، توصیف میشود و طرحواره در اینجا، طرحی است که رکوردها، ویژگیها و روابط موجود در یک نما را بیان میکند. واژههای «نًما» و «طرحواره» گاهی اوقات به جای یکدیگر هم مورد استفاده قرار میگیرند.
برای تعریف طرحوارههای «خارجی» و «مفهومی»، از «زبان تعریف داده» (Data Definition Language | DDL) استفاده میشود. از دستورات «زبان پرسوجوی ساختیافته» (Structured Query Language | SQL)، نیز برای تعریف جنبههای فیزیکی (یا طرحواره داخلی) استفاده میکنیم. اطلاعات مربوط به طرحوارههای داخلی، مفهومی و خارجی، در کاتالوگِ سیستم، ذخیره میشوند. به بیان دیگر، ویژگیهای این ۳ لایه را بهطوریکه در ادامه آمده است، میتوان بیان کرد.
- سطح «داخلی» (Internal): به نحوه ذخیرهسازی دادهها به صورت فیزیکی، میپردازد. جایی که دادهها در واقع به صورت ساختارهای دادهای و فایلها ذخیره میشوند.
- «مفهومی» (Conceptual): سطح مفهومی به نحوه مشاهده دادهها توسط کاربران، اشاره دارد.
- سطح «خارجی» (External): این سطح، به عنوان رابطی بین ۲ سطح دیگر عمل میکند.

در ادامه، با بیان یک مثال، توضیحات بیشتری را در رابطه با هر کدام از این سطوح، بیان میکنیم.
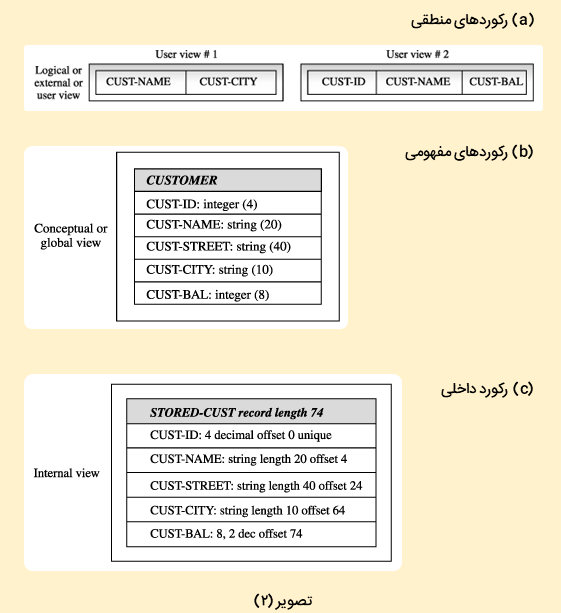
در این مثال، همانطور که در تصویر (۱) قسمت «a» مشخص است، رکورد «CUSTOMER» را مورد بررسی قرار دادهایم. تعریف یکپارچه از رکورد «CUSTOMER»، نیز در قسمت «b» این تصویر مشخص است. با توجه به تصویر (۲)، «دادهها» در ۳ سطحِ متناظر با ۳ نما (یعنی نماهای داخلی، مفهومی و خارجی) انتزاع شده است (از هم جدا شدهاند).
همانطور که در تصویر (۲) مشخص است، پایینترین سطح از انتزاع دادهها، نحوه ذخیرهسازی دادهها را توصیف میکند و «نمای داخلی» نام دارد. سطح دوم انتزاع، نمای مفهومی یا «کلی» (Global) است. بالاترین سطح انتراعی یا سطح سوم هم، نمای خارجی است که توسط کاربر یا برنامه کاربردی مشاهده میشود و آن را به نام «نمای کاربر»، میشناسیم. لازم به ذکر است که نمای «مفهومی»، مجموع نمای کاربر یا نمای خارجی دادهها است. با توجه به تصویر (۲)، میتوان مواردی که در ادامه بیان میشوند را استنتاج کرد.
- در سطح داخلی (یا فیزیکی)، مشتریان (Customers) در نوعی رکورد بهنام «STORED-CUST»، ذخیره میشوند که ۷۴ کاراکتر (یا بایت) طول دارد. همانطور که در قسمت «c» مشخص است، رکورد «CUSTOMER»، پنج فیلد (یا آیتمِ دادهای) بهنامهای «CUST-NAME»، «CUST-CITY»، «CUST-STREET»،«CUST-ID» و «CUST-BAL» را شامل میشود که متناظر با ۵ ویژگی مربوط به مشتریان است.
- در سطح مفهومی یا جهانی (Global)، با توجه به قسمت «b»، پایگاه داده، حاوی اطلاعات مربوط به نوعی موجودیت، به نام «CUSTOMER» است. که فیلدهای CUST-ID (۴ رقم)، CUST-NAME (۲۰ کاراکتر)، CUST-STREET (۴۰ کاراکتر)، CUST-CITY (۱۰ کاراکتر) و CUST-BAL (۸ رقم) را شامل میشود.
- «نمای کاربر ۱» (user view 1) در قسمت «a»، دارای طرحوارهای «خارجی» از پایگاه داده است که در آن هر مشتری با رکوردی حاوی ۲ فیلد (یا آیتم دادهای)، به نامهای «CUST-NAME» و «CUST-CITY»، نشان داده میشود. ۳ فیلد دیگر برای این کاربر، سودی ندارند، بنابراین حذف شدهاند.
- «نمای کاربر ۲» (user view 2) در قسمت «a»، دارای طرحوارهای «خارجی» از پایگاه داده است که در آن هر مشتری با رکوردی حاوی ۳ فیلد (یا آیتم دادهای)، بهنامهای «CUST-ID» و «CUST-NAME» و «CUST-BAL»، نشان داده میشود. بهدلیل اینکه کاربر علاقهای به ۲ فیلد دیگر ندارد، بنابراین آنها کنار گذاشته شدند.
- در هر پایگاه داده، تنها یک «طرحواره مفهومی» و یک «طرحواره داخلی» وجود دارد.
سطح خارجی در معماری ANSI SPARC چیست؟
سطح خارجی بهطور خلاصه، نمایی است که کاربر از پایگاه داده دارد (طوری که کاربر، پایگاه داده را میبیند). این سطح، که بالاترین سطحِ انتزاعِ داده است، تنها، بخشی از پایگاه داده را توصیف میکند که به هر کاربر یا برنامه مربوط میشود. سطح خارجی تعدادی نمای خارجی مختلف از پایگاه داده را شامل میشود.

هر کاربر، نمایی از «دنیای واقعی» دارد که در قالبی مناسب (و شناخته شده) برای آن کاربر نمایش داده شده است. نمای خارجی، فقط شامل آن دسته از موجودیتها، ویژگیها و «روابط» (Relationships) در «دنیای واقعی» میشود که کاربر به آنها علاقه دارد. سایر «موجودیتها» (Entities)، ویژگیها یا روابطی که دلخواه کاربر نیستند، ممکن است در پایگاه داده، ارائه شوند اما کاربر از آنها بیاطلاع باشد. برای یک نمای مفهومی یا کلی از پایگاه داده، هر تعداد از نماهای کاربر، حتی «یکسان» (مشابه)، ممکن است وجود داشته باشد.
علاوه بر این، نماهای مختلف، ممکن است بازنماییهای متفاوتی را از دادههای مشابه، داشته باشند. به عنوان مثال، یک کاربر، ممکن است تاریخها را به شکل «روز، ماه، سال» مشاهده کند، در حالی که کاربر دیگر ممکن است آنها را به صورت «سال، ماه، روز» ببیند. برخی از نماها، ممکن است شامل دادههای «مشتق شده» یا «محاسبه شده» باشند. دادههایی که در واقع، در پایگاه داده ذخیره نشدهاند، اما در صورت نیاز، ایجاد میشوند.
به عنوان مثال، واحد منابع انسانی را در سازمانی در نظر بگیرید، ممکن است بخواهیم سن یکی از کارکنان را مشاهده کنیم. احتمال کمی وجود دارد که ویژگی «سن» در پایگاه داده ذخیره شده باشد، زیرا این نوع دادهها باید مرتباٌ به روز شوند. درعوض، از آنجاییکه به احتمال قوی، تاریخ تولد کارمند ذخیره شده است، با ارجاعِ به آن، سن کارمند توسط «سیستم مدیریت پایگاه داده» محاسبه میشود. نماها، حتی میتوانند شامل دادههای ترکیبی یا مشتق شده از چندین موجودیت، نیز باشند.
هر نمای خارجی، طرحواره خارجی خود را دارد که شامل تعریف رکوردهای منطقی و روابط در نمای خارجی مشود. طرحواره خارجی، همچنین نحوه استخراج اشیاء (مانند موجودیتها، ویژگیها و روابط) در نمای خارجی، از اشیاء موجود را تشریح میکند. طرحوارههای خارجی، به تک تک کاربران یا گروهها اجازه میدهد تا دسترسی به دادههای خود را شخصیسازی کنند.
هر پایگاه داده، تنها «یک» طرحواره داخلی یا فیزیکی و یک طرح مفهومی دارد. به دلیل اینکه تنها یک مجموعه از روابط ذخیره شده موجود است (تصویر ۲، قسمتهای «a» و «b»). با این حال، هر پایگاه داده میتواند چندین طرحواره خارجی داشته باشد که هر کدام برای گروه کاربری خاصی، سفارشی شده است. طرحواره خارجی، با استفاده از زبان تعریف داده خارجی (DDL خارجی) ایجاد میشود.
این طرحواره، همچنین، شامل روش استخراج اشیاء (مانند موجودیتها، ویژگیها و روابط) در نمای خارجی از شی موجود در نمای مفهومی است. طرحوارههای خارجی اجازه میدهند تا دسترسی به دادهها در سطح تک تک کاربران یا گروهی از کاربران، سفارشی شود. تصویر (۲)، قسمت «a»، رکورد نمای خارجی (یا کاربری) پایگاه داده را نشان میدهد.
سطح مفهومی در معماری ANSI SPARC چیست؟
سطح مفهومی یا سطح میانی در معماری ۳ لایه پایگاه داده، بیانگر نمایی است که «اجتماع» (Community)، از پایگاه داده دارد (به بیان ساده، روشی که «کامیونیتی» پایگاه داده را میبیند). این سطح توضیح میدهد که چه اطلاعاتی باید در پایگاه داده ذخیره شوند. همچنین چه روابطی بین دادهها وجود دارد. سطح میانی، شامل ساختارِ منطقی کل پایگاه داده است که توسط DBA، دیده میشود و نمایی کامل از الزامات دادهای سازمان را تشکیل میدهد که مستقل از هرگونه ملاحظات ذخیرهسازی است.
طرحواره مفهومی، نمایی مفهومی را تعریف میکند که به آن طرحواره منطقی نیز میگویند. تنها یک طرح مفهومی در هر پایگاه داده وجود دارد. تصویر (۲)، قسمت «b»، رکورد نمای مفهومی پایگاه داده را نشان میدهد. این طرحواره شامل روش استخراج اشیاء (در نمای مفهومی) از اشیای موجود در نمای داخلی است. در ادامه مواردی فهرست شدهاند که به وسیله سطح مفهومی بیان میشوند.
- همه موجودیتها، ویژگیها و روابط بین آنها
- محدودیتهایی موجود روی دادهها
- اطلاعات معنایی در مورد دادهها
- بررسیهای مربوط به حفظ ثبات و درستی دادهها
- اطلاعات امنیت و یکپارچگی دادهها
سطح مفهومی، از هر نمای خارجی (نمایی که مربوط به سطح خارجی است) پشتیبانی میکند، به این صورت که هر داده مورد دسترس کاربر، باید در سطح مفهومی موجود باشد یا از آن مشتق شود. در عین حال، این سطح نباید جزئیات وابسته به ذخیرهسازی را شامل شود. برای مثال، توصیف یک موجودیت باید فقط شامل «انواع دادهها» (Data Types)، ویژگیها (به عنوان مثال، عدد صحیح، حقیقی یا کاراکتر بودن آن) و طول آنها (مانند حداکثر تعداد ارقام یا کاراکترها) باشد، اما در مقابل، شامل ملاحظات ذخیرهسازی، مانند «تعداد بایتهای اشغال شده»، نباشد.
انتخاب رابطهها (Relations) و همچنین فیلد (یا آیتم دادهای) برای هر یک از این روابط، همیشه واضح (مشخص) نیست. فرایندی که منجر به طرحواره مفهومی مناسبی میشود، «طراحی پایگاه داده مفهومی» نام دارد و با استفاده از زبان تعریف دادهِ مفهومی (DDL مفهومی)، نوشته شده است.
سطح داخلی در معماری ANSI SPARC چیست؟
بهطور خلاصه میتوان گفت که این سطح، «نمایش فیزیکی» پایگاه داده در کامپیوتر را بیان میکند و در پایینترین سطح انتزاع پایگاه داده وجود دارد. سطح داخلی، نحوه ذخیره دادهها در پایگاه داده، و همچنین ساختارهای دادهای، ساختارهای فایل و روشهای دسترسی مورد استفاده توسط پایگاه داده را توصیف میکند. این سطح، پیادهسازی فیزیکی پایگاه داده، برای دستیابی به عملکرد بهینه زمان اجرا و استفاده از فضای ذخیرهسازی را شامل میشود.
سطح داخلی یا درونی، بیانگر روشی است که DBMS و سیستم عامل، دادههای موجود در پایگاه داده را درک میکنند. مثال بیان شده در تصویر (۲)، قسمت «c»، رکورد نمای داخلیِ پایگاه دادهای را نشان میدهد. درست در زیر سطح داخلی، ساختار دادههای سطح فیزیکی وجود دارد که اجرای آن توسط سطح داخلی، برای دستیابی به عملکرد معمول و استفاده از فضای ذخیرهسازی، پوشش داده شده است. طرحواره داخلی، بیانگر سطح (یا نمای) داخلی است و شامل تعریف رکورد ذخیره شده، روش نمایش فیلدهای داده (یا ویژگیها)، شاخصگذاری و «هش کردن»، و همچنین روشهای دسترسی مورد استفاده را، شامل میشود.
سطح داخلی، اساساً نشان میدهد که چگونه روابط توصیف شده در طرح مفهومی، بر روی دستگاههای ذخیرهسازی ثانویه (مانند دیسکها و نوارها)، ذخیره میشوند. این سطح، همچنین با روشهای دسترسی (تکنیکهای مدیریت فایل برای ذخیره و بازیابی رکوردهای دادهای) سیستم عامل برای ضبط دادهها روی دستگاههای ذخیرهسازی، ایجاد نمایهها، بازیابی دادهها و سایر موارد، ارتباط برقرار میکند.
سطح داخلی مربوط به مواردی است که در ادامه بیان میشود.
- تخصیص فضای ذخیرهسازی برای دادهها و ذخیرهسازی
- توضیحات مربوط به رکوردها، برای ذخیرهسازی (به همراه اندازههای ذخیره شده برای اقلام دادهای).
- ضبط رکورد
- تکنیکهای «فشردهسازی» (Compression) و «رمزگذاری» (Encryption) دادهها
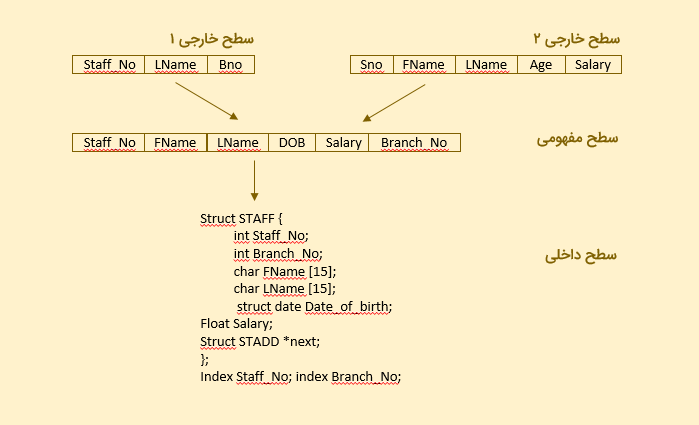
روند دستیابی به طرحواره مطلوب داخلی (یا فیزیکی)، طراحی پایگاه داده فیزیکی نام دارد و با استفاده از SQL یا «زبان تعریف داده داخلی» (Internal Data Definition Language | DDL) یا (DDL داخلی)، نوشته شده است. علاوه بر مواردی که تا اینجا بیان کردیم، معماری ۳ سطحی ANSI SPARC، قابلیتهای بسیار بیشتری را ارائه میدهد. مثالی که در ادامه آورده شده است، میتواند درک بهتری را در مورد تفاوت لایههای موجود در معماری ANSI SPARC، به شما بدهد.
مزایای ۳ لایه ای بودن معماری پایگاه داده چیست ؟
هدف اصلی که معماری پایگاه داده ۳ لایه دنبال میکند، «جداسازی» (Isolate) هر نمای کاربر پایگاه داده، از نحوه ذخیره یا نمایش فیزیکی پایگاه داده است. در ادامه، مزایای مربوط به معماری پایگاه داده ۳ لایه آورده شده است.

- مدیر پایگاه داده (DBA)، میتواند ساختار پایگاه داده را تغییر دهد، بدون اینکه تاثیری روی کاربران داشته باشد.
- مدیر پایگاه داده، همچنین میتواند ساختارهای مربوط به ذخیرهسازی پایگاه داده را بدون تاثیر روی نماهای کاربر، تغییر دهد.
- کاربران میتوانند به دادههایی یکسان، اما با نمای دادهای سفارشی متفاوتی (باتوجه به نیازهای خود)، دسترسی داشته باشند. هر کاربر میتواند نحوه مشاهده دادهها را تغییر دهد و این تغییر، بر سایر کاربران همان پایگاه داده تأثیری نمیگذارد.
- تعامل کاربر با پایگاه داده مستقل از ساختار ذخیرهسازی دادههای فیزیکی است و نگرانی از این بابت برای کاربر، وجود ندارد.
- ساختار داخلی پایگاه داده، تحت تأثیر تغییرات ساختار ذخیرهسازی فیزیکی (مانند تغییر دستگاه ذخیرهسازی به نوعی جدیدتر)، قرار نمیگیرد.
ویژگیهای معماری ۳ لایه پایگاه داده چیست ؟
در ادامه، جدولی آورده شده است که میزان انتزاع، ویژگیها و نوع سیستمهای مدیریت پایگاه داده مورد استفاده برای معماری ۳ سطحی را نشان میدهد.
| ویژگیها | سطح انتزاعی | سطح فیزیکی | سطح داخلی | سطح مفهومی | سطح خارجی |
| درجه انتزاع | کم | متوسط | زیاد | متوسط | |
| ویژگیها | به نرمافزار و سختافزار وابسته است. | به نرمافزار و سختافزار وابسته است. | به نرمافزار و سختافزار وابسته است. | به نرمافزار و سختافزار وابسته است. | |
| میزان دانش و تخصص مورد نیاز طراح پایگاه داده | DBMS-های سلسله مراتبی | لازم است به جزئیات سطح فیزیکی توجه شود. | لازم است به جزئیات سطح فیزیکی توجه شود. | لازم است به جزئیات سطح فیزیکی توجه شود. | لازم است به جزئیات سطح فیزیکی توجه شود. |
| DBMS-های شبکهای | لازم است به جزئیات سطح فیزیکی توجه شود. | لازم است به جزئیات سطح فیزیکی توجه شود. | لازم است به جزئیات سطح فیزیکی توجه شود. | لازم است به جزئیات سطح فیزیکی توجه شود. | |
| DBMS-های رابطهای | هیچ نگرانی در مورد جزئیات سطح فیزیکی وجود ندارد. | هیچ نگرانی در مورد جزئیات سطح فیزیکی وجود ندارد. | هیچ نگرانی در مورد جزئیات سطح فیزیکی وجود ندارد. | هیچ نگرانی در مورد جزئیات سطح فیزیکی وجود ندارد. |
در سیستم پایگاه داده سنتی، دادهها در چندین فایل ذخیره میشدند. به عنوان مثال، دادههای هر مشتری ممکن بود در فایلی جداگانه ذخیره شوند. در مقابل، یک سیستم پایگاه داده متمرکز تمام دادهها را در یک فایل ذخیره میکند. این کار مدیریت دادهها و همچنین جستجوی آنها را آسانتر میسازد، زیرا همگی در مکانی واحد ذخیره شدهاند.
سیستم پایگاه داده متمرکز چیست؟
«پایگاه داده متمرکز» (Centralized Database | CDB)، پایگاه دادهای است که در مکانی واحد قرار دارد و عملیات ذخیرهسازی و نگهداری دادهها در همانجا انجام میشود. این مکان، معمولاً، کامپیوتر یا سیستم پایگاه داده مرکزی، به عنوان مثال، کامپیوتری رومیزی، سرور، یا «Mainframe» است.
این نوع از پایگاه داده، در بیشتر موارد، توسط موسسات (مانند دانشگاه)، سازمانها (مانند شرکتهای تجاری) و غیره مورد استفاده قرار میگیرد. کاربران از طریق شبکه کامپیوتری، میتوانند به پایگاه داده متمرکز و به پردازنده مرکزی (که به منظور پردازش پایگاه داده اختصاص داده شده است)، دسترسی داشته باشند.
بنابراین، سیستم مدیریت پایگاه داده متمرکز، که بهنام «سیستم پایگاه داده کامپیوتر مرکزی» (Central Computer Database System)، نیز شناخته میشود، بیشتر در سازمانها، شرکتهای تجاری یا موسسات، برای متمرکز کردن وظایف (Tasks) مورد استفاده قرار میگیرد. کامپیوترهای «مِینفِریم» (Mainframe)، نمونهای از سیستم مدیریت پایگاه داده متمرکز، محسوب میشود.

اهداف سیستم پایگاه داده متمرکز چیست ؟
در این قسمت، برخی از اهداف سیستم پایگاه داده متمرکز، بیان شده است.
- «پردازش پرسوجوی توزیع شده» (Distributed Query Processing): عملکرد اصلی سیستم مدیریت پایگاه داده متمرکز، فراهم کردن امکانات و قابلیت دسترسی به تمام کامپیوترهای متصل است که همه الزامات (نیازهای) درخواست شده به وسیله هر «گره» (Node) را برآورده میسازد.
- «واحد مرکزی منفرد» (Single Central Unit): تمام دادهها و اطلاعات موجود، در سیستم مدیریت پایگاه داده متمرکز ذخیره میشوند. در اینجا، سیستمی کامپیوتری که الزامات تمام کامپیوترهای متصل را برآورده میکند، بهعناون «سرور» و سایر کامپیوترها به عنوان «کلاینت» شناخته میشوند.
- شفافیت (Transparency): تمامی پرسوجوها در سیستم کامپیوتری منفرد پردازش میشوند که به عنوان سرور نیز شناخته شده است. در این سیستم مدیریتی، هیچ داده «تکراری» (Duplication) یا «بیربطی» (Irrelevant)، ذخیره نمیشود و تمام کامپیوترهای متصل، برای پردازش پرسوجوی مورد نیاز خود، به کامپیوتر مرکزی دسترسی دارند.
- «مقیاسپذیری» (Scalable)، کامپیوترهای متعددی را میتوان به سیستم مدیریت پایگاه داده متمرکز اضافه کرد. این کامپیوترها از طریق شبکه به سیستم، متصل میشوند.
کاربردهای پایگاه داده های متمرکز کدام اند؟
پایگاه دادههای متمرکز، اغلب توسط سازمانها، برای ذخیرهسازی دادههایی مورد استفاده قرار میگیرند که به وسیله بسیاری از کاربران، به اشتراک گذاشته شدهاند. به بیان دیگر، مشاغل کوچک یا شرکتهای بزرگ، برای ذخیره اطلاعات مشتری، دادههای موجودی، سوابق مالی و بسیاری موارد دیگر، از این نوع سیستمها کمک میگیرند. در مقایسه با سایر سیستمها، این نوع از پایگاههای داده، مزایا و قابلیتهای زیادی را ارائه میدهند.
هر فردی با در اختیار داشتن مجوزهای لازم، میتواند به پایگاه داده متمرکز، دسترسی داشته باشد. این بدان معنی است که چندین نفر میتوانند بهطور همزمان روی دادهای مشابه کار کنند که این مورد میتواند صرفهجویی در زمان را به دنبال داشته باشد. همچنین، امکان همکاری یا مشارکت بهتر را فراهم میکند. زیرا افراد، به راحتی میتوانند دادهها و ایدهها را به طور قابل اعتمادی به اشتراک بگذارند. چون این نوع سیستمها، بر روی سرورهایی میزبانی میشوند که با هدف فعال بودن دائمی، طراحی شدهاند. یعنی اگر یکی از سرورها با مشکلی مواجه شود و از کار بیفتد، سایر سرورها همچنان قابل دسترسی هستند.
مزایای پایگاه داده متمرکز چیست ؟
پایگاه داده متمرکز، مزایای قابل توجهی را در مقایسه با سیستمهای دیگر پایگاه داده دارا است. در ادامه برخی از این مزایا، از جمله، یکپارچگی دادهها، افزونگی دادهها، امنیت، مقیاسپذیری و بومیسازی، قابلیتحمل، نیازمند هزینه بودن و نیازِ کمتر به نگهداری، شرح داده شده است.
- از آنجایی که دادهها، در مکانی فیزیکی و سیستم کامپیوتریِ واحدی ذخیره و مدیریت میشوند، دارای «یکپارچگی» (Integrity) حداکثری هستند. در نتیجه، سازماندهی و هماهنگسازی دادهها، برای به دست آوردن دادههای قابل اعتمادتر و معنیدار، آسانتر است.
- در پایگاه داده متمرکز، حداقل میزان «افزونگی» (Redundancy) دادهها را شاهد هستیم. تمام دادهها با هم ذخیره میشوند و در مکانهای مختلف پراکنده نشدهاند. بنابراین، اطمینان از اینکه دادههای اضافی مانند نسخه «تکراری» (Duplication) و «بیربط» (Irrelevancy) وجود ندارد، آسانتر است.
- از آنجایی که همه دادهها در مکانی واحد هستند، میتوان تدابیر امنیتی قویتری را برای حافظت از آن اِعمال کرد. بنابراین، پایگاه داده متمرکز، امنیت نسبتاً بالایی دارد.
- مقیاس پذیری و محلیسازی: سیستمهای کامپیوتری جدید را میتوان به راحتی در سیستم مدیریت پایگاه داده متمرکز موجود، اضافه یا از آن حذف کرد.
- دادهها به راحتی «قابلِحمل» (Portable) هستند. یعنی میتوان آنها را به راحتی از کامپیوتری به کامپیوتر دیگر منتقل کرد، زیرا در سیستم مدیریت پایگاه داده متمرکز و در مکانی یکسان ذخیره شدهاند.
- سیستم پایگاه داده متمرکز، در نصب و نگهداری نسبت به سایر سیستمهای مدیریت پایگاه داده، هزینه کمتری را به دنبال دارد و نیازمند سیستم ذخیرهسازی واحدی است، بهطوریکه دادهها توسط تمام کامپیوترهای متصل، قابل دسترسی هستند.
- دسترسی به اطلاعات در سیستم پایگاه داده متمرکز ساده است و همه دادهها را میتوان از مکانی واحد، بهطور همزمان بازیابی کرد.

معایب معماری پایگاه داده متمرکز چیست ؟
برخی از معایب سیستم پایگاه داده متمرکز، از جمله «پردازش کُند»، «عملکرد پایینتر» و «احتمال از دست رفتن دادهها»، در ادامه، بیان شده است.
- پردازش کند: دادهها در یک مکان ذخیره میشوند و سرعت دسترسی و پردازش دادهها در سیستم مدیریت پایگاه داده متمرکز، کمتر از سایر سیستمها است. زیرا دسترسی به دادهها از یک مکان، نیازمند زمان بیشتری است. از آنجاییکه همه دادهها، در مکانی واحد هستند، جستجو و دسترسی به آن زمان بیشتری نیاز دارد. اگر شبکه کند باشد، این فرایند حتی بیشتر هم طول خواهد کشید.
- کارایی کمتر: اگر چندین کاربر بخواهند بهطور همزمان، پرسوجو را روی سرور، پردازش و به آن دسترسی پیدا کنند، مشکلاتی رخ میدهد و سرعت پردازش کامپیوتر مرکزی، کاهش مییابد که در نتیجه تأثیری منفی روی عملکرد سیستم دارد.
- از دست دادن دادهها: در سیستم مدیریت پایگاه داده متمرکز، اگر هر گونه خرابی در سیستم رخ دهد یا هر دادهای از بین برود، در صورتیکه اقدامات «بازیابی» (Recovery)، در پایگاه داده تعبیه نشده باشد.دادهها قابل بازیابی نیستند.
- بروز تنگنا: به دلیل اینکه ترافیک زیادی برای دسترسی به دادههای موجود در پایگاه داده متمرکز وجود دارد، ممکن است با یک موقعیت «تنگنا» (Bottleneck) روبهرو شویم.
معماری سیستم پایگاه داده توزیع شده چیست؟
پایگاه داده «توزیع شده» (Distributed Database)، سیستمی است که در آن، دادهها در مکانهای فیزیکی مختلفی ذخیره میشوند. به عنوان مثال، چندین کامپیوتر که در مکانی فیزیکی، مانند مرکز داده قرار دارند. همچنین ممکن است دادهها، روی شبکهای از کامپیوترهای متصل به هم، پراکنده شوند.
بر خلاف سیستمهای «موازی» که پردازندهها در آن، ارتباط تنگاتنگی با هم دارند یا اصطلاحاً «Tightly Coupled» هستند و سیستم پایگاه داده واحدی را تشکیل میدهند، سیستم پایگاه داده «توزیعشده» متشکل از سایتهایی (سیستمهایی حاوی پایگاه داده) است که ارتباط سُستی «Loosely Coupled» با هم دارند و هیچ مؤلفه فیزیکی را به اشتراک نمی گذارند.
پایگاه داده «توزیع شده» (Distributed)، اشاره به مجموعهای از دادههای به اشتراک گذاشته شده دارد که به لحاظ منطقی مرتبط به هم هستند و روی شبکهای کامپیوتری توزیع شدهاند. سیستم نرمافزاری که امکان مدیریت پایگاه داده توزیع شده را فراهم و استفاده از آن را برای کاربران شفاف و آسان میکند، «سیستم مدیریت پایگاه داده» (Database Management System | DBMS) نامیده میشود. به طور خلاصه، در سیستم Distributed Database، پایگاه داده، به چندین قسمت کوچکتر، تقسیم و هر کدام از این قسمتها روی یک یا چندین کامپیوتری ذخیره میشوند که تحت نظارت DBMS جداگانهای است.
این کامپیوترها نیز توسط شبکهای ارتباطی به یکدیگر متصل هستند. بنابراین، در این نوع پایگاه داده، «دادهها» روی انواع مختلفی از دیتابیسها توزیع و توسط نرمافزارهای گوناگون DBMS مدیریت میشوند که قابل اجرا روی سیستمعاملهای مختلف هستند. کامپیوترهای مذکور از نظر موقعیت جغرافیایی، پخش یا توزیع شدهاند و توسط شبکههای ارتباطی گوناگون به هم متصل هستند. گفتیم که در این نوع پایگاه داده، دادهها روی چندین دستگاه توزیع میشوند که «Site» یا «Node» نام دارند. شبکههای موجود در این نوع از سیستمهای پایگاه داده، معمولاً «شبکههای محلی» (LAN) یا «شبکههای گسترده» (WAN) است که البته تأخیر بالاتری دارد.
تکرار و تکثیر در پایگاههای داده توزیعشده چیست ؟
۲ فرایند «تکرار» (Replication) و «تکثیر» (Duplication)، تضمین میکنند که پایگاههای دادههای توزیعشده، بهروز میمانند. «Replication»، شامل به کارگیری نرمافزارهای تخصصی است که منجر به تغییراتی در پایگاه داده توزیعی میشود. هنگامی که تغییرات شناسایی شدند، فرایند تکرار، باعث میشود همه پایگاههای داده، یکسان (دارای اطلاعاتی مشابه) بهنظر برسند. فرایند «Replication»، بسته به اندازه و تعداد پایگاههای دادهای توزیع شده، میتواند پیچیده و زمانبر باشد. این فرایند همچنین میتواند به زمان و منابع کامپیوتری زیادی نیاز داشته باشد.
از سوی دیگر «Duplication»، پیچیدگی کمتری دارد. پایگاه دادهای را به عنوان «Master» شناسایی و سپس آن را کپی میکند. فرایند «Duplication»، معمولاً در زمان مشخصی (پس از ساعاتی مشخص) صورت میگیرد. برای اطمینان از اینکه مکانهای مختلف دارای دادههای یکسانی هستند، در فرایند «Duplication»، کاربران ممکن است فقط پایگاه داده اصلی «Master» را تغییر دهند. این مورد تضمین میکند که دادههای محلی (Local)، بازنویسی نخواهند شد. هر ۲ فرایند «Replication» و «Duplication»، میتوانند دادهها را در سراسر مکانهای توزیعی، «جاری» (Current) یا بهروز نگه دارند.
علاوه بر اینها، فناوریهای دیگری هم برای طراحی پایگاه داده «توزیع شده»، به عنوان مثال، فناوریهای پایگاه داده توزیع شده «مستقل محلی»، «همزمان» (Synchronous)، «ناهمزمان» (Asynchronous) و غیره وجود دارد. پیادهسازی این فناوریها، میتواند به نیازهای کسبوکار، حساسیت (از نظر محرمانگی دادههای ذخیرهشده در پایگاه داده) و هزینه مالی بستگی دارد که کسبوکار مایل است برای اطمینان از وجودِ «امنیت» (Security)، «ثُبات» (Consistency) و «یکپارچگی» (Integrity) دادهها بپردازد.
انواع پایگاه داده توزیع شده در معماری پایگاه داده چیست ؟
سیستم پایگاه داده توزیع شده را با توجه به دادهها و ذخیرهسازی آن، میتوان به ۲ دسته «همگن» و «ناهمگن»، تقسیم کرد که در ادامه، به شرح هر کدام پرداخته شده است.

پایگاه داده توزیع شده همگن چیست ؟
در سیستم پایگاه داده توزیع شده «همگن» (Homogeneous)، همه سایتها از DBMS و سیستم عاملهای یکسان استفاده میکنند. ویژگیهای این نوع سیستم در ادامه بیان شده است.
- سایتها از نرم افزارهای بسیار مشابه استفاده میکنند.
- سایتها از DBMS یکسان، یا DBMS یک عرضهکننده را به کار میگیرند.
- هر سایتی از تمام سایتهای دیگر آگاه است و برای پردازش درخواستهای کاربران با سایتهای دیگر همکاری میکند.
- سیستم پایگاه داده از طریق رابطی واحد قابل دسترسی است، گویی یپایگاه داده واحدی است.
انواع پایگاه داده توزیع شده همگن چیست ؟
پایگاه داده توزیع شده همگن، به ۲ نوع «مستقل» و «غیر مستقل»، تقسیم میشود که در ادامه توضیح داده شده است.
- مستقل: هر پایگاه دادهای که به تنهایی کار میکند، مستقل است. این پایگاهها توسط برنامهای کنترلی با هم کار میکنند و از ارسال پیام برای به اشتراکگذاریِ بهروزرسانی دادهها استفاده میکنند.
- غیر مستقل: دادهها در سراسر گرههای همگن توزیع میشوند و یک DBMS مرکزی یا «اصلی» (Master) بهروزرسانی دادهها را در سراسر سایتها هماهنگ میکند.
یکی دیگر از اهدافِ پایگاه داده توزیع شده همگن، ارائه نمایی از پایگاه دادهای واحد و پنهانسازی جزئیات توزیع است. همچنین، نرمافزار یا طرحواره یکسانی در همه سایتها وجود دارد و دادهها ممکن است بین سایتها تقسیم شوند.

پایگاه داده توزیع شده ناهمگن چیست ؟
در یک پایگاه داده توزیع شده «ناهمگن» (Heterogeneous)، سایتهای مختلف، سیستم عامل، محصولات DBMS و مدلهای دادهای متفاوتی دارند. برخی از ویژگیهای این نوع دیتابیس توزیع شده در ادامه فهرست شدهاند.
- سایتهای مختلف، از طرحوارهها (Schemas) و نرمافزارهای متفاوتی استفاده میکنند.
- این نوع سیستم، ممکن است از انواع DBMSها مانند رابطهای، شبکهای، سلسلهمراتبی یا شی گرا تشکیل شده باشد.
- به دلیل متفاوت بودن طرحوارهها، پردازش پرسوجو پیچیده است.
- ممکن است سایتها، از وضعیت یکدیگر مطلع یا آگاه نباشند، بنابراین همکاری محدودی در پردازش درخواستهای کاربران وجود دارد.
از دیگر ویژگیهای پایگاه داده توزیع شده ناهمگن، این است که سایتها دارای نرمافزار یا طرحوارههای مختلفی هستند. همچنین، پایگاههای دادهای موجود، برای ارائه عملکردی مفید، تجمیع شدهاند.
انواع پایگاه داده توزیع شده ناهمگن چیست ؟
پایگاه داده توزیع شده ناهمگن، شامل ۲ نوع «متحد» و «غیر متحد»، تقسیم میشود که در ادامه توضیح داده شده است.
- متحد: سیستمهای پایگاه داده توزیع شده ناهمگن ماهیت مستقلی دارند و با هم یکپارچه شدهاند بهطوری که به عنوان سیستم پایگاه دادهای واحد عمل میکنند.
- غیر متحد: سیستمهای پایگاه داده، از ماژول هماهنگکننده مرکزی، برای دسترسی استفاده میکنند.
مزایای سیستم پایگاه داده توزیع شده چیست ؟
سیستم پایگاه داده توزیع شده، دارای مزیتهایی هستند که در ادامه، بیان شده است.
- «قابلیت اطمینان» (Reliable): در سیستم مدیریت پایگاه داده توزیع شده، اگر هر یک از سیستمهای متصل، در انجام کار با مشکلی مواجه شود، تاثیری منفی بر عملکرد سیستم نخواهد داشت و سیستم به کار خود ادامه میدهد. در نتیجه، از سایر سیستمهای مدیریت پایگاه داده ساده، قابل اعتمادتر است.
- «ارتباطات کم هزینه» (Low Communication Cost): دادهها و اطلاعات، به صورت محلی در سیستم مدیریت پایگاه داده توزیع شده، ذخیره میشوند. هزینه ارتباطات کمتر و دستکاری (تغییر) دادهها آسانتر است.
- «توسعه ماژولار» (Modular Development): مِدولاسیون یا «تغییر و تعدیل» در سیستم مدیریت پایگاه داده توزیع شده، بسیار آسان است. در نتیجه، سیستمهای بیشتری را میتوان تنها با اتصال به سیستم پایگاه داده توزیع شده، بدون ایجاد وقفه و خرابی، نصب کرد یا تغییر داد.
- «پاسخ سریعتر» (Better Response): تمامی سیستمهای کامپیوتری که به صورت مرکزی نصب میشوند، میتوانند هر درخواستی را در کمترین زمان ممکن پردازش کنند. به دلیل پردازش متمرکز در سیستمهای مدیریت پایگاه داده، پاسخ سریعتری ارائه میشود.
- «بازیابی اطلاعات» (Data recovery): عمل بازیابی دادههاپس از ازبین رفتن آن، در سیستمهای مدیریت پایگاه داده توزیع شده، بهراحتی انجام میشود.
- پایگاه داده (روی سرور) را میتوان در چندین سیستم کلاینت (برنامه) به اشتراک گذاشت.
- با افزایش حجم دادهها و نرخ تراکنش، کاربران میتوانند سیستم را به صورت تدریجی رشد دهند.
- افزودن موقعیتهای (مکانهای) جدید، تأثیر کمتری بر عملیات در حال انجام دارد.
- سیستم پایگاه داده «توزیع شده»، استقلال محلی را فراهم میکند.
معایب سیستم پایگاه داده توزیع شده چیست ؟
سیستم پایگاه داده توزیع شده، در کنار مزیتهایی که در اختیار ما قرار میدهد، معایبی هم دارد که در ادامه، بیان شده است.
- «یکپارچگی داده» (Data Integrity): بهروزرسانی دادهها در سایتهای متعدد، میتواند مشکلاتی را بهوجود آورد. یکپارچگی دادهها در این نوع سیستم، پیچیدهتر و مدیریت آن بسیار سخت است.
- «تکراری شدن دادهها» (Duplication of Data): سیستمهای مختلف، دادههای مشابهی را ذخیره میکنند و این باعث تکراری شدن دادهها میشود. در نتیجه، برای ذخیره دادههای مشابه در سیستمهای کامپیوتری مختلف در سیستمهای مدیریت پایگاه داده توزیع شده، فضای بیشتری را نیاز داریم.
- «توزیع نادرست دادهها» (Improper Data Distribution): توزیع نادرست دادهها میتواند، کندی پاسخ در پردازش پرسوجو را بهدنبال داشته باشد. دادههای یکسانی که در کامپیوترهای متعدد ذخیره میشود.
- «سرعت پردازش کمتر» (Less Processing Speed): برای انجام یک پرسوجوی ساده، نیاز به ارتباطات (Communication) زیادی است. به همین دلیل، حل یک مسئله خاص، مدت زمان زیادی را نیاز دارد.
حل مشکل پیش آمده در سیستمهای پایگاه داده «توزیع شده»، نسبت به سیستمهای «متمرکز»، فرایند پیچیدهتری دارد.
اهداف پایگاه داده توزیع شده چیست ؟
سیستم مدیریت پایگاه داده «توزیع شده»، بیانگر ذخیره دادهها، در مکانهای متعدد است. در این راستا، تعدادی هدف برای توزیع دادهها وجود دارد که در ادامه، با هم مرور میکنیم.
- «قابلیت اطمینان» (Reliability): سیستم مدیریت پایگاه داده توزیع شده، قابل اطمینان بیشتری نسبت به دیگر سیستمهای پایگاه داده دارد. بهطوریکه اگر هر یک از سیستمهای کامپیوتری متصل به شبکه، نتواند کاری را انجام دهد (به علت خرابی)، کامپیوترهای دیگر میتوانند کار مربوطه را بدون معطلی (به موقع) انجام دهند.
- «دسترسیپذیری» (Availability): اگر سرور کامپیوتری در هر زمانی متوقف شود و از کار بیوفتد، سرورهای کامپیوتر دیگر میتوانند کار را مطابق درخواست انجام دهند.
- «کارایی» (Performance): در سیستمهای مدیریت پایگاه داده «توزیع شده»، میتوان به دادهها و اطلاعات از مکانهای مختلفی دسترسی داشت. همچنین، اقدامات مربوط به مدیریت و «نگهداری» (Maintain) آن، بسیار آسان است.
یکپارچهسازی دادهها در سیستم پایگاه داده توزیع شده چیست؟
در این قسمت، برخی از ویژگیهای یکپارچهسازی دادهها در سیستم پایگاه داده توزیع شده، بیان شده است.
- استقلال: فایده یکپارچهسازی دادهها بین چندین پایگاه داده، در سیستم «توزیع شده»، این است که هر سایت میتواند تا حدودی کنترل خود را روی دادههای ذخیره شده به صورت محلی، حفظ کند.
- اشتراکگذاری دادهها: کاربرانِ موجود در یک سایت، میتوانند به دادههایی که در برخی سایتهای دیگر وجود دارد، دسترسی داشته باشند.
سیستم پایگاه داده موازی چیست؟
معماری «سیستم پایگاه داده موازی» (Parallel Database System)، متشکل از چندین «واحد پردازش مرکزی» (CPU) و دیسکهایی متعدد به منظور ذخیرهسازی دادهها، به صورت موازی است. از این رو، سرعت «پردازش» و «ورودی/خروجی» (I/O)، مناسبی دارد. سیستمهای پایگاه داده موازی، معمولاً در برنامههایی مورد استفاده قرار میگیرند که، اندازه پایگاه دادههای مورد پرسوجو در آنها بسیار بزرگ است و همچنین قرار است تا تعداد بسیار زیادی تراکنش (در واحد ثانیه) را پردازش کنند.
این نوع از سیستمها، محاسبات را به صورت موازی و بر روی چندین «واحد پردازشی» (Processing Unit) مختلف (که بهطور همزمان مورد استفاده قرار میگیرند) انجام میدهند. واحدهای پردازشی میتوانند، هستههای روی یک پردازنده یا پردازندههای متعددی باشند. یا اینکه پردازندهای «تکهستهای» با اجرای «همزمانِ شبیهسازی شده»، مانند «اشتراک زمانی» (Time-Sharing)، چندوظیفهای مشارکتی یا غیر-مشارکتی (رقابتی) را شامل شوند.
این معماری، در تلاش است تا فرایند اجرا را بهبود بخشد و این هدف را از طریق موازیسازیِ وظیفههای مختلف، همچون بارگذاری دادهها، ساخت رکودردها و نمایهها، ارزیابی پرسوجوها و غیره انجام میدهد. به بیان سادهتر، با همکاری چندین واحد پردازشی برای کار بر روی پایگاه داده، خدمات مناسبی را ارائه میدهد.
ویژگی های سیستم موازی در معماری پایگاه داده چیست ؟
در این قسمت، برخی از ویژگیهای سیستم پایگاه داده موازی، بیان شده است.
- سیستم پایگاه داده موازی، شامل چندین پردازنده و هارد دیسک (به منظور ذخیرهسازی) است که توسط شبکهای با اتصال سریع، به هم متصل شدهاند.
- مدیریت «حجم کاری» (Workloads)، بسیار فراتر از آنچه است که سیستمی کامپیوتری، به تنهایی میتواند انجام دهد.
- تراکنشها را با کارایی بالا پردازش میکند. (به عنوان مثال، رسیدگی به درخواستهای کاربر در مقیاس اینترنت)
- از تصمیمگیری در مورد مقادیر بسیار زیاد «داده» پشتیبانی میکند. (به عنوان مثال، دادههای جمعآوری شده توسط وب سایتها یا برنامههای بزرگ)
- دستگاهِ پردازش موازیِ «Coarse-Grain»، از تعداد کمی پردازنده قدرتمند تشکیل شده است. در مقابل، دستگاه «به شدت موازی» (Massively Parallel) یا (Fine Grain Parallel)، هزاران پردازنده کوچکتر را به کار میگیرند.
- معمولاً در «مرکز داده» (Data Center) میزبانی میشود.
۲ معیار کارایی اصلی در سیستم پایگاه داده موازی چیست ؟
سیستم پایگاه داده موازی، دارای ۲ معیار اصلی «توان عملیاتی» و «زمان پاسخ» است که در ادامه آن را توضیح دادهایم.
- توان عملیاتی (Throughput)، که بیانگر تعداد تَسکهایی است که میتوان در بازه زمانی مشخصی تکمیل کرد.
- زمان پاسخ (Response Time)، که مدت زمان لازم برای تکمیل یک تسک، از زمانی که ارسال شده است را نشان میدهد.
انواع سیستم پایگاه داده موازی چیست؟
این نوع از سیستمهای پایگاه داده، شامل انواعی است که در ادامه فهرست شدهاند و سپس هر کدام را نیز در زیربخشهایی بیشتر شرح دادهایم.
- «حافظه مشترک» (Shared Memory)
- «دیسک ذخیرهسازی مشترک» (Shared Disk)
- «غیر اشتراکی» (Shared Nothing)
- «سلسلهمراتبی» (Hierarchical)
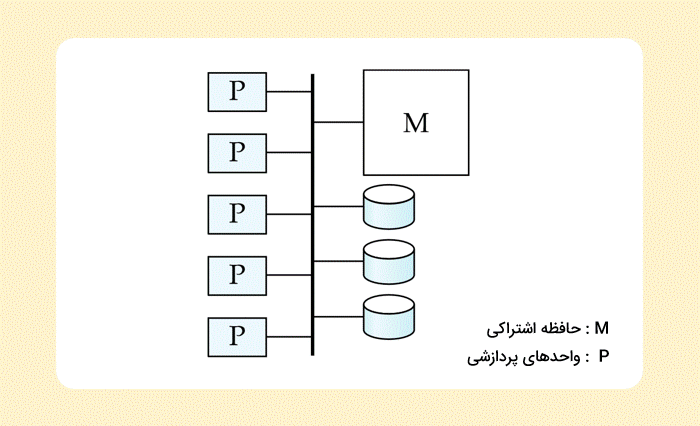
پایگاه داده موازی با حافظه اشتراکی چیست ؟
در این نوع سیستم، پردازندهها (یا هستههای پردازنده) و دیسکها، به حافظهای مشترک، دسترسی دارند. در گذشته این ارتباط از طریق «Bus» و امروزه به واسطه شبکههای ارتباطی انجام میشود. ارتباط پردازندهها در این سیستم بسیار کارآمد است. ایرادی که میتوان از این نوع سیستمها گرفت، این است که، معماری حافظه اشتراکی، بیش از ۶۴ تا ۱۲۸ هسته پردازنده، مقیاسپذیر نیست و این امکان وجود دارد که شبکه ارتباطی حافظه، به «گلوگاه» (Bottleneck) تبدیل شود.
پایگاه داده موازی با دیسک اشتراکی چیست؟
در این نوع سیستمِ پایگاه داده، تمامی پردازندهها میتوانند بهطور مستقیم، به همه دیسکهای ذخیرهسازی، دسترسی داشته باشند و این دسترسی، از طریق شبکه ارتباطی انجام میشود. لازم به ذکر است که در این معماری، پردازندهها دارای حافظههای مخصوص به خود (غیر اشتراکی) هستند.
این معماری، قابلیت «تحملپذیری در برابر خطا» (Fault-Tolerance) را تا حدودی فراهم میکند. یعنی اگر پردازندهای با مشکل روبهرو شود، پردازندههای دیگر، وظیفه تکمیل وظیفه آن را بر عهده میگیرند. دادههای پردازندهای که با مشکل روبهرو شده، روی دیسکهایی قرار دارند که توسط همه پرداززندهها قابل دسترسی هستند. مشکلی که این معماری دارد، این است که، احتمال ایجاد گلوگاه در ارتباطات موجود (در زیر سیستمهای دیسک)، زیاد است.
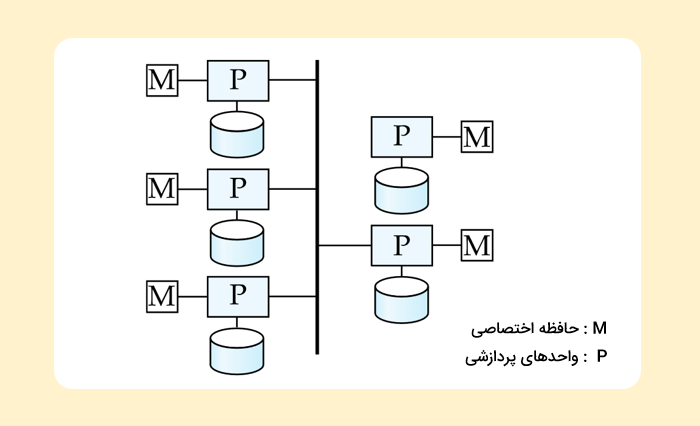
پایگاه داده موازی غیر اشتراکی چیست؟
در این نوع سیستم پایگاه داده موازی، یعنی «غیر اشتراکی» «Shared Nothing»، هر گره، از پردازنده، حافظه و یک یا چند دیسک به منظور ذخیرهسازی، تشکیل شده است و تمامی ارتباطات، از طریق اتصالات شبکه صورت میگیرند. این نوع شبکهها بدون اینکه دچار تداخلی شوند، قابلیت بزرگتر شدن تا هزاران پردازنده را دارند. ایرادی که میتوان از سیستم غیر اشتراکی گرفت، این است که هزینه ناشی از ارتباطات و دسترسی به دیسکهای غیر محلی را به دنبال دارد (ارسال داده شامل تعاملات نرمافزاری از هر دو سَمت است).
پایگاه داده سلسه مراتبی موازی چیست؟
معماری «سلسله مراتبی» (Hierarchical)، ترکیبی از معماریهای «حافظه اشتراکی»، «دیسک اشتراکی» و «Shared Nothing» است. بهطوریکه لایه بالایی آن، از سیستم «Shared Nothing» تشکیل شده و هر «گره» (Node) در اینجا، از نوع سیستم «حافظه اشتراکی» است. لایه بالایی، همچنین میتواند متشکل از سیستم «دیسک اشتراکی» نیز باشد.
تفاوت حافظه اشتراکی با Shared-Nothing چیست؟
ماهیت سیستم «حافظه اشتراکی»، مشابه «Shared Nothing» است. بهطوریکه هر پردازنده، دسترسی مستقیم به حافظه خود و دسترسی غیرمستقیم (در سطح سخت افزار) به سایر حافظهها دارد. این سیستم، با نام «معماری حافظه غیریکنواخت» (Non-Uniform Memory Architecture | NUMA)، نیز شناخته میشود.
سیستم «غیراشتراکی»، میتواند شبیه سیستم «حافظه اشتراکی » به نظر برسد. کاهش پیچیدگی برنامهنویسی در چنین سیستمهایی، با انتزاع «حافظه مجازی توزیع شده»، انجام میگیرد. همچنین «دسترسی مستقیم به حافظه از راه دور» (Remote Direct Memory Access | RDMA)، انتزاع حافظه مشترک با تأخیر بسیار پایین را در سیستمهای اشتراکی فراهم میکند. اما با سهلانگاری در برنامهنویسی، میتواند مشکلات عملکردی را به دنبال داشته باشد.
سرعت و مقیاس در پایگاه داده موازی چگونه است؟
هر چه منابع بیشتری را برای انجام کار مربوطه مورد استفاده قرار دهیم، سریعتر میتوان آن را به پایان رساند. لازم به ذکر است که این توانایی، با حفظ همان سطح عملکرد (زمان پاسخگویی) انجام میشود. حتی زمانی که حجم کار و میزان منابع، با هم افزایش پیدا میکنند.
مزایای سیستم پایگاه داده موازی چیست؟
در این قسمت، برخی از مزیتهای سیستم پایگاه داده موازی، بیان شده است.
- سیستمهای پایگاه داده موازی، برای برنامههایی که باید پایگاه دادههای بسیار بزرگی (در مقیاس ترابایت) را پرسوجو کنند، یا اینکه تعداد بسیار زیادی تراکنش را در ثانیه (مثلا هزاران تراکنش در ثانیه) را پردازش کنند بسیار، مفید هستند.
- در سیستمهای پایگاه داده موازی، «توان عملیاتی» (تعداد کارهایی که در یک بازه زمانی معین میتوانند بهطور کامل انجام شوند)، بسیار زیاد و در مقابل، «زمان پاسخ» (مقدار زمانی که برای انجام یک کار واحد، از زمان ارسال آن طول میکشد) اندک است.
معایب سیستم پایگاه داده موازی چیست؟
در این قسمت، برخی از معایب سیستم پایگاه داده موازی، بیان شده است.
- در سیستم پایگاه داده موازی، هزینهای برای راهاندازی وجود دارد که با شروع فرایند همراه است. این زمان راهاندازی، ممکن است زمان پردازش واقعی را تحت تأثیر قرار دهد و تأثیری منفی روی سرعت داشته باشد.
- از آنجاییکه اجرای فرایند در سیستم پایگاه داده موازی، با دسترسی به منابع مشترک انجام میشود، ممکن است مقداری کاهش سرعت، به دلیل تداخل هر فرایند جدید با فرایندهایی که از قبل وجود دارند و در حال تکمیل هستند را شاهد باشیم. زیرا فرایندها، در دسترسی به منابع گوناگون، از جمله دیسکهای ذخیرهسازی اشتراکی، Busهای سیستم و غیره با یکدیگر رقابت میکنند.

تفاوت سیستم های متمرکز و توزیعشده در معماری کامپیوتر چیست ؟
ایده اصلی موجود در «پایگاه داده متمرکز»، این است که آنها باید بتوانند تمام درخواستهای ارائه شده توسط سیستم اصلی را به تنهایی مدیریت کنند (منظور دریافت، نگهداری و تکمیل آنها است). نکته دیگر این است که تنها یک فایل پایگاه داده وجود دارد که در مکانی واحد و در شبکهای مشخص نگهداری میشود. در حالی که، پایگاه داده توزیع شده، پایگاهی است که در آن تمامی اطلاعات، در مکانهای فیزیکی متعدد ذخیره میشوند.

پایگاه داده توزیع شده به دو گروه «همگن» و «ناهمگن» تقسیم میشود و برای بهروز نگه داشتن سوابق خود، بر ۲ ویژگی «تکرار» و «تکثیر» در زیر پایگاههای متعدد خود متکی است. در صورتی که سیستم توزیعشده از چندین فایلِ پایگاه داده تشکیل شده است که همگی توسط یک «DBMS» مرکزی کنترل میشوند.
تفاوتهای اصلی بین پایگاه داده «متمرکز» و «توزیع شده»، به ویژگیهای اساسی این سیستمها مربوط میشود. برخی از این تفاوتها، در ادامه بیان شدهاند (اما تنها به همینها، محدود نیستند).
- پایگاه داده متمرکز، دادهها را روی یک CPU، که به مکانِ فیزیکی (یا جغرافیایی) خاصی، محدود شده است ذخیره میکند. با این حال، پایگاههای داده توزیعشده، به DBMS مرکزی متکی هستند که تمام دستگاههای ذخیرهسازی مختلف خود را از راه دور مدیریت میکند، زیرا لزومی ندارد آنها را در مکان فیزیکی خاصی نگهداری کرد.
- همانطور که پیشتر بیان شد، بهروزرسانی پایگاه داده «متمرکز»، آسانتر از پایگاه داده «توزیع شده» است. به این دلیل که پایگاه داده «توزیعشده» به اقداماتی اضافی (و معمولاً دستی) برای مرتبط نگه داشتن دادههای ذخیرهشده و جلوگیری از افزونگی دادهها و همچنین بهبود عملکرد کلی نیاز دارند.
- اگر دادههای موجود در سیستم مرکزی از بین بروند، بازیابی آنها مشکل خواهد بود. با این حال، اگر برای دادههای موجود در سیستم «توزیع شده»، مشکلی پیش بیاید، بازیابی آن بسیار آسان خواهد بود. زیرا همیشه کپی دادهها، در مکان دیگری از پایگاه داده وجود دارد.
- طراحی پایگاه داده «متمرکز»، به طور کلی، پیچیدگی کمتری نسبت به سیستمهای «توزیع شده» دارد، زیرا سیستمهای پایگاه داده «توزیع شده» ساختاری سلسلهمراتبی دارند.
سیستم پایگاه داده سرور چیست؟
بهطور کلی، معماری «سیستمهای سرور» را میتوان به ۲ دسته، «سرورهای تراکنش» (Transaction Servers) و «سرورهای داده» (Data Server) طبقهبندی کرد. که در ادامه، هریک از این موارد را مورد بررسی قرار میدهیم.
سرور تراکنش چیست؟
«سرورهای تراکنش»، نوع خاصی از معماری «سرورِ پایگاه داده» هستند که با تَسکهای مربوط به تراکنشهای نرمافزاری یا پردازش تراکنشها، سر و کار دارند. این نوع معماری، به طور گسترده در سیستمهای «پایگاه داده رابطهای» (Relational Databases) مورد استفاده قرار میگیرد. در ادامه برخی از ویژگیهای این نوع معماری را مرور خواهیم کرد.
- این معماری با نامهای «سرور پرسوجو» (Query Server) یا «سیستمهای سرور SQL»، نیز شناخته میشود. روند کار آن اینگونه است که کلاینتها، درخواستهای خود را به سرور ارسال میکنند، تراکنشها در سرور پردازش میشوند و در نهایت، نتایج به سمت کلاینت بر میگردند.
- درخواستها، در زبان SQL، تعیین و از طریق ساز و کار «فراخوانی رویه از راه دور» (Remote Procedure Call | RPC)، به سرور منتقل میشوند.
- RPC تراکنشی، فراخوانیهای RPC متعددی را برای ایجاد یک تراکنش ارائه میدهد.
سرور داده چیست؟
«سرور داده» (Data Server) یا سیستمهای ذخیرهسازی داده، تَسکهایی مانند تجزیه و تحلیل، ذخیرهسازی، دستکاری، بایگانی و سایر وظایف مربوط به دادهها را با استفاده از معماری «کلاینت/سرور» انجام میدهند. «سرورهای داده موازی»، برای اجرای سیستمهای پردازش تراکنش (با کارایی بالا) استفاده میشوند.
سیستم کلاینت سرور در معماری پایگاه داده چیست ؟
سیستم «کلاینت/سرور» برای کار در محیطهایی محاسباتی متنوع توسعه یافته است که تعداد زیادی کامپیوتر و «سِرور» از طریق شبکه به یکدیگر متصل شدهاند. در این معماری، «Client» به نمای کاربر اشاره دارد که رابط کاربری و همچنین قابلیتهای پردازش «محلی» (Local) را فراهم میکند.
هنگامی که هر کلاینت به عملکردهای اضافی، مانند دسترسی به پایگاه داده نیاز پیدا کند، میتواند به سروری متصل شود که قادر به ارائه این عملکرد است. سرور، اساساً سیستمی است که سرویسهایی (یا خدماتی) را به کلاینت، یعنی دستگاهِ کاربر ارائه میدهد.
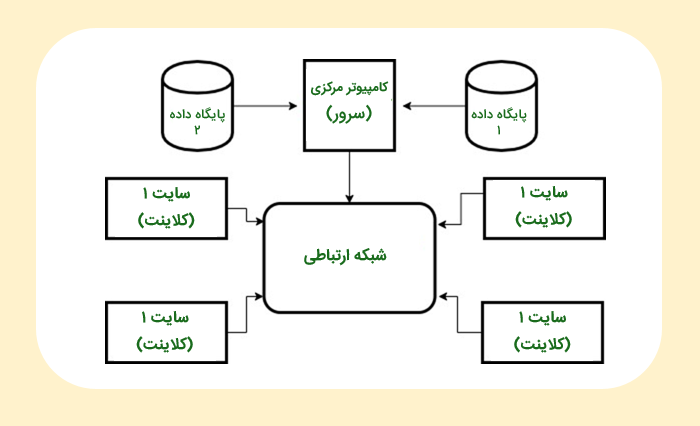
بهبیان دیگر، معماری «کلاینت/سرور»، مدلی محاسباتی است که در آن، «سِرور» بخش زیادی از منابع و خدمات مورد استفاده توسط کلاینتها را منتقل میکند و بر آن نظارت دارد.
مزایای سیستم پایگاه داده سرور کلاینت چیست؟
در ادامه، برخی از مزایای سیستمهای «سرور/کلاینت»، بیان شده است.
- سیستم «کلاینت/سرور»، پلتفرمهای ارزانتری را برای پشتیبانی از برنامههایی ارائه میدهد که پیش از این، فقط بر روی کامپیوترهای بزرگ و گرانقیمت یا «مِینفِریم» (Mainframe) اجرا میشدند.
- در این نوع سیستم، «کلاینت»، رابطی کاربرپسند بر مبنای منوها و آیکنها ارائه میدهد که برتری زیادی نسبت به خطِ فرمانهای سنتی و رابطِ ترمینالی گُنگِ سیستمهای کامپیوتری مِینفِریم دارد.
- محیط «کلاینت/سرور»، به کاربران کمک میکند تا بهتر کار کنند و دادههای موجود را بهطور موثرتری به کار گیرند.
- این نوع سیستم پایگاه داده، در مقایسه با سیستم «متمرکز»، انعطافپذیری بیشتری دارد.
- سیستم سرور/کلاینت، «توانِ عملیاتی» (Throughput) بالایی دارد و زمان پاسخگویی آن کم است.
- کامپیوتر سرور (پایگاه داده)، را میتوان با این هدف که سیستم مدیریت پایگاه داده، عملکرد بهتری داشته باشد، سفارشیسازی کرد.
- کلاینت (پایگاه داده برنامه)، ممکن است «ایستگاه کاری» (Workstation) پرسنلی باشد که متناسب با نیاز کاربران نهایی است و در نتیجه رابطهای بهتر، دسترسپذیری بالا، پاسخدهی سریعتر و بهبود کلی سهولت استفاده برای کاربر را، ارائه دهد.
- پایگاه داده (روی سرور) میتواند در چندین سیستم کلاینتِ مجزا (برنامه) به اشتراک گذاشته شود.
معایب سیستم پایگاه داده کلاینت سرور چیست؟
در این قسمت، برخی از معایب سیستم پایگاه داده «کلاینت/سرور»، بیان شده است.
- هزینه برنامهنویسی در محیطهای «کلاینت/سرور»، بهویژه در مراحل ابتدایی، نسبتاٌ زیاد است.
- مشکل فقدان ابزارهای مدیریتی برای «عیبیابی» (Diagnosis)، «نظارت بر عملکرد» و امنیت برای DBMS، کلاینت، سیستم عامل و محیطهای شبکه، وجود دارد.
سوالات پر تکرار
در این قسمت از مطلبِ «معماری پایگاه داده چیست»، تعدادی از سوالات رایج در این حوزه را، با هم بررسی میکنیم.
مزایای ANSI SPARC در معماری پایگاه داده چیست ؟
هدف اصلی این معماری، جداسازی یا ایزوله کردن هر یک از نماهای کاربری، از نحوه ذخیرهسازی دادهها، در پایگاه داده است. کاربر نگران جزئیات ذخیرهسازی فیزیکی دادهها نیست. همچنین، میتواند به دادههای یکسان، اما با نمای سفارشی متفاوتی دسترسی داشته باشد. مدیر پایگاه داده در این نوع معماری، میتواند ساختارهای مربوط به ذخیرهسازی را بدون تاثیر روی سایر نماهای کاربر تغییر دهد.
مزایای سیستم متمرکز در معماری پایگاه داده چیست ؟
پایگاه داده متمرکز، مزایای قابل توجهی را در مقایسه با سیستمهای دیگر، ارائه میدهد، که میتوان به مواردی همچون، یکپارچگی بیشینه و افزونگی کمینه دادهها، امنیت، مقیاسپذیری و بومیسازی، قابلیتحمل و نیازِ کمتر به نگهداری، اشاره کرد.
ویژگی های سیستم پایگاه داده توزیع شده چیست؟
سیستم پایگاه داده توزیع شده، دارای ویژگیهایی از قبیل، قابلیت اطمینان، ارتباطات کم هزینه، توسعه ماژولار، پاسخدهی سریعتر و بازیابی اطلاعات است.
انواع سیستم موازی در معماری پایگاه داده چیست ؟
سیستمهای پایگاه داده موازی، انواع مختلفی، مانند حافظه اشتراکی، دیسک اشتراکی، غیر اشتراکی و سلسله مراتبی را شامل میشود.
هدف از معماری پایگاه داده چیست ؟
توجه به معماری پایگاه داده، دارای اهمیت زیادی است. به عنوان مثال، به ما کمک میکند تا درک بهتری از دادهها داشته باشیم. رهنمودهایی را برای مدیریت دادهها، از زمان جمعآوری در سیستمهای منبع، تا زمانیکه توسط کسب و کارها مورد استفاده قرار میگیرد، به ما ارائه میدهد. همچنین، چارچوبی را به منظور توسعه و پیادهسازی «حاکمیت داده» فراهم میکند.
الزامات کسب مهارت در معماری پایگاه داده چیست ؟
برای اینکه به معمار پایگاه داده ماهری تبدیل شویم، نیاز است تا در یکی از رشتههای علوم یا مهندسی کامپیوتر یا رشتهای مرتبط با آن، تحصیل کرده باشیم. به نحوی که این دوره، مباحثی همچون مدیریت داده، برنامهنویسی، طراحی اپلیکیشن، توسعه کلاندادهها، تجزیه و تحلیل سیستمها و معماری فناوری را پوشش داده باشد.
مولفه های معماری پایگاه داده چیست ؟
معماری سیستم پایگاه داده شامل مجموعهای از خدمات است که بر روی سرویسهای اساسی سیستم عامل، سرویسهای ذخیرهسازی فایلهای سیستم و خدمات مربوط به مدیریت بافر در حافظه اصلی، ساخته شدهاند.

سیستم ۳ لایه در معماری پایگاه داده چیست ؟
اکثر پایگاه دادههای کنونی از معماری ANSI SPARC، الهام گرفتهاند. این معماری متشکل از ۳ سطح داخلی، مفهومی و خارجی است. سطح داخلی، در مورد نحوه ذخیرهسازی دادهها به صورت فیزیکی میشود. سطح مفهومی، نحوه مشاهده دادهها توسط کاربران را بیان میکند و سطح خارجی به عنوان رابطی بین این ۲ سطح، عمل میکند.
انواع سیستم های پایگاه داده چیست ؟
از انواع سیستمهای پایگاه داده، میتوان به سیستم پایگاه داده موازی، سیستمهای توزیعشده و همچنین سیستم پایگاه داده متمرکز، اشاره کرد.
جمعبندی
در این مطلب از مجله فرادرس، در پاسخ به این پرسش که «معماری پایگاه داده چیست»، معماری و سیستمهای متداول در حوزه پایگاه داده را مورد بررسی قرار دادیم. علاوه بر این، به بیان ساختار و همچنین مزایا و معایب هر کدام از این نوع سیستمها نیز، پرداخته شده است.
دورههای آموزشی متعددی در این مطلب معرفی شد که امیدواریم استفاده از آنها، در روند مسیر یادگیری معماری پایگاه داده و جزئیات آن، مفید واقع شود.










