

Index در پایگاه داده چیست؟ – اندیس گذاری و انواع آن به زبان ساده
در جوامع امروزی، کسب و کارهای مرتبط با دادهها به شکل سرسامآوری در حال پیشرفت هستند. در حقیقت، برخی از غولهای فناوری صدها پتابایت (یعنی هزار به توان ۵ بایت) داده را به طور روزانه پردازش میکنند. ذخیرهسازی تمام این دادهها در یک پایگاه داده خیلی هم خوب است، اما برای شرکتی دادهمحور، قابلیت دسترسی سریع به دادههای مورد نیاز به منظور کسب موفقیت در این حوزه بسیار ضروری به نظر میرسد. با استفاده از Index در پایگاه داده این امر محقق میشود. در این مقاله به این موضوع پرداخته شده است که Index در پایگاه داده چیست و چگونه میتوان با استفاده از اندیس یا ایندکس در پایگاه داده و اندیس گذاری یا ایندکس گذاری در پایگاه داده ، دادهها را سریع و به طور بهینه مدیریت کرد.





Index در پایگاه داده چیست ؟
Index در پایگاه داده ابزاری قدرتمند در پسزمینه بانک اطلاعاتی است که برای سرعت بخشیدن به کوئری زدن (عملیات پرس و جو) و بازیابی اطلاعات از دیتابیس از آن استفاده میشود. ایندکسها به وسیله فراهمسازی روشی برای پیدا کردن سریع دادههای درخواستی به کوئریهای پایگاه داده قدرت میبخشند. به بیان ساده، Index در پایگاه داده اشارهگری به دادهها در یک جدول به حساب میآید. ایندکس در پایگاه داده بسیار شبیه به مفهوم «نمایه» (Index) در انتهای یک کتاب است.

ایندکس پایگاه داده نسخه کپی شدهای از ستونهای انتخابی دادهها از یک جدول به حساب میآید که برای فراهمسازی امکان جستجوی بسیار کارامد طراحی میشود. معمولاً ایندکس پایگاه داده شامل یک «کلید» (key) یا پیوند مستقیم به سطر مربوط به دادهای میشود که از آن کپی شده است تا از این طریق بتوان تمام آن سطر را بهگونهای بهینه بازیابی کرد.
در برخی از بانکهای اطلاعاتی، قدرت و نیروی اندیس گذاری در پایگاه داده گسترش و افزایش داده شده است. به دنبال این گسترش قابلیتهای اندیس گذاری ، برنامه نویسان میتوانند ایندکسهایی را روی مقادیر ستونی ایجاد کنند که به وسیله توابع یا عبارتهایی تغییر داده شدهاند. برای مثال میتوان رویupper(last_name) ایندکسی را ساخت که تنها نسخههای با حروف بزرگ در فیلدlast_name را ذخیره کند. انتخاب دیگری که گاهی از آن پشتیبانی میشود، استفاده از «اندیسهای پارهای» (Partial Index) است.

در ایندکسهای پارهای یا جزءجزء، ورودیهای ایندکس تنها برای رکوردهایی ایجاد میشوند که یک عبارت شرطی برای آنها صدق کند. جنبه دیگری از انعطافپذیری در این خصوص این است که بتوان روی توابع تعریف شده توسط کاربر و همچنین عبارتهای شکل گرفته از مجموعهای از توابع داخلی، اندیس گذاری در پایگاه داده را انجام داد.
تعریف Index در پایگاه داده

ایندکس پایگاه داده ساختار یا ساختمان دادهای است که سرعت عملیات بازیابی دادهها را در جدول پایگاه داده بهبود میدهد. البته استفاده از Index در پایگاه داده بدون هزینه نیست و برای نگهداری و استفاده از ساختمان داده ایندکس در پایگاه داده، لازم است دادههای بیشتری ذخیره و نوشته شوند و به دنبال آن، فضای ذخیرهسازی بیشتری اشغال خواهد شد.
از ایندکس در پایگاه داده برای یافتن موقعیت و پیدا کردن سریع دادهها بدون نیاز به جستجوی سطر به سطر بانک اطلاعاتی در هر بار دسترسی به جدول پایگاه داده استفاده میشود. ایندکسهای پایگاه داده را میتوان با استفاده از یک یا بیش از یک ستون از جدول ایجاد کرد که و بدین وسیله پایه و اساسی را هم برای جستجوهای سریع تصادفی و هم برای دسترسی بهینه به رکوردهای مرتبسازی شده بوجود آورد.
دلیل استفاده از ایندکس در پایگاه داده چیست ؟
تصور کنید وارد کتابخانهای بزرگ میشوید و ماموریت پیدا کردن کتابی خاص در ۱۰ دقیقه به شما محول شده است. آیا میتوان این ماموریت را در مدت زمان تعیین شده به انجام رساند؟ کتابخانههای بزرگ حاوی هزاران یا حتی میلیونها جلد کتاب هستند. برای سرعت بخشیدن به انجام این کار میتوان درخواست کرد Index کتابخانه در اختیارمان قرار داده شود؛ زیرا ایندکسها حاوی تمام اطلاعات مورد نیاز برای دسترسی سریع و بهینه به اقلام مختلف هستند.
به همین شکل، Index در پایگاه داده نیز حاوی همه اطلاعات لازم برای دسترسی سریع و کارآمد به دادهها است. درست مانند مثال کتابخانهای عظیم، روش بهینه برای رفع مشکل دسترسی در زمان سر و کار داشتن با دادههای بزرگ، از طریق استفاده از Index در پایگاه داده محقق میشود. ایندکسها به عنوان جدولهای جستجویی عمل میکنند که دادهها به وسیله آنها به صورت بهینه و کارامد برای بازیابی سریعتر ذخیره میشوند.

Index در پایگاه داده چگونه ایجاد میشود؟
در بانک اطلاعاتی، دادهها به صورت سطری ذخیره و در قالب جدولهایی سازماندهی میشوند. هر سطر دارای کلید منحصربهفردی است که آن را از سایر سطرها متمایز میکند و این کلیدها در Index پایگاه داده برای بازیابی سریع ذخیره میشوند.
به دلیل اینکه کلیدها در ایندکسها ذخیره میشوند، هر دفعه که سطری جدید با کلیدی منحصربهفرد اضافه میشود، ایندکس پایگاه داده به طور خودکار بهروزرسانی میشود. اگرچه گاهی لازم است دادههایی سریعاً پیدا شوند که به عنوان کلید در Index پایگاه داده ذخیره نشدهاند. برای مثال، ممکن است نیاز داشته باشیم به سرعت مشتریان را بر اساس شماره تلفن پیدا کنیم. در این مورد ممکن است استفاده از معیاری منحصربهفرد ایده خوبی نباشد، چون ممکن است چندین مشتری با شماره تلفن یکسان در پایگاه داده وجود داشته باشد. در چنین مواردی میتوان ایندکس پایگاه داده مخصوص به خود را ساخت.
آموزش سینتکس ساخت Index در پایگاه داده
سینتکس مربوط به ایجاد Index در پایگاه داده های مختلف متفاوت است. اگرچه این سینتکس معمولاً شامل کلمه کلیدیCREATE میشود که به دنبال آن نیز کلمه کلیدیINDEXمیآید و پس از آن هم نامی که میخواهیم را برای ایندکس مربوطه مینویسیم.
در ادامه، سینتکس Index در پایگاه داده نیز کلمه کلیدی ON میآید و به دنبال آن نیز نام جدولی را درج میکنیم که حاوی دادههای مورد نظر ما است و قصد داریم دسترسی سریع به آنها ایجاد کنیم. در نهایت، آخرین بخش از گزاره مربوط به ساخت Index در پایگاه داده باید اسامی ستونهایی از جدول مربوطه باشند که قرار است ایندکس شوند. بنابراین، سینتکس ساخت Index در پایگاه داده به صورت زیر است:
مثال ساخت Index در پایگاه داده
برای مثال، اگر بخواهیم شمارههای تلفن را در جدولی به نامcustomers در پایگاه داده اندیسگذاری کنیم، میتوان از گزاره زیر استفاده کرد:
CREATE INDEX customers_by_phone ON customers (phone_number)
کاربران نمیتوانند ایندکسهای پایگاه داده را ببینند و Index در پایگاه داده تنها برای سرعت بخشیدن به جستجوها و کوئریها استفاده میشود.

نکته: بهروزرسانی یک جدول با ایندکسها نسبت به بهروزرسانی جدول بدون آن بیشتر زمان میبرد، زیرا علاوهبر جدول، نیاز به بهروزرسانی ایندکسها هم وجود خواهد داشت. بنابراین توصیه میشود تنها ستونهایی اندیسگذاری شوند که به طور دائم مورد جستجو قرار میگیرند.
معرفی فیلم های آموزش پایگاه داده

در پلتفرم فرادرس، دورههای آموزشی براساس موضوع دستهبندی شدهاند و مجموعههای آموزشی مختلفی برای آنها ایجاد شده است. یکی از این مجموعههای آموزشی که با مفاهیم شرح داده شده در این مطلب ارتباط دارد، مجموعه دورههای آموزش پایگاه داده فرادرس به حساب میآید. در این مجموعه دورههای آموزشی مختلفی پیرامون مبحث پایگاه دادهها ارائه شده است.
دورههایی در سطوح مختلف مقدماتی تا پیشرفته برای انواع پایگاه دادهها و سیستمهای مدریت بانکهای اطلاعاتی در این مجموعه موجودند و همچنین دورههایی هم برای کار با پایگاه داده در زبانهای برنامه نویسی مختلف در مجموعه آموزشهای بانک اطلاعاتی فرادرس در دسترس علاقهمندان قرار دارند. در تصویر فوق تنها برخی از دورههای این مجموعه آمده است.
- برای شروع یادگیری پایگاه داده ها و دسترسی به همه دوره های مجموعه آموزش های پایگاه داده فرادرس + اینجا کلیک کنید.
ایندکس گذاری در پایگاه داده چیست ؟
ایندکس گذاری در پایگاه داده یا اندیس گذاری در پایگاه داده روشی است که به کاربر امکان میدهد تا به سرعت رکوردها را از فایل پایگاه داده بازیابی کند. ایندکس جدول کوچکی است که تنها ۲ ستون دارد. اولین ستون از نسخه بازنویسی (کپی) کلید اصلی یا کلید کاندید یک جدول تشکیل شده است. ستون دوم آن حاوی مجموعهای از اشارهگرهایی است. این اشارهگرها برای نگهداری آدرس بلوک دیسک استفاده میشوند که در آنها مقدار کلید مربوطه ذخیره شده است.
انواع ایندکس و اندیس گذاری در پایگاه داده
در این بخش به معرفی و شرح انواع ایندکس در پایگاه داده پرداخته شده است. در ادامه هر یک از انواع Index در پایگاه داده فهرست شده است.

- ایندکس طرح بیتی (Bitmap index)
- اندیس متراکم (Dense Index)
- Index پراکنده (Sparse Index)
- شاخص معکوس (Reverse Index)
- نمایه اصلی (Primary Index)
- ایندکس ثانویه (فرعی | Secondary Index)
- اندیس درهم (Hash Index)

در زیربخش بعدی از انواع ایندکس در پایگاه داده به شرحی انواع اصلی ایندکس و اندیس گذاری در پایگاه داده پرداخته شده است. پس از آن نیز به شرح سایر انواع ایندکس در پایگاه داده پرداخته خواهد شد.
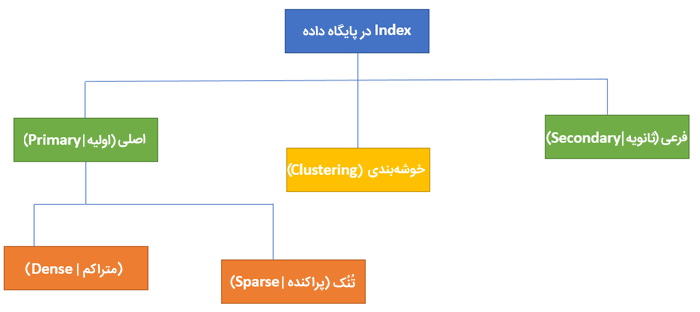
اصلی ترین انواع ایندکس در پایگاه داده
ایندکس گذاری در پایگاه داده بر اساس صفتهای اندیس گذاری آن تعریف میشود. ۲ نوع اصلی اندیس گذاری در پایگاه داده در ادامه فهرست شدهاند:
- اندیس گذاری اصلی (اولیه | Primary Indexing)
- ایندکس گذاری فرعی (ثانویه | Secondary Indexing)
در ادامه به شرح و آموزش هر یک از این انواع ایندکس در پایگاه داده پرداخته شده است.
ایندکس گذاری اصلی در پایگاه داده چیست ؟
اندیس گذاری اولیه در پایگاه داده یا همان اندیس گذاری اولیه به ایجاد فایلی مرتبسازی شده گفته میشود که دارای اندازهای مشخص و ۲ فیلد است. اولین فیلد مشابه کلید اصلی است و دومی به بلوک داده مشخصی اشاره میکند. در اندیس اصلی یا اولیه همیشه ارتباط یک به یک میان ورودیها در جدول ایندکس وجود دارد. ایندکس گذاری اولیه در یک سیستم مدیریت پایگاه داده خودش به ۲ نوع مختلف تقسیم میشود:
- ایندکس متراکم (اندیس متراکم | شاخص متراکم | Dense Index)
- ایندکس تُنُک (شاخص پراکنده | Sparse Index)

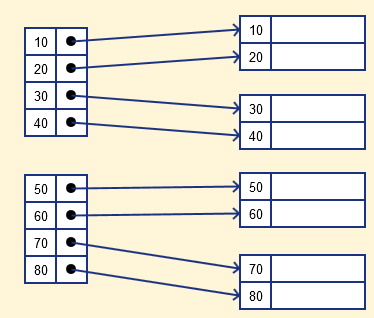
اندیس متراکم در پایگاه داده چیست ؟
در ایندکس متراکم برای هر کلید جستجوی ارزشگذاری شده در پایگاه داده یک رکورد ایجاد میشود. این به فرد کمک میکند تا بتواند سریعتر جستجو کند، اما در این شیوه نیاز به فضای بیشتری برای ذخیرهسازی رکوردهای ایندکس وجود دارد. در این روش ایندکس گذاری در پایگاه داده رکوردهای متُد حاوی مقدار کلید جستجو است و به رکورد واقعی روی دیسک اشاره میکند.
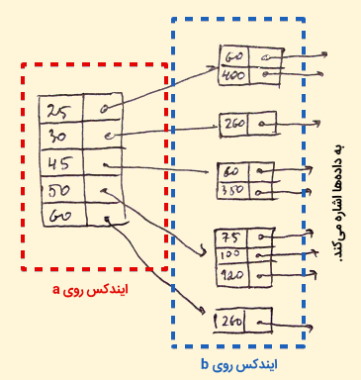
ایندکس پراکنده در پایگاه داده چیست ؟
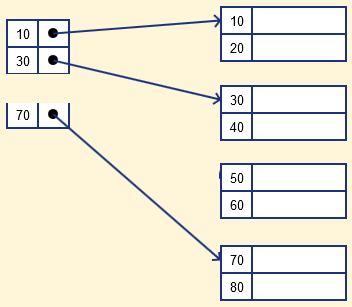
ایندکس تُنُک یا همان Index پراکنده، رکورد اندیسی است که تنها برای برخی از مقادیر در فایل ایندکس درج میشود. ایندکس تُنُک به حل کردن مشکل اندیس گذاری متراکم در پایگاه داده کمک میکند. در این شیوه از ایندکس گذاری در پایگاه داده بازهای از ستونهای Index آدرس بلوک داده یکسانی را ذخیره میکنند و وقتی که نیاز به بازیابی دادهها وجود داشته باشد، آدرس بلوک مورد نظر دریافت خواهد شد.
اگرچه، ایندکس پراکنده رکوردهای Index را تنها برای برخی از مقادیر کلید-جستجو ذخیرهسازی میکند. اندیس تنک نیاز به فضای کمتر و سربار نگهداری کمتری برای درج و حذف دارد، اما در مقایسه با ایندکس متراکم در خصوص موقعیتیابی رکوردها کندتر عمل میکند. در تصویر زیر مثالی از ایندکس گذاری پایگاه داده به روش اندیس تُنُک یا همان شاخص پراکنده آمده است.
ایندکس گذاری فرعی در پایگاه داده چیست ؟
ایندکس گذاری فرعی یا ثانویه در پایگاه داده میتواند به وسیله فیلدی تولید و انجام شود که دارای مقداری منحصربهفرد برای هر رکورد است و باید یک کلید کاندید باشد. به Index فرعی «اندیس غیرخوشهای» (Non-Clustering Index) هم میگویند. این روش اندیس گذاری ۲ سطحی در پایگاه داده برای کاهش اندازه نگاشت سطح اول استفاده میشود. به این منظور، بازه بزرگی از اعداد برای سطح اول انتخاب میشوند؛ به همین دلیل اندازه نگاشت همواره کوچک باقی میماند.

مثالی برای اندیس گذاری ثانویه در پایگاه داده
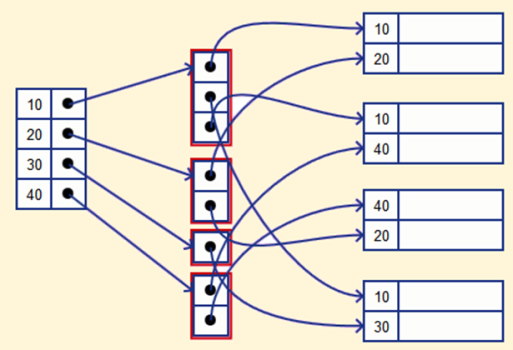
برای درک بهتر ایندکس گذاری فرعی در پایگاه داده بهتر است مثالی ارائه شود. در این مثال فرض میشود پایگاه دادهای از حسابهای بانکی وجود دارد. در این بانک اطلاعاتی دادهها به صورت متوالی بر اساس شماره حساب (acc_no) ذخیرهسازی میشوند.
میتوان تمام حسابها را در شاخهای مشخص از بانک ABC پیدا کرد. در اینجا میتوان Index ثانویهای در پایگاه داده برای هر کلید جستجو (Search-Key) داشت. رکورد ایندکس نقطه رکورد اشاره کننده به «سطلی» است که خود اشارهگرهایی را به همه رکوردهای دارای مقدار مشخص کلید جستجو دارا هستند.
Index خوشه بندی در پایگاه داده چیست ؟
در یک Index خوشهبندی شده، رکوردها خودشان در ایندکس و نه در اشارهگرها ذخیرهسازی میشوند. گاهی Index روی ستونهای غیرکلید اصلی ایجاد میشود که ممکن است برای هر رکورد منحصربهفرد نباشد؛ در چنین شرایطی، میتوان یک یا بیش از یک ستون را گروهبندی کرد تا مقادیر منحصربهفرد دریافت شوند و ایندکسی ساخته شود که به آن Index خوشهبندیشده میگویند. همچنین این مسئله کمک میکند تا بتوان رکورد مربوطه را سریعتر شناسایی کرد.
مثال Index خوشه بندی شده در پایگاه داده
برای مثال اگر فرض شود که شرکتی تعداد زیادی از کارمندان را در حوزههای مختلف جذب کرده است. در چنین شرایطی، اندیس گذاری خوشهبندیشده در پایگاه داده باید برای تمام کارمندانی که در بخش یکسانی از شرکت هستند ایجاد شود. در خوشهای واحد اینطور در نظر گرفته میشود که یک نقطه ایندکس به خوشه مربوطه به عنوان یک کل اشاره میکند. در اینجا Department _no کلیدی غیرمنحصربهفرد به حساب میآید.
Index چندسطحی در پایگاه داده چیست؟
اندیس گذاری چند سطحی در پایگاه داده زمانی ایجاد میشود که حافظه کافی برای گنجاندن ایندکس اولیه یا همان ایندکس اصلی وجود نداشته باشد. در این روش ایندکس گذاری در پایگاه داده میتوان تعداد دسترسیها به دیسک را در هر رکورد روی دیسک به عنوان فایلی ترتیبی کاهش داد و پایهای تُنُک و پراکنده روی آن فایل ایجاد کرد.
ایندکس B-Tree در پایگاه داده چیست ؟
ایندکس B-Tree ساختمان دادهای پراستفاده برای اندیس گذاری درختی در پایگاه داده به حساب میآید. این نوع اندیس گذاری دارای قالب ایندکس گذاری درختی چندسطهی است که درختهای جستجوی دودویی متعادلی دارد. تمام گرههای برگ B-Tree اشارهگرهای داده واقعی را مشخص میکنند. علاوهبر این، تمام گرههای برگ با یک لیست پیوندی به هم پیوند داده شدهاند؛ این روش هم امکان پشتیبانی از دسترسی تصادفی در B-Tree را امکانپذیر ساخته است و هم به این شیوه امکان دسترسی ترتیبی فراهم میشود.
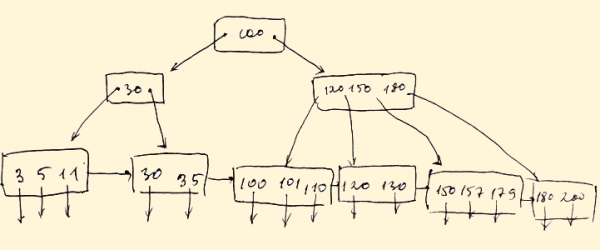
- گرههای تقدم باید بین ۲ تا ۴ مقدار داشته باشند.
- هر مسیری از ریشه تا برگ غالباً دارای طولی مساوی است.
- گرههای غیر برگ به غیر از گره ریشه بین ۳ تا ۵ گره فرزند دارند.
- هر گرهای که ریشه یا برگ نباشد، از n/2 تا n فرزند دارد.
مزایای اندیس گذاری در پایگاه داده چیست ؟
برخی از نقاط قوت و مزایای ایندکس گذاری در پایگاه داده در ادامه فهرست شدهاند:
- اندیس گذاری در پایگاه داده به کاهش عملیات ورودی/خروجی لازم برای بازیابی دادهها کمک میکند و بنابراین نیازی به دسترسی به یک ردیف در پایگاه داده از ساختار شاخص وجود ندارد.
- با ایندکس گذاری در پایگاه داده جستجو و بازیابی دادهها برای کاربران سریعتر خواهد بود.
- علاوه بر این، ایندکس گذاری به کاهش فضای جدول کمک میکند، زیرا دیگر نیازی به پیوند زدن به سطری در جدول وجود نخواهد داشت و همچنین لازم نیست شناسه سطر را در ایندکس ذخیرهسازی کرد.
- نمیتوان دادهها را در گرههای تقدم مرتبسازی کرد، زیرا مقادیر کلید اصلی آن را دستهبندی میکنند.

معایب اندیس گذاری در پایگاه داده چیست ؟
برخی از مهمترین کاستیها و معایب اندیس گذاری در ادامه شرح داده شدهاندک
- برای اجرای ایندکس گذاری در پایگاه داده نیاز به یک کلید اصلی دارای مقداری منحصربهفرد در جدول وجود دارد.
- نمیتوان هیچ اندیس دیگری را روی دادههای ایندکس شده اجرا کرد.
- اندیس گذاری در SQL میزان عملکرد را در کوئریهای DELETE ،INSERT و UPDATE کاهش میدهد.
اندیس طرح بیتی یا Bitmap index در پایگاه داده چیست ؟
ایندکس بیتمپ یا همان طرح بیتی (Bitmap Index) نوع خاصی از اندیس گذاری است که توده و حجمی از دادههای آن به عنوان آرایههای بیتی (بیتمپها) ذخیره میشوند و به اکثر کوئریها به وسیله اجرای عملیات منطقی بیتی روی این بیتمپها پاسخ میدهد. پراستفادهترین ایندکسهای استفاده شده مثل درختهای B+، اگر مقادیری که ایندکس گذاری میکنند تکرار نشوند یا به تعداد دفعات کمی تکرار شوند از همه بهینهتر هستند.
برخلاف آن، ایندکس بیتمپ برای مواردی طراحی شده است که مقادیر یک متغیر در آن به طور مکرر تکرار میشوند. مثلاً فیلد جنسیت در پایگاه داده مشتریان معمولاً حداکثر حاوی ۳ مقدار منحصربهفرد است که شامل مذکر، مونث یا ناشناخته (ثبت نشده) میشود. برای چنین متغیرهایی، ایندکس بیتمپ میتواند در برابر درختهای رایج برتری عملکردی ویژهای داشته باشد.
ایندکس معکوس یا Reverse Index در پایگاه داده چیست ؟
index کلید معکوس، مقدار کلید را قبل از وارد کردن آن در ایندکس معکوس میکند. برای مثال مقدار ۲۴۵۳۸ در ایندکس به ۸۳۵۴۲ تغییر میکند. معکوس کردن مقدار کلید به طور خاص برای دادههای اندیس گذاری مثل اعداد ترتیبی کاربردی و مفید است، چون در آنها مقادیر کلید به طور یکنواخت افزایش پیدا میکنند.
جمعبندی
این مطلب با هدف ارائه دید کلی نسبت به مفهوم Index در پایگاه داده ارائه شد. در ادامه فهرستی از خلاصه موارد بیان شده در این مطلب آمده است:
- Index در پایگاه داده ابزاری قدرتمند است که در پسزمینه پایگاه داده برای سرعت بخشیدن به کوئری زدن مورد استفاده قرار میگیرد.
- ایندکسهای پایگاه داده حاوی تمام اطلاعات مورد نیاز برای دسترسی سریع و بهینه به آیتمها است.
- Index در پایگاه داده به عنوان جدولهای جستجو با هدف ذخیرهسازی بهینه دادهها به منظور بازیابی سریعتر خدمترسانی میکند.
- کلیدهای جدول در ایندکسهای پایگاه داده ذخیره میشوند.
- ایندکسهای مقادیری که کلید نیستند را میتوان با دستور یا عبارتCREATE INDEX ایجاد کرد.
- اندیس گذاری جدول کوچکی است که شامل ۲ ستون میشود.
- ۲ نوع اصلی از انواع اندیس گذاری در پایگاه داده ایندکس گذاری اصلی و فرعی را شامل میشود.










