




دسته بندی داده ها با پایتون – راهنمای کاربردی
در این مطلب، چندین الگوریتم «یادگیری ماشین» (Machine Learning) در «زبان برنامهنویسی پایتون» (Python Programming Language) با استفاده از کتابخانه «سایکیت لِرن» (Scikit-Learn) که یکی از محبوبترین کتابخانههای یادگیری ماشین است، پیادهسازی شدهاند. این الگوریتمها، برای «دستهبندی» (Classification) یک مجموعه داده برچسبدار از میوهها، مورد استفاده قرار گرفتهاند. در واقع، از یک مجموعه داده ساده، برای آموزش دادن «دستهبند» (Classifier) و تمایز ایجاد کردن بین انواع میوهها، استفاده شده است. هدف از این مطلب، شناسایی الگوریتم یادگیری ماشینی است که برای چنین مسالهای بالاترین صحت را ارائه میکند. بنابراین، الگوریتمهای گوناگون در ادامه با یکدیگر مقایسه میشوند و الگوریتمی با بهترین عملکرد، انتخاب میشود. با مطالعه این مطلب، میتوان با روشهای گوناگون دسته بندی داده ها با پایتون آشنا شد.




داده
مجموعه داده میوهها، توسط دکتر «لاین مورای» (Iain Murray) از «دانشگاه اِدینبرا» (University of Edinburgh) ساخته شده است. وی، مقادیر زیادی پرتقال، لیمو و سیب از گونههای گوناگون را تهیه و اندازههای آنها را در یک جدول ثبت کرده است.
سپس، اساتید دانشگاهی در «میشیگان» (Michigan)، دادههای میوهها را به تدریج قالببندی کردهاند. مجموعه داده نهایی حاصل شده از این فرایند را میتوان از اینجا [+] دانلود کرد. در ادامه، نگاهی به سطرهای اول این مجموعه داده انداخته میشود.
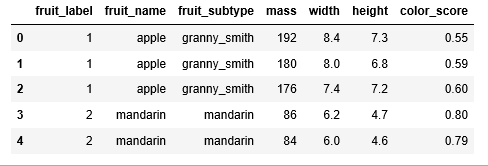
هر سطر از مجموعه داده، نشانگر یک میوه به همراه «ویژگیهای» (Features) آن است. ۵۹ عدد نمونه (اطلاعات مربوط به ۵۹ میوه)، همراه با هفت ویژگی پیرامون آنها، در این مجموعه داده آورده شده است.
ورودی:
خروجی:
(59, 7)
چهار نوع میوه، در مجموعه داده وجود دارد (در واقع، با توجه به برچسبدار بودن مجموعه داده، چهار برچسب وجود دارد).
ورودی:
خروجی:
[‘apple’ ‘mandarin’ ‘orange’ ‘lemon’]
دادهها به جز در مورد «پرتقال ماندارین» (Mandarin)، متوازن هستند (که البته میتوان با این مساله کنار آمد).
ورودی:
خروجی:

ورودی:
خروجی:

بصریسازی
نمودار جعبهای، برای هر متغیر عددی، ایدهای کلی از شیوه توزیع متغیرهای ورودی به دست میدهد.
ورودی:
خروجی:
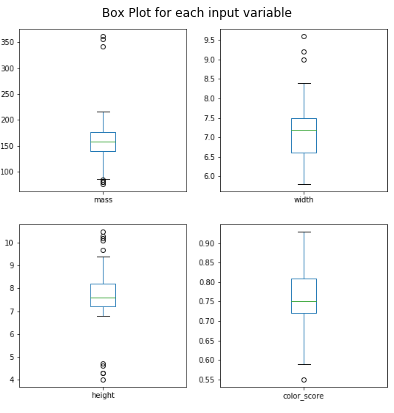
به نظر میرسد که امتیاز رنگ، دارای توزیعی نزدیک به «توزیع گاوسی» (Gaussian Distribution) است.
ورودی:
خروجی:

برخی از جفت ویژگیها، همبسته هستند (جرم و عرض). این امر موجب همبستگی بالا و رابطه قابل پیشبینی میشود.
ورودی:
خروجی:

خلاصه آماری

میتوان مشاهده کرد که مقادیر عددی، دارای مقیاس یکسانی نیستند. بنابراین، نیاز به اعمال استانداردسازی مجموعه داده تست است؛ در اینجا باید همان روش استانداردسازی که برای مجموعه داده آموزش مورد استفاده قرار گرفته، روی مجموعه داده تست اعمال شود .
ساخت مجموعههای آموزش، تست و اعمال استانداردسازی
دسته بندی داده ها با پایتون
همانطور که پیشتر بیان شد، چندین مدل گوناگون روی مجموعه داده اعمال میشوند تا کارایی آنها سنجیده و صحت خروجی حاصل از هر یک از آنها، با دیگر الگوریتمها مقایسه شود. در نهایت، مدل با بهترین خروجی، انتخاب خواهد شد.
رگرسیون لجستیک
برای مطالعه بیشتر پیرامون الگوریتم «رگرسیون لجستیک» (Logistic Regression)، مطالعه مطلب «رگرسیون لجستیک در پایتون — راهنمای گام به گام»، توصیه میشود. در زیر، پیادهسازی این الگوریتم با استفاده از کتابخانه Scikit-Learn انجام شده است.
- صحت دستهبند رگرسیون لجستیک روی مجموعه داده آموزش: ۰.۷۰
- صحت دستهبند رگرسیون لجستیک روی مجموعه داده تست: ۰.۴۰
درخت تصمیم
برای مطالعه بیشتر پیرامون الگوریتم «درخت تصمیم» (Decision Tree)، مطالعه مطلب «درخت تصمیم با پایتون — راهنمای کاربردی» پیشنهاد میشود. در زیر، قطعه کد مربوط به اعمال این الگوریتم روی مجموعه داده میوهها، ارائه شده است.
- صحت دستهبند درخت تصمیم روی مجموعه داده آموزش: 1.00
- صحت دستهبند درخت تصمیم، روی مجموعه داده تست: ۰.۷۳
K-نزدیکترین همسایگی
برای مطالعه بیشتر پیرامون الگوریتم «K-نزدیکترین همسایگی» (k-Nearest Neighbors | KNN)، مطالعه مطلب «الگوریتم K-نزدیکترین همسایگی به همراه کد پایتون» توصیه میشود. در ادامه، قطعه کد مربوط به اعمال الگوریتم KNN روی مجموعه داده میوهها، ارائه شده است.
- صحت دستهبندی KNN روی مجموعه داده آموزش: ۰.۹۵
- صحت دستهبندی KNN روی مجموعه تست: ۱.۰
آنالیز تشخیصی خطی
برای مطالعه بیشتر پیرامون الگوریتم «آنالیز تشخیصی خطی» (Linear Discriminant Analysis | LDA)، مطالعه مطلب «آنالیز تشخیصی خطی (LDA) در پایتون — راهنمای کاربردی» توصیه میشود.

در ادامه، الگوریتم LDA روی مجموعه داده میوه اعمال شده است.
- صحت دستهبندی LDA روی مجموعه داده آموزش: ۰.۸۶
- صحت دستهبندی LDA روی مجموعه داده تست: ۰.۶۷
نایو بیز گاوسی
برای آشنایی بیشتر با الگوریتم «دستهبند بیز ساده» (Naive Bayes Classifiers)، مطالعه مطلب «دسته بند بیز ساده (Naive Bayes Classifiers) — مفاهیم اولیه و کاربردها» توصیه میشود. در ادامه، قطعه کد مربوط به اعمال الگوریتم نایو بیز گاوسی روی مجموعه داده میوهها ارائه شده است.
- صحت دستهبند نایو بیز گاوسی روی مجموعه آموزش: ۰.۸۶
- صحت دستهبند نایو بیز گاوسی روی مجموعه تست: ۰.۶۷
ماشین بردار پشتیبان
برای مطالعه بیشتر پیرامون الگوریتم «ماشین بردار پشتیبان» (Support Vector Machine | SVM)، مطالعه مطلب «ماشین بردار پشتیبان — به همراه کدنویسی پایتون و R» توصیه میشود.
در ادامه، پیادهسازی SVM با استفاده از کتابخانه سایکیتلرن انجام شده است.
- صحت دستهبند ماشین بردار پشتیبانی روی مجموعه آموزش: ۰.۶۱
- صحت دستهبند ماشین بردار پشتیبان روی مجموعه تست: ۰.۳۳
نتیجهگیری
همانطور که از صحتهای حاصل شده مشهود است، مدل KNN بالاترین خروجی را داشته است. «ماتریس درهم ریختگی» (Confusion Matrix) حاکی از عدم وجود هرگونه خطا در خروجی الگوریتم K-نزدیکترین همسایگی برای مجموعه داده تست است. اگرچه، مجموعه داده تست استفاده شده، خیلی کوچک محسوب میشود.

ترسیم مرزهای دستهبندی برای دستهبند K-نزدیکترین همسایگی


برای این مجموعه داده، بالاترین صحت هنگامی حاصل میشود که مقدار K در الگوریتم KNN برابر با پنج (k=5) تعیین شده است.
خلاصه
در این مطلب، الگوریتمهای دستهبندی گوناگون با استفاده از کتابخانه سایکیتلرن پیادهسازی و روی یک مجموعه داده برچسبدار (مجموعه داده میوهها) اعمال شدند. سپس، صحت نتایج حاصل از هر یک از الگوریتمها با دیگر موارد مقایسه شد. در واقع، در این بررسی موردی روی صحت پیشبینیها تمرکز شده و هدف، یافتن مدلی بود که صحت خوبی داشته باشد. چنین مدلی، صحت پیشبینی را بیشینه میسازد. در نهایت، الگوریتم یادگیری ماشینی که بهترین خروجی را برای مساله بیان شده داشت (دستهبندی انواع میوهها)، یعنی KNN، شناسایی شد. کدهای استفاده شده برای این پروژه، در گیتهاب [+] موجود هستند.

اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزشهای دادهکاوی یا Data Mining در متلب
- مجموعه آموزشهای هوش مصنوعی
- زبان برنامهنویسی پایتون (Python) — از صفر تا صد
- یادگیری ماشین با پایتون — به زبان ساده
- آموزش یادگیری ماشین با مثالهای کاربردی — مجموعه مقالات جامع وبلاگ فرادرس
- چگونه یک دانشمند داده شوید؟ — راهنمای گامبهگام به همراه معرفی منابع
^^










خیلی ب دردم خورد دمتون گرم