



درخت تصمیم با پایتون – راهنمای کاربردی
در این مطلب، چگونگی ساخت «درخت تصمیم» (Decision Trees) در «زبان برنامهنویسی پایتون» (Python Programming Language) آموزش داده شده است. یک درخت تصمیم، مدلی است که برای حل وظایف «دستهبندی» (Classification) و «رگرسیون» (Regression) مورد استفاده قرار میگیرد. مدل، امکان تولید خروجیهای گوناگون را فراهم کرده و امکان انجام تصمیمگیری با دادهها را فراهم میکند. در مثال بیان شده در این مطلب، تاثیر «متغیرهای توصیفی» (explanatory variables) (از جمله سن، جنسیت، صفحات وب بازدید شده در روز، ساعت ویدئوهای بازدید شده در هفته و درآمد فرد) در استفاده از اینترنت (مصرف مگابایت در هفته) تحلیل خواهد شد. شایان توجه است که مجموعه داده مورد استفاده در این مطلب، از این مسیر (+) قابل دانلود است. شایان توجه است که ورودی و خروجی ها با توجه به محل قرارگیری مجموعه داده در سیستم افراد گوناگون، تفاوتهایی را با کدهای موجود در این مطلب خواهد داشت.


گام ۱: بارگذاری کتابخانهها
ابتدا، کتابخانه «نامپای» (Numpy) و train_test_split از کتابخانه «سایکیتلِرن» (Scikit-Learn) وارد (Import) میشود.
با استفاده از کلاس فراخوانی شده از کتابخانه sklearn، مجموعه داده به دادههای «آموزش» (Training) و «آزمون» (Test) شکسته میشود، و به موجب آن، مدل روی دادههای آموزش ساخته و صحت این مدل در مقابل دادههای «آزمون» (Test) آزموده میشود.
ورودی [1]:
خروجی [1]:
'C:\\Users\\michaeljgrogan\\Documents\\a_documents\\computing\\data science\\datasets'
گام ۲: بارگذاری مجموعه داده و متغیرها
اکنون از np.loadtxt برای بارگذاری دادهها در فرمت csv استفاده میشود.
ورودی [۲]:
گام ۳: ایمپورت کردن DecisionTreeRegressor از sklearn
در ادامه، DecisionTreeRegressor از کتابخانه سایکیت لِرن وارد (Import) میشود و دادهها را به مولفههای «آموزش» (training) و «آزمون» (test) جدا میکند.
چنانکه پیشتر بیان شد، میتوان مشاهده کرد که دادههای X_train و y_train برای ساخت مدل مورد استفاده قرار گرفتهاند.
ورودی [۳]:
گام ۴: تعیین صحت مجموعه آموزش و آزمون
هنگامی که صحت ارزیابی شد، میتوان مشاهده کرد که صحت ٪۱۰۰ برای مجموعه آموزش و ٪۸۵.۱ برای مجموعه آزمون حاصل شده است.
ورودی [۴]:
خروجی [۴]:
Training set accuracy: 1.000 Test set accuracy: 0.851
گام ۵: انجام پیشبینیها از درخت تصمیم
با استفاده از tree.predict، پیشبینیها برای متغیرهای وابسته با استفاده از مدل انجام میشود.
ورودی [۵]:
ورودی [۶]:
خروجی [۶]:
گام ۶: محاسبه درصد خطای بین پیشبینیها و دادههای واقعی
این موضوع حقیقتا واضح است. مدل درخت تصمیم، استفاده از اینترنت را تخمین زده و اکنون هدف محاسبه انحراف بین پیشبینیها و مقادیر واقعی است.
ورودی [۷]:
خروجی [۷]:
array([ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, -6.59871600e+00, 0.00000000e+00, ... 1.64641577e+02, 0.00000000e+00, 1.09477689e+01, 0.00000000e+00, 0.00000000e+00, 1.21515057e+01, 0.00000000e+00, 6.60971223e+00, 0.00000000e+00, 0.00000000e+00, -1.13177394e+01])
ورودی [۸]:
خروجی [۸]:
4.116144626944652
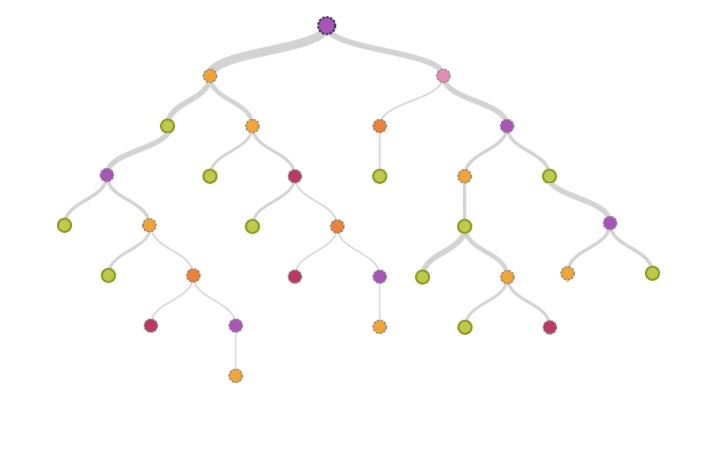
گام ۷: ترسیم گراف درخت تصمیم
با توجه به اینکه پس از محاسبات مشخص شده که مدل درخت تصمیم مورد استفاده در اینجا دارای نرخ صحت بالایی است، در حال حاضر هدف ترسیم نمودار آن به صورت بصری است تا امکان تفسیر روابط میان متغیرها وجود داشته باشد.

کتابخانهای که برای انجام این کار مورد استفاده قرار گرفته «گرافویز» (graphviz) نام دارند و با pip به شیوهای که در ادامه بیان میشود قابل نصب است. شایان توجه است که با توجه به استفاده نویسنده این مطلب از پایتون ۳.۶، pip3 برای نصب مورد استفاده قرار گرفته است.
اکنون که graphviz نصب شد، ابتدا درخت به صورت یک فایل .dot خروجی گرفته (export) و سپس مجددا وارد میشود.
با پایان یافتن این کار، میتوان «شِل» (shell) را باز کرد و درخت تصمیم را در فرمت pdf خروجی گرفت.
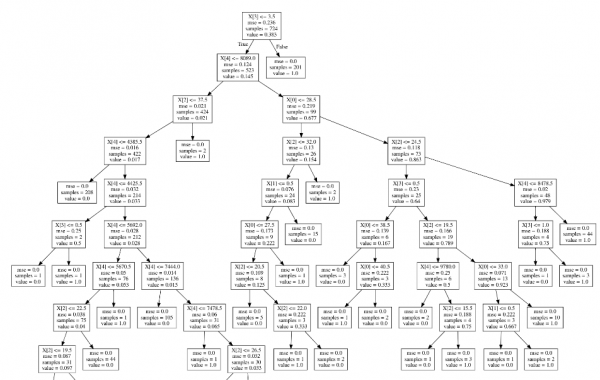

نتیجهگیری
همانطور که مشاهده شد، انحراف ٪۴.۱۱ بین مقادیر پیشبینی شده و مقادیر واقعی وجود داشت. با در نظر گرفتن این موضوع و با مقدار به دست آمده ۰.۸۵۱ برای مجموعه تست، میتوان گفت درخت تصمیم دارای درجه بالایی از صحت در پیشبینی استفاده از اینترنت است.
شایان توجه است که مجموعه داده مورد استفاده در این مطلب، از این مسیر (+) قابل دانلود است.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای برنامه نویسی پایتون (Python)
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای هوش محاسباتی
- آموزش برنامهنویسی R و نرمافزار R Studio
- مجموعه آموزشهای برنامه نویسی متلب (MATLAB)
^^










با سلام وقتی بر روی دانلود برای مجموعه داده ها زده میشود خطا میگیرد
سلام، وقت شما بخیر؛
این مورد بررسی شد و مشکلی در دانلود فایل مجموعه دادهها وجود ندارد؛ لطفاً در صورتیکه بازهم پیغام خطا دریافت میکنید، با یک مرورگر دیگر امتحان بفرمائید.
از همراهی شما با مجله فرادرس بسیار سپاسگزاریم.
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزاریم. برای رفع مشکل، در آرایه و در هنگام ارائه بازه، باید از سطر دوم یعنی بعد از سرآیند آغاز به کار کرد.
پیروز، شاد و تندرست باشید.
با سلام
به من این ارور رو میده
return float(x)
ValueError: could not convert string to float: ‘age’
برا منم این خطا رو میده!
صفحه ی داده ها مورد استفاده باز نمیشود !!
با سلام؛
از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم. لینک فایل به مطلب اضافه شد.
با سپاس.
یک سوال در مورد path داشتم،شما پاسخ میدین؟