



دستور Distinct در SQL – از کاربرد تا نحوه استفاده به زبان ساده
SQL یا «زبان جستوجوی ساختاریافته» (Structured Query Language)، ابزار بسیار ضروری برای مدیریت و دستکاری دادهها در «پایگاههای داده رابطهای» (Relational Databases) است. یکی از چالشهای رایجی که کاربران «پایگاه داده» (Database) با آن روبهرو میشوند، کارکردن با دادههای تکراری در جدولها است. برای حل این مشکل، SQL کلمه کلیدی قدرتمندی به نام DISTINCT را معرفی میکند که به کاربران اجازه میدهد که مقادیر تکراری را فیلتر کنند و در نتایج کوئریهایی که اعمال میکنند، مقدارها فقط بهصورت یکتا نمایشداده شوند. در این مطلب از مجله فرادرس درباره سناریوهای رایج برای استفاده از دستور Distinct در SQL صحبت خواهیم کرد. سعی خواهیم کرد مطلب را بهصورت آسان و قابل درکی بیان کنیم و در حالی که برای افراد تازهکار واضح و قابل فهم است برای حرفهایها هم مفید باشد.
- میآموزید دستور SELECT DISTINCT در SQL چیست و چه زمانی کاربرد دارد.
- یاد میگیرید چگونه با دستور DISTINCT مقادیر غیرتکراری را از پایگاه داده استخراج کنید.
- با نحوه استفاده از DISTINCT همراه با چندین ستون و سایر عبارات SQL آشنا میشوید.
- میتوانید عبارت DISTINCT را با WHERE، ORDER BY و GROUP BY ترکیب کنید.
- یاد میگیرید چطور مقادیر NULL را با کمک دستور DISTINCT شناسایی و فیلتر کنید.
- تفاوت DISTINCT و UNIQUE در SQL و کاربرد دقیق آنها را بهدرستی میآموزید.




همچنین، به چند «تحلیل داده» (DataAnalysis) ساده ارائه شده برپایه کلمه کلیدی DISTINCT در این مقاله خواهیم پرداخت. علاوه بر این، بهراحتی فقط با کپی و اجرا کردن کدهای نوشته شده در هر پایگاه دادهای که با زبان SQL کار کند، خوانندگان این مطلب تجربه پیادهسازی موارد کاربردی رایج مورد بحث را بدست خواهند آورد.

درک SELECT Distinct در SQL
در ابتدا باید با کمک مثالهای ساده، درک واضحی از دستور Distinct در SQL همراه با عبارت SELECT بدست بیاوریم. با پایگاه دادهای ساده، تشکیل شده از فقط یک جدول شروع میکنیم.
تنظیم پایگاه داده نمونه
برای نمونه، پایگاه داده سادهای به نام StudentExamDemo میسازیم و جدولی به نام Student درون آن ایجاد میکنیم. از این پایگاه داده برای دیدن نتایج عملیات روی مثالهای ساده استفاده خواهیم کرد. برای تمرین و کد زدن همراه با مطالعهی این مطلب، میتوانید حتی از پایگاه داده Azure SQL هم استفاده کنید. ما در اینجا برای نمایش مثالها از نمونه پایگاه داده غیرابری SQL استفاده خواهیم کرد.
از اسکریپت زیر در سرور پایگاه داده استفاده کنید تا پایگاه داده StudentExamDemo را بسازید.
سپس، با استفاده از کد زیر در پایگاه داده خود، جدول Student را ایجاد کنید. در کوئری زیر از دستور IF در SQL استفاده شده است.
عبارت SELECT در مقابل عبارت SELECT ALL
قبل از اینکه به صحبت درباره SELECT Distinct در SQL بپردازیم، باید بدانیم تنها ردیفهای مشخص شده با توجه به ستونهای انتخابی - در دستور Select - استخراج میشوند.
سینتکس پایه SELECT DISTINCT
عبارت DISTINCT در دستور SELECT بهکار میرود. شکل خام سینتکس پایه برای استفاده از دستور Distinct در SQL بهصورت زیر است.
قبل از هر چیز، درباره عبارت SELECT
نکته مهم در رابطه با دستور SELECTاین است که این عبارت در حالت پیشفرض، همه رکوردهای واجد شرایط را ازجمله مقادیر تکراری ستونها را نیز برمیگرداند. بنابراین، از لحاظ فنی همه عبارات SELECT بهطور پیشفرض دارای کلمه ALL هستند مگر اینکه خلاف آن بیان شود.
میخواهیم همه ردیفهای جدول Student را که قبلا ساختهایم با استفاده از عبارتSELECT ببینیم. طبق کدی که در ادامه آوردهایم این کار را انجام دهید.
برای ساخت View در SQL از دستور SELECT استفاده میشود. هرچند سینتکس مربوط به ساخت View در SQL با کد نوشته شده در کادر بالا اندکی تفاوت دارد. خروجی این عبارت بهصورت زیر میشود.

دوباره همان اسکریپت را اجرا خواهیم کرد اما این بار کلمه کلیدیALL را به ابتدای اسکریپت اضافه میکنیم.
در تصویر زیر، خروجی کد آورده شده است.

در نتیجه میبینیم بدون اینکه بند خاصی به فرمان SELECT اضافه شود، بهصورت پیشفرض از کلمه کلیدیALLاستفاده میکند. در مثالهای بالا هر دو حالت این دستور را دیدیم. همچنین متوجه شدیم که یکی از رکوردهای دانشجویان دوبار تکرار شده است. فرض میکنیم که این تکرار، بهخواطر ورود اشتباهی توسط کاربر در هنگام ثبت نام رخ داده است و در ادامهی کار به حل این مسئله خواهیم پرداخت.

عبارت SELECT ALL در مقابل عبارت SELECT Distinct در SQL
کلمه کلیدی دستور Distinct در SQL همرا با عبارت SELECTمیتواند به کاربران کمک کند تا فقط رکوردهای غیرتکراری بر پایه ستون مشخصی را نمایشدهند. به این معنی که دیگر ردیفهای تکراری نخواهیم دید. مانند ردیفهایی که بالاتر در مثال قبلی دیدیم.
نمونه کد ساده برای دستور Distinct در SQL
برای درک بهتر روش استفاده از عبارت DISTINCT به همراه دستور SELECT و دیدن نتیجه اجرای این اسکریپت به نمونه کد زیر توجه کنید.
نتیجه اجرای این کوئری بهصورت زیر میشود.

در این نوبت، ردیف مربوط به دانشجو Atif را بهصورت تکراری نمیبینیم. دفعه پیش این ردیف دوبار تکرار شده بود. زیرا اینبار درحال نگاه کردن به نامهای «غیرتکراری» (Distinct) هستیم چون دستورDISTINCT را روی مقادیر مربوط به ستون Name اعمال کردهایم و بهعنوان نتیجه، از نمایش ردیفهای تکراری در مجموعه نتایج جلوگیری کردهایم. البته این اتفاق بر روی جدول موقتی رخ میدهد، که از نتیجه کوئریها حاصل میشود.
محل قرارگیری کلمه کلیدی DISTINCT
توجه کنید که درون اسکریپت T-SQL یا همان کوئری SQL، دستور Distinct که برای نمایش ردیفها بهصورت غیرتکراری استفاده میشود، باید اولین کلمه بعد از عبارت SELECTباشد. پس درحالی که ستون اول را رها کردهاید، نمیتوانید از دستورDISTINCTبرای ستون دوم استفاده کنید.
برای مثال اجرای اسکریپت زیر باعث نمایش پیغام خطا خواهد شد.
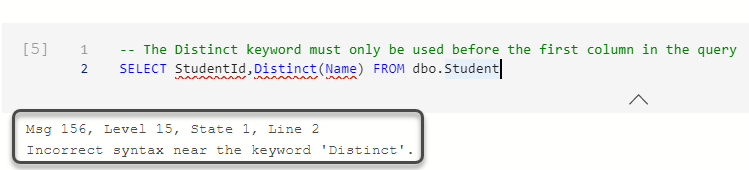
استفاده از دستور Distinct در SQL با چندین ستون
وقتی که از عبارت SELECT DISTINCT در SQL استفاده میکنیم در اصل به پایگاه داده میگوییم که فقط مقادیر یکتا را در ستونهای مشخص شده برگرداند. موتور پایگاه داده هر سطر را در مجموعه نتایج مقایسه میکند و اگر سطری را در همه ستونهای مشخص شده، پیدا کند که با سطر دیگری یکسان باشد، سطر تکراری را دور میاندازد.
وقتی که میخواهید ترکیبات یکتا از مقادیر چندین ستون را واکشی کنید، کافی است به آسانی ستونها را بعد از کلمه کلیدی DISTINCT فهرست کنید، درحالی که آنها را با کاما از هم جدا کردهاید.
توجه کنید که اگر از ترکیب ستونها برای پیدا کردن مقادیر یکتا استفاده کنید نتیجهای که در خروجی خواهید دید بسته به ستونهایی که ترکیب کردهاید، یا حتی اینکه یک ستون انتخاب کردهاید، متفاوت خواهد بود.
استفاده از دستور Distinct همراه با سایر عبارت ها
میتوان از کلمه کلیدی DISTINCT همراه با عبارتها یا محاسبات شامل یک یا چندین ستون استفاده کرد. در این روش «عبارت» (Expression) بعد از کلمه کلیدی DISTINCT قرار میگیرد.
برای مثال فرض کنید که جدول محصولات فروشگاهی شامل ستونهایی برای قیمت price و تعداد موجودی quantity هر محصول است.

اگر بخواهید مبلغ کل را بهصورت مجزا با توجه به فرمول قیمت * تعداد بدست بیاورید، میتوانید از کوئری SELECT که در ادامه آمده، استفاده کنید.
در این کوئری، فرمول quantity * price مبلغ کل را برای هر ردیف محاسبه میکند و کلمه کلیدی DISTINCT تضمین میکند که فقط مقادیر منحصربهفرد به کاربر برگشت داده شوند.

استفاده از دستور Distinct در SQL، درون کوئری ها
در این بخش، به بررسی بعضی از موارد کاربرد و مثالهای دستور Distinct در SQL خواهیم پرداخت. بعضی موضوعات گفته شده نیز با مثال کوتاهی بررسی میشوند. برای مثالهای آورده شده در این بخش، از جدول فرضی مشخصات کارمندان استفاده خواهیم کرد.

درباره مواردی که در زیر فهرست شدند، در ادامه بهطور اختصاصی صحبت کردهایم.
- انتخاب کردن مقادیر منحصربهفرد
- حذف کردن موارد تکراری - برای نمایش رکوردها استفاده میشود و بالاتر درباره این مورد صحبت کردهایم.
- شمارش مقادیر منحصربهفرد
چگونه مقادیر منحصر به فرد را با استفاده از دستور Distinct در SQL انتخاب کنیم؟
وقتی که میخواهید موارد تکراری را حذف کنید و فقط مقادیری را فهرست کنید که با یکدیگر تفاوت دارند کلمه کلیدی DISTINCT بسیار کاربردی خواهد بود. سادهترین نمونه از سینتکسی که برای انتخاب مقادیر یکتا بهکار میرود در ادامه آمده است.
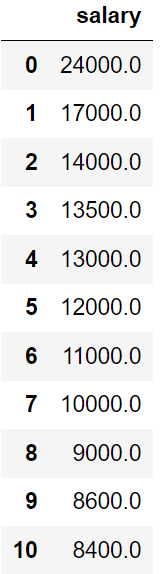
به عنوان مثال، میتوانید مقادیر یکتا را از ستون حقوق کارمندان در جدول کارمندان استخراج کنید.
از دستور ORDER BY برای مرتبسازی مجموعه نتایج بهصورت صعودی یا نزولی استفاده میشود. دستور ORDER BY به طور پیشفرض مجموعه نتایج را بهصورت صعودی مرتب میکند. برای مرتبسازی رکوردها بهصورت نزولی، از کلمه کلیدی DESC استفاده میشود. خروجی فرضی زیر را برای کد مثال زده شده در بالا نمایش میدهیم.
چگونه مقادیر مجزا از یکدیگر را با استفاده از SQL DISTINCT بشماریم؟
میتوانید از دستور Distinct در SQL برای تجمیع توابع نیز استفاده کنید. یعنی دستورDISTINCT را درون تابع COUNT در SQL ، برای شمارش تعداد مقادیر یکتای حاضر در ستون استفاده کنید. برای اینکه بهتر متوجه شوید و با سینتکس این علمیات آشنا شوید، به نمونه کدی که در ادامه آمده دقت کنید.
در این کد کلمه column به نام ستونی اشاره میکند که میخواهید اطلاعات درون آن ستون را بررسی کنید. این کد خروجی اطلاعات را درون جدول موقتی برای نمایش به کاربر میریزد، بهجای کلمه AggregateName نام جدول موقتی را وارد کنید که قرار است به عنوان نتیجه کوئری، دادهها را به ما نمایش دهد. کلمه table_name هم به نام جدولی اشاره دارد که اکنون موجود است و ستون مورد بررسی، درون این جدول قرار دارد.
ترکیب دستور Distinct در SQL با عبارت های شرطی
در این بخش، به این مطلب خواهیم پرداخت که چگونه عبارتDISTINCT را با عبارتهای دیگری در زبان برنامهنویسی SQL ترکیب کنیم و برای هر کدام سینتکس مربوط به آن را برای روش اجرای عملیات نمایش خواهیم داد. در فهرست زیر چهار نوع از ترکیبات نمایش داده میشوند که میخواهیم آنها را بررسی کنیم.
- DISTINCT با WHERE
- DISTINCT با ORDER BY
- DISTINCT با GROUP BY
- DISTINCT با JOIN
چگونه عبارت DISTINCT را با WHERE ترکیب کنیم؟
عبارت دستوری DISTINCT میتواند با عبارت دستوری WHERE در SQL ترکیب شود تا مقادیر یکتا را با توجه به شرایط خاصی نمایش دهد. از این ترکیب دستوری زمانی استفاده کنید که میخواهید فهرستی از مقادیر یکتا را نمایش دهید که از معیارهای مشخصی پیروی میکنند.

برای مثال فرض کنیم که جدولی به نام «Invoices» برای ذخیره فاکتورهای فروش داریم. میخواهیم فهرست مجموع سفارشات غیرتکراری را از یک شهر مشخص در این جدول استخراج کنیم. ابتدا به نمونه کد توجه کنید تا در ادامه توضیحات بیشتری بدهیم.
در این نمونه کد اسم ستون مورد اشاره Total است. این جدول ستونی هم به نام BillingCity دارد که نام همه شهرهایی که برای آن شهر فاکتور تنظیم شده را ذخیره میکند. این کد از ستون Total همه مقادیر یکتا را نمایش میدهد به شرط اینکه در ستون BillingCity نام شهر Berlin باشد.
چگونه عبارت DISTINCT را با ORDER ترکیب کنیم؟
وقتی میخواهید که نتایج یکتای استخراج شده از کوئری را منظم کنید، میتوانید عبارت DISTINCT را بههمراه ORDER استفاده کنید. این ترکیب تضمین میکند که نتایج غیرتکراری، بهطوری که خواستهاید، با نظم و چیدمان مرتب نمایش داده شوند.
مثال بالا را گسترش میدهیم تا لیست مجموعه فاکتورهایی را که از شهر برلین میآیند منظم کنیم.
در این مثال، کوئری، مقادیر یکتایی را که از ستون Total واقع در جدول invoices با کد SELECT DISTINCT Total وFROM invoices استخراج میکند به شرط آنکه از شهر برلین آمده باشند -WHERE BillingCity = 'Berlin' - به ترتیب صعودی -از کم به زیاد- با کدORDER BY Total ASC; منظم میکند. برای ترتیب صعودی در آخر دستور ORDER از کلمه کلیدیASC استفاده میکنیم. درصورتی که از هیچ کلمه کلیدی استفاده نکنیم هم ساختار پیشفرض عبارت ORDER بر اساس حالت صعودی مرتبسازی میکند.
چگونه عبارت DISTINCT را با GROUP ترکیب کنیم؟
عبارت DISTINCT معمولا همراه دستور GROUP BY در SQL استفاده میشود تا درحالی که توابع با هم ترکیب میشوند، مقادیر یا ترکیبات یکتا از چندین ستون را برگرداند. به هرحال، وقتی که از عبارتGROUP BY استفاده میکنید، میتوان کلمه کلیدیDISTINCT را حذف کرد زیرا از قبل بهصورت پنهان وجود دارد. به مثال زیر توجه کنید.
در این مثال، کوئری، دادههای جدول invoices را طبق ستون BillingCity گروهبندی میکند. با کد GROUP BY BillingCity تعداد رخدادهای مقادیر یکتا را در ستون CustomerID میشمارد و به نام ستون TotalCustomers، با کد زیر نمایش میدهد.
SELECT BillingCity, COUNT(CustomerId) AS TotalCustomersدر نهایت هم مقادیر ستون TotalCustomers را در جدول موقتی نتایج به صورت نزولی -از زیاد به کم- با کد ORDER BY TotalCustomers DESC; نمایش میدهد. برای ترتیب نزولی در آخر دستور ORDER از کلمه کلیدیDESC استفاده میکنیم.

چگونه عبارت DISTINCT را با JOIN ترکیب کنیم؟
میتوانید عبارتهای DISTINCT و JOIN را باهم ترکیب کنید تا از چندین جدول که با شرایط خاصی به هم متصل شدهاند، مقادیر یکتا را استخراج کنید. این روش برای مواقعی استفاده میشود که میخواهید از رکوردهای تکراری دوری کنید که بر اثر اتصال جدولها به یکدیگر بهوجود میآیند. به نمونه کدی که در ادامه آوردهایم دقت کنید.
در این مثال، کوئری، با استفاده از کدSELECT DISTINCT t1.column1, t2.column2 مقادیر یکتایی را از ستون column1 در جدول table1 و ستون column2 در جدول table2<strong> </strong> واکشی میکند. به شرطی که ستون column3 در نقطه متناظر بین دادههای هر دو ستون قبلی همسان باشد. این شرط با کمک کدهای FROM table1 t1 وJOIN table2 t2 ON t1.column3 = t2.column3; بررسی میشود.
برطرف کردن مقادیر NULL به کمک دستور Distinct در SQL
در این بخش، به بررسی روش مدیریت مقادیر NULL به کمک دستور Distinct در SQL میپردازیم. برای این منظور به فرایندی ۲ مرحلهای خواهیم پرداخت که شامل پیداکردن مقادیر NULL در ابتدای کار و مدیریت مقادیر NULL در انتهای کار میشود.
مرحله اول، دستور Distinct و یافتن مقادیر NULL در نتیجه کوئری
زمانی که از کلمه کلیدی دستور Distinct در SQL استفاده میکنیم، مهم است بلد باشیم چگونه مقادیر NULL را مدیریت کنیم. هدف از دستور Distinct حذف کردن رکوردهای تکراری و برگشت دادن مقادیر یکتا در مجموعه نتایج کوئری است. اگرچه، وقتی نوبت به مقادیر NULL میرسد، دستور Distinct آنها را حذف نمیکند بلکه با آنها همانند مقادیر یکتا رفتار میکند.
به عنوان مثال، نمونه کد آمده از جدول فرضی در پایین را درنظر بگیرید.
با فرض اینکه در جدول مرجعی که کد بر روی آن اجرا شده مقدار NULL وجود داشته باشد، مجموعه نتیجه شامل مقدار تهی با نماد NaN، نیز خواهد بود. به تصویر زیر از خروجی فرضی کد بالا، نگاه کنید. این کد مقادیر تهی را هم برای ما پیدا میکند.

در تصویر بالا عبارت DISTINCT با مقادیر خالی با محتوای None ، NaN و null همانند مقداری یکتا رفتار کرده است و در ردیف با ایندکس 0 مقدار را NaN به نمایندگی از همه مقادیر تهی قرار داده است.
مرحله دوم، فیلتر کردن مقادیر NULL
هنگامی که از دستور Distinct در SQL استفاده میکنید، برای بیرون کردن مقادیر NULL از مجموعه نتیجه گرفته شده، میتوانید از عبارت WHERE به همرا عملگرNOT NULL استفاده کنید. مثال بالا را درنظر بگیرید و کوئری که در ادامه آمده را اجرا کنید تا مقادیر NULL را فیلتر کنید.
نباید در جدول نتیجه، مقادیر NULL به عنوان مقدار یکتار مانند تصویر زیر، ظاهر شوند.

موارد استفاده رایج از دستور Distinct در SQL
در این بخش از مطلب رایجترین موارد استفاده از دستور Distinct در SQL را خواهیم دید و با تماشای نمونه کدها، روش استفاده از این کلمه کلیدی را بررسی خواهیم کرد.
تجزیه و تحلیل و افزایش دقت در داده ها بر اساس مقادیر غیرتکراری
فرض کنید که قرار است تجزیه و تحلیل بسیار مهمی روی دادهها انجام دهیم و در طول فرایند این تحلیل، تمایل داریم دقت دادههای تا اینجای کار، تحلیل شده خود را بهدست آوریم. اجازه دهید بیان کنیم که میزان دقت در فرآیند تجزیه تحلیل وابسته به یکتا بودن ستون نامName در جدول دانشجوStudent است. پس ما برای اینکه متوجه شویم، دادههای ما از نظر دقت چقدر خوب هستند، باید از دستور Distinct در SQL به همراه عبارت SELECTاستفاده کنیم.

روش اول شمارش مقادیر منحصربهفرد در مقابل تمام مقادیر جدول است و اگر تعداد مقادیر منحصربهفرد از تعداد کل دادهها کمتر بود به این معنا است که چند رکورد تکراری در جدول حضور دارند که میتوانند نتایج تحلیل دادهها را تحت تاثیر قرار دهند.
با اجرا کردن اسکریپتی که در ادامه آمده، میتوان مطلب بیان شده در بالا را اثبات کرد.
خروجی کوئری داده شده در بالا بهصورت زیر میشود.
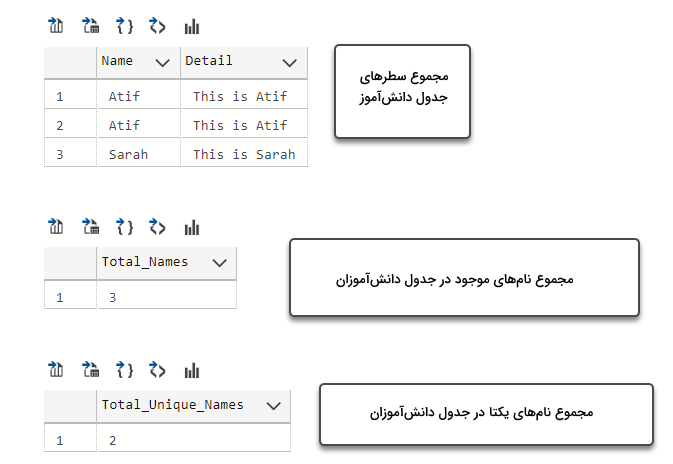
بهوضوح از خروجی کوئری مشخص است که نسبت به تعدادی که انتظار داریم -توقع ظاهر شدن ۳ عدد رکورد را داریم- تعداد نامهای منحصربهفرد کمتری، در واقع ۲ نام غیرتکراری، وجود دارند. اگر تصور کنیم این دادهای است که به اشتباه 2 بار در پایگاه داده ما درج شده پس حتما بر روی نتایج تحلیل ما تاثیر منفی خواهد داشت.
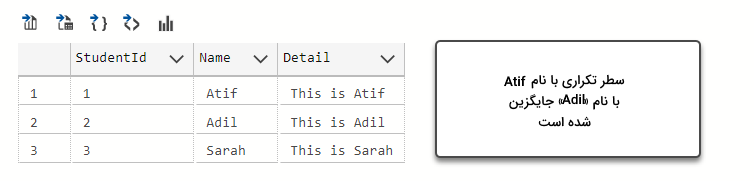
به همین شکل، میتوانیم از این اطلاعات برای حذف موارد تکراری استفاده کنیم. این کار به عنوان روشی برای افزایش کیفیت خروجی تجزیه و تحلیل دادهها درنظر گرفته میشود. اجازه دهید مشکل را با جایگذاری نام تکراری با نام دیگری حل کنیم تا مطمئن شویم که سه ردیف منحصربهفرد داریم و دیگر داده تکراری در جدولمان وجود ندارد.
در نهایت خروجی کد بالا به شکل زیر خواهد بود.
یافتن مراجع یکتای داده ها
میتوانیم از دستور Distinct در SQL به همرات عبارت SELECT برای یافتن مراجع یکتای دادهها استفاده کنیم. برای مثال، مجموعه نتایجی داریم که ردیفهای مختلف جدول را نمایش میدهد و هر ردیف شامل ستونهایی میشود. پیش میآید که بعضی وقتها بیشتر علاقهمند به الگوهای یکتای دادهها هستیم تا خود دادهها، که یکی از موارد کلیدی در تجزیه و تحلیل جستوجوگرانه است.
برای بررسی مثال بالا نیاز داریم که جدولهای Subject وStudentSubject را به وسیله اجرا کردن کد اسکریپت زیر ایجاد کنیم.
اجازه دهید الان بر روی جدولStudentSubject تمرکز کنیم. این جدول شامل رکورد همه دانشجویانی میشود که در مقابل درسهایشان، در امتحان نمره گرفتهاند.
بنابر این، در زیر موارد مورد علاقهمان را که در این سناریو دنبال خواهیم کرد، فهرست کردهایم.
- دانشجویان
- دروس
- نمرات کسب شده
لطفا توجه کنید که دانشجویان از قبل در جدول مرجعی به نام Student تعریف شدهاند و به همان شکل، جدول مرجعی نیز برای دروس به نامSubject از قبل آماده داریم. اکنون با توجه به جداول مرجع، میتوانیم بگوییم دانشجویانی که در جدول StudentSubject ظاهر شدهاند در واقع از جدول مرجع خودشان نشأت گرفتهاند.
در ابتدای کار اسکریپت زیر را اجرا میکنیم تا دادههای جدول StudentSubject را ببینیم.
خروجی کد اسکریپت بالا به شکل زیر میشود.

به هرحال، علاقهمند به قسمت نسبتا متفاوتی از اطلاعات هستیم که به آن با عنوان یافتن مراجع یکتا یا الگوهای منحصر بفرد داده اشاره کردهایم. یعنی میخواهیم بدانیم، چه تعداد نمره منحصربهفرد توسط دانشآموزان گرفته شده است که به ما الگوی منحصربهفردی از نمرات کسب شده را میهد.
این موضوع را به کمک عبارت دستوری SELECT Distinct در SQL بهصورتی که در ادامه آمده است باید کشف کنیم.
خروجی کوئری بالا بهصورت آمده در زیر نمایشداده میشود.

این اطلاعات نه تنها به ما میگویند دانشجویان عملکرد عالیی دارند بلکه همچنین میفهمیم که ستون نمرات از الگوی یکتایی از 70، 80 و 90 پیروی میکند. سپس میتوانیم از این الگو برای ساخت جدول دیگری به نام الگوی نمرات یکتا یاUnique_Marks_Pattern استفاده کنیم و سپس در این اطلاعات بیشتر کندوکاو کنیم.

حالت دادن به داده ها به وسیله چندین ستون یکتا در مخزن داده
این مورد سناریو کمیاب و نادری است که البته پیش میآید و قدرت فوق العادهی دستور Distinct در SQL را وقتی همراه با SELECT میآید نشان میدهد که اسکریپت نوشته شده را برای رسیدن به هدف تغییر میدهد.
فهم مسئله
خود را به عنوان توسعه دهنده SQL/BI فرض کنید که درحال کار بر روی «منطق اسکلتبندی داده» (Staging Data Logic) هستید. منطق استیجینگ داده به این معنا است که بهطور مثال شما درحال ساخت اسکریپتهای SQL هستید تا با موفقیت دادهها را از منابع مختلف به مخزن داده خود واکشی کنید بهصورتی که همان اول کار در یک محیط اسکلتبندی شده یا سازماندهی شده بارگزاری شده باشند. این کار برای استفاده بهعنوان راه حلهایی که در مسائل مربوط به «انبار داده» (Data Warehouse) در بحث «هوش تجاری» (Business Intelligence) پیش میآیند، بسیار رایج و متداول است.
مسئله این است که نیاز دارید دادهها را از جدولی با چندین ستون یکتا فراخوانی کنید اما طبق رفتار استاندارد، نمیتوانید روی جداول استیجینگ محدودیتهای یکتا تعریف کنید، زیرا آنها باید از هر محدودیتی رها باشند تا بطور مستقیم دادهها را انتقال دهند.
استیج کردن: به کشیدن گزینش شده اطلاعات از مخازن داده برای ارائه به کاربر و آراستن آنها به نوعی که برای هدف کاربر مناسب باشد، چه هدف تجزیه و تحلیل داده باشد و چه نمایش آن، استیج کردن در پایگاه داده میگویند.
فرایند حل مسئله
در ادامه با اجرای اسکریپت زیر، به بررسی این مسئله خواهیم پرداخت. در کوئری زیر به اضافه کردن سطرها یا ردیفهای بیشتر به جدولStudentSubject با درسهای موجود برای دانشجویان یکسان، پرداختهایم.
بعد نوبت به دیدن دادههای جدولStudentSubjectمیرسد.
نتایج این کوئری در تصویر زیر نمایشداده شده است.
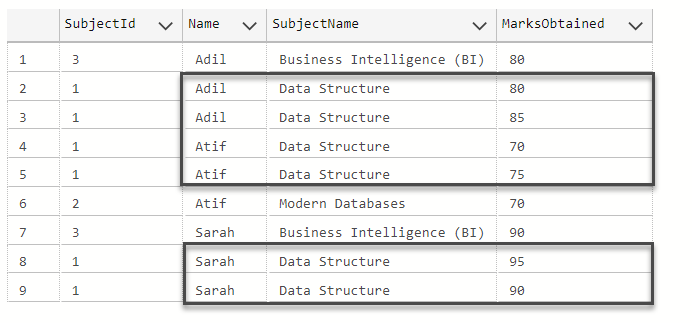
اکنون فقط خواهان استیج کردن دانشجویان و درسهایشان بدون درنظر گرفتن نمرههای کسب شده، از این جدول هستیم. پس یک همچین کوئری سادهای گزینههای تکراری را هم برمیگرداند. همانطور که در ادامه آمده است.
کوئری بالا بهصورتی که در زیر آمده است خروجی میدهد.

به هرحال، نیاز به نوشتن کد کوئری خاصی برای استیج کردن داریم تا فقط آن دو دانشجو و درسهای منحصربهفرد را برای نمایش از جدول بیرون بکشیم و این کار به وسیله عبارت دستوری SELECT Distinct در SQL ممکن میشود.
مجموعه نتایج این اسکریپت، بهصورتی که در زیر نمایشداده شده است.

بالاخره، همانطور که در ادامه میبینید، میتوانیم با استفاده از دستور Distinct در SQL، ستون Id را برای استیج کردن ایجاد کنیم تا در پردازشهای بعدی استفاده شود.
نتایج این اسکریپ بهصورتی که در زیر میبینید حاصل میشوند.

سوالات متداول
سوالات پرتکراری که قبلا پرسیده شدهاند و احتمال دارد برای شما هم هنگام کار با دستور Distinct در SQL پیش آیند، در این بخش بررسی میکنیم.
تفاوت بین دستورهای DISTINCT و UNIQUE در SQL چیست؟
دستور DISTINCT در SQL، در عبارت SELECT استفاده میشود تا سطرهای تکراری را از مجموعه نتیجه کوئری حذف کند و فقط مقادیر یکتا را نمایش دهد. کلمه کلیدی UNIQUE به محدودیت اعمال شده به هر ستون در جدول میگویند که باعث شود تمام مقادیر آن ستون در بین تمام ردیفهای جدول به صورت یکتا و غیر قابل تکرار باشند.

دستور Distinct در SQL با مقادیر NULL چه طور برخورد می کند؟
وقتی که از کلمه کلیدی DISTINCT استفاده میکنید، مقادیر خالی نسبت به سایر مقادیر و یکدیگر به عنوان یک مقدار مجزا درنظر گرفته میشوند. بنابراین، اگر در ستونی که انتخاب شده چندین مقدار NULL وجود داشته باشد، دستور DISTINCT فقط یک NULL را برمیگرداند.
جمع بندی
دستور Distinct در SQL، ابزار غیر قابل جایگزینی برای انجام عملیات کارآمد بازیابی و تجزیه و تحلیل اطلاعات است. همانطوری که در این راهنما دیدید، به راحتی به کوئریهای SQL افزوده میشود و بهمیزان زیادی کار کردن با اطلاعات تکراری را در پایگاه دادههای بزرگ آسان میکند.

با استفاده از DISTINCT ، میتوانید دادههای مازاد تکراری را حذف و روی مقادیر یکتایی تمرکز کنید که به تجزیه و تحلیلتان مرتبط هستند. همچنین، به کمک ترکیب هوشمندانه دستور Distinct با عبارتهای مربوط به فیلترکردن، مرتب کردن و گروهبندی کردن، میتوانید نتایج کوئریهای خود را بسیار خوب تنظیم کنید تا بهطور دقیق شامل اطلاعات منحصربهفردی باشد که نیاز دارید.
با بهکارگیری دقیق عبارت SELECT DISTINCTدر کوئریهایی که بهطور صحیحی ساخته شدهاند، میتوانید پایگاه داده درون سازمانتان را به طرز کارآمد و سادهای مدیریت کنید.










