



۱۹ الگوریتم هوش مصنوعی که باید بدانید – به زبان ساده
در دنیای امروز، کمتر کسی را میتوان یافت که با اصطلاح «هوش مصنوعی» (Artificial Intelligence | AI) آشنایی نداشته باشد. همه ما درباره این شاخه از فناوری اطلاعات مطالب و مقالات خبری مختلفی خواندهایم یا دستکم با دیدن فیلمهای علمی تخیلی پیرامون این حوزه، با ابزارها و سیستمهای هوش مصنوعی آشنا شدهایم. سیستمهای هوشمند بر پایه یک سری روشها و الگوریتم های هوش مصنوعی به یادگیری مسائل مختلف میپردازند و بهصورت خودکار وظایفی را انجام میدهند. در مطلب حاضر از مجله فرادرس به توضیح ۱۹ الگوریتم هوش مصنوعی میپردازیم و ویژگیها و کاربردهای آنها را بررسی خواهیم کرد.
- یاد میگیرید الگوریتمهای اصلی هوش مصنوعی به چه دستههایی تقسیم میشوند.
- میآموزید هر نوع یادگیری مانند با نظارت، بدون نظارت و تقویتی چه مفهوم و کارکردی دارد.
- خواهید آموخت که برای هر مسئله، چه الگوریتمی مناسبتر است.
- مزایا و محدودیتهای هریک از الگوریتمهای رایج AI را میآموزید.
- یاد خواهید گرفت داده و ویژگیهای آن چگونه روی خروجی مدل اثر میگذارند.
- یاد میگیرید هوش مصنوعی چه نقشی در تحول کاربردهایی مانند پزشکی، مالی و حملونقل دارد.




در این مطلب ابتدا توضیح کوتاهی در رابطه با هوش مصنوعی بیان میکنیم و نحوه کارکرد هوش مصنوعی را یاد میگیریم. سپس، چهار دسته کلی الگوریتمهای هوش مصنوعی ازجمله الگوریتم نظارت شده، نظارت نشده، یادگیری تقویتی و الگوریتم جستجوی هوش مصنوعی را بیان میکنیم. در انتها نیز مزایا و معایب الگوریتمها و کاربرد آنها را نیز بیان میکنیم. پس اگر میخواهید با الگوریتمهای هوش مصنوعی آشنا شوید، تا انتهای این مطلب با مجله فرادرس همراه باشید.
توضیح مختصری پیرامون هوش مصنوعی
با نگاهی به تاریخچه هوش مصنوعی و پژوهشهای آن میتوان گفت هوش مصنوعی شاخهای از علوم کامپیوتر است که با استفاده از روشها و الگوریتمهای ارائه شده در این حیطه، میتوان سیستمها، ماشینهای سختافزاری و برنامههای نرمافزاری هوشمندی را طراحی کرد که میتوانند وظایف مختلفی را بهطور خودکار یاد بگیرند و در انجام امور و تصمیمگیری پیرامون موضوعات مختلف به انسان کمک کنند. به عبارتی، میتوان گفت سیستمهای سختافزاری و نرمافزاری هوشمند به این هدف ساخته شدهاند که بدون نیاز به دخالت انسان، مسئولیتی را مشابه انسان یا بهتر از انسان انجام دهند.
سیستمهای هوشمند بر اساس یک سری الگوریتم هوش مصنوعی و دادههای آموزشی به یادگیری مسائل مختلف میپردازند. چندین نوع الگوریتم هوش مصنوعی وجود دارد که با توجه به نوع مسئله، ویژگیهای الگوریتم هوش مصنوعی، نوع داده آموزشی و سایر نیازمندیهای کاربران، میتوان یکی از الگوریتم های هوش مصنوعی را برای طراحی و ساخت سیستم هوشمند استفاده کرد. در ادامه مطلب، به این موضوع میپردازیم که الگوریتم هوش مصنوعی چیست و روال کار آن به چه شکل است. سپس، بر اساس یک دستهبندی جامع، رویکردهای یادگیری الگوریتم های هوش مصنوعی را بررسی خواهیم کرد.

الگوریتم هوش مصنوعی چیست؟
در علوم کامپیوتر و ریاضیات به مجموعهای از دستورالعملهای محاسباتی و عملیاتی به منظور رسیدن به هدفی خاص، الگوریتم گفته میشود. اگر بخواهیم این تعریف را در حیطه هوش مصنوعی به کار ببریم، میتوانیم بگوییم که الگوریتم هوش مصنوعی فرآیندی است که برای کامپیوتر مشخص میکند چگونه عملیاتی خاص را بهطور خودکار یاد بگیرد. به بیان دیگر میتوان گفت هوش مصنوعی شامل مجموعهای از الگوریتمها است و فرآیند یادگیری آنها بسیار پیچیدهتر از فرآیند یادگیری انسان است.
الگوریتمهایی که توسط انسان نوشته میشوند و جزء الگوریتم های هوش مصنوعی نیستند، برای حل مسائل ساده به کار میروند. برنامه نویس مراحل مختلف عملیاتی یک الگوریتم را از ابتدا تا انتها با مجموعهای از دستورات تعریف میکند. این نوع الگوریتمها، معمولاً دادههای مشخص و سادهای را دریافت میکنند و پس از اعمال یک سری محاسبات از پیش تعریف شده توسط برنامه نویس، خروجی را تولید میکنند. به عبارتی، این نوع الگوریتمها، مسئله را یاد نمیگیرند و فقط با دریافت دادههای ورودی، بر اساس یک سری قواعد از پیش تعریف شده، مقدار خروجی را محاسبه میکنند.
الگوریتم های هوش مصنوعی در مقایسه با الگوریتمهای معمولی، پیچیدهتر هستند و روال یادگیری آنها بهطور خودکار انجام میشود. الگوریتم هوش مصنوعی بر اساس آزمون و خطا، مسئله خاصی را یاد میگیرد و عملکرد خود را برای حل مسئله بهطور خودکار بهتر میکند. به بیان دقیقتر میتوان گفت برنامه نویس در یادگیری الگوریتم های هوش مصنوعی نقشی ندارد و این الگوریتمها قادر هستند دادههای ورودی متنوعی را دریافت کنند و با انجام یک سری عملیات محاسباتی پیچیده، درباره خروجی تصمیم بگیرند.
الگوریتم هوش مصنوعی چگونه کار می کند؟
الگوریتم های هوش مصنوعی عملکرد پیچیدهتری نسبت به سایر الگوریتمها دارند. الگوریتم هوش مصنوعی با دریافت دادههای آموزشی از ورودی، مسئلهای خاص را یاد میگیرد. دادههای آموزشی الگوریتم های هوش مصنوعی میتوانند توسط برنامه نویس به صورتهای مختلف آماده شوند یا الگوریتم هوش مصنوعی از محیط اطراف خود، دادههای آموزشی مورد نیاز را دریافت کند. پس از دریافت دادههای آموزشی، الگوریتم های هوش مصنوعی از ویژگیها و تشخیص الگوهای موجود در آنها به منظور یادگیری مسئله تعریف شده استفاده میکنند.
در بخش بعدی مطلب حاضر، به معرفی انواع الگوریتم های هوش مصنوعی میپردازیم و ویژگیهای آنها را بررسی میکنیم.
انواع الگوریتم های هوش مصنوعی چیست ؟
بر اساس نحوه یادگیری الگوریتم های هوش مصنوعی و نوع دادههای آموزشی آنها، میتوان چهار دسته کلی برای رویکردهای یادگیری الگوریتم های هوش مصنوعی در نظر گرفت:
- الگوریتمهای «یادگیری نظارت شده» (Supervised Learning)
- الگوریتمهای «یادگیری نظارت نشده» (Unsupervised Learning)
- الگوریتم «یادگیری تقویتی» (Reinforcement Learning)
- الگوریتمهای جستجوی هوش مصنوعی
در ادامه مطلب، به توضیح دستهبندیهای ذکر شده در بالا میپردازیم و برای هر یک از آنها، پرکاربردترین الگوریتم های هوش مصنوعی را معرفی میکنیم.
الگوریتم های یادگیری با نظارت
الگوریتم های یادگیری نظارت شده یا الگوریتمهای با نظارت برای یادگیری مسائل، نیاز به دادههای آموزشی برچسبدار دارند. برچسبهای دادهها به عنوان اطلاعات اضافی برای یادگیری و بهبود عملکرد الگوریتم استفاده میشوند. دو نوع مسئله را میتوان با الگوریتم های هوش مصنوعی از نوع نظارت شده حل کرد:
- مسائل «دستهبندی» (Classification): در این نوع مسائل به دنبال دستهبندی دادهها در دستههای از پیش مشخص شده هستیم. به عنوان مثال، میتوان به مسئله تشخیص ایمیلهای «هرزنامه» یا اسپم (Spam) اشاره کرد. در این نوع مسئله میتوان ایمیلها را بر اساس محتویاتشان، به دو دسته هرزنامه و غیر هرزنامه گروهبندی کرد.
- مسائل «رگرسیون» (Regression): مقدار خروجی این نوع از الگوریتمها محدود به مقادیر خاصی (نظیر مسئله دستهبندی) نیست و الگوریتم های هوش مصنوعی رگرسیون میتوانند مقادیر مختلفی را با توجه به ورودی تولید کنند. در این نوع مسائل معمولاً متغیرهایی از نوع وابسته و مستقل داریم و الگوریتم با توجه به مقادیر متغیرهای مستقل، باید مقدار متغیر وابسته را پیشبینی کند. مسئلهای نظیر تخمین قیمت مسکن را درنظر بگیرید. در این مسئله، میتوان قیمت خانه (متغیر وابسته) را بر اساس ویژگیهای مختلفی (متغیرهای مستقل) نظیر متراژ خانه، تعداد اتاقها، پارکینگ و مواردی از این قبیل پیشبینی کرد.

برخی از رایجترین و پرکاربردیترین الگوریتم های یادگیری ماشین که برای مسائل دستهبندی و رگرسیون استفاده میشوند، در ادامه فهرست شدهاند:
- الگوریتم هوش مصنوعی «درخت تصمیم» (Decision Tree)
- الگوریتم «ماشین بردار پشتیبان» (Support Vector Machine)
- مدل «بیز ساده» (Naive Bayes)
- مدل«رگرسیون لاجستیک» (Logistic Regression)
- الگوریتم «رگرسیون خطی» (Linear Regression)
در ادامه، به توضیح مختصری پیرامون هر یک از الگوریتمهای ذکر شده در فهرست بالا میپردازیم.
۱. الگوریتم هوش مصنوعی درخت تصمیم
درخت تصمیم به عنوان یکی از پرکاربردترین الگوریتم های هوش مصنوعی محسوب میشود. نام این الگوریتم برگرفته از ساختار آن است که شباهت به درخت دارد. دادههای آموزشی در ریشه درخت تصمیم قرار میگیرند و هر یک از «گرههای» (Nodes) درخت ویژگیهایی هستند که دادههای آموزشی بر اساس آنها سنجیده میشوند. به گرهای که زیرشاخه نداشته باشد، «برگ» (Leaf) گفته میشود.
میتوان از درخت تصمیم به منظور دستهبندی دادهها استفاده کرد. دادهها بر اساس ویژگیهای تعریف شده در هر گره در دستههای متفاوت قرار میگیرند تا جایی که دیگر نتوان آنها را در دستههای جداگانه قرار داد.

همچنین، درنظر گرفتن یک حد آستانه برای تفکیک دادهها یا رسیدن به گرههای برگ نیز میتوانند شرایطی برای اتمام دستهبندی دادهها درنظر گرفته شوند.
۲. الگوریتم هوش مصنوعی ماشین بردار پشتیبان
ماشین بردار پشتیبان به عنوان یکی دیگر از الگوریتم های یادگیری ماشین با رویکرد یادگیری نظارت شده تلقی میشود که در هر دو مسئله دستهبندی و رگرسیون کاربرد دارد اما از آن بیشتر در حل مسائل دستهبندی استفاده میشود.
این مدل به دنبال پیدا کردن «ابَر صفحهای» (Hyperplane) است که دادههایی با ویژگی مشابه را از دادههای غیرمشابه تفکیک کند. موقعیت این ابر صفحه باید به گونهای باشد که بیشترین فاصله را بین دستهها ایجاد کند. در فضای دو بعدی که دادهها از دو بعد تشکیل شدهاند، میتوان ابر صفحه را به شکل خط نشان داد. برای تفکیک دستهها نیز میتوان از بیش از یک ابر صفحه استفاده کرد.

۳. الگوریتم بیز ساده
از دیگر الگوریتم های هوش مصنوعی پرکاربرد، میتوان به مدل نایو بیز یا بیز ساده اشاره کرد. این مدل، یک الگوریتم احتمالاتی است که احتمال رخداد یک رویداد را بر اساس نظریه بیز محاسبه میکند.
مهمترین فرضیهای که این مدل در مورد دادهها در نظر میگیرد، این است که ویژگیها مستقل از یکدیگر هستند و با تغییر مقادیر ویژگیها، تاثیری بر روی سایر مقادیر حاصل نمیشود. به عبارتی، از این فرضیه برای ساده کردن روال یادگیری الگوریتم استفاده میشود.
۴. الگوریتم لاجستیک رگرسیون
الگوریتم لاجستیک رگرسیون به عنوان یکی از الگوریتم های هوش مصنوعی محسوب میشود که از آن میتوان برای دستهبندی دادهها در دو کلاس استفاده کرد. در این مدل، از تابع غیر خطی برای تبدیل مقدار خروجی در بازه صفر تا یک استفاده میشود و منحنی تابع رگرسیون لجستیک مشابه حرف S است که پس از تغییر مقدار خروجی به بازه صفر تا یک، مقدار ۰٫۵ مرز بین دو کلاس را مشخص میکند.

به منظور گرفتن نتیجه بهتر از این الگوریتم بهتر است ویژگیهای غیرمرتبط را از دادههای آموزشی مدل حذف کنید تا مدل، رابطه بین دادههای ورودی و مقدار خروجی را بهتر یاد بگیرد.
۵. مدل رگرسیون خطی
رگرسیون خطی به عنوان یکی از الگوریتم های یادگیری ماشین با رویکرد یادگیری نظارت شده محسوب میشود که رابطه بین متغیر ورودی (متغیر مستقل) و مقدار خروجی (متغیر وابسته) را با تعیین یک خط در فضای مختصات مشخص میکند. از این الگوریتم برای مسائل رگرسیون نظیر پیشبینی قیمت مسکن استفاده میشود.

این الگوریتم هوش مصنوعی به دنبال پیدا کردن بهترین خطی است که بتواند موقعیت قرارگیری دادهها را در فضای مختصات یاد بگیرد و بر اساس ویژگیهای دادههای آموزشی، درباره دادههای جدید تصمیمگیری کند.

مزایای الگوریتم های هوش مصنوعی با نظارت
هر یک از الگوریتم های هوش مصنوعی با نظارت، دارای مزایای منحصربفردی هستند. با این حال میتوان مزیتهای همگانی این دسته از الگوریتمها را در فهرست زیر خلاصه کرد:
- این نوع الگوریتمها به دادههای برچسبدار نیاز دارند و برچسب آنها را به عنوان معیار اصلی برای سنجش عملکرد خود درنظر میگیرند. بدین ترتیب، روشهای با نظارت در راستای رسیدن به هدف (تشخیص صحیح برچسب دادهها) عملکرد خود را بهبود میدهند.
- درک فرآیند یادگیری و عملکرد الگوریتم های هوش مصنوعی با نظارت ساده است. در الگوریتمهای بدون نظارت، بهسادگی نمیتوان عملکرد درون مدل و نحوه یادگیری آن را درک کرد.
- پیش از آموزش مدل، دقیقاً تعداد کلاسهای مسئله مشخص است.
- پس از اتمام آموزش الگوریتم های هوش مصنوعی با نظارت، نیازی به نگهداری دادههای آموزشی درون حافظه نیست.
- الگوریتم های هوش مصنوعی با نظارت، عملکرد بسیار خوبی در مسائل دستهبندی دارند.
معایب الگوریتم های هوش مصنوعی با نظارت
علاوهبر مزیتهای مهمی که الگوریتم های هوش مصنوعی با نظارت دارند، میتوان برای آنها معایبی را نیز به صورت زیر برشمرد:
- الگوریتم های هوش مصنوعی با نظارت درباره دادههای جدیدی که شباهتی با دادههای آموزشی ندارند، اطلاعات درستی ارائه نمیکنند. به عنوان مثال، فرض کنید مدلی را برای دستهبندی دادهها پیادهسازی کردید که دادههای آموزشی آن شامل تصاویر حیوانات سگ و گربه بود. در زمان استفاده از این دستهبند، چنانچه تصویری از زرافه را به عنوان ورودی به مدل بدهیم، مدل برچسب درستی برای این تصویر ارائه نخواهد داد.
- برای آموزش الگوریتم های هوش مصنوعی با نظارت، لازم است که برای هر دسته، دادههای آموزشی جامعی فراهم کنیم تا دقت مدل در زمان تست مورد قبول باشد.
- چنانچه حجم دادههای آموزشی برای مدلهای هوش مصنوعی با نظارت بسیار زیاد باشد، میزان بار محاسباتی برای آموزش مدل زیاد خواهد بود.
- چنانچه حجم دادههای آموزشی این مدلها بسیار کم باشد و نتوان دادههای آموزشی مناسبی برای یادگیری آنها آماده کنیم، عملکرد مدلها نیز به مراتب ضعیفتر خواهد بود.
الگوریتم های یادگیری بدون نظارت
در مقایسه با الگوریتم های یادگیری با نظارت، دادههای ورودی الگوریتم های یادگیری بدون نظارت، برچسب ندارند و این نوع الگوریتمها بر اساس بررسی میزان شباهت دادهها به یکدیگر، آنها را در «خوشههای» (Clusters) مجزا قرار میدهند به گونهای که دادههای درون یک خوشه، بیشترین شباهت را به یکدیگر دارند و نسبت به دادههای سایر خوشهها بسیار متفاوت باشند.
از دیگر کاربردهای رویکرد یادگیری بدون نظارت، کاهش ابعاد دادهها است که از آن برای جلوگیری از «بیش برازش» (Overfitting) استفاده میشود. الگوریتمهای مختلفی برای «خوشهبندی» (Clustering) و کاهش بعد وجود دارند که در ادامه به پرکابردیترین آنها اشاره شده است:
- الگوریتم خوشهبندی «K میانگین» (K-means)
- الگوریتم خوشهبندی «آمیخته گاوسی» (Gaussian Mixture)
- الگوریتم کاهش بعد «تحلیل مولفه اساسی» (Principal Component Analysis | PCA)
- مدل کاهش بعد «تجزیه مقادیر منفرد» (Singular Value Decomposition | SVD)
- مدل کاهش ابعاد «خودرمزگذار» (Autoencoders)
در ادامه، به توضیحی پیرامون الگوریتم های هوش مصنوعی ذکر شده در بالا میپردازیم و نحوه یادگیری آنها را شرح میدهیم.
۶. الگوریتم خوشه بندی K میانگین
به عنوان یکی از الگوریتم های هوش مصنوعی با رویکرد بدون نظارت، میتوان به مدل K میانگین اشاره کرد. برای کار با این الگوریتم، باید تعداد خوشههای دادهها را از قبل تعریف کنیم تا مدل بر اساس آن، دستهها را در خوشههای مجزا قرار دهد. فرض کنید برنامه نویس برای عدد K مقدار ۳ را تعریف میکند. بدین ترتیب، الگوریتم K میانگین به دنبال قرار دادن دادهها در سه خوشه مجزا است.

به این منظور، الگوریتم K-means در ابتدا سه داده را به عنوان مرکز خوشهها درنظر میگیرد. سپس، فاصله سایر دادهها را نسبت به این سه داده (مراکز خوشهها) میسنجد و بر اساس فاصله مشخص میکند کدام داده در کدام خوشه قرار گیرد. پس از تعیین خوشههای دادهها، مجدد مراکز خوشهها محاسبه میشوند و دادهها نسبت به خوشههای جدید، تفکیک میشوند. این روال آنقدر ادامه پیدا میکند تا مراکز خوشهها تغییر زیادی نداشته باشند.

۷. الگوریتم خوشه بندی آمیخته گاوسی
روال یادگیری الگوریتم خوشهبندی آمیخته گاوسی مشابه با الگوریتم K میانگین است. هر دوی این الگوریتمها به دنبال این هستند تا دادههای مشابه را در خوشههای یکسان قرار دهند. با این حال تفاوتی که این دو الگوریتم با یکدیگر دارند، در محدوده تقسیمبندی خوشهها است. خوشههای تشکیل شده توسط الگوریتم K میانگین به شکل دایرهای هستند در حالی که خوشههای حاصل شده از الگوریتم آمیخته گاوسی به شکل مستطیل است. الگوریتم آمیخته گاوسی به دلیل نحوه خوشهبندی دادهها در فضای مستطیل شکل، عملکرد دقیقتر و بهتری نسبت به الگوریتم K میانگین دارد.
۸. الگوریتم هوش مصنوعی تحلیل مولفه های اساسی
یکی از کاربردهای الگوریتم های هوش مصنوعی بدون نظارت، کاهش ابعاد دادهها و فشردهسازی دادهها با ابعاد بالا است. در این روش، از مبدلهای خطی به منظور بازنمایی دادههای جدید استفاده میشود. این الگوریتم بر پایه دو مولفه اصلی کار میکند. اولین مولفه باعث میشود مقدار واریانس دادهها به حداکثر برسد و دومین مولفه بیشترین میزان واریانس دادهها را پیدا میکند.

۹. الگوریتم تجزیه مقادیر منفرد
روش تجزیه مقادیر منفرد از دیگر الگوریتم های هوش مصنوعی بدون نظارت است که از آن نیز به منظور کاهش ابعاد دادهها استفاده میشود.

در این روش، ماتریس اولیه دادهها به سه ماتریس مجزا با رنک پایین تبدیل میشوند و میتوان از ماتریسهای حاصل شده در محاسبات بعدی خود استفاده کرد.
۱۰. الگوریتم هوش مصنوعی خودرمزگذار
به غیر از روشهای یادگیری ماشین، میتوان از شبکههای عصبی و الگوریتم های یادگیری عمیق به منظور کاهش ابعاد دادهها با رویکرد یادگیری بدون نظارت استفاده کرد. یکی از انواع شبکه های عصبی مصنوعی که بدین منظور استفاده میشود، الگوریتم خودرمزگذار است.
این مدل، از سه بخش اصلی تشکیل شده است:
- بخش«رمزگذار» (Encoder): بخش رمزگذار، دادهها را از ورودی دریافت و آنها را فشرده میکند. این عملیات فشردهسازی به نحوی انجام میشود که بتوان داده فشرده شده را در بخش رمزگشا به حالت اولیه خود بازگرداند.
- بخش «کد» (Code): به داده فشرده توسط بخش رمزگذار، کد گفته میشود که ورودی بخش رمزگشا است.
- بخش «رمزگشا» (Decoder): بخش رمزگشا کد دریافت شده را رمزگشایی میکند تا داده اصلی بازگردانده شود.

چنانچه نیاز به دادههایی با ابعاد پایین داشته باشید، میتوانید دادههای آموزشی خود را به مدل خودرمزگذار بدهید و در نهایت از بخش کد این مدل برای مسئله خود استفاده کنید.
مزایای الگوریتم های هوش مصنوعی بدون نظارت
برخی از مهمترین مزیتهای الگوریتم های هوش مصنوعی بدون نظارت را میتوان در فهرست زیر ارائه کرد:
- الگوریتمهای هوش مصنوعی بدون نظارت میتوانند ویژگیهایی از دادهها را تشخیص بدهند که برای انسان به وضوح مشخص نباشند.
- از آنجایی که این نوع الگوریتمها نیازی به دادههای برچسبدار ندارند، زمان آمادهسازی مدل و استفاده از آن به مراتب کاهش پیدا میکند.
- این نوع الگوریتمها در مقایسه با الگوریتم های هوش مصنوعی با نظارت از محاسبات کمتری برخوردار هستند.
معایب الگوریتم های هوش مصنوعی بدون نظارت
الگوریتم های هوش مصنوعی بدون نظارت دارای معایبی نیز هستند که در ادامه به آنها اشاره میشود:
- از آنجایی که هیچ گونه برچسبی برای دادههای آموزشی به عنوان معیار سنجش عملکرد مدل وجود ندارد، نمیتوان با قطعیت گفت که خروجی الگوریتم های هوش مصنوعی بدون نظارت کاملاً صحیح هستند.
- درک عملکرد این نوع الگوریتمها سختتر از الگوریتم های هوش مصنوعی با نظارت است و در هنگام استفاده از آنها، نیاز به فرد متخصصی داریم تا بتواند الگوها و روابط بین دادهها را تشخیص دهد تا خوشهبندی حاصل شده، قابل درک باشند.
- خروجی الگوریتمهای بدون نظارت بستگی زیادی به مدل دارند و ممکن است با تغییر مدل یا پارامترهای آن، تفاوت فاحشی در خروجیها حاصل شود.
الگوریتم یادگیری تقویتی
سومین رویکرد یادگیری الگوریتم های هوش مصنوعی، رویکرد یادگیری تقویتی است که «عامل هوشمند» (Intelligent Agent) بر اساس بازخوردهایی که از محیط پیرامون خود دریافت میکند، نحوه حل مسئله را یاد میگیرد و سعی دارد با دریافت اطلاعات از اطراف خود، عملکردها و اقدامات خود را بهبود دهد.
در این روش از یادگیری، در ابتدای کار هیچ داده آموزشی برای مدل وجود ندارد و الگوریتم صرفاً با اطلاعاتی که از کنش و واکنش به دست میآورد، مسائل را یاد میگیرد. الگوریتم هوش مصنوعی تقویتی از چهار مفهوم اصلی تشکیل شده است:
- عامل هوشمند: عامل هوشمند اقداماتی را انجام میدهد و از محیط بازخوردهایی (اطلاعاتی) دریافت میکند.
- محیط: محیطی است که عامل درون آن اقداماتی را انجام میدهد.
- پاداش: امتیازی است که نشان میدهد عملکرد الگوریتم در یک محیط تعریف شده چقدر است.
- سیاست یا خط مشیء (Policy): هدف الگوریتم تقویتی یادگیری سیاستی است که بر اساس آن تصمیم بگیرد در هر گام چه اقدامی را انجام دهد تا در نهایت به بیشترین پاداش برسد.
برای درک بهتر الگوریتم هوش مصنوعی تقویتی، میتوان از یک مثال ساده بهره گرفت. فرض کنید قصد دارید با استفاده از روش یادگیری تقویتی، محیطی را شبیهسازی کنید که در آن به آموزش و تربیت یک سگ بپردازید. برای آموزش سگ میتوانید از یک سری پاداش و تنبیه نیز استفاده کنید. چنانچه سگ مطابق درخواست شما رفتار کرد، به آن پاداش دهید و اگر رفتار مورد انتظار شما را نداشت، برای آن تنبیهی در نظر بگیرید. در این مثال، سگ به عنوان عامل هوشمند تعریف میشود که باید بهترین عملکرد را داشته باشد تا به بیشترین میزان پاداش برسد.

الگوریتم های هوش مصنوعی یادگیری تقویتی را میتوان بر اساس سیاست (Policy) به دو دسته کلی زیر تقسیم کرد:
- مدلهای یادگیری تقویتی «مبتنی بر محیط» (Model-based): در مدلهای مبتنی بر محیط، عامل هوشمند سعی دارد محیط پیرامون خود را درک کند و مدلی را بر پایه کنش خود و واکنش محیط بسازد. به بیان دیگر میتوان گفت اگر عامل هوشمند بتواند پاداش هر کنش خود را پیش از انجام آن، پیشبینی کند، از روش یادگیری تفویتی مبتنی بر محیط تبعیت میکند. الگوریتم «موقعیت-کنش-پاداش-موقعیت-کنش» یا سارسا (State-action-reward-state-action | SARSA) به عنوان یکی از مهمترین الگوریتمهای مبتنی بر محیط محسوب میشود.
- مدلهای یادگیری تقویتی «مستقل از محیط» (Model-free): در الگوریتمهای یادگیری تقویتی مستقل از محیط، عامل هوشمند بر اساس نتایجی که از کنشهای خود میگیرد، سیاست (Policy) را یاد میگیرد. به عبارتی، عامل هوشمند در الگوریتمهای تقویتی مستقل از محیط باید کنشی را انجام دهد تا واکنش محیط را دریافت کند و بر اساس آن، یادگیری را پیش ببرد. بدینترتیب، چنین عاملی در این روش از یادگیری، قادر به پیشبینی پاداش کنش خود نیست. یکی از شناختهشدهترین الگوریتمهای یادگیری تقویتی مستقل از محیط، روش Q-Learning است.
در ادامه مطلب حاضر از مجله فرادرس، به توضیح دو الگوریتم یادگیری تقویتی Q-Learning و SARSA میپردازیم.
۱۱. الگوریتم یادگیری تقویتی Q-Learning
الگوریتم Q-Learning بر پایه یک جدول جستجو تعریف میشود که این جدول، جدول Q نام دارد. سطرهای جدول Q وضعیت هر «موقعیت | وضعیت» (State) عامل را نشان میدهد و ستونهای این جدول نشاندهنده اقداماتی است که عامل هوشمند میتواند انجام دهد. مقادیر اولیه این جدول را میتوان با عدد صفر مقداردهی کرد. با انجام هر کنش عامل هوشمند و دریافت واکنش از محیط، مقادیر خانههای جدول Q بهروزرسانی میشوند و این تغییرات و روال یادگیری الگوریتم تا زمانی اتفاق میافتند که مقادیر جدول Q تغییر زیادی نداشته باشند.

پس از مرحله یادگیری، مدل در هر موقعیتی در محیط قرار بگیرد، کنشی را انجام میدهد که به موقعیتی با بیشترین مقدار Q منتقل شود. فرض کنید بر اساس تصویر زیر، سه کنش Aِِ ،B و C پیش روی عامل هوشمند است که با انتخاب کنش A مقدار Q برابر ۳ را دریافت میکند. با انتخاب کنشهای B و C نیز مقادیر Qهای حاصل شده بهترتیب برابر با ۳ و ۷ خواهند بود. از آنجا که الگوریتم Q-Learning مبتنی بر روش حریصانه عمل میکند، کنش C را انجام میدهد تا بالاترین مقدار Q را به دست آورد.

الگوریتم Q-Learning از معادله «بلمن» (Bellman) به منظور بهروزرسانی مقادیر Q در زمان یادگیری مدل استفاده میکند. این معادله را در تصویر زیر ملاحظه میکنید:
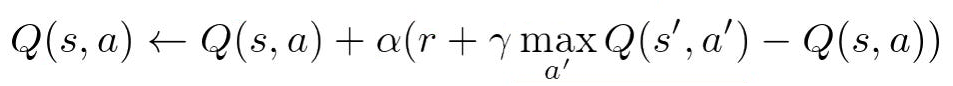
این فرمول دارای پارامترهای مختلفی است که در ادامه به توضیح آنها میپردازیم:
- پارامتر s: وضعیت فعلی عامل هوشمند را مشخص میکند.
- پارامتر a: کنش انتخابی عامل را مشخص میکند.
- پارامتر α: «نرخ یادگیری» (Learning Rate) مدل است. چنانچه مقدار این پارامتر بزرگ باشد، مقدار بهروزرسانی مقادیر Q زیاد خواهد بود. مقدار این پارمتر، عددی بین صفر تا یک است.
- پارامتر ɣ: «ضریب تخفیف» (Discount Factor) است که مشخص میکند عامل هوشمند بر روی راهحل طولانی برای رسیدن به هدف تمرکز کند یا به دنبال راهحلهای کوتاه باشد.
- پارامتر 's: وضعیت بعدی عامل را پس از انجام کنش مشخص میکند.
- پارامتر 'a: کنش بعدی عامل را در وضعیت 's مشخص میکند.
- پارامتر r: پاداش دریافتی به ازای کنش انتخابی است.
بر اساس فرمول بلمن، عامل هوشمند برای انتخاب بهترین کنش در وضعیت s، نه تنها پاداش مرحله فعلی را مد نظر قرار میدهد، بلکه برای ادامه مسیر، کنشی (a) را انتخاب میکند که مقدار Q حاصل شده در وضعیت بعدی (یعنی در وضعیت 's) با انجام کنش 'a بیشترین مقدار را داشته باشد.
۱۲. الگوریتم یادگیری تقویتی SARSA
الگوریتم سارسا یکی از الگوریتم های هوش مصنوعی محسوب میشود که هدف آن یادگیری سیاست روال تصمیمگیری مارکوف است. در این الگوریتم، در موقعیت فعلی (s)، کنشی (a) انجام میشود و به ازای آن کنش، به عامل پاداشی (r) تخصیص داده شده و موقعیت عامل به 's تغییر پیدا میکند و در این موقعیت جدید، باید کنشی ('a) را انجام دهد.
روال یادگیری الگوریتم سارسا با روال یادگیری روش Q-Learning اندکی متفاوت است. در روش یادگیری سارسا، برای تمام کنشهایی (a) که در موقعیت جاری (s) میتوان انجام داد، درصدی از احتمال لحاظ میشود، درحالیکه در روش یادگیری تقویتی Q-Learning، عامل هوشمند صرفاً کنشی را انتخاب میکرد که بیشترین مقدار Q را در پی داشته باشد. در ادامه، فرمول بهروزرسانی مقادیر Q را برای الگوریتم سارسا ملاحظه میکنید.
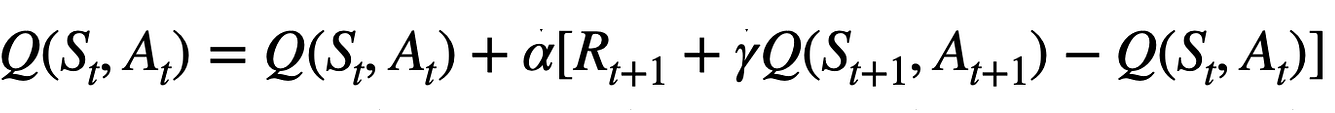
مزایای الگوریتم یادگیری تقویتی
رویکرد یادگیری تقویتی دارای مزیتهای منحصربفردی است که میتوان آنها را در فهرست زیر خلاصه کرد:
- از الگوریتم یادگیری تقویتی میتوان در حل مسائل پیچیدهای بهره برد که از سایر روشهای هوش مصنوعی نتوان برای آنها استفاده کرد.
- روال یادگیری این نوع الگوریتمها، مشابه با یادگیری انسان است. بدینترتیب، میتوان انتظار داشت که به عملکرد بسیار خوبی در حل مسائل برسند.
- مدلهای یادگیری تقویتی میتوانند خطاهای خود را در حین یادگیری اصلاح کنند.
- زمانی که مدل در حین یادگیری، خطای خود را تشخیص میدهد و آن را اصطلاح میکند، احتمال رخداد خطای مشابه توسط مدل در آینده بسیار پایین خواهد بود.
- الگوریتم یادگیری تقویتی در حوزه رباتیک و طراحی ربات کاربرد بسیار دارد.
- این نوع الگوریتم نیازی به آمادهسازی دادههای آموزشی برای یادگیری ندارد.
معایب الگوریتم یادگیری تقویتی
علاوهبر نقاط قوت الگوریتم یادگیری تقویتی، میتوان نقاط ضعفی را نیز برای آن برشمرد که به برخی از مهمترین آنها در ادامه میپردازیم:
- از یادگیری تقویتی بهتر است در حل مسائل ساده استفاده نشود زیرا یادگیری این نوع الگوریتمها بهتدریج انجام میشود و برای یک مسئله ساده نیازی نیست زمان زیادی را صرف آموزش چنین مدلهایی کنیم.
- مدلهای یادگیری تقویتی از زنجیره و فرآیند مارکوف (Markovian) تبعیت میکنند که در آن احتمال رخداد هر رویداد صرفاً به وقوع رویداد پیش از آن وابسته است. این فرضیه در دنیای واقعی صادق نیست.
- برای حل بسیاری از مسائل یادگیری تقویتی، باید این روش را با سایر روشها نظیر یادگیری عمیق ترکیب کرد تا به نتایج خیلی خوبی دست پیدا کنیم.
- یادگیری تقویتی به زمان زیادی برای یادگیری کامل یه مسئله نیاز دارد و حجم زیادی از محاسبات و دادههای دریافتی از محیط لازم است تا عملکرد چنین مدلهایی به میزان چشمگیری بالا روند.
الگوریتم های جستجوی هوش مصنوعی
الگوریتمهای جستجو یکی دیگر از مهمترین مباحث رشته هوش مصنوعی محسوب میشوند که شامل روشهای حل مسئله هستند. در الگوریتمهای جستجو، یک «عامل عاقل» (Rational Agent) یا «عامل حل مسئله» (Problem-solving Agents) وجود دارد که به دنبال پیدا کردن بهترین مسیر برای رسیدن به هدف است.
در مباحث مربوط به الگوریتمهای جستجو، از چندین اصطلاح استفاده میشود که در ادامه به آنها اشاره شده است:
- جستجو: به روال مرحله به مرحله برای حل مسئله در یک فضای جستجو، عمل جستجو گفته میشود. مسئله جستجو داری سه عنصر اصلی است:
- فضای جستجو: فضای جستجو شامل مجموعهای از راهحلهایی است که عامل هوشمند باید از میان آنها بهترین پاسخ را انتخاب کند.
- وضعیت شروع: وضعیت ابتدایی، حالتی است که عامل از آن نقطه جستجو را شروع میکند.
- سنجش هدف: تابعی است که وضعیت فعلی را بررسی میکند تا مشخص شود آیا به وضعیت نهایی رسیدهایم یا باید روال جستجو را ادامه دهیم؟
- درخت جستجو: مسائلی که با استفاده از الگوریتمهای جستجوی هوش مصنوعی قابل حل هستند، در قالب درخت بازنمایی میشوند. ریشه درخت، به عنوان وضعیت شروع برای جستجو محسوب میشود.
- اقدامات: مجموعهای از اقداماتی است که عامل هوشمند میتواند در هنگام جستجو انجام دهد.
- تابع انتقال: تابعی است که نتیجه هر اقدام عامل هوشمند را مشخص میکند.
- هزینه مسیر: تابعی است که به هر مسیر در فضای جستجو، هزینهای را تخصیص میدهد.
- راهحل: مجموعهای از اقدامات است که عامل هوشمند را از وضعیت شروع به وضعیت پایانی (هدف) میرساند.
- راهحل بهینه: راهحلی است که کمترین هزینه مسیر را دارد.
بر اساس مسائلی که با الگوریتمهای جستجوی هوش مصنوعی قابل حل هستند، میتوان این روشهای جستجو رو به دو دسته کلی زیر تقسیم کرد:
- «جستجوی آگاهانه» (Informed Search)
- الگوریتم «جستجوی اول بهترین» (Best First Search)
- الگوریتم جستجوی A*
- «جستجوی ناآگاهانه» (Uniformed | Blind Search)
- الگوریتم «جستجوی اول سطح» (Breadth First Search | BFS)
- الگوریتم «جستجوی اول عمق» (Depth First Search | DFS)
- الگوریتم «جستجو با هزینه یکنواخت» (Uniform Cost Search)
- الگوریتم «جستجو با عمق محدود» (Depth Limited Search)
- الگوریتم «جستجوی دوطرفه» (Bidirectional Search)
در ادامه، به توضیح مختصری پیرامون هر یک از الگوریتمهای جستجوی هوش مصنوعی میپردازیم.

روش های جستجوی آگاهانه
الگوریتمهای جستجوی آگاهانه از دانش مسئله برای پیدا کردن بهترین راهحل استفاده میکنند. به عبارتی، این اطلاعات اضافی نه تنها به پیدا کردن راهحل کمک میکنند، بلکه تضمین میدهند بهینهترین پاسخ از میان فضای جستجو انتخاب شود. در ادامه مطلب، به توضیح دو تا از معروفترین روشهای جستجوی آگاهانه، یعنی الگوریتم اول بهترین و الگوریتم A* میپردازیم.
۱۳. الگوریتم اول بهترین
الگوریتم اول بهترین یکی از روشهای جستجوی آگاهانه است که هر سطر از درخت را برای رسیدن به هدف بررسی میکند. در هر سطر گرهای انتخاب میشود که کمترین هزینه را داشته باشد. این الگوریتم تضمین میدهد اگر راهحلی برای مسئله وجود داشته باشد، مسیری با کمترین هزینه را برای آن پیدا میکند.
۱۴. الگوریتم A*
الگوریتم A* نیز به عنوان یکی دیگر از الگوریتمهای حریصانه محسوب میشود. این روش جستجو بهترین مسیر راهحل را با توجه به کوتاهترین مسیر طی شده پیدا میکند. الگوریتم حریصانه A* به اطلاعات طول مسیر و وزنهای گرههای درخت احتیاج دارد تا با توجه به آنها بهینهترین مسیر را انتخاب کند.
مزایای الگوریتم های جستجوی آگاهانه
روش جستجوی آگاهانه نقاط قوتی دارند که در ادامه به آنها میپردازیم:
- الگوریتمهای جستجوی آگاهانه از دانش بیشتری نسبت به مسئله برخوردار هستند و با بهرهگیری از آنها میتوانند به پاسخ بهینه مسئله برسند.
- عملکرد این الگوریتمها در یافتن پاسخ مسئله سریع است.
- این الگوریتمها تضمین میدهند که پاسخ مسئله را پیدا کنند.
- پیادهسازی الگوریتمهای جستجوی آگاهانه ساده است.
معایب الگوریتم های جستجوی آگاهانه
معایب اصلی الگوریتمهای جستجوی هوش مصنوعی آگاهانه را میتوان به شکل زیر برشمرد:
- با این که الگوریتمهای جستجوی آگاهانه با عنوان الگوریتمهای حریصانه شناخته میشوند، ممکن است در برخی شرایط کوتاهترین مسیر را برای رسیدن به هدف پیدا نکنند.
- الگوریتم جستجوی آگاهانه نظیر A* به میزانی از حافظه برای نگهداری گرههای تولید شده نیاز دارد. هرچقدر میزان دادههای (گرهها) مسئله بیشتر شود، حجم حافظه مصرفی به مراتب بیشتر خواهد شد.
روش های جستجوی غیرآگاهانه
در روشهای جستجوی غیرآگاهانه هیچ گونه دانشی پیرامون موقعیت هدف و میزان فاصله نزدیکی نسبت به هدف نداریم. دانش این نوع الگوریتمها به نحوه جستجوی درخت و تشخیص برگ و گره هدف محدود میشود.

این نوع روشهای جستجو با رسیدن به هر گره بررسی میکنند که آیا به پاسخ مسئله رسیدهاند یا باید جستجوی خود را ادامه دهند. در ادامه به توضیح انواع روشهای جستجوی غیرآگاهانه میپردازیم.
۱۵. الگوریتم جستجوی اول سطح
الگوریتم BFS یکی از روشهای جستجوی ناآگاهانه است که برای یافتن مقداری خاص در یک درخت یا گراف استفاده میشود. روند جستجوی الگوریتم اول سطح از گره ریشه درخت یا گراف آغاز میشود و الگوریتم، سطر به سطر گرهها را به ترتیب بررسی میکند. جستجو در سطح بعدی این ساختار دادهها ادامه پیدا میکند. با کمک این الگوریتم میتوان بدون گیر افتادن در یک حلقه بیپایان، هر گره را بررسی کرد.
۱۶. الگوریتم جستجوی اول عمق
الگوریتم جستجوی اول عمق نیز همانند الگوریتم BFS یک روش جستجوی ناآگاهانه است با این تفاوت که این روش، جستجوی درخت را به صورت عمقی پیش میبرد. روند جستجو از گره ریشه درخت یا گراف شروع میشود و الگوریتم گرههای یک شاخه از درخت را تا برگ بررسی میکند تا به گره هدف برسد.

۱۷. الگوریتم جستجو با هزینه یکنواخت
الگوریتم جستجو با هزینه یکنواخت به دنبال پیدا کردن کمهزینهترین مسیر برای رسیدن به پاسخ مسئله است. در این روش، هر گره درخت، هزینه مصرف شده از ریشه تا گره فعلی را در خود نگه میدارد و اگر بخواهیم گره جدیدی را گسترش دهیم، گره ای از درخت انتخاب میشود که کمهزینهترین گره در میان گرههای گسترش نیافته را داشته باشد.
۱۸. الگوریتم جستجو با عمق محدود
الگوریتم جستجو با عمق محدود نسخه تغییر یافتهای از الگوریتم جستجوی اول عمیق است. یکی از معایب روش جستجوی اول عمیق این است که اگر عمق درخت بینهایت یا بسیار طولانی باشد، ممکن است مدت زمان بسیار زیادی طول بکشد تا الگوریتم به پاسخ مسئله برسد یا کلاً راهحلی برای مسئله پیدا نکند.
در این شرایط، روش جستجو با عمق محدود میتواند عملکرد بهتری داشته باشد. روال جستجوی این الگوریتم، مشابه با روش DFS است و فقط محدودیتی برای تعداد گرههای قابل جستجو در عمق ایجاد میکند تا الگوریتم در حین جستجو، بیشتر از میزان عمق تعیین شده پیش نرود.
۱۹. الگوریتم جستجوی دو طرفه
الگوریتم جستجوی دو طرفه با استفاده از روش جستجوی BFS از نقطه شروع و نقطه هدف درخت یا گراف بهطور همزمان شروع به بررسی گرهها میکند تا کوتاهترین مسیر اتصال نقطه شروع و مقدار هدف را پیدا کند. اولین نقطه اتصالی هر دو مسیر، پاسخ این الگوریتم خواهد بود.

مزایای الگوریتم های جستجوی ناآگاهانه
در بخش پیشین از مطلب حاضر مجله فرادرس، به توضیح الگوریتمهای جستجوی ناآگاهانه هوش مصنوعی پرداختیم. در ادامه، مزایای مهم این نوع الگوریتمها را شرح میدهیم.
- چنانچه تعداد گرههای درخت خیلی زیاد نباشند، الگوریتمهای جستجوی ناآگاهانه میتوانند خیلی سریع پاسخ مسئله را پیدا کنند.
- الگوریتمهایی نظیر روشهای جستجوی دو طرفه به گونهای طراحی شدهاند که میتواند در سریعترین زمان و با حداقل میزان حافظه به پاسخ برسند.
- الگوریتمهای جستجوی دو طرفه و جستجو با عمق محدود به لحاظ میزان مصرف حافظه، بهینه هستند.
معایب الگوریتم های جستجوی ناآگاهانه
معایب اصلی روشهای هوشمند جسنجوی ناآگاهانه را میتوان به شرح زیر خلاصه کرد:
- برخی از روشهای جستجوی ناآگاهانه نظیر BFS و DFS برای انجام جستجو باید مقادیر گرهها را در حافظه نگهداری کنند. هر چقدر تعداد گرههای درخت زیاد باشد، میزان حجم مورد نیاز حافظه بیشتر میشود.
- در الگوریتمهای جستجوی ناآگاهانهای که وزنی برای یالها یا گرهها وجود ندارد، هزینه تمامی مسیرها یکسان درنظر گرفته میشوند و اولویتی برای انتخاب مسیری خاص وجود ندارد. همین مسئله ممکن است به طولانی شدن زمان جستجوی الگوریتم برای رسیدن به پاسخ منجر شود.
- احتمال گیر کردن در حلقه بینهایت جستجو برای این نوع از الگوریتمها وجود دارد.
- این نوع الگوریتمها اطلاعات اضافی درباره مسئله ندارند و به همین خاطر ممکن است به پاسخ بهینه مسئله نرسند.
- روشهای جستجوی ناآگاهانه در مقایسه با روشهای جستجوی آگاهانه، کندتر هستند.

کاربرد الگوریتم های هوش مصنوعی
دامنه کاربرد الگوریتمها و روشهای هوش مصنوعی بسیار گسترده است و میتوان گفت امروزه دستاوردهای این حوزه از فناوری اطلاعات در تمامی جنبههای زندگی بشر دیده میشود. یکی از اصلیترین حوزههایی که با پژوهشهای هوش مصنوعی دستخوش تغییر و تحولات بسیاری شده، حوزه پزشکی و درمانی است. الگوریتم های هوش مصنوعی به کار رفته در مسائل «داده کاوی» (Data Mining) برای تشخیص بیماریهای خطرناک نظیر سرطان، در کاهش میزان مرگ و میر افراد تاثیر بهسزایی دارند. همچنین، از روشهای هوش مصنوعی در پژوهشهای گسترده داروسازی و انجام عملهای جراحی به وفور استفاده میشوند.
از دیگر حوزههایی که میتوان کاربرد روشهای هوش مصنوعی را در آن ملاحظه کرد، حیطه تولید مواد غذایی و آمادهسازی سفارشات مشتریان است. بسیاری از رستورانها با استفاده از چت بات هوش مصنوعی سفارشات مشتریان را دریافت میکنند و در برخی از رستورانها و کافیشاپها از رباتهای هوشمند به منظور سرو سفارشات مشتریان استفاده میشود.
بانکداری و مدیریت امور مالی را نیز میتوان از دیگر حوزههایی برشمرد که از هوش مصنوعی بهره زیادی برده است. از ابزارهای هوشمند برای پردازش امور بانکی استفاده میشود که میتوانند در کسری از ثانیه، محاسبات حجیمی را انجام دهند. بهعلاوه، تشخیص فعالیتهای مشکوک بانکی نیز توسط سیستمهای مجهز به هوش مصنوعی سادهتر از قبل شده و همین امر نقش چشمگیری در کاهش میزان کلاهبرداریهای مالی داشته است.
با پیشرفت پژوهشها در طراحی و ساخت ماشینهای هوشمند، شاهد تحول عظیمی در صنعت حمل و نقل هستیم. اتومبیلهای خودران Tesla و Volvo نمونهای از آخرین دستاوردهای هوش مصنوعی در این حوزه هستند.
الگوریتم های هوش مصنوعی تحولات عظیمی را نیز در امور فراغت افراد به وجود آوردهاند. افراد میتوانند با بهرهگیری از ابزارهای «پردازش زبان طبیعی» (Natural Language Processing | NLP) بهراحتی زیرنویس زبان مادری خود را برای فیلمهای مختلف جهان تولید کنند. همچنین، افراد میتوانند از انجام بازیهای جذاب طراحی شده توسط هوش مصنوعی لذت ببرند.
رسانههای اجتماعی نیز از دیگر حوزههایی است که تحت تاثیر هوش مصنوعی قرار گرفته است و افراد بهسادگی میتوانند انواع مختلفی از محتوا نظیر متن، صوت، تصویر و ویدئو را در فضای اینترنت تولید کنند.
تولیدات، صادرات و واردات محصولات، آموزش، مد و کسب و کار از دیگر بخشهای مهمی هستند که بدون استفاده از هوش مصنوعی عملکرد خوبی را در دنیای امروز نخواهند داشت و افراد فعال در این حوزهها به منظور پیشرفت در کار خود باید به استفاده از پیشرفتهترین سیستمهای هوشمند روی آورند.
بهطور خلاصه میتوان گفت حوزه نوین هوش مصنوعی تاثیرات مثبتی را بهطور کلی برای زندگی بشر به همراه داشته و میزان رفاه زندگی انسان را نسبت به گذشته افزایش داده است. با این حال، نمیتوان از خطرات احتمالی این شاخه از فناوری را نادیده گرفت و باید با دقت بیشتری آینده هوش مصنوعی را بررسی کنیم و تا بتوان از اثرات زیانبار آن پیشگیری کرد.
جمعبندی
تاثیرات چمشگیر هوش مصنوعی در دنیای امروز بر هیچ کس پنهان نیست و میتوان گفت بدون استفاده از دستاوردهای این حوزه، با چالشها و سختیهای مختلفی مواجه میشویم. سیستمهای هوشمند بر پایه الگوریتمهای مختلف، یاد میگیرند چطور مسائل را حل کنند. بر اساس ویژگیهای هر یک از الگوریتمها و دادهها و نوع مسئله، برنامه نویس تصمیم میگیرد مناسبترین روش را انتخاب کند. در این مطلب از مجله فرادرس سعی داشتیم به این پرسش پاسخ دهیم الگوریتم هوش مصنوعی چیست و بر چه اساسی کار میکند. سپس، به معرفی انواع الگوریتم های هوش مصنوعی پرداختیم و کاربرد هر یک از آنها و مزایا و معایبشان را شرح دادیم.









در عمل آیا از ترکیب بعضی یا همه ی روشهای فوق استفاده می شود یا نه ؟
با سلام و وقت بخیر خدمت شما همراه گرامی؛
بله، در بسیاری از پروژههای واقعی هوش مصنوعی از ترکیب چند روش و الگوریتم مختلف استفاده میشود. هر الگوریتم نقاط قوت و محدودیتهای خاص خود را دارد. به همین دلیل، توسعهدهندگان بسته به نوع مسئله، چند تکنیک را در کنار هم به کار میبرند. با این روش، نتایج دقیقتری بدست میآید. برای مثال، ممکن است در سیستمی ابتدا از روشهای پردازش داده برای آمادهسازی اطلاعات استفاده شود. سپس مدل یادگیری ماشین دادهها را تحلیل کند. در مرحله بعد از آن هم، الگوریتم دیگری وظیفه تصمیمگیری یا بهینهسازی را انجام دهد.
در نتیجه، در کاربردهای عملی، استفاده ترکیبی از روشها بسیار رایجتر از استفاده از یک الگوریتم کاملاً مستقل است.
با آرزوی موفقیت برای شما و سپاس از همراهیتان با مجله فرادرس
ممنون از توضیحاتتون. مختصر، مفید، کاربردی