



شبکه LVQ در پایتون – از صفر تا صد
در «علوم کامپیوتر» (Computer Science)، روشهای «رقمی ساز بردار یادگیر» (Learning Vector Quantization | LVQ) که به اختصار، به آنها شبکه LVQ نیز گفته میشود، خانوادهای از الگوریتمهای «دستهبندی نظارت شده مبتنی بر الگو» (Prototype-based Supervised Classification) هستند. شبکه LVQ، نقطه مقابل سیستمهای «رقمیسازی بردار» (Vector Quantization) است.



شبکه LVQ را میتوان به عنوان مورد خاصی از «شبکه عصبی مصنوعی» (Artificial Neural Network) تصور کرد. شبکه LVQ، از رویکرد «همه مال برنده» (Winner-Take-All) و مبتنی بر «یادگیری هبین» (Hebbian Learning) یا «یادگیری انجمنی» (Associate Learning) برای آموزش شبکه و دستهبندی دادهها استفاده میکند. روش شبکه LVQ، ارتباط نزدیک و تنگاتنگی با نوع خاصی از شبکههای عصبی به نام «نگاشتهای خود سازمانده» (Self-Organizing Maps) دارد. همچنین، این دسته از روشهای دستهبندی نظارت شده، شباهت معناداری به یکی دیگر از روشهای «یادگیری ماشین» (Machine Learning) به نام «K-نزدیکترین همسایه» (K-Nearest Neighbor) دارد. شبکه LVQ، توسط دانشمندی به نام «تئو کوهنن» (Tuevo Kohonen) ابداع شده است.
یکی از معایب مهم روش K-نزدیکترین همسایه این است که برای تضمین عملکرد بهینه الگوریتم یادگیری، نیاز است تا تمامی نمونههای آموزشی موجود در «مجموعه داده آموزش» (Training Dataset)، در اختیار این مدل یادگیری قرار گرفته شده باشند. الگوریتم شبکه LVQ، یک مدل شبکه عصبی مصنوعی است که به سیستم اجازه میدهد تا تعداد و مدل بردارهای (الگوهای) دستهبندی کننده داده را (الگوییهایی که جهت دستهبندی بهینه دادهها، باید در اختیار مدل یادگیری قرار گرفته شده باشند)، یاد بگیرد.

در این مطلب، مبحث شبکه LVQ و ساختار آن در دستهبندی نمونههای آموزشی مورد بحث قرار میگیرد. به عبارت دیگر، در این مطلب قرار است موضوعات مرتبط با تعریف، پیادهسازی و استفاده از شبکه LVQ جهت دستهبندی دادهها شرح داده شود:
- مقدمهای از شبکه LVQ و ویژگیهای آن.
- مدل نمایشی از دادهها که در شبکه LVQ مورد استفاده قرار میگیرد.
- سازوکاری که از طریق آن میتوان با استفاده از یک شبکه LVQ آموزش داده شده، به انجام پیشبینی در مورد دادههای تست مبادرت ورزید.
- چگونگی فرایند آموزش در این دسته از سیستمهای یادگیری ماشین و نحوه یادگیری یک مدل شبکه LVQ از روی دادههای آموزشی.
- برخی از روشهای ارائه شده جهت «آمادهسازی دادهها» (Data Preparation) با هدف ارتقاء عملکرد شبکه LVQ در دستهبندی دادهها.
- نحوه پیادهسازی شبکه LVQ در پایتون.
شبکه LVQ
شبکه LVQ که مخفف عبارت Learning Vector Quantization است، یکی از الگوریتمهای یادگیری ماشین به شمار میآید که در خانواده مدلهای شبکه عصبی مصنوعی و «محاسبات عصبی» (Neural Computation) طبقهبندی میشود؛ در یک طبقهبندی گستردهتر، شبکه LVQ زیر مجموعهای از خانواده روشهای «هوش محاسباتی» (Computational Intelligence) محسوب میشود.
شبکه LVQ، یک شبکه عصبی نظارت شده است که از استراتژی «یادگیری رقابتی» (Competitive Learning) و به طور ویژه، رویکرد «همه مال برنده» (Winner-Take-All) برای یادگیری و دستهبندی دادهها استفاده میکند. از این جهت، شبکه LVQ، به دیگر مدلهای شبکه عصبی مصنوعی نظیر «پرسپترون» (Perceptron) و الگوریتم «پس انتشار» (BackPropagation) مرتبط است. همچنین، شبکه LVQ ارتباط معناداری با برخی دیگر از شبکههای عصبی مبتنی بر یادگیری رقابتی، نظیر الگوریتم نگاشتهای خود سازمانده (Self-Organizing Maps | SOM) دارد.
الگوریتمهای نگاشتهای خود سازمانده، دسته ای از روشهای «یادگیری نظارت نشده» (Unsupervised Learning) هستند که از مدلسازی ارتباط میان «نرونهای» (Neurons) تعریف شده در یک شبکه، جهت «خوشهبندی» (Clustering) دادهها استفاده میکنند. شایان توجه است که شبکه LVQ یک الگوریتم «مبنا» (Baseline) برای خانواده الگوریتمهای LVQ محسوب میشود؛ تاکنون انواع مختلفی از شبکه LVQ نظیر LVQ1 ،LVQ2 ،LVQ3 ،OLVQ1 و OLVQ2 برای دستهبندی دادهها معرفی شدهاند.
همانطور که پیش از این نیز اشاره شد، شبکه LVQ ارتباط معناداری با دیگر شبکههای عصبی مبتنی بر یادگیری رقابتی نظیر الگوریتم نگاشتهای خود سازمانده (Self-Organizing Maps | SOM) دارد. الگوریتم نگاشتهای خود سازمانده (SOM) نیز به نوبه خود از قابلیتهای «خود سازماندهی» (Self-Organizing) نرونها در سیستم «کورتکس بصری» (Visual Cortex) مغز انسان الهام گرفته شده است.

استراتژی شبکه LVQ در دستهبندی دادهها به زبان ساده
شبکه LVQ و استراتژی «پردازش اطلاعات» (Information Processing) تعبیه شده در این روش یادگیری به گونهای توسعه داده شده است که ابتدا مجموعهای از بردارهای «رمزنگار» (Codebook) یا «الگو» (Prototype) را در دامنه ورودیهای «مشاهده شده» (Observed) مشخص میکند. در مرحله بعد، از بردارهای رمزنگار جهت دستهبندی دادههای «دیده نشده» (Unseen) استفاده میشود.
برای پیادهسازی این استراتژی در شبکه LVQ، ابتدا مجموعهای اولیه و تصادفی از بردارها (بردارهای رمزنگار) آمادهسازی میشوند. سپس، شبکه LVQ این بردارها را در معرض نمونههای آموزشی قرار میدهد. در مرحله بعد، استراتژی همه مال برنده (Winner-Take-All) جهت دستهبندی نمونههای آموزشی به کار گرفته میشود؛ در این استراتژی، یک یا چند برداری که بیشترین شباهت را به به یک الگوی ورودی داشته باشند، انتخاب میشوند. مقادیر بردار انتخاب شده، به نحوی توسط شبکه LVQ، تغییر مییابند (بهروزرسانی) که این بردار به سمت الگوی ورودی حرکت داده شود. در برخی موارد نیز، در صورتی که الگوی ورودی و بردار انتخاب شده در یک کلاس یکسان دستهبندی نشوند، مقادیر بردار انتخاب شده به نحوی توسط شبکه LVQ بهروزرسانی میشوند (تغییر مییابند) که این بردار از الگوی ورودی فاصله بگیرد.
تکرار چنین فرایندی، سبب توزیع شدن بردارهای رمزنگار (بردارهایی که در مرحله آموزش، یا به سمت الگوهای ورودی حرکت میکنند و یا از آنها دور میشوند) در «فضای ورودی» (Input Space) میشود. در واقع، توزیع بردارهای رمزنگار در فضای ورودی مسأله، توزیع نمونههای موجود در «مجموعه داده تست» (Test Dataset) را برای سیستم «تقریب» (Approximate) میزند؛ اینکه تقریبهای تولید شده (در مرحله آموزش) تا چه حدی با توزیع واقعی دادههای تست مطابقت دارد، در مرحله تست و بر اساس معیارهای ارزیابی عملکرد سیستم مشخص میشود.

نمایش مدل شبکه LVQ
نمایش ایجاد شده از شبکه LVQ، بر اساس مجموعهای از بردارهای رمزنگار حاصل میشود. همانطور که پیش از این نیز اشاره شد، شبکه LVQ به عنوان یک الگوریتم دستهبندی (Classification) توسعه داده شده است و مورد استفاده قرار میگیرد. مدل دستهبندی شبکه LVQ، از الگوی «دستهبندی باینری» (Binary Classification) و الگوی «دستهبندی مسائل چند کلاسی» (Multi-Class Classification Problems) تبعیت میکند.
یک بردار رمزنگار، یک نمونه متشکل از «ویژگیهای عددی» (Numerical Features) است که مجموعه ویژگیهای آن با مجموعه ویژگیهای مدل شده در مجموعه داده آموزشی برابری میکند. همچنین، نوع «برچسب کلاسی» (Class Labels) این بردارها، از جنس برچسب کلاسی دادههای آموزشی است. به عنوان نمونه، در صورتی که مسأله دستهبندی موردنظر، یک مسأله دستهبندی باینری باشد، برچسبهای کلاسی بردارهای رمزنگار، همانند نمونههای آموزشی، صفر یا یک خواهد بود. علاوه بر این، در صورتی که مجموعه ویژگی دادههای آموزشی از سه ویژگی عددی طول، عرض و ارتفاع تشکیل شده باشد، ویژگیهای عددی بردارهای رمزنگار نیز از سه ویژگی طول، عرض و ارتفاع تشکیل خواهد شد.
بنابراین، مدل نمایشی شبکه LVQ از مجموعهای ثابت از بردارهای رمزنگار (CodeBook Vectors) تشکیل شده است که به وسیله آنها، رفتار دادههای آموزشی یاد گرفته میشود. بردارهای رمزنگار، از لحاظ ماهیتی، به نمونههای آموزشی شباهت دارند ولی مقدار هر یک از ویژگیهای عددی آنها، بر اساس روش یادگیری (روش آموزش) شبکه LVQ و بسته به دادههای آموزشی تغییر پیدا میکند (مقدار نهایی ویژگیهای عددی بردارهای رمزنگار، بر اساس مقادیر ویژگیهای عددی نمونههای مشابه یا نمونههای نزدیک به این بردار در فضای ورودی مسأله مشخص میشود).
در زبان شبکههای عصبی مصنوعی، هر یک از بردارهای رمزنگار (CodeBook Vectors) معادل یک «نرون» (Neuron) شناخته میشوند. همچنین، هر یک از ویژگیهای عددی موجود در یک بردار رمزنگار، معادل یک «وزن» (Weight) است و به مجموعه متشکل از تمامی بردارهای رمزنگار، شبکه (شبکه LVQ) گفته میشود.

پیشبینی با استفاده از شبکه LVQ
تولید پیشبینی در مدل یادگیری شبکه LVQ، با استفاده از بردارهای رمزنگار (CodeBook Vectors) انجام میشود. رویکرد تولید پیشبینی در شبکه LVQ تا حد بسیار زیادی به مدل تولید پیشبینی در الگوریتم K-نزدیکترین همسایه شباهت دارد. برای اینکه فرایند تولید پیشبینی برای یک نمونه جدید (نظیر ) انجام شود، ابتدا الگوریتم شبکه LVQ، مجموعه بردارهای رمزنگار را برای پیدا کردن K بردار رمزنگار مشابه (K بردار مشابه با نمونه ورودی جدید) جستجو میکند (برچسب کلاسی متناظر با K بردار رمزنگار یافت شده، برای پردازشهای آتی، در سیستم ذخیره میشود). شایان توجه است که فرایند تولید بردارهای رمزنگار اولیه، مقادیر ویژگیهای عددی آنها و مقادیر برچسب کلاسی این بردارها، کاملا تصادفی است.

معمولا برای تولید پیشبینی برای نمونهها، از مقدار K=1 استفاده میشود. به عبارت دیگر، الگوریتم شبکه LVQ، مجموعه بردارهای رمزنگار را برای پیدا کردن تنها یک بردار رمزنگار مشابه با نمونه ورودی جدید (مشابهترین بردار رمز نگار به نمونه جدید) جستجو میکند. بردار رمزنگار که بیشترین شباهت را به نمونه ورودی داشته باشد، «بهترین واحد تطبیق داده شده» (Best Matching Unit | BMU) نامیده میشود.
برای اینکه مشخص شود کدام k بردار رمزنگار، بیشترین شباهت را به نمونه ورودی جدید دارند، از یک «معیار محاسبه فاصله» (Distance Calculation Measure) استفاده میشود. برای بردارهای رمزنگار و نمونههایی که مقادیر ویژگیهای عددی آنها از نوع «مقادیر حقیقی» (Real Values) هستند، محبوبترین معیار محاسبه فاصله، «فاصله اقلیدسی» (Euclidean Distance) است. برای محاسبه فاصله اقلیدسی میان یک نمونه جدید () و یک بردار رمزنگار ()، از رابطه زیر استفاده میشود:
یادگیری یک مدل شبکه LVQ از روی دادههای آموزشی
همانطور که پیش از این نیز اشاره شد، بردارهای رمزنگار و مقادیر عددی ویژگیهای آنها، بر حسب دادههای آموزشی یاد گرفته میشوند. برای یادگیری یک مدل شبکه LVQ از روی دادههای آموزشی، ابتدا لازم است تا تعداد بردارهای رمزنگار مشخص شود (به عنوان نمونه، 20 تا 40 بردار میتواند برای این کار مناسب باشد). یک راه ممکن برای پیدا کردن تعداد بهینه بردارهای رمزنگار، انتخاب مقادیر مختلف برای این پارامتر (تنظیم دستی پارامتر) و آزمایش آن روی دادههای آموزشی است.
الگوریتم یادگیری مدل شبکه LVQ کار خود را با مجموعهای از بردارهای رمزنگار تصادفی آغاز میکند. برای تولید مجموعه بردارهای رمزنگار، این امکان وجود دارد که تعدادی از نمونههای موجود در دادههای آموزشی، به طور تصادفی، به عنوان بردار رمزنگار انتخاب شوند. با این حال، روش پیشفرض برای تولید بردارهای رمزنگار، ایجاد تصادفی بردارهایی است که تعداد ویژگیهای آنها، مقیاس (حد بالا و پایین) ویژگیهای آنها و نوع برچسب کلاسی آنها، متناظر با نمونههای موجود در دادههای آموزشی باشد.
در مرحله آموزش مدل شبکه LVQ، دادههای آموزشی یکی به یکی وارد سیستم یادگیری میشوند. به ازاء هر یک از نمونههای آموزشی که وارد سیستم میشود، مشابهترین بردار رمزنگار به این نمونه ورودی جدید (از میان مجموعه بردارهای رمزنگار) انتخاب میشود. در صورتی که برچسب کلاسی بردار رمزنگار با برچسب کلاسی نمونه ورودی به سیستم برابر باشد، بردار رمزنگار به سمت ورودی حرکت داده میشود تا به آن نزدیکتر شود. در صورتی که برچسب کلاسی بردار رمزنگار با برچسب کلاسی نمونه وارد شده به سیستم برابر نباشد، بردار رمزنگار به گونهای حرکت داده میشود که از این ورودی فاصله بگیرد.
میزان حرکت بردار رمزنگار در فضای ورودی مسأله، توسط پارامتری در الگوریتم به نام «نرخ یادگیری» (Learning Rate) تنظیم میشود. به عنوان نمونه، در صورتی که برچسب کلاسی یک بردار رمزنگار با برچسب کلاسی یک نمونه ورودی برابر باشد، ویژگی یا متغیر از این بردار رمزنگار (به مقداری که توسط پارامتر نرخ یادگیری کنترل میشود)، به سمت ویژگی یا متغیر در نمونه ورودی حرکت میکند تا به آن نزدیکتر شود. مقدار این حرکت از طریق رابطه زیر به دست میآید:
همچنین، در صورتی که برچسب کلاسی یک بردار رمزنگار با برچسب کلاسی یک نمونه ورودی برابر نباشد، ویژگی یا متغیر از این بردار رمزنگار (به مقداری که توسط پارامتر نرخ یادگیری کنترل میشود)، از ویژگی یا متغیر در نمونه ورودی فاصله میگیرد. مقدار این حرکت از طریق رابطه زیر به دست میآید:
این کار برای تمامی متغیرهای (یا ویژگیهای) بردار رمزنگار و نمونه ورودی تکرار میشود. از آنجایی که هنگام وارد شدن هر کدام از نمونههای آموزشی به شبکه LVQ، تنها یک بردار رمزنگار انتخاب و مقادیر آن (جهت نزدیک شدن به نمونه یا دور شدن از آن) دستکاری میشود، اصطلاح همه مال برنده (Winner-Take-All)، در توصیف این الگوریتم یادگیری مورد استفاده قرار میگیرد. همچنین، الگوریتم شبکه LVQ در زمره الگوریتمهای یادگیری رقابتی قلمداد میشود.
این فرایند برای تمامی نمونههای موجود در دادههای آموزشی تکرار میشود. به هر تکراری که در آن تمامی نمونههای آموزشی، یکی به یکی، وارد سیستم میشوند و مقادیر ویژگیها یا متغیرهای بردارهای رمزنگار تغییر پیدا میکنند (این بردارها یا به سمت نمونههای وارد شده به سیستم حرکت میکنند و یا از آنها دور میشوند)، «دوره» (Epoch) گفته میشود. پس از انتخاب تعداد Epochهای لازم برای آموزش شبکه LVQ (به عنوان نمونه، 200 epoch)، گام طراحی فرایند آموزش و یادگیری یک مدل شبکه LVQ به پایان میرسد.

علاوه بر موارد ذکر شده، پارامتر نرخ یادگیری نیز باید «مقداردهی اولیه» (Initialize) شود (به عنوان نمونه، ). روش مقداردهی این پارامتر به گونه است که مقدار باید در طول فرایند یادگیری و با پایان یافتن هر Epoch کاهش پیدا کند؛ بدین صورت که در ابتدا، یک مقدار بزرگ برای این پارامتر انتخاب میشود (انتخاب مقدار بزرگ در epochهای اولیه سبب میشود تا بیشترین تغییرات در مقادیر ویژگیهای بردار رمزنگار ایجاد شود) و در epochهای پایانی، مقداری کوچک (نزدیک به صفر) برای پارامتر نرخ یادگیری انتخاب میشود (انتخاب مقدار کوچک در epochهای پایانی سبب میشود تا کمترین تغییرات ممکن در مقادیر ویژگیهای بردار رمزنگار ایجاد شود). برای محاسبه نرخ یادگیری در هر epoch از رابطه زیر استفاده میشود:
در این رابطه، پارامتر نرخ یادگیری شبکه LVQ برای epoch کنونی را نشان میدهد (مقدار epoch از صفر تا خواهد بود). پارامتر مقدار نرخ یادگیری است که در ابتدای کار الگوریتم، توسط کاربر، مقداردهی شده است. همچنین، پارامتر تعداد کل epochهای لازم برای آموزش شبکه LVQ است که توسط کاربر مقداردهی اولیه میشود.
فرایند یادگیری در شبکه LVQ بر اساس مفهوم «فشردهسازی» (Compression) ابداع و توسعه داده شده است. به عبارت دیگر، مجموعه متشکل از بردارهای رمزنگار، به نوعی فشردهسازی دادههای مجموعه آموزشی محسوب میشوند؛ یعنی، بردارهای رمزنگار، تا نقطهای که بتوانند کلاسهای موجود در مجموعه داده آموزشی را به بهترین شکل ممکن جداسازی (Separate) کنند، دادهها را فشردهسازی میکنند.
آمادهسازی دادهها و بهینهسازی عملکرد شبکه LVQ
به طور کلی، پیشنهاد میشود که پیش از پیادهسازی و اجرای شبکه LVQ، مجموعهای از فرایندهای آمادهسازی روی دادههای مسأله انجام شوند تا عملکرد بهینه شبکه LVQ در دستهبندی دادهها تضمین شود:
- دستهبندی: شبکه LVQ یک الگوریتم دستهبندی محسوب میشود که برای مسائل دستهبندی باینری و مسائل دستهبندی چند کلاسی مورد استفاده قرار میگیرد. همچنین، نسخههایی از این الگوریتم برای حل مسائل «رگرسیون» (Regression) ارائه شده است.
- اجرای چندین باره الگوریتم LVQ: یکی از روشهایی که به بهبود عملکرد الگوریتم در دستهبندی دادهها خواهد انجامید، اجرای چندین باره الگوریتم LVQ روی دادههای آموزشی است (اجرای چندین باره الگوریتم یادگیری و آموزش سیستم). همچنین، توصیه میشود که در اولین اجرای شبکه LVQ، مقدار بزرگی برای پارامتر نرخ یادگیری انتخاب شود تا از این طریق، مجموعه بردارهای رمزنگار بتوانند رفتار دادههای آموزشی را یاد بگیرند. در اجرای بعدی، بهتر است مقدار کوچکتری برای پارامتر نرخ یادگیری مشخص شود تا عملکرد بردارهای رمزنگار در دستهبندی داده بهبود پیدا کند (Fine Tuning).
- مشخص کردن چندین بردار رمزنگارِ مشابه با نمونههای آموزشی ورودی: برخی از نمونههای گسترش یافته شبکه LVQ، چندین بردار رمزنگار (به عنوان نمونه، یک بردار رمزنگار که برچسب کلاسی آن با نمونه ورودی یکسان و یک بردار دیگر، که برچسب کلاسی آن با نمونه ورودی متفاوت است) به ازاء هر نمونه ورودی انتخاب و مقادیر متغیرها یا ویژگیهای آنها را تغییر میدهند (به سمت نمونه ورودی حرکت میدهند یا از این نمونه دور میکنند). همچنین، انواع دیگری از شبکه LVQ، از یک پارامتر نرخ یادگیری متغیر و سفارشیسازی شده به ازاء هر کدام از بردارهای رمزنگار استفاده میکنند. این دسته از الگوریتمهای LVQ، عملکرد بهتری نسبت به شبکه LVQ استاندارد از خود نشان میدهند.
- «نرمالسازی» (Normalizing) دادههای ورودی: معمولا، پیش از اجرای الگوریتم، دادههای ورودی به مقادیری بین 0 تا 1 نرمالسازی میشوند (مقیاسبندی دوباره دادههای ورودی). چنین عملیات پیشپردازشی با این هدف انجام میشود تا هنگام محاسبه فاصله میان نمونه ورودی و بردارهای رمزنگار، یک ویژگی که مقدار عددی بسیار بزرگتری نسبت به ویژگیهای دیگر دارد، ویژگیهای دیگر را تحت شعاع خود قرار ندهد (مقادیر متغیرهای مختلف، نقش متناسبی در محاسبه فاصله داشته باشند). در صورتی که دادههای ورودی نرمالسازی شده باشند (در مقیاس 0 تا 1)، این امکان وجود دارد تا بردارهای رمزنگار با مقادیر 0 تا 1 مقداردهی اولیه شوند.
- «انتخاب ویژگی» (Feature Selection): انتخاب ویژگی، ابعاد فضای ویژگیهای (متغیرهای) مسأله را کاهش میدهد و «دقت» مدل یادگیری را بهبود میبخشد. شبکه LVQ همانند الگوریتم K-نزدیکترین همسایه (KNN) از «معضل ابعاد» (Curse of Dimensionality) رنج میبرد.
پیادهسازی شبکه LVQ در پایتون
همانطور که پیش از نیز اشاره شد، یکی از معایب مهم روش K-نزدیکترین همسایه این است که برای تضمین عملکرد بهینه الگوریتم یادگیری نیاز است تا تمامی نمونههای آموزشی موجود در مجموعه داده آموزش در اختیار این مدل یادگیری قرار گرفته شده باشند. برای رفع این مشکل، شبکه LVQ روی مجموعه بسیار کوچکتر از الگوها، که به بهترین شکل ممکن قادر به نمایش دادههای آموزشی هستند، آموزش میبیند.
در این بخش، نحوه پیادهسازی شبکه LVQ در زبان پایتون مورد بررسی قرار میگیرد. موضوعاتی که در این بخش مورد بررسی قرار میگیرند، عبارتند از:
- نحوه آموزش مجموعهای از بردارهای رمزنگار (Codebook Vectors) با استفاده از مجموعه دادههای آموزشی.
- نحوه انجام پیشبینی با استفاده از بردارهای رمزنگار آموزش داده شده.
- بهکارگیری الگوریتم شبکه LVQ جهت حل یک مسأله دستهبندی (پیشبینی برچسب کلاسی نمونهها) در جهان واقعی.
مجموعه داده یونوسفر (Ionosphere)
مجموعه داده یونوسفر (Ionosphere)، ساختار یونوسفر را با توجه به دادههای خروجی رادار پیشبینی میکند. هر کدام از نمونههای موجود در مجموعه داده، خصوصیات دادههای تولید شده توسط رادار، از جو (Atmosphere) زمین، را توصیف میکنند. وظیفه یک مدل پیشبینی این است که وجود ساختار در لایه یونوسفر را پیشبینی کند.

در این مجموعه داده، 345 نمونه وجود دارد که هر کدام از این نمونهها از 34 ویژگی (متغیر) عددی متشکل شدهاند؛ مجموعه ویژگیهای موجود در این مجموعه داده، از 17 جفت ویژگی تشکیل شده است که معمولا مقادیری بین 0 و 1 دارند. برچسب (متغیر) کلاسی نیز یک مقدار رشته (String) است که میتواند یکی از دو مقدار g، به معنای داده خوب (Good) و b، به معنای داده بد (Bad) را به خود بگیرد. این مجموعه داده از طریق لینک [+] قابل دسترس است.
جهت پیادهسازی شبکه LVQ در پایتون، استفاده از آن جهت دستهبندی دادههای مجموعه داده یونوسفر (Ionosphere) و ارزیابی و مقایسه عملکرد آن، یک روش دستهبندی مبنا (Baseline) نیز مورد استفاده قرار گرفته است. در این مطلب، از «الگوریتم قانون صفر» (Zero Rule Algorithm) به عنوان الگوریتم مبنا استفاده شده است.
الگوریتم قانون صفر یک معیار ساده ولی مؤثر برای ارزیابی عملکرد الگوریتمهای دستهبندی محسوب میشود. به شکل بسیار ساده، خروجی این الگوریتم، متناوبترین برچسب دستهبندی موجود در یک مجموعه داده است. به عنوان نمونه، در صورتی که متناوبترین برچسب کلاسی موجود در یک مجموعه داده، جهت برچسبگذاری 65 درصد از دادههای این مجموعه استفاده شده باشد، خروجی این الگوریتم در تمامی حالات برابر با متناوبترین برچسب کلاسی خواهد بود؛ در نتیجه، دقتی برابر با 65 درصد، برای این الگوریتم ثبت خواهد شد.
بهکارگیری الگوریتم قانون صفر (به عنوان الگوریتم مبنا) و دستهبندی دادههای مجموعه داده یونوسفر توسط این دستهبند مبنا، دقتی برابر با 64٫286 درصد برای سیستم رقم خواهد زد. در ادامه، جهت پیادهسازی شبکه LVQ، کد نویسی مؤلفههای زیر در «زبان برنامهنویسی پایتون» (Python Programming Language) آموزش داده خواهد شد:
- فاصله اقلیدسی (Euclidean Distance) جهت پیدا کردن مشابهترین بردارهای رمزنگار به دادههای ورودی.
- نحوه مشخص کردن مشابهترین بردار رمزنگار به داده ورودی یا «بهترین واحد تطبیق داده شده» (Best Matching Unit | BMU).
- نحوه آموزش بردارهای رمزنگار.
- استفاده از مدل شبکه LVQ آموزش داده شده جهت دستهبندی دادههای مجموعه داده یونوسفر (Ionosphere).
فاصله اقلیدسی در شبکه LVQ
اولین گام جهت پیادهسازی شبکه LVQ در زبان پایتون، محاسبه فاصله اقلیدسی میان نمونههای موجود در مجموعه داده و بردارهای رمزنگار است؛ به عبارت دیگر، سیستم باید قادر به مشخص کردن فاصله اقلیدسی میان سطرهای مجموعه داده باشد. عناصر موجود در سطرهای یک مجموعه داده، معمولا از مقادیر عددی تشکیل شدهاند و یک راه حل ساده برای محاسبه فاصله میان دو سطر یا بردار، رسم یک خط صاف است که این دو نمونه را در فضای ویژگی مسأله به هم متصل میکند. انجام چنین کاری جهت یافتن فاصله میان نقاط در فضای دوبُعدی یا سهبُعدی منطقی است. از همه مهمتر، مقیاسپذیری این روش در فضاهای با ابعاد بالاتر، بسیار خوب انجام میشود.
با استفاده از فاصله اقلیدسی، این امکان وجود دارد تا اندازه خط مستقیم میان دو بردار (فاصله میان دو بردار) را محاسبه کرد. فاصله اقلیدسی را میتوان در قالب جذرِ مربع اختلاف میان دو بردار محاسبه کرد.
در چنین رابطهای، x1 سطر اول و x2 سطر دوم دادههایی هستند که قرار است فاصله میان آنها مشخص شود. همچنین، شاخص (Index) ویژگیهای موجود در داده را نشان میدهد. در هنگام محاسبه فاصله اقلیدسی میان دو بردار، هر چه قدر که مقدار فاصله میان آنها کمتر باشد، دو بردار شباهت بیشتری به یکدیگر خواهند داشت. مقدار صفر، به عنوان مقدار فاصله میان دو بردار، بیانگر شباهت کامل میان دو بردار خواهد بود (هیچ تفاوتی میان آنها وجود ندارد). تابع euclidean_distance()، فاصله اقلیدسی میان دو بردار را در زبان پایتون محاسبه میکند.
همانطور که در کدهای بالا قابل مشاهده است، آخرین ستون دادهها (آخرین ویژگی یا متغیر) به عنوان برچسب کلاسی دادهها در نظر گرفته شده است و در محاسبه فاصله دخالت داده نمیشود. برای آزمون مؤلفههای مختلف شبکه LVQ و تضمین عملکرد مناسب آنها ، یک مجموعه داده دوبُعدی و بسیار کوچک (Dummy Dataset) طراحی شده است. این مجموعه داده (Dummy Dataset)، متفاوت از مجموعه داده یونوسفر است و تنها جهت آزمون مؤلفههای مختلف شبکه LVQ در زبان پایتون طراحی شده است.
در مرحله بعد، برای آزمون تابع فاصله اقلیدسی، از قطعه کد نمونه زیر جهت محاسبه فاصله میان سطر اول و تمامی سطرهای موجود در مجموعه داده (Dummy Dataset) استفاده میشود. بنابراین، در صورت عملکرد صحیح این تابع، فاصله میان سطر اول و خودش باید برابر با صفر باشد:
با اجرای این قطعه کد، فاصله میان سطر اول و تمامی سطرهای موجود در مجموعه داده (Dummy Dataset) محاسبه و در خروجی نمایش داده میشود (از جمله، فاصله سطر اول با خودش).
در مرحله بعد، از تابع فاصله اقلیدسی، جهت پیدا کردن مشابهترین بردار رمزنگار به داده ورودی یا همان بهترین واحد تطبیق داده شده (Best Matching Unit | BMU) استفاده میشود.
بهترین واحد تطبیق داده شده (Best Matching Unit | BMU)
بهترین واحد تطبیق داده شده (BMU)، بردار رمزنگاری (Codebook Vector) است که بیشترین شباهت را به نمونه ورودی به سیستم دارد. برای این که بتوان بهترین واحد تطبیق داده شده با یک نمونه ورودی جدید را مشخص کرد، ابتدا باید فاصله میان بردارهای رمزنگار و این داده ورودی محاسبه شود. برای این کار، از تابعی که در بخش قبل پیادهسازی شده است استفاده میشود.
پس از محاسبه فاصله میان بردارهای رمزنگار و داده ورودی جدید، بردارهای رمزنگار بر اساس شباهت آنها به داده ورودی رتبهبندی میشوند. سپس، مشابهترین بردار (اولین بردار در لیست مرتب شده) به عنوان بهترین واحد تطبیق داده شده یا مشابهترین بردار به ورودی جدید مشخص میشود.
از تابع get_best_matching_unit()، جهت محاسبه فاصله میان بردارهای رمزنگار و داده ورودی، رتبهبندی بردارهای رمزنگار برحسب فاصله آنها با داده ورودی و انتخاب مشابهترین بردار رمزنگار به داده ورودی (به عنوان بهترین واحد تطبیق داده شده (BMU)) استفاده میشود.
همانطور که در کدهای بالا قابل مشاهده است، از تابع euclidean_distance() توسعه داده شده در بخش قبل، برای محاسبه فاصله اقلیدسی میان دادههای ورودی جدید (test_row) و بردارهای رمزنگار (codebooks) استفاده میشود. سپس، بردارهای رمزنگار بر اساس شباهت آنها به داده ورودی، رتبهبندی و مشابهترین بردار رمزنگار، به عنوان بهترین واحد تطبیق داده شده (BMU) انتخاب میشود.
در مرحله بعد، برای آزمون تابع get_best_matching_unit() روی مجموعه داده (Dummy Dataset)، از قطعه کد نمونه زیر استفاده میشود. در این قطعه کد فرض شده است که نمونه اول مجموعه داده (Dummy Dataset)، نمونه جدید ورودی است و تمامی نمونههای موجود در مجموعه داده (Dummy Dataset)، بردارهای رمزنگار هستند. در نتیجه، این انتظار وجود دارد که نمونه اول، به عنوان بهترین واحد تطبیق داده شده (BMU) برای نمونه جدید ورودی انتخاب شود (زیرا هر نمونه بیشترین شباهت را با خودش دارد).
با اجرای این قطعه کد، بهترین واحد تطبیق داده شده (BMU) متناظر با نمونه اول مجموعه داده، در خروجی نمایش داده میشود. همانطور که انتظار میرفت، از آنجایی که مشابهترین بردار رمزنگار به نمونه اول، خودش است، این نمونه در خروجی نمایش داده میشود.
با داشتن مجموعهای از بردارهای رمزنگار آموزش داده شده، انجام پیشبینی در مورد نمونههای جدید نیز به همین منوال انجام میشود. برای این کار از الگوریتم «1-نزدیکترین همسایه» (Nearest Neighbor) استفاده میشود. به عبارت دیگر، به ازاء هر نمونه ورودی به سیستم که قرار است روی آن پیشبینی انجام شود، مشابهترین بردار رمزنگار انتخاب و برچسب کلاسی متناظر با آن در خروجی (به عنوان پیشبینی دستهبندی نمونه جدید) نمایش داده میشود.
پس از پیادهسازی تابع لازم جهت مشخص کردن بهترین واحد تطبیق داده شده (BMU) متناظر با نمونههای ورودی به سیستم، نحوه آموزش دادن بردارهای رمزنگار نمایش داده خواهد شد.
آموزش مجموعه بردارهای رمزنگار در شبکه LVQ
گام اول در آموزش مجموعه بردارهای رمزنگار در شبکه LVQ، مقداردهی اولیه (Initialize) به آنها است. مجموعه بردارهای رمزنگار را میتوان با استفاده از الگوهای ساخته شده با استفاده از ویژگیهای (متغیرهای) تصادفی، مقداردهی اولیه کرد.
تابع random_codebook()، که در ادامه نمایش داده شده است، چنین کاری را انجام میدهد. این تابع، مجموعه ورودیها (مجموعه ویژگی یا متغیر) و برچسب کلاسی متناظر با آنها را، به طور تصادفی، از دادههای آموزشی انتخاب و به عنوان مقادیر اولیه بردارهای رمزنگار انتخاب میکند.
پس از این که بردارهای رمزنگار توسط یک مجموعه تصادفی مقداردهی اولیه شدند، مقادیر آنها باید توسط فرایند یادگیری شبکه LVQ تنظیم شود تا بتوان از بردارهای رمزنگار برای دستهبندی نمونههای جدید استفاده کرد. چنین کاری طی یک فرایند تکراری انجام میپذیرد.
- دورهها (Epochs): فرایند آموزش مجموعه بردارهای رمزنگار در شبکه LVQ، برای تعداد دوره (Epoch) مشخصی تکرار میشود. در هر تکرار، تمامی دادههای آموزشی، یکی به یکی، وارد سیستم میشوند و مقادیر بردارهای رمزنگار تنظیم میشوند.
- مجموعه داده آموزشی (Training Dataset): در هر دوره (Epoch)، تمامی دادههای آموزشی، یکی به یکی، وارد سیستم میشوند و مجموعه بردارهای رمزنگار و مقادیر آنها بهروزرسانی میشوند.
- مقادیر ویژگیهای (متغیرهای) بردارهای رمزنگار: به ازاء هر نمونه آموزشی، هر یک از ویژگیهای (متغیرهای) بهترین واحد تطبیق داده شده (BMU) به نحوی بهروزرسانی میشوند که یا به سمت نمونه آموزشی در فضای ورودیها حرکت کنند یا از آن فاصله بگیرند.
به ازاء هر نمونه آموزشی تنها یک بردار رمزنگار به عنوان بهترین واحد تطبیق داده شده (BMU) انتخاب و بهروزرسانی میشود. اختلاف میان نمونه آموزشی و بهترین واحد تطبیق داده شده (BMU)، به عنوان «خطای» (Error) شبکه LVQ محاسبه میشود. سپس، برچسبهای کلاسی متناظر با نمونه آموزشی و بهترین واحد تطبیق داده شده (BMU) مقایسه میشوند؛ در صورتی که برچسبهای کلاسی برابر باشند، مقدار خطا به بهترین واحد تطبیق داده شده (BMU) اضافه میشود تا این واحد به نمونه آموزشی نزدیک شود، در غیر این صورت، مقدار خطا از بهترین واحد تطبیق داده شده (BMU) کم میشود تا این واحد از نمونه آموزشی فاصله بگیرد.
مقیاسی که بر اساس آن واحد BMU به نمونه آموزشی نزدیک میشود یا از آن فاصله میگیرد، توسط پارامتر نرخ یادگیری (Learning Rate) مشخص میشود. به عنوان نمونه، در صورتی که نرخ یادگیری برابر با ۰٫۳ باشد، واحدهای BMU تنها توسط سی درصد خطا (یا فاصله میان این واحد و نمونه آموزشی) به سمت نمونه آموزشی حرکت میکنند یا از آن فاصله میگیرند.
همچنین، پارامتر نرخ یادگیری به گونهای تنظیم میشود تا بیشترین تاثیر را در دوره (Epoch) اول داشته باشد و هر چه قدر که آموزش شبکه LVQ به دورههای پایانی نزدیکتر میشود، این تاثیر کمتر و کمتر میشود تا اینکه در دوره آخر، کمترین تاثیر ممکن را خواهد داشت. به چنین پدیدهای «زوال خطی» (Linear Decay) نرخ یادگیری گفته میشود که در دیگر شبکههای عصبی مصنوعی نیز مورد استفاده قرار میگیرد.
زوال خطی نرخ یادگیری پس از هر دوره (Epoch) توسط رابطه زیر فرمولبندی میشود:
عملکرد زوال خطی نرخ یادگیری را میتوان روی یک نرخ یادگیری برابر با ۰٫۳ و برای 10 دوره (Epoch) سنجید.
در ادامه، تابعی به نام train_codebooks() نمایش داده میشود که با در اختیار با داشتن یک مجموعه داده آموزشی، فرایند آموزش مجموعه بردارهای رمزنگار را، در شبکه LVQ انجام میدهد. این تابع، سه آرگومان اضافی را به عنوان ورودی دریافت میکند:
- تعداد بردارهای رمزنگاری که باید ساخته و آموزش داده شوند.
- نرخ یادگیری اولیه.
- تعداد دورههای (Epochs) لازم برای آموزش بردارهای رمزنگار (Codebook).
این تابع، مجموع مربعات خطا در هر دوره (Epoch) را محاسبه و با نمایش یک پیام در خروجی، شماره دوره (Epoch)، نرخ یادگیری در آن دوره (Epoch) و مجموع مربعات خطا را نمایش میدهد. چنین پیامهایی، فرایند «اشکالزدایی» (Debugging) تابع آموزش مجموعه بردارهای رمزنگار در شبکه LVQ را تسهیل میبخشند.
همانطور که در کدهای زیر قابل نمایش است، از تابع random_codebook() برای مقداردهی اولیه بردارهای رمزنگار و در هر دوره (Epoch)، از تابع get_best_matching_unit() جهت پیدا کردن بهترین واحد تطبیق داده شده (BMU) به ازاء هر نمونه ورودی به سیستم استفاده میشود.
با در کنار هم قرار دادن توابع نمایش داده در بخشهای قبلی و توابع این بخش، میتوان قطعه کد لازم برای آموزش مجموعه بردارهای رمزنگار روی مجموعه داده (Dummy Dataset) تدارک دیده شده را (و کد لازم جهت اطمینان از عملکرد صحیح آنها) تولید کرد:
با اجرای قطعه کد بالا، مجموعهای متشکل از 2 بردار رمزنگار، جهت دستهبندی نمونههای موجود در مجموعه داده (Dummy Dataset) آموزش داده میشوند. تعداد دورههای (Epochs) لازم برای آموزش بردارهای رمزنگار برابر با 10 و نرخ یادگیری نیز برابر با 0٫۳ در نظر گرفته شده است.
همچنین، با اجرای قطعه کد بالا، جزئیات مرتبط با هر دوره (Epoch) و مقادیر مرتبط با مجموعه متشکل از 2 بردار رمزنگار یادگیری شده (در هر دوره (Epoch))، در خروجی نمایش داده میشود.
همانطور که در خروجیهای بالا مشهود است، نرخ یادگیری در هر دوره (Epoch)، بر اساس رابطه نمایش داده شده در این بخش، کاهش پیدا میکند. همچنین پس از هر دوره (Epoch)، تغییرات میزان مربعات خطا به روند نزولی خود ادامه میدهد. در مرحله بعد، توابع و قطعه کدهای نمایش داده شده جهت آموزش مدل شبکه LVQ، با هدف دستهبندی دادههای مجموعه داده یونوسفر (Ionosphere) مورد استفاده قرار میگیرند.
آموزش مدل شبکه LVQ جهت دستهبندی دادههای مجموعه داده یونوسفر (Ionosphere)
در این بخش، از شبکه LVQ برای دستهبندی دادههای موجود در مجموعه داده یونوسفر (Ionosphere) استفاده میشود. ابتدا لازم است تا دادهها در سیستم بارگیری و از حالت رشته به حالت عددی تبدیل شوند تا بتوان از آنها برای محاسبه فاصله اقلیدسی استفاده کرد.
همچنین، از یک مجموعه متشکل از 20 بردار رمزنگار برای آموزش شبکه LVQ استفاده شده است. برای ارزیابی عملکرد سیستم در دستهبندی دادهها، از اعتبارسنجی متقابل K-Fold (مقدار K=5) استفاده میشود.
اجرای این قطعه کد، شبکه LVQ و مجموعه بردارهای رمزنگار را روی مجموعه داده یونوسفر (Ionosphere) آموزش میدهد. در پایان، «دقت» (Accuracy) هر کدام از Foldها (K=5) و همچنین دقت میانگین مدل نمایش داده میشود.
همانطور که در خروجیها قابل مشاهده است، میانگین دقت شبکه LVQ در دستهبندی دادهها برابر با 87٫۱۴۳% گزارش شده است. بدون شک، دقت حاصل شده از دقت روش مبنا (روش Zero Rule با دقت برابر با 64٫286٪) به مراتب بالاتر است. با این حال، این امکان وجود دارد که با انتخاب تعداد بیشتری بردار رمزنگار، به دقت بالاتری در دستهبندی دادهها دست یافت.

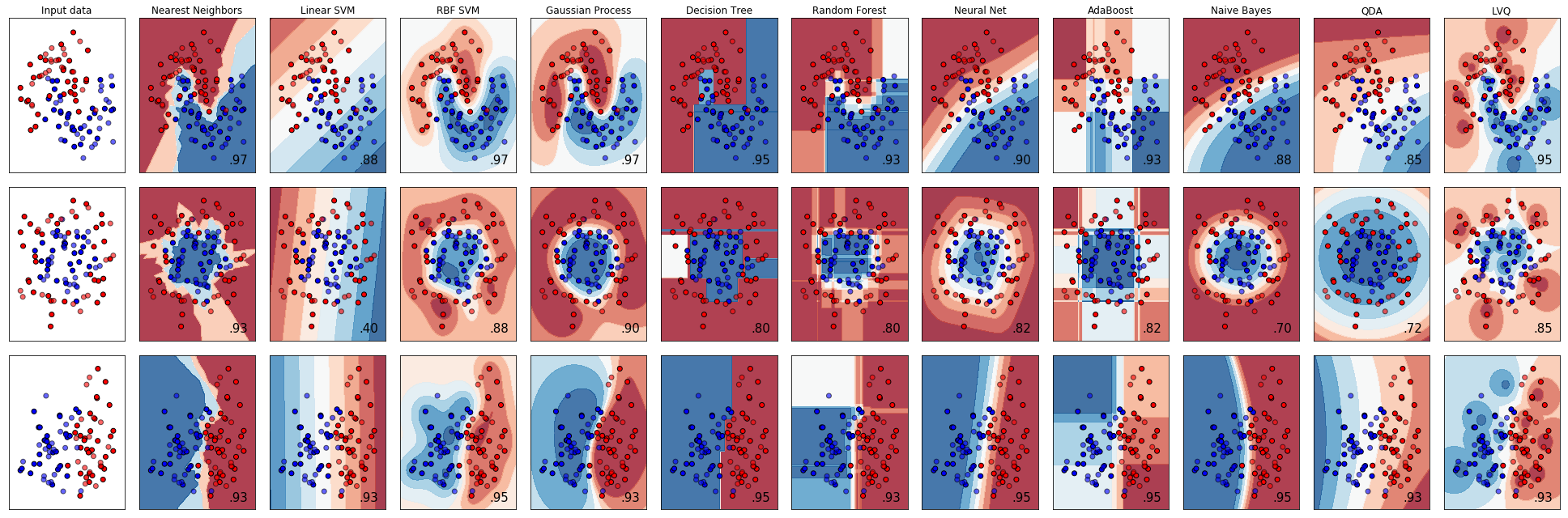
در ادامه با استفاده از یک مجموعه داده مشترک (متفاوت از مجموعه داده یونوسفر (Ionosphere))، عملکرد دستهبندهای مختلفی Nearest Neighbors ،Linear SVM ،RBF SVM ،Gaussian Process ،Decision Tree ،Random Forest ،Neural Network ،AdaBoost ،Naive Bayes و QDA با شبکه LVQ مقایسه و عملکرد آنها در دستهبندی دادهها، به صورت بصری (Visual)، نمایش داده میشود.
خروجی:
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش اصول و روشهای دادهکاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- پرسپترون چند لایه در پایتون — راهنمای کاربردی
- نقشه دانش فناوریهای هوش مصنوعی و دسته بندی آنها — راهنمای جامع
- کد نویسی شبکه های عصبی مصنوعی چند لایه در پایتون — راهنمای کامل
- پیادهسازی مدلهای دستهبندی متن در پایتون — راهنمای کاربردی







