ضریب پراکندگی چیست؟ – به زبان ساده + فرمول محاسبه
اندازهگیری پراکندگی به ما کمک میکند تا بتوانیم در دو یا چند مجموعه داده، میزان گستردگی و تنوع دادهها را کمیسازی کنیم. این اندازهگیری با محاسبه چند پارامتر آماری مهم، مانند ضریب دامنه، ضریب انحراف میانگین، ضریب تغییرات و ضریب انحراف چارک انجام میشود. به همین علت، به هر کدام از این کمیتها «ضریب پراکندگی» (Coefficient of Dispersion) گفته میشود و برای هر یک، فرمول ضریب پراکندگی مشخصی تعریف شده است.
- تفاوتهای پراکندگی مطلق و نسبی را درک خواهید کرد.
- با فرمولها و نحوه محاسبه معیارهای پراکندگی آشنا خواهید شد.
- توانایی محاسبه و تحلیل ضریب تغییرات، دامنه و واریانس را کسب میکنید.
- یاد خواهید گرفت چگونه پراکندگی را برای دادههای مختلف محاسبه و نتایج را مقایسه کنید.
- خواهید آموخت شاخص مناسب برای توصیف دادهها را بهشکل بهتری انتخاب کنید.
- با نقش ضرایب پراکندگی در مقایسه دادههای هممقیاس و غیرهممقیاس آشنا میشوید.


اندازهگیری پراکندگی با توجه به نوع دادهها ممکن است مطلق یا نسبی باشد. در اندازهگیری مطلق پراکندگی، کمیتهایی مانند دامنه، انحراف میانگین، انحراف معیار و انحراف چارک بررسی میشوند، در حالی که در اندازهگیری نسبی پراکندگی ضرایب هر کدام از این کمیتها باید تحلیل شوند. بنابراین فرمول ضریب پراکندگی با فرمول پارامترهایی مانند دامنه، انحراف معیار، انحراف میانگین و انحراف چارک متفاوت است. در این نوشته از مجله فرادرس ابتدا به بررسی تفاوت اندازهگیری مطلق و نسبی پراکندگی خواهیم پرداخت. سپس، همراه با حل مثال توضیح میدهیم انواع ضریب پراکندگی چیست و نحوه محاسبه هر کدام به چه صورت است.
ضریب پراکندگی چیست و چه انواعی دارد؟
اگر دو یا چند مجموعه داده داشته باشیم و بخواهیم نحوه گسترش دادهها، فواصل آنها نسبت به هم یا فواصل آنها نسبت به مقدار مرکزی دادهها را بررسی کنیم، بهترین راه محاسبه چند پارامتر آماری مهم به نام ضریب دامنه، ضریب انحراف میانگین، ضریب تغییرات و ضریب انحراف چارک است:
| ضریب پراکندگی | فرمول ضریب پراکندگی |
| ضریب دامنه (CR) | |
| ضریب انحراف میانگین (CMD) | |
| ضریب تغییرات (CV) | |
| ضریب انحراف چارک (CQD) |
هر کدام از این کمیتها یک ضریب پراکندگی نام دارد. در جدول بالا، انواع فرمول ضریب پراکندگی آورده شده است. کاربرد اصلی ضرایب پراکندگی زمانی است که دو یا چند مجموعه داده با واحدهای متفاوت داریم، در نتیجه مقادیر میانگین کاملا متفاوتی برای هر سری از دادهها ایجاد شدهاند.
محاسبه هر کدام از انواع ضریب پراکندگی، از دیدگاه متفاوتی به بررسی دادههای ما کمک میکند. برای مثال، دامنه نشان میدهد اختلاف بین بزرگترین و کوچکترین مقدار ما در یک مجموعه داده چیست. اما واریانس میانگینی از مربع انحرافات تمام مشاهدات را محاسبه میکند. بنابراین برای اینکه اندازهگیری پراکندگی بهدرستی انجام شود، لازم است تمام این کمیتها محاسبه و تحلیل شوند. بهویژه اگر دادههای پرت یا outliers داشته باشیم، اهمیت بررسی پراکندگی بهتر مشخص میشود.
نکته مهم بعدی این است که برای محاسبه انواع ضریب پراکندگی برای مثال ضریب تغییرات، ابتدا باید بدانیم واریانس چگونه محاسبه میشود. به همین دلیل ابتدا فرمول محاسبه دامنه، انحراف میانگین، واریانس و انحراف چارک را بیان میکنیم و در بخشهای بعد به معرفی انواع فرمول ضریب پراکندگی خواهیم پرداخت.
مفهوم اندازهگیری پراکندگی در آمار
در بخش قبل با کلیت انواع ضریب پراکندگی آشنا شدیم. پراکندگی در آمار مفهومی است که چگونگی پخش شدن یا نحوه گستردگی دادهها حول مقدار میانگین را توصیف میکند و به ما کمک میکند تا تشخیص دهیم چقدر دادهها بهم نزدیک یا از هم دور هستند. به این ترتیب، میزان «سازگاری» (Consistency) یا «تنوع» (Variability) در یک مجموعه داده مشخص خواهد شد.


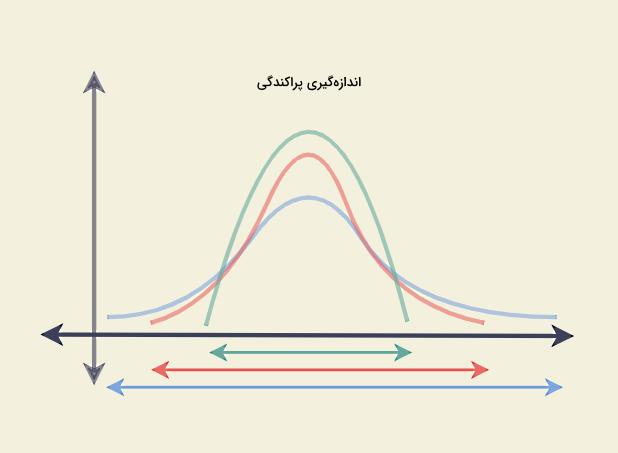
مثال ۱
برای مثال در تصویر بالا دو توزیع را مشاهده میکنید که در آنها محور افقی نشاندهنده مقادیر داده و محور عمودی بیانگر فراوانی هر داده است. هر دو توزیع، یک توزیع نرمال محسوب میشوند و برای هر دو، سه مقدار میانگین، میانه و مد یکسان است. اما واضح است که دو توزیع کاملا از لحاظ گستردگی و نحوه پخش دادهها یا پراکندگی با هم متفاوتاند.
بنابراین اگر پراکندگی را برای این دو توزیع اندازه بگیریم، خواهیم دید توزیعی که در راستای قائم گسترده شده است، پراکندگی کمتری نشان میدهد، در حالی که توزیع پهنتر، پراکندگی بیشتری نشان خواهد داد. پس هر چقدر پراکندگی کمتر باشد، دادهها به مقادیر مرکزی نزدیکتر هستند.
مثال ۲
در مثال دیگری، سه مجموعه داده زیر را که نشاندهنده نمرات کسب شده در یک آزمون هستند، در نظر بگیرید:
با وجود اینکه هر سه مجموعه دارای مقادیر میانگین و میانه مشابهی برابر با هستند، اما کاملا با هم فرق دارند. در مجموعه اول، تمام اعداد یکسان هستند، در حالی که در مجموعه دوم نیمی از اعداد به یک شکل و نیم دیگری از اعداد به شکل دیگر هستند.
در مجموعه سوم با اینکه سازگاری و تشابه مجموعه اول وجود ندارد، اما گستردگی مجموعه دوم هم دیده نمیشود. بنابراین با بررسی این مثال، میتوانیم به این نتیجه برسیم که ما علاوه بر دانستن میانگین و میانه، به اطلاعات دیگری برای بررسی نحوه انتشار یا توزیع دادههای خود نیاز داریم. اندازهگیری پراکندگی این امکان را به ما میدهد که اطلاعات کاملی در مورد دادههای خود بهدست آوریم. اگر بتوانیم پراکندگی را اندازهگیری کنیم، نتایج بهدست آمده به ما نشان میدهد که نحوه توزیع دادهها به چه صورت است. اندازهگیری پراکندگی به دو شیوه انجام میشود:
- اندازهگیری نسبی پراکندگی
- اندازهگیری مطلق پراکندگی
در هر کدام از این دو روش اندازهگیری، مطابق جدول زیر پارامترها یا کمیتهای آماری خاصی محاسبه میشوند:
| اندازهگیری پراکندگی | |||||||||
| اندازهگیری نسبی | اندازهگیری مطلق | ||||||||
| ضریب دامنه | ضریب انحراف میانگین | ضریب تغییرات | ضریب انحراف چارک | دامنه | انحراف میانگین | واریانس | انحراف چارک | ||
در ادامه به معرفی و نحوه محاسبه هر کدام از این پارامترها خواهیم پرداخت. خواهیم دید در محاسبات هر کدام از این موارد، لازم است به نکات خاصی دقت کنید از جمله تفاوت بررسی در نمونه و جامعه آماری یا اینکه دادهها بهصورت گروهبندی شده هستند یا خیر. در این زمینه، مطالعه مطلب «مفاهیم آماری – شاخصهای توصیفی» از مجله فرادرس به شما کمک میکند تا دید بهتری نسبت به برخی از مهمترین مفاهیم آماری و شاخصهای توصیفی که برای توصیف جامعه یا نمونهی آماری بکار میروند، بهدست آورید.
یادگیری مباحث آمار و احتمال دبیرستان با فرادرس
پیش از اینکه به توضیح انواع اندازهگیریهای پراکندگی بپردازیم، در این قسمت میخواهیم چند نمونه فیلم آموزشی از مجموعه فرادرس را به دانشآموزان معرفی کنیم تا با مشاهده آنها اطلاعات خوبی در زمینه مباحث آمار و احتمال کسب کنند. در کتابهای درسی رشتههای علوم ریاضی و علوم تجربی، مباحث آمار و احتمال از فصل نهم کتاب ریاضی پایه هفتم آغاز میشود و تا پایه دوازدهم ادامه دارد. بنابراین مشاهده فیلمهای آموزشی زیر میتواند در تسلط کامل شما به مباحث آمار و احتمال مفید باشد:

- فیلم آموزش ریاضی پایه هفتم فرادرس
- فیلم آموزش ریاضی پایه هشتم فرادرس
- فیلم آموزش ریاضی پایه دهم فرادرس
- فیلم آموزش ریاضی پایه یازدهم علوم تجربی فرادرس
- فیلم آموزش آمار و احتمال پایه یازدهم فرادرس
- فیلم آموزش ریاضی پایه دوازدهم علوم تجربی فرادرس
به ویژه در کتاب درسی ریاضی دهم رشته علوم انسانی، موضوعاتی مانند معیارهای پراکندگی، مفهوم انحراف از معیار و نحوه به دست آوردن آن، واریانس و مفهوم دامنه میانچارکی توضیح داده شده است. مشاهده فیلم آموزش مربوط به این دورهها نیز در کنار این مطلب، به یادگیری عمیق شما کمک خواهد کرد:
- فیلم آموزش رایگان نمایش داده ها ریاضی پایه دهم علوم انسانی فرادرس
- فیلم آموزش ریاضی و آمار ۱ پایه دهم علوم انسانی فرادرس
- فیلم آموزش ریاضی و آمار ۱ پایه دهم به همراه حل سوالات کنکور فرادرس
اندازهگیری مطلق پراکندگی
تا اینجا آموختیم پراکندگی چیست و با انواع ضریب پراکندگی نیز بهصورت کلی آشنا شدیم. اگر اندازهگیریهای پراکندگی را در مورد دادههایی اجرا کنیم که همگی دارای واحد یکسانی هستند، در این صورت میگوییم اندازهگیری مطلق داشتهایم. برای مثال واحدهایی مانند متر، دلار یا کیلوگرم، بسته به نوع دادههایی که در اختیار داریم. نکته مهم این است که چون واحد تمام دادهها یکسان است یا چون تمام دادهها دارای واحد هستند، پس اندازهگیری ما واحد دارد.


همانطور که اشاره شد، کمیتهای آماری که در اندازهگیری مطلق پراکندگی میتوانند محاسبه شوند، عبارتاند از:
- دامنه یا Range
- انحراف میانگین یا Mean Deviation
- واریانس یا Variance
- انحراف معیار یا Standard Deviation
- دامنه میانچارکی یا Interquartile Range
- انحراف چارک یا Quartile Deviation
- خمیدگی یا چولگی یا Skewness
در ادامه هر کدام از این پارامترها را به همراه روش محاسبه توضیح خواهیم داد.
دامنه چیست و چگونه محاسبه میشود؟
در اولین قدم لازم است مفهوم دامنه را بدانیم. دامنه یا R سادهترین کمیت در بررسی پراکندگی محسوب میشود و معادل است با اختلاف بین بیشترین و کمترین مقدار داده در یک مجموعه داده. اما پیش از آنکه به بررسی مفهوم دامنه بپردازیم، میخواهیم فیلم آموزش مفاهیم آماری در داده کاوی و پیاده سازی آن در پایتون Python فرادرس را به شما معرفی کنیم که در آن پس از توضیح مفاهیم معرفی شده در این نوشته، نحوه کاربرد آنها در پایتون نیز توضیح داده شده است. برای مشاهده این دوره میتوانید به لینکی که در ادامه برای شما قرار داده شده است، مراجعه کنید:
بنابراین محاسبه این کمیت با فرمول زیر انجام میشود:
که در آن L بزرگترین و S کمترین مقدار در میان دادهها است.

برای مثال دادههای شکل زیر را در نظر بگیرید. در این مجموعه داده، عدد ۹۵ بهعنوان بیشترین و عدد ۶۴ بهعنوان کمترین مقدار مشخص است. پس دامنه برای این مجموعه داده برابر میشود با .

دقت کنید در این بخش فرمول دامنه را برای یک مجموعه داده گروهبندی نشده معرفی کردیم. در بخش بعد روش محاسبه این کمیت را برای یک مجموعه داده گروهبندی شده توضیح میدهیم.
محاسبه دامنه برای دادههای گروهبندی شده
برای اینکه با تفاوت دادههای گروهبندی شده و دادههای گروهبندی نشده در بخش قبل بهتر آشنا شوید، به مثال زیر توجه کنید. فرض کنید نمرات کسب شده توسط یک کلاس طبق جدول زیر جمعآوری شدهاند و میخواهیم دامنه را برای این مجموعه داده گروهبندی نشده پیدا کنیم:
| بازه نمرات | فراوانی |
طبق آنچه توضیح داده شد، ابتدا باید بیشترین و کمترین مقدار داده را پیدا کنیم که برای این نوع داده، به شکل زیر تعیین میشود:
- بیشترین مقدار یا L: کرانه بالا یا بیشترین مقدار در بالاترین طبقه
- کمترین مقدار یا S: کرانه پایین یا کمترین مقدار در پایینترین طبقه

بنابراین با توجه به جدول بالا و اینکه بالاترین طبقه معادل است با و پایینترین طبقه یعنی ، بنابراین و خواهند شد و در نتیجه دامنه برابر است با:
دقت کنید در محاسبه دامنه باید چند نکته را مدنظر داشته باشیم:
- بالا بودن دامنه میتواند علامت این باشد که تنوع در مجموعه داده ما بالا است.
- اگر فقط دامنه را محاسبه کنیم، تحلیل چندان دقیقی نخواهیم داشت.
- برای توزیعهای فراوانی با انتهای باز امکان محاسبه دامنه وجود ندارد.
در مورد نکته شماره دو، علت این است که در این بررسی فقط بیشترین و کمترین مقادیر دادهها را در نظر گرفتهایم، در حالی که این دو عدد قطعا نمیتوانند نحوه انتشار یا پخششدگی دادهها را نشان دهند. همچنین در سومین نکته، بهتر است بدانیم توزیعهای فراوانی با انتهای باز به توزیعهایی گفته میشود که در آنها کرانه پایین پایینترین طبقه یا کرانه بالای بالاترین طبقه تعریف نشده است.
مثال
دامنه را برای توزیع فراوانی زیر محاسبه کنید:
| بازه نمرات | فراوانی |
پاسخ
با توجه به اینکه در این سوال دادهها در قالب سه بازه مختلف با طول یکسان تعریف شدهاند، پس با دادههای گروهبندی شده مواجه هستیم و لازم است برای تعیین بیشترین و کمترین مقادیر، روش گفته شده در بخش قبل را بکار ببریم:
- بیشترین مقدار یا L = بیشترین مقدار در بالاترین طبقه یعنی =
- کمترین مقدار یا S = کمترین مقدار در پایینترین طبقه یعنی =
انحراف میانگین چیست و چگونه محاسبه میشود؟
پیشنیاز درک ضریب پراکندگی انحراف میانگین این است که ابتدا به انحراف میانگین و فرمول آن مسلط باشیم. انحراف میانگین که با MD نمایش داده میشود، برابر است با میانگین حسابی حاصل تفریق مقادیر داده و مقدار میانگین. انحراف میانگین در حقیقت به ما نشان میدهد فاصله یک داده فرضی از نقطه مرکزی دادهها چقدر است. دقت کنید منظور ما از نقطه مرکزی دادهها لزوما میانگین دادهها نیست، بلکه نقطه مرکزی دادهها میتواند «میانگین» (Mean)، «میانه» (Median) یا «مد» (Mode) باشد.

پیش از اینکه به توضیح بیشتر در مورد انحراف میانگین بپردازیم، بهتر است ابتدا روش محاسبه میانگین را به سادهترین شکل ممکن بیان کنیم. اگر مجموعه داده ما گروهبندی نشده باشد، نقطه مرکزی دادهها منطبق بر میانگین است. در دادههای گروهبندی نشده، تعدادی داده بهصورت داریم که میانگین آنها با μ نشان داده میشود و برابر است با:
در رابطه بالا n تعداد دادهها است. با داشتن میانگین، انحراف میانگین توسط فرمول زیر بهدست خواهد آمد:
که در آن ∑ به معنای مجموع و قدر مطلق به این معنا است که پس از محاسبه ، چنانچه عدد منفی حاصل شد، علامت آن را در نظر نمیگیریم. پس فرمول انحراف میانگین در این حالت مشخص شد. برای مثال فرض کنید مجموعه دادهای به شکل زیر داریم:
برای اینکه انحراف میانگین این سه عدد را پیدا کنیم، ابتدا میانگین را محاسبه میکنیم:
سپس جدولی به شکل زیر رسم کرده و مقادیر خواسته شده را بهدست میآوریم:
در آخرین مرحله کافی است عدد بهدست آمده در انتهای ستون سوم را بر تعداد دادهها تقسیم کنیم:
همچنین میتوانیم با نوشتن مستقیم فرمول MD و عددگذاری، حاصل را به صورت زیر حساب کنیم:
به اثر علامت قدر مطلق در محاسبات بالا دقت کنید. اگر قدر مطلق را اعمال نکنیم، حاصل صفر بهدست میآید که اشتباه است.
محاسبه انحراف میانگین برای دادههای گروهبندی شده
اگر دادههای ما گروهبندی شده باشند، در این صورت همانطور که گفتیم، نقطه مرکزی ممکن است میانگین نباشد. فرمول محاسبه انحراف میانگین در این شرایط برابر است با:
در این فرمول نقطه مرکزی دادهها یعنی میانه است. محاسبه انحراف میانگین برای دادههای گروهبندی شده و غیرگروهی با فرمولهایی که در این دو بخش گفتیم امکانپذیر است.
همچنین ممکن است دادههای ما شامل مقادیر عددی گسسته و دارای فراوانی مشخصی باشند. برای مثال جدول دادههای زیر را در نظر بگیرید که در یک ستون آن مقادیر عددی مقدار حقوق دریافتی کارکنان یک مجموعه و در ستون دیگر، فراوانی هر مقدار بیان شده است. منظور از فراوانی، تعداد تکرارهای یک مقدار مشخص در یک مجموعه داده است. برای مثال زمانی که میگوییم فراوانی عدد ۲۵۰۰ برابر است با هفت، یعنی حقوق دریافتی هفت نفر برابر با ۲۵۰۰ است.
| میزان حقوق دریافتی | فراوانی |
فرمولی که برای محاسبه انحراف میانگین در این شرایط میتوانیم استفاده کنیم، به شکل زیر است:
که در آن برابر است با فراوانی هر داده. همچنین اگر مجموعه دادههایی به شکل زیر داشتیم که در آن بهجای مقادیر عددی گسسته، با یک بازه عددی مواجه شدیم (برای مثال گروه سنی ۱۰ تا ۲۰ سال)، در این صورت دادههای ما از نوع پیوسته محسوب میشوند:
| گروه سنی | فراوانی |
فرمول محاسبه انحراف میانگین در این حالت بهصورت زیر است:
مثال ۱
انحراف میانگین یک مجموعه داده به شکل زیر را پیدا کنید:
پاسخ
برای حل این مثال، چند گام زیر را بهترتیب اجرا میکنیم:
- محاسبه میانگین دادهها
- محاسبه اختلاف یا فاصله هر داده از میانگین
- محاسبه میانگین اعداد بهدست آمده از مرحله قبل
چون دادهها شامل یک گروه هستند، پس اولین قدم محاسبه مقدار میانگین این دادهها با فرمول زیر است:
در مرحله بعد، کافی است اختلاف هر مقدار داده را از میانگین محاسبه شده پیدا کنیم. این اختلاف «فاصله یا انحراف» (Deviation) هم نامیده میشود. برای اینکه از اشتباه جلوگیری کنید، بهتر است محاسبات خود را با رسم جدولی مشابه جدول زیر انجام دهید:
در آخرین مرحله، انحراف میانگین را با فرمول بیان شده در بخش قبل حساب میکنیم:

مثال ۲
انحراف میانگین را برای دادههای نمایش داده شده در جدول زیر محاسبه کنید:
| بازه | فراوانی |
پاسخ
اولین قدم محاسبه مقدار مرکزی این دادهها است که در هر بازه میتوان بهراحتی آن را مشخص کرد. برای مثال در بازه ۵ تا ۱۵، عدد مرکزی برابر است با ۱۰، اما در بازه ۱۵ تا ۲۵ عدد مرکزی ۲۰ خواهد شد و به همین ترتیب. در ستون چهارم جدول زیر، مقادیر دو ستون قبلی در هم ضرب شدهاند.
| بازه | فراوانی () | نقطه مرکزی () | |
بنابراین حالا میتوانیم میانه را با کمک گرفتن از فرمول زیر محاسبه کنیم:
در مرحله بعد باید انحراف هر مقدار از عدد بهدست آمده در مرحله قبل را بهدست آوریم. بهتر است مجددا جدولی به شکل جدول زیر در نظر بگیریم:
| بازه | فراوانی () | نقطه مرکزی () | |
حالا کافی است مقادیر بهدست آمده را در فرمول زیر قرار دهیم:
تمرین
واریانس و انحراف معیار چه هستند و چگونه محاسبه میشوند؟
در سومین بخش از اندازهگیریهای مطلق پراکندگی، به معرفی و روش محاسبه واریانس و انحراف معیار میپردازیم. یادگیری این مبحث به ما کمک میکند تا بتوانیم از فرمول ضریب پراکندگی مهمی به نام فرمول ضریب تغییرات بهراحتی در حل مسائل آماری خود استفاده کنیم. واریانس یا بهصورت میانگین حسابی مجذور انحرافات دادهها از مقدار میانگین تعریف میشود، در حالی که انحراف معیار یا معادل است با ریشه دوم واریانس.
پس این دو کمیت معمولا به دنبال هم محاسبه میشوند و با داشتن واریانس، پیدا کردن انحراف معیار آسان است. در واقع واریانس برابر است با مجذور انحراف معیار. این کمیتها از اساسیترین پارامترهای آماری محسوب میشوند که در ادامه با بررسی مثال نحوه محاسبه آنها را آموزش میدهیم.

نکته مهم در محاسبه واریانس این است که آیا برای دادههای یک نمونه محاسبه میشود یا جامعه آماری. اگر دادههای جمعیت را بررسی میکنیم، فرمول واریانس به شکل زیر است:
که در آن μ میانگین جمعیت است و n تعداد مشاهدات. با داشتن واریانس، انحراف معیار دادهها در یک جامعه آماری بهصورت زیر محاسبه میشود:
چنانچه دادههای ما مربوط به یک نمونه باشند، فرمول واریانس برابر است با:
در رابطه بالا میانگین نمونه است. واریانس برای نمونه را با هم نشان میدهند. بنابراین فرمول انحراف معیار در این حالت میشود:
تقریبا هر دو فرمول مشابه هم هستند، تفاوت اساسی در مخرج است که در مورد جمعیت n و در مورد نمونه n-1 در نظر گرفته میشود. اصلاح n به n-1 برای نمونه، تصحیح بسل نام دارد و باعث شده است نتایج درستتری حاصل شود.
محاسبه واریانس جهت اطلاع از گستردگی یک مجموعه داده خیلی مهم است. برای مثال اگر تمام دادههای ما یکسان باشند، در این صورت واریانس صفر است. هر واریانس مخالف صفری، همواره یک عدد مثبت است. واریانس پایین به معنای این است که دادههای نقطهای ما هم به مقدار میانگین و هم به یکدیگر نزدیکتر هستند. در حالی که واریانس بالا نشاندهنده این است که دادههای نقطهای نسبت به میانگین و یکدیگر توزیع گستردهتری دارند و از هم دورتر هستند.
برای مثال فرض کنید میخواهیم انحراف معیار را در مورد جامعه آماری زیر پیدا کنیم:
محاسبه با پیدا کردن میانگین، واریانس و در نهایت انحراف معیار کامل میشود. پس ابتدا فرمول میانگین را به شکل زیر مینویسیم:
حالا به کمک جدول زیر قدم به قدم واریانس را حساب میکنیم. میدانیم فرمول واریانس برای یک جامعه آماری به شکل زیر است:
مرحله بعدی این است که آخرین سلول از ستون سوم جدول بالا را به تعداد دادهها تقسیم کنیم تا واریانس بهدست آید:
بنابراین انحراف معیار طبق فرمول زیر میشود:
مثال
واریانس نمونه را برای یک مجموعه داده به شکل پیدا کنید:
پاسخ
دقت کنید در صورت سوال ذکر شده است واریانس نمونه، پس فرمول مناسب برای حل این سوال به شکل زیر است:
ابتدا باید را پیدا کنیم. سپس با توجه به فرمول بالا و در نظر گرفتن n-1 در مخرج، واریانس پیدا میشود:
حالا به کمک جدول زیر گام به گام واریانس را بهدست میآوریم:
مرحله بعدی این است که آخرین سلول از ستون سوم جدول بالا را به n-1 تقسیم کنیم تا واریانس بهدست آید:
تمرین
دامنه میانچارکی و انحراف چارک چه هستند و چگونه محاسبه میشوند؟
تا اینجا یاد گرفتیم که به میزان تفاوت مقادیر یک توزیع نسبت به مقادیر متوسط، پراکندگی گفته میشود و اندازهگیری پراکندگی ممکن است مطلق باشد یا با محاسبه انواع ضریب پراکندگی انجام شود. همچنین با بخشی از کمیتهای مهم در ارزیابی پراکندگی آشنا شدیم. در ادامه با یکی دیگر از کمیتهای آماری مهم به نام دامنه میانچارکی آشنا میشویم که برابر است با اختلاف مقادیر چارک بالا یا چارک سوم (Q3) و چارک پایین یا چارک اول (Q1) و با فرمول زیر محاسبه میشود:
برای اینکه بهتر درک کنید مفهوم چارک چیست، شکل زیر را در نظر بگیرید:
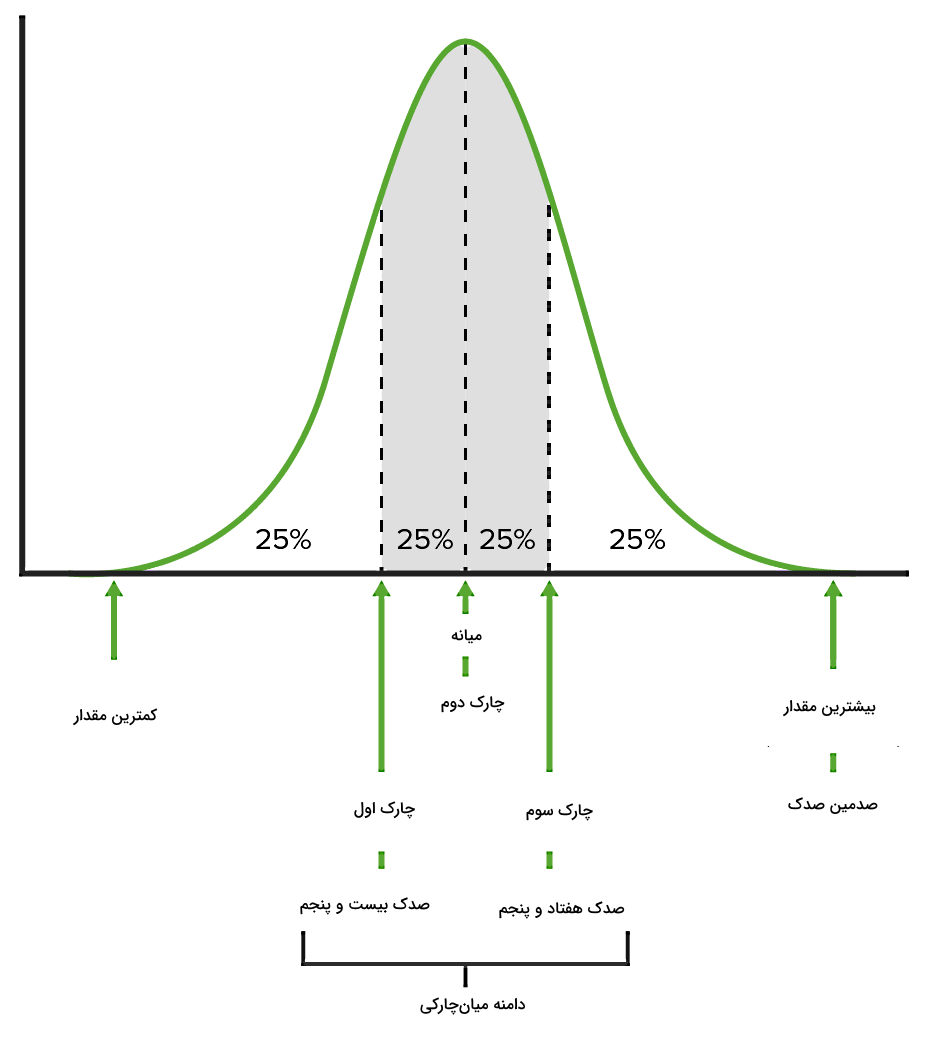
چارکها به منظور تقسیم یک مجموعه داده به چهار بخش مساوی استفاده میشوند. اگر بخواهیم در یک مجموعه داده چارک اول و سوم را به راحتی پیدا کنیم، میتوانیم از روابط زیر استفاده کنیم:
- چارک بالا یا Q3: اندازه آیتم ام
- چارک پایین یا Q1: اندازه آیتم ام
انحراف چارک که با نماد QD نشان داده میشود، بهصورت نصف اختلاف مقادیر چارک بالا و پایین در یک مجموعه داده تعریف میشود. گفتیم اختلاف مقادیر دو چارک بالا و پایین با دامنه میانچارکی برابر است. پس میتوانیم بگوییم انحراف چارک با نصف دامنه میانچارکی برابر است:
بنابراین با فرمول انحراف چارک نیز آشنا شدیم. برای مثال فرض کنید دادههایی به شکل زیر در اختیار دارید و میخواهید انحراف چارک را پیدا کنید:
بهتر است ابتدا دامنه میانچارکی را پیدا کنیم. اما پیش از آن، اولین گام در مبحث چارک این است که دادههای خود را به ترتیب از کمترین تا بیشترین مقدار مرتب کنیم:
حالا میتوانیم چارک اول و سوم را پیدا کنیم. طبق فرمولی که در بالا گفتیم، چارک پایین برابر است با اندازه آیتم ام که میشود:
دقت کنید n برابر است با تعداد دادهها که در اینجا معادل است با عدد هفت. پس باید ببینیم مقدار آیتم دوم در دادههای مرتب شده ما چیست:
همچنین برای چارک بالا خواهیم داشت:
ششمین آیتم در دادههای مرتب شده برابر است با عدد ۲۶۸. پس داریم:
حالا با داشتن چارک اول و سوم میتوانیم دامنه میانچارکی و به دنبال آن، انحراف چارک را محاسبه کنیم:
محاسبه انحراف چارک برای دادههای گروهبندی شده
در این بخش با یک مثال نشان میدهیم که اگر دادههای گروهبندی شده داشتیم، چگونه میتوانیم انحراف چارک را پیدا کنیم. فرض کنید جدول زیر نمرات کسب شده توسط دانشآموزان یک کلاس را به شما میدهد:
| نمرات | فراوانی |
در این مثال شرایط کمی با مثال قبلی متفاوت است. در واقع با مجموعه دادههایی سروکار داریم که دارای فراوانی هستند، یعنی دو سری داده داریم. در چنین شرایطی باید فراوانی تجمعی یا CF را محاسبه کنیم. به این منظور، لازم است ابتدا دادههای خود را مرتب کنیم که در این مثال دادهها بهصورت پیش فرض مرتب شده هستند.
سپس اولین فراوانی تجمعی برابر خواهد شد با فراوانی مطلق اولین یا کوچکترین مقدار. دومین فراوانی تجمعی برابر است با مجموع اولین فراوانی تجمعی و دومین فراوانی مطلق. سومین فراوانی تجمعی برابر است با مجموع دومین فراوانی تجمعی و سومین فراوانی مطلق و به همین ترتیب. در جدول زیر این روند را نشان دادهایم:
| نمرات | فراوانی مطلق | فراوانی تجمعی |
حالا با در نظر گرفتن آخرین عدد از ستون سوم، یعنی ۱۹۹ بهعنوان n، میتوانیم چارکهای بالا و پایین را طبق روندی که توضیح داده بودیم، بهدست آوریم. چارک پایین برابر است با اندازه آیتم ام که میشود:
سپس باید ببینیم مقدار آیتم پنجاهم در جدول بالا برابر با کدام مقدار است. به ستون سوم نگاه میکنیم. عدد ۵۰ در این ستون از ۴۶ بیشتر و از ۷۴ کمتر است. پس باید نمرهای که معادل با ردیف سوم است، یعنی عدد ۶۸ را بهعنوان چارک پایین در نظر بگیریم:
همچنین برای چارک بالا خواهیم داشت:
صد و پنجاهمین آیتم در دادههای ستون سوم بین ۱۳۶ و ۱۶۰ قرار دارد. پس نمره معادل با این چارک ۸۸ خواهد بود:
حالا با داشتن چارک اول و سوم میتوانیم دامنه میانچارکی و به دنبال آن، انحراف چارک را محاسبه کنیم:
اندازهگیری نسبی پراکندگی
پس از اینکه با روش محاسبه کمیتهای مهم در اندازهگیری پراکندگی آشنا شدیم، حالا میتوانیم انواع مختلف فرمول ضریب پراکندگی را معرفی کنیم. در اندازهگیری نسبی پراکندگی، دادههایی داریم که ممکن است دارای واحدهای مختلفی باشند یا اصلا واحد نداشته باشند. پس حاصل اندازهگیری نسبی پراکندگی، اعدادی بدون واحد است که ضریب پراکندگی نام دارند. معمولا زمانی که دو یا چند مجموعه داده با مقادیر میانگین کاملا متفاوت داریم، لازم است اندازهگیری نسبی انجام دهیم، به این صورت که انواع ضریب پراکندگی شامل موارد زیر را محاسبه میکنیم:
- ضریب دامنه یا Coefficient of Range
- ضریب انحراف میانگین یا Coefficient of Mean Deviation
- ضریب تغییرات یا Coefficient of Variation
- ضریب انحراف چارک یا Coefficient of Quartile Deviation
در ادامه هر ضریب پراکندگی را تعریف کرده و با حل مثال، روش محاسبه آنها را توضیح خواهیم داد. پیشنهاد میکنیم موارد بیان شده در این بخش را با موارد مشابه بخش قبل حتما مقایسه کنید تا دید دقیقتری نسبت به انواع اندازهگیریهای پراکندگی، ضریب پراکندگی و فرمول ضریب پراکندکی بهدست آورید.
ضریب دامنه چیست و چگونه محاسبه میشود؟
بهعنوان سادهترین ضریب پراکندگی، ابتدا ضریب دامنه را توضیح میدهیم. گفتیم دامنه برابر است با اختلاف میان بیشترین و کمترین مقادیر در یک مجموعه داده. اگر نسبت دامنه را به مجموع بیشترین و کمترین مقادیر داده محاسبه کنیم، ضریب دامنه یا CR را پیدا کردهایم. بنابراین فرمول ضریب پراکندگی در این بخش به شکل زیر است:
که در آن L برابر است با بیشترین مقدار داده و S کمترین مقدار داده محسوب میشود.
مثال
برای دو گروه داده زیر، ضریب پراکندگی دامنه را محاسبه کنید:
پاسخ
در اولین گروه، بیشترین مقدار یا L برابر است با ۱۲۵ و کمترین مقدار یا S میشود ۶۳. بنابراین ضریب دامنه یا QR با کاربرد فرمول ضریب پراکندگی مناسب برابر خواهد شد با:
در مورد دادههای گروه دوم، هم به همین شکل عمل میکنیم:
تمرین
ضریب انحراف میانگین چیست و چگونه محاسبه میشود؟
دومین ضریب پراکندگی که میخواهیم توضیح دهیم، ضریب انحراف میانگین یا CMD است. برای تعریف این کمیت هم نیاز داریم از تعریف ارائه شده در بخشهای قبل برای انحراف میانگین استفاده کنیم. پس از محاسبه انحراف میانگین، کافی است مقدار بهدست آمده را به مقدار دادهای که در مرکزیترین نقطه از نقاط دادههای ما قرار میگیرد، تقسیم کنیم تا ضریب انحراف میانگین را داشته باشیم. پس فرمول ضریب پراکندگی مناسب برای این کمیت به شکل زیر است:
در رابطه بالا برابر است با میانگین دادهها. در صورتی که مقدار مرکزی معادل میانه است، فرمول به شکل زیر اصلاح خواهد شد:
که در آن میانه است.
ضریب تغییرات چیست و چگونه محاسبه میشود؟
در بخشهای قبل یاد گرفتیم انحراف معیار و واریانس چه هستند و چگونه محاسبه میشوند. انحراف معیار به نوعی اندازهگیری مطلقی از پراکندگی محسوب میشود که نمیتوان از آن جهت مقایسه دو مجموعه داده با واحدهای مختلف استفاده کرد. به همین دلیل برای اینکه بتوانیم چنین مقایسهای داشته باشیم، نیاز است از کمیت متفاوتی استفاده کنیم.
مهمترین ضریب پراکندگی، ضریب تغییرات یا CV است که جهت مقایسه دو مجموعه داده از نظر ثبات، میزان سازگاری و همگنی بکار میرود. مرسوم است ضریب تغییرات را در قالب درصد بیان کنیم. ضریب تغییرات نوعی اندازهگیری نسبی است که توسط «کارل پیرسون» (Karl Pearson) معرفی شد. به همین دلیل، این ضریب را ضریب تغییرات پیرسون هم مینامند. فرمول این ضریب پراکندگی به شکل زیر است:
که در آن انحراف معیار و میانگین است. تمام توزیعها یا سریهای دادهای که ضریب تغییرات بالایی دارند، معمولا دارای همگنی، سازگاری، ثبات و یکنواختی کمتری هستند. برای اینکه با نحوه محاسبه این ضریب بهتر آشنا شوید، مثال زیر را در نظر بگیرید.

فرض کنید دانشآموزان دو کلاس امتحان مشابهی داشتهاند و میانگین نمرات هر دو کلاس برابر با ۷۵ شده است. اگر این کمیت تنها مشخصه مقایسه آماری دو کلاس باشد، احتمالا نتیجهگیری شما این خواهد شد که دو کلاس مشابه هم هستند. بهویژه اینکه حتی ضریب دامنه دو مجموعه داده ما نیز برابر با ۱۵ است. اما واقعیت این است که دادههای این بررسی به شکل زیر هستند:
اگر یک بررسی اجمالی روی دو گروه داده داشته باشیم، متوجه خواهیم شد که در گروه دوم مقادیر دادهها به میانگین یعنی عدد ۷۵ نزدیکتر هستند، در حالی که در گروه اول مقادیر دادهها از میانگین دورتر است. پس احتمالا ضریب تغییرات برای گروه اول نسبت به گروه دوم بیشتر است. بیاید با استفاده از فرمول این پیشبینی را نشان دهیم. فرمول ضریب پراکندگی در این بخش معادل فرمول ضریب تغییرات و به شکل زیر است:
پس باید انحراف معیار را محاسبه کنیم. فرمول واریانس را مینویسیم و به کمک جداول زیر، قدم به قدم واریانس را برای هر گروه پیدا میکنیم. انحراف معیار هم با گرفتن جذر واریانس تعیین میشود:
محاسبات گروه اول:
مرحله بعدی این است که آخرین سلول از ستون سوم جدول بالا را به تعداد دادهها تقسیم کنیم تا واریانس برای گروه اول بهدست آید:
بنابراین انحراف معیار برای اولین گروه داده برابر است با:
حالا میتوانیم ضریب تغییرات گروه اول را محاسبه کنیم:
محاسبات گروه دوم:
حالا باید آخرین سلول از ستون سوم جدول بالا را به تعداد دادهها تقسیم کنیم تا واریانس برای گروه دوم بهدست آید:
بنابراین انحراف معیار برای دومین گروه میشود:
و ضریب تغییرات گروه دوم نیز برابر است با:
پس ثابت کردیم که طبق محاسبات هم ضریب تغییرات گروه اول از ضریب تغییرات گروه دوم بیشتر میشود و این نتیجه با پیشبینی اولیه ما مطابقت دارد. همچنین به اهمیت محاسبه ضریب تغییرات برای بررسی دقیقتر دو مجموعه داده پی بردیم و دیدیم که ممکن است حتی با داشتن میانگین و ضریب دامنه مساوی، واریانس و در نتیجه پراکندگی دو مجموعه داده ما کاملا متفاوت باشد.
مثال
میانگین دمای ضبط شده برای یک بازه زمانی پنج روزه در زمستان سال گذشته بهصورت زیر گزارش شده است:
اگر میانگین این دادهها برابر با ۱۹٫۲ باشد، ضریب تغییرات را محاسبه کنید:
پاسخ
در این سوال مقدار میانگین دادهها داده شده است. پس تقریبا محاسبه آسانتری برای ضریب تغییرات با فرمول زیر در پیش داریم:
ابتدا باید انحراف معیار را پیدا کنیم که از واریانسی با فرمول زیر حاصل میشود:
دقت کنید چون پنج روز از کل روزهای سال انتخاب شده است، پس باید فرمول واریانس نمونه را استفاده کنیم که در آن مخرج یک واحد کمتر از تعداد کل دادهها است. پس در نهایت واریانس برابر میشود با:
بنابراین انحراف معیار میشود:
و ضریب تغییرات نیز برابر است با:
تمرین
ضریب انحراف چارک چیست و چگونه محاسبه میشود؟
در بخشهای قبل یاد گرفتیم انحراف چارک اندازه مطلقی از پراکندگی برای دادههایی با واحد مشابه را به ما میدهد. اما برای مقایسه تنوع دو یا تعداد بیشتری توزیع داده که در قالب واحدهای مختلفی بیان میشوند، نیاز داریم یک اندازهگیری نسبی روی پراکندگی داشته باشیم. به این منظور باید یک ضریب پراکندگی جدید به نام ضریب انحراف چارک یا CQD را محاسبه کنیم. برای محاسبه این ضریب کافی است ابتدا انحراف چارک را محاسبه کنیم و سپس آن را به مجموع مقادیر چارک اول و سوم تقسیم کنیم:
که در آن چارک بالا یا Q3 برابر است با اندازه آیتم ام، در حالی که چارک پایین یا Q1 با اندازه آیتم ام معادل است. پس فرمول ضریب پراکندگی برای انحراف چارک را هم یاد گرفتیم.

مثال
اگر دادههایی بهصورت زیر داشته باشیم، ضریب انحراف چارک چقدر است؟
| داده | فراوانی |
پاسخ
در این سوال دادههای گروهبندی شده داریم. پس لازم است در اولین قدم پس از مرتب کردن دادهها، فراوانی تجمعی را بهدست آوریم:
| داده | فراوانی | فراوانی تجمعی |
بنابراین با در نظر گرفتن n برابر با ۱۰۷ ادامه میدهیم. اولین قدم محاسبه چارک اول است که برابر میشود با اندازه آیتم ام:
آیتم بیست و هفتم در دادهها بین ۲۴ و ۵۳ در ستون سوم قرار دارد و داده معادل آن میشود ۲۴. پس چارک پایین برابر است با:
حالا میرویم سراغ چارک بالا که برابر است با اندازه آیتم ام:
آیتم هشتاد و یکم در ستون سوم جدول بین ۸۰ و ۱۰۷ قرار دارد. پس داده معادل با آن ۴۳ است:
با داشتن چارکهای بالا و پایین و با نوشتن فرمول ضریب انحراف چارک، بهراحتی کمیت موردنظر در سوال محاسبه میشود:
اندازهگیری پراکندگی و تمایل مرکزی
پس از اینکه انواع ضریب پراکندگی و فرمول محاسبه هر کدام را کاملا آموختیم، در این بخش میخواهیم اندازهگیری پراکندگی را با بررسی تمایل مرکزی مقایسه کنیم و ببینیم فواید و کاربرد هر کدام به چه صورت است. اندازهگیری پراکندگی و تمایل مرکزی هر دو جزء روشهایی هستند که برای توصیف دادهها بکار میروند. همچنین رابطه این دو اندازهگیری به این صورت است که هر چه پراکندگی دادههای ما در یک توزیع کمتر باشد، تمایل مرکزی بیشتر است.
اما باید به تفاوت این دو نیز کاملا آگاه باشیم. تفاوتهای این دو اندازهگیری عبارتاند از:
- تمایل مرکزی برای اعدادی بکار میرود که یک توصیف کمی از خواص مجموعه داده ما ارائه میدهند، در حالی که اندازه پراکندگی به منظور کمیسازی تنوع پراکندگی دادهها بکار میرود.
- اندازهگیری تمایل مرکزی با محاسبه کمیتهایی مانند میانگین، میانه و مد انجام میشود.
- اندازهگیری پراکندگی شامل پارامترهای بیشتری مثل دامنه، واریانس، انحراف معیار، انحراف میانگین و انحراف چارک است که برای محاسبه برخی از این پارامترها، نیاز داریم ابتدا میانگین، میانه یا مد را بهدست آوریم.
مسیر یادگیری کابردهای آمار و احتمال با فرادرس
با توجه به اینکه برای درک بهتر شاخههای جدید علم مانند «علم داده» (Data Science) نیاز به دانش قوی در زمینه مقدمات آمار و پراکندگی دارید، بنابراین در این بخش قصد داریم چند فیلم آموزشی مهم در رابطه با مباحث آمار و احتمال که با حوزه علم داده مرتبط است، به شما معرفی کنیم:

- فیلم آموزش آمار و احتمال مهندسی جامع و با مثال های مختلف فرادرس
- فیلم آموزش آمار ریاضی ۲ – آزمون فرض فرادرس
- فیلم آموزش مبانی احتمال مرور و حل تست کنکور ارشد فرادرس
- فیلم آموزش رایگان انواع داده در کامپیوتر فرادرس
- فیلم آموزش مفاهیم آماری در داده کاوی و پیاده سازی آن در پایتون Python فرادرس
- فیلم آموزش یادگیری ماشین و پیاده سازی در پایتون Python بخش یکم فرادرس
همچنین در لیست زیر برخی از کاربردیترین دورههای فرادرس را که شامل مفاهیم آماری در زمینه یادگیری ماشین، نحوه کار با نرمافزارهای آماری مانند اکسل یا SPSS میشوند را مشاهده میکنید:
- مجموعه آموزش اس پی اس اس SPSS – مقدماتی تا پیشرفته فرادرس
- فیلم آموزش آنالیز واریانس با اس پی اس اس SPSS فرادرس
- فیلم آموزش آمار مرور و حل سوالات آزمون های استخدامی فرادرس
- فیلم آموزش رایگان درخت تصمیم در یادگیری ماشین فرادرس
- فیلم آموزش محاسبات آماری در اکسل Excel فرادرس
جمعبندی
در این مطلب از مجله فرادرس آموختیم انواع مختلف فرمول ضریب پراکندگی چگونه تعریف میشوند. همچنین یاد گرفتیم درک مفهوم پراکندگی به ما نشان میدهد نحوه توزیع دادهها در یک مجموعه داده چگونه است و برای اینکه بتوانیم آن را اندازهگیری کنیم، نیاز است کمیتهای مختلفی محاسبه شوند. در جدول زیر، خلاصهای از تمام فرمولهای مورد نیاز در بررسی، اندازهگیری و تحلیل پراکندگی را جمعآوری کردهایم:
| ضریب پراکندگی | اندازهگیری نسبی پراکندگی | اندازهگیری مطلق پراکندگی |
| ضریب دامنه (QR) | ||
| ضریب انحراف میانگین (CMD) | ||
| ضریب تغییرات (CV) | ||
| ضریب انحراف چارک (CQD) |