



۱۵ مورد رایج خطا در تحلیل داده – راهنمای تصویری و کاربردی
دادهها در اقتصاد دادهمحور امروز نقش انکارناپذیری در کسب بینشهای نوین، تصمیمگیریها و ساخت محصولات جدید دارد. در واقع امروزه شاهد سیل فزاینده دادهها هستیم که حجمشان هر دو سال دو برابر میشود و تا سال 2025 به عدد حیرتانگیز 175 هزار اگزابایت داده خواهیم رسید. این عدد بسیار بزرگ و تصور کردن آن کاری دشوار است. برای آن که تخمینی از این عدد در ذهن خود داشته باشید، باید اشاره کنیم که این مقدار داده معادل 1,000,000,000 گیگابایت داده است. پنج اگزابایت داده تقریباً معادل همه واژههایی است که بشر در عمر خود صحبت کرده است. بدیهی است که وقتی صحبت از این حجم داده و تحلیل آنها میشود، بروز خطا نیز ناگزیر خواهد بود. با ما همراه باشید تا با انواع مختلف خطا در تحلیل داده و توضیح آنها آشنا شوید.




انواع رایج خطا در تحلیل داده
چنان که شاید متوجه شده باشید، بررسی همه این دادهها چالش بسیار بزرگی محسوب میشود. دادهها معمولاً شکلهای بسیار مختلفی دارند و تحلیل همه آنها آسان نیست. در نتیجه اغلب وسوسه میشویم که میانبرهایی روی دادهها به کار گیریم یا این که تلاش میکنیم دادههای ورودی را با نمادهای از پیش مشخصی که با آنها آشنا هستیم، تطبیق دهیم. در تصاویر زیر برخی از مغالطههای رایج را مشاهده میکنید که افراد در زمان تحلیل دادهها مرتکب میشوند.
15 مورد رایج خطا در تحلیل داده
در این بخش با 15 مورد رایج از خطا در تحلیل داده آشنا میشویم.
خطای انتخاب گزینشی (Cherry Picking)

در این نوع مغالطه، فرد نتایجی که با ادعایش مطابقت دارد را انتخاب کرده و آنهایی که ادعایش را رد میکند، کنار میگذارد.
خطای لایروبی دادهها (Data Dredging)

در این مغالطه، فرد اقدام به تست کردن فرضیههای مختلف روی یک مجموعه داده ثابت میکند و برخی از آنها که فرضیهاش را تأیید میکند گزارش کرده و بقیه را کنار میگذارد. به این ترتیب فرد نمیتواند درک کند که اغلب همبستگیهایی که مشاهده میکند، نتیجه تصادف است.
خطای اثر کبرا (Cobra Effect)

در این حالت اقدامی انجام مییابد که نتیجه آن معکوس چیزی است که در ابتدا قصد شده بود. این خطا به نام «نیت معکوس» نیز نامیده میشود.
خطای علیت نادرست (False Causality)

در این حالت فرد به اشتباه تصور میکند که وقتی دو رویداد در ظاهر مرتبط با هم رخ میدهند، لزوماً باید نتیجه یکدیگر باشند.

خطای سوگیری نمونه (Sampling Bias)

در این حالت فرد از یک مجموعه داده نتایجی به دست آورده و به جامعه مورد نظر تعمیم میدهد، اما نمونه مورد مطالعه نسبت به جمعیتی که باید مطالعه شود، گویا نیست.
خطای قمارباز (Gambler)

در این حالت فرد به نادرست بر این باور است که وقتی اتفاقی در گذشته بیشتر از حد معمول رخ داده است، در آینده باید کمتر رخ بدهد (و یا برعکس).
خطای بازگشت به میانگین (Regression towards the mean)

در این حالت فرد تصور میکند وقتی اتفاقی افتاده که به طور نامعمولی بد یا خوب است، در طی زمان به سمت مقدار میانگین خود بازخواهد گشت.
خطای پارادوکس سیمپسون (Simpson Paradox)

این حالت زمانی ایجاد میشود که روندی در زیرمجموعههای مختلفی از دادهها رخ دهد، اما هنگامی که این زیرمجموعهها را با هم ترکیب میکنیم، این روند ناپدید شده و یا حتی معکوس میشود.
خطای بیشبرازش (Overfitting)

در این حالت، فرد یک مدل ایجاد میکند که به طور کلی برای دادههایی که مورد بررسی هستند مناسب است، اما گویای روند کلی نیست.
خطای سوگیری انتشار (Publication Bias)

این خطا نشان میدهد که نتایج تحقیقاتی که جالبتر هستند، احتمال بیشتری برای پذیرش انتشار دارند و از این جهت درک ما از واقعیت را مورد اعوجاج قرار میدهند.
خطای سوگیری بقا (Survivorship Bias)

در این حالت از روی مجموعه ناقصی از دادهها، نتیجهگیری میشود، زیرا تنها بخشی از دادهها بر اساس یک معیار گزینشی باقی ماندهاند.

خطای کژحوزهبندی (Gerrymandering)

در این حالت، مرزهای جغرافیایی به منظور گروهبندی دادهها جهت تغییر دادن یک نتیجه خاص دستکاری میشوند.
خطای اثر هاوثورن (Hawthorne Effect)

این خطا بیان میکند که نظارت کردن بر یک فرد میتواند بر رفتار او تأثیر بگذارد و منجر به یافتههای نادرستی شود. این حالت به نام «اثر مشاهدهگر» نیز نامیده میشود.
مغالطه مکنامارا (McNamara fallacy)

در این حالت فرد تنها روی برخی معیارها در موقعیتهای پیچیده تمرکز میکند و به این ترتیب تصویر بزرگتر را از دست میدهد.
خطر معیارهای خلاصه (Summary Metrics)

در این حالت فرد تنها به بررسی معیارهای خلاصهبندی شده میپردازد و از این رو تفاوتهای فاحشی که در دادههای خام وجود دارد را از دست میدهد.
همه خطاهای فوق را به صورت یکجا و در اینفوگرافی جامع تصویر زیر میتوانید مشاهده کنید. برای دانلود تصویر روی این لینک (+) کلیک کنید. همچنین در صورتی که قصد دارید این اینفوگرافی را پرینت بگیرید، میتوانید این فایل PDF مناسب چاپ (+) را دانلود کنید.
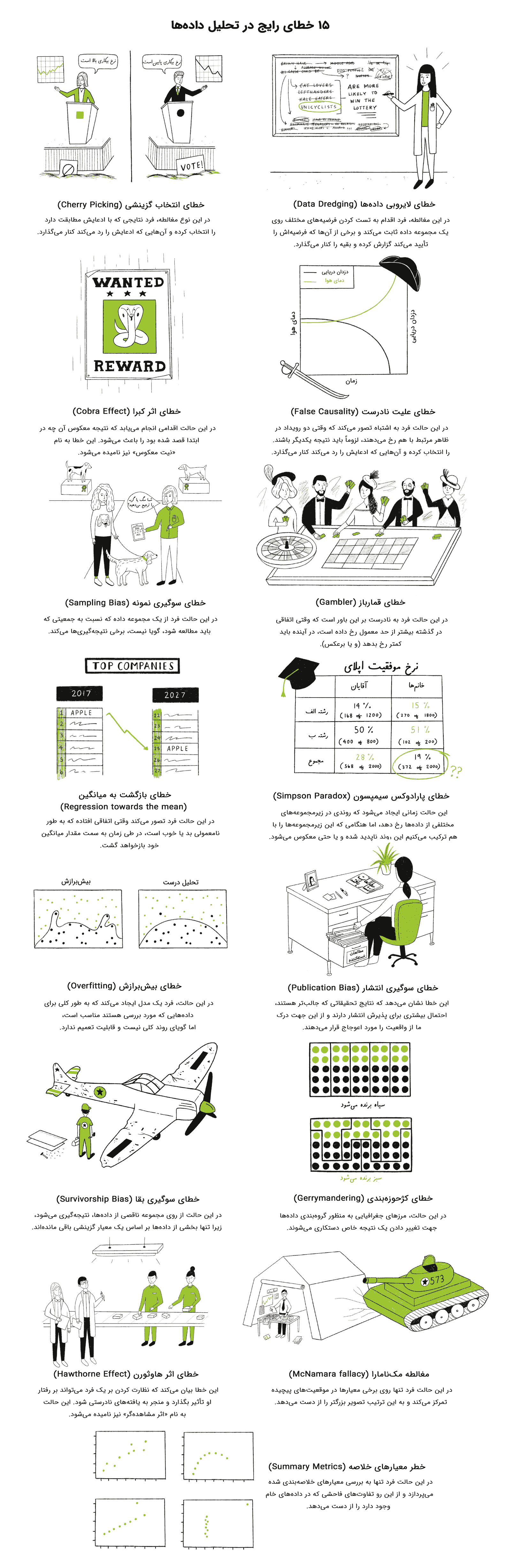
توضیح برخی از انواع خطای رایج در تحلیل داده
مغالطهها باعث میشوند که ما به دنبال کشیدن خال زیر محل اصابت تیر به سیبل باشیم و از این رو نمیتوانیم دادهها را به روشی منطقی، منسجم و روشمند تفسیر کنیم. برای جلوگیری از این حالت باید موارد رایج خطا در تحلیل داده را بشناسیم و بدانیم که چگونه خطاها موجب انحراف تفسیرهای ما میشوند. در این بخش با بررسی برخی مثالها با انواع خطاها و مغالطههای رایج که پیشتر اشاره کردیم، بیشتر آشنا خواهیم شد.

سوگیری بقا
هنگامی که افراد به دنبال بررسی مهارتهایی هستند که یک کارآفرین موفق داشته است، به طور معمول به بررسی جامعه کنونی کارآفرینهای موفق میپردازند. اما باید بدانید که وقتی نمونه مورد بررسی را به گروه باقیماندگان کارآفرینها محدود میکنید، ریسک مواجهه با سوگیری بقا را به همراه دارد.
درسهایی وجود دارند که میتوان از همه کارآفرینهایی که شکست خوردهاند آموخت، اما پیدا کردن این موارد دشوارتر است. با ادغام این دادهها با داستان موفقیت کارآفرینها میتوانیم تصویر کاملتری به دست آوریم.
علیت نادرست
آیا میدانید بین نرخ ازدواج در ایالت کنتاکی آمریکا و تعداد افرادی که هر سال بر اثر بیرون افتادن از قایق در این ایالت غرق میشوند، 95% همبستگی وجود دارد؟
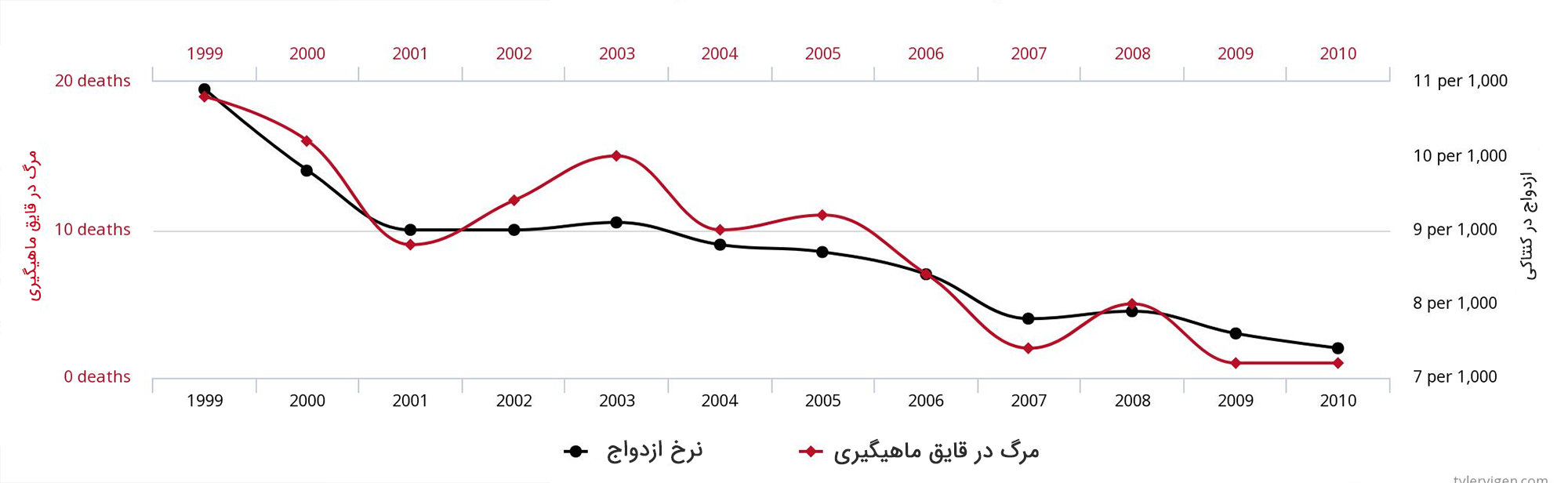
آیا این همبستگی بدان معنا است که رابطهای بین این دو متغیر وجود دارد؟ باید توجه داشت که وجود یک نرخ همبستگی بالا میتواند صرفاً بر اثر یک تصادف محض باشد. با این حال ارتکاب خطای «علیت نادرست» یکی از رایجترین خطاهای آماری اغلب افراد تازهکار است.
خطای قمارباز
اگر چرخ رولت 26 بار پشت سر هم روی ناحیه مشکی بایستد، آیا تضمینی هست که در دفعه 27 روی ناحیه قرمز بایستد؟
شاید اکنون که این سؤال را میخوانید به سادگی بگویید که ضریب موفقیت تغییری نمییابد، اما آیا وقتی در چنین موقعیتی قرار گرفتهاید نیز این طور فکر میکنید؟ خطای قمارباز در زمان تحلیل دادهها نیز رخ میدهد. این که اتفاقی در طی زمان به طور نامعمول بیش از حد نرمال رخ دهد، بدان معنی نیست که در نهایت این مقدار اضافه از سوی طبیعت به حالت نرمال باز خواهد گشت.
اثر کبرا
ما میتوانیم از دادهها برای اندازهگیری پیشرفت در رسیدن به اهداف تجاری کمک بگیریم، اما چه میشود اگر نیتی برای بازی گرفتن این اهداف در میان باشد؟
بانک «ولز فارگو» (Wells Fargo) یک ابتکار برای افزایش فروش به مشتریان موجود خود طراحی کرد و نام آن را «هشت خوب است» گذاشت. به طور خلاصه در این طرح هر کارمند بانک باید هشت حساب را به مشتریان میفروخت که این حسابها میتوانستند به صورت کارت اعتباری، حسابهای پسانداز و دیگر سرویسهای مالی باشند.
همان طور که میدانیم گاهی اوقات نیتهای خوب به نتایج خوبی منتهی نمیشوند. در این مورد نیز کارمندان بانک فارگو شروع به نقض قوانین برای دست یافتن به هدف هشت حساب کردند. به این ترتیب میلیونها حساب سپردهگذاری و کارت اعتباری غیرمجاز به خاطر این ابتکار بازاریابی ایجاد شد. در نهایت بانک فارگو مجبور به پرداخت جریمهای برابر با 142 میلیون دلار شد.
سخن پایانی
کار با دادهها بسیار حساس و خطیر و به طور مداوم در معرض بروز خطاهای گوناگون است. همچنین برخی افراد با اهداف متفاوت اقدام به سوءاستفاده از مغالطههای مختلف میکنند تا ادعاهای خود را علمی جلوه بدهند. آشنایی با انواع مختلف خطا در تحلیل دادهها به شما کمک میکند که در زمان اجرای تحلیل روی دادهها از بروز چنین مواردی جلوگیری کنید همچنین در صورتی که شخصی بخواهد با توسل به مغالطههای مختلف شما را فریب دهد، میتوانید سره را از ناسره تشخیص داده و راه درست را انتخاب کنید. در این مطلب تلاش کردیم تا شما را با برخی از رایجترین انواع خطا در تحلیل دادهها آشنا سازیم.










