



تجزیه مقادیر منفرد (SVD) – به زبان ساده
روش تجزیه مقادیر منفرد یا SVD تاریخچه طولانی و البته جالبی دارد. این روش، در علوم اجتماعی و با تست هوش شروع شد. در گذشته، پژوهشگران آزمونهایی را برای اندازهگیری جنبههای مختلف هوش مانند هوش فضایی و هوش کلامی ارائه کردند که همبستگی زیادی با هم داشتند. آنها بر این باور بودند که یک معیار عمومی مشترک برای هوش وجود دارد و آن را برای هوش کلی، نامیدند که امروزه بیشتر به عنوان آی کیو (IQ) شناخته میشود. بنابراین، پژوهشگران تصمیم گرفتند عوامل مختلف هوش را تجزیه و مهمترین آنها را انتخاب کنند. در سادهترین حالت، تجزیه مقادیر منفرد به نوعی همین تجزیه و انتخاب مهمترین عوامل یک ماتریس را انجام میدهد.
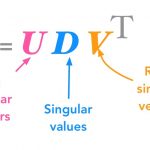
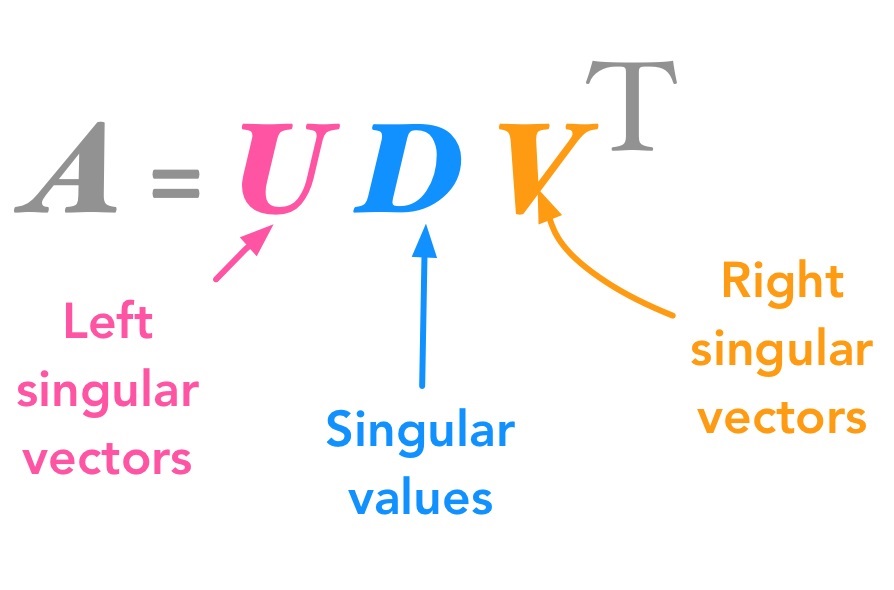


تجزیه مقادیر منفرد (Singular Value Decomposition) یا SVD با نامهای مختلفی شناخته میشود. این روش، ابتدا به عنوان «تجزیه عامل» (Factor Analysis) نامیده میشد. تحلیل مؤلفههای اصلی (Principal Component) یا PC و تجزیه توابع متعامد تجربی (Empirical Orthogonal Function) یا EOF نیز از دیگر اصطلاحات نزدیک به این روش است. همه این نامها از نظر مفهوم ریاضی معادل هستند، هرچند در فرایند محاسبه آنها تفاوتهای زیادی وجود دارد.
امروزه، تجزیه مقادیر منفرد در بسیاری از شاخههای علوم و نجوم کاربرد دارد. این روش، در یادگیری ماشین و آمار توصیفی و مدلسازی آماری نیز بسیار مورد استفاده قرار میگیرد.
محاسبات تجزیه مقادیر منفرد
به طور خلاصه میتوان گفت که تجزیه مقادیر منفرد روشی است که یک ماتریس را به سه ماتریس دیگر تجزیه میکند. برای مثال، ماتریس را میتوان به صورت زیر نوشت:

که در آن:
- یک ماتریس ؛
- یک ماتریس متعامد ؛
- یک ماتریس قطری
- و یک ماتریس متعامد است.
شکل بصری ابعاد ماتریسها به صورت زیر است:

ماتریس قطری مقادیر منفرد مربعی نیست، اما شکل آن مشابه است.
شکل زیر نیز، یک نمایش بصری از تجزیه مقادیر منفرد را نشان میدهد.

دلیل آنکه ماتریس آخر به صورت ترانهاده نوشته شده، در ادامه مشخص میشود. مفهوم عبارت «متعامد» و نیز دلیل متعامد بودن دو ماتریس کناری را نیز بیان خواهیم کرد.
فرض میکنیم باشد. رابطه ماتریسی (۱) را با استفاده از نمادگذاری سریها بازنویسی میکنیم. با نوشتن رابطه ماتریسی به صورت یک سری، اگر هم فرایند محاسبات ساده نشود، همه چیز کاملاً صریح خواهد شد:

توجه کنید که چگونه ماتریس قطری را به یک بردار تبدیل کردهایم و به صورت یک سری نوشتهایم. متغیرهای مقادیر تکین یا منفرد نام دارند و معمولاً از بزرگترین به کوچکترین نوشته میشوند:

ستونهای ، بردارهای منفرد چپ و ستونهای ، بردارهای منفرد راست نامیده میشوند.
از جبر خطی میدانیم و وقتی متعامد هستند که رابطه زیر برقرار باشد:

که در آن، ماتریس واحد یا همانی است. درایههای قطری ماتریس ، یک هستند و بقیه درایههای آن برابر با صفرند. ماتریس فقط در یک جهت متعامد است؛ یعنی نمیتوان گفت .
با استفاده از ویژگی تعامد، میتوانیم رابطه (۱) را به فرم دو معادله مقدار ویژه بنویسیم:


از آنجایی که تعداد سطرهای کوچکتر یا مساوی است، یک روند متداول و با محاسبات کمتر، قرار دادن معادله (۳) در یک محاسبهگر مقدار ویژه برای یافتن و و در نتیجه، یافتن با تصویر کردن در است:

توجه کنید که وقتی ترانهاده شود، مکان و تغییر میکند:

بنابراین، اگر باشد، میتوانیم ترانهاده را محاسبه کرده، تجزیه را انجام داده، سپس نقش و را تغییر دهیم.
در این حاالت، یک ماتریس مربعی است، زیرا حداکثر مقدار ویژه غیرصفر میتواند داشته باشد. در حالی که یک ماتریس است.
مفهوم SVD چیست؟
در بخش قبل، ریاضیات مربوط به SVD را بیان کردیم. اما همانطور که متوجه شدهاید، این ریاضیات درک شهودی از این روش به ما نمیدهد.
برای درک شهودی تجزیه مقادیر منفرد، میتوان ماتریس را به عنوان یک تبدیل خطی در نظر گرفت. این تبدیل را نیز میتوان به سه زیرتبدیل تجزیه کرد: ۱) چرخش یا دوران ۲) تغییر مقیاس ۳) چرخش. این سه گام متناظر با سه ماتریس ، و هستند. شکل زیر، این موضوع را به خوبی نشان میدهد.

در ادامه، در قالب یک مثال ساده دو بعدی با SVD بیشتر آشنا میشویم. روندی که بررسی خواهیم کرد، قابل تعمیم به ابعاد بزرگتر است.
مثال عددی
دو بردار دو بعدی و را در نظر بگیرید. همانطور که در شکل زیر نشان داده شده است، میتوانیم یک بیضی را با قطر بزرگ و قطر کوچک به این دو بردار منطبق کنیم. برای سادگی و کاهش محاسبات، معادلات را با استفاده از جبر ماتریسی مینویسیم.

معادله بیضی را با اندازه و دوران دلخواه و با کش دادن و چرخش یک دایره واحد مینویسیم. فرض کنید مختصات حاصل باشد که تحت تبدیل زیر قرار گرفته است:

که در آن، ماتریس دوران است:

و یک ماتریس قطری است که شامل قطرهای بزرگ و کوچک بیضی است:

بردار را در حالت کلی و به صورت جمله به جمله مینویسیم:

که در آن، برابر با اُمین درایه قطری ماتریس است و برای حالت دو بعدی داریم:

توجه کنید که دوران به صورت ساعتگرد است. زاویهها نسبت به مرجع نیز به صورت پادساعتگرد تعیین میشوند.
معادله دایره واحد به صورت زیر است:

مجموعه ها را در سطرهای ماتریس قرار میدهیم:

در نهایت، معادله ماتریسی به صورت زیر خواهد بود:

عبارت اخیر، در حقیقت، بازنویسی معادله (۳) است. اگر را به عنوان مجموعهای از نقاط در نظر بگیریم، آنگاه مقادیر منفرد، محورهای یک بیضی برازش شده با کمترین مربعات هستند، در حالی که دوران آن است. ماتریس تصویر هر نقطه در روی محورها است.
کاربردها
مجموع مربعات مقادیر منفرد باید برابر با واریانس کلی در باشد. بنابراین، اندازه هر یک از این مقادیر بیان میکند که چه مقدار از واریانس کلی برای هر بردار منفرد محاسبه میشود.
به عنوان جایگزین، میتوان یک SVD بریده را که شامل ۹۹ درصد واریانس است تشکیل داد:

که در آن، تعداد مقادیر منفردی است که آنها را نگه داشتهایم. معمولاً این تعداد کمتر از ۱۰ مقدار منفرد برجسته () خواهد بود. این، یکی از قابلیتهای تجزیه مقادیر منفرد برای استخراج حداقل مؤلفهها است.
حل معادلات ماتریسی
با بازنویسی معادله (۱) میتوانیم دستگاه معادلات خطی را حل کنیم:

معادلات بالا را میتوانیم به صورت مجموع سری زیر بنویسیم:

این معادلات را میتوان به ماتریسهای غیرمربعی تعمیم داد. از آنجایی که یک ماتریس که در آن است، تنها مقدار منفرد خواهد داشت، در استفاده از تجزیه مقادیر منفرد، با حل یک ماتریس معادل با مقدار منفرد مواجه خواهیم بود. برای ماتریسهای غیرمربعی، معکوس ماتریس با استفاده از تجزیه مقادیر منفرد، برابر با حل معادله معمولی زیر خواهد بود:

این معادله، جواب را که نزدیکترین به مبدأ است و کمترین فاصله را از آن دارد به دست میدهد. معادله معمولی، جواب مسئله کمینهسازی زیر است:

کاهش داده
یکی چالشهای متداول در یادگیری ماشین، وجود چند صد متغیر است، در حالی که بسیاری از الگوریتمهای یادگیری ماشین، اگر با تعدادی بیش از یک مقدار مشخص متغیر کار کنند، با شکست مواجه میشوند. این موضوع، استفاده از تجزیه مقادیر تکین را برای کاهش متغیر در یادگیری ماشین ضروری میکند.
اگر تعداد و انواع مناسبی از ویژگیها برای حل یک مساله خاص به الگوریتمهای یادگیری ماشین داده شود، این الگوریتمها به خوبی کار میکنند. اما، در صورتی که تعداد ویژگیها (متغیرها) بسیار زیاد باشد، اغلب الگوریتمهای یادگیری ماشین در حل مسئله دچار مشکل میشوند، زیرا با مسئله «دادههای ابعاد بالا» (High Dimensional Data) مواجه خواهیم بود. در اینجا است که بحث «کاهش ابعاد» (Dimensionality Reduction) مطرح میشود.
قبلاً در معادله (۶)، گفتیم که چگونه یک SVD با کاهش تعداد مقادیر تکین میتواند یک ماتریس را بسیار دقیق تقریب بزند. از این ویژگی میتوان برای فشردهسازی دادهها با فرمهای کوتاه شده ، و به جای و برای کاهش متغیر از جایگزینی با استفاده کرد. البته در پایان، بر اساس معادله (۴) باید با ضرب و نتایج را به دستگاه مختصات اصلی تبدیل کرد.
در ادامه، مثالی را درباره این موضوع بیان و برنامه کامپیوتری آن را نیز ارائه میکنیم.
مثال کاهش متغیر
فرض کنید ماتریس با ابعاد ، مجموعهای از دادههای آموزش را با هر بردار آموزش در هر سطر رابطه (۵) ذخیره میکند و طول هر بردار و عددی بسیار بزرگ است.

میخواهیم را به الگوریتم خوشهبندی وارد کنیم که خروجی آن، یک عدد ثابت از مراکز خوشه است. از آنجایی که بسیار بزرگ است، اجرای الگوریتم بسیار طول خواهد کشید یا ناپایدار خواهد شد. بنابراین، تعداد متغیرها را با استفاده از SVD کاهش میدهیم. مراحل زیر، فرایند انجام این کار را نشان میدهند.
گام اول: خواندن دادهها
در ابتدا، باید دادهها را برای تکمیل ماتریس بخوانیم. برنامه مربوط به این گام از فرایند، به صورت زیر است:
گام دوم: تعریف SVD
از برنامه تجزیه مقدار تکین آماده در فایل هِدِر (header)، استفاده میکنیم:
معمولاً مقادیر تکین، با توجه به نوع ماتریس و بردار مورد استفاده، اغلب پیچیدهتر از این است. البته این برنامه، برای قرار دادن همه موارد در یک تابع فشرده مناسب است. در ادامه بخش قبل، داریم:
گام سوم: تحلیل خوشه
الگوریتم خوشهبندی، یک مجموعه از مراکز خوشه را تولید میکند، به گونهای که :
در ادامه، مراکز خوشهها را تعیین میکنیم:
از آنجایی که الگوریتم خوشهبندی از دادههای آموزش جدید استفاده میکند، مراکز خوشهها در سیستم جدید به صورت زیر محاسبه میشوند:

یا

با نوشتن جزء به جزء جملات، داریم:

که در آن، تعداد مختصاتها در سیستم کاهش یافته است.
گام چهارم:
در این مرحله، مراکز خوشه را در دستگاه مختصات قبلی ذخیره کرده و سپس، معادله (۱۰) را اعمال میکنیم.
اگر علاقهمند به یادگیری مباحث مشابه مطلب بالا هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- بردار ویژه و مقدار ویژه — از صفر تا صد
- تقلب نامه (Cheat Sheet) جبر خطی برای یادگیری ماشین — راهنمای سریع و کامل
- تحلیل مولفه اساسی (PCA) در پایتون — راهنمای کاربردی
^^











بسیار مفید بود فقط همونطور که دوست عزیز دیگه ای هم فرمودن لطفا حداقل در پرانتز واژه های لاتین معادل اصطلاحات رو استفاده کنید. خسته نباشید عالی و کاربردی!
سلام.
از اینکه این مطلب برایتان مفید بوده، خوشحالیم. همه معادلهای انگلیسی در ابتدای متن ذکر شدهاند.
سالم و موفق باشید.
مطالب تهیه شده توسط اساتید فرادرس بسیار روان وجالب هستند.تشکر از زحماتتون . اگر اصطلاحات وبرگردان هایی که به فارسی شده ذکر گردندکه برگردان چه کلمه لاتینی است خیلی خوب میشه تا بتوان درکنارآشنایی تحقیق بیشتری روی آن ها انجام داد.
سلام
خیلی مفید و کاربردی بود
یکی از کاربردهای آن در شبیه سازی های داینامیک هست و با کمک svd میشه شبیه سازی های برف یا شن یا حتی اجسام elastic رو انجام داد
برای پیاده سازی این سیستم مطلب شما در فهم svd خیلی کمکم کرد
این واقعا چیزی بود که من بشه نیاز داشتم.
ممنون.