



شبکه عصبی مصنوعی و پیادهسازی در پایتون – راهنمای کاربردی
اغلب با واژه «شبکه عصبی مصنوعی» (Artificial Neural Network) برخورد کردهایم و به نظر میرسد که باید این مفهوم به شکلی با شبکه عصبی موجودات زنده در ارتباط باشد. شبکه عصبی مصنوعی را به اختصار گاهی ANN نیز مینامند. ساختار اصلی مغز و شبکههای عصبی طبیعی از «نورون» (Neuron) یا «سلول عصبی» تشکیل شده است. هر نورون در موجودات زنده از سه بخش اصلی تشکیل شده است. ۱- جسم یاختهای (سلول)، ۲- دندریت، ۳- آکسون. سلول عصبی به شکل یک درخت است که در آن دندریت اطلاعات را از طریق سرشاخههایی از سلولهای عصبی دیگر دریافت میکند و به جسم سلولی (یاخته) میدهد. نتیجه تحلیل سلول عصبی توسط آکسون انتقال یافته و بوسیله سرشاخههای به نام «سیناپس» (Synapse) به سلولهایی از نوع عصبی، عضلانی یا حسی ارسال میشود.



با الگو گرفتن از این سلولها، شبکههای عصبی مصنوعی نیز در دو دهه است که ظهور کردهاند و البته کاربردهای زیادی بخصوص در «بهینهسازی» (Optimization) و «هوش مصنوعی» (Artificial Inelegance) دارند. در این نوشتار به بررسی شبکه عصبی مصنوعی آشنا خواهیم شد و بوسیله مفاهیم و مبانی اولیه ریاضی سعی میکنیم از آن برای حل مسائل بهره ببریم. به منظور پیادهسازی محاسبات در شبکه عصبی از زبان برنامهنویسی پایتون استفاده خواهیم کرد.
برای آشنایی با انواع شبکه عصبی و کاربردهای آنها، بهتر است مطلب شبکههای عصبی مصنوعی – از صفر تا صد را مطالعه کنید. همچنین خواندن مطالب مرتبط با هوش مصنوعی در نوشتار فراگیری مفاهیم هوش مصنوعی — مجموعه مقالات جامع وبلاگ فرادرس نیز خالی از لطف نیست.
شبکه عصبی مصنوعی (ANN)
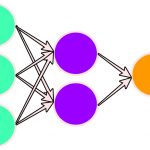
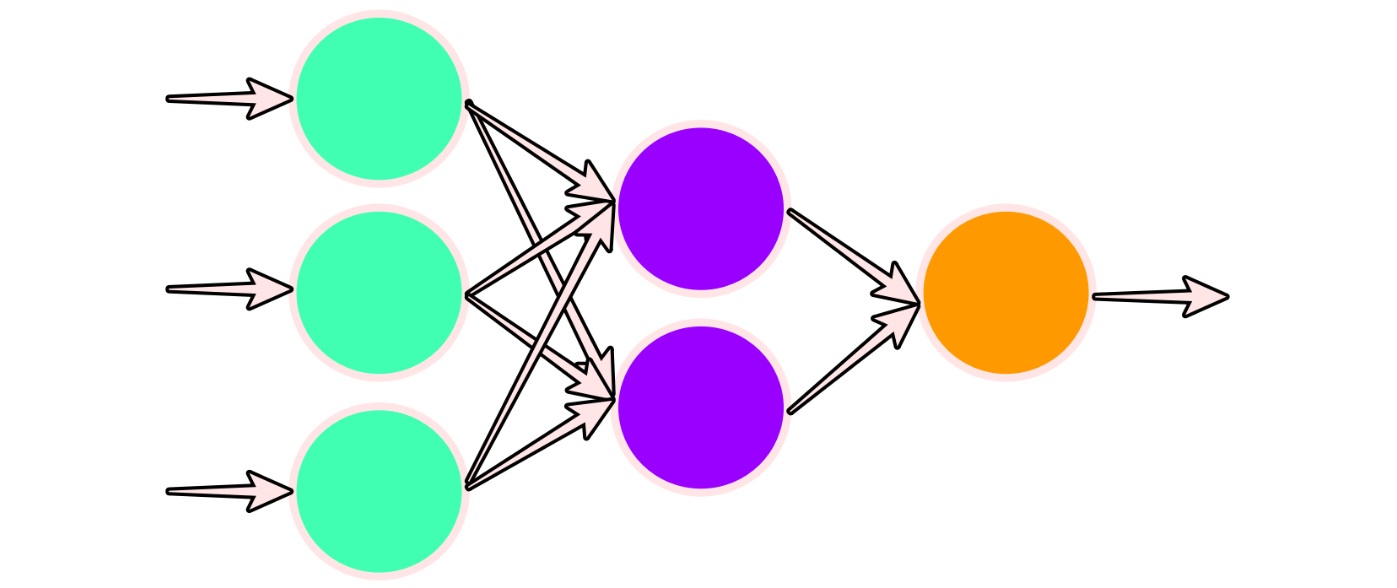
با الگو گرفتن از ساختار یک سلول و شبکه عصبی طبیعی، میتوان یک سلول و شبکه عصبی مصنوعی ساخت. در تصویرهای زیر مقایسهای بین سلول عصبی طبیعی و مصنوعی صورت گرفته است.
در تصویر اول، خلاصهای از شکل یک سلول عصبی طبیعی دیده میشود که براساس آن ساختار یک سلول عصبی مصنوعی ایجاد شده که در تصویر دوم قابل مشاهده است.


همانطور که دیده میشود، یک سلول عصبی مصنوعی ساختار بسیار سادهای دارد. سیگنال یا دادههای ورودی دارای دو مشخصه هستند. مقدار متغیر و وزن یا اهمیت آن مقدار. ورودی یک سلول عصبی مصنوعی حاصلضرب مقدارها در وزنهای مربوطه است. معمولا ورودیها به بردار مقدارها و بردار وزنها در نظر گرفته میشوند.
زمانی که یک سینگال یا ورودی به سلول وارد میشود، با ورودیهای دیگر تجمیع شده و براساس تابعی محاسباتی (که معمولا یکی از انواع «تابع زیان» (Loss Fucntion) در نظر گرفته میشود)، مقدار خروجی حاصل میشود. ممکن است برای مثال تابع محاسباتی جمع باشد. این کار درون سلول عصبی صورت میگیرد. تابع خروجی یا «تابع فعالسازی» (Activation Function) براساس این محاسبه مقدار خروجی را تعیین میکند. یکی از معمولترین توابع فعال سازی، «تابع باینری» (Binary Function) است که به صورت یک «تصمیم صفر و یک» (Binary Decision) خواهد بود. تصویر زیر این مراحل را به خوبی نشان میدهد.
در اینجا وزن و هر ورودی هستند. تابع محاسبه شده در پرسپترون نیز میتواند به صورت جمع وزنی مقادیر باشد. در صورتی که این جمع از مقدار خاصی بیشتر شود، مقدار تابع فعالسازی برابر با ۱ و در غیر اینصورت برابر با صفر خواهد بود. البته جمله در محاسبه سلول پرسپترون به همراه یک مقدار اریبی (Bias) مثل ظاهر شده است.
بنابراین اگر یک شبکه عصبی مصنوعی را ترکیبی از سلولهای عصبی مصنوعی در نظر بگیریم، ساختار آن را میتوانیم به صورت زیر تصور کنیم.

در ادامه به بررسی یک شبکه عصبی ساده و پیادهسازی آن در پایتون به منظور تشخیص و خوشهبندی دو گروه داده خواهیم پرداخت.
پیادهسازی شبکه عصبی در پایتون
به منظور آشنایی با نحوه عملکرد یک شبکه عصبی و ارتباط بین سلولهای عصبی (پرسپترون) از یک مثال با کدهای پایتون برای ایجاد و محاسبه عملگر AND در محاسبات دودویی استفاده میکنیم. فرض کنید دو ورودی Input1 و Input2 به شبکه وارد شده و قرار است ساختاری به مانند زیر به عنوان خروجی در Output ایجاد شود. این دقیقا همان جدول ارزش برای ترکیب عطفی گزارههای منطقی است.

از کدهایی زیر به این منظور استفاده شده است. توجه داشته باشید که در اینجا به ورودیها هیچ وزنی داده نشده است در نتیجه همه ورودیها اهمیت یکسانی (وزنی برابر با 0.5) دارند. بنابراین اگر هر مقدار باینری (۰ یا ۱) به عنوان Input1 و Input2 به سلول عصبی خورانده شود در مقدار وزن 0.5 ضرب شده و حاصل جمع آنها محاسبه میشود. اگر این مجموع از 0.5 کوچکتر باشد، جواب صفر و در غیراینصورت جواب یا خروجی ۱ خواهد بود.
همانطور که در کد قابل مشاهده است، تعیین وزنها در بخش __def__init صورت گرفته است. همچنین استفاده از وزنها و محاسبه ورودیها در بخش ــdef__call قابل مشاهده است. همچنین تابع فعالسازی نیز در قسمت staticmethod@ قابل تشخیص است. مجموعه این بخشها یک کلاس پایتون به نام Perceptron را تشکیل میدهد.
با توجه به ورودیها که توسط حلقه for ایجاد شده است، محاسبات در شبکه عصبی صورت گرفته و نتیجه اجرای کد در متغیر y ثبت شده است. در انتها نیز با دستور print ورودیها و خروجی نمایش داده شدهاند. با اجرای این کد خروجی به صورت زیر خواهد بود.
تفکیک و تشخیص دو گروه به کمک شبکه عصبی
در ادامه با کد و برنامهای کار خواهیم کرد که به کمک شبکه عصبی، قادر به تشخیص دو خوشه یا دو کلاس از اشیاء در فضای دو بُعدی است. نقاطی که در تصویر زیر میبینید اعضای خوشهها یا کلاسها را نشان میدهند.

نکته: در اینجا معادله خط مورد نظر را با رگرسیون و مدل خطی اشتباه نگیرید. در رگرسیون هدف برآورد و مشخص کردن پارامترهایی است که به کمک آن نقاط قابل پیشبینی هستند ولی در این مسئله، موضوع مربوط به خطی است که بیشترین تفکیک را بین کلاسها ایجاد میکند.

قرار است پارامترهای معادله یک خط به عنوان خط تفکیک کننده توسط شبکه عصبی شناسایی و برآورد شود. در اینجا خط L را که وظیفه تفکیک را به عهده دارد، به نام «مرز تصمیم» (Decision Boundary) میشناسیم.

کدهایی که در ادامه مشاهده میکنید به این منظور نوشته شده است. مشخص است که قسمتی از کد قبلی در اینجا هم دیده میشود. وزن هر مشاهده در این برنامه به صورت زیر در نظر گرفته شده است.
خروجی و نمودار حاصل از اجرای این برنامه در ادامه قابل مشاهده است.

حال فرض کنید که برای نقاط، وزنها به صورت زیر تعریف شده باشند.
این امر نشان میدهد که برای مقدارهای بزرگتر از 0.5 وزن افزایش داشته ولی برای مقدارهای کوچکتر از آن، وزن منفی خواهد بود. پس انتظار داریم نیمی از نقطهها بالا و نیمی نیز در پایین خط قرار گیرند.
از آنجایی که تولید اعداد به صورت تصادفی است ممکن است با هر بار اجرای این برنامه خروجیهای متفاوتی دریافت کنید. ولی برای مثال یکی از حالتهایی گوناگون را نتیجه اجرای برنامه است، در ادامه آوردهایم.
این خروجی نشان میدهد که حدود ۷ مورد از نقاط توسط خط، به درستی در گروه خود قرار نگرفتهاند و میزان کارایی الگوریتم و معادله خط در تشخیص نقاط حدود ۹۳ درصد است. با توجه به شرایط مسئله و وزنهای مثبت و منفی، برای معادله خط باید رابطه زیر بین نقاط در نظر گرفته شود تا حاصل جمع (که همان تابع فعالسازی است) اریبی نداشته باشد.
برای مثال اگر را با وزن و را را وزن در نظر بگیریم، خواهیم داشت.
بنابراین چون معادله یک خط به صورت نوشته میشود، معادله خط جداکننده برای این مشاهدات از مرکز مختصات عبور خواهد کرد ولی شیب آن تقریبا برابر با 1.02 است. حال فرض کنید که وزنها متفاوت باشند. در این صورت نسبت آنها برابر با یک نخواهد بود. در اینجا وزنها براساس رابطه زیر بدست میآید.
همانطور که در ادامه میبینید، همان محاسبات قبلی به همراه خطوطی از کدهای جدید وجود دارد. این کد البته نمودار مربوط به نقاط را هم ترسیم میکند. توجه داشته باشید که این خطوط را در ادامه کد قبلی قرار داده شده و اجرا شوند.
خروجی به صورت زیر و به همراه نمودار خواهد بود. همانطور که دیده میشود دو خط ترسیم شده و برای دو شکل از معادله خط نمودار ظاهر شده است. عددی که در زیر مشاهده میکنید شیب خطی است که شبکه عصبی جدید برای دادهها مشخص کرده است. همانطور که مشخص است این شیب کمی با مقدار ۱ متفاوت است.

در ادامه به بررسی کدی میپردازیم که براساس وزنهای مختلف در شبکه عصبی، محاسبات را انجام میدهد. کدهایی که در ادامه قابل مشاهدهاند به منظور تولید دادهها در دو کلاس و با وزنهای متفاوت ولی بدون اریبی (عرض از مبدا) نوشته شدهاند.
پس از به کارگیری شبکه عصبی و اجرای برنامه، برای تفکیک این نقاط، میزان دقت تشخیص و شیب خط به صورت زیر است. به نظر میرسد که مدل ایجاد شده دارای دقت کافی نیست.

همانطور که به نظر میرسد، مدل مورد نظر نتوانسته به خوبی خوشهها را پیشبینی کند زیرا نقطههای آبی در حول مرکز با مختصات (0,0) پراکنده هستند. بنابراین وجود اریبی اینجا ضروری است تا شبکه عصبی، بهتر خوشهها را از یکدیگر تفکیک کند. در نتیجه به معادله خطی احتیاج داریم که دارای عرض از مبدا باشد.
شبکه عصبی تک لایه با میزان اریبی
همانطور که گفته شد، نشانگر عرض از مبدا یا محلی است که خط ترسیم شده محور عمودی را قطع میکند. ولی در قسمت قبلی مدل خطی که ایجاد کردیم از مرکز مختصات میگذشت در نتیجه عرض از مبدا برای آن صفر بود.

برای چنین حالتی میتوانیم میزان اریبی را نیز مشخص کرده و مدل جدیدی را برای دادهها لحاظ کنیم. تصویر زیر یک شبکه عصبی با وجود اریبی به اندازه را نشان میدهد.

در این حالت رابطهای که باید در پرسپترون شبکه عصبی لحاظ کرد به صورت زیر است.
به این ترتیب بین طول و عرض نقاط خط تفکیک کننده باید رابطه زیر برقرار باشد.
در کد زیر یک کلاس پرسپترون با وزنهای مختلف و البته اریبی نوشته شده است. اصول و نحوه عملکرد درست به مانند حالت قبل است به جز اینکه در میزان وزندهی و اریبی تفاوت وجود دارد. همانطور که مشخص است از توزیع یکنواخت (Uniform Distribution) که با تابع np.random.uniform مشخص شده، برای تولید اعداد تصادفی استفاده شده است. در ضمن از تابع سیگموئید (Sigmoid) که با sigmoid_function معرفی شده، به عنوان تابع فعالسازی استفاده شده است.
خروجی و نمودار ترسیم شده در این حالت به صورت زیر خواهد بود.
همانطور که دیده میشود، دقت تفکیک نقطهها بسیار بهبود یافته است. شیب و عرض از مبدا برای خط تفکیک کننده نیز منفی است و مدل حدود ۹۰٪ موفق بوده است.

اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- آموزش شبکههای عصبی مصنوعی در متلب
- مجموعه آموزشهای هوش محاسباتی
- ساخت شبکه عصبی (Neural Network) در پایتون — به زبان ساده
- شبکه عصبی پیچشی (Constitutional Neural Networks) — به زبان ساده
^^







