پاکسازی داده چیست؟ – Data Cleaning از صفر تا صد
همزمان با تولید روزانه حجم عظیمی از داده و اطلاعات، پردازش داده به موضوعی مهم برای بسیاری از صنایع و کسبوکارها تبدیل شده است. دادههای خام بهندرت تمیز و همگن هستند و این مسئله باعث میشود نتوانیم به نتایج مورد انتظار خود از مدلهای یادگیری ماشین دست پیدا کنیم. به همین دلیل، بسیاری از شرکتهای بزرگ هزینه زیادی صرف استخدام متخصصان علم داده میکنند. بهطور معمول، دادههای نامرتب در نتیجه مواردی همچون خطای انسانی یا ترکیب دادهها از چند مرجع متفاوت ایجاد میشوند. در این مطلب از مجله فرادرس، یاد میگیریم پاکسازی داده چیست و با شرح مثالهایی، از اهمیت آن در کاربردهایی مانند تحلیل داده و ساخت مدلهای یادگیری ماشین آگاه میشویم. از آنجا که دادههای نامرتب نتیجهای جز خروجی بیکیفیت ندارند، متخصصان علم داده، بیشتر زمان خود را صرف پیدا کردن روشهایی برای پاکسازی یا تمیزسازی داده ها میکنند.
- با مفهوم پاکسازی داده و اهمیت آن در تحلیل دقیق آشنا میشوید.
- میتوانید خطاهای داده مانند مقادیر گمشده یا ناهماهنگ را تشخیص دهید.
- با مراحل اصلی پاکسازی مانند شناسایی و اصلاح داده آشنا میشوید.
- میتوانید تفاوت تمیزسازی، پالایش و پاکسازی داده را درک کنید.
- روشهای حذف یا اصلاح دادههای نادرست را یاد میگیرید.
- میتوانید دادهها را برای تحلیل و تصمیمگیری بهتر آماده کنید.




در این مطلب، ابتدا به پرسش پاکسازی داده چیست پاسخ میدهیم و با اهمیت آن در یادگیری ماشین میشویم. سپس از تفاوت میان سه مفهوم تمیزسازی داده، پالایش داده و پاکسازی داده میگوییم و شرحی از مراحل پاکسازی داده ارائه میدهیم. در ادامه، هر کدام از مراحل پاکسازی داده را با استفاده از زبان برنامهنویسی پایتون پیادهسازی میکنیم و به معرفی ابزارها و همچنین پروژههای موجود در این زمینه میپردازیم. در انتهای این مطلب از مجله فرادرس، با مزایا و چالشهای پاکسازی داده آشنا میشویم و به چند نمونه از سوالات متداول پیرامون پاکسازی داده پاسخ میدهیم.
پاکسازی داده چیست؟
در اصطلاح داده کاوی، تمیزسازی یا «پاکسازی داده» (Data Cleaning) مرحلهای از یادگیری ماشین است که در آن، دادهها شناسایی و نمونههای ناقص یا تکراری حذف میشوند. دادههای نامرتب و پرخطا، در عملکرد مدلهای یادگیری ماشین تاثیر منفی میگذارند. به همین خاطر، هدف از پاکسازی یا پالایش داده، اطمینان حاصل کردن از دقت و مرتب بودن دادهها است.
متخصصان علم داده بر این باور هستند که الگوریتمهای مفید و ارزشمند تنها از دادههای با کیفیت حاصل میشوند و از همین جهت، بخش زیادی از هزینه و زمان خود را صرف این مرحله، یعنی پاکسازی داده میکنند. در نتیجه، پاکسازی داده که گاهی با عناوین «تمیزسازی داده» (Data Cleansing) و «پالایش داده» (Data Scrubbing) نیز شناخته میشود، قدمی ضروری در علم داده برای اصلاح خطاها و بهبود کیفیت دادهها است.

اهمیت پاکسازی داده چیست؟
بهطور معمول هرگاه از مدیریت داده صحبت میکنیم، در واقع به پاکسازی دادهها اشاره داریم. اغلب، هنگام کار با پروژههای عملی در حوزه علم داده و یادگیری ماشین با مشکلاتی در زمینه کیفیت دادهها مواجه میشوید. برخی از این مشکلات عبارتاند از:
- «دادههای گمشده» (Missing Data)
- «دادههای تکراری» (Duplicate Data)
- «دادههای پرت» (Outliers)
- «دادههای پر اشتباه» (Erroneous Data)
- «دادههای نامرتبط» (Irrelevant Data)
طراحی و ساخت مدل یادگیری ماشینی که قادر به درک دادهها باشد، نیازمند پیشپردازش و پالایش داده بسیاری است. نحوه یادگیری کامپیوتر متفاوت از انسان است و از همین جهت، هر نوع دادهای ابتدا باید به نوع عددی و قابل درک برای کامپیوتر تبدیل شود. در ادامه، بیشتر با اهمیت فرایند تمیزسازی داده، در ساخت یک مدل یادگیری ماشین کارآمد آشنا میشویم.
تفاوت تمیزسازی داده، پالایش داده و پاکسازی داده چیست؟
پاکسازی داده، تمیزسازی داده و پالایش داده، اغلب عباراتی هستند که بهجای یکدیگر استفاده میشوند. اگرچه در بیشتر اوقات منظور یکسانی از هر سه عبارت برداشت میشود. اما گاهی نیز، پالایش داده تنها قسمتی از فرایند پاکسازی داده است که وظیفه حذف دادههای قدیمی، غیر ضروری و تکراری را از «مجموعهداده» (Dataset) بر عهده دارد.

پاکسازی داده شامل چه مراحی است؟
حالا که بهخوبی میدانید منظور از پاکسازی داده چیست، در این بخش، به شرح مراحل انجام پاکسازی داده میپردازیم. پاکسازی داده فرایندی هدفمند برای تشخیص و اصلاح خطاهای موجود در مجموعهداده است. در فهرست زیر به مراحل اصلی پاکسازی داده اشاره کردهایم:

- حذف نمونه دادههای نامرتبط: در این مرحله از پاکسازی داده، ابتدا هر کدام از نمونهها بررسی شده و سپس دادههای اضافی، اطلاعات تکراری یا نقاط دادهای که مشارکتی در فرایند تجزیه و تحلیل ندارند، حذف میشوند. به این صورت، علاوهبر منظم شدن مجموعهداده یا همان دیتاست، تعداد اطلاعات نویزی کاهش یافته و کیفیت نهایی افزایش پیدا میکند.
- رفع خطاهای ساختاری: منظور از خطاهای ساختاری، مواردی از جمله ناهماهنگی در فرمت دادهها و عدم وجود قواعدی یکپارچه برای نامگذاری متغیرها است. در نتیجه، این مرحله به استانداردسازی فرمت دادهها و اصلاح نامگذاری متغیرها اختصاص دارد. رفع خطاهای ساختاری، باعث ایجاد هماهنگی میان دادههای شده و تحلیل و تفسیر دقیق دادهها را تسهیل میبخشد.
- مدیریت دادههای پرت: وظیفه این مرحله در شناسایی و مدیریت نقاط داده پرت یا همان نمونههای متفاوت از «نرم» (Norm) خلاصه میشود. بسته به نوع مسئله، گاهی دادههای پرت بهطور کلی حذف شده و در سایر مواقع به نوعی قابل استفاده تبدیل میشوند. مدیریت دادههای پرت نقش مهمی در کیفیت اطلاعات حاصل از پردازش دادهها دارد.
- مدیریت دادههای گمشده: بررسی و مدیریت دادههای گمشده، نیازمند نوعی راهکار هدفمند است. راهکارهایی از جمله «جایگزینی» (Imputing) بر اساس روشهای آماری و حذف نمونههایی که شامل مقادیر گمشده هستند. در نتیجه مدیریت موثر دادههای گمشده، به مجموعهدادهای جامع منجر شده که از احتمال وجود مشکلاتی مانند «بیشبرازش» (Overfitting) و «کمبرازش» (Underfitting) در مدلهای یادگیری ماشین میکاهد.
چگونه مرتب سازی دیتا فریم در پایتون را یاد بگیریم؟

زبان برنامهنویسی پایتون، بهنوعی محبوبترین ابزار در داده کاوی و همچنین یادگیری ماشین است. از جمله کاربردیترین کتابخانههای این زبان برنامهنویسی میتوان به Pandas اشاره کرد که اغلب برای پردازش هر نوع مجموعهدادهای به آن نیاز پیدا میکنید. پس از فراخوانی دیتاست مدنظر در محیط برنامهنویسی، دادهها با فرمتی تحت عنوان «دیتافریم» (Dataframe) که مختص کتابخانه Pandas است، ذخیره میشوند و ادامه فرایند پردازش داده به دانش و مهارت شما در کار با این نوع داده بستگی دارد. از همین جهت و در صورتی که قصد دارید مهارتهای خود را در این زمینه توسعه دهید، مشاهده فیلمهای آموزشی فرادرس را به ترتیب زیر پیشنهاد میدهیم:
- فیلم آموزش رایگان کار با دیتافریم ها در پکیج Pandas فرادرس
- فیلم آموزش رایگان پانداس pandas برای تحلیل اطلاعات در پایتون فرادرس
- فیلم آموزش تجزیه و تحلیل و آماده سازی داده ها با پایتون فرادرس
پاکسازی داده چگونه انجام می شود؟
برای شروع فرایند تمیزسازی و پالایش داده، ابتدا باید شناخت کاملی از دادهها داشته باشیم و با بررسی ساختار مجموعهداده، به شناسایی مشکلاتی از قبیل دادههای گمشده، پرت و تکراری بپردازیم. در حالی که برای رفع مشکل دادههای گمشده اجرای دو روش جایگزینی و حذف امکانپذیر است، راهی بهجز حذف دادههای تکراری برای کاهش افزونگی وجود ندارد. همچنین، با رسیدگی به دادههای پرت، مطمئن میشویم که مقادیر خارج از نرم، تاثیری بر نتایج تجزیه و تحلیل نداشته باشند. خطاهای ساختاری نیز از طریق استانداردسازی فرمت و نوع متغیرها قابل حل هستند.

پیشنهاد میشود در طول فرایند تمیزسازی داده، بهمنظور شفافیت و حفظ قابلیت تکرارپذیری در آینده، تمامی تغییرات مستندسازی شوند. ارزیابی و آزمودن مدل یادگیری ماشین، اثربخشی فرایند پاکسازی داده را تایید کرده و در نهایت نیز به مجموعهدادهای مطمئن برای سایر مسائل و کاربردها ختم میشود.
پاکسازی داده ها در پایتون
حالا که به خوبی میدانید منظور از پاکسازی داده چیست، در این بخش، نحوه پیادهسازی مراحل مختلف پاکسازی داده را با استفاده از زبان برنامهنویسی پایتون و دیتاست «تایتانیک» (Titanic) یاد میگیریم. ابتداییترین مراحلی که لازم است انجام دهیم عبارتاند از:

- فراخوانی کتابخانههای مورد نیاز
- بارگذاری دیتاست
- بررسی اطلاعات موجود در دیتاست
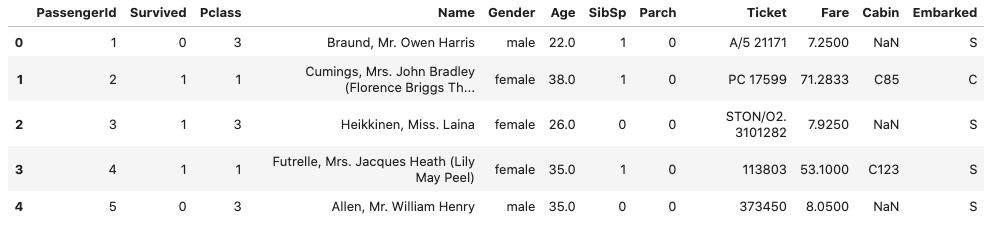
با اجرای قطعه کد زیر، هر کدام از سه مرحله عنوان شده را پیادهسازی میکنیم:
همانطور که در تصویر خروجی نیز مشاهده میکنید، این دیتاست از ۱۲ ستون یا ویژگی شامل اطلاعات مسافران تشکیل شده است:
بازیابی داده
پس از فراخوانی کتابخانههای مورد نیاز و بررسی ساختار دیتاست، باید ناهماهنگیهایی مانند دادههای تکراری را با فراخوانی متد duplicated() کتابخانه Pandas پیدا کنیم:
در تصویر زیر، خروجی اجرای قطعه کد بالا را ملاحظه میکنید:

در ادامه، برای آنکه اطلاعات دقیقتری از دیتاست بهدست آوریم و از نوع دادههای هر ویژگی مطلع شویم، متد info() را فراخوانی میکنیم:
خروجی مانند زیر است:
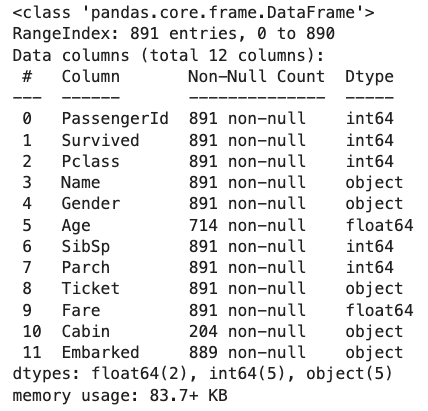
با بررسی دقیق خروجی متد info() ، اطلاعات زیادی حاصل میشود. به عنوان مثال، تعداد نمونههای دو ستون Age و Cabin نابرابر بوده و نوع ویژگیها از اعداد صحیح (int64) تا اعشاری (float64) متغیر است. همچنین، ستونهایی مانند Ticket که از نوع object هستند، در دسته ویژگیهای «طبقهبندی شده» (Categorical) قرار میگیرند. با اجرای قطعه کد نمونه، ویژگیهایی با دو نوع داده طبقهبندی شده و عددی را به نمایش میگذاریم:
خروجی به شرح زیر است:
Categorical columns : ['Name', 'Gender', 'Ticket', 'Cabin', 'Embarked']
Numerical columns : ['PassengerId', 'Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare']با توجه به نتایج حاصل شده، ۵ ستون در گروه ویژگیهای طبقهبندی شده قرار گرفته و ۷ ستون دیگر از نوع عددی هستند. همچنین، فراخوانی متد nunique() بر روی ویژگیهای طبقهبندی شده دیتاست، تعداد مقادیر منحصربهفرد یا به اصطلاح Unique را نتیجه میدهد:
در تصویر زیر، خروجی اجرای قطعه کد بالا را مشاهده میکنید:

تا این مرحله، یاد گرفتیم پاکسازی داده چیست و بازیابی دادههای موجود در دیتاست چگونه انجام میشود. در قدم بعدی با نحوه حذف دادههای غیر ضروری در زبان برنامهنویسی پایتون آشنا میشویم.
حذف نمونه های نامطلوب
منظور از حذف نمونههای نامطلوب، پاکسازی دادههای تکراری، اضافی یا نامرتبط از دیتاست است. بهطور معمول، در زمان جمعآوری مجموعهداده، احتمال وجود نمونههای تکراری افزایش پیدا میکند و دادههای نامرتبط نیز به آن دسته از نمونههایی گفته میشود که ارتباطی با هدف مسئله ندارند. تاثیر دادههای تکراری در عملکرد مدلهای یادگیری ماشین غیرقابل چشم پوشی است؛ زیرا باعث «سوگیری» (Bias) شده و پیشبینی نهایی با واقعیت متفاوت خواهد بود. از طرف دیگر، دادههای نامرتبط هیچ کاربردی نداشته و تنها باید حذف شوند. برای یادگیری بیشتر در مورد پیش پردازشدادهها، میتوانید فیلم آموزش روشهای پیشپردازش دادههای فرادرس که لینک آن در ادامه آورده شده است را مشاهده کنید:

میدانیم که ماشین یا کامپیوتر درکی از دادههای متنی ندارد. در نتیجه، یا باید ویژگیهای طبقهبندی شده را حذف و یا آنها را به نوع دادهای دیگر مانند مقادیر عددی تبدیل کنیم. در این مثال، تمامی مقادیر ستون Name منحصربهفرد بوده و تاثیر چندانی بر متغیر یا کلاس هدف ما ندارد. به همین خاطر آن را حذف میکنیم. با استفاده از قطعه کد زیر، ابتدا ۵۰ نمونه منحصربهفرد ستون Ticket را در خروجی نمایش میدهیم:
خروجی، آرایهای مانند زیر است:
array(['A/5 21171', 'PC 17599', 'STON/O2. 3101282', '113803', '373450',
'330877', '17463', '349909', '347742', '237736', 'PP 9549',
'113783', 'A/5. 2151', '347082', '350406', '248706', '382652',
'244373', '345763', '2649', '239865', '248698', '330923', '113788',
'347077', '2631', '19950', '330959', '349216', 'PC 17601',
'PC 17569', '335677', 'C.A. 24579', 'PC 17604', '113789', '2677',
'A./5. 2152', '345764', '2651', '7546', '11668', '349253',
'SC/Paris 2123', '330958', 'S.C./A.4. 23567', '370371', '14311',
'2662', '349237', '3101295'], dtype=object)پس از بررسی چند نمونه از مقادیر ویژگی Ticket، متوجه میشویم که برخی از آنها مانند نمونه اول، شامل دو بخش با مقادیری همچون A/5 و 21171 هستند. در مبحث «مهندسی ویژگی» (Feature Engineering) یاد میگیریم که چگونه بهمنظور بهبود فرایند آموزش مدل، ویژگیهای دیگری را از چنین ستونهایی استخراج کنیم. با این حال، در مثال ما و بهطور ویژه ستون Ticket، میان نمونهها هماهنگی وجود ندارد و بهتر است تا مانند زیر، آن را همراه با ستون Name حذف کنیم:
فراخوانی ویژگی shape بر روی متغیر df1 ، ابعاد جدید دیتاست را نتیجه میدهد. همانطور که ملاحظه میکنید، تعداد ستونها به ۱۰ عدد کاهش یافته است:
(891, 10)مدیریت داده های گمشده
از «دادههای گمشده» (Missing Data) به عنوان یکی از مشکلات رایج در مجموعهدادهها یاد میشود که در نتیجه خطای انسانی، سیستمی یا چالش در جمعآوری دادهها بهوجود میآید. برای حل مشکل دادههای گمشده از تکنیکهایی مانند «جایگزینی» (Imputation) و «حذف» (Deletion) استفاده میشود.

در این مرحله، باید با بهرهگیری از متد isnull() ، درصد مقادیر گمشده ستونها را بهازای هر سطر محاسبه کنیم. خروجی متد isnull() از نوعی «بولی» (Boolean) است و نشاندهنده خالی (Null) بودن یا نبودن هر سطر است. سپس با فراخوانی متد sum() بر مقدار بازگشتی متد isnull() ، جمع تعداد سطرهای Null را بهدست آورده و پس از تقسیم بر تعداد کل سطرها، نتیجه را در عدد ۱۰۰ ضرب میکنیم:
خروجی مانند زیر است:

نمیتوان دادههای گمشده را بهسادگی حذف یا نادیده گرفت؛ چراکه ممکن است نشاندهنده مشکلی قابل توجه در مجموعهداده باشند. در کاربردهای حقیقی، به هر شکلی که شده باید خروجی دادههای جدید را پیشبینی کنید؛ حتی اگر بخشی از دادهها به اصطلاح گمشده باشند. همانطور که از نتایج پیداست، ۷۷ درصد از مقادیر ستون Cabin برابر با Null هستند و در نتیجه، بهتر است این ویژگی حذف شود. از طرف دیگر، تنها ۰/۲۲ درصد از ستون Embarked را مقادیر Null تشکیل دادهاند و از همینرو، تنها سطرهایی با مقدار Null را حذف میکنیم:
مطابق با خروجی ویژگی shape ، تعداد ستونها به ۹ و تعداد سطرها به ۸۸۹ عدد کاهش یافته است:
(889, 9)پس از رسیدگی به دو ستون Cabin و Embarked، حالا تنها ویژگی Age باقیمانده است که برای جایگزینی مقادیر گمشده آن، میتوانیم از دو روش «میانگین» (Mean Imputation) و «میانه» (Median Imputation) استفاده کنیم. توجه داشته باشید که روش میانگین متناسب دادههایی با «توزیع نرمال» (Normal Distribution) است و زمانی از روش میانه استفاده میشود که نمونههای پرت زیادی داشته باشیم. با اجرای قطعه کد زیر، مقادیر گمشده ستون Age را با میانگین تمامی مقادیر آن جایگزین میکنیم و مجدد، تعداد دادههای گمشده هر ستون را به نمایش میگذاریم:
مطابق با آنچه که در خروجی دیده میشود، تعداد دادههای گمشده به صفر رسیده است:

مدیریت داده های پرت
تا این بخش بهخوبی میدانیم پاکسازی داده چیست و مدیریت دادههای نامطلوب و گمشده چگونه انجام میشود. با این حال، نوع دیگری از دادهها با عنوان دادههای «پرت» (Outliers) نیز وجود داشته که تفاوت چشمگیری با سایر نمونهها دارند. وجود دادههای پرت، بر عملکرد مدلهای یادگیری ماشین تاثیرگذار است و از تکنیکهایی چون «خوشهبندی» (Clustering)، «درونیابی» (Interpolation) یا «تبدیل» (Transformation) برای مدیریت آنها استفاده میشود. بهطور کلی، برای بررسی دادههای پرت از «نمودار جعبهای» (Box Plot) که با نام «نمودار جعبه و خط» (Box and Whisker) نیز شناخته میشود کمک میگیریم. نمودار جعبهای، نمایشی گرافیکی از توزیع مجموعهداده است. هر نمودار جعبهای حاوی معیارهای همچون میانه، «چارکها» (Quartiles) و دادههای پرت احتمالی است و خط درون جعبه، «دامنه میان چارکی» (Interquartile Range | IQR) را نشان میدهد.


خطوط نمودار، بهسمت رایجترین مقدار و تا فاصله ۱.۵ برابری IQR امتداد دارند. از همین جهت، نقاط دادهای که فَرای خطوط قرار میگیرند، به عنوان نمونههای پرت شناسایی میشوند. نمودار جعبهای، روشی آسان برای درک دامنه دادهها و تشخیص نمونههای پرت موجود در دیتاست است. رسم نمودار جعبهای ستون Age مانند زیر انجام میشود:
در تصویر زیر، نمودار جعبهای حاصل از اجرای قطعه کد بالا را مشاهده میکنید:
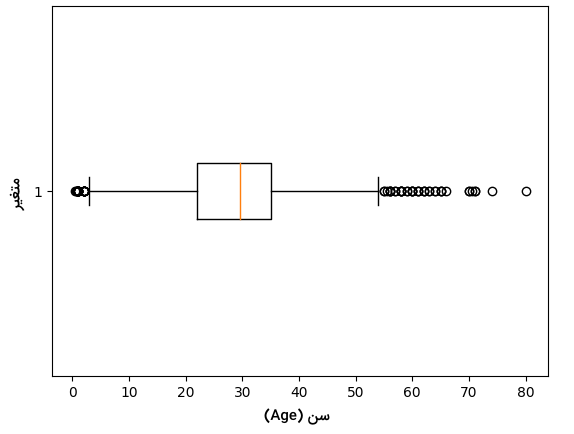
همانطور که در نمودار فوق مشخص است، ویژگی Age شامل مقادیر پرت است. به بیان دقیقتر، مقادیر داده کمتر از ۵ و همچنین بیشتر از ۵۵ در دسته نمونههای پرت قرار میگیرند. از طریق اجرای قطعه کد زیر، حدود آستانه بالا و پایین را شناسایی و دادههای پرت را حذف میکنیم:
در خروجی زیر، دو حد آستانه بالا و پایین مشخص شده است:
Lower Bound : 3.7054001079256587
Upper Bound : 55.57878528533277تبدیل داده
به فرایند تغییر نوع داده به شکلی که قابل تحلیل باشد، «تبدیل داده» (Data Transformation) میگویند. در تبدیل داده از روشهایی مانند «نرمالسازی» (Normalization)، «مقیاسبندی» (Scaling) و «کدگذاری» (Encoding) استفاده میشود. فرایند تبدیل داده متشکل از دو بخش «اعتبارسنجی داده» (Data Validation) و «تغییر فرمت داده» (Data Formatting) است که در ادامه این بخش از مطلب مجله فرادرس به توضیح هر کدام میپردازیم.

اعتبارسنجی داده
در طی فرایند «اعتبارسنجی داده» (Data Validation)، نمونه دادهها با سایر منابع خارجی و «دانش پیشین» (Prior Knowledge) مقایسه شده و از دقت آنها اطمینان حاصل میشود. در یادگیری ماشین، فرایند اعتبارسنجی داده با جداسازی ویژگیهای هدف و مستقل از یکدیگر شروع میشود. در این مثال، ستونهای Gender، Age، SibSp، Parch، Fare و Embarked به عنوان ویژگیهای مستقل در نظر گرفته میشوند و ستون Survived نیز نقش کلاس هدف را دارد. ستون PassengerId را جزو ویژگیهای مستقل بهحساب نمیآوریم. زیرا تاثیری در «نرخ نجات یافتگی» (Survival Rate) ندارد. پیادهسازی این بخش از تمیزسازی داده مانند زیر انجام میشود:
تغییر فرمت داده
به فرایند تبدیل دادهها به فرمت یا ساختاری استاندارد که به آسانی برای الگوریتمها و مدلهای یادگیری ماشین قابل پردازش باشد، «تغییر فرمت داده» (Data Formatting) گفته میشود. روشهای مقیاسبندی و نرمالسازی، بسیار در تغییر فرمت دادهها کاربرد دارند.
روش مقیاس بندی
در این روش، مقادیر ویژگیها به دامنهای مشخص بسط داده میشوند. با این حال، ابعاد توزیع اصلی ثابت مانده و تنها مقیاس تغییر میکند. برخی از الگورتیمها نسبت به اندازه ویژگیها حساس بوده و از همین جهت، بیشترین کاربرد این روش در مسائلی با مقیاس ویژگی متفاوت است. دو روش مقیاسپذیری «کمینه-بیشینه» (Min-Max) و «استانداردسازی» (Standardization)، مثالهایی رایج از مقیاسبندی هستند که در ادامه بیشتر با هر کدام آشنا میشویم.
مقایس بندی کمینه-بیشینه
در این روش و بهطور معمول، مقادیر داده در بازه ۰ تا ۱ قرار میگیرند. باید توجه داشت که در مقیاسبندی «کمینه-بیشینه» (Min-Max)، همزمان با حفظ توزیع اصلی دادهها، مقدار کمینه به ۰ و مقدار بیشینه به ۱ نگاشت میشود. قطعه کد زیر، نحوه پیادهسازی این روش را با استفاده از زبان برنامهنویسی پایتون نشان میدهد:
در تصویر زیر، دادههای مقیاسبندی شده ستونهای منتخب را مشاهده میکنید:
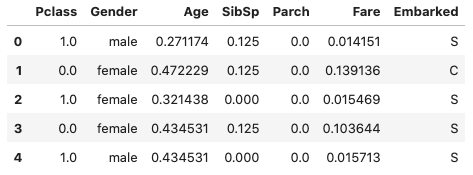
استانداردسازی
در تکنیک «استانداردسازی» (Standardization)، نمونه دادهها بهگونهای تغییر پیدا میکنند که مقدار «میانگین» (Mean) و «انحراف معیار» (Standard Deviation) مجموعهداده به ترتیب برابر با ۰ و ۱ باشد. به این ترتیب، تمامی دادهها حول محور مقدار میانگین جمع شده و مقیاسی برابر با انحراف معیار خواهند داشت. استانداردسازی، بیشتر مناسب الگوریتمهایی است که توزیع مجموعهداده را «گاوسی» (Gaussian Distribution) در نظر گرفته و به ویژگیهایی با میانگین صفر و «واریانس» (Variance) واحد نیاز دارند. معادله روش استانداردسازی عبارت است از:
در معادله فوق، بیانگر دادهها، برابر با میانگین مقادیر و انحراف معیار است.
ابزار های پاکسازی داده چیست؟
حالا که به پرسش پاکسازی داده چیست پاسخ دادیم و نحوه پیادهسازی مراحل مختلف این فرایند را با استفاده از زبان برنامهنویسی پایتون یاد گرفتیم، دیگر میدانیم که پالایش داده را نمیتوان بهصورت دستی و بدون کمک الگوریتمهای یادگیری انجام داد. در نتیجه، با توجه به معیارهایی همچون نوع دادهها و سیستمی که از آن استفاده میکنیم، ابزار مناسب برای تمیزسازی داده نیز متفاوت است. در این بخش، به بررسی چند مورد از رایجترین این ابزارها میپردازیم.

پاکسازی داده ها در اکسل
نرمافزار «مایکروسافت اِکسل» (Microsoft Excel) از سال انتشارش یعنی ۱۹۸۵ تا کنون، از جمله اساسیترین ابزارهای محاسباتی بهشمار میرود. صرفنظر از دیدگاههای شخصی، نرمافزار اکسل، محبوبیت زیادی در زمینه پاکسازی داده دارد. توابع آمادهای مانند «حذف عبارات تکراری» (Deduping)، جایگزینی اعداد و متون، تغییر شکل سطرها و ستونها و یا ادغام سلولهای مختلف، به کاربران اکسل اجازه میدهد تا بخشهای بسیاری از فرایند پاکسازی داده را بهطور خودکار انجام دهند. همچنین، به سادگی قابل یادگیری است و همین موضوع، آن را به ابزاری جذاب برای افراد مبتدی در حوزه تحلیل داده تبدیل میکند.

پاکسازی داده با زبان های برنامه نویسی
اغلب، وظیفه خودکارسازی فرایند پاکسازی داده بر عهده برنامههایی است که با زبانهای برنامهنویسی مختلف توسعه داده میشوند. توابع آماده نرمافزار اکسل نیز از همین طریق پیادهسازی شدهاند. با این حال، از آنجا که در فرایند تمیزسازی داده، نقشی برای کاربر نهایی تعریف نشده است، عمده فعالیتها مانند پردازش مجموعهدادههای حجیم، پیچیده و همچنین طراحی برنامههای مرتبط، از جمله وظایف فرد توسعهدهنده است. زبانهای برنامهنویسی «پایتون» (Python)، «روبی» (Ruby)، SQL و R از محبوبیت زیادی در میان تحلیلگران داده برخوردار هستند. در حالی که برخی از متخصصان باتجربه علم داده، از ابتدا خود کدنویسی تمامی بخشها را انجام میدهند، اما الزامی وجود نداشته و کتابخانههای آماده فراوانی برای اجرای فرایندهایی همچون پاکسازی داده در دسترس همگان قرار دارند. بهطور خاص، زبان برنامهنویسی پایتون با کتابخانههایی مانند NumPy و Pandas در این زمینه پیشتاز است.
پاکسازی داده از طریق مصورسازی
استفاده از تکنیکهای «مصورسازی» (Visualization)، راهی مناسب برای تشخیص خطاهای موجود در دیتاست است. برای مثال، «نمودار میلهای» (Bar Plot) بهخوبی مقادیر منحربهفرد را به تصویر کشیده و به شناسایی ویژگیهایی که از طریق روشهای مختلف برچسبگذاری شدهاند کمک میکند. به طریقی مشابه، «نمودار نقطهای» (Scatter Plot) نیز در تشخیص دادههای پرت کاربرد دارد. برای آشنایی بیشتر با مفاهیم و کاربردهای مصورسازی داده، پیشنهاد میکنیم مطلب زیر را از مجله فرادرس مطالعه کنید:
پاکسازی داده با نرم افزارهای اختصاصی
امروزه شرکتهای بسیاری ترجیح میدهند نرمافزار اختصاصی خود را برای تحلیل داده در اختیار داشته باشند. هدف اصلی چنین نرمافزارهایی، سادهسازی فرایند پاکسازی داده برای افرادی است که چندان تخصصی در این حوزه ندارند. تعداد نرمافزارهای زیادی برای پاکسازی داده وجود دارد. با این حال، پلتفرمهای OpenRefine «+» و Trifacta «+» دو نمونه رایگان و متنبازی هستند که بسیار مورد استفاده قرار میگیرند.
معرفی پروژه های پاکسازی داده
پس از آنکه یاد گرفتیم پاکسازی داده چیست و با نحوه استفاده از ابزارهای رایج در این حوزه آشنا شدیم، زمان آن رسیده است تا به معرفی تعدادی از پروژههای تمیزسازی داده مناسب افراد مبتدی در وبسایت Kaggle «+» بپردازیم. پروژههایی از جمله:

- دیتاست Titanic «+»: با پاکسازی و پالایش دادههای نامرتب و پراکنده این مجموعهداده، احتمال نجات یافتن افراد حاضر در کشتی را پیشبینی کنید.
- دیتاست New York City Airbnb Open Data «+»: این دیتاست، توصیفی از عملکرد و معیارهای ارزیابی مکانهای اقامتی شرکت «ایربیانبی» (Airbnb) شهر نیویورک ارائه میدهد. از تکنیکهای پاکسازی داده برای پیدا کردن اقامتگاهها و موقعیتهای جغرافیایی در دسترس استفاده کنید.
- دیتاست Hotel Booking Demand «+»: با پالایش دادههای این دیتاست، بهترین زمان برای رزرو هتل یا زمانی که قیمتها پایین هستند را پیدا کنید.
- دیتاست Taxi Trajectory Data «+»: این دیتاست، اطلاعات سفرهای انجام شده توسط تاکسیها را در طول سال در اختیار شما قرار میدهد. با بررسی و پاکسازی دادهها، از نحوه فعالیت سرویسهای تاکسیرانی مطلع شوید.
- دیتاست Trending Youtube Video Stats «+»: از تمیزسازی داده برای شناسایی عوامل موثر در محبوبیت ویدئوهای پلتفرم «یوتوب» (YouTube) بهره ببرید.

این پروژهها، انواع مختلفی از دادهها را در اختیار شما قرار داده و به شما کمک میکنند تا مهارتهای خود را در زمینه پاکسازی داده و بهطور کلی علم داده گسترش دهید.
مزایای پاکسازی داده چیست؟
همانطور که تا اینجا یاد گرفتیم پاکسازی داده چیست، بهمنظور بررسی موثر و دستیابی به نتایج دقیق و ارزشمند، ابتدا دادهها باید پالایش شوند. در فهرست زیر، به چند مورد از مزایای تمیزسازی داده اشاره کردهایم:

- سازمانیافتگی: امروزه کسبوکارها اطلاعات بسیاری همچون آدرس و شماره تماس کاربران و مشتریهای خود را جمعآوری میکنند. پاکسازی مداوم این دست از دادهها، به ذخیرهسازی و همچنین بازیابی کارآمد و ایمنتری ختم میشود.
- اجتناب از خطا: تاثیر نامرتب بودن دادهها تنها به فرایند تحلیل داده خلاصه نمیشود و عملیاتهای روزانه را نیز با چالش مواجه میکند. به عنوان مثال، تیمهای بازاریابی پایگاه دادهای از اطلاعات مشتریها دارند و اگر دادهها بهخوبی پالایش و مرتب شده باشند، دسترسی به آنها نیز راحتتر خواهد بود.
- ارتقاء بهرهوری: بهروزرسانی و تمیزسازی منظم دادهها به معنی حذف سریع اطلاعات بیارزش است. با این کار، زمان زیادی از تیمها ذخیره میشود و دیگر لازم نیست با حجم عظیمی از دادهها و مستندات قدیمی سر و کار داشته باشند.
- حذف هزینههای اضافی: اتخاذ تصمیمات تجاری بر اساس اطلاعات بیکیفیت، به اشتباهات پرهزینهای ختم میشود. اما اثر مخرب دادههای نامناسب به اینجا ختم نمیشود. بلکه فرایندهای سادهای مانند پردازش خطاها نیز بهندرت گسترش یافته و کسبوکار را تحت تاثیر قرار میدهند. از همین جهت، لازم است تا مدیریت بهموقع و منظمی نسبت به دادهها داشته باشید و از وقع چنین مشکلات بزرگی پشیگیری کنید.
- بهبود تطبیقپذیری: روز به روز به تعداد سازمانهایی که قصد اصلاح زیرساختهای داخلی خود را دارند افزوده میشود. آنها برای این کار و اجرای فرایندهایی مانند «مدلسازی» (Modeling) و طراحی پروژههای جدید، دست به استخدام متخصصان علم داده میزنند. شروع کار با دادههای تمیز و مرتب، هم سرعت پیشرفت را افزایش داده و هم در آینده به چالشهای کمتری منجر میشود.

پاکسازی داده چه چالش هایی دارد؟
تمامی فرایندهایی که شامل انواع مختلفی از دادهها میشوند، با چالشهای متنوعی روبهرو هستند. پاکسازی داده نیز از این قاعده مستثنا نبوده و بهخاطر مشکلاتی که باید برطرف شوند و همچنین پیدا کردن منشاء خطاها، فرایندی زمانبر است. برخی دیگر از این چالشها عبارتاند از:
- تصمیمگیری برای چگونگی رفع مشکل دادههای گمشده به نحوی که تجزیه و تحلیل نتایج، تحت تاثیر قرار نگیرد.
- بررسی و شناسایی دادههای نامرتبط در سیستمهای عملیاتی.
- پاکسازی دادهها در سیستمهای «کلان دادهای» (Big Data) که ترکیبی از نمونه دادههای «ساختارمند» (Structure)، «نیمه ساختارمند» (Semistructured) و «بدون ساختار» (Unstructured) را شامل میشوند.
- دسترسی داشتن به منابع با کیفیت و ارائه پشتیبانی پایدار.
- مقابله با مشکلاتی که در فرایند تمیزسازی داده اختلال ایجاد میکنند.
مسیر یادگیری داده کاوی و یادگیری ماشین با فرادرس

اگر تا اینجا مطلب را دنبال کرده باشید، بهخوبی میدانید پاکسازی داده چیست و از نحوه پیادهسازی گرفته تا مزایا و چالشهای این زمینه اطلاعات کسب کردهاید. بهطور کلی، پردازش داده که پاکسازی داده نیز قسمتی از آن است، ابتداییترین قدم در طراحی و توسعه هر نوع سیستم مبتنیبر هوش مصنوعی است و در ادامه، نیاز دارید تا با تکنیکهای داده کاوی و همچنین پیادهسازی مدلهای یادگیری ماشین آشنا شوید. پس اگر شما نیز جزو علاقهمندان این حوزه هستید و قصد آغاز مسیر شغلی خود را دارید، مشاهده مجموعه فیلمهای آموزشی فرادرس را که در لینک زیر قرار گرفته است به شما توصیه میکنیم:
سوالات متداول پیرامون پاکسازی داده چیست؟
حالا که یاد گرفتیم پاکسازی داده چیست، با نحوه پیادهسازی، مزایا و چالشهای آن نیز آشنا شدیم، در این بخش از مطلب مجله فردارس، به چند نمونه از پرسشهای متداول در این زمینه پاسخ میدهیم.
پاکسازی داده به چه معناست؟
فرایندی که پس از شناسایی خطاها و ناسازگاریهای موجود در مجموعهداده، راهحل متناسب را پیدا کرده و موجب بهبود دقت نهایی در تصمیمگیری میشود.
چه مثالی از پاکسازی داده وجود دارد؟
حذف دادههای تکراری در پایگاه دادهای که از اطلاعات کاربران تشکیل شده است، دقت و بیطرفانه بودن تحلیل دادهها را تضمین کرده و از برآوردهای بیهوده جلوگیری میکند.

پاکسازی داده چگونه انجام می شود؟
پاکسازی یا پالایش داده شامل مراحلی از جمله حذف نمونههای تکراری، مدیریت مقادیر گمشده و اصلاح ناسازگاریها است. فرایندی که نیازمند بررسی ساختارمند و برطرفسازی مشکلات نشات گرفته از دادههای بیکیفیت است.
جمعبندی
اغراق نیست اگر بگوییم پاکسازی داده مهمترین بخش از فرایند تحلیل داده است. شاید در ابتدا، بهکارگیری روشهای پاکسازی داده دشوار بهنظر برسد. اما باید در نظر داشت که چنین تکنیکهایی، بخش جدانشدنی از هر پروژه در حوزه علم داده هستند. همانطور که در این مطلب از مجله فرادرس خواندیم، دادههای با کیفیت تاثیر چشمگیری در نتایج مدلهای یادگیری ماشین دارند و نادیده گرفتن دادههای تکراری و زائد، به استراتژیهای مخربی ختم میشود. پس از پاکسازی و استفاده از ابزارهای معرفی شده، به راحتی میتوانید دادههای منتخب را در آموزش الگوریتمهای یادگیری بهکار گیرید.