



تفسیر نتایج رگرسیون در SPSS | گام به گام و تشریحی
رگرسیون خطی چه در حالت تک متغیره (ساده)، یا چندگانه و چند متغیره، در نرمافزار SPSS قابل اجرا است. در اغلب موارد خروجی حاصل از این مدلها در این نرمافزار، مشابه یکدیگر هستند. از آنجایی که تفسیر و توجیه مدل ارائه شده، در تحلیل و مدلسازی آماری، امری مهم تلقی میشود، در این نوشتار از مجله فرادرس، به بررسی خروجی و تفسیر نتایج رگرسیون در SPSS پرداختهایم. البته در این متن، مبنا مدل رگرسیونی چندگانه است و مسیر اجرا و نتایج حاصل براساس این تکنیک مورد توجه قرار گرفته است.



برای آشنایی بیشتر با مدلسازی براساس رگرسیون، بهتر است نوشتارهای رگرسیون خطی — مفهوم و محاسبات به زبان ساده و آموزش رگرسیون — مجموعه مقالات جامع وبلاگ فرادرس را مطالعه کنید. همچنین برای فرا گرفتن نحوه کار در محیط SPSS، خواندن مطالب پنجره خروجی SPSS یا Output — راهنمای کاربردی و پنجره ویرایشگر داده (Data Editor) در SPSS — راهنمای کاربردی نیز خالی از لطف نیست.
تفسیر نتایج رگرسیون در SPSS
همانطور که گفته شد، در این نوشتار قرار است با نتایج حاصل از اجرای رگرسیون خطی در SPSS آشنا شده و از آنها، تفسیر درستی ارائه کنیم. در این بین از یک فایل داده آموزشی استفاده خواهیم کرد.
اطلاعات مربوط به نمرات ۲۰۰ دانش آموز دبیرستان در سه درس «ریاضیات» (Math)، «مطالعات اجتماعی» (Socst) و «خواندن» و ... معرفی شدهاند. جدول ۱، این متغیرها را مشخص و ویژگیهای آن را معرفی کرده است.
جدول ۱: ویژگیهای متغیرهای مورد تحلیل
| نام متغیر | عملکرد | نوع داده | توضیحات |
| id | شمارنده مشاهدات | عددی | در مدل به کار نمیرود. |
| female | نوع جنسیت | عددی/دو وضعیتی | در مدل با مقادیر male و female |
| race | نژاد | عددی/ چهار سطحی | عددی با کدهای (hispanic، asian، africal-amer، white) |
| ses | منطقه مدرسه | سه سطحی | عددی با کدهای (low-medium-high) |
| schtype | نوع مدرسه | دو وضعیتی | عددی با کدهای (public-private) |
| prog | نوع روش تدریس | سه وضعیتی | عددی با کدهای (general، academic، vocation) |
| read | نمره رو خوانی | ارزیابی خواندن | عددی- مقادیر پیوسته |
| write | نمره نوشتار | ارزیابی نوشتن | عددی- مقادیر پیوسته |
| math | نمره ریاضی | ارزیابی ریاضیات | عددی- مقادیر پیوسته |
| science | نمره علوم | ارزیابی علوم | عددی- مقادیر پیوسته |
| socst | نمره اجتماعی | ارزیابی اجتماعی | عددی- مقادیر پیوسته |
واضح است که به غیر متغیر science، بقیه متغیرها، به عنوان پیشگو یا متغیرهای توصیفی به کار میروند تا مدل رگرسیونی را ایجاد کنند. اغلب چنین متغیرهایی را به عنوان متغیرهای مستقل میشناسیم.
به منظور دریافت این فایل اطلاعاتی کافی است اینجا کلیک کنید. البته فایل به صورت فشرده (zip) به دست شما خواهد رسید. برای نمایش دادهها در نرمافزار SPSS، باید فایل دریافتی به نام hsb2.zip را از حالت فشرده خارج کرده، سپس در نرمافزار بارگذاری کنید.
در تصویر زیر، نمای از مشخصات متغیرهای مربوط به این فایل دیده میشود. همانطور که میبینید، همه متغیرها از نوع عددی (Numeric) هستند.

در ادامه نیز تصویر مربوط به مقادیر این متغیرها برای ۱۰ مشاهده اول، قابل مشاهده است.

به منظور اجرای فراخوانی و اجرای رگرسیون خطی چندگانه در SPSS میتوان از کد دستوری زیر استفاده کرد. توجه داشته باشید که این دستورات را باید در پنجره Syntax نرمافزار وارد کنید.
البته برای دسترسی به پنجره تعیین پارامترهای رگرسیون خطی، از مسیر زیر نیز میتوان اقدام کرد.
Analyze — Regression — Linear Regression
واضح است که خط اول در کد بالا، به منظور فراخوانی فایل و خطوط بعدی برای اجرای رگرسیون و تعیین پارامترهای آن درج شدهاند.
دستور get file برای بارگذاری دادهها در SPSS استفاده میشود. درون علامت ""، باید تعیین کنید که فایل داده در کدام محل از رایانه شما قرار داشته و مسیر آن را مشخص کنید. به یاد داشته باشید که فایل باید دارای پسوند sav بوده و در انتهای دستور نیز از نقطه (.) استفاده کرده باشید.
دستور بعدی برای اجرای رگرسیون نوشته شده که با regression آغاز میشود. زیرفرمان statsitcs/ برای محاسبه آمارههای توصیفی به کار رفته است. همانطور که مشخص است، متغیر science، به عنوان متغیر وابسته یا پیشبین (dependent) و متغیرهای math, female, socst و read به عنوان متغیرهای پیشگو یا مستقل با روش ورود (method= Enter) به کار میروند.
نکته: هر زیر فرمان یا زیردستور با علامت «/» از بقیه دستور جدا میشود. هر زیردستور نیز با زدن کلید Enter در پنجره Syntax تکمیل خواهد شد. در این متن از سه زیردستور statistics, dependent و method استفاده کردهایم. برای مشخص کردن اتمام دستور علامت «.» در انتهای خط فرمان، قرار میدهند.
به یاد داشته باشید که برای اجرای رگرسیون به زیرفرمان آمار توصیفی (Statistics) احتیاج نیست، اما براساس آن میتوان گزینههایی را که میخواهیم در خروجی قرار دهیم. در اینجا، ما گزینه ci را به منظور نمایش فواصل اطمینان برای ضرایب رگرسیونی استفاده کردهایم. همانطور که در ادامه خواهیم دید، این خروجیها برای تفسیر نتایج آزمون مربوطه بسیار مفید هستند.
چهار جدول در خروجی آورده شده است. SPSS برخی از زیرنویسها را با علامتهای a ،b و غیره، برای کمک به شما در بالای جدول یا بخشهایی از آن درج کرده که مطالعه آنها برای درک صحیح و تفسیر نتایج رگرسیون در SPSS بسیار موثر است.
خروجی اول، متغیرهای مدل رگرسیونی
اولین خروجی حاصل از اجرای دستورات بالا، جدولی به نام Variables Entered/Removed است که دو عبارت بالانویس (Superscript) دارد. همچنین در این جدول چهار ستون برای مشخص کردن مدلها و متغیرهای مورد نظر، اختصاص یافته است. هنگام تفسیر نتایج رگرسیون در SPSS در این جدول متغیرهای مستقل و وابسته را مشاهده میکنید.
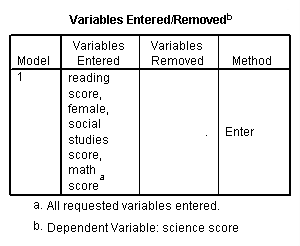
اولین بالانویس آن که با حرف مشخص شده، به معرفی متغیر وابسته پرداخته است. همانطور که در پایین جدول مشاهده میکنید، متغیر «نمره علوم» (science score) متغیر وابسته در نظر گرفته شده.
ستون اول جدول، شماره مدل را مشخص کرده است. از آنجایی که همه متغیرها در مدل لحاظ شدهاند، دستور یاد شده، فقط یک مدل ایجاد کرده است.
ستون دوم مربوط به متغیرهای مستقل مورد استفاده در مدل است. اندیس ، به معرفی متغیرهای ورودی به مدل اختصاص دارد. از آنجایی که یک مدل به کار رفته، همه متغیرها به عنوان متغیرهای مستقل در مدل مورد استفاده قرار گرفتهاند.
نکته: در صورتی که از «رگرسیون سلسله مراتبی» (Hierarchical Regression) یا «رگرسیون گام به گام» (Stepwise Regression) استفاده کرده باشید، تعداد مدلها متفاوت بوده و بعضی از متغیرها در مدل کنار گذاشته یا وارد آن میشوند.
ستون سوم، مربوط به متغیرهای خارج شده در مدل است. این مورد زمانی که از رگرسیون سلسله مراتبی یا گام به گام استفاده کرده باشید، معنی خواهد داشت. همچنین ستون چهارم به مشخص کردن نحوه ورود متغیرها در مدل رگرسیون پرداخته است. از آنجایی که شیوه ورود متغیرها به صورت استفاده از گزینه ورود همه متغیرها در تعریف مدل انتخاب شده، همه متغیرها در مدل نقش داشته، در نتیجه گزینه Enter در این ستون دیده میشود.
همانطور که دیدید، این قسمت به معرفی متغیرهای مورد استفاده در مدل اختصاص دارد. باید این متغیرها را هنگام تفسیر نتایج رگرسیون در SPSS و گزارش خود ارائه دهید. البته در حالت گام به گام (Stepwise)، برای ورود یا خروج یک متغیر در مدل، معیار یا محدودیتهای خاصی وجود دارد که مطالب مرتبط با آن را در نوشتار
خروجی دوم، خلاصه برازش مدل
تا اینجا تفسیر نتایج رگرسیون در SPSS توسط جدولی که به نام Model Summary معروف است، صورت میگیرد که ویژگی و آمارهها مربوط به برازش مدل رگرسیونی را نشان میدهد. هنگام تفسیر نتایج رگرسیون در SPSS اهمیت این جدول مشخص میشود. همانطور که در تصویر زیر مشاهده میکنید، این جدول شامل پنج ستون است که در ادامه هر یک از آنها را مورد بررسی قرار میدهیم.

ستون اول، شماره مدل را براساس جدول پیشین مشخص کرده است. ستونی که با حرف R مشخص شده، مقدار «ضریب همبستگی پیرسون» (Pearson Coefficient of Correlation) را نشان میدهد. در حقیقت این ضریب، نشانگر همبستگی خطی بین مقدار متغیرها وابسته و مقدار پیشبینی شده توسط مدل است. هر چه این ضریب به ۱ (یا ۱-) نزدیکتر باشد، مدل توانسته سهم بیشتری از تغییرات متغیر وابسته را نشان دهد. البته مقدار نزدیک به ۱ برای ما مقدار مطلوب تلقی میشود. اگر مقدار ضریب همبستگی به ۱- برسد، نشان از معکوس بودن رابطه بین مقدار پیشبینی شده توسط مدل و مقدار مشاهده شده برای متغیر وابسته دارد. البته این امر بسیار به ندرت پیش میآید.
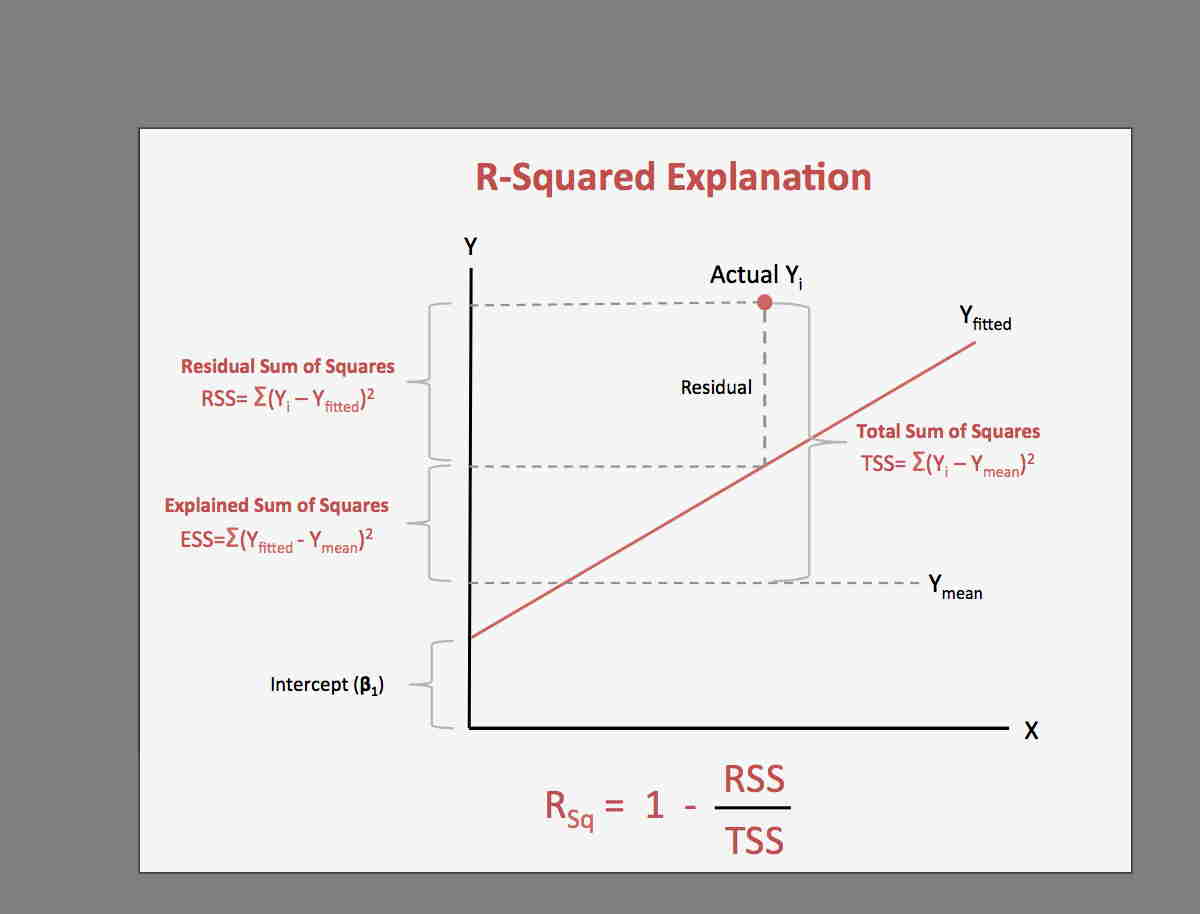
ستون دوم، یا R Square، ضریب تعیین (Coefficient of Determination) گفته میشود که همان مربع ضریب همبستگی است. مقدارهای نزدیک به یک، برازش بهتر و همچنین سهم بیشتر در بیان تغییرات متغیر وابسته را توسط مدل «کمترین مربعات خطا» (OLS) نشان میدهند. این مقدار در تصویر ۴ برابر با تقریبا ۰٫۵ است که نشانگر سهم ۵۰٪ مدل در بیان پراکندگی متغیر وابسته (نمره ارزیابی علوم) است.
ستون سوم، Adjusted R Square یا ضریب تعیین اصلاح یا تعدیل شده است. همانطور که متغیرهای مستقل یا پیشگو به مدل اضافه میشوند، ضریب تعیین افزایش یافته و به نظر مدل بهتری حاصل میشود. میتوان با اضافه كردن متغیرهای مستقل به مدل ادامه داد تا جایی که توانایی مدل در توصیف متغیر وابسته بهبود یابد. البته این امر به پیچیده شدن مدل رگرسیونی منجر میشود. اگر چه افزودن متغیر مستقل به مدل باعث افزایش مقدار ضریب تعیین میشود ولی ممکن است این امر به علت تغییرات تصادفی یا شانسی حاصل از نمونهها رخ داده باشد. ضریب تعیین اصلاح شده تلاش میکند ارزیابی بهتری بین پیچیدگی مدل و تعداد متغیرها با توصیف پراکندگی متغیر وابسته ارائه کند. به این ترتیب توسط ضریب تعیین اصلاح شده، افزایش متغیرها و ضریب تعیین به یک تعادل میرسند.
همانطور که دیدید بخشی از تفسیر نتایج رگرسیون در SPSS به مقدار ضریب تعیین ارتباط دارد که در مثال ما برابر 0٫۴۸۹ است، در حالیکه مقدار ضریب تعیین اصلاح شده برابر با 0٫۴۷۹ است. نزدیکی این دو مقدار به هم نشانگر آن است که متغیرهای به کار رفته در مدل، توانستهاند به خوبی به کار آیند و برازش مناسبی ارائه دهند. شیوه محاسبه ضریب تعیین تعدیل یا اصلاح شده به صورت زیر است.
که در آن همان ضریب تعیین اصلاح شده و ضریب تعیین است. همانطور که در فرمول مشاهده میشود، وقتی تعداد مشاهدات () کم و تعداد پیش بینیها (متغیرهای مستقل ) زیاد باشد، تفاوت بین ضریب تعیین و ضریب تعیین تعدیل شده بسیار زیاد خواهد بود زیرا نسبت بزرگتر از ۱ خواهد شد.
در مقابل، هنگامی که تعداد مشاهدات در مقایسه با تعداد پیش بینیها بسیار زیاد باشد، مقدار ضریب تعیین به ضریب تعیین اصلاح شده نزدیک و نزدیکتر میشود، زیرا نسبت به 1 نزدیک خواهد شد.
در ستون آخر نیز خطای استاندارد برآورد (Std. Error of the Estimate) که به آن میانگین ریشه مربع خطا نیز میگویند دیده میشود. در حقیقت این مقدار، انحراف معیار اصطلاح خطا است و ریشه مربعات باقیمانده (یا خطا) را نشان میدهد. از این مقدار برای برآورد واریانس متغیر وابسته نیز میتوان استفاده کرد.
در مورد ارزیابی دو مدل، با ضرایب تعیین تقریبا یکسان، مدلی انتخاب میشود که خطای استاندارد مقادیر خطا (باقیمانده) کمتری داشته باشد.
خروجی سوم، جدول آنالیز واریانس
بخش بعدی در تفسیر نتایج رگرسیون در SPSS مربوط به جدول ANOVA یا تحلیل واریانس است. در جدول آنالیز واریانس، منابع تغییرات، در سه بخش تفکیک و ارائه شدهاند.
- تغییراتی یا پراکندگی که توسط مدل رگرسیون بیان شدهاند. در جدول این منبع با عبارت Regression مشخص میشود.
- تغییراتی که براساس باقیماندههای (خطا) حاصل از مدل رگرسیونی مشخص شده است. عبارت Residual به منظور تعیین این منبع تغییرات در جدول قابل مشاهده است.
- تغییرات یا پراکندگی کل که براساس مجموع مربعات فاصله مقادیر متغیر وابسته از میانگینشان ساخته میشود. سطری که مربوط به عبارت Total است، تغییرات کل را نمایش میدهد.
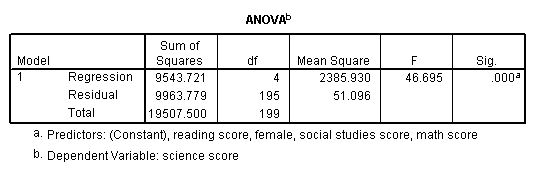
ستون اول در این جدول به معرفی منابع تغییرات پرداخته است. همچنین شماره مدل نیز در این بخش دیده میشود. توجه داشته باشید که مجموع مربعات رگرسیون و باقیمانده برابر با تغییرات کل است.
ستون دوم، مجموع مربعات پراکندگی (Sum of Square) یا به اختصار SS، را برای هر یک از منابع تغییر مشخص کرده. از نظر مفهومی، این مقادیر را می توان به صورت زیر بیان کرد:
- SSTotal یا مجموع مربعات تغییرپذیری مقادیر پیرامون میانگین. رابطه زیر برای محاسبه آن به کار میرود.
- SSResidual یا مجموع مربعات خطاهای پیش بینی. فرمول محاسباتی به صورت زیر است. نماد برای مقادیر برازش شده به کار میرود.
- SSRegression یا پراکندگی مدل رگرسیونی. این بار به جای مقادیر مشاهده شده از متغیر وابسته، مقادیر برازش شده برای سنجش پراکندگی به کار میرود. مجموع مربعات اختلاف مقادیر برازش از میانگین کل، مبنای محاسبه SSRegression است.
نکته: با توجه به فرمولها و تعاریف ارائه شده، بین این مقادیر پراکندگی رابطه زیر برقرار خواهد بود. بنابراین محاسبه فقط دو معیار پراکندگی برای تکمیل جدول آنالیز واریانس کافی است.
در قسمت قبل، به ضریب تعیین اشاره کردیم که نسبت پراکندگی مدل رگرسیونی به پراکندگی کل است. بنابراین مشخص است که رابطه زیر برای محاسبه ضریب تعیین به کار رفته است.
این مقدار از طریق جدول آنالیز واریانس نیز ۰٫۴۸۹ بدست میآید.
ستون سوم به «درجه آزادی» (Degree of Freedom) اختصاص دارد. درجه آزادی به منابع پراکندگی ارتباط دارد. پراکندگی کل دارای درجه آزادی است، زیرا یک برآورد (میانگین کل) صورت گرفته، در نتیجه یک واحد از درجه آزادی کاسته میشود. این امر به این معنی است که از مشاهده، یکی به طور آزاد تغییر نکرده و مشاهده میتوانند آزادانه تغییر نمایند زیرا میانگین کل از پیش تعیین شده است. در این حالت و در مثال ما، دانش آموز وجود دارد، بنابراین درجه آزادی برای پراکندگی کل 199 است.

درجه آزادی مدل رگرسیونی که مربوط به تعداد متغیرهای پیشگو است نیز برابر با است. مشخص است که چهار متغیر مستقل (نمره ریاضی-math، جنسیت-female، نمره مطالعات اجتماعی-socst و رو خوانی-reading) در مدل به کار رفته است. از طرفی یک پارامتر دیگر نیز در مدل وجود دارد که به آن «عرض از مبدا» (Intercept) یا «مقدار ثابت» (Constant) میگویم که براساس میانگین کل حاصل میشود. بنابراین کل پارامترهای مدل برابر با است. بنابراین مدل دارای درجه آزادی است.
با توجه به رابطهای که بین مربعات پراکندگی وجود داشت، بین درجههای آزادی نیز همان رابطه وجود دارد.
بنابراین درجه آزادی برای عبارت خطا (باقیمانده - SSResidual) برابر با است که در مثال ما خواهد بود.
در ستون چهارم، میانگین مربوط به مجموع مربعات پراکندگیها (یا واریانس) برای دو منبع تغییرات مدل رگرسیونی (MSR) و باقیماندهها (MSE) بدست میآید. میانگین گیری به این طریق انجام میشود که هر یک از مقادیر مجموع مربعات بر درجه آزادی تقسیم میشوند. به این ترتیب برای مدل رگرسیونی و باقیماندهها خواهیم داشت:
بنابراین در ستون پنجم، نسبت F، محاسبه از تقسیم MSR به MSE حاصل میشود. این نسبت، نشانگر سهمی است که مدل رگرسیونی نسبت به باقیماندهها در بیان پراکندگی کل دارد. هر چه این مقدار بزرگتر باشد، مدل رگرسیونی مناسبتر خواهد بود.
ستون آخر یا Sig نیز میزان بزرگی را مشخص کرده است. هر چه مقدار F بزرگتر باشد، Sig به صفر نزدیکتر میشود. مقدار کوچکتر از ۰٫۰۵، برای Sig، نشانگر ارائه مدل مناسب رگرسیون است. مقدار ۰٫۰۵، همان خطای نوع اول یا سطح آزمون در نظر گرفته میشود. در مثال ما مقدار F بزرگ و Sig بسیار کوچک است. بنابراین مدل ارائه شده به خوبی نمره علوم را به عنوان متغیر وابسته، توصیف میکند.
جدول ضرایب مدل رگرسیونی
بخش بعدی برای تفسیر نتایج رگرسیون در SPSS به جدول ضرایب مدل ارتباط دارد. شاید این جدول شلوغترین و در عین حال، مهمترین خروجی مدلسازی در SPSS باشد. در تصویر 6، نمونهای از این جدول را مشاهده میکنید که برای مثال مورد نظرمان تولید شده است. مشخص است که هفت ستون در این جدول دیده میشود. در ادامه هر یک از این ستونها را معرفی خواهیم کرد.
نکته: اگر گزینه ci در دستور به کار نمیرفت، قسمت «فاصله اطمینان» (Confidence Interval) در انتهای این جدول دیده نمیشد.
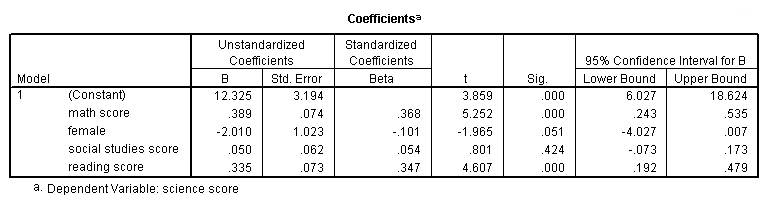
بهتر است به بالانویس اولیه که در کنار عبارت Coefficients دیده میشود، هنگام تفسیر نتایج رگرسیون در SPSS اشارهای داشته باشیم. در پایین جدول، این بالانویس، توصیف شده که نشانگر نام متغیر وابسته، یعنی همان «نمره ارزیابی درس علوم» (Science Score) است.
از آنجایی که یک مدل ساخته شده، در ستون اول نیز اسامی مربوط به متغیرهای مستقل مدل اول دیده میشود. اگر مدلهای بیشتری مورد بررسی قرار میگرفت، شماره مدل و متغیرهای مستقل مربوطه نیز در سطرهای بعدی جدول دیده میشدند. واضح است که متغیرهای مستقل منظور شده در مدل، چهار متغیر اصلی ما هستند.
در ستون دوم و سوم، ضریب هر یک از متغیرها به همراه خطای استاندارد (انحراف معیار برآوردگر) دیده میشود. در حقیقت ستون ، میانگین و ستون Std. Error، انحراف معیار برآوردگرهای هر یک از ضرایب رگرسیونی است. این مقادیر باید هنگام ارائه تفسیر نتایج رگرسیون در SPSS نیز نوشته شوند.
به کمک این دو معیار میتوان به کمک یک آزمون T، فرض صفر بودن این ضرایب را اجرا کرد و به تفسیر نتایج رگرسیون در SPSS را به درستی انجام داد.
برای مشخص کردن اهمیت هر یک از متغیرها و نقش آنها در مدل رگرسیونی، باید به ستون Standardized Coefficients یا ضرایب استاندارد شده توجه کرد. از آنجایی که دو متغیر math و reading بزرگتری ضریب استاندارد را دارند، نقش موثرتری در پیشبینی متغیر وابسته (نمره علوم) خواهند شد. البته حساسیت مدل به متغیرهایی که ضرایب بزرگتری دارند بیشتری است ولی نقش و اهمیت هر یک از متغیرها (بدون در نظر گرفتن واحد اندازهگیری) توسط ضرایب استاندارد تعیین میشود.
نکته: برای محاسبه ضرایب استاندارد شده، از دادههای استاندارد شده استفاده میشود. به این معنی که هر مقدار از متغیرهای وابسته و مستقل را از میانگینشان کم کرده و بر انحراف معیار، تقسیم میکنیم. سپس مدل رگرسیونی را برازش داده و ضرایب را محاسبه میکنیم. از آنجایی که هیج یک از متغیرها در این حالت، واحد ندارند، بزرگی یا کوچکی آنها به واحد اندازهگیری بستگی نخواهد داشت.
ستونهای T و Sig نیز به آزمون فرض ضرایب پرداختهاند. هر چه مقدار T بزرگ باشد، فرض صفر بودن ضریب، ضعیفتر شده و نقش آن متغیر در مدلسازی، بیشتر است. این بزرگی را به کمک مقدار Sig نیز مشخص میکنند. اگر مقدار Sig کوچکتر از ۰٫۰۵ باشد، فرض صفر که بیانگر بیاثر بودن متغیر در مدل است، رد میشود.
طبق جدول مربوط به تصویر ۶، همه ضرایب به جز نمره درس مطالعات اجتماعی و جنسیت از لحاظ آماری معنیدار بوده و باید در مدل لحاظ شوند.
در ستون آخر نیز فاصله اطمینان 95٪ برای هر یک از ضریبها ساخته شده. اگر فاصله اطمینان شامل نقطه صفر باشد، میتوان آن متغیر را از مدل حذف کرده و دوباره مدل رگرسیونی را برازش داد. باز هم با توجه به فاصله اطمینان، مشخص میشود که دو متغیر جنسیت (female) و نمره مطالعات اجتماعی (socst) در مدل نقشی ندارند.
به هر حال مدل ارائه شده توسط این برازش رگرسیونی به صورت زیر خواهد بود.
مشخص است که ضریب نمره ریاضی با استفاده از احتمال خطای نوع اول (سطح آزمون) 0/05 از نظر آماری تفاوت معناداری دارد زیرا «پی-مقدار» (p-value) که با Sig در SPSS نشان داده میشود برابر با ۰٫۰۰۰ است که کوچکتر از ۰٫۰۵ است.
نکته: هر گاه ضریبی از مدل رگرسیونی، از لحاظ آماری معنیدار نباشد، آن را هنگام تفسیر نتایج رگرسیون در SPSS محسوب نخواهیم کرد. این امر به معنی بیاثر بودن آن متغیر در پیشبینی متغیر وابسته است.
ضریب برای جنسیت از نظر آماری در سطح 0٫05 معنی دار نیست زیرا Sig بیشتر از 0٫05 است. ضریب مطالعات اجتماعی نیز از نظر آماری با 0 تفاوت معناداری ندارد زیرا p-مقدار آن قطعاً بزرگتر از 0٫05 است. ضریب متغیر خواندن از نظر آماری معنی دار است زیرا p-مقدار برایش برابر با 0٫000 بوده که کمتر از ۰٫۰۵ خواهد بود.
مشخص است که فاصله اطمینانها تولید شده نیز همین نتایج را نشان میدهند.
به این ترتیب باید دو متغیر جنسیت (female) و نمره مطالعات اجتماعی (Socst) را از مدل حذف کرده و مجدد محاسبات رگرسیونی را اجرا کرد تا به ضرایب صحیح برای متغیرهای معنیدار رسید. همانطور که مشخص شد اجرای درست تفسیر نتایج رگرسیون در SPSS به تشخیص ضریبها و متغیرهای صحیح منجر خواهد شد.
خلاصه و جمعبندی
تفسیر نتایج حاصل از اجرای رگرسیون خطی اهمیت زیادی دارد. هر چند در حالت عادی، خروجیها محدود بوده و به چهار یا پنج جدول محدود میشوند ولی برای ارائه نتیجه باید با دقت مقادیر موجود در این جدولها را گزارش و تفسیر کرد. به همین علت کارشناسان علم داده باید از نحوه تفسیر نتایج رگرسیون در SPSS آگاه باشند و بدانند هر جمله یا عبارتی که در گزارش ارائه میکنند به چه معنی است.











ممنونم ازتون خیلی کامل و ساده توضیح داده شده.
خدایا چقدر جامع وروان وساده بیان شده..خیلی اموختم .سپاس
بسیار عالی و روان توضیح داده شد
سلام بنده دانشجوی دکتری پرستاری هستم، واقعا از مطالب شما که ساده و روان و درعین حال جامع بیان شده رضایتمندم و کمال تشکر دارم، سلامت و شادی براتون آرزو میکنم.
با سلام خدمت شما…..
دوستی به من گفت که شغلش تحلیل گر داده و برنامه نویس است پرسیدم تحلیلگر داده چیست؟ شما تو صدا و سیما هستید و طول موج فرکانس و اصوات رو اندازه گیری میکنید گفت نه مثلا برای کارخونه چی توز برنامه نوشتم و در روابط عمومی شرکت وقتی با تماس مشتری اعلام رضایت یا نارضایتی میکند را برسی میکنیم … من که متوجه نشدم چطور امکان برسی وجود داره….
دومین مطلب تابه حال با دوربین دیجیتال یا همین گوشی های معمولی از اطراف یک شعله عکس تهیه کردید که زوایا و طول موج یا دیتا رو محاسبه کنید آیا امکان پذیر هست یا نه…. ممنون از شما
با سلام،خیلی ممنون آقای دکتر بابت مطالب خوبتون. فقط ببخشید تعاریفِ مفاهیم آماری مثل R2 و..به جز spss شامل بقیه نرم افزار های مدلسازی آماری نیز میباشد؟
با تشکر
دمتون گرم
مطالب بسیار آموزنده، ارزشمند، کامل و جامعه بود. از این مطالب در پایان نامه دکترایم بسیار استفاده کردم. امیدوارم در پناه یزادن پاک روزه روز دانش شما افزونتر گردد
مطالب دقیق بود ممنون