



آموزش یادگیری ماشین با مثالهای کاربردی ــ بخش ششم
در بخشهای پیشین از مجموعه مطالب «آموزش یادگیری ماشین با مثالهای کاربردی»، مبانی و مفاهیم هوش مصنوعی و یادگیری ماشین، شبکههای عصبی، یادگیری عمیق، شبکههای عصبی پیچشی، بینایی ماشین، تشخیص چهره و ترجمه ماشینی مورد بررسی قرار گرفت. در این بخش، به مبحث بازشناسی گفتار و تشخیص صدا پرداخته خواهد شد.




بازشناسی گفتار «Speech recognition» زندگی بشر را بهطور کامل متحول کرده است. این فناوری در تلفنها، کنسولهای بازی و ساعتهای هوشمند وجود دارد. امروزه، بازشناسی گفتار حتی در خودکارسازی قسمتهای مختلف خانهها نیز مورد استفاده قرار میگیرد. پیشرفت این فناوری به حدی بوده که در حال حاضر با مبلغ ناچیزی میتوان دستگاههای دیجیتال مجهز به این فناوری، مثل بلندگوی اکو دات آمازون را خریداری کرد. این بلندگو واقعا یک جعبه جادویی است که با بهرهگیری از آن میتوان صرفا با بلند صحبت کردن پیتزا سفارش داد، گزارش آب و هوا را دریافت و حتی پلاستیک زباله خریداری کرد.

سوالی که اکنون مطرح میشود این است که چرا با وجود جریان داشتن بازشناسی گفتار برای چند دهه، همچنان یکی از موضوعات داغ روز است؟ دلیل این امر آن است که «یادگیری عمیق» (Deep Learning) در نهایت موجب شده تا در بازشناسی گفتار به سطحی از صحت دست یافته شود که حتی در خارج از محیطهای کاملا کنترل شده نیز بتوان از آن بهرهبرداری کرد. «اندرو وو» (Andrew Ng)، دانشمند کامپیوتر و هوش مصنوعی پیشبینی کرده که بازشناسی گفتار از صحت ۹۵٪ به ۹۹٪ دست پیدا میکند و به راهکار اصلی تعامل با کامپیوترها مبدل خواهد شد.
نکته قابل توجه این است که همین شکاف ۴٪ مطرح شده برای صحت (بین ۹۵٪ و ۹۹٪)، تفاوت فاحشی بین آزاردهنده و غیر قابل اعتماد بودن این فناوری و به شدت مفید بودن آن ایجاد میکند. به لطف یادگیری عمیق، این چالش نیز در حال برطرف شدن است و بشر به صحت نزدیک به ۱۰۰٪ در تشخیص گفتار دست پیدا خواهد کرد. در ادامه به مبحث تشخیص گفتار با بهرهگیری از یادگیری عمیق پرداخته میشود.
یادگیری عمیق همیشه جعبه سیاه نیست
افرادی که با نحوه عملکرد ترجمه ماشینی عصبی آشنایی دارند، احتمالا میتوانند حدس بزنند که برای بازشناسی گفتار نیز صداهای ضبط شده به شبکه عصبی خورانده و شبکه برای تولید متن آموزش داده میشود.

نقطه اوج تشخیص گفتار، بهرهگیری از یادگیری عمیق محسوب میشود. چالش اساسی مطرح در اینجا، تفاوت در سرعت گفتارهای گوناگون است. فردی احتمال دارد کلمه «!hello» را خیلی سریع بگوید و فرد دیگر ممکن است همین کلمه را به صورت بسیار کند، «!heeeelllllllllllllooooo»، ادا کند. این تفاوت سرعت موجب میشود، فایلهای صوتی برای یک کلمه واحد دارای طولها و حجم دادههای متفاوت باشند.
توجه به این نکته لازم است که محتوای هر دو این فایلهای صوتی باید به عنوان یک متن یکسان یعنی «!hello» شناسایی شوند. ترازبندی خودکار، فایلهای صوتی با طولهای گوناگون را به یک طول واحد تبدیل میکند که البته کاری بسیار دشوار است. برای انجام این کار، باید از ترفندها و پردازشهای خاصی علاوه بر شبکههای عصبی عمیق استفاده شود.
تبدیل صدا به بیت
واضح است که اولین گام در تشخیص گفتار، خوراندن امواج صدا به کامپیوتر است. در بخش سوم از مجموعه مطلب «آموزش یادگیری ماشین با مثالهای کاربردی»، روش دادن عکس به عنوان ورودی مدل و مواجهه با آن به صورت یک آرایه از اعداد آموزش داده شد.
بر اساس مطالب بیان شده، میتوان خروجی مدل مذکور را - که به صورت آرایهای از اعداد است - برای تشخیص تصویر، مستقیما به یک شبکه عصبی داد.
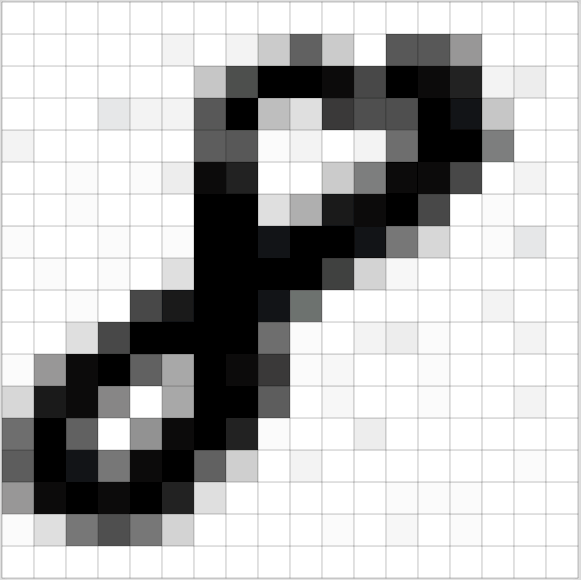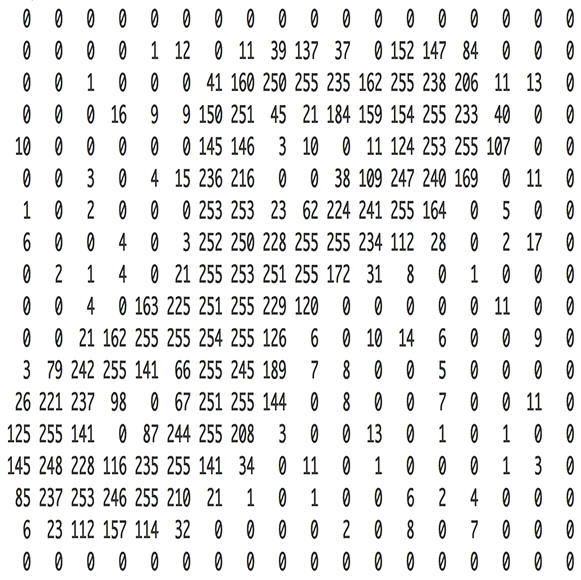
همانگونه که تصاویر برای استفاده در مدل بازشناسی به آرایهای از اعداد مبدل میشوند، صدا نیز به صورت موج قابل استفاده است. پرسشی که اکنون مطرح میشود این است که چگونه میتوان صدا را به اعداد تبدیل کرد؟ در ادامه برای حل این مساله، از یک کلیپ صوتی که فرد در آن میگوید «Hello»، استفاده خواهد شد.

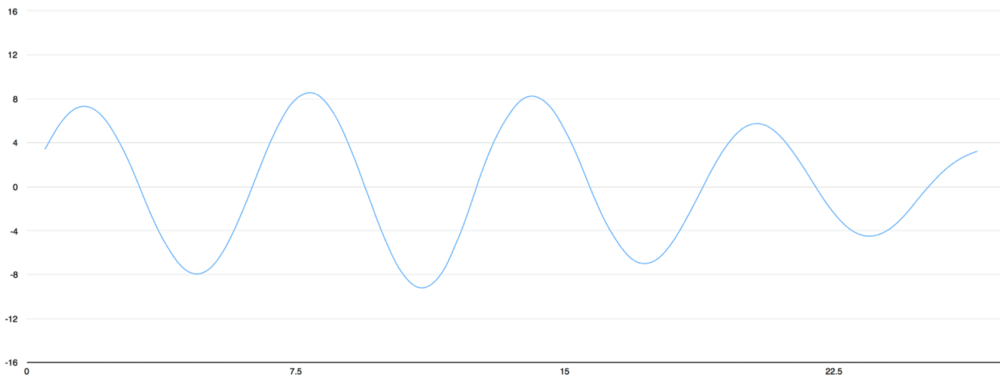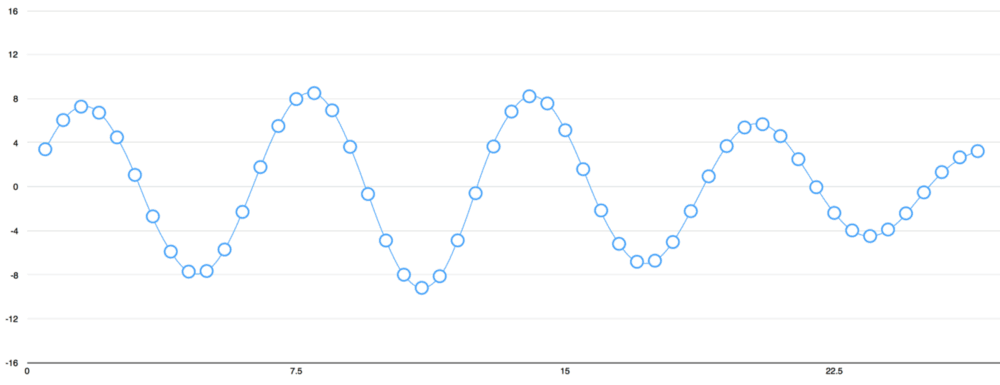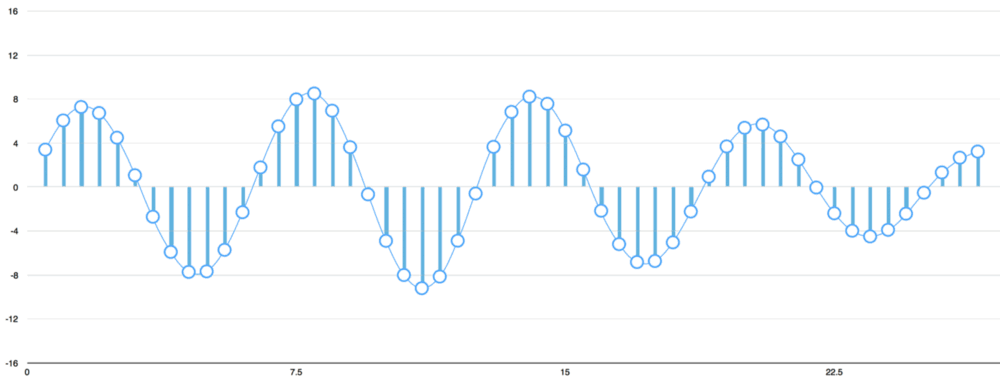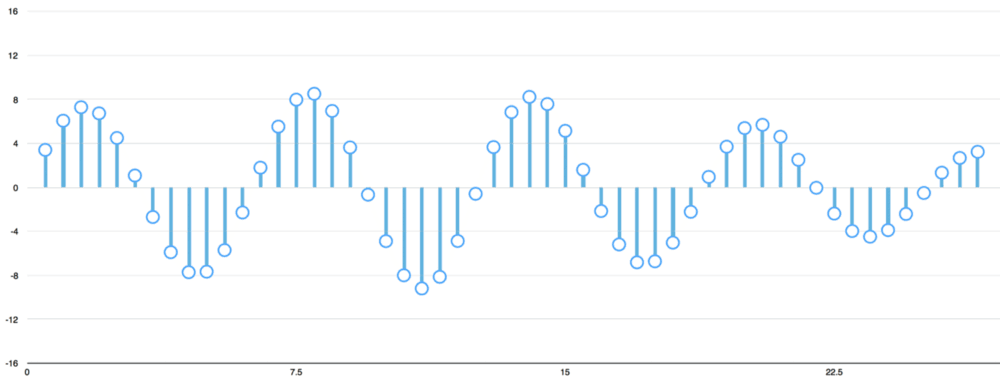
موجهای صدا، تک بُعدی و در هر دقیقه از زمان، دارای یک مقدار مجرد بر پایه ارتفاع موج هستند. در تصویر زیر بخش کوچکی از یک موج به صورت بزرگنمایی شده قابل مشاهده است.

برای تبدیل صدا به اعداد، تنها کافیست ارتفاع موج در نقاط دارای فاصله مساوی ثبت شوند.
به این کار نمونهبرداری گفته میشود. در این فرآیند، موج هزاران بار در ثانیه خوانده و سپس اعدادی که نشانگر ارتفاع موج صدا در آن نقاط زمان هستند ثبت میشوند. کلیه فایلهای غیر فشرده wav. به این صورت هستند. فایل صوتی «CD Quality» در ۴۴.۱ (۴۴٬۱۰۰ بار در ثانیه خوانده شده) کیلوهرتز نمونهبرداری شده است.
برای بازشناسی گفتار، نرخ نمونهبرداری ۱۶ کیلوهرتز (۱۶٬۰۰۰ نمونه در ثانیه) برای پوشش دادن طیف فرکانس گفتار انسان کافی است. بر همین اساس، اکنون موج صدای «Hello» با ۱۶٬۰۰۰ نمونهبرداری میشود. صد نمونه اول به صورت زیر هستند:

یک توضیح سریع از نمونهبرداری دیجیتال
ممکن است به نظر برسد که نمونهبرداری در واقع ایجاد تخمینی خام از موج صدای اصلی است. در حالیکه این کار صرفا دریافت خوانشهای گاهبهگاه است.
در این خوانشها شکافهایی وجود دارد، بنابراین احتمال دارد که دادهها از دست بروند.

به لطف قضیه نمونهبرداری نایکوئیست-شنون، میتوان از ریاضیات برای بازسازی کامل موج صدای اصلی در نمونههای فاصلهدار استفاده کرد. این کار هنگامی قابل انجام است که نمونهبرداری دستکم دوبار سریعتر از بالاترین فرکانسی که قصد ثبت آن وجود دارد انجام شود. دلیل متذکر شدن این نکته آن است که بسیاری از افراد برداشت اشتباهی از این موضوع دارند و بر این باورند که استفاده از نرخ نمونهبرداری بالاتر همیشه منجر به کیفیت صوت بیشتری میشود، در حالیکه اینطور نیست.
پیشپردازش دادههای صوت نمونهبرداری شده
اکنون آرایهای از اعداد وجود دارد که در آن، هر عدد نوسان موج صدا را در بازههای ثانیهای ۱/۱۶۰۰۰ نشان میدهد. میتوان این اعداد را به شبکه عصبی داد. اما تلاش برای تشخیص الگوهای گفتار با پردازش مستقیم این نمونهها کاری دشوار است.
در عوض، میتوان مساله را با انجام پیشپردازشهایی روی دادههای صوتی، آسانتر کرد. کار با گروهبندی دادههای صوتی نمونهبرداری شده در تکههای ۲۰ میلیثانیهای انجام میشود. در تصویر زیر اولین ۲۰ میلیثانیه از فایل صوتی قابل مشاهده است (اولین ۳۲۰ نمونه).

ترسیم نمودار خطی این اعداد، تخمین خامی از طول موج اصلی آن طی ۲۰ میلیثانیه از زمان به دست میدهد.

این فایل صوتی تنها ۱/۵۰ ثانیه به طول میانجامد. اما، حتی این فایل صوتی کوتاه نیز آش شله قلمکاری از فرکانسهای گوناگون صدا است. صداهای پایین، متوسط و حتی مرتبه بالایی در همین فایل وجود دارند. با قرارگیری همه این موارد در کنار هم، صدای پیچیدهای از گفتار انسان تشکیل میشود. برای آنکه پردازش داده برای شبکه عصبی آسانتر شود، این صدای پیچیده به مولفههای آن شکسته میشود. در این راستا، قسمتهای مرتبه پایین، میانی و بالا از یکدیگر جدا میشوند. سپس با افزودن انرژی موجود در هر یک از دستههای فرکانس (از پایین تا بالا) یک اثر انگشت از چنین قطعههای صدایی ساخته میشود.

صدایی مفروض است که در آن یک نفر در حال نواختن آکورد ماژور C پیانو است. این صدا ترکیبی از سه نوت موسیقی C ،E - و G - است که با یکدیگر و در یک صدای پیچیده ترکیب شدهاند. هدف از شکستن این صدای پیچیده به نوتهای مجزا کشف C، E و G است. این کار با استفاده از ریاضیات و تبدیل فوریه قابل انجام است.
روش مذکور، موجهای صدای پیچیده را به موجهای سادهای میشکند که آن را تشکیل دادهاند. هنگامی که موجهای صدای منحصر به فرد فراهم شدند، میتوان انرژی که در هر یک وجود دارد را نیز محاسبه کرد. نتیجه نهایی امتیازی از اهمیت هر طیف فرکانسی از مرتبه پایین (نوتهای باس) تا مرتبه بالا است. هر یک از اعدادی که در زیر آمدهاند نشانگر میزان انرژی مصرف شده در هر باند ۵۰ هرتزی از کلیپ صوتی ۲۰ میلیثانیهای هستند.

اما راهکار سادهتر آن است که این مورد را به صورت یک جدول نشان داد.

اگر این فرآیند برای هر تکه ۲۰ میلی ثانیهای صدا تکرار شود، در نهایت یک طیفنما حاصل میشود (هر ستون از چپ به راست یک تکه ۲۰ میلی ثانیهای است).

نمودار طیفنما جالب است زیرا با بهرهگیری از آن، میتوان نوتهای موسیقی و دیگر الگوهای مراتب را در دادههای صوتی دید. یک شبکه عصبی میتواند الگوها را در این نوع از دادهها نسبت به موجهای صدای خام به شکل سادهتری پیدا کند. این ارائهای از دادهها است که به شبکه عصبی داده میشود.
تشخیص کاراکتر از صداهای کوتاه
اکنون که صداهای کوتاه در قالبی فراهم شدند که پردازش آنها سادهتر است، به شبکه عصبی عمیق خورانده میشوند. ورودی شبکه عصبی، تکههای صدای ۲۰ میلیثانیهای است.
برای هر تکه صدای کوچک، مدل تلاش میکند تا حرفی را تشخیص دهد که صدای بیان شده را شامل میشود.

برای مدلسازی، از یک شبکه عصبی بازگشتی (شبکه عصبی که دارای حافظ است و پیشبینیهای آینده را تحت تاثیر قرار میدهد) استفاده خواهد شد. دلیل این امر آن است که هر حرفی که توسط مدل پیشبینی میشود، باید درستنمایی حرف بعدی که پیشبینی خواهد شد را تحت تاثیر قرار دهد. برای مثال، اگر «HEL» گفته شود، احتمال آن وجود دارد که «LO» نیز پس از آن برای کامل کردن کلمه «HELLO» بیان شود.

در عین حال، احتمال آنکه چیز غیر قابل تلفظی مانند «XYZ» پس از «HEL» گفته شود کمتر است. بنابراین شبکه عصبی با داشتن حافظه از پیشبینیهای قبلی، میتواند به ساخت پیشبینیهای آتی صحیحتر بپردازد. پس از آنکه یک کلیپ صوتی در شبکه عصبی اجرا شد (یک تکه در هر بار)، کار با نگاشت هر تکه صوتی با حروفی که در طول هر تکه بیشتر بیان میشوند پایان مییابد. در تصویر زیر، نگاشت کلمه «HELLO» قابل مشاهده است.

شبکه عصبی پیشبینی میکند که یکی از محتملترین کلماتی که فرد گفته «HHHEE_LL_LLLOOO» است. همچنین، فکر میکند که احتمال دارد که فرد «HHHUU_LL_LLLOOO» یا «AAAUU_LL_LLLOOO» را نیز گفته باشد. گامهایی وجود دارد که برای تصفیه کردن این خروجیها باید انجام شوند. ابتدا، هر کاراکتر دارای تکرار با یک کاراکتر یکتا جایگزین میشود.
- HHHEE_LL_LLLOOO میشود HE_L_LO
- HHHUU_LL_LLLOOO میشود HU_L_LO
- AAAUU_LL_LLLOOO میشود AU_L_LO
سپس، کلیه فضاهای خالی حذف میشوند.
- HE_L_LO میشود HELLO
- HU_L_LO میشود HULLO
- AU_L_LO میشود AULLO
این موجب میشود که سه رونوشت «Hello»، «Hullo» و «Aullo» باقی بمانند. اگر هر سه این رونوشتها با صدای بلند بیان شوند شبیه به «Hello» خواهند بود. با توجه به اینکه هربار یک کاراکتر پیشبینی میشود، شبکه عصبی این سه رونوشت را تولید خواهد کرد. برای مثال اگر فرد بگوید «He would not go»، احتمال دارد یکی از رونوشتهای ممکن «He wud net go» باشد.
ترفند قابل انجام در اینجا این است که پیشبینیهای تلفظ محور با امتیاز درستنمایی موجود در یک پایگاه داده بزرگ از متنهای نوشته شده (کتابها، مقالات خبری و دیگر موارد) ترکیب شوند. بدین شکل، رونوشتهایی که واقعی بودن آنها کمتر محتمل به نظر میرسد حذف و مواردی که بیشتر واقعی به نظر میرسند حفظ میشوند. رونوشت محتمل برای «Hello»، «Hullo» و «Aullo» قطعا «Hello» خواهد بود که در مجموعه داده متنی بارها تکرار شده و لذا احتمالا درست است. بنابراین «Hello»، - به جای دیگر گزینهها - انتخاب نهایی خواهد بود.
صبر کنید!
ممکن است این پرسش برای افراد مطرح شود که که اگر شخص واقعا بگوید «Hullo» چه؟ این کلمه معتبر است و ممکن است انتخاب «Hello» صحیح نباشد.

البته ممکن است که فردی به جای «Hello» بگوید «Hullo». اما سیستم بازشناسی گفتاری مانند این (که با کلمات انگلیسی آموزش دیده) هرگز «Hullo» را به عنوان پاسخ نهایی ارائه نمیکند. از نظر سیستم، بیان این کلمه توسط کاربر در مقایسه با «Hello» غیرمحتمل است و بنابراین، مدل همیشه - بدون توجه به اینکه شخص چقدر روی حرف «U» تاکید میکند - کلمه کاربر را «Hello» به حساب میآورد.
افرادی که گوشی خود را روی دیکشنری انگلیسی-آمریکایی تنظیم کردهاند، میتوانند این مورد را بیازمایند. اگر به دستیار دیجیتال کلمه «Hullo» گفته شود، خروجی حاصل از شناسایی کلمه همواره «Hello» خواهد بود. عدم تشخیص «Hullo» منصفانه به نظر میرسد، اما گاهی گوشیهای هوشمند از درک کلمات معتبری که کاربر میگوید عاجز هستند. به همین دلیل است که مدلهای بازشناسی گفتار همیشه با دادههای بیشتر بازآموزی میشوند تا بتوانند این مسائل حاشیهای را حل کنند.
آیا افراد میتوانند سیستم بازشناسی گفتار خود را بسازند؟
یکی از جذابترین نکات درباره «یادگیری ماشین» (Machine Learning) سادگی آن در برخی موارد است. با داشتن مقادیری داده و دادن آن به الگوریتم یادگیری ماشین، کاربر به طرز معجزهآسایی یک سیستم هوش مصنوعی در کلاس جهانی دارد که روی کارت ویدئو ویژه بازیهای کامپیوتری خود اجرا میکند.
این امر در برخی موارد صادق است ولی در بازشناسی گفتار چنین نیست. در این مساله، کاربر باید بر چالشهای نامحدودی غلبه کند، از این جمله میتوان به کیفیت بد میکروفون، نویز پس زمینه، بازتاب و پژواک (اکو)، تنوع لهجهها و بسیاری از موارد دیگر اشاره کرد. همه این مسائل باید در مجموعه دادههای آموزش لحاظ شده باشد تا شبکه عصبی بتواند با آنها سر و کله بزند.
در ادامه، مثال دیگری در همین رابطه ارائه میشود. انسانها در درک صدای فردی که در محیط شلوغ با صدای بلند صحبت میکند تا صدایش در میان نویز موجود در محیط شنیده شود، مشکلی ندارند. اما شبکههای عصبی باید برای مدیریت چنین شرایط خاصی آموزش ببینند. بنابراین مدل باید با دادههای افرادی که در نویز فریاد میزنند نیز آموزش ببیند.
برای ساخت یک سیستم تشخیص صدا که در سطح «سیری» (SIRI)، الکسا (Alexa) یا !Google Now کار میکند نیاز به حجم بالایی از دادههای آموزش - بسیار بیشتر از آنکه صدها نفر برای ثبت صدایشان استخدام شوند - نیاز است. از آنجا که کاربران تحمل کمی در مقابل کیفیت پایین سیستمهای تشخیص صدا دارند، نمیتوان از این چالشها چشمپوشی کرد.
هیچ کس سیستم تشخیص صدایی که ۸۰٪ مواقع کار کند را نمیخواهد. برای شرکتی مانند گوگل یا آمازون، صدها هزار ساعت صداهای ضبط شده از زندگی واقعی افراد حکم طلا دارد. این سادهترین چیزی است که سیستمهای بازشناسی گفتار را از یک سیستم معمولی خانگی متمایز میسازد.
نکته اصلی نهفته در پس قرار دادن !Google Now و Siri در گوشیهای هوشمند، به صورت رایگان یا در ازای پرداخت مبلغ بسیار ناچیز این است که کاربران باید آنها را تا حد ممکن استفاده کنند! هر چیزی که کاربر به چنین سیستمهایی بگوید تا ابد ذخیره میشود و بهعنوان دادههای آموزش برای نسخههای آتی الگوریتمهای بازشناسی گفتار مورد بهرهبرداری قرار میگیرند. عجب بازی بزرگی!
افرادی که این حرف را باور ندارند میتوانند روی این لینک کلیک کرده و همه حرفهایی که تاکنون به دستیار صوتی !Google Now زدهاند را بشنوند.

برای بلندگوهای الکسا، کاربران میتوانند به صفحه مشابهی در نرمافزار کاربردی این سختافزار مراجعه کنند. این در حالیست که Apple حتی به کاربران اجازه نمیدهد به دادههای خودشان در این رابطه دسترسی داشته باشند.

مطالعه بخش بعدی این مطلب به شما توصیه میشود.
اگر نوشته بالا برای شما مفید بود، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- آموزش مقدماتی پردازش صوت با متلب (MATLAB)
- آموزش ساخت اپلیکیشن دیکشنری صوتی دو زبانه با قابلیت تشخیص صدای کاربر
- آموزش کاربردهای پردازش سیگنالهای صدا و ارتعاشات در سامانههای مکانیکی و زیستی در متلب
- گنجینه آموزشهای یادگیری ماشین و دادهکاوی
^^







