



آموزش یادگیری ماشین با مثالهای کاربردی ــ بخش پنجم




در بخشهای پیشین از مجموعه مطالب «آموزش یادگیری ماشین با مثالهای کاربردی»، مبانی و مفاهیم هوش مصنوعی و یادگیری ماشین، شبکههای عصبی، یادگیری عمیق، شبکههای عصبی پیچشی، بینایی ماشین و تشخیص چهره مورد بررسی قرار گرفت. در این بخش، به شبکههای عصبی بازگشتی و مدلهای دنباله به دنباله پرداخته خواهد شد.
«ترجمهگر گوگل» (Google Translate)، سرویسی است که اغلب افراد با آن آشنایی کامل داشته و دستکم یکبار برای ترجمه کلمه یا متن از یک زبان مبدا به دیگر زبانها، به آن سر زدهاند. این سرویس ماشینی، از ۱۰۰ زبان زنده گوناگون پشتیبانی میکند و از طریق گوشیها و ساعتهای هوشمند نیز به صورت رایگان در دسترس همگان است. کاری که این سرویس انجام میدهد چیزی شبیه جادو است! (البته با گذشت زمان و استفاده مکرر افراد از این سرویس، حتی ارائه چنین خدماتی توسط ماشین نیز برای انسانها طبیعی شده)

شکل ۱: مترجم ماشینی در گوشیهای هوشمند
فناوری نهفته در پس ترجمهگر گوگل را «ترجمه ماشینی» (Machine Translation) مینامند. این سرویس امکان برقراری ارتباط به زبانهای گوناگون را برای افراد در شرایط مختلف فراهم و اینگونه جهان را دستخوش تغییر کرده.
اغلب افراد از آن برای ترجمه متون خود بهره میبرند، برای مثال دانشآموزان مدرسهای برای حل تمرینات زبان انگلیسی خود و دانشجویان برای ترجمه متون تخصصی و مقالات از آن استفاده میکنند. این در حالیست، کمتر کسانی هستند که بدانند شیوه عملکرد این سرویس چگونه و چه رویکردی در پس آن نهفته است.

شکل ۲: ترجمهگر گوگل، قویترین سرویس ترجمه ماشینی
روش یادگیری عمیق، رویکرد پژوهشگران به ترجمه ماشینی را بهطور کامل تغییر داد. پژوهشگران این حوزه که از ترجمه زبان تقریبا هیچ چیز نمیدانستند، با بهرهگیری از این رویکرد «یادگیری ماشین» (Machine Learning)، بهترین راهکارهای ترجمه ماشینی ساخته شده توسط دیگر کارشناسان را شکست دادند.
فناوری موجود در پس سرویس ترجمهگر ماشینی ساخته شده با یادگیری عمیق، «یادگیری دنباله به دنباله» (sequence-to-sequence learning) نام دارد. این روش بسیار قدرتمند میتواند در حل بسیاری از مشکلات مفید باشد. از آنجا که توانمندی این روش در ترجمه ماشینی بسیار بالا است، هدف این مطلب استفاده از آن برای نوشتن رباتهای چت هوش مصنوعی محسوب میشود. همچنین، در ادامه همین مطلب به منظور آشنایی با دیگر تواناییهای روش مذکور مدلی برای شرح تصاویر (عنوانگذاری برای تصویر) ارائه خواهد شد.
ترجمه کامپیوتری
چگونه میتوان یک کامپیوتر را به گونهای برنامهریزی کرد که زبان انسانی را ترجمه کند؟ در پاسخ به این سوال باید گفت، سادهترین رویکرد جایگزینی هر کلمه در جمله با ترجمه آن کلمه در زبان مقصد است.

در تصویر زیر یک نمونه از ترجمه کلمه به کلمه از یک زبان مبدا (اسپانیایی) به زبان مقصد (انگلیسی) قابل مشاهده است.

شکل ۳: در جمله بالا هر کلمه اسپانیایی با معادل آن در زبان انگلیسی جایگزین شده است.
پیادهسازی روش بیان شده بسیار ساده است زیرا برای این کار تنها کافیست ترجمه هر کلمه را در دیکشنری جستوجو کرد. اما نتایج خروجی چنین راهکار سادهای به همان میزان بد خواهد بود، زیرا در این روش دستور زبان و محتوا نادیده گرفته میشود.
بنابراین، کار بعدی که باید انجام شود افزودن «قواعد ویژه زبان» (language-specific rules) به مدل جهت ارتقای نتایج آن است. برای مثال، انسان ممکن است یک عبارت دو کلمهای را به صورت یک گروه واحد از کلمات ترجمه کند. همچنین، احتمال دارد ترتیب اسمها و صفتها را تغییر دهد، زیرا مثلا ترتیب آنها در اسپانیایی معمولا برعکس انگلیسی است.

شکل ۴: لحاظ کردن دستور زبان و محتوا برای ترجمه خوب لازم است.
جواب داد! تنها با افزودن چند قاعده بیشتر و با افزایش مدیریت دستور زبان، برنامه قادر به ترجمه هر جملهای خواهد بود. روشی که بیان شده، شیوه مورد استفاده در سیستمهای ترجمه ماشین اولیه است. زبانشناسان با قواعد پیچیدهای مواجهند و آنها را یک به یک برنامهریزی کردهاند. برخی از هوشمندترین زبانشناسان دنیا در طول سالهای جنگ سرد برای ساخت یک سیستم ترجمه بهمنظور تفسیر سادهتر ارتباطات روسها، به سختی تلاش کردند.
متاسفانه، این روش تنها برای اسناد آسان و دارای ساختار ساده مانند گزارشهای آب و هوا جوابگو بود. مشکل از آنجا ناشی میشد که زبان انسانی از یک مجموعه ثابت از قواعد پیروی نمیکند بلکه، سرشار از استثناها، تنوعات قومی و شکستهنویسی بدون هرگونه اصل و قانونی است. شیوه امروزی انگلیسی صحبت کردن افراد، از کسانی که صدها سال پیش این زبان را اختراع کردهاند روانتر است و دلیل این امر تعریف قواعد دستور زبان است.
بهبود ترجمه کامپیوتری با استفاده از آمار
پس از شکست سیستمهای مبتنی بر قاعده، رویکردهای جدید ترجمه با استفاده از مدلهای مبتنی بر آمار و احتمالات به جای قواعد دستور زبان افزایش یافت. ساخت یک سیستم ترجمه ماشینی نیازمند حجم زیادی از دادههای آموزش است که در آن یک متن مشابه دستکم به دو زبان ترجمه شده باشد.

این متن دو بار ترجمه شده را «parallel corpora» مینامند. مشابه روشی که سنگ روزتا توسط دانشمندان در دهه ۱۸۰۰ برای درک هیروگلیف مصری از یونانی استفاده شده، کامپیوترها نیز میتوانند از parallel corpora برای حدس زدن چگونگی ترجمه از یک زبان به دیگری استفاده کنند.
خوشبختانه، متنهای ترجمه شده به دو زبان مختلف در مکانهای متعددی موجودند. برای مثال، مذاکرات پارلمان اروپا توسط این نهاد به ۲۱ زبان ترجمه میشود. بنابراین اغلب پژوهشگران معمولا از دادههای موجود برای ساخت سیستمهای مترجم استفاده میکنند.

شکل ۵: دادههای آموزش زیادی در جهان وجود دارند. اما این موارد معمولا میلیونها میلیون خط از اسناد خشک رسمی و دولتی هستند.
تفکر احتمالاتی
تفاوت اساسی سیستمهای ترجمه آماری با دیگر سیستمها آن است که تلاشی برای تولید ترجمه دقیق (تحتاللفظی) نمیکنند. در عوض، هزاران ترجمه ممکن را تولید کرده و این ترجمهها را با احتمال صحیح بودن آنها رتبهبندی میکنند. این روشها، «صحیح» بودن یک ترجمه را بر اساس مشابهت آن با دادههای آموزش تخمین میزنند.
گام ۱: شکستن متن اصلی به تکهها
در ابتدا باید جمله را به تکههای سادهای شکست که به سادگی قابل ترجمه هستند.

شکل ۶: شکستن جمله به کلمات سازنده آن برای ترجمه
گام ۲: پیدا کردن همه ترجمههای ممکن برای هر تکه
پس از شکستن متن به تکههای ساده و قابل ترجمه، هر یک از این تکهها باید به کلیه روشهایی که انسانها آنها را ترجمه کردهاند و در دادههای آموزش وجود دارد ترجمه شوند.
لازم به ذکر است که برای ترجمه این تکهها، فقط از یک فرهنگ لغت ساده بهره گرفته نخواهد شد. بلکه، از ترجمههایی که انسانها برای آنها در جملههای جهان واقعی بهکار بردهاند استفاده میشود. این امر به گردآوری روشهای گوناگون کاربرد یک کلمه در متن کمک میکند.

شکل ۷: حتی متداولترین عبارات نیز ترجمههای متعددی دارند.
برخی از ترجمههای موجود برای هر یک از تکهها، بیش از سایر آنها استفاده میشوند. بر اساس تعداد تکرارهایی که برای هر ترجمه در دادههای آموزش وجود دارد، میتوان به آنها امتیاز داد. برای مثال، معمولا اگر فردی بگوید «Quiero»، معنای متداول آن «I want» و نه «I try» است. بنابراین بر اساس تعداد دفعاتی که «Quiero» در مجموعه داده «I want» ترجمه شده، به آن وزن بیشتری - نسبت به ترجمههایی با تکرار کمتر - تخصیص داده میشود.
گام ۳: تولید همه جملههای ممکن و یافتن محتملترین حالت
اکنون، کلیه ترکیبهای ممکن از ترجمه تکهها جهت ساخت کلیه ترجمههای ممکن برای جمله تولید میشوند. میتوان با استفاده از ترجمه تکههایی که در گام دوم لیست شدهاند و ترکیب آنها، نزدیک به ۲٬۵۰۰ ترجمه گوناگون ساخت.
در ادامه نمونههایی از این ترجمهها نشان داده شدهاند.
I love | to leave | at | the seaside | more tidy.
I mean | to be on | to | the open space | most lovely.
I like | to be |on | per the seaside | more lovely.
I mean | to go | to | the open space | most tidy.
اما در سیستمهای جهان واقعی، ترکیبات بیشتری نیز وجود دارد، زیرا انسانها از توالیهای متفاوتی از واژهها در جملات خود استفاده میکنند. در ادامه مثالهایی از این مورد قابل مشاهده است.
I try | to run | at | the prettiest | open space.
I want | to run | per | the more tidy | open space.
I mean | to forget | at | the tidiest | beach.
I try | to go | per | the more tidy | seaside.
اکنون نیاز به اسکن کردن همه این جملات تولید شده برای یافتن گزینه «انسانگونهتر» است. برای انجام این کار، هر جمله تولید شده با میلیونها جمله واقعی از کتابها و متنهای خبری نوشته شده به زبان انگلیسی مقایسه میشود. هرچه جملات انگلیسی بیشتری در دسترس باشند بهتر است زیرا به بهبود خروجی کمک شایان ذکری خواهد کرد.
این ترجمه احتمالی مفروض است:
I try | to leave | per | the most lovely | open space.
به احتمال زیاد تا به حال هیچکس جملهای مانند این را به زبان انگلیسی ننوشته. به این جمله امتیاز احتمال کمی داده میشود. اکنون ترجمه احتمالی زیر مفروض است:
I want | to go | to | the prettiest | beach.
این جمله به برخی (تعداد قابل توجهی) از جملات موجود در مجموعه داده شبیه است، بنابراین امتیاز احتمال بالایی به آن داده میشود. ترجمه نهایی منتخب «I want to go to the prettiest beach» است.
ترجمه ماشینی، یک نقطه عطف بزرگ
سیستمهای ترجمه ماشینی آماری در صورت داشتن حجم مناسبی از دادههای آموزش، نسبت به سیستمهای مبتنی بر قاعده عملکرد بهتری دارند. «فرانز جوزف آک» (Franz Josef Och)، این ایده را توسعه داد و در اوایل سال ۲۰۰۰ از آن برای ساخت ترجمهگر گوگل استفاده کرد. ترجمه ماشین سرانجام در دسترس همه جهانیان قرار گرفت.
در روزهای اول ارائه این سرویس، برای اغلب افراد شگفتآور بود که یک رویکرد «خنگ» برای ترجمه که مبتنی بر احتمال است، بهتر از دیگر روشهای مبتنی بر قاعده ساخته شده توسط زبانشناسان کار میکند. این امر منجر به ایجاد یک ضربالمثل معروف در میان پژوهشگران این حوزه در دهه ۸۰ شد:
«هر بار که یک زبانشناس را آتش میزنم، صحت مدلم افزایش پیدا میکند.»
ــ فردریک جلیلک (پژوهشگر در زمینه پردازش زبان طبیعی، نظریه اطلاعات و بازشناسی گفتار خودکار)
محدودیتهای ترجمه ماشین آماری
سیستمهای ترجمه ماشین آماری عملکرد خوبی دارند، اما ساخت و نگهداری آنها کار پیچیدهای است. هر جفت جدید از زبانهایی که کاربر قصد ترجمه آنها به یکدیگر را دارد، نیازمند گروهی از کارشناسان است که سلسله مراحل ترجمه را انجام دهند. به دلیل زمانبر بودن ساخت این سلسله مراحل، باید موازنهای صورت بگیرد.
در همین راستا، اگر کاربر از گوگل بخواهد که متنی را از زبان گرجی به تلوگو ترجمه کند، گوگل ابتدا آن را به انگلیسی ترجمه کرده و سپس از انگلیسی (این فرآیند به صورت داخلی انجام میشود و برای کاربر قابل مشاهده نیست) به تلوگو ترجمه میکند. دلیل این امر آن است که ترجمههای گرجی-تلوگویی زیادی اتفاق نمیافتد که سرمایهگذاری زیادی در این حوزه انجام شود. بنابراین، سلسله مراحل ترجمه نیز نسبت به ترجمه فرانسوی به انگلیسی که بسیار زیاد اتفاق میافتد، کمتر توسعه داده میشود.
بهبود ترجمه کامپیوتری، بدون استفاده از کاربر متخصص
پیچیدهترین بخش ترجمه ماشینی، جعبه سیاهی است که خودش ـ تنها با نگاه کردن به دادههای آموزش ـ میآموزد که چگونه یک متن را ترجمه کند. با وجود ترجمه ماشین آماری، انسانها همچنان نیازمند آن هستند که مدلهای آماری چند مرحلهای را ساخته و توسعه دهند.
در سال ۲۰۱۴، تیم کیانگ هیون چو راهکاری برای این امر ارائه کردند. آنها راهی کشف کردند که با بهرهگیری از آن از یادگیری عمیق برای ساخت جعبه سیاه سیستم ترجمه ماشینی استفاده کنند. مدل یادگیری عمیق ارائه شده توسط این تیم، parallel corpora را دریافت کرده و از آن برای یادگیری چگونگی ترجمه بین دو زبان بدون داشتن هرگونه مداخله انسانی استفاده میکند. دو ایده بزرگی که این کار را امکانپذیر ساختند، شبکههای عصبی بازگشتی و رمزنگاری هستند. با ترکیب این دو ایده به شیوهای زیرکانه، میتوان یک سیستم شبکه عصبی خودآموز ساخت.
شبکههای عصبی بازگشتی
در بخش دوم از مجموعه مطالب «آموزش یادگیری ماشین با مثالهای کاربردی» مبحث شبکههای عصبی مصنوعی مورد بررسی قرار گرفت. یک شبکه عصبی معمولی (غیر بازگشتی)، در واقع یک الگوریتم یادگیری ماشین عمومی است که لیستی از اعداد را دریافت کرده و نتایج را محاسبه میکند. شبکههای عصبی را میتوان به عنوان جعبه سیاهی برای حل مسائل متعدد استفاده کرد. برای مثال، میتوان از شبکه عصبی برای تخمین قیمت یک خانه برپایه ویژگیهای آن بهره برد.

اما، همچون اغلب الگوریتمهای «یادگیری ماشین» (Machine Learning)، شبکه عصبی نیز بدون حالت است. طی کار با این الگوریتم، لیستی از اعداد به آن داده میشود و بر این اساس شبکه خروجی را محاسبه میکند. اگر این اعداد مجددا هم به الگوریتم داده شوند، باز هم نتایج مشابهی را در خروجی ارائه میکند. الگوریتم شبکه عصبی هیچ حافظهای از محاسبات گذشته خود ندارد. به عبارت دیگر، ۲+۲ برای آن همیشه برابر با ۴ است.
یک شبکه عصبی بازگشتی (یا به طور خلاصه RNN) نسخه تغییر یافتهای از شبکه عصبی است که در آن حالت پیشین شبکه یکی از ورودیهای آن جهت انجام محاسبات بعدی محسوب میشود. این بدین معناست که محاسبات پیشین، نتیجه محاسبات آتی را دستخوش تغییر میکند.

شکل ۹: شبکه عصبی بازگشتی (RNN) دارای حافظه است.
سوالی که اکنون پیش میآید این است که چرا باید از چنین چیزی استفاده کرد؟ مگر ۲+۲ همواره و بدون در نظر گرفتن محاسبات پیشین برابر با ۴ نیست؟ این ترفند به شبکه عصبی امکان یادگیری الگوهای موجود در توالی دادهها را میدهد. برای مثال، میتوان از این شبکه برای پیشبینی محتملترین کلمه بعدی در یک جمله بر اساس چند کلمه اول استفاده کرد.
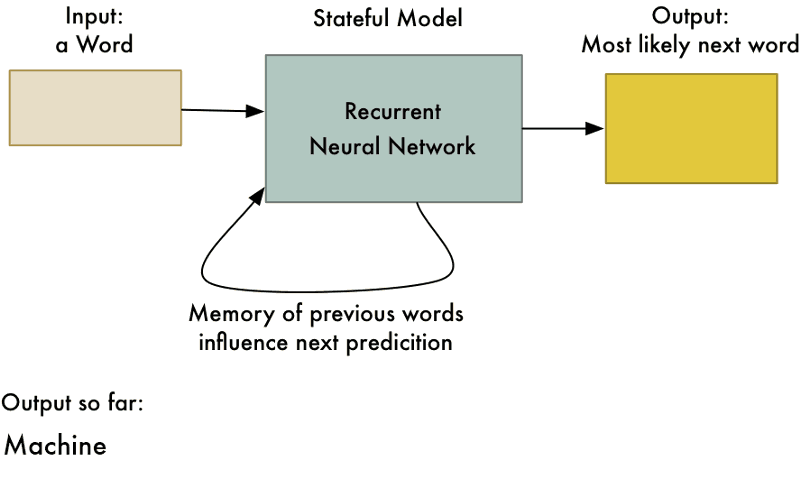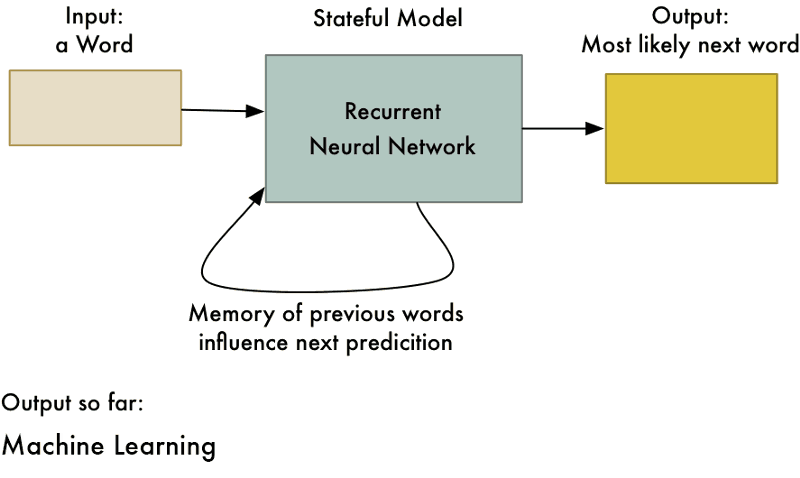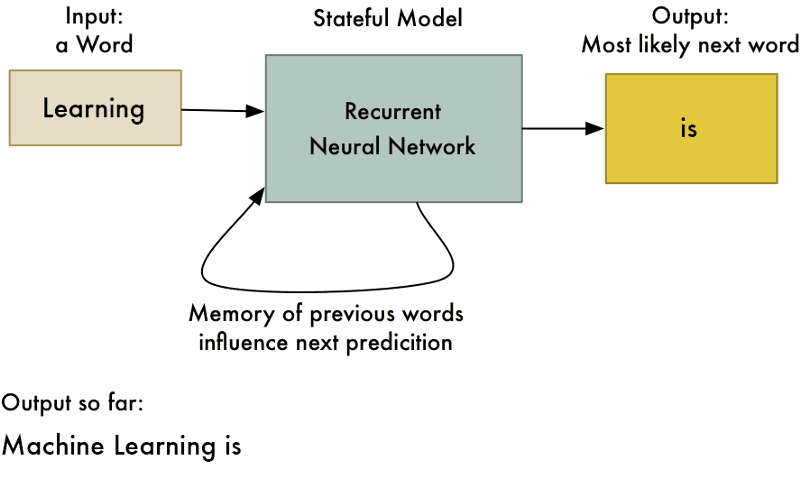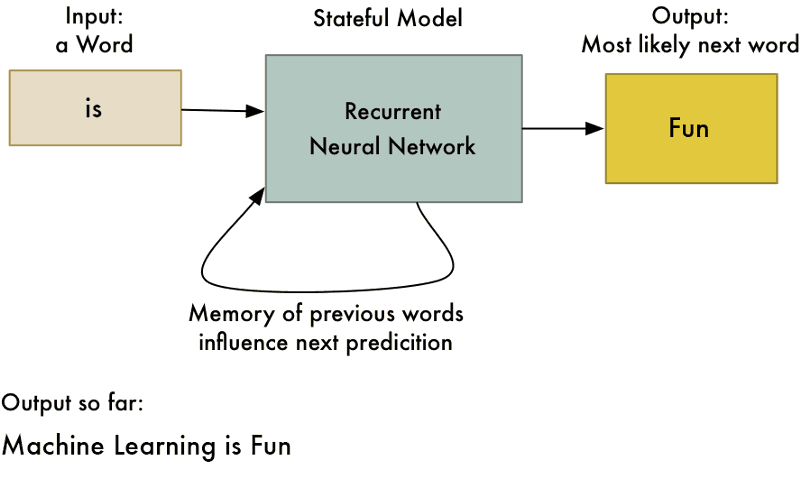
شکل ۱۰: این رویکردی است که میتوان با استفاده از آن نرمافزار «تصحیح خودکار» برای گوشیهای هوشمند ساخت.
علاقمندان به یادگیری شبکه عصبی بازگشتی (RNN)، میتوانند بخش دوم از این مجموعه مطلب را مطالعه کنند که به تولید کتاب جعلی بر اساس کتاب ارنست همینگوی و همچنین ساخت یک مرحله از بازی برادران سوپر ماریو میپردازد.
رمزنگاری
ایده دیگری که نیاز به بررسی دارد، رمزنگاری است. درباره رمزنگاری در بخش چهارم و به عنوان بخشی از فرآیند تشخیص چهره صحبت شد. برای تشریح رمزنگاری، مجددا چگونگی تشخیص چهره دو انسان متفاوت توسط کامپیوتر به صورت مختصر مورد بررسی قرار میگیرد.
برای آنکه چهره دو فرد متفاوت از هم با کامپیوتر تشخیص داده شود، سنجههای مختلف از هر چهره گردآوری شده و از مقایسه آنها برای تشخیص یکی بودن یا نبودن دو چهره استفاده میشود. برای مثال، ممکن است اندازه گوش و فاصله بین چشمها در دو چهره اندازهگیری و مقایسه شوند. افرادی که سریال تحقیقات صحنه جرم (سیاسآی) را دیدهاند، با این ایده آشنایی دارند.

ایده تبدیل چهره به لیستی از سنجهها مثالی از رمزنگاری است. در این فرآیند، داده خام (تصویر یک چهره) از ورودی گرفته شده و به لیستی از سنجهها (رمزنگاری) تبدیل میشود. این سنجهها به عنوان ارائهای از داده اصلی (تصویر) قابل استفاده هستند. اما، همانطور که در بخش چهارم بیان شد، انسان نمیتواند لیست خاصی از ویژگیهای چهره را برای سنجش آن تولید کند. کامپیوتر در تعیین و محاسبه این سنجهها که به بهترین شکل چهره دو شخص را از یکدیگر متمایز میکند عملکرد بهتری دارد.

شکل ۱۱: سنجههای چهره «ویل فرل» (Will Ferrell) که توسط شبکه عصبی تولید شدهاند. این شبکه عصبی آموزش دیده تا سنجههایی را تولید کند که برای چهرههای افراد مختلف متمایز باشند.
مثال ارائه شده، نمونهای از رمزنگاری است. این کار امکان ارائه موارد بسیار پیچیده (مانند تصویر یک فرد) را به صورت ساده (با ۱۲۸ عدد) میدهد. با بهرهگیری از این نمایش ساده، میتوان دو چهره متفاوت را به شکل آسانتری با یکدیگر مقایسه کرد، زیرا به جای مقایسه کل تصویر، تنها کافیست ۱۲۸ سنجه هر چهره با یکدیگر مقایسه شوند. میتوان کار مشابهی را برای مقایسه جملات با یکدیگر نیز انجام داد. در این راستا میتوان از روشی رمزنگاری استفاده کرد که کلیه جملات را به صورت یک مجموعه از اعداد نشان میدهد.

شکل ۱۲: این لیست از اعداد، نشانگر جمله انگلیسی «Machine Learning is Fun» است. هر جمله با مجموعه متمایزی از اعداد نشان داده میشود.
برای تولید این رمزنگاری، جمله به شبکه عصبی بازگشتی (RNN) خورانده میشود (یک کلمه در واحد زمان). نتایج نهایی پس از پردازش آخرین کلمه، سنجههایی است که نشانگر کل جمله هستند.
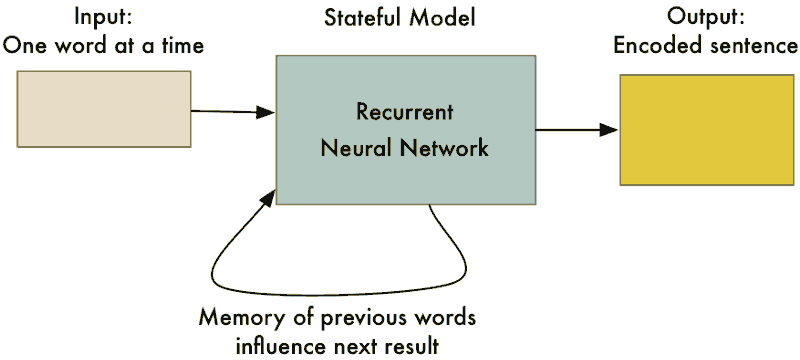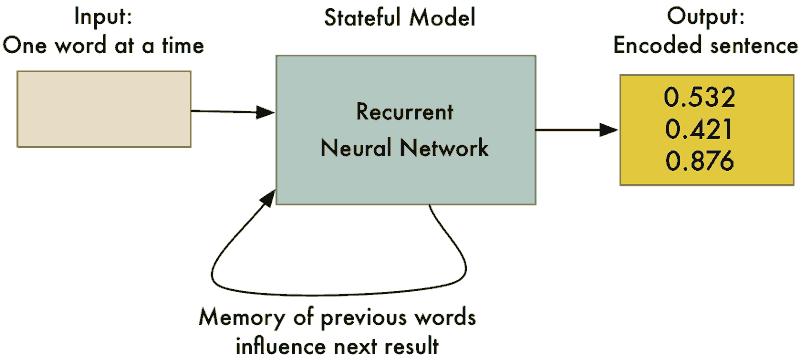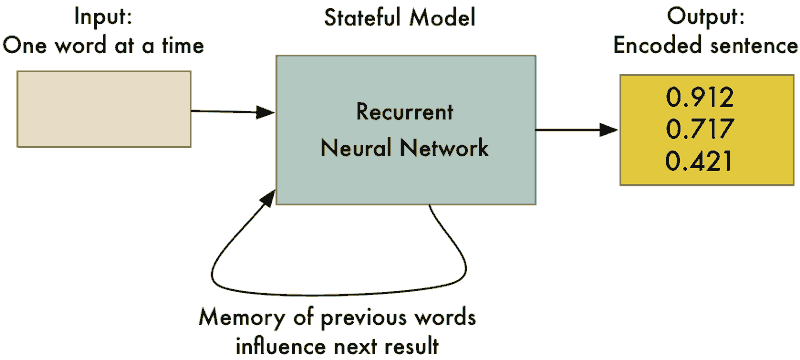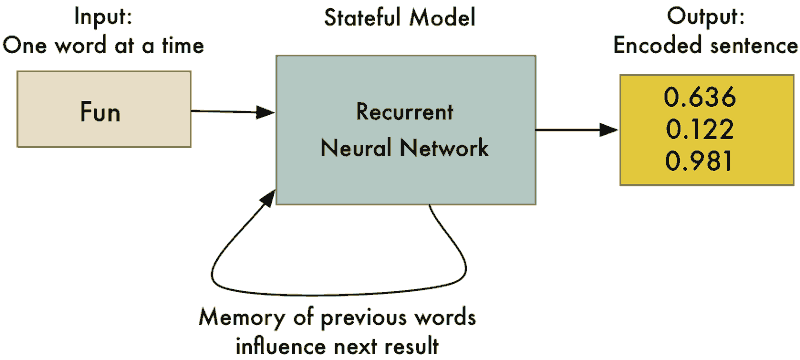
شکل ۱۲: به دلیل آنکه شبکه عصبی بازگشتی برای هر یک از کلماتی که به آن داده شده دارای حافظه است، نتیجه نهایی محاسبه شده، ارائهای از کلیه کلمات جمله است.
روش بیان شده راهکاری برای ارائه کل جمله به صورت مجموعهای از اعداد یکتا است. انسان نمیداند که هر عدد یکتا چه معنایی دارد و البته این مساله اهمیتی هم ندارد. تا زمانی که هر جمله به وسیله یک مجموعه از اعداد یکتا شناسایی شود، نیازی به دانستن چگونگی تولید این اعداد نیست.
زمان ترجمه فرا رسیده!
اکنون مشخص شد که چگونه از شبکه عصبی بازگشتی برای رمزنگاری یک جمله به مجموعهای از اعداد یکتا استفاده میشود. یک ایده آن است که دو شبکه RNN را به صورت انتها به انتها به یکدیگر متصل کرد. در این شرایط دومین شبکه میتواند رمزنگاری را دریافت کرده و از منطق مشابهی برای معکوس کردن آن و تولید جمله اصلی استفاده کند.

شکل ۱۳: استفاده از شبکه عصبی بازگشتی برای رمزنگاری و رمزگشایی متن
البته داشتن توانایی رمزنگاری یک جمله و سپس رمزگشایی آن خیلی مفید نیست. اما اگر بتوان شبکه عصبی را به گونهای آموزش داد که قادر باشد جمله را به زبان اسپانیایی (به جای انگلیسی) رمزگشایی کند چه؟ میتوان از دادههای آموزش parallel corpora برای آموزش شبکه بهمنظور انجام این کار استفاده کرد.

شکل ۱۴: استفاده از شبکه عصبی بازگشتی برای تولید ترجمهگر ماشینی
و به همین صورت یک راه عمومی برای تبدیل دنبالهای از کلمات انگلیسی به توالی برابری از کلمات اسپانیایی ساخته شد! این ایده بسیار قدرتمندی است، زیرا:
- این رویکرد معمولا با مقدار دادههای آموزشی که کاربر دارد و قدرت پردازش کامپیوتر محدود میشود. پژوهشگران یادگیری ماشین (Machine Learning) این روش را چند سال پیش اختراع کردهاند، اما به خوبی سیستمهای یادگیری ماشین آماری که ساخت و توسعه آنها ۲۰ سال طول کشید کار میکند.
- این ایده به دانستن هیچ قاعدهای از زبان انسانی وابسته نیست. در این رویکرد، الگوریتم خود قوانین را کشف میکند. این بدین معناست که نیازی به کاربر متخصص برای تنظیم هر گام از مراحل ترجمه نیست بلکه کامپیوتر این کار را انجام میدهد.
- این رویکرد برای هر نوع مساله دنباله به دنبالهای جوابگو است. همچنین میتوان با استفاده از آن، بسیاری از مسائل را به مسائل دنباله به دنباله تبدیل کرد.
لازم به ذکر است که بهمنظور کارایی داشتن مدل برای دادههای جهان واقعی، کارهای دیگری نیز انجام شده است. از این جمله میتوان به سر و کار داشتن با بحث طولهای مختلف جملات ورودی و خروجی اشاره کرد (خواندن این مطلب توصیه میشود). مشکل دیگر ترجمه صحیح کلمات نادر است.
ساخت سیستم ترجمه دنباله به دنباله سفارشی
اگر فردی قصد داشته باشد سیستم ترجمه زبانی خود را بسازد، یک پیش نمایش (Demo) با کتابخانه «تنسورفلو» (TensorFlow) از سیستم ترجمه زبانی که زبان انگلیسی را به فرانسه ترجمه میکند از اینجا در دسترس است. این فناوری بسیار نو و به شدت نیازمند منابع است. حتی اگر یک کامپیوتر سریع با کارت گرافیک بالا موجود باشد، ممکن است زمان پردازش برای آموزش دادن سیستم ترجمه زبان یک ماه مداوم به طول بیانجامد.
همچنین، روشهای ترجمه زبان دنباله به دنباله به سرعت بهبود مییابند و بنابراین همگام بودن با آنها کاری دشوار است. بسیاری از ارتقاهای اخیر (مانند افزودن یک مکانیزم توجه یا ردیابی متن) نتایج را به شدت بهبود بخشیده، اما سرعت این توسعهها آنقدر زیاد است که حتی صفحه ویکیپدیا نیز برای آنها هنوز ساخته نشده. برای آنکه بتوان کار قابل توجهی در زمینه یادگیری دنباله به دنباله انجام داد، باید با توسعههایی که در این زمینه اتفاق میافتد به روز بود.
قدرت جالب مدلهای دنباله به دنباله
همانطور که پیش از این بیان شد، مدلهای دنباله به دنباله علاوه بر ترجمه ماشینی، کاربردهای متعدد دیگری نیز دارند. حدود یک سال پیش، پژوهشگران گوگل نشان دادند که میتوان از این مدلها برای ساخت رباتهای هوش مصنوعی استفاده کرد. ایده این کار بسیار آسان و البته فوقالعاده است. آنها ابتدا لوگ گفتوگوهای بین کارکنان گوگل و تیم پشتیبانی گوگل را ذخیره میکردند. سپس یک مدل دنباله به دنباله را آموزش دادند که پرسش کارکنان ورودی و پاسخ تیم پشتیبانی فنی «ترجمه» آن بود.

شکل ۱۵: استفاده از مدل دنباله به دنباله برای ساخت ربات پاسخگوی فنی
هنگامی که یک کاربر با ربات تعامل برقرار میکرد، مدل هر یک از پیامهای کاربر را به منظور دریافت پاسخ از ربات، برای آن «ترجمه» میکرد. نتیجه نهایی یک ربات نیمه-هوشمند است که میتواند (گاهی) پرسشهای پشتیبانی فنی واقعی را پاسخ دهد. در ادامه نمونه مکالمه بین کاربر و ربات (مقاله اصلی) قابل مشاهده است.
Human: connection refused or something like that
Machine: may i know the version of network connect you connect?
Human: i am not sure i know that
Machine: is the network connect prompting for any user certificate?
Human: yes
Machine: are you at home or at work at the moment? office?
Human: i am at home
Machine: try this. goto <URL redacted> page and enter your name and password
Human: done
Machine: try logging in with <NAME redacted> and check if its working fine now
Human: yes, now it works!
Machine: great. anything else that i can help?
آنها همچنین تلاش کردند که بر پایه میلیونها زیرنویس فیلم موجود، یک ربات چت بسازند. ایده این کار استفاده از مکالمات بین کاراکترهای فیلم برای آموزش دادن مدل به صورت یک انسان بود. جمله ورودی این مدل یک خط از دیالوگی است که توسط یک کاراکتر فیلم گفته میشود و آنچه کاراکتر بعدی میگوید «ترجمه» به حساب میآید.

شکل ۱۶: مدل استفاد شده برای ساخت ربات با بهرهگیری از زیرنویس فیلمها
این امر نتایج بسیار جالبی را به دنبال داشت. نه تنها ربات مانند انسانها مکالمه میکرد، بلکه از خود، هوشمندی نیز نشان میداد.
Human: my name is david. what is my name?
Machine: david.
Human: my name is john. what is my name?
Machine: john.
Human: are you a leader or a follower?
Machine: i’m a leader.
Human: are you a follower or a leader?
Machine: i’m a leader.
این صرفا آغاز کارهای ممکن با استفاده از مدلهای دنباله به دنباله است. این مدلها صرفا به تبدیل یک جمله به جمله دیگر محدود نشدهاند. همچنین این امکان نیز وجود دارد که یک تصویر به مدل دنبالهای تبدیل شود که میتواند آن تصویر را به متن مبدل کند. یک تیم دیگر در گوگل این کار را با جایگزینی اولین شبکه عصبی بازگشتی (RNN) با یک شبکه عصبی پیچشی (مانند آنچه در بخش سوم بیان شد) انجام دادند. این کار امکان دریافت تصویر به عنوان ورودی به جای جمله را فراهم میکند. کلیت کار مشابه آنچه است که پیشتر برای مدل ترجمه ماشینی بیان شد.

شکل ۱۷: استفاده از مدل دنباله به دنباله برای عنوانگذاری هوشمند تصویر
درست به همین صورت میتوان تصویر را به کلمات تبدیل کرد (در صورتی که حجم بسیاری بالایی از دادههای آموزش وجود داشته باشد). «آندراژ کارپثی» (Andrej Karpathy) این ایده را گسترش داده و از آن برای ساخت سیستمی که قادر به تشریح تصاویر با سطح خوبی از جزئیات است استفاده کرد. این کار با پردازش نواحی گوناگون یک تصویر بهطور مجزا اتفاق میافتد.

شکل ۱۸: تصویری از این مقاله که توسط آندراژ کارپثی ارائه شده است.
این کار امکان ساخت موتورهای جستوجوی تصویری که قادر به یافتن تصاویری متناسب با یک متن خاص هستند را فراهم میکند.

شکل ۱۸: مثالی در همین رابطه
حتی پژوهشگرانی وجود دارند که روی معکوس این مساله یعنی تولید تصویر بر اساس یک توصیف متنی نیز کار میکنند. تنها با مثال بیان شده در این مطلب نیز میتوان قدرت مدلهای دنباله به دنباله را مشاهده کرد. این روش کاربردهای زیادی از بازشناسی گفتار گرفته تا بینایی ماشین دارد.

بخش ششم این مجموعه مطلب را مطالعه کنید.
اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- آموزش یادگیری ماشین
- آموزش یادگیری عمیق (Deep learning)
- مجموعه آموزشهای کاربردی شبکههای عصبی مصنوعی
- مجموعه آموزشهای دادهکاوی یا Data Mining در متلب
- آموزش یادگیری ماشین (Machine Learning) با پایتون (Python)
- گنجینه آموزشهای یادگیری ماشین و دادهکاوی
- دوره یادگیری ماشین با مثالهای کاربردی
^^








