



هوش مصنوعی با پایتون – آموزش با انجام پروژه + نمونه کدها
زبان برنامه نویسی پایتون (Python) یکی از زبانهای همهمنظوره است که از آن میتوان در توسعه پروژههای مختلفی استفاده کرد. این زبان برنامه نویسی به دلیل داشتن ابزارها و کتابخانههای جامع، در حوزه هوش مصنوعی (Artificial Intelligence) یا همان AI نیز توجه بسیاری از برنامه نویسان فعال در این حیطه را به خود جلب کرده است و به عنوان یکی از پرکاربردترین زبانهای برنامه نویسی رشته هوش مصنوعی محسوب میشود. در مطلب حاضر، به ویژگیهای مهم پایتون در هوش مصنوعی اشاره و کتابخانههای مهم پایتون و منابع یادگیری رایج آنها در این حیطه (هوش مصنوعی) معرفی میشوند. همچنین، در این مطلب، به نحوه پیادهسازی تعدادی از مدلهای هوش مصنوعی با پایتون پرداخته خواهد شد تا افراد علاقهمند به این شاخه از برنامه نویسی، با روال حل مسئله و ساخت مدلها آشنایی کلی پیدا کنند.
- با مفاهیم و کاربردهای هوش مصنوعی و یادگیری عمیق آشنا میشوید.
- ویژگیها و مزایای پایتون در توسعه پروژههای AI را میآموزید.
- کتابخانههای مهم پایتون و کاربردهای هر یک را یاد میگیرید.
- مراحل پیادهسازی مدلهای یادگیری ماشین و یادگیری عمیق را بهشکل گامبهگام میآموزید.
- نحوه پیادهسازی پروژههای واقعی AI با دادههای مختلف را تمرین میکنید.
- منابع تخصصی و مسیرهای یادگیری هوش مصنوعی با پایتون را خواهید شناخت.


مروری اجمالی بر هوش مصنوعی
هوش مصنوعی به عنوان یکی از گرایشهای حوزه و رشته علوم کامپیوتر محسوب میشود که هدف محققان این حیطه، طراحی و ساخت سیستمهای مصنوعی هوشمندی است که شیوه رفتار، عملکرد و تفکر انسان را تقلید کنند و بدون نیاز به دخالت انسان، وظایف و مسئولیتهایی را انجام دهند.
برای حل مسائل ساده، میتوان سیستمهای هوشمندی را با استفاده از یک سری دستورات شرطی طراحی کرد که با در نظر گرفتن تعدادی از محدودیتها، عملکردی خاص را انجام میدهند. برای حل مسائل پیچیدهتر، نیاز است که برای آموزش ماشین از روشهای دیگری استفاده شود تا ماشین بتواند خودش درباره مسئله تصمیم بگیرد و رفتار آن محدود به چندین دستور شرطی ساده نباشد.
«یادگیری ماشین» (Machine Learning) و «یادگیری عمیق» (Deep Learning) دو زیر شاخه اصلی و مهم هوش مصنوعی محسوب میشوند که از مدلها و الگوریتمهای مطرح شده در این دو حوزه میتوان برای آموزش ماشین مصنوعی استفاده کرد. در ادامه، به توضیح مختصری پیرامون این دو زیرشاخه پرداخته میشود.

یادگیری ماشین در هوش مصنوعی
با استفاده از روشهای یادگیری ماشین میتوان سیستمهای مصنوعی را برای حل مسائل مختلف آموزش داد. الگوریتمهای یادگیری ماشین که بر پایه مفاهیم آماری شکل گرفتهاند، برای یادگیری مسائل مختلف، به دادههای آموزشی احتیاج دارند. به عبارتی، مدل نهایی برای حل مسئله از دادههای آموزشی و الگوریتمهای یادگیری ماشین تشکیل شده است.

رویکردهای یادگیری ماشین را که برای یادگیری نیاز به دادههای آموزشی دارند، میتوان به دو روش کلی «یادگیری نظارت شده» (Supervised Learning) و «یادگیری بدون نظارت» (Unsupervised Learning) تقسیم کرد. در رویکرد یادگیری نظارت شده، دادههای آموزشی شامل اطلاعاتی (مقادیر هدف | Target Values) هستند که مدل نهایی باید آن اطلاعات را پیشبینی کند. مسائل نظارت شده را میتوان به دو دسته «رگرسیون» (Regression) و «دستهبندی» (Classification) تقسیم کرد.

در مسائل رگرسیون، مدل با دریافت ورودی به پیشبینی مقداری در خروجی اقدام میکند. مسائلی نظیر پیشبینی قیمت مسکن را میتوان از مسائل رگرسیون به حساب آورد که در آنها مدل با دریافت یک سری ویژگی مانند متراژ خانه، منطقه، تعداد اتاق و امکانات خانه، قیمتی را برای آن خانه پیشبینی میکند.

در مسائل دستهبندی، چندین دسته برای دادهها تعریف میشود که اطلاعات این دستهها در زمان آموزش، در اختیار مدل قرار میگیرند و در زمان تست، مدل باید به پیشبینی نوع دسته داده جدید بپردازد. مسائلی از قبیل «تحلیل احساسات» (Sentiment Analysis) متن، تشخیص نویسنده، تشخیص ایمیلهای اسپم و غیر اسپم به عنوان موضوعات دستهبندی محسوب میشوند.
در رویکرد بدون نظارت، دادههای آموزشی هیچ گونه اطلاعات اضافی ندارند و الگوریتم یادگیری ماشین بر اساس مقایسه دادههای آموزشی، به «خوشهبندی» (Clustering) آنها میپردازد و دادههای مشابه را در خوشههای جداگانه قرار میدهد.

به منظور پیادهسازی روشهای یادگیری ماشین هوش مصنوعی با پایتون میتوان از کتابخانه Scikit-Learn استفاده کرد. این کتابخانه، شامل ابزارهای مختلفی برای آمادهسازی دادههای آموزشی، آموزش مدل و سنجش نهایی عملکرد مدل است.
یادگیری عمیق در هوش مصنوعی
یادگیری عمیق، همانند یادگیری ماشین، شامل مدلهایی میشود که هدف آنها یادگیری مسائل مختلف و تصمیمگیری درباره دادههای جدید است. با این حال، میتوان روال یادگیری مسائل را به عنوان یکی از مهمترین تفاوتهای یادگیری ماشین و یادگیری عمیق دانست.

در یادگیری ماشین، به منظور آموزش الگوریتمها، باید گامی را به «مهندسی ویژگی» (Feature Engineering) اختصاص داد. به عبارتی، الگوریتمهای یادگیری ماشین دادههای خام نظیر متن، تصویر و صوت را نمیتوانند به عنوان ورودی دریافت کنند و باید از روشهای مختلف مهندسی و انتخاب ویژگی نظیر «استخراج ویژگی» (Feature Selection) استفاده کرد تا بتوان از این نوع دادهها، ویژگیهایی را استخراج کرد که برای الگوریتمهای یادگیری ماشین قابل درک و قابل استفاده باشند.
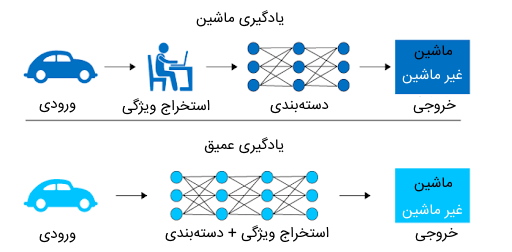
در روشهای یادگیری عمیق، نیازی نیست برنامه نویس مرحلهای را به مهندسی ویژگی تخصیص دهد. به عبارتی، مدلهای یادگیری عمیق میتوانند در حین آموزش، از دادههای ورودی بهطور خودکار ویژگیهای مختلفی را یاد بگیرند.
یکی دیگر از تفاوتهای مدلهای یادگیری عمیق با روشهای یادگیری ماشین، ساختار آنها است. برای طراحی مدلهای یادگیری عمیق از ساختار مغز انسان الهام گرفته شده است و شبکههای عصبی از ساختار لایهای ساخته شدهاند که هر لایه مسئولیت اعمال یک سری عملیات محاسباتی را بر روی داده ورودی خود دارند.

میتوان گامهای یادگیری شبکههای عصبی را به شکل زیر فهرست کرد:
- دریافت دادههای آموزشی از ورودی
- انجام محاسبات بر روی دادهها در هر لایه
- تولید مقدار خروجی در لایه نهایی مدل
- مقایسه مقدار خروجی پیشبینی شده توسط مدل با مقدار اصلی مورد انتظار
- بهروزرسانی پارامترهای مدل بر اساس خروجی پیشبینی شده توسط مدل
دادههای ورودی در شبکههای عصبی، در قالب «بردار» (Vector) ذخیره میشوند. در برنامه نویسی هوش مصنوعی با پایتون، میتوان بردارها را با استفاده از ساختار داده «آرایه» (Array) ایجاد کرد. مقادیر بردارها با عبور از هر لایه در شبکه عصبی، دستخوش تغییراتی میشوند و عملکرد هر لایه را میتوان به عنوان مهندسی ویژگی تفسیر کرد. به عبارتی، در هر لایه، یک سری عملیات محاسباتی بر روی بردارهای ورودی اعمال میشوند و خروجیهای نهایی لایه، بازنمایی خاصی از ورودیها هستند.

خاطر نشان میشود که عملیات محاسباتی در لایههای شبکههای عصبی، میتوانند بر روی هر نوع دادهای اعمال شوند. به عبارتی، شبکههای عصبی میتوانند دادههایی را از ورودی دریافت کنند که شامل اطلاعات تصاویر یا متون باشند. برای هر دو نوع داده، عملیات پردازشی یکسانی برای آموزش مدل عمیق انجام میشوند.
هوش مصنوعی با پایتون
افراد تازهکاری که قصد دارند در حیطه هوش مصنوعی به عنوان برنامه نویس مشغول به کار شوند، در ابتدای مسیر خود ممکن است برای انتخاب بهترین زبان برنامه نویسی دچار چالش شوند. زبانهای برنامه نویسی مختلفی را میتوان برای پیادهسازی مدلهای انواع هوش مصنوعی انتخاب کرد؛ با این حال، امروزه زبان پایتون به دلیل داشتن یک سری ویژگیهای خاص، تبدیل به یکی از رایجترین و پرکاربردترین زبانهای برنامه نویسی در حوزه هوش مصنوعی شده است.
پیش از ادامه این مبحث لازم است یادآور شویم که میتوانید هوش مصنوعی با پایتون را با استفاده از مجموعه آموزش هوش مصنوعی با پایتون – مقدماتی تا پیشرفته فرادرس یاد بگیرید. در ادامه مطلب، به ویژگیها و مزایای منحصربفرد این زبان خواهیم پرداخت.
چرا پایتون یکی از رایج ترین زبان های برنامه نویسی هوش مصنوعی است ؟
زبان پایتون به دلیل داشتن ویژگیهای منحصربفرد، به عنوان یکی از پرکاربردترین زبانهای برنامه نویسی محسوب میشود و برنامهنویسان و توسعهدهندگان ترجیح میدهند در بسیاری از زمینههای مختلف برنامه نویسی نظیر علم داده، یادگیری ماشین، یادگیری عمیق و تحلیل داده از آن استفاده کنند. حجم کدنویسی پایین، داشتن کتابخانههای متنوع در حوزههای مختلف برنامه نویسی، یادگیری آسان، مستقل بودن از پلتفرمهای مختلف و تعداد کابران بالا از ویژگیهای مهم و اصلی زبان پایتون محسوب می شوند.
در ادامه، به توضیح هر یک از ویژگیهای زبان پایتون پرداخته شده است.
- حجم کدنویسی پایین: زبان پایتون شامل کتابخانههای از پیش تعریف شده متنوعی مخصوصاً در حوزه یادگیری ماشین و یادگیری عمیق است. بدین ترتیب، پیادهسازی مدلهای هوش مصنوعی با پایتون بهراحتی انجام میشود و برنامهنویسان صرفاً با نوشتن چند خط کد، از پیچیدهترین مدلها بهسادگی استفاده میکنند.
- کتابخانههای متنوع: زبان برنامه نویسی پایتون شامل تعداد بسیار زیادی کتابخانه برای پیادهسازی مدلهای یادگیری ماشین و یادگیری عمیق است. بدین ترتیب، چنانچه به عنوان برنامه نویس قصد دارید به طراحی و ساخت مدل هوش مصنوعی با پایتون بپردازید، کافی است کتابخانه مورد نظر را نصب و در برنامه خود فراخوانی کنید.
- یادگیری آسان: «قواعد نحوی | سینتکس» (Syntax) زبان پایتون بسیار ساده است. به دلیل وجود چنین ویژگیای، افراد برای توسعه پیچیدهترین پروژههای هوش مصنوعی با پایتون با مشکل مواجه نخواهند شد و در کمترین زمان ممکن میتوانند دستورات و نحوه کار با مدلها را در این زبان یاد بگیرند.

مستقل بودن از پلتفرمهای مختلف: افراد برنامه نویسی که به پیادهسازی پروژههای مختلف و مدلهای هوش مصنوعی با پایتون میپردازند، میتوانند برنامههای خود را بر روی پلتفرمهای مختلف نظیر ویندوز، لینوکس، یونیکس و سایر پلتفرمها اجرا کنند. از کتابخانه PyInstaller در پایتون میتوان برای انتقال قطعه کدها از یک پلتفرم به پلتفرم دیگر بهسادگی استفاده کرد.
- تعداد کاربران بالا: کاربران بسیاری در سراسر جهان از زبان برنامه نویسی پایتون در پروژههای مختلف استفاده میکنند. گروهها، انجمنها و Forumهای مختلفی وجود دارند که افراد سوالات خود را در زمینه برنامه نویسی با پایتون به اشتراک میگذارند. افرادی که در این حیطه تازهکار هستند، میتوانند پرسشهای خود را پیرامون پیادهسازی مدلهای هوش مصنوعی با پایتون از افراد فعال در این زمینه مطرح کنند و از اشخاص متخصص در این حوزه راهنماییهای لازم را در راستای رفع خطاهای برنامه و توسعه پروژه بگیرند.

رایج ترین کتابخانه های هوش مصنوعی در پایتون کدامند ؟
زبان برنامه نویسی پایتون شامل کتابخانههای بسیار زیادی در حوزههای مختلف برنامه نویسی است. افرادی که قصد دارند به پیادهسازی مدلهای هوش مصنوعی با پایتون بپردازند، میتوانند از کتابخانههای این زبان برای شاخههای هوش مصنوعی همگانی، یادگیری ماشین، یادگیری عمیق و شبکههای عصبی، پردازش تصویر، پردازش زبان طبیعی (Natural Language Processing | NLP) و علم داده استفاده کنند. برخی از مهمترین و پرکابردترین کتابخانههای مورد استفاده در پیادهسازی مدلهای هوش مصنوعی پایتون عبارتاند از:

- Numpy
- Pandas
- Tensorflow
- Theano
- Keras
- Sklearn
- PyTorch
- NLTK
- Mathplotlib
- Scrapy
در ادامه، کاربردهای هر یک از این کتابخانهها شرح داده میشوند.
کتابخانه Numpy در پایتون
کتابخانه Numpy یکی محبوبترین از کتابخانههای اپن سورس برای تحلیلهای عددی است.
با استفاده از این کتابخانه میتوان دادههای ذخیره شده در انواع ساختارهای داده پایتون را در قالب ماتریس و آرایههای چند بُعدی ذخیره و عملیات محاسباتی مختلفی را در کمترین زمان بر روی آنها اعمال کرد.

کتابخانه Pandas در زبان پایتون
یکی دیگر از پرکاربردترین کتابخانههای پایتون برای علم داده و «پردازش زبان طبیعی»، کتابخانه Pandas است. از ابزارهای این کتابخانه میتوان برای آمادهسازی داده برای مدلهای هوش مصنوعی با پایتون و تحلیل دادهها استفاده کرد. این کتابخانه دارای ساختارهای داده قدرتمندی برای اعمال پردازشهای مختلف و سریع بر روی دادهها است.
استفاده از کتابخانه Tensorflow برای پیاده سازی هوش مصنوعی با پایتون
کتابخانه «تنسورفلو» (Tensorflow) به عنوان یکی از بهترین کتابخانهها برای توسعه پروژههای هوش مصنوعی با پایتون محسوب میشود. این کتابخانه توسط تیم گوگل توسعه پیدا کرده است و شامل ابزارهای مختلفی برای پیادهسازی مدلهای مختلف در حوزههای علم داده، یادگیری عمیق، یادگیری ماشین و پردازش زبان طبیعی است. افراد تازهکار و برنامهنویسان حرفهای بهراحتی میتوانند از این کتابخانه برای پیادهسازی شبکههای عصبی مختلف استفاده کنند.
فریمورک و معماری کتابخانه تنسورفلو را میتوان بر روی پلتفرمهای محاسباتی مختلف نظیر CPU و GPU اجرا کرد؛ با این حال، بهترین پلتفرم برای استفاده از این کتابخانه، پلتفرم TPU است.
کتابخانه Theano در زبان برنامه نویسی پایتون
از کتابخانه Theano برای پیادهسازی مدلهای هوش مصنوعی با پایتون، مخصوصاً مدلهای یادگیری ماشین، استفاده میشود. با استفاده از این کتابخانه میتوان عملیات مختلفی نظیر محاسبات ماتریسی، محاسبات مختلف ریاضی و بهینهسازی را انجام داد. از ابزارهای این کتابخانه میتوان به همراه دستورات کتابخانه Numpy استفاده کرد. دستورات مرتبط با این کتابخانه را میتوان بر روی GPU با سرعت بسیار بالا اجرا گرفت.

کتابخانه Keras در پایتون
کتابخانه «کراس» (Keras) به عنوان کتابخانه منبع باز محسوب میشود که از آن میتوان برای توسعه پروژههای مبتنی بر هوش مصنوعی با پایتون استفاده کرد. کار با این کتابخانه ساده است و به افراد برنامه نویس تازهکار پیشنهاد میشود برای شروع کار خود از این کتابخانه استفاده کنند.

از این کتابخانه میتوان برای پیادهسازی پروژههای مختلف در حوزههای علم داده، پردازش زبان طبیعی و یادگیری ماشین و یادگیری عمیق استفاده کرد. این کتابخانه ابزارهای مورد نیاز برای ساخت مدل، تحلیل دادهها، مصورسازی گراف و بارگذاری مستقیم دادهها را شامل میشود.
استفاده از کتابخانه Scikit-Learn برای پیاده سازی هوش مصنوعی با پایتون
کتابخانه Scikit-Learn یکی دیگر از کتابخانههای پرکاربرد برای هوش مصنوعی با پایتون است که از آن برای پیادهسازی مدلهای هوش مصنوعی با پایتون استفاده میشود. برنامه نویسانی که قصد دارند پروژههایی را با زبان پایتون در زمینههای پردازش زبان طبیعی، پردازش تصویر و برنامههای مبتنی بر یادگیری ماشین توسعه دهند، با این کتابخانه سر و کار خواهند داشت.
کتابخانه Scikit-Learn شامل مدلهای یادگیری ماشین نظارت شده و بدون نظارت است و با استفاده از ابزارهای پیش پردازش این کتابخانه، دادههای مورد نیاز مدلها را آماده کرد.
کتابخانه PyTorch در زبان پایتون
یکی دیگر از کتابخانههای محبوب پایتون، کتابخانه «پایتورچ» (PyTorch) است که برنامه نویسان از آن برای طراحی مدلهای هوش مصنوعی با پایتون استفاده میکنند. پایتورچ کتابخانهای منبع باز است که در سال ۲۰۱۶ توسط تیم پژوهشگران هوش مصنوعی شرکت فیسبوک ارائه شد. از این کتابخانه برای طراحی مدلهای مختلف در حوزه پردازش زبان طبیعی، علم داده و «بینایی ماشین» (Computer Vision) استفاده میشود.

سرعت اجرای برنامههای نوشته شده توسط کتابخانه پایتورچ زیاد است و به همین خاطر این کتابخانه میتواند بهترین ابزار برای ساخت گرافهای پیچیده باشد. برنامههایی را که با این کتابخانه نوشته شدهاند را میتوان بهراحتی بر روی CPU یا GPU اجرا کرد.
کتابخانه Scrapy
برنامهنویسانی که در حوزه علم داده فعالیت دارند، با کتابخانه Scrapy آشنا هستند. این کتابخانه پایتون، یکی از کتابخانههای منبع باز است که از آن برای استخراج دادهها از صفحات وب استفاده میشود. بدین ترتیب، افرادی که قصد دارند «خزشگری» (Crawler) برای وب طراحی کنند که دادههای ساختاریافتهای از صفحات وب گردآوری و از آنها در توسعه برنامههای خود استفاده کنند، میتوانند از این کتابخانه بهره ببرند.

کتابخانه NLTK در پایتون
کتابخانه NLTK به عنوان یکی از بهترین کتابخانههای پایتون برای توسعه پروژههای پردازش زبان طبیعی تلقی میشود.
این کتابخانه دارای ابزارهای مختلفی برای «برچسبزنی» (Tagging) متن، «تجزیه کردن» (Parsing) جمله، تحلیل معنایی متن و مواردی از این قبیل است. از این کتابخانه برای آمادهسازی دادهها برای مدلهای یادگیری عمیق و یادگیری ماشین استفاده میشود.
کتابخانه Matplotlib در زبان برنامه نویسی پایتون
کتابخانه Matplotlib در پایتون، بهترین انتخاب برای پردازش تصاویر محسوب میشود. با استفاده از این کتابخانه میتوان تصاویر را در پروژه بارگذاری کرد و آنها را نمایش داد. همچنین، میتوان با استفاده از کتابخانه Matplotlib دادهها را در فضای دو بعدی مصورسازی کرد.

بهعلاوه، با استفاده از ابزارهای این کتابخانه میتوان گزارشهایی را از دادهها در قالب نمودارهای «پراکندگی» (Scatter Plots)، «هیستوگرام» (Histograms) و «نمودار میلهای» (Bar Graphs) ارائه داد.

مراحل پیاده سازی مدل های هوش مصنوعی
به منظور پیادهسازی مدلهای هوش مصنوعی، برنامه نویس باید چندین مرحله را انجام دهد. این گامها برای پیادهسازی مدلهای یادگیری ماشین و مدلهای یادگیری عمیق تقریباً یکسان هستند و ممکن است با توجه به ویژگیهای برخی از مدلها، مراحل مربوط به آمادهسازی و پیش پردازش مدلها کم یا زیاد شوند.

در ادامه، مراحل کلی توسعه پروژههای هوش مصنوعی با پایتون فهرست شدهاند.
- مرحله اول: تعریف مسئله
- مرحله دوم: جمعآوری داده از منابع مختلف
- مرحله سوم: آمادهسازی دادهها
- مرحله چهارم: تحلیل دادهها
- مرحله پنجم: انتخاب و ساخت مدل
- مرحله ششم: ارزیابی مدل و بهینهسازی آن
- مرحله هفتم: استفاده از مدل برای دادههای جدید
در ادامه مطلب، به توضیح هر یک از مراحل ذکر شده در بالا پرداخته میشود.
گام اول پیاده سازی مدل هوش مصنوعی: تعریف مسئله
به منظور حل یک مسئله، در ابتدا باید به درک کاملی از آن رسید و بهطور دقیق مشخص کرد که به دنبال رفع چه نیازی هستیم. چنانچه مثالی را که درباره پیشبینی وقوع بارندگی با توجه به یک سری ویژگیهای آب و هوایی در نظر بگیریم، میتوان هدف مسئله را پیشبینی میزان احتمال بارندگی بر اساس ویژگیهای موجود تعریف کرد.
همچنین، در این گام باید دادههایی را مشخص کرد که برای حل مسئله به آنها نیاز داریم. بهعلاوه، در این مقطع باید رویکرد حل مسئله را نیز مشخص کنیم. به عبارتی، برنامه نویس باید تصمیم بگیرد با توجه به مسئله و دادههای آن، کدام یک از رویکردهای یادگیری نظارت شده و بدون نظارت برای حل مسئله مناسب هستند.

گام دوم: جمع آوری داده
مدلهای هوش مصنوعی نظارت شده و بدون نظارت برای یادگیری مسائل مختلف، نیاز به داده دارند. به منظور تهیه دادههای مورد نیاز مسئله، باید به یک سری سوالات پاسخ دهیم تا مناسبترین داده را انتخاب کنیم.
این سوالات میتوانند به شرح زیر باشند:
- چه نوع دادههایی برای حل مسئله مورد نیاز است؟
- آیا دادهها را میتوان از منبع خاصی تهیه کرد؟
- چطور میتوان دادهها را گردآوری کرد؟
پس از مشخص شدن منبع دادهها، میتوان آنها را بهصورت دستی یا بهطور خودکار جمعآوری کرد. البته، افرادی که در مسیر یادگیری هوش مصنوعی تازهکار هستند، میتوانند از دادههای آمادهای استفاده کنند که بهطور رایگان در بستر اینترنت وجود دارند.

این منابع داده برای مسائل مختلف تهیه شدهاند و بهراحتی میتوان آنها را بر روی سیستم دانلود و در پروژه هوش مصنوعی خود استفاده کرد. همچنین، کتابخانههای زبان پایتون نیز دارای یک سری مجموعه داده آماده هستند و از آنها میتوان برای آموزش و ساخت مدل بهره برد.
در خصوص مثالی که درباره پیشبینی وقوع بارندگی مطرح شد، میتوان دادههای مورد نیاز مسئله را مواردی نظیر میزان سطح رطوبت هوا، دمای هوا، میزار فشار هوا، شرایط هوا به لحاظ ابری یا آفتابی بودن، منطقه جغرافیایی و ویژگیهایی از این قبیل در نظر گرفت.
گام سوم پیاده سازی مدل هوش مصنوعی: آماده سازی داده
یکی از مراحل مهم در پیادهسازی مدلهای هوش مصنوعی با پایتون، گام آمادهسازی داده است. معمولاً، دادههای جمعآوری شده نیاز به یک سری عملیات پیش پردازش دارند، زیرا ناسازگاریهای بسیاری نظیر «مقادیر مفقود | مقادیر از دست رفته» (Missing Values)، «متغیرهای حشو» (Redundant Variables) و «مقادیر تکراری» (Duplicate Values) در آنها ملاحظه میشود. این دادههای ناسازگار ممکن است در یادگیری مدل، اشکال ایجاد کنند و باعث شوند مدل، به اشتباه مسئله را حل کند.

گام چهارم: تحلیل داده
تحلیل دادهها یکی دیگر از گامهای مهم برای آمادهسازی دادههای مدل هوش مصنوعی است. در این گام باید توزیع و الگوهای دادهها را بررسی و روابط بین متغیرها و ویژگیها را مشخص کرد.
در مثالی که درباره پیشبینی وقوع بارندگی ارائه شد، میتوان گفت ویژگی دمای هوا، ارتباط زیادی با وقوع بارندگی دارد. هر چه دمای هوا کاهش پیدا کند، احتمال وقوع بارندگی بیشتر میشود.
گام پنجم: ساخت مدل
برای انتخاب مدل و طراحی آن، باید در ابتدا مشخص کنیم که مسئله مطرح شده، جزء مسائل دستهبندی محسوب میشوند یا برای حل آن باید از دیگر روشهای رگرسیون و خوشهبندی استفاده کرد. همچنین، برای حل مسئله باید میزان حجم داده و پیچیدگی مسئله را نیز در نظر داشت.
پس از بررسی ویژگیهای مدلها، مزایا و معایب آنها و انتخاب مناسبترین مدل برای مسئله موجود، باید دادههای موجود را به دو بخش دادههای آموزشی و دادههای تست تقسیم کرد و آموزش مدل را با استفاده از دادههای آموزشی انجام داد.

گام ششم: ارزیابی و بهینه سازی مدل
پس از آموزش مدل، باید عملکرد آن را بر روی دادههای تست سنجید تا کارایی و دقت آن مشخص شود. پس از محاسبه دقت مدل، با اعمال تغییراتی در مدل نظیر مقداردهی جدید به «هایپرپارامترها» (Hyper-parameters) میتوان میزان دقت مدل را مجددا سنجید تا به بالاترین دقت مدل دست پیدا کنیم.
گام هفتم: پیش بینی با مدل هوش مصنوعی ساخته شده
در مرحله نهایی، مدل را برای دادههای جدید به منظور پیشبینی مقدار هدف استفاده میکنیم. این دادهها، دادههای جدید و واقعی مسئله هستند که مدل آموزشی قرار است بهطور خودکار به حل آن بپردازد.
پیاده سازی مدل های هوش مصنوعی با پایتون
در این بخش به دو مثال پرداخته خواهد شد و با تحلیل مراحل پیادهسازی مدلهای هوش مصنوعی، با استفاده از زبان پایتون به پیادهسازی آنها میپردازیم. با توجه به دادههای آموزشی ارائه شده در هر دو مثال، از هر دو رویکرد یادگیری نظارت شده و یادگیری نظارت نشده استفاده شده است. در مثال اول، به نحوه آموزش چند مدل یادگیری ماشین برای دستهبندی دادهها و در مثال دوم به نحوه استفاده از یک روش نظارت نشده به منظور خوشهبندی دادهها پرداخته خواهد شد.
یادگیری ماشین با پایتون (روش نظارت شده)
در این بخش، سعی داریم مسئله پیشبینی وقوع بارندگی را که در بخش پیشین به عنوان مثال مطرح کردیم، با استفاده از پایتون پیادهسازی کنیم. به منظور ساخت و استفاده از مدل، باید هفت گام ذکر شده در بخش قبل را طی کنیم که در ادامه، به توضیح هر یک از این مراحل برای مسئله وقوع بارندگی پرداخته میشود.
تعریف مسئله
مسئله فعلی، درباره ساخت و آموزش مدل یادگیری ماشین در پایتون است که بتواند بر اساس ویژگیهای مختلف تعریف شده، پیشبینی کند آیا بارندگی اتفاق میافتد؟
جمع آوری داده
در مسئله پیشبینی وقوع بارندگی، برای آموزش مدل، از دادههای آمادهای استفاده شده است که در یک فایل CSV با نام weatherAUS.csv ذخیره شدهاند. این فایل حدوداً شامل 145 هزار سطر داده و 23 ویژگی است که این ویژگیها شرایط آب و هوایی روزانه یکی از شهرهای استرالیا را نشان میدهند.

مقداری هم در این فایل برای هر سطر مشخص شده است که وقوع یا عدم وقوع بارندگی را مشخص میکند. بدین ترتیب، این مسئله، با روشهای دستهبندی قابل پیادهسازی است و تعداد کلاسهای تعریف شده در این مسئله، دو تا است. با استفاده از قطعه کد زیر، میتوان اطلاعات دادههای مسئله را ملاحظه کرد. در ابتدا، کتابخانههای مورد نیاز را فراخوانی میکنیم:
سپس، فایل CSV دادهها را با استفاده از کتابخانه Pandas در برنامه بارگذاری میکنیم:
خروجی قطعه کد بالا در ادامه ملاحظه میشود. ستون آخر نشاندهنده وقوع و عدم وقوع بارندگی است.
Size of weather data frame is : (145460, 24)
Date Location MinTemp ... RainToday RISK_MM RainTomorrow
0 2008-12-01 Albury 13.4 ... No 0.0 No
1 2008-12-02 Albury 7.4 ... No 0.0 No
2 2008-12-03 Albury 12.9 ... No 0.0 No
3 2008-12-04 Albury 9.2 ... No 1.0 No
4 2008-12-05 Albury 17.5 ... No 0.2 No
در ادامه مطلب، به نحوه آمادهسازی دادهها برای آموزش مدل یادگیری ماشین در پایتون پرداخته میشود.

آماده سازی داده
به منظور آمادهسازی دادهها برای پیادهسازی مدل هوش مصنوعی با پایتون، در ابتدا با استفاده از قطعه کد زیر میزان تهی بودن مقادیر هر یک از این ستونهای ویژگی را بررسی میکنیم.
خروجی قطعه کد بالا در ادامه ملاحظه میشود. بر اساس اطلاعات زیر، بیش از 40 درصد از مقادیر چهار ستون اول، تهی هستند. برای آموزش مدل بهتر است از این ستونها استفاده نشود.
[5 rows x 24 columns]
Sunshine 75625
Evaporation 82670
Cloud3pm 86102
Cloud9am 89572
Pressure9am 130395
Pressure3pm 130432
WindDir9am 134894
WindGustDir 135134
WindGustSpeed 135197
Humidity3pm 140953
WindDir3pm 141232
Temp3pm 141851
RISK_MM 142193
RainTomorrow 142193
RainToday 142199
Rainfall 142199
WindSpeed3pm 142398
Humidity9am 142806
Temp9am 143693
WindSpeed9am 143693
MinTemp 143975
MaxTemp 144199
Location 145460
Date 145460
dtype: int64همچنین، در مرحله پیش پردازش دادهها باید ویژگیهایی را حذف کنیم که در حل مسئله نقش مهمی ندارند. استفاده از ویژگیهای زیاد باعث میشود پیچیدگی مسئله بیشتر و یادگیری مدل با دشواری انجام شود.
بدین ترتیب، ویژگیهای Location و Date را نیز از دادههای موجود حذف میکنیم. بهعلاوه، ویژگی RISK_MM را نیز کنار میگذاریم. این ویژگی، میزان بارندگی در روز بعد را نشان میدهد.
سطرها و ستونهای باقی مانده بهصورت زیر هستند:
(145460, 17)با استفاده از قطعه کد زیر، سطرهایی را حذف میکنیم که شامل ستونهایی با مقادیر تهی هستند:
بدین ترتیب، تعداد سطر و ستون دادههای باقی مانده بهصورت زیر است:
(112925, 17)یکی دیگر از مراحل پیش پردازش، حذف «دادههای پرت | ناهنجار» (Outliers) است. با استفاده از قطعه کد زیر میتوان این نوع دادهها را از دادههای باقی مانده حذف کرد.
خروجی قطعه کد بالا را در ادامه ملاحظه میکنید:
[[0.11756741 0.10822071 0.20666127 ... 1.14245477 0.08843526 0.04787026]
[0.84180219 0.20684494 0.27640495 ... 1.04184813 0.04122846 0.31776848]
[0.03761995 0.29277194 0.27640495 ... 0.91249673 0.55672435 0.15688743]
...
[1.44940294 0.23548728 0.27640495 ... 0.58223051 1.03257127 0.34701958]
[1.16159206 0.46462594 0.27640495 ... 0.25166583 0.78080166 0.58102838]
[0.77784422 0.4789471 0.27640495 ... 0.2085487 0.37167606 0.56640283]]
(107868, 17)مقادیر ستون آخر دادهها که وقوع بارندگی را مشخص میکنند، از نوع غیرعددی هستند. این مقادیر را نیز با استفاده از قطعه کد زیر، به مقادیر عددی تبدیل میکنیم:
در نهایت، میتوان مقادیر ستونها را نرمالسازی کنیم و بازه مقادیر دادهها را به رنج صفر تا یک تغییر دهیم. به منظور نرمالسازی دادهها میتوان از تابع MinMaxScaler از کتابخانه Sklearn استفاده کرد.
خروجی دستور بالا در ادامه ملاحظه میشود:
MinTemp MaxTemp Rainfall ... WindDir9am_W WindDir9am_WNW WindDir9am_WSW
4 0.628342 0.696296 0.035714 ... 0.0 0.0 0.0
5 0.550802 0.632099 0.007143 ... 1.0 0.0 0.0
6 0.542781 0.516049 0.000000 ... 0.0 0.0 0.0
7 0.366310 0.558025 0.000000 ... 0.0 0.0 0.0
8 0.419786 0.686420 0.000000 ... 0.0 0.0 0.0
9 0.510695 0.641975 0.050000 ... 0.0 0.0 0.0
[6 rows x 62 columns]در ادامه مطلب، به نحوه تحلیل دادهها با استفاده از کتابخانه Sklearn در پایتون پرداخته میشود.

تحلیل داده در یادگیری ماشین با پایتون
پس از آمادهسازی دادهها، میتوان به تحلیل و بررسی دادهها پرداخت و مشخص کرد کدام یک از ویژگیها، تاثیر بیشتری برای پیشبینی مقدار خروجی در مدل دارند. بدین منظور، میتوان از تابع SelectBest در کتابخانه Sklearn به شکل زیر استفاده کرد.
با استفاده از دستور بالا، میتوان سه ویژگی دادهها را مشخص کرد که ارتباط بیشتری با مقدار هدف دارند. این سه ویژگی شامل ستونهای Rainfall ،Humidity3pm و RainToday هستند. خروجی قطعه کد بالا در ادامه ملاحظه میشود.
Index(['Rainfall', 'Humidity3pm', 'RainToday'], dtype='object')به منظور کاهش میزان بار محاسباتی آموزش مدل، میتوان تنها از این سه ویژگی یا فقط از یک ویژگی استفاده کرد. در قطعه کد زیر، ویژگی Humidity3pm به عنوان تنها ویژگی برای آموزش مدل انتخاب شده است:
ساخت مدل یادگیری ماشین با پایتون
برای پیادهسازی مدلهای یادگیری ماشین در پایتون میتوان از کتابخانه Sklearn استفاده کرد. با استفاده از این کتابخانه میتوان ارزیابی عملکرد مدل را نیز سنجید. برای حل مسئله پیشبینی وقوع بارندگی، از سه مدل یادگیری ماشین استفاده کردیم. در قطعه کد زیر، نحوه استفاده از مدل «لاجستیک رگرسیون» (Logistic Regression) ملاحظه میشود.
خاطر نشان میشود دادههای آماده شده را به دادههای آموزشی و دادههای تست تقسیم میکنیم تا در زمان آموزش، فقط از دادههای آموزشی و به منظور سنجش عملکرد مدل، از دادههای تست استفاده شود.
خروجی قطعه کد بالا در ادامه ملاحظه میشود که میزان دقت این مدل را برای مثال مطرح شده نشان میدهد.
Accuracy using Logistic Regression: 0.8330181332740015
Time taken using Logistic Regression: 0.1741015911102295
مدل بعدی انتخابی برای حل مثال پیشبینی وقوع بارندگی، مدل «درخت تصمیم» (Decision Tree) است که نحوه استفاده از این مدل با پایتون در ادامه نشان داده شده است:
میزان دقت این مدل بر روی دادههای آموزشی در ادامه ملاحظه میشود:
Accuracy using Decision Tree Classifier: 0.831423591797382
Time taken using Decision Tree Classifier: 0.0849456787109375
مدل نهایی انتخاب شده برای مسئله پیشبینی وقوع بارندگی، مدل «ماشین بردار پشتیبان» (Support Vector Machine | SVM) است که قطعه کد آن را در ادامه ملاحظه میکنید.
مقدار دقت مدل بر روی دادههای تست، در ادامه ملاحظه میشود.
Accuracy using Support Vector Machine: 0.8886676308080246
Time taken using Support Vector Machine: 88.42247271537781
در بخش بعدی مطلب حاضر، به پیادهسازی یکی از مدلهای یادگیری ماشین با رویکرد نظارت نشده به همران نمونه کد پایتون پرداخته میشود.
یادگیری ماشین با پایتون (روش نظارت نشده)
در این بخش، سعی داریم مسئلهای را با مدل K-means پیادهسازی کنیم. این مدل، به عنوان یکی از روشهای نظارت نشده محسوب میشود و برای تهیه دادههای آموزشی آن نیازی به مقدار هدف (Target) نداریم. به منظور پیادهسازی گام به گام این مدل، میتوان از دادههای آماده کتابخانه Sklearn استفاده کرد.
یکی از این مجموعه دادهها، دادههای Iris است که مشخصات مجموعهای از گلها را شامل میشود. در مطلب حاضر، از این دادهها به منظور آموزش مدل K-means استفاده میکنیم تا دادهها را بر اساس ویژگیهای مشترکشان، در خوشههای جداگانه قرار دهد.
تعریف مسئله
مسئله فعلی، درباره ساخت مدل یادگیری ماشین «k میانگین» (K-means) با استفاده از زبان برنامه نویسی پایتون است که بتواند بر اساس ویژگیهای مختلف تعریف شده برای دادهها، آنها را بر اساس میزان شباهت، خوشهبندی کند.
جمع آوری داده
همانطور که گفته شد، برای آموزش مدل K-means از دادههای آماده کتابخانه Skearn استفاده میشود. فایلی که دادههای مرتبط با انواع گلها را دربر دارد، فایل Iris.csv است که با قطعه کد زیر میتوان آن را در برنامه بارگذاری کرد.
خروجی قطعه کد بالا ده سطر از دادههای موجود در دیتاست Iris است که در ادامه ملاحظه میشوند.

آماده سازی داده
ستون Species در دیتاست Iris، اسامی انواع گلها را نشان میدهد و هدف این است که مدل K-means بتواند دادهها را بر اساس سایر ستونهای این دیتاست که ویژگیهای گلها را مشخص میکنند، در چندین خوشه مجزا تفکیک کند.
از میان ستونهای موجود در این دیتاست، چهار ستون اول را میتوان به عنوان ویژگیهای دادهها در نظر گرفت و دادههای آموزشی مدل را بر اساس آنها آماده کرد.
در بخش بعدی مطلب فعلی، به نحوه تحلیل داده و آموزش مدل K-means پرداخته خواهد شد.
تحلیل داده
مدل K-means دارای پارامتی به نام K است که تعداد خوشهها را باید با استفاده از آن مشخص کرد. تعیین مقدار این پارامتر چالشبرانگیز است و باید از روشهای مختلفی برای تشخیص مناسبترین مقدار این پارامتر استفاده کرد. در این مثال، از روش Elbow به منظور یافتن بهینهترین مقدار پارامتر K استفاده شده است.
خروجی قطعه کد بالا را در ادامه ملاحظه میکنید. بر اساس منحنی حاصل شده از روش Elbow، مناسبترین مقدار برای پارامتر K برابر با عدد 3 است.

ساخت مدل
پس از یافتن مناسبترین مقدار برای پارامتر K در الگوریتم K-means، با استفاده از قطعه کد زیر، دادههای آموزشی را به مدل میدهیم.
میتوان خوشههای پیشبینی شده توسط مدل را در یک ستون مجزا به نام Cluster در دیتافریم Iris اضافه کرد.
در تصویر زیر، حاصل خوشهبندی مدل را ملاحظه میکنید.

در نهایت نیز میتوان خوشهبندی حاصل شده توسط مدل K-means را با استفاده از قطعه کد زیر مصورسازی کرد.
خروجی قطعه کد بالا را در ادامه ملاحظه میکنید.

در ادامه مطلب، به محدودیتهای مدلهای یادگیری ماشین برای حل مسائل پرداخته شده و سپس نحوه پیادهسازی یک مدل یادگیری عمیق با رویکرد با نظارت به همراه نمونه کد پایتون شرح داده میشود.
محدودیت های مدل های یادگیری ماشین
در بخش قبل، به نحوه پیادهسازی دو مسئله هوش مصنوعی با پایتون پرداخته شد. در مثال پیشبینی وقوع بارندگی از سه مدل یادگیری ماشین استفاده کردیم که مدل SVM با دقت 88 درصد، بالاترین میزان دقت را داشته است.

با این حال، مدلهای یادگیری ماشین دارای محدودیتهایی هستند که در ادامه به مهمترین آنها اشاره شده است:
- از مدلهای یادگیری ماشین نمیتوان برای یادگیری دادههایی استفاده کرد دارای ابعاد زیادی هستند.
- به دلیل آن که مدلهای یادگیری ماشین برای یادگیری مسائلی با ابعاد بالا مناسب نیستند، نمیتوان از این مدلها برای موضوعاتی نظیر تشخیص تصاویر، تشخیص اشیاء و مسائلی از این قبیل استفاده کرد.
- مدلهای یادگیری ماشین نیاز به گامی برای «استخراج ویژگی» (Feature Extraction) دارند. به عبارتی، برای آموزش این مدلها نیاز است که برای مدل مشخص شود کدام یک از ویژگیهای دادهها از اهمیت بالایی برخوردار هستند و از کدام ویژگی باید برای یادگیری مسئله استفاده کند. استخراج ویژگی مرحلهای است که توسط برنامه نویس باید بهصورت دستی انجام گیرد و مدل یادگیری ماشین قادر به تشخیص ویژگیها بهطور خودکار نیست.
به دلیل محدودیتهای موجود در روشهای یادگیری ماشین، نمیتوان از آنها در حل مسائل خاصی استفاده کرد. برای مقابله با چنین محدودیتهایی، روشهای یادگیری عمیق مناسبترین انتخاب برای حل مسائل هستند. به عبارتی، مدلهای یادگیری عمیق میتوانند به یادگیری دادههایی با ابعاد بالا بپردازند و نیازی به گام استخراج ویژگی ندارند.
این مدلها بهطور خودکار ویژگیهای دادههای ورودی را بهطور خودکار در حین آموزش یاد میگیرند. در ادامه مطلب حاضر، به توضیح پیادهسازی مدلهای یادگیری عمیق با پایتون پرداخته میشود.
یادگیری عمیق با پایتون
به منظور حل مسائل هوش مصنوعی با پایتون میتوان از کتابخانهها و ابزارهای یادگیری عمیق در این زبان استفاده کرد. در این بخش به مثالی از نحوه تشخیص کلاهبرداری بر اساس تراکنشهای بانکی میپردازیم و مدل دستهبندی را با استفاده از کتابخانه Keras پیادهسازی میکنیم. در ادامه، به گامهای حل مسئله پرداخته میشود.
تعریف مسئله
مسئله فعلی، درباره ساخت یک مدل یادگیری عمیق با پایتون است که بتواند بر اساس ویژگیهای مختلف تراکنشهای مالی، به تشخیص کلاهبرداری بپردازد.
جمع آوری داده
برای آموزش مدل، از دادههای آمادهای استفاده کردیم که در یک فایل CSV ذخیره شدهاند. این فایل شامل حدوداً 284 هزار تا سطر از اطلاعات تراکنشهای مالی در طی دو روز است که 492 تراکنش، به عنوان تراکنش کلاهبرداری مشخص شدهاند.

قصد داریم با استفاده از روشهای دستهبندی، به طراحی مدل یادگیری عمیق بپردازیم که بتواند تراکنشهای کلاهبرداری را تشخیص بدهد. در ادامه، کتابخانههای مورد نیاز را برای بارگذاری و طراحی مدل فراخوانی میکنیم.
با استفاده از قطعه کد زیر، دادهها را از فایل CSV در برنامه بارگذاری میکنیم.
خروجی قطعه کد بالا در ادامه ملاحظه میشود. ستون آخر فایل، مقدار هدف را نشان میدهد. عدد صفر نشاندهنده تراکنش عادی و عدد یک نشاندهنده تراکنش کلاهبرداری است. سایر ستونها اطلاعات مربوط به هر تراکنش را نشان میدهد و مدل با استفاده از آنها به تصمیمگیری درباره تراکنش میپردازد.
Time V1 V2 V3 ... V27 V28 Amount Class
0 0.0 -1.359807 -0.072781 2.536347 ... 0.133558 -0.021053 149.62 0
1 0.0 1.191857 0.266151 0.166480 ... -0.008983 0.014724 2.69 0
2 1.0 -1.358354 -1.340163 1.773209 ... -0.055353 -0.059752 378.66 0
3 1.0 -0.966272 -0.185226 1.792993 ... 0.062723 0.061458 123.50 0
4 2.0 -1.158233 0.877737 1.548718 ... 0.219422 0.215153 69.99 0
در بخش بعدی این مطلب، به نحوه آمادهسازی دادهها برای آموزش مدل شبکه عصبی با پایتون پرداخته خواهد شد.
آماده سازی داده
در بخش پیشین گفته شد که برای آموزش مدل یادگیری عمیق برای مسئله تشخیص کلاهبرداری بر اساس تراکنشهای بانکی، از یک فایل CSV استفاده کردیم که تعداد دادههای این فایل حدوداً 284 هزار است و از بین این تعداد داده، 492 تا تراکنش، به عنوان تراکنش کلاهبرداری مشخص شدهاند.
به دلیل این که تعداد دادههای هر کلاس تفاوت زیادی با یکدیگر دارند، باید برای آموزش مدل، از روش متعادلسازی بین کلاسها استفاده کنیم. در این مثال، از روش «نمونهبرداری» (Sampling) استفاده شده است که در ادامه قطعه کد پایتون آن ملاحظه میشود.
سپس، به منظور ساده کردن بار محاسباتی یادگیری مدل، ویژگیهایی (ستونهایی) را که برای آموزش مدل نیاز نیستند، از داده حذف میکنیم. در مثال فعلی، میتوان ویژگی time را از دادهها حذف کرد زیرا این ویژگی نقشی در تشخیص تراکنشهای کلاهبرداری ندارد.
خروجی قطعه کد بالا در ادامه ملاحظه میشود.
0 2508
1 492
Name: Class, dtype: int64
سپس، با استفاده از قطعه کد زیر، دادهها را مخلوط میکنیم.
در نهایت، دادههای آموزشی را از دادههای تست جدا میکنیم.
خروجی قطعه کد بالا در ادامه ملاحظه میشود. تعداد دادههای آموزشی مدل برابر با 2400 است که هر یک از دادهها 29 بعد دارد.
(2400, 29)به منظور نرمالسازی دادهها و قرار دادن مقادیر هر یک از ویژگیها در بازه صفر تا یک نیز میتوان از تابع MinMaXScaler استفاده کرد.
ساخت مدل
برای ساخت مدل هوش مصنوعی با پایتون برای مثال تشخیص کلاهبرداری بر اساس تراکنشهای مالی، از شبکه عصبی استفاده کردیم. این شبکه دارای سه لایه «تمام متصل» (Fully Connected Layer) به همراه یک لایه Dropout است.

اولین و دومین لایه این شبکه دارای 200 نود با تابع فعالسازی ReLU است و لایه آخر تنها یک نود با تابع فعالسازی Sigmoid دارد.
خروجی قطعه کد بالا را در ادامه ملاحظه میکنید که خلاصهای از ساختار مدل به همراه اطلاعاتی از پارامترهای آن را نشان میدهد.
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 200) 6000
_________________________________________________________________
dropout_1 (Dropout) (None, 200) 0
_________________________________________________________________
dense_2 (Dense) (None, 200) 40200
_________________________________________________________________
dropout_2 (Dropout) (None, 200) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 201
=================================================================
Total params: 46,401
Trainable params: 46,401
Non-trainable params: 0قطعه کد زیر نیز نوع بهینهساز در این مدل و نحوه ارسال دادهها به مدل را نشان میدهد.
خروجی قطعه کد بالا را در ادامه ملاحظه میکنید.
Train on 479 samples, validate on 1921 samples
Epoch 1/200
- 1s - loss: 0.6916 - acc: 0.5908 - val_loss: 0.6825 - val_acc: 0.8360
Epoch 2/200
- 0s - loss: 0.6837 - acc: 0.7933 - val_loss: 0.6717 - val_acc: 0.8360
Epoch 3/200
- 0s - loss: 0.6746 - acc: 0.7996 - val_loss: 0.6576 - val_acc: 0.8360
Epoch 4/200
- 0s - loss: 0.6628 - acc: 0.7996 - val_loss: 0.6419 - val_acc: 0.8360
Epoch 5/200
- 0s - loss: 0.6459 - acc: 0.7996 - val_loss: 0.6248 - val_acc: 0.8360
در بخش بعدی، به نحوه ارزیابی مدل پیادهسازی شده و تحلیل نتایج پیشبینی شده با استفاده از کتابخانه Mathplotlib پرداخته میشود.
ارزیابی مدل
پس از آموزش مدل، به منظور ارزیابی عملکرد آن، از دادههای تست استفاده میکنیم.
میزان دقت مدل بر روی دادههای تست در ادامه ملاحظه میشود.
Accuracy= 0.98همچنین میتوان از Heatmap نیز به منظور تحلیل خروجی مدل با استفاده از قطعه کد زیر استفاده کرد.
خروجی قطعه کد بالا در ادامه ملاحظه میشود.

منابع یادگیری هوش مصنوعی با پایتون
زبان برنامه نویسی پایتون به دلیل داشتن ابزارها و کتابخانههای جامع و استفاده آسان از آنها، به عنوان یکی از بهترین زبانهای برنامه نویسی برای پیادهسازی مدلهای هوش مصنوعی محسوب میشود.

منابع مختلف و زیادی برای یادگیری هوش مصنوعی با پایتون در بستر اینترنت وجود دارند که همه افراد با سطوح مختلف میتوانند از آنها استفاده کنند. این منابع، میتوانند در قالب ویدئوهای آموزشی آنلاین باشند یا در قالب کتب مختلف، به توضیح مدلها و نحوه پیادهسازی آنها بپردازند. در ادامه، به معرفی مهمترین منابع آموزشی هوش مصنوعی با پایتون اشاره خواهد شد.
دوره های آنلاین برای آموزش هوش مصنوعی با پایتون
افرادی که قصد دارند به یادگیری هوش مصنوعی با پایتون بپردازند، در وهله اول باید دورههای آموزشی معتبری را پیدا کنند. بهتر است افراد متقاضی در دورههای معتبر شرکت کنند تا از وقت و هزینهای که در راستای یادگیری صرف میکنند، مطمئن باشند. دورههای آنلاین مختلفی چه به زبان انگلیسی و چه به زبان فارسی وجود دارند که در ادامه به برخی از معتبرترین آنها اشاره خواهد شد.

دوره های آنلاین انگلیسی برای آموزش هوش مصنوعی با پایتون
افراد تازهکاری که قصد دارند در مسیر یادگیری هوش مصنوعی با پایتون قدم بگذارند اما دانش تخصصی زیادی در این حیطه ندارند، میتوانند به سایت Udemy مراجعه کنند و در دوره «The Complete Machine Learning Course with Python» [+] شرکت کنند. افراد شرکتکننده در این دوره مفاهیم پایهای مدلهای یادگیری ماشین و یادگیری عمیق را یاد میگیرند و با کاربرد هر یک از رویکردهای این دو حوزه برای حل مسائل مختلف آشنا میشوند.

دورههای تخصصی سایت Coursera نظیر «Machine Learning with Python» [+] نیز مناسب افرادی است که دانش پایهای از زبان برنامه نویسی پایتون دارند و با ابزارهای تحلیل داده در این زبان آشنا هستند. با شرکت در این دوره، میتوان با نحوه پیادهسازی مدلهای یادگیری ماشین با زبان پایتون آشنا شد.

اشخاصی که با زبان برنامه نویسی پایتون آشنا هستند، میتوانند در دورههای تخصصی «Deep Learning Specialization» [+] در سایت Coursera شرکت کنند. این مجموعه دوره شامل مباحثی پیرامون آموزش ساخت شبکههای عصبی برای مسائل مختلف نظیر ترجمه ماشین، چتبات، تشخیص گفتار و مواردی از این قبیل است.

همچنین، دوره «Machine Learning» [+] در سایت Stanford مناسب افرادی است که مهارت تخصصی در کار با زبان برنامه نویسی پایتون دارند و قصدشان یادگیری پیادهسازی مدلهای یادگیری ماشین با استفاده از این زبان است.

دوره های آنلاین فارسی برای آموزش هوش مصنوعی با پایتون
در سایت فرادرس به عنوان بزرگترین پلتفرم آموزشی فارسیزبان، میتوان به جامعترین دورههای تخصصی و آموزشی هوش مصنوعی دسترسی داشت. این دورههای آموزشی شامل مباحث پایهای تا پیشرفته هوش مصنوعی با پایتون هستند.
افراد علاقهمند به این حوزه میتوانند با شرکت در این دورهها، به یادگیری پیادهسازی انواع مختلف الگوریتمهای یادگیری ماشین و مدلهای یادگیری عمیق بپردازند. سطوح آموزشی این دورهها مختلف است و مخاطبان میتوانند با هر سطح دانشی که دارند، در این دورههای آنلاین شرکت کنند. برخی از مهمترین دورههای سایت فرادرس در ادامه فهرست شدهاند:
- (+) آموزش یادگیری ماشین
- (+) آموزش یادگیری ماشین Machine Learning با پایتون Python
- (+) آموزش یادگیری ماشین و پیاده سازی در پایتون Python – بخش یکم
- (+) آموزش یادگیری ماشین و پیاده سازی در پایتون Python – بخش دوم
- (+) آموزش کتابخانه scikit-learn در پایتون – الگوریتم های یادگیری ماشین
- (+) آموزش پیاده سازی گام به گام شبکه های عصبی در پایتون
- (+) آموزش یادگیری عمیق با پایتون – تنسورفلو و کراس TensorFlow و Keras
بهترین کتاب های آموزش هوش مصنوعی با پایتون کدام است؟
منابع مطالعاتی مختلفی برای یادگیری پیادهسازی مدلهای هوش مصنوعی با پایتون وجود دارند که میتوان این منابع را برای تازهکاران و افراد متخصص در حوزه برنامه نویسی تقسیمبندی کرد. کتاب «Introduction to Machine Learning with Python» به نوشته «سارا گیدو» (Sarah Guido)، یکی از مناسبترین منبع مطالعاتی برای افراد تازهکار در حوزه هوش مصنوعی محسوب میشود. افرادی که قصد دارند با مطالعه این کتاب به یادگیری طراحی و ساخت مدلهای هوش مصنوعی با پایتون بپردازند، باید دانش اولیهای از کار با زبان پایتون را داشته باشند.
این کتاب شامل مفاهیم اصلی و پایهای یادگیری ماشین است و نحوه حل مسائل مختلف را با الگوریتمهای یادگیری ماشین و کتابخانه Scikit-Learn پایتون توضیح میدهد.

افرادی که با زبان پایتون آشنا هستند، میتوانند با استفاده از کتاب Deep Learning Using Python به نوشته «دنیل انیس» (Daneyal Anis) با کتابخانههای Numpy و Scikit-Learn آشنا شوند و مدلهای مختلفی را برای مسائل یادگیری ماشین و یادگیری عمیق پیادهسازی کنند. این کتاب شامل مثالهای مختلفی از یادگیری ماشین و یادگیری عمیق است که پیادهسازی آنها را مرحله به مرحله آموزش میدهد.

افراد متخصصی که دانش و مهارت در حوزه یادگیری ماشین دارند و میخواهند مهارت خود را در این حوزه بهبود ببخشند، میتوانند به سراغ منابع تخصصیتر بروند. یکی از کتابهای آموزش یادگیری ماشین با پایتون برای سطوح پیشرفته، کتاب Advanced Machine Learning with Python نوشته «جان هرتی» (John Hearty) است. این کتاب شامل مباحث اخیر حوزه یادگیری ماشین است که خوانندگان این کتاب میتوانند با مطالعه آن، به پیادهسازی روشهای جدید در این حیطه بپردازند.

کتاب The Elements of Statistical Learning نوشته «ترور هستی» (Trevor Hastie)، «رابرت تیبشیرانی» (Robert Tibshirani) و «جرم فریدمن» (Jerome Friedman) نیز مناسب افرادی است که علاقهمند به «دادهکاوی» (Data Mining) هستند و قصد دارند به جای مفاهیم ریاضیاتی آن، مفاهیم و کاربرد روشهای آن را یاد بگیرند.

یکی دیگر از کتابهایی که در حوزه یادگیری عمیق، مباحث تخصصی را شامل میشود، کتاب Deep Learning (Adaptive Computation and Machine Learning series) نوشته «ایان گودفیلو» (Ian Goodfellow) است که تصویر این کتاب را در ادامه ملاحظه میکنید.

برخی از فصلهای این کتاب به مباحث ریاضی و آمار و احتمال مورد نیاز در حوزه یادگیری عمیق اختصاص داده شده است. همچنین، مطالعهکنندگان این کتاب میتوانند علاوهبر انواع شبکههای عصبی، با روشهای مختلف بهینهسازی و «تنظیمات» (Regularization) مدلها آشنا شوند.
جمعبندی
هوش مصنوعی یکی از شاخههای علوم کامپیوتر است که امروزه کاربرد آن را در اکثر جنبههای زندگی بشر مشاهده میکنیم. فرصتهای شغلی بسیاری در این حوزه وجود دارند و افرادی که قصد دارند در این زمینه مشغول به کار شوند، باید مهارتهای تخصصی خود را تقویت کنند.
یکی از این مهارتها، یادگیری زبان برنامه نویسی مناسب در حوزه هوش مصنوعی است. امروزه، زبان برنامه نویسی پایتون به عنوان یکی از پرکاربردترین زبانهای حوزه هوش مصنوعی شناخته میشود. این زبان با داشتن ویژگیهای منحصربفرد و مختلف، انتخاب بسیاری از برنامه نویسان و توسعه دهندگان پروژههای هوش مصنوعی است.
در مطلب حاضر، به ویژگیهای خاص زبان برنامه نویسی پایتون اشاره شد تا افراد تازهکار با قابلیتهای این زبان آشنا شوند. همچنین، کتابخانههای معروف و رایج حوزه هوش مصنوعی در این مطلب معرفی گردید و کاربرد هر یک از آنها مورد بررسی قرار گرفت.
بهعلاوه، به منابع یادگیری مختلف هوش مصنوعی با پایتون اشاره شد تا خوانندگان مطلب بتوانند برای یادگیری عمیقتر این حوزه به آنها رجوع کنند. در نهایت، برای آشنایی افراد تازهکار به نحوه پیادهسازی مدلهای هوش مصنوعی با پایتون، به ارائه دو مثال از یادگیری ماشین و یادگیری عمیق پرداخته و مراحل مختلف توسعه یک برنامه مبتنی بر هوش مصنوعی بهصورت گام به گام به همراه نمونه کدهای پایتون شرح داده شد.








واقعا آفزین دارید. چندمین باره که از مطالب علمیتون استفاده میکنم و بهترین آموزش هست فک کنم حداقل دوهفته برای نوشتن این آموزش زمانبرده شده. دم مدیریتتون گرم که به فکر فروش فیلم اموزشی نیستید و دارید فرادرس رو به دانشگاه علمی تبدیل میکنید. به شخصه سال ۹۴ که دانشجوی ارشد بودم فکر نمیکردم روزی فرادرس به این مرحله برسه .
با سلام؛
ارائه بازخورد شما برای ما بسیار خوشحالکننده است و خوشحالیم که مطالعه مطلب برای شما مفید بوده است.
با تشکر از همراهی شما با مجله فرادرس
من به عنوان غیر متخصص و علاقمند وقتی این کدها رو میبینم که برای یه دستور ساده اینقدر پیچیده نوشته شده حقیقتا ناامید میشم چون کد ها رو واقعا نمیشه حفظ کرد. پس چاره چیست؟ باید کپی کرد لابد
ممنون از زحمات شما
ولی ای کاش فایل های csv مربوطه رو هم میذاشتید
واقعا دمتون گرم
من از خیلی از مطالبتون تا به حال استفاده کردم
بسیار کاربردی هستند
آرزوی بهترین ها رو براتون دارم.