



روش های نمونه گیری در پایتون – راهنمای کاربردی
بسیاری از محققان و دانشمندان فعال در حوزه «هوش مصنوعی» (Artificial Intelligence) و «علم داده» (Data Science)، به طور روزمره با الگوریتمهای زیادی سر و کار دارند. علم داده، علم مطالعه الگوریتمها است. با این حال، مطالعه و پیادهسازی الگوریتمهای هوش مصنوعی و تحلیل داده، بدون داشتن دانش کافی در مورد «نمونه گیری» (Sampling) امکانپذیر نیست. در این مطلب سعی شده است تا به بررسی شایعترین و پر استفادهترین الگوریتمهای نمونهگیری پرداخته شود. شایان توجه است که الگوریتمهایی که در این مطلب پوشش داده میشوند، جزء شناخته شدهترین الگوریتمهای نمونه گیری هستند که برای کار کردن با دادهها مورد استفاده قرار میگیرند.





روش نمونه گیری تصادفی ساده (Simple Random Sampling)
فرض کنید که میخواهید یک زیر مجموعه از جمعیت دادهها انتخاب کنید؛ به طوری که، احتمال انتخاب هر کدام از دادهها یکسان باشد (احتمال قرار گرفتن هر کدام از دادهها در زیر مجموعه جدید، برابر باشد). از طریق کد زیر، 100 نمونه به طور تصادفی از مجموعه داده انتخاب میشوند.
نمونه گیری طبقهای (Stratified Sampling)
فرض کنید که نیاز است تا تعداد میانگین رأیهای هر کدام از کاندیداهای انتخابات در یک کشور تخمین زده شود. کشوری که در آن انتخابات برگزار شده است، سه شهر عمده دارد. آمار افراد شاغل، کارگران کارخانه و بازنشستگان در این شهرها به قرار زیر است:
- شهر A، یک میلیون کارگر کارخانه دارد.
- شهر B، دو میلیون کارگر دارد.
- شهر C، سه میلیون بازنشسته دارد.
یک راه تخمین تعداد رأیهای کاندیداهای انتخاباتی، انتخاب تصادفی 60 نمونه از تمام جمعیت کشور است. با این کار، این امکان وجود دارد که توازن جمعیتی سه شهر، در نمونههای تصادفی انتخاب شده رعایت نشود (به عنوان نمونه، اکثریت جمعیت تصادفی انتخاب شده از یک شهر خاص باشند). در چنین حالتی، «اریبی» (Bias) ایجاد شده در جمعیت تصادفی تولید شده، سبب خطای قابل توجه در تخمین میانگین رأیهای هر کدام از کاندیداها خواهد شد.
در عوض، اگر به ترتیب تعداد 10، 20 و 30 نمونه تصادفی از شهرهای (B) ،(A) و (C) انتخاب شوند، خطای ایجاد شده در هنگام تخمین میانگین رأیها، نسبت به حالت قبل کمتر خواهد شد. در زبان برنامهنویسی پایتون، چنین کاری به راحتی و از طریق کد زیر قابل انجام است.


نمونه گیری Reservoir
به تعریف مسألهای که در ادامه آمده است، دقت کنید. فرض کنید جریانی با طول ناشناخته (معمولا نزدیک به بینهایت فرض میشود) از آیتمها (Items) دارید. چنین جریانی را تنها میتوان یکبار از ابتدا به انتها پیمایش کرد و در هر زمان، تنها یک آیتم از این جریان قابل مشاهد است. هدف تولید الگوریتمی است که به طور تصادفی، یک آیتم از این جریان انتخاب و ذخیره کند؛ به گونهای که، احتمال انتخاب هر کدام از آیتمها برابر باشد. سؤالی که در اینجا پیش میآید این است که چگونه میتوان چنین کاری را انجام داد؟
فرض کنید که قرار است پنج آیتم از یک جریان بینهایت (Infinite Stream)، نمونهگیری و ذخیره شود؛ به طوری که، احتمال انتخاب هر یک از عناصر عضو این جریان برابر باشد. با استفاده از کد زیر در زبان برنامهنویسی پایتون، میتوان مسأله نمونهگیری شرح داده شده را حل کرد.
یک خروجی محتمل برای کد بالا، میتواند به شکل زیر باشد.
[1369, 4108, 9986, 828, 5589]
از طریق مفاهیم ریاضی میتوان ثابت کرد که در جمعیت نمونهگیری شده، هر کدام از عناصر با احتمال برابر از جریان انتخاب شدهاند. فرض کنید که جریانی از آیتمها داریم و تنها یک آیتم در هر واحد زمان قابل مشاهده است. هدف این است که 10 آیتم انتخاب و ذخیره شوند و احتمال انتخاب هر کدام از آیتمها برابر باشد. اگر تعداد آیتمها () شناخته شده باشد، کار بسیار راحت است و کافی است 10 آیتم متمایز با اندیس () انتخاب و سپس آنها را ذخیره کنیم. مشکل اینجا است که تعداد آیتمهای جریان از پیش مشخص نیست. یک راه حل ممکن برای چنین مشکلی، میتواند به شکل زیر تعریف شود:
- 10 آیتم اول ذخیره میشوند.
- برای ()، وقتی که آیتم مشاهده میشود:
- با احتمال ، آیتم جدید ذخیره میشود (یکی از آیتمهای قدیمی نادیده گرفته میشود؛ انتخاب اینکه کدام آیتم قدیمی باید با آیتم جدید جایگزین شود، تصادفی است).
- با احتمال ، آیتمهای جدید نادیده گرفته و همان آیتمهای قدیمی ذخیره میشوند.
بنابراین،
- وقتی که تعداد آیتمها برابر 10 باشد، احتمال انتخاب هر کدام از آیتمها برابر 1 است.
- وقتی تعدادآیتمها برابر 11 باشد، هر آیتم جدید با احتمال ذخیره میشود؛ برای آیتمهای قدیمی، این مقدار به شکل محاسبه میشود.
- وقتی تعدادآیتمها برابر 11 باشد، آیتم دوازدهم با احتمال و تمامی 11 آیتم قبلی، با احتمال ذخیره میشوند.
- از طریق اصل استقراء، به راحتی میتوان ثابت کرد که وقتی تعداد آیتمها برابر باشد، احتمال انتخاب و ذخیره هر آیتم برابر خواهد بود.
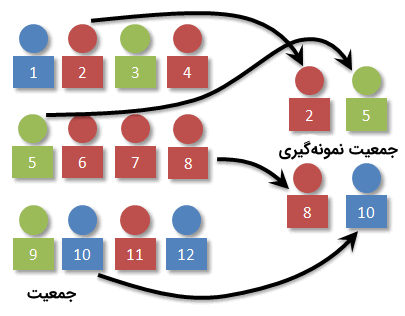

کم نمونه گیری و بیش نمونه گیری تصادفی
در بسیاری از کاربردهای هوش مصنوعی و علم داده، محققان و دانشمندان با «دادههای نامتوازن» (Imbalanced Data) سر و کار دارند. یکی از تکنیکهای قابل قبول و پر کاربرد برای دست و پنجه نرم کردن با دادههای نامتوازن، روشهای «بازنمونهگیری» (Resampling) هستند.

در چنین روشهایی، یا نمونهها از «کلاس غالب» (Majority Class) حذف میشوند (کم نمونهگیری) و یا نمونههای بیشتری به «کلاس اقلیت» (Minority Class) اضافه میشوند. ابتدا با استفاده از دستورات زیر در زبان برنامهنویسی پایتون یک دیتاست نامتوازن ساخته میشود.
در مرحله بعد، با استفاده از کد زیر، عملیات «کم نمونهگیری» (Undersampling) و «بیش نمونهگیری» (OverSampling)، روی دادههای نامتوازن انجام میشود.
خروجی:
OUTPUT: 90 10 20 180
کم نمونهگیری و بیش نمونهگیری با بسته نرمافزاری imbalanced-learn
بسته نرمافزاری imbalanced-learn در زبان برنامهنویسی پایتون، برای غلبه بر معضل مجموعه دادههای نامتوازن توسعه داده شده است. این بسته نرمافزاری، روشهای مختلفی برای کمنمونهگیری و بیشنمونهگیری در اختیار کاربران قرار میدهد.
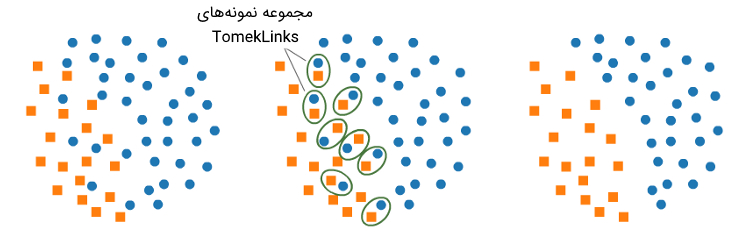
کم نمونهگیری با استفاده از ابزار TomekLinks
یکی از روشهای موجود برای کمنمونهگیری در بسته نرمافزاری imbalanced-learn، ابزار TomekLinks است. اصطلاح TomekLinks، به مجموعهای از جفت نمونهها در جمعیت دادهها اطلاق میشود که در دو کلاس کاملا مخالف یکدیگر قرار دارند ولی در «فضای ویژگی» (Feature Space) در همسایگی همدیگر قرار گرفتهاند. با استفاده از این ابزار، عناصر کلاس غالب از مجموعه Tomek Links حذف میشوند. چنین کاری به نوبه خود، «مرز تصمیم» (Decision Boundary) بهتری برای «دستهبندها» (Classifiers) تولید میکند. به عبارت دیگر، ابزار TomekLinks، همپوشانی ناخواسته میان کلاسها را حذف میکند. این تا زمانی ادامه دارد که همه دادههای همسایه متعلق به کلاس یکسان باشند. با استفاده از کد زیر، عمیات کمنمونهگیری بر روی دادههای نامتوازن قابل اجرا است.

بیش نمونهگیری با استفاده از ابزار SMOTE
ابزار SMOTE، پیادهسازی الگوریتم شناخته شده «تکنیک بیشنمونهگیری اقلیت مصنوعی» (Synthetic Minority Oversampling Technique) است که در بسته نرمافزاری imbalanced-learn قرار دارد. این الگوریتم برای کلاس اقلیت، نمونههای جدیدی در همسایگی نمونههای موجود در این کلاس تولید میکند. با استفاده از کد زیر، عملیات بیشنمونهگیری بر روی دادههای نامتوازن قابل اجرا است.

علاوه بر روشهای ذکر شده، روشهای کمنمونهگیری و بیشنمونهگیری دیگری نیز در بسته نرمافزاری imbalanced-learn پیادهسازی شدهاند. روشهایی نظیر Cluster Centroids و NearMiss از جمله روشهای کمنمونهگیری پیادهسازی شده در این بسته هستند. همچنین، روشهای ADASYN و bSMOTE، از روشهای بیشنمونهگیری پیادهسازی شده در این بسته محسوب میشوند.
جمعبندی
به جرأت میتوان گفت که الگوریتمها، یکی از حیاتیترین بخشهای علم داده محسوب میشوند. نمونهگیری یکی از موضوعات مهم در این حوزه به حساب میآید؛ ولی متأسفانه به اندازه کافی در مورد آن بحث و اظهار نظر نمیشود.

استفاده از یک روش نمونهگیری مناسب میتواند موفقیت الگوریتمهای یادگیری را، در تعمیم آموزش انجام شده به مرحله تست تضمین کند. از سوی دیگر، به کارگیری استراتژی نمونهگیری نامناسب در یک پروژه هوش مصنوعی و علم داده، سبب تولید جوابهای نادرست و شکست پروژه خواهد شد.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش اصول و روشهای دادهکاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- روشهای نمونهگیری (Sampling) در آمار — به زبان ساده
- نمونهگیری و بازنمونهگیری آماری (Sampling and Resampling) — به زبان ساده
- نمونهگیری گیبز (Gibbs Sampling) و کاربردهای آن — به زبان ساده
^^








