
داده کاوی (Data Mining) و پایتون برای تحلیل چاقی کودکان – راهنمای کاربردی
امروزه، جمله «بچهها هر روز چاقتر میشوند» به کرات از رسانهها و افراد گوناگون شنیده میشود. اما پرسشی که در این وهله امکان دارد مطرح شود آن است که آیا این موضوع حقیقت دارد؟ آیا کودکان روز به روز در حال چاقتر شدن هستند؟ در همین رابطه نموداری میان مردم دست به دست میچرخد که نشان میدهد طی پنج سال آینده، وزن کودکان انگلیسی به اندازه تراکتور افزایش خواهد یافت! این ادعا به نظر کمی غیر قابل باور میرسد و بنابراین به انگیزهای برای انجام این تحلیل مبدل شد. «داده کاوی» (Data Mining) راهکاری مناسب برای پاسخ به پرسشهای مطرح شده محسوب میشود. در این راهنما، چگونگی استفاده از دادهکاوی برای تحلیل چاقی کودکان با بهرهگیری از مجموعه داده مربوط به کشور انگلستان مورد بررسی قرار گرفته است.




داده
دادههای مورد استفاده در این تحلیل از اینجا (+) دریافت شدهاند و برای نگارش این مطلب، از فایل 2014 XLS استفاده شده است. پژوهشگر باید این فایل را دانلود کرده و در نرمافزار صفحه گسترده منتخب خودش (OpenOffice Calc ،LibreOffice، اکسل یا هر گزینه دیگری) باز کند. در فایل مذکور باید به شیت ۷.۲ رفت، زیرا دادههای مورد نظر برای این تحلیل در آنجا وجود دارد.

اکنون، پیش از آنکه به تحلیل دادهها با پایتون پرداخته شود، یک گام به عقبتر رفته و این مساله مورد بررسی قرار میگیرد که اگر امکان تحلیل دادهها با صفحه گسترده وجود دارد، چرا از پایتون استفاده میشود؟
پایتون یا صفحه گسترده؟
این پرسشی است که اغلب افرادی که به حوزه تحلیل داده ورود میکنند با آن مواجه هستند. در حالیکه پایتون ممکن است برای جامعه برنامهنویسان شناخته شده باشد، نرمافزارهای صفحه گسترده در سراسر دنیا بیشتر شناخته شده هستند. اغلب مدیران اداری، کارشناسان فروش، بازاریابها و دیگر افراد در جایگاههای شغلی و علمی گوناگون از اکسل استفاده میکنند. هیچ مشکلی نیز در این رابطه وجود ندارد. نرمافزارهای صفحه گسترده برای افرادی که به چگونگی استفاده از آنها واقف هستند ابزارهای خوبی محسوب میشوند. چنین ابزارهایی موجب شدهاند تا بسیاری از افراد غیر فنی نیز به تحلیلگرانی موفق در حوزه کاری خود مبدل شوند.

پاسخ دادن به پرسش «از پایتون استفاده کنم یا اکسل؟!» کار راحتی نیست. اما در نهایت، هیچ بایدی وجود ندارد، میتوان از هر یک از آنها و یا هر دو آنها با هم استفاده کرد. اکسل به عنوان یک نرمافزار صفحه گسترده، برای نمایش دادهها، اجرای تحلیلهای مقدماتی و رسم نمودارهای ساده بسیار خوب است، اما در زمینه «پاکسازی دادهها» (Data Cleaning) مناسب نیست (مگر اینکه فرد چگونگی استفاده از ویژوال بیسیک برای برنامهها یا Visual Basic for Applications را بداند). اگر یک فایل ۵۰۰ مگابایتی اکسل با «دادههای ناموجود» (missing data)، دادههای در «فرمتهای» (Formats) گوناگون و به صورت بدون هدر وجود داشته باشد، پاکسازی آنها به صورت دستی یک عمر طول خواهد کشید. در صورتی که دادهها در چندین فایل CSV وجود داشته باشند (که مساله معمول و متداولی به شمار میآید) نیز همین امر صادق است.
انجام همه این پاکسازیها با پایتون و کتابخانه «Pandas» (کتابخانهای برای تحلیل داده است) کاری بدیهی محسوب میشود. Pandas بر مبنای NumPy ساخته شده و وظایف سطح بالا را به سادگی انجام میدهد، بنابراین میتوان نتایج آن را روی یک فایل صفحه گسترده نوشت و با افراد غیر برنامهنویس نیز به سادگی به اشتراک گذاشت. بنابراین، پایتون ابزاری بسیار خوب برای انجام کلیه مراحل تحلیلهای داده سطح بالا شامل پیشپردازش دادهها است.
کد
اکنون کار با نوشتن کد لازم برای انجام تحلیلهای داده آغاز میشود (نسخه کامل این کد به همراه فایل دادههای مورد استفاده که در بالا نیز به آن اشاره شد در مخزن گیت (+) موجود است). کار با ساخت یک اسکریپت با نام obesity.py و ایمپورت کردن کتابخانههای pandas و matplotlib آغاز میشود. از کتابخانه matplotlib بعدا برای ترسیم نمودارها استفاده خواهد شد.
با استفاده از دستور pip install pandas matplotlib میتوان اطمینان حاصل کرد که همه وابستگیها نصب شدهاند. اکنون، دادههای فایل اکسل خوانده میشوند.
تنها با یک خط کد، کل فایل اکسل خوانده شد. اکنون آنچه وجود دارد با استفاده از دستور زیر پرینت میشود.
با استفاده از دستور زیر، اسکریپت اجرا میشود.
دادههای بالا آشنا به نظر میرسند؟ مقادیر نشان داده شده در بالا در واقع شیتهایی هستند که پیشتر مشاهده شدند. باید به خاطر داشت که تمرکز این نوشته بر شیت ۷.۲ است. اکنون، اگر به شیت ۷.۲ در اکسل نگاه شود، ۴ سطر بالا و ۱۴ سطر پایین شامل اطلاعات بدون استفادهای هستند. لازم است این جمله بدین شکل تصحیح شود که این اطلاعات برای انسان مفید هستند ولی برای اسکریپت تحلیلی که در اینجا نوشته شده کاربردی ندارد. در اینجا تنها از سطرهای ۱۸-۵ استفاده خواهد شد.
پاکسازی
هنگامی که شیت خوانده شد، نیاز به حصول اطمینان از این امر است که کلیه اطلاعات غیر مفیدی رها شدهاند.
اکنون باید اسکریپت را مجددا اجرا کرد.
شیت خوانده میشود و ۴ سطر بالا و ۱۴ سطر پایین آن نادیده گرفته میشوند (زیرا حاوی اطلاعاتی که برای این تحلیل مفید باشند نیستند). سپس، آنچه موجود است پرینت میشود (برای سادگی، تنها اولین خط کدها نشان داده میشوند). اولین خط نشان دهنده هدر ستونها است. میتوان به وضوح مشاهده کرد که کتابخانه Pandas کاملا هوشمند است زیرا اغلب هدرها را به درستی برداشته (به جز خط اول یعنی Unnamed : 0). اما چرا برای خط اول این اتفاق افتاده؟ پاسخ این سوال ساده است، باید ابتدا به فایل اکسل نگاه کرد. همانطور که در فایل میتوان دید، «سرآیند» (Header | هِدِر) برای سال وجود ندارد. مساله دیگر آن است که یک خط خالی در فایل اصلی وجود دارد و به صورت NaN (سرنامی برای Not a Number) نمایش داده میشود. اکنون تنها نیاز به انجام دو کار است که در ادامه بیان شدهاند.
- تغییر نام اولین هِدِر به Year
- راحت شدن از سطرهای خالی
در کد بالا با استفاده از تابع توکار ()rename به Pandas گفته شده که ستون Unnamed: 0 به Year تغییر کند. inplace = True شی موجود را تغییر میدهد. بدون این قسمت، Pandas یک شی جدید را ساخته و باز میگرداند. تنها به یک چیز دیگر نیاز است که کل این کارها آسانتر شود. اگر به جدول data_age نگاه شود، اولین مقدار یک عدد است. این یک اندیس به شمار میآید و Pandas از قابلیت پیشفرض اکسل که اندیسها را به صورت عدد دارد، استفاده میکند. اگرچه، در اینجا قصد تغییر دادن اندیس به Year است. این کار ترسیم نمودار را آسانتر میکند، زیرا اندیس معمولا به عنوان محور x رسم میشود.
با استفاده از کد بالا، اندیس به Year تغییر کرد. اکنون دادههای پاکسازی شده پرینت و سپس اسکریپت اجرا میشود.
همانطور که مشهود است، اندیس اکنون به Year تغییر یافته و همه NaNها حذف شدهاند.
نمودارها
نمودار دادههای موجود با دستور زیر ترسیم شدهاند.

در دادههای اصلی یک فیلد کلی وجود دارد که کلیه موارد دیگر را غرق میکند و باید آن را حذف کرد.
axis =1 کمی گیجکننده محسوب میشود، اما آنچه واقعا معنا میدهد انداختن ستونها است که در این پرسش Stack Overflow (+) به آن پرداخته شده. اکنون نمودار آنچه وجود دارد ترسیم میشود.
در این نمودار میتوان گروههای سنی مجزا را مشاهده کرد. و اما در نمودار موجود کدام گروه سنی بیشترین چاقی را دارد؟

به پرسش اصلی مطرح شده بازگشته و به آن پاسخ داده میشود که آیا واقعا کودکان در حال چاق شدن هستند؟ در این راستا، نمودار یک بخش کوچک از دادهها که مربوط به افراد زیر ۱۶ سال است و افراد بالغ در رده سنی ۳۵-۴۴ ترسیم میشود.
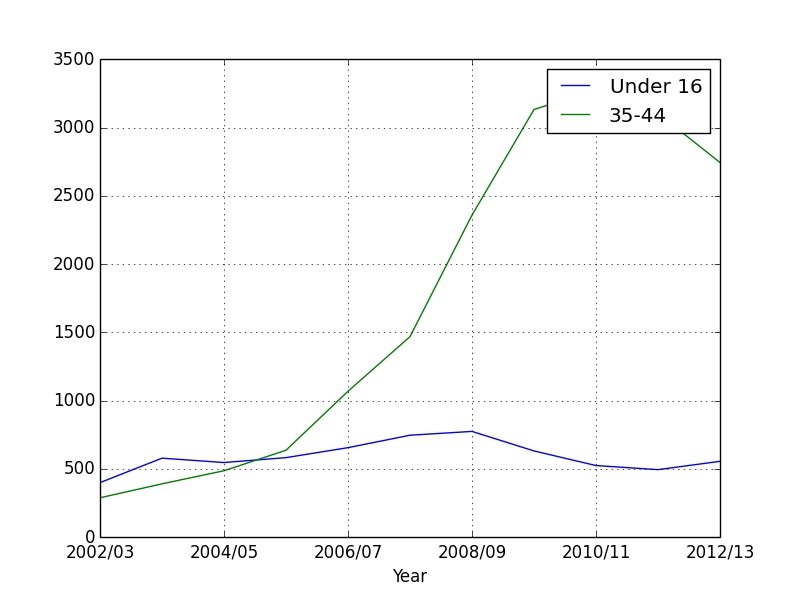

چه کسی چاقتر شده؟
همانطور که در نمودار قابل مشاهده است، چاقی کودکان رو به کاهش است و والدین آنها در حال تبدیل شدن به بالن هستند! بنابراین به نظر میرسد والدین به جای فرزندانشان باید نگران خودشان باشند.

پیشبینی آینده
نمودار همچنان نشان نمیدهد که چه اتفاقی برای چاقی کودکان در آینده میافتد. راههایی برای استخراج نمودارهایی مانند آنچه برای حال ترسیم شد، برای آینده نیز وجود دارد، اما باید پیش از انجام پردازش یک هشدار به مخاطبان داده شود، «چاقی هیچ مبنای ریاضیاتی ندارد». به همین دلیل نمیتوان فرمولی پیدا کرد که نشان دهد این مقادیر در آینده چگونه تغییر میکنند. همه چیز از اساس کار حدسی است. با در نظر داشتن این هشدار، چگونگی استخراج نمودار پیشبینی برای آینده شرح داده خواهد شد.
Scipy یک تابع برای استخراج فراهم میکند، اما این تابع فقط برای دادههای دارای رشد یکنوا کار میکند (در حالیکه دادههای موجود مربوط به چاقی بالا و پایین میروند). از این رو، میتوان از «برازش منحنی» (curve fitting) استفاده کرد.
- برازش منحنی در تلاش برای برازش کردن یک منحنی از طریق نقاط روی نمودار با تلاش برای تولید یک تابع ریاضیاتی برای دادهها است. تابع ممکن است بسیار صحیح باشد یا نباشد و این امر بستگی به خود دادهها دارد.
- کاربر میتواند از «درونیابی چند جملهای» (Polynomial Interpolation) هنگامی که یک معادله وجود دارد، برای آزمودن و درونیابی هر مقداری در نمودار استفاده کند.
از این دو تابع همراه با یکدیگر برای آزمودن و پیشبینی آینده کودکان انگلستان استفاده میشود.
در اینجا، مقادیر برای کودکان زیر ۱۶ سال استخراج میشود. برای محور x، گراف اصلی تاریخ دارد. برای ساده کردن گراف، تنها نیاز به استفاده از اعداد ۰ تا ۱۰ است.
خروجی:
array([ 400., 579., 547., 583., 656., 747., 775., 632., 525., 495., 556.]) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
یک مساله دیگر که باید به آن توجه داشت این است که برازش منحنی از درجات گوناگونی از چندجملهایها استفاده میکند. به عبارت بسیار ساده، هر چه درجه بالاتر باشد، برازش منحنی نیز دقیقتر است، اما این شانس نیز وجود دارد که نتایج به درد نخور باشند. گاهی در صورتی که درجه مورد استفاده خیلی بالا باشد، Scipy به کاربر هشدار میدهد. این مساله با نگاه به مثالهای زیر شفافتر میشود.
در کد بالا، درجه چندجملهای برابر با ۳ قرار داده شده است. سپس، از تابع ()polyfit در کتابخانه Numpy برای برازش نمودار از طریق دادههای موجود استفاده میشود. تابع ()poly1d سپس در معادلهای که به منظور ساخت تابع تولید شده و برای تولید مقادیر مورد استفاده قرار میگیرد فراخوانی میشود. این کار تابعی را باز میگرداند که poly_interp نامیده میشود و در کد زیر مورد استفاده قرار میگیرد.
در کد بالا از ۰ تا ۱۰ حلقه زده میشود، و فراخوانی تابع ()poly_interp برای هر مقدار صورت میپذیرد. این نکته را باید به خاطر سپرد که این تابعی است که هنگام اجرای الگوریتم برازش منحنی تولید شده است.
پیش از جلوتر رفتن، به بررسی این مساله پرداخته خواهد شد که درجات گوناگون چندجملهای به چه معنا هستند. در این راستا، نمودار دادههای اصلی و دادههای تولید شده در اینجا ترسیم میشوند تا مشخص شود معادله موجود چقدر با دادههای ایدهآل نزدیک است.
دادههای اصلی خط آبی رنگ و دارای برچسب «Orig» هستند، در حالیکه دادههای تولید شده به رنگ قرمز و با برچسب «Fitted» هستند. با درجه چند جملهای برابر سه نمودار زیر حاصل میشود.

همانطور که مشهود است، این درجه نتوانست برازش مناسبی را فراهم کند، بنابراین درجه ۵ مورد آزمون قرار میگیرد.

خروجی بهتر شده، اکنون مقدار ۷ امتحان میشود.

اکنون، یک جفت تقریبا مناسب ایجاد شد. سوالی که در این وهله مطرح میشود آن است که با این حساب چرا همیشه از مقادیر بالاتر (برای درجه چند جملهای) استفاده نمیشود؟
دلیلی که برای این امر باید برشمرد آن است که مقادیر بالاتر به طور تنگاتنگی با این نمودار جفت شدهاند (بیش برازش)، بنابراین استفاده از آنها برای پیشبینی بلا استفاده است. اگر برای استخراج پیشبینیها از نمودار بالا تلاشی صورت پذیرد، مقادیر به درد نخوری حاصل میشوند. نویسنده اصلی این مطلب، با آزمودن مقادیر گوناگون به این نتیجه دستیافته که درجه چند جملهای ۳ و ۴ تنها حالاتی هستند که منجر به ارائه پاسخ صحیح میشوند، بنابراین در اینجا نیز از آن مقادیر استفاده خواهد شد. اکنون تابع ()poly_interp مجددا برای مقادیر ۰ تا ۱۵ باز اجرا میشود، تا پنج سال آینده را پیشبینی کند.
این کد مشابه قبل است. اکنون، نتایج با درجه چند جملهای ۳ و ۴ مجددا بررسی میشوند. خط استخراج شده جدید به رنگ سبز است و پیشبینیهای انجام شده را نشان میدهد.

این نمودار حاکی از آن است که چاقی کاهش خواهد یافت. نمودار زیر مقادیر پیشبینی شده با درجه چندجمله ای ۴ را نشان میدهد.

نمودار بالا نشان میدهد که در آینده افزایش وزن شدیدی در میان کودکان رخ خواهد داد و کودکان هم وزن تراکتورها خواهند شد!
اکنون این پرسش مطرح میشود که کدام نمودار درست است؟ و پاسخ این سوال گاهی بستگی به ذینفعان پروژه تحلیل و خوشآیند آنها دارد نه حقیقت، هرچند گاهی نیز با بهرهگیری از سایر روشهای پیشبینی و ارزیابی مدل میتوان درجه صحت خاصی برای پیشبینیها تعیین کرد. البته نباید فراموش کرد این پیشبینیها پیرامون آینده است و تا زمانی که آینده به وقوع نپیوندد نمیتوان به طور صد در صد درباره درستی یا غلطی این نتایج اظهار نظر کرد.
اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- گنجینه آموزشهای برنامه نویسی پایتون (Python)
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای هوش محاسباتی
- آموزش برنامهنویسی R و نرمافزار R Studio
- مجموعه آموزشهای برنامه نویسی متلب (MATLAB)
^^








