



پیش بینی سهام با شبکه های عصبی مصنوعی در پایتون – راهنمای کاربردی
حوزههای «یادگیری ماشین» (Machine Learning) و «یادگیری عمیق» (Deep Learning)، جزء پرمخاطبترین و داغترین حوزههای تحقیقاتی در «هوش مصنوعی» (Artificial Intelligence) محسوب میشوند. شرکتهای بزرگ تجاری، سازمانهای چند ملیتی و غولهای صنعت «فناوری اطلاعات» (Information Technology | IT)، تاکنون سرمایهگذاری زیادی جهت «تحقیق و توسعه» (Research and Development) در زمینه پیادهسازی «سیستمهای یادگیری هوشمند» (Intelligent Learning Systems) انجام دادهاند. استفاده از شبکههای عصبی برای پیش بینی سهام مالی و قیمت آنها، یکی از کاربردهای روشهای یادگیری هوشمند محسوب میشود.



در حوزه اقتصاد و بخشهای تجاری-مالی (Financial-Commercial)، از روشهای یادگیری ماشین و یادگیری عمیق جهت تولید استراتژیهای مؤثر مالی استفاده میشود. از چنین استراتژیهایی در «صندوقهای پوشش ریسک» (Hedge Funds) استفاده میشود تا «حاشیه سود» (Profit Margin) سرمایهگذاریهای مالی انجام شده در «بخشهای» (Sectors) مختلف بیشینه شود.
بنابراین، ترکیب هوش مصنوعی و سیستمهای تولید استراتژیهای مالی، موضوع تحقیقاتی جالبی برای علاقهمندان به حوزههای هوش مصنوعی و مسائل تجاری-مالی خواهد بود. همچنین، ترکیب این دو حوزه، این امکان را برای مخاطبان و خوانندگان این مطلب فراهم میآورد تا با کاربردهای هوش مصنوعی در موجودیتهای مالی نظیر صندوقهای پوشش ریسک و «شرکتهای کارگزاری» (Brokerage Companies) آشنا شوند.
این مطلب، در اصل مقدمهای بر استفاده از مدلهای «شبکه عصبی مصنوعی» (ANN | Artificial Neural Network) نظیر «پرسپترون چند لایه» (Multi-Layer Perceptron | MLP) و «شبکههای عصبی بازگشتی» (Recurrent Neural Networks | RNN) با «حافظه کوتاه مدت بلند» (Long Short-Term Memory | LSTM) جهت پیش بینی سهام و نوسان در قیمت شرکتهای لیست شده در «بازار سهام» (Stock Market) است. به قیمت سهام یک شرکت عرضه شده در بازار سهام، «شاخص» (Index) نیز گفته میشود. در این مطلب، به طور خاص روی پیش بینی سهام و قیمت شرکتهای لیست شده در بازار سهام تمرکز میشود. بنابراین، هدف این مطلب پیش بینی سهام و قیمت مرتبط با یکی از شرکتهای مد نظر کاربران، در یک دوره خاص، با استفاده از شبکههای پرسپترون چند لایه و شبکههای عصبی بازگشتی است.

نیاز به شبکههای عصبی در اقتصاد و تجارت
حوزه اقتصاد و بخشهای تجاری-مالی، بسیار «غیرخطی» (Non-Linear) هستند و در بسیاری از مواقع، دادههای مرتبط با قیمت سهام کاملا «تصادفی» (Random) به نظر میرسند. روشهای «سریهای زمانی» (Time Series) سنتی نظیر «میانگین متحرک خودهمبسته یکپارچه» (ARIMA | AutoRegressive Integrated Moving Average) و «واریانس ناهمسانی شرطی اتورگرسیو» (Autoregressive Conditional Heteroskedasticity | GARCH)، تنها زمانی در پیش بینی سهام و قیمتهای آن مؤثر هستند که دادههای سری وارد شده به سیستم «مانا» (Stationary) باشند.
فرض مانا بودن دادههای سری زمانی، «فرض محدود کنندهای» (Restricting Assumption) برای سیستم خواهد بود. در چنین حالتی و با فرض مانا بودن دادههای سری زمانی، این دادهها باید از طریق تبدیلاتی نظیر Log Returns «پیشپردازش» (Pre-Process) شوند تا برای مدلسازی قیمت سهام و سود شرکتها مورد استفاده قرار بگیرند. در سیستمهای مالی مرسوم، به جای اینکه از مقادیر واقعی قیمت سهام یا مقادیر واقعی «سود سرمایهگذاری» (Returns) استفاده شود، از «لگاریتم» (Log) این مقادیر برای پیش بینی سهام و قیمت آنها استفاده میشود.
با این حال، مشکل اصلی در فرض مانا بودن دادههای سری زمانی، مواقعی نمایان میشود که از مدلهای پیادهسازی شده برای انجام پیشبینی در «سیستمهای معاملات تجاری لایو» (Live Trading Systems) استفاده میشود. در سیستمهای معاملات تجاری لایو، برخلاف «سیستمهای معاملات تجاری کاغذی» (Paper Trading Systems)، از پول واقعی برای انجام معاملات استفاده میشود؛ در نتیجه، حاشیه خطای بسیار کمی برای سیستم وجود خواهد داشت. نکته مهم در مورد سیستمهای معاملات تجاری لایو این است که هیچ تضمینی وجود ندارد که دادههای سری زمانی ورودی به سیستم، مانا باشند. بنابراین، احتمال عملکرد نادرست چنین سیستمهایی بسیار بالاست.

برای رفع چنین نقیصهای، میتوان از شبکههای عصبی مصنوعی استفاده کرد. ویژگی مهم استفاده از شبکههای عصبی مصنوعی در سیستمهای مالی، عدم فرض مانا بودن دادههای سری زمانی است. علاوه بر این، شبکههای عصبی مصنوعی، سیستمهای بسیار مؤثری جهت پیدا کردن «روابط» (Relationships) میان دادهها، مدلسازی آنها و استفاده از مدلهای تولید شده برای انجام «پیشبینی» (Prediction) در مورد دادههای جدید (یا «دستهبندی» (Classify) دادههای جدید) محسوب میشوند.
به طور کلی، یک پروژه تعریف شده در حوزه «علم داده» (Data Science) شامل مراحل زیر خواهد بود:
- «اکتساب یا جمعآوری دادهها» (Data Acquisition): در این مرحله، دادههای خام لازم برای یک پروژه علم داده (نظیر پیش بینی سهام و قیمت آن) جمعآوری میشود. این دادهها، «ویژگیهای» (Features) لازم را برای پیادهسازی یک مدل یادگیری هوشمند فراهم میآورند.
- پیشپردازش دادهها: بسیاری از «دانشمندان علم داده» (Data Scientists) و «مهندسان هوش مصنوعی» (Artificial Intelligence Engineers)، از این مرحله به دلیل وقتگیر بودن و نیاز به صرف انرژی زیاد، فراری هستند. با این حال، پیشپردازش دادههای ورودی به سیستم، یکی از حیاتیترین بخشهای پیادهسازی یک پروژه مرتبط با علم داده محسوب میشود.
- توسعه و پیادهسازی مدلها: در این مرحله، توسعهدهندگان، مدلهای لازم (در این مطلب، مدلهای استفاده شده از نوع شبکههای عصبی مصنوعی هستند) برای پیادهسازی سیستم و پارامترهای بهینه آنها را مشخص میکنند.
- «مدل بَکتست» (Backtest Model): فرایندی است که در آن، عملکرد استراتژیهای تولید شده برای معاملات تجاری یا «مدلهای تحلیلی» (Analytical Models) پیادهسازی شده (جهت پیش بینی سهام و قیمت آنها و همچنین سود شرکتها)، روی «دادههای تاریخی» (Historical Data) ارزیابی میشوند. هدف از چنین فرایندی، سنجش میزان «دقت» (Accuracy) مدل تحلیلی یا استراتژی مالی تولید شده، در پیشبینی نتایج واقعی است.
- «بهینهسازی» (Optimization) پارامترها: در این مرحله، بهینهترین و مناسبترین پارامترها جهت آموزش مدل یادگیری هوشمند (شبکههای عصبی مصنوعی) انتخاب میشوند. این مرحله، اختیاری است. از آنجایی که هدف این مطلب، آشنایی خوانندگان و مخاطبان با روشهای یادگیری هوشمند جهت پیش بینی سهام و قیمت آنها است، بهینهسازی پارامترها گنجانده نشده است. با این حال، این مبحث میتواند تأثیر مثبتی در بهبود عملکرد مدلهای شبکه عصبی داشته باشد.
اکتساب یا جمعآوری دادهها
خوشبختانه، دادههای مرتبط با قیمت سهام، که در این پروژه مورد نیاز است، توسط وبسایت (Yahoo Finance) برای استفاده عمومی در اختیار قرار گرفته است. دادههای مرتبط با قیمت سهام شرکتها، یا از طریق وبسایت (Yahoo Finance) و یا از طریق «واسط برنامهنویسی کاربردی» (Application Programming Interface) ارائه شده توسط این وبسایت، قابل دریافت یا جمعآوری است.
با استفاده از قطعه کد زیر در «زبان برنامهنویسی پایتون» (Python Programming Language)، دادههای مورد نیاز برای آموزش مدل یادگیری جمعآوری خواهد شد (نکته: برخی از پارامترهای کدهای ارائه شده، باید قبل از اجرا توسط کاربران مقداردهی شوند).
با استفاده از کد بالا، دادههای سری زمانی مرتبط با قیمت سهام یک شرکت خاص (در این مورد خاص، برای پیش بینی سهام شرکت اپل (APPLE)) جمعآوری میشوند.
پیشپردازش دادهها
در این مطلب و برای پیش بینی سهام شرکتها و قیمت آنها، نیاز است تا دادههای جمعآوری شده به «مجموعههای آموزشی» (Training Sets) متشکل از ده داده مرتبط با قیمت سهام یک شرکت و یک داده متناظر با قیمت روز بعد سهام آن شرکت تقسیمبندی شوند. در این پروژه، برای انجام موارد بالا، کلاسی به نام DataProcessing تعریف میشود. سپس، دادههای جمعآوری شده به دو دسته «دادههای آموزشی» (Training Data) و «دادههای تست» (Test Data) تقسیمبندی میشوند.

برای تولید دادههای آموزشی، تابعی به نام (get_train(self, seq_len تعریف شده است؛ ورودی این تابع، یک پارامتر اندازه پنجره (در اینجا، مقدار 10 به عنوان ورودی دریافت میشود و متناظر با ده داده مرتبط با قیمت سهام یک شرکت است) و خروجی آن، دادههای آموزشی (داده و خروجی مورد انتظار) در قالب آرایههای تعریف شده به وسیله کتابخانه نرمافزاری (numpy) است. برای تولید دادههای تست نیز، تابعی مشابه با تابع تولید کننده دادههای آموزشی تعریف میشود.
با استفاده از قطعه کد زیر، دادههای لازم برای تولید دادههای آموزشی و تست (جهت آموزش و تست شبکههای عصبی پیادهسازی شده) تولید میشوند:
توسعه و پیادهسازی مدلهای پیش بینی سهام
در این بخش، مدلهای پیادهسازی شده (شبکه عصبی پرسپترون چند لایه و شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند) برای پیش بینی سهام شرکتها و قیمت آنها روی دادههای سری زمانی، معرفی خواهند شد.

لازم به ذکر است که برای پیادهسازی این مدلها در زبان برنامهنویسی پایتون، «وابستگیهای برنامهنویسی» (Programming Dependencies) زیر باید در محیط برنامهنویسی پایتون «وارد» (Import) شوند.
- بسته نرمافزاری pandas-datareader
- بسته نرمافزاری fix-yahoo-finance
- بسته نرمافزاری numpy
- بسته نرمافزاری pandas
- بسته نرمافزاری tensorflow
- بسته نرمافزاری keras
شبکههای عصبی مصنوعی
در این پروژه، از دو مدل شبکه عصبی مصنوعی جهت پیش بینی سهام شرکتها و قیمت آنها استفاده است: شبکه عصبی پرسپترون چند لایه و شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند. در ادامه، تعریفی مختصری از نحوه عملکرد این دسته از مدلهای شبکه عصبی مصنوعی ارائه خواهد شد.
شبکه عصبی پرسپترون چند لایه
شبکه عصبی پرسپترون چند لایه، یکی از سادهترین مدلهای شبکه عصبی مصنوعی است. در این مدل، ابتدا ورودیها وارد مدل مدلمیشوند. در مرحله بعد، با در اختیار داشتن مجموعهای از وزنهای متناظر با نودهای شبکههای عصبی، ورودیها از لایه ورودی به سمت لایههای نهان و پس از آن به سمت لایه خروجی انتشار داده میشوند (انتشار رو به جلوی نمونههای ورودی).
یادگیری شبکه عصبی پرسپترون چند لایه از طریق یک فرایند یادگیری به نام «پس انتشار خطا» (Error Backpropagation) انجام میشود. در این فرایند، خطای پیشبینی انجام شده در لایه خروجی شبکه، به سمت لایههای نهان پس انتشار داده میشود (انتشار رو به عقب خطای شبکه) و از این طریق، وزنهای نودهای شبکههای عصبی تغییر میکنند.

مشکل مهم شبکه عصبی پرسپترون چند لایه، نبود حافظه است. به عبارت دیگر، شبکه هیچ اطلاعی در مورد نمونههای آموزشی که در تکرارهای گذشته وارد شبکه عصبی شدهاند ندارد و نمیتواند تأثیر آموزشهای گذشته را بر نمونههای آموزشی جدید بسنجد. در زمینه مدلهای یادگیری جهت پیش بینی سهام شرکتها و قیمت آنها، تفاوت میان دادههای مرتبط با ده روز خاص در یک مجموعه داده، با دادههای مرتبط با همان ده روز در مجموعه داده دیگر، ممکن از اهمیت ویژهای برخوردار باشد. با این حال، شبکه عصبی پرسپترون چند لایه قادر به تحلیل چنین روابطی در دادهها نخواهد بود.
در چنین حالتی و برای رفع چنین نقیصهای در شبکه عصبی پرسپترون چند لایه، از شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند استفاده میشود. شبکه عصبی بازگشتی، قابلیت ذخیره اطلاعات خاصی را در مورد دادههای ورودی دارد و میتواند از این اطلاعات در مراحل بعدی یادگیری استفاده کند. چنین ویژگی مهمی در شبکه عصبی بازگشتی، قابلیت شبکه در تحلیل ساختار پیچیدۀ روابط میان دادههای قیمت سهام را به شدت افزایش میدهد.
مهمترین مشکل شبکههای عصبی بازگشتی، «محو شدگی گرادیان» (Vanishing Gradient) است. دلیل وقوع چنین پدیدهای این است که با بالا رفتن تعداد لایهها در شبکه، «نرخ یادگیری» (Learning Rate) چندین بار ضرب خواهد شد (نرخ یادگیری، مقداری کوچکتر از 1 است) و این سبب میشود تا مقادیر گرادیانهای محاسبه شده مدام کاهش پیدا کنند. در نتیجه، در تکرارهای رو به انتها، وزنهای شبکه عصبی تغییر محسوسی نخواهد کرد. چنین مشکلی با اضافه شدن واحد حافظه کوتاه مدت بلند (LSTM) به شبکه عصبی بازگشتی مرتفع شده است. به همین دلیل، شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند، عملکرد بهتری نسبت به شبکههای عصبی بازگشتی مرسوم از خود نشان میدهد.
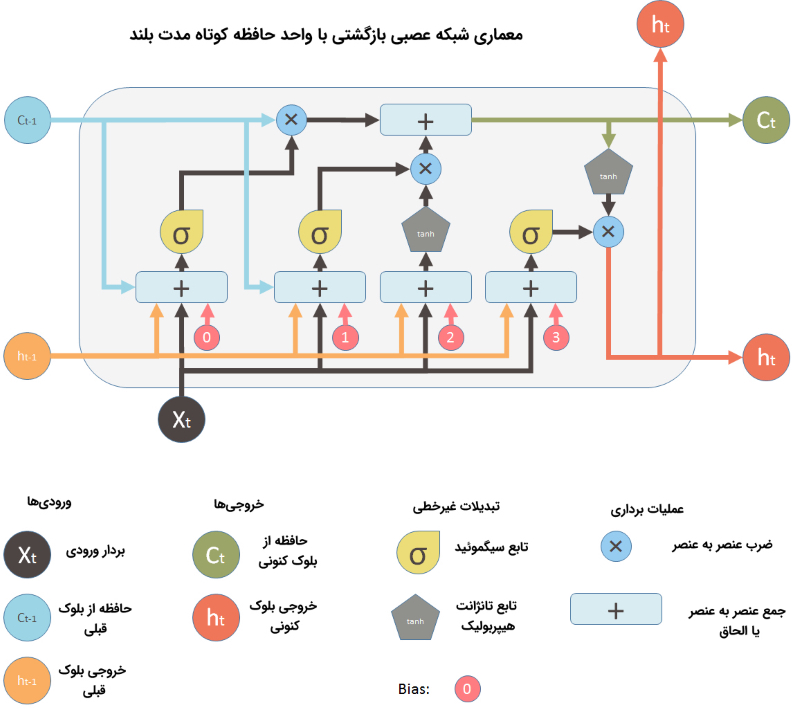
برای پیادهسازی مدلهای شبکه عصبی مصنوعی ذکر شده، از کتابخانه keras استفاده میشود. ویژگی مهم در کتابخانه keras، اضافه کردن مرحله به مرحلۀ لایهها، به جای تعریف یکباره مدل است. از این طریق، به راحتی میتوان تعداد لایهها و نوع آنها را تغییر داد؛ ویژگی مشخصهای که در هنگام «بهینهسازی» (Optimization) شبکه عصبی بسیار مفید خواهد بود.

یکی از مهمترین بخشهای پیادهسازی مدل، به ویژه در هنگام استفاده از دادهها برای آموزش آنها، «نرمالسازی» (Normalization) دادههای ورودی است. روش معمول نرمالسازی دادهها، روش «نمره استاندارد» (Standard Score) است. با این حال، از آنجایی که قرار است از سیستم پیادهسازی شده جهت پیشبینی در سیستمهای معاملات تجاری لایو (در یک بازه زمانی) استفاده شود، استفاده از روش آماری نمره استاندارد ممکن است روش دقیقی برای نرمالسازی دادهها نباشد.
در این پروژه، جهت نرمالسازی دادهها، تمامی نمونههای دادهای بر عدد 200 تقسیم میشوند (یک عدد دلخواه که سبب کوچک شدن تمامی مقادیر دادهای میشود). اگر چه ممکن است این روش کمی اختیاری به نظر برسد، با این حال، از بزرگ شدن مقادیر وزنهای نودهای شبکه عصبی به شکل مؤثری جلوگیری میکند.
از طریق تعریف یک «مدل ترتیبی» (Sequential Model) و اضافه کردن «لایههای متراکم» (Dense Layers) روی آن، میتوان به راحتی یک شبکه عصبی پرسپترون چند لایه ایجاد کرد.
از طریق کد بالا، یک شبکه عصبی پرسپترون چند لایه متشکل از دو لایه نهان ایجاد میشود. در هر کدام از لایههای نهان از 100 نود (یا نرون) استفاده میشود. همچنین، از بهینهساز Adam (یا Adam Optimizer) جهت به روز رسانی وزنها استفاده میشود. این الگوریتم، جایگزین الگوریتم استاندارد «گرادیان کاهشی تصادفی» (Stochastic Gradient Descent) خواهد شد. به دلیل عملکرد بهتر بهینهساز Adam نسبت به الگوریتم گرادیان کاهشی تصادفی، این روش محبوبیت دوچندانی در میان فعالان حوزه یادگیری ماشین پیدا کرده است.
برای روشنتر شدن دلیل برتری روش بهینهساز Adam، ابتدا ویژگیها و نقاط مثبت دو روش مبتنی بر گرادیان کاهشی تصادفی ذکر خواهد شد. سپس، دلیل برتری روش بهینهساز Adam بیان خواهد شد:
- «الگوریتم گرادیان انطباقی» (Adaptive Gradient Algorithm | AdaGrad): در این روش، از یک نرخ یادگیری به ازاء هر پارامتر (Per-Parameter Learning Rate) برای یادگیری استفاده میشود. این روش، عملکرد شبکه عصبی را در حل مسائلی که «گرادیانهای اسپارس» (Sparse Gradients) دارند، بهبود میبخشد (نظیر مسائل مرتبط با «پردازش زبان طبیعی» (Natural Language Processing) و «بینایی کامپیوتر» (Computer Vision)).
- روش «انتشار ریشه میانگین مربعات» (Root Mean Square Propagation | RMSProp): در این روش نیز همانند روش بالا، از یک نرخ یادگیری به ازاء هر پارامتر برای یادگیری استفاده میشود. این نرخها، بر اساس میانگین مقادیر اخیر گرادیانهای وزنها (در اصل، بر اساس میزان سرعت تغییر وزنها) تطبیق داده میشوند. این الگوریتم در مسائل «آنلاین» (Online | برخط) و «نامانا» (Non-Stationary) بسیار خوب عمل میکند.
روش بهینهساز Adam، ویژگیها و نقاط مثبت دو روش بالا را با هم ترکیب میکند و به همین خاطر است که عملکرد بهتری نسبت به روشهای گرادیان کاهشی تصادفی از خود نشان میدهد. در مرحله بعد، مدل شبکه عصبی روی دادههای آموزشی «برازش» (Fit) میشود.
پس از برازش مدل روی دادههای آموزشی، از دادههای تست برای ارزیابی عملکرد آن استفاده میشود. نتایج به دست آمده از ارزیابی مدل روی دادههای تست، برای سنجش عملکرد سیستم در تعمیم آموزش شبکه به مرحله تست و قابلیت مدل در پیش بینی سهام شرکتها و قیمت آنها مورد استفاده قرار میگیرند.
کد کامل پیادهسازی شبکه عصبی پرسپترون چند لایه در زبان برنامهنویسی پایتون، برای پیش بینی سهام شرکتها و قیمت آنها، در ادامه آمده است:
شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند
برای پیادهسازی شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند، از رویهای مشابه با پیادهسازی شبکه عصبی پرسپترون چند لایه استفاده میشود. کد کامل پیادهسازی شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند در زبان برنامهنویسی پایتون، جهت پیش بینی سهام شرکتها و قیمت آنها، در ادامه نمایش داده شده است:
نکته مهم در مورد استفاده از دادههای ورودی برای آموزش و تست شبکه عصبی این است که در کتابخانه keras، دادههای آموزشی و تست باید ابعاد مشخصی داشته باشند (ابعاد دادههای آموزشی و تست توسط دادههای ورودی تعیین میشود). در نتیجه، تغییر شکل دادهها با استفاده از تابع reshape در کتابخانه numpy ضروری است.
بَکتست مدلهای آموزش دیده و تست شده
پس از اینکه مدلهای شبکه عصبی پیادهسازی شده روی دادههای آموزشی، برازش و روی دادههای تست، ارزیابی شدند، میتوانیم یک گام جلوتر در جهت ارزیابی مدلها برداریم.همانطور که پیش از این نیز اشاره شد، بَکتست فرایندی است که در آن، الگوریتم پیادهسازی شده جهت پیشبینی معاملات مالی-تجاری، روی دادههای تاریخی و با هدف سنجش میزان دقت مدل در پیشبینی نتایج واقعی، ارزیابی میشود. برای چنین کاری از قطعه کد زیر استفاده میشود.
روش بَکتست ارائه شده در این روش، روش سادهای است. روشهای بَکتستِ پیشرفته برای ارزیابی مدلهای پیشبینی در سیستمهای مالی، عوامل خارجی نظیر «هزینههای معاملات» (Transaction Costs)، «تغییرات نظام بازار» (Market Regime Change) و سایر موارد را در هنگام ارزیابی مدلها در نظر میگیرند. با این حال، از آنجایی که هدف این مطلب آموزشی است، ارائه یک روش بَکتست ساده کفایت میکند.
شکل زیر، عملکرد مدل شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند (LSTM) را در پیش بینی سهام شرکت اپل (APPLE) و قیمت آنها در ماه «فوریه» (February) میلادی نمایش میدهد.

عملکرد نمایش داده شده در بالا، بدون استفاده از روشهای بهینهسازی پارامترها حاصل شده است. برای یک مدل شبکه عصبی بازگشتی با حافظه کوتاه مدت بلند (LSTM)، چنین نتایجی حاکی از عملکرد خوب آنها در پیش بینی سهام و قیمت آنها (در این مورد، قیمت سهام شرکت اپل) دارد. همچنین، این نتایج قدرت شبکههای عصبی و مدلهای یادگیری ماشین را در مدلسازی روابط پیچیده میان پارامترها نشان میدهد.
جمعبندی
روشهای یادگیری ماشین به سرعت در حال تکامل هستند و الگوریتمهای جدید و بدیعی در این حوزه در حال پیادهسازی شدن هستند. یکی از راههایی که از طریق آن دانش برنامهنویسان در مورد مدلهای یادگیری هوشمند افزایش مییابد، پیادهسازی کاربردهایی نظیر پیشبینی قیمت سهام توسط شبکههای عصبی مصنوعی است.

اگرچه شبکه عصبی LSTM پیادهسازی شده در این مطلب، عملکرد خیلی دقیقی در پیشبینی قیمت سهام ندارد و برای استفاده کاربردی جهت پیشبینی در سیستمهای معاملات تجاری لایو مناسب نیست، اما میتوان در آینده، از بنیان مدلهای پیادهسازی شده در این مطلب و بهبود آنها، جهت تولید یک سیستم معاملات تجاری لایو برای پیشبینی قیمت سهام استفاده کرد.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش اصول و روشهای دادهکاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- کدنویسی شبکه های عصبی مصنوعی چند لایه در پایتون — راهنمای کامل
- پیشبینی قیمت سهام با کتابخانه کرس (Keras) — راهنمای کاربردی
- پیشبینی قیمت بیت کوین با شبکه عصبی — راهنمای کاربردی
^^








سلام ممنون از سایت خوبتون..من کد های شبکه عصبی در سایت رو دیدم ولی برای قسمتی از تحقیقم کدشبکه عصبی GRU (گیت ) رو میخوام که نتونستم پیدا کنم میشه لطف کنین برام ایمیل کنین
model = tf.keras.models.Sequential()
سلام
چرا tf قبلا تعریف نشده؟
مشکل از کجاست؟