تبدیل داده چیست؟ – توضیح داده Data Transforming به زبان ساده
داده میتواند هر شکل و اندازهای داشته باشد. از تصویر گرفته تا متن و مقادیر سری زمانی، همه از انواع داده هستند. در حالی که ممکن است دیتاست در حوزه کلان داده شامل میلیونها سطر و هزاران ستون باشد، از طرف دیگر، جدولی با تنها چند ستون در نرمافزار اکسل نیز نوعی مجموعهداده به حساب میآید. صرفنظر از فرمت دیتاست، اجرای فرایند «تبدیل داده» (Data Transforming) برای قابل استفاده بودن دادهها در پروژههای یادگیری ماشین ضرورت دارد. تبدیل داده فرایندی است که طی آن دادههای خام از جهان حقیقی جمعآوری شده و سپس به فرمتی که برای کامپیوتر قابل درک و استفاده تبدیل میشوند. قدمی مهم در پروژههای یادگیری ماشین که ممکن است پیچیده و همچنین گمراهکننده بهنظر برسد. در این مطلب از مجله فرادرس یاد میگیریم تبدیل داده چیست، چه ضرورتی داشته و چگونه میتوان انواع آن را پیادهسازی کرد.
- با ضرورت و جایگاه تبدیل داده در پروژههای دادهمحور آشنا میشوید.
- تمایز نحوه درک داده توسط انسان و کامپیوتر را یاد میگیرید.
- فرآیندهای اساسی پاکسازی، نرمالسازی و انتخاب ویژگی را خواهید آموخت.
- انواع استراتژیهای کلیدی تبدیل داده را یاد خواهید گرفت.
- نقش روشهای ایجاد و استخراج ویژگی را یاد میگیرید.
- با ابزارهای مهم و سازمانی Data Transformation آشنا میشوید.




در این مطلب ابتدا یاد میگیریم منظور از تبدیل داده چیست و پس از آشنایی با انواع مختلف آن، چند مورد از تکنیکهای رایج تبدیل داده را پیادهسازی و شرح میدهیم. سپس به توضیح علت نیاز به فرایند تبدیل داده میپردازیم و در انتهای این مطلب از مجله فرادرس، برخی از ابزارهایی که در اجرای تبدیل داده و دیگر عملیاتهای پردازشی به اشخاص حقیقی و سازمانها کمک میکنند را معرفی میکنیم.
مفهوم تبدیل داده چیست؟
انسانها میتوانند بدون فکر کردن به پیکسلها، امواج صدا یا واژگان، درک عمیقی از تصاویر، صداها و متون مختلف بهدست آوردند. اما کامپیوترها فاقد چنین توانایی هستند. از همین جهت و بهمنظور کار کردن با دادهها در سیستمهای کامپیوتری، ابتدا باید فرمت دادهها را بهگونهای که برای کامپیوتر قابل فهم باشد تغییر دهیم. این فرایند را تبدیل داد مینامند.

به عنوان مثال دانشمند علم دادهای را در نظر بگیرید که از او خواستهاند تا با طراحی یک مدل یادگیری عمیق، قیمت خانهها را بر اساس گسترهای از ویژگیها پیشبینی کند. پیش از آنکه دانشمند علم داده بتواند کار خود را بر روی دادههای مجموعه آموزشی شروع کند، ابتدا باید به اجرای مراحلی که تحت عنوان «پاکسازی داده» (Data Cleaning) شناخته میشوند مانند مدیریت «دادههای گمشده» (Missing Data)، ادغام منابع مختلف داده و همچنین مدیریت نمونههای پرت بپردازد. دادههای پرت را میتوان با پیدا کردن نمونههایی که چندین انحراف معیار با میانگین فاصله دارند یا بررسی مقادیر کمینه و بیشینه موجود در دیتاست شناسایی کرد.

به بیان ساده، هر کسبوکاری برای بهبود کیفیت دادهها که بعدتر به نتایجی کارآمد از مدلهای یادگیری ماشین منجر میشوند به تبدیل داده نیاز دارد. فرایندی که با بهرهگیری از ابزارهایی مانند SQL، کتابخانه Pandas در زبان برنامهنویسی پایتون یا حتی بدون کدنویسی انجام میشود. تبدیل داده را با نامهای آمادهسازی داده یا پیشپردازش داده نیز میشناسند. پس از اجرای فرایند تبدیل داده، مطمئن میشوید که دادهها تمیز و آماده استفاده توسط الگوریتمهای یادگیری ماشین هستند. بدون تبدیل داده، سیستم هوشمند شما نمیتواند پیشبینیهای دقیقی از مسئله ارائه دهد. پس از آنکه یاد گرفتیم تبدیل داده چیست، در ادامه توضیح جامعی از انواع و تکنیکهای تبدیل داده ارائه میدهیم.
یادگیری پردازش و آماده سازی داده ها با فرادرس

آمادهسازی و پردازش دادهها یکی از مهمترین مراحل در پروژههای دادهکاوی و یادگیری ماشین است. دادههای خام که از منابع مختلف جمعآوری میشوند اغلب دارای نویز، نمونههای گمشده، ناهنجاری و حتی خطاهای انسانی هستند. این مشکلات میتوانند کیفیت دادهها را تحت تاثیر قرار داده و در نتیجه باعث کاهش دقت مدلهای یادگیری ماشین شود. به همین خاطر، پیش از آنکه بتوان از دادهها در الگوریتمهای پیچیده یادگیری ماشین استفاده کرد، باید آنها را پردازش و آمادهسازی نمود.
این فرایند شامل مراحل متعددی از جمله پاکسازی داده، شناسایی و جایگذاری دادههای گمشده، حذف نویز و نمونههای پرت، نرمالسازی، انتخاب و استخراج ویژگیهای مناسب برای ورود به مدل یادگیری است. زبان برنامه نویسی پایتون و نرمافزار (SPSS) دو مورد از ابزارهایی هستند که بیشترین کاربرد را در این زمینه دارند. برای کمک به یادگیری مهارتهای پردازش و آمادهسازی داده، پلتفرم فرادرس مجموعهای از فیلمهای آموزشی جامع و کاربردی را آماده کرده است که لینک آنها به ترتیبی که پیشنهاد میشود در ادامه قرار داده شده است:
- فیلم آموزش رایگان روشهای پیشپردازش دادهها فرادرس
- فیلم آموزش تجزیه و تحلیل و آمادهسازی دادهها با پایتون فرادرس
- فیلم آموزش آمادهسازی دادهها در SPSS برای تحلیل آماری فرادرس
- فیلم آموزش رایگان کار با پیشپردازش دادهها در یادگیری ماشین با پایتون فرادرس
انواع تبدیل داده چیست؟
حالا که یاد گرفتیم منظور از تبدیل داده چیست، در این بخش به بررسی انواع مختلف این فرایند میپردازیم. تبدیل داده بسته به هدف مسئله و فرمت داده میتواند انواع مختلفی داشته باشد. در فهرست زیر به چند مورد از رایجترین انواع تبدیل داده اشاره شده است:
- پاکسازی داده
- «استخراج ویژگی» (Feature Extraction)
- «ایجاد ویژگی» (Feature Creation)
- نرمالسازی داده
- «تجمیع و تفکیک داده» (Data Aggregation | Data Disaggregation)
- نمونهگیری

همچنین از تبدیل داده به عنوان قدمی مهم در ویرایش تصویر یاد میشود. فرایندی که در آن فرمت، اندازه یا رنگ تصاویر تغییر پیدا میکند. در ادامه نگاه دقیقتری به هر یک از روشهای عنوان شده در فهرست بالا میاندازیم.
پاکسازی داده
به فرایند حذف نمونههای نادرست یا اطلاعات ناقص از دیتاست، اضافه کردن مقادیر گمشده و مدیریت نمونههای پرت «پاکسازی داده» گفته میشود. مرحلهای مهم در هر نوع فرایند تبدیل داده که اغلب بسیار زمانبر است. به این دلیل که اکثر دادههای جمعآوری شده در جهان نامرتب و همچنین ناقص هستند، اجرای فرایند پاکسازی داده لازم و ضروری است. داده نامناسب ممکن است به هر شکلی ظاهر شود. از تاریخ تولد اشتباهی که با سن فرد تطابق ندارد گرفته تا کد پستی که چند رقم آخر آن حذف شده است. از طرفی امکان دارد دادهها شامل نویز باشند. مانند سطری از مجموعهداده که توسط انسان وارد شده و خطای تایپی دارد. برای یادگیری بیشتر در مورد فرایند پاکسازی، میتوانید فیلم آموزش پاکسازی دادهها در پایتون فرادرس که لینک آن در ادامه آورده شده است را مشاهده کنید:

اشتباه انسانی، باگ نرمافزاری یا حتی مشکلات سادهای مانند گمشدن دادهها میتواند از جمله دلایل این خطاها باشد. دلیل هر چه که باشد، بسیار مهم است که پیش از بهرهگیری از دیتاست در مدلهای یادگیری ماشین، ابتدا دادههای خود را به اصطلاح پاکسازی کنید.
استخراج ویژگی
فرایند کاهش حجم زیادی از اطلاعات به مجموعه کوچکتری از متغیرهای کارآمد استخراج ویژگی نام دارد. تکنیکی متداول از تبدیل داده که عمده استفاده آن هنگام کار کردن با محتوای تصویری است. استخراج ویژگی نوعی «تقلیل داده» (Data Reduction) و شیوهای رایج در یادگیری ماشین به حساب میآید. با بهرهگیری از این تکنیک استفاده از دادهها آسانتر شده و دقت پیشبینیها نیز افزایش پیدا میکند.
ایجاد ویژگی
در طول فرایند «ایجاد ویژگی» (Data Creation) اطلاعات جدیدی به دیتاست اضافه میشود. بیشترین کاربرد تکنیک ایجاد ویژگی زمانی است که قصد استفاده از دادههایی با فرمتهای نامتعارف را دارید. برای مثال شاید دیتاستی از تصاویر داشته باشید که تاریخ آنها مشخص نیست. با استفاده از روش ایجاد ویژگی میتوان این قبیل از اطلاعات را به دیتاست اضافه کرد. به این گونه که اطلاعات اضافی هنگام تصویربرداری که با عنوان «فایل تصویری قابل تبادل» (Exchangeable Image File) یا همان EXIF شناخته میشوند بررسی شده و در صورت عدم وجود این اطلاعات نیز، از روشهایی مانند «ارجاع متقابل» (Cross-referencing) استفاده میشود. ایجاد ویژگی نوعی «داده افزایی» (Data Augmentation) است و موجب استفاده از دادههای فراموش شده میشود.

نرمال سازی داده
فرایندی که با انجام آن از یکسان بودن مقیاس همه مقادیر موجود در دیتاست اطمینان حاصل میشود را «نرمالسازی داده» گویند. تکنیکی رایج از تبدیل داده که اغلب هنگام کار با دادههای عددی از آن استفاده میشود. فرض کنید دیتاستی دارید که واحد اندازهگیری برخی از مقادیر آن به اینچ و برخی دیگر به سانتیمتر است. از طرفی دامنه مقادیر یک ستون از ۰ تا ۱۰۰ و ستون دیگر از ۰ تا ۱ متغیر است. اگر قصد طراحی مدل یادگیری ماشینی را بر اساس این نمونهها داشته باشید، ابتدا باید دادهها را نرمال کنید تا همه ویژگیها مقیاس یکسانی داشته باشند.

تجمیع و تفکیک داده
ترکیب چند دیتاست و ایجاد دیتاستی واحد «تجمیع داده» (Data Aggregation) نام دارد. عمده کاربرد این تکنیک زمانی است که دادهها از منابع مختلفی جمعآوری شده باشند. به عنوان مثال ممکن است دادههای مورد نیاز خود را از دو نظرسنجی با پرسشهای متفاوت گردآوری کرده باشید. در چنین مسئلهای میتوانید از تکنیک تجمیع داده برای ادغام این دو دیتاست بهره ببرید و در یک مرحله تمامی دادهها را تجزیه و تحلیل کنید.

اما «تفکیک داده» (Data Disaggregation) برعکس تجمیع داده عمل میکند. به بیان سادهتر، فرایند تقسیم یک دیتاست بزرگ به چند دیتاست کوچکتر را تفکیک داده گویند. مانند وقتی که دادههای شما بر اساس معیار کشور از یکدیگر تفکیک شده باشند. به این صورت که با استفاده از روش تفکیک داده میتوانید دیتاست اولیه خود را بهازای هر کشور به چند دیتاست کوچکتر تقسیم کنید و تجزیه و تحلیل مربوط به هر کشور را جداگانه انجام دهید.
نمونه گیری
زمانی که تنها بخشی از دیتاست خود را مورد استفاده قرار میدهید، در واقع «نمونهگیری» کردهاید. بیشترین کاربرد تکنیک نمونهگیری زمانی است که حجم دیتاست زیاد بوده و امکان ذخیرهسازی آن بر روی سیستم کامپیوتری وجود ندارد. به عنوان مثال اگر دیتاستی با میلیونها سطر داشته باشید و زیرمجموعهای کوچکتر را مانند ۱۰ هزار سطر از دادهها جدا کنید یعنی نمونهگیری کردهاید.
طراحی و ساخت مدلهای یادگیری ماشین پس از تبدیل داده با روشهای عنوان شده انجام میگیرد. مرحلهای که خود شامل بخشهایی مانند آموزش مدل رگرسیون خطی یا لجستیک و یا ساخت یک «درخت تصمیم» و شبکه عصبی میشود. انتخاب مدل یادگیری مناسب به نوع مسئلهای که میخواهید حل کنید بستگی دارد. بعد از ساخت مدل باید با بهرهگیری از معیاری هدفمند مانند «صحت» (Accuracy)، «دقت» (Precision) یا «بازیابی» (Recall)، آن را مورد ارزیابی قرار دهید. برای آشنایی بیشتر در مورد معیارهای ارزیابی در یادگیری ماشین، مطالعه مطلب زیر را از مجله فرادرس به شما پیشنهاد میکنیم:
همچنین مصورسازی یکی دیگر از فرایندهایی است که اغلب در این مرحله و بهمنظور درک دادهها و نتایج حاصل شده از مدل پیادهسازی میشود. تا اینجا یاد گرفتیم تبدیل داده چیست و چه انواعی دارد. در ادامه این مطلب از مجله فرادرس با چند مورد از تکنیکهای رایج تبدیل داده آشنا میشویم.
تکنیک های تبدیل داده
بهطور کلی، انواع تکنیکهای تبدیل داده را میتوان به سه دسته زیر تقسیم کرد:

- تبدیل لگاریتمی
- بریدگی
- تبدیل مقیاس

هر دیتاستی پیش از آنکه برای کاربردی خاص مورد استفاده قرار گیرد، ابتدا باید طی فرایندهایی همچون «مهندسی ویژگی» (Feature Engineering) و «تحلیل اکتشافی داده» (EDA) پردازش و پاکسازی شود. در این بخش، برای شرح انواع تکنیکهای تبدیل داده از دیتاست «تحلیل بازاریابی» (Marketing Analytics) که در وبسایت Kaggle موجود است کمک میگیریم و تعدادی از ویژگیهای دیتاست را برای پردازش آماده میکنیم.
۱. تبدیل سال تولد به سن
در اولین قدم مانند نمونه، کتابخانه Pandas را فراخوانی کرده و پس از بارگذاری دیتاست در متغیری با نام df، مقادیر ستون سال تولد یا همان Year_Birth را از سال فعلی تفریق و در ویژگی جدیدی با عنوان Age ذخیره میکنیم:
۲. تبدیل تاریخ ثبت نام به طول عضویت
در مرحله بعد، ستون DT_Customer که نشاندهنده تاریخ ثبتنام مشتریان است را به ویژگی دیگری با عنوان مدت زمان عضویت یا Enrollment_Length تبدیل میکنیم:
۳. تبدیل واحد درآمد به میلیون
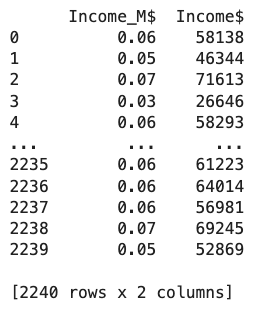
این مرحله از دو بخش تبدیل مقادیر Null به ۰ و تغییر مقیاس اعداد به میلیون دلار تشکیل میشود. با تغییر واحد مقادیر ستون درآمد یا Income به میلیون، مصورسازی توزیع دادهها راحتتر میشود. در قطعه کد زیر شاهده نحوه پیادهسازی این بخش هستید:
خروجی مانند زیر است:
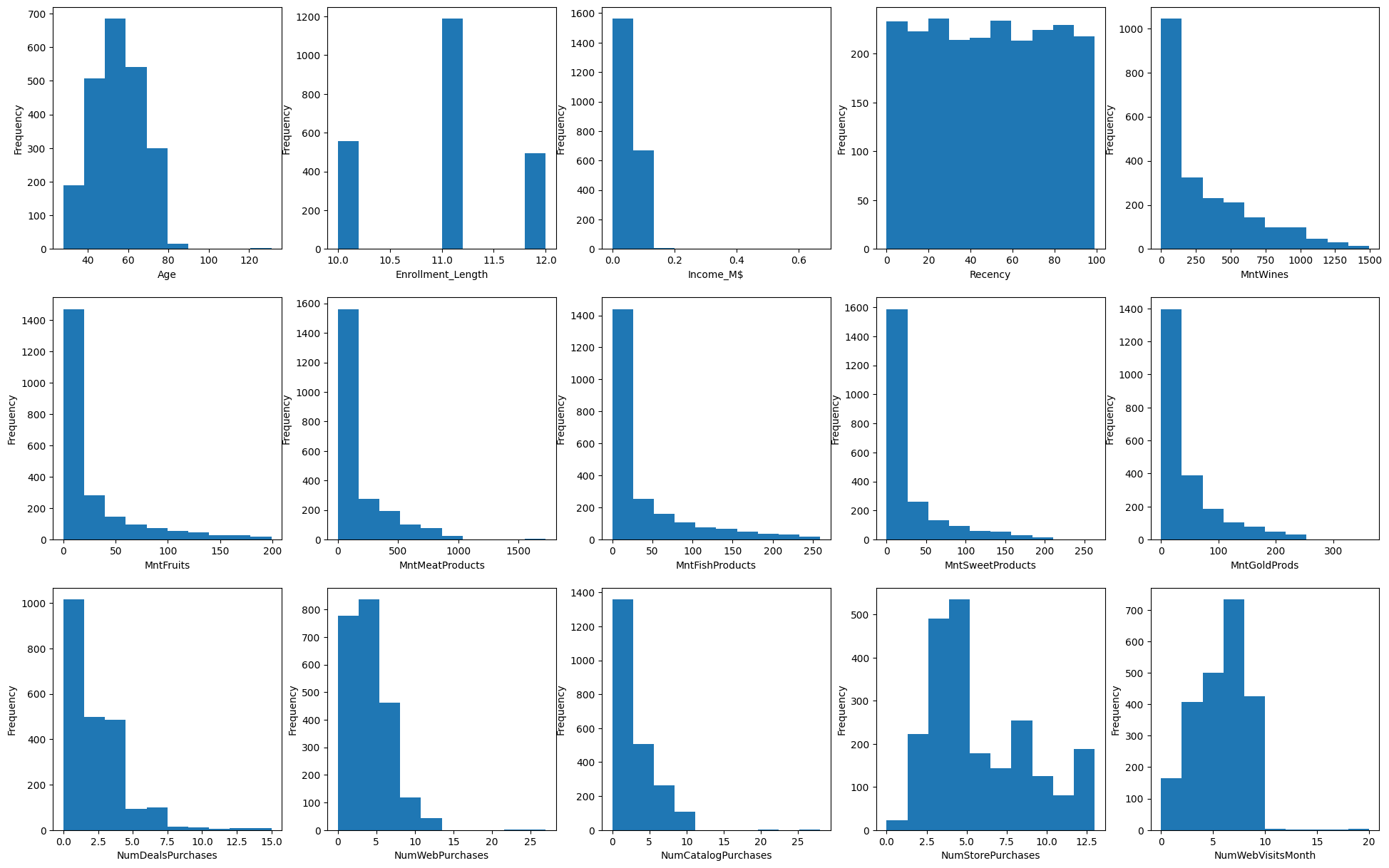
حالا که ویژگیهای مورد نیاز خود را به موجودیتهای کارآمدی تبدیل کردیم، از تکنیک سادهای در تحلیل اکتشافی که هیستوگرام نام دارد برای ترسیم توزیع دادهها استفاده میکنیم:
در تصویر زیر نمودار هیستوگرام رسم شده برای هر ۱۵ ویژگی دیتاست را مشاهده میکنید. توجه داشته باشید که محور افقی بیانگر ویژگی و محور عمودی میزان تکرار هر نمونه داده را نشان میدهد:
در ادامه این بخش، با استفاده از زبان برنامه نویسی پایتون، نحوه پیادهسازی سه تکنیک تبدیل داده را که پیشتر به آنها اشاره شد یاد میگیریم. اگر میخواهید آشنایی کاملتری نسبت به انواع روشهای مصورسازی پیدا کنید، مشاهده فیلم آموزش مصورسازی داده فرادرس که لینک آن در ادامه قرار داده شده است را به شما پیشنهاد میکنیم:
۱. تبدیل لگاریتمی
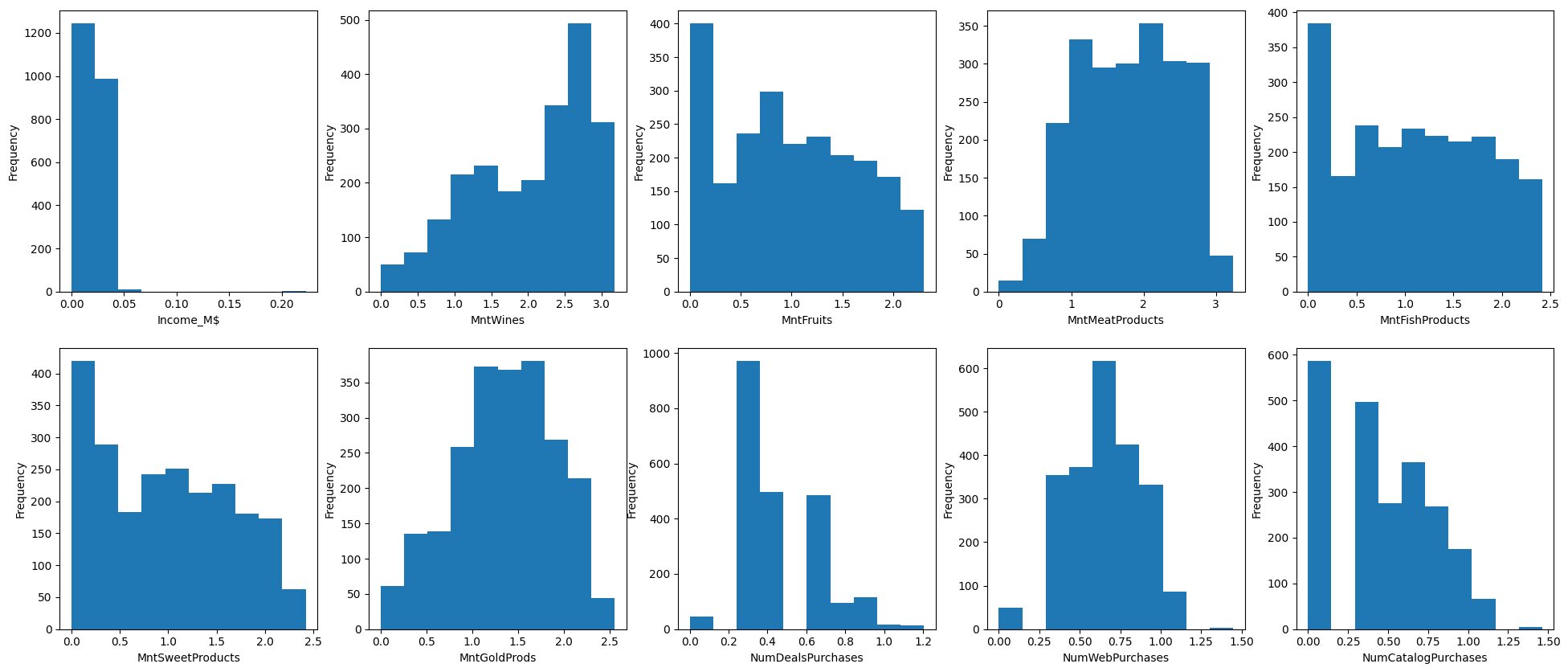
اگر نمونه دادهها از «توزیع توانی» (Power law Distribution) پیروی کنند، میتوانیم با بهکارگیری تکنیک «تبدیل لگاریتمی»، توزیع دادهها را به نرمال تغییر دهیم. از آنجا که در دیتاست ما اغلب ویژگیها توزیع «منحرف به راست» دارند، تنها کافیست مانند زیر از تابع log کتابخانه Numpy برای تغییر توزیع به فرم نرمال استفاده کنیم:
همانطور که در تصویر زیر مشاهده میکنید، توزیع ۱۰ نمونه از ویژگیهای دیتاست تا حد قابل قبولی نرمال شده است:
۲. بریدگی
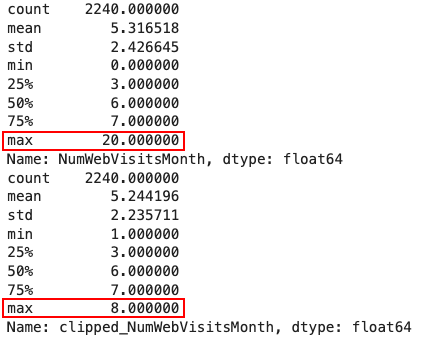
تکنیک (Clipping) مناسب زمانی است که دیتاست شامل نمونههای پرت باشد. این روش حد بالا و پایینی برای دیتاست مشخص میکند و تمامی دادهها را در آن دامنه قرار میدهد. برای یافتن دامنه اکثریت مقادیر داده که از «صدک» ۰/۰۵اُم تا ۰/۹۵اُم متغیر است، میتوانیم از تابع quantile کتابخانه Pandas استفاده کنیم. هر عددی کوچکتر از حد پایین (تعریف شده با صدک ۰/۰۵اُم)، به حد پایین گرد میشود. بهطور مشابه، اعدادی که بیشتر از حد بالا (تعریف شده با صدک ۰/۹۵اُم) باشند، به حد بالا گرد میشود. مانند زیر تکنیک بریدگی را برای دو ویژگی Age و NumWebVisitsMonth پیادهسازی میکنیم:
از نتایج بهدست آمده در بخش مهندسی ویژگی مشهود است که دو ویژگی Age و NumWebVisitsMonth تعداد زیادی نمونه پرت دارند. به همین خاطر تکنیک بریدگی را تنها بر این دو ستون اعمال کردیم. همانطور که در تصویر زیر مشاهده میکنید، مقدار بیشینه ویژگی Age (با عنوان max مشخص شده است) از ۱۳۱ به ۷۴ کاهش یافته است:
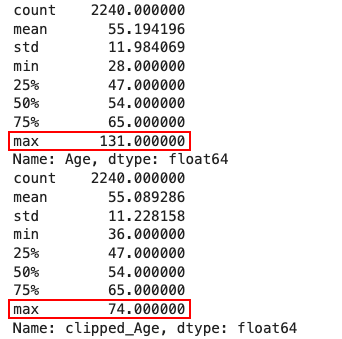
همچنین حداکثر مقدار ویژگی NumWebVisitsMonth نیز از ۲۰ به ۸ کاهش یافته است:
۳. تبدیل مقیاس
پس از اجرای تبدیل لگاریتمی و حل مشکل نمونههای پرت، میتوانیم با استفاده از کتابخانه مخصوص پیشپردازشِ Scikit-learn، مقیاس دادهها را یکسانسازی کنیم. این کتابخانه شامل توابع کارآمدی مانند MinMaxScaler، StandardScaler و RobustScaler است که هر کدام مناسب مسائل متفاوتی هستند. در ادامه بیشتر با هر کدام از این رویکردها آشنا میشویم.
تابع Min Max Scaler
عمده استفاده تابع MinMaxScaler برای زمانی است که دیتاست منظم باشد. رویکردی که بر اساس فرمول زیر، دادهها را در دامنهای بین ۰ و ۱ نرمالسازی میکند:
تابع Standard Scaler
هنگامی از استانداردسازی استفاده میشود که توزیع دیتاست نرمال باشد. تابع StandardScaler اعداد را بر اساس فرمول زیر به فرم استانداردی با میانگین ۰ و انحراف معیار ۱ تبدیل میکند:
تابع Robust Scaler
بهطور معمول زمانی تابع RobustScaler بهکار گرفته میشود که دیتاستی با «توزیع منحرف شده» (Skewed Distribution) و نمونههای پرت داشته باشیم. زیرا در این روش، تبدیل داده بر اساس دو معیار «میانه» (Median) و «دامنه میان چارکی» (Interquartile Range) صورت میگیرد:
برای مقایسه نتایج حاصل از این توابع، یک حلقه تکرار ایجاد میکنیم و هر سه تابع را بر چند ویژگی دیگر از دیتاست همراه با دو ویژگی Age و NumWebVisitsMonth که پیشتر تبدیل شدهاند اعمال میکنیم:
مطابق نمودارهای بهدست آمده، ملاحظه میکنید که تغییری در شکل توزیع دادههای ایجاد نشده و تنها تراکم و پراکندگی نقاط داده تحت تاثیر قرار گرفته است:
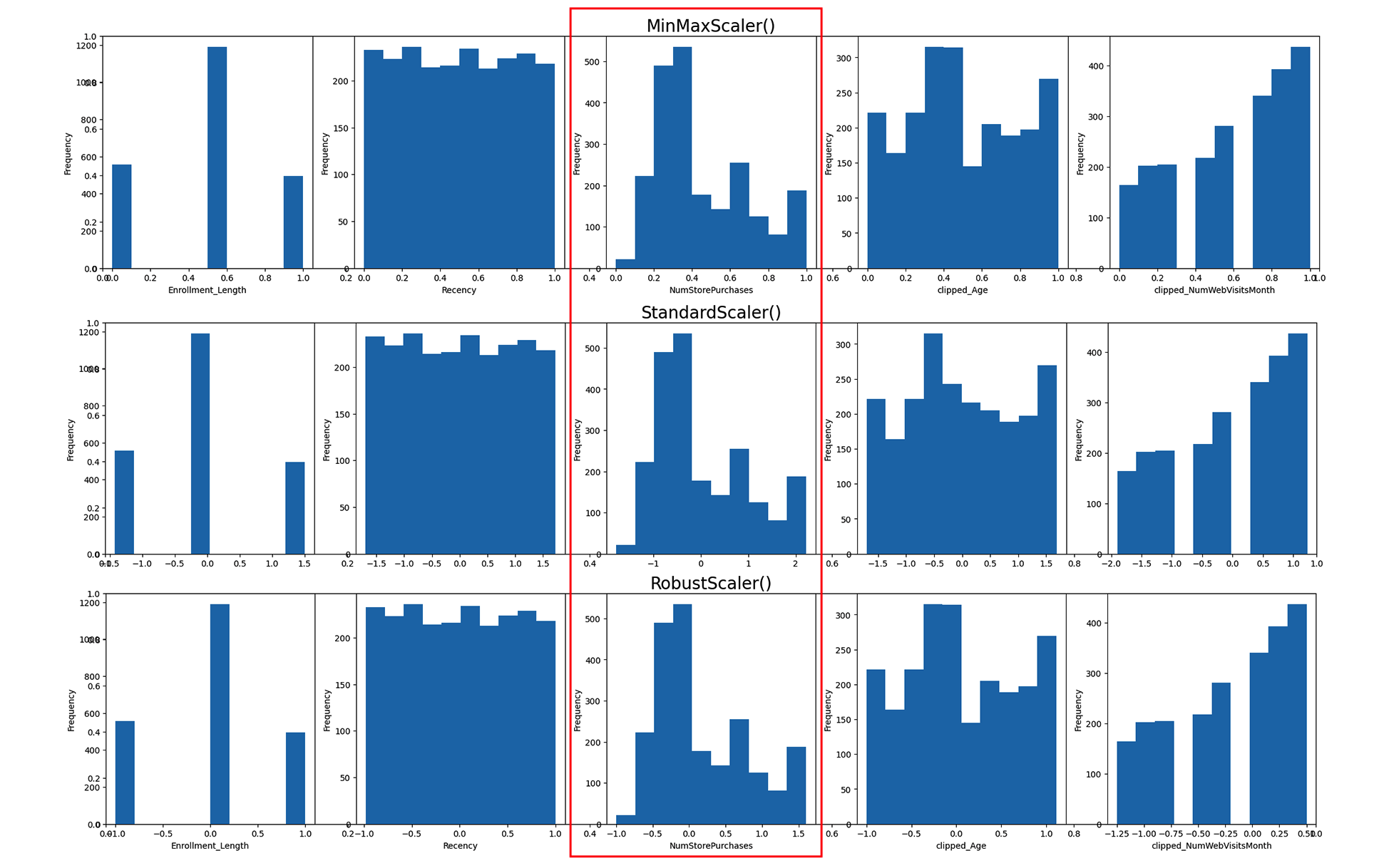
به عنوان مثال، نمودار هیستوگرام ویژگی تعداد کل فروشها یا همان NumStorePurchases که با رنگ قرمز مشخص شده است را در نظر بگیرید. در سطر اول، نتایج تابع MinMaxScaler را مشاهده میکنید که تمامی مقادیر داده را به اعدادی در دامنه ۰ تا ۱ تبدیل کرده است. سطر دوم نتایج حاصل از تابع StandardScaler را نشان میدهد که میانگینی برابر با ۰ دارند و سطر سوم یا نمودار حاصل از تابع RobustScaler نیز میانه دیتاست را به ۰ تغییر داده است. از آنجا که این پنج ویژگی منظم هستند و توزیع نرمال نیز ندارند، تابع MinMaxScaler گزینه مناسبی برای تبدیل داده محسوب میشود.
حالا که تمامی ویژگیها را به فرم ایدهآل تبدیل کردیم، بهتر است مجدد نگاهی به نمودار هستیوگرام آنها بعد از تبدیل داده بیندازیم. در تصویر زیر توزیع دادهها پس از تبدیل داده به نمایش گذاشته شده است:
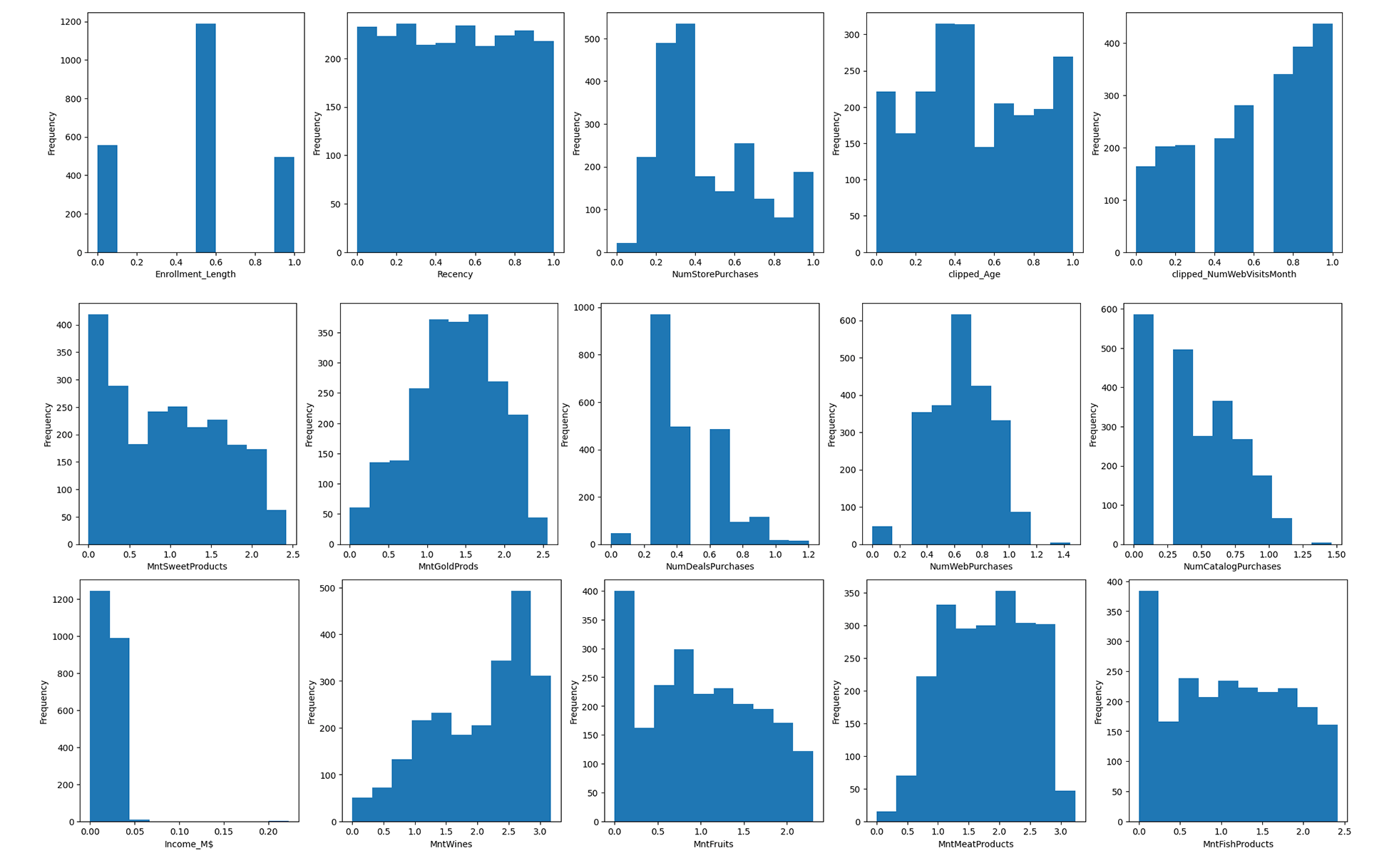
همانطور که ملاحظه میشود، نظم دادهها بهمراتب بیشتر شده و چنین دیتاستی برای مورد استفاده قرار گرفتن در فرایند آموزش مدلهای یادگیری ماشین و تولید خروجیهای مفید مناسبتر است.
چرا به تبدیل داده نیاز است؟
پس از آنکه به پرسش تبدیل داده چیست پاسخ دادیم و انواع و همچنین تکنیکهای آن را بررسی کردیم، در این بخش از ضرورت اجرای فرایند تبدیل داده میگوییم. تبدیل داده با پیچیدگیهای فراوانی همراه است و شاید فکر کنید که چرا کسبوکارها یا صنایع مختلف باید خود را درگیر چنین روند زمانبر و پرهزینهای کنند. با این حال، مواردی از جمله درک شرایط مشتری، اتخاذ تصمیمات هوشمندانه و مدیریت بهتر اطلاعات، همه دلایل خوبی برای توجیه فرایند تبدیل داده هستند. در ادامه توضیح جامعتری از دلایل ذکر شده ارائه میدهیم.


۱. درک شرایط مشتری
یکی از مهمترین مزایای تبدیل داده درک بهتر مشتری است. با استفاده از تبدیل داده میتوانید اطلاعات مربوط به مشتریهای خود را خوشهبندی یا «طبقهبندی» کنید. در خوشهبندی نقاط داده شبیه بهم در گروههای یکسانی قرار میگیرند. به این صورت تحلیل رفتار مشتری راحتتر میشود. برای مثال اگر دیتاستی از تاریخچه پرداختها داشته باشید، با خوشهبندی دادهها میتوانید مشتریهایی را که تمایل به خرید محصولات مشابه دارند شناسایی کنید. از طرف دیگر، فرایند برچسبگذاری نقاط داده را طبقهبندی گویند. با طبقهبندی دادهها درک مناسبی از اولویتهای مشتری حاصل میشود. اگر مجدد همان مثال دیتاست تاریخچه پرداختها را در نظر بگیریم، با طبقهبندی دادهها میتوان خریدهای آینده مشتری را پیشبینی کرد.
۲. اتخاذ تصمیمات هوشمندانه
تبدیل داده در تصمیمگیری بهتر بسیار موثر است و به استخراج ارزش بیشتری از دادهها منجر میشود. اگر دیتاست شما تمیز نبوده و شامل مقادیر گمشده فراوانی باشد، پیشبینی نهایی مدل یادگیری، دقت بالایی نخواهد داشت. تعجبی هم ندارد چرا که پیشبینی بر اساس دادههای نادرست یا ناقص انجام گرفته است. با این حال، اگر با تبدیل داده به پاکسازی دادههای خود بپردازید، به نتایج دقیقتری دست پیدا میکنید.
۳. مدیریت بهتر اطلاعات
از دیگر مزایای تبدیل داده میتوان به مدیریت و سازماندهی بهتر دادهها اشاره کرد. تبدیل داده نقش بهسزایی در کاهش خطاهای موجود در دیتاست دارد. اگر دیتاست شما سرشار از خطاهای گوناگون باشد، درک و ایجاد تغییر در آن با چالش همراه میشود. تبدیل داده و حذف خطاها راهحل کارآمدی برای غلبهبر این چالش است.
در مجموع، درک شرایط مشتری، اتخاذ تصمیمات هوشمندانه و مدیریت بهتر اطلاعات سه نمونه از مواردی هستند که ضرورت تبدیل دادهها را بهخوبی نشان میدهند.
ابزار های تبدیل داده چیست؟
حالا که بهخوبی میدانیم منظور از تبدیل داده چیست، در این بخش به معرفی چند مورد از معروفترین ابزارهای این حوزه میپردازیم. ابزارهایی که شرکتهای بزرگ برای پیشبرد اهداف خود در زمینه تبدیل داده توسعه دادهاند.


۱. IBM InfoSphere
با استفاده از ابزار IBM InfoSphere که توسط شرکت (IBM) طراحی شده است، بهراحتی میتوانید دادههای خود را پاکسازی، ویرایش و تبدیل کنید. از دیگر مزایای این ابزار میتوان به امکان انتقال داده به دریاچه داده و دیگر منابع ذخیرهسازی اشاره کرد. همچنین برای استفاده سازمانی نیز شرکت IBM نسخههایی را در دو بستر درونسازمانی و فضای ابری توسعه داده است. بسته نرمافزاری تبدیل داده درونسازمانی، هم ابزارهای سنتی و هم مدرن مصورسازی داده و همگامسازی را شامل میشود.
۲. SAP Data Services
تبدیل، «نمایهسازی» (Profiling)، پردازش محتوای متنی و یکپارچهسازی داده همه بر روی یک پلتفرم که از سرویس شرکت SAP و رویکرد یکپاچهسازی ETL استفاده میکند پیادهسازی شدهاند. با بهکارگیری دو رویکرد یکپارچهسازی ETL و ELT، پلتفرم SAP Data Services دادههای داخل پتلفرم و همچنین نمونههای جمعآوری شده از منابع خارجی را ترکیب و پردازش میکند. این سرویس ابزارهای بسیاری را برای یکپارچهسازی، تضمین کیفیت و پاکسازی داده دربرمیگیرد. با استفاده از این پلتفرم، شما میتوانید اپلیکیشنهای تبدیل داده منحصر به خود را ساخته و پس از اتصال منابع داده خارجی به آن، از امکاناتی مانند پشتیبانی از سیستمهای مدیریت پایگاه داده و فایلها بهرهمند شوید.

۳. Dataform
ابزار Dataform پلتفرم رایگان و متنبازی برای تبدیل داده است که از طریق آن میتوانید تمامی فرایندهای خود را در بستر فضای ابری مدیریت کنید. افراد آشنا با زبان پرسوجوی SQL این امکان را دارند تا با بهرهگیری از دستورات خط فرمان، سیستمهای تبدیل داده مقاوم و پایداری توسعه دهند. در نتیجه، بهجای مدیریت زیرساخت، توجه مهندسان داده جلب فرایند تجزیه و تحلیل آماری میشود.

۴. Azure Data Factory
امکان پاکسازی، ادغام و تغییر فرمت دادههای سازمانی به مقیاس بزرگ با کمک ابزار Azure Data Factory شرکت مایکروسافت مهیا میشود. با استفاده از این ابزار میتوانید دادههای جمعآوری شده خود را از منابع مختلف یکپارچهسازی کنید. علاوهبر آن، حق انتخاب میان دو رویکرد ETL یا ELT را نیز دارید و پلتفرم Data Factory بهطور خودکار تمامی کدهای مورد نیاز را برای شما مینویسد.

۵. Qlik Compose
به لطف Qlik Compose که ابزاری با معماری «چابک» (Agile) برای خودکارسازی رویکردهای یکپارچهسازی مانند ETL و همچنین تبدیل داده محسوب میشود، مدیران داده دیگر نیازی به کدنویسی و توسعه دستی سیستمها ندارند. پلتفرم Qlik Compose با بهینهسازی فرایند طراحی انبار داده و توسعه خودکار کدهای مربوط به رویکرد ETL، کاهش چشمگیری در زمان، هزینه و خطرات ناشی از تبدیل داده برای کسبوکارها ایجاد میکند. با بهرهگیری از این ابزار بهراحتی میتوانید انبارهای داده خود را طراحی، ایجاد، مدیریت و بهروزرسانی کنید. از ارسال مداوم دادههای پایدار، با کیفیت و بهروزرسانی شده به پلتفرمهای کلان دادهای مانند «آپاچی هادوپ» (Apache Hadoop) به عنوان یکی دیگر از مزایای ابزار Qlik Compose یاد میشود.

۶. Data Build Tool
پلتفرم Data Build Tool یا به اختصار dbt یکی دیگر از ابزارهایی است که با استفاده از آن میتوان بسیار سریع و راحت فرایند تبدیل و مدیریت دادهها را آغاز کرد. این پلتفرم از امکاناتی مانند سیستمهای «کنترل نسخه» (Version Control) مانند «گیت» (Git) و همچنین «پیمانهبندی» (Modularity) پشتیبانی میکند.

جمعبندی
تبدیل داده فرایندی لازم و ضروری در صنعت IT بهشمار میرود. همزمان با متنوعتر شدن سیستمهای کامپیوتری و پیدایش انواع مختلف دیتاستها، نیاز به سازگاری میان دادهها بیش از پیش احساس میشود. همانطور که در این مطلب از مجله فرادرس یاد گرفتیم تبدیل داده چیست، این فرایند استفاده و جابهجایی اطلاعات را میان پلتفرمهای مجزا به مراتب راحتتر میسازد. کسبوکارها و صنایع با تبدیل داده علاوهبر بهینهسازی و ارتقا کیفیت دادهها، ارزش بهمراتب بیشتری نیز در حوزه فعالیت خود خلق میکنند.