



سری زمانی با رویکرد بیزی – راهنمای کاربردی
«رگرسیون» (Regression) و تکنیکهای آن یکی از معمولترین و پرطرفدارترین روشهای مدلسازی در آمار و البته در «تحلیل سری زمانی» (Time Series Analysis) است. مدل «اتورگرسیو» (Autoregressive) که با AR نشان داده میشود دارای یک پارامتر به نام است که براساس «تابع خودهمبستگی» (Autoregressive Function) یا ACF و «خودهمبستگی جزئی» (Partial Autoregressive Function) یا PACF تعیین میشود. در این نوشتار به بررسی و پیادهسازی مدل AR، البته با نگاهی بر «آمار بیز» (Bayesian Approach) و «قضیه بیز» (Bayesian Theorem) خواهیم پرداخت. به این ترتیب با طی کردن مراحلی، یک سری زمانی با رویکرد بیزی ایجاد خواهیم کرد. به عنوان پیشزمینه در این مبحث بهتر است نوشتارهای استنباط و آمار بیزی — به زبان ساده و قضیه بیز در احتمال شرطی و کاربردهای آن و همچنین تحلیل سری زمانی — تعریف و مفاهیم اولیه و سری زمانی در علم داده — از صفر تا صد را بخوانید. از طرفی مطالعه مطلب تابع خودهمبستگی (Autocorrelation Function) — مفاهیم و کاربردها نیز خالی از لطف نیست.



به منظور انجام محاسبات و پیادهسازی مدل AR با رویکرد بیزی در این نوشتار، از زبان برنامهنویسی و محاسباتی R استفاده کردهایم. همچنین از کتابخانههای ggplot ،ggplot2 ،reshape2 ،matrixStats و همچنین funplot برای انجام ترسیمها و نمودارها استفاده شده است. بنابراین قبل از اجرای برنامهها این بستهها یا کتابخانهها را روی نرمافزار R یا محیط Rstudio نصب کنید. برای کار در محیط برنامهنویسی R نیز بهتر است که از نرمافزار RStudio استفاده کرده تا بتوانید خروجی و روند تغییر و مقدار دهی متغیرها را به راحتی دنبال کنید. برای آشنایی بیشتر با زبان برنامهنویسی R و محیط نرمافزار Rstudio بهتر است آموزش ویدیويی فرادرس در این زمینه با عنوان آموزش برنامه نویسی R و نرم افزار RStudio و آموزش تکمیلی برنامه نویسی R و نرم افزار RStudio را تهیه و مشاهده کنید.
سری زمانی با رویکرد بیزی
در این نوشتار قصد داریم به کمک آمار و استنباط بیزی، رگرسیون و مدلسازی را برای دادههای سری زمانی که مربوط به بانک انگلستان است، به کار بریم. این مجموعه دادهها، رشد شاخص GDP را در سالهای مختلف نشان میدهد. در ادامه نحوه بارگذاری و استفاده از این مجموعه داده گفته خواهد شد.
بهرهگیری از آمار بیز در تجزیه و تحلیلهای آماری، فوایدی زیادی بخصوص در سری زمانی دارد. هنگامی که در آنالیز سری زمانی، مدلسازی روی دادهها را با پارامترهای زیاد در یک مقطع یا بازه کوتاهی از زمان (مثلا در یک بازه ۳ ساله)، انجام میدهیم، ممکن است دچار مشکل بیشبرازش (Overfitting) شویم. این مشکل معمولا در تحلیل دادههای اقتصادی در مدلسازی روی میدهد. به این ترتیب مدل ایجاد شده روی دادههای موجود خوب عمل کرده ولی قادر به پیشبینی برای دادههای جدید نخواهد بود. یکی از روشهای غلبه بر بیشبرازش و حل این مشکل، استفاده از رویکرد بیزی و استفاده از «توزیعهای پیشین» (Prior Distribution) برای پارامترهای مدل است.
برای آنکه بفهمیم چگونه میتوان بر مشکل بیشبرازش غلبه کرد به یک تکنیک رگرسیونی اشاره میکنیم. «رگرسیون ستیغی» (Ridge Regression) را به عنوان مثال در نظر بگیرید. در این روش رگرسیونی از یک تابع جریمه در فضای استفاده میشود که مدل را به ازاء استفاده از پارامترهای با مقدارهای بزرگ، بیشتر جریمه میکند. در همین راستا اگر برای هر یک از پارامترهای مدل رگرسیونی، توزیع پیشین نرمال را انتخاب کنیم، میتوانیم مدل رگرسیونی را براساس مشاهدات و توزیع پیشین بهینه کرده و مناسبترین پارامترها را انتخاب کنیم. از طرفی استفاده از آمار بیز این اجازه را میدهد که به پارامترهای مدل رگرسیونی به دید متغیرهای تصادفی نگاه کرده و بنابراین انتخاب حدود و توزیع احتمالی آنها در برآورد مقدارهایشان در مدل آینده موثر خواهد بود.
قضیه بیز و کاربرد آن در پیشبینی رگرسیونی
در دیگر نوشتارهای فرادرس با مفهوم رگرسیون چندگانه (Multiple Regression) آشنا شدهاید. اینجا میخواهیم از چنین مدلی برای پیشبینی سری زمانی استفاده کنیم. فرض کنید مقدار مشاهده شده بردار تصادفی در زمان به صورت و متناظر با آن مقدار متغیر تصادفی در زمان نیز به صورت نشان داده شده باشد. در این صورت مدل رگرسیون خطی چند گانه به صورت زیر نوشته میشود.
مدل رگرسیونی
واضح است که منظور از مقدار خطای تصادفی با توزیع نرمال با میانگین صفر و واریانس است.
به منظور برآورد پارامترها () از نمونههای تصادفی برای هر یک از متغیرها استفاده و «تابع درستنمایی» (Likelihood Function) را مشخص میکنیم. در اینجا فرض بر این است که توزیع به شرط پارامترهای یا در حقیقت به شرط ، نرمال است.
با استفاده از روشهای برآورد به کمک «حداکثرسازی تابع درستنمایی» (Maximization Likelihood Function) که به واسطه لگاریتمگیری و محاسبه مشتق تابع درستنمایی عمل میکند، برآورد حداکثر درستنمایی که همان برآورد «حداقل مربعات معمولی» (OLS) است را محاسبه میکنیم. در این حالت برآورد پارامترهای مدل (بردار پارامترها) به صورت زیر خواهد بود.
به نظر میرسد که این رابطه به صورت کسری است که صورت آن کوواریانس بین و بوده و مخرج نیز واریانس است. از طرفی برآورد واریانس جمله خطا نیز به صورت زیر خواهد بود.
نکته: در اینجا تعداد مشاهدات (دنباله یا سری زمانی) و نیز همان «ترانهاد» (Transpose) ماتریس یا بردار است.
تفاوت اصلی در بین روش و دیدگاه «فراوانیگراها» (Frequentist) و «روش بیزی» (Bayesian Approach) این است که پارامترهای مدل در دیدگاه بیزی به عنوان یک متغیر تصادفی دیده میشوند و میتوان به کمک دادهها و توزیع پیشین آنها، توزیع پسین و برآوردهای مناسبتری را مشخص و تعیین کرد. جالب آن است که اگر هیچ اطلاعی از توزیع پیشین وجود نداشته باشد و از «توزیع جفریز» (Jeffreys Prior) استفاده شود، برآوردهای حاصل شده توسط روش بیزی با برآوردگرهای تولید شده توسط دیدگاه فراونیگراها یکسان خواهد بود. در جدول زیر تفاوت بین رویکرد فراوانیگراها و روش بیزی مشخص شده است.
| فراوانیگراها | روش بیزی | |
| پارامترهای مدل رگرسیونی (نامعلوم) | ثابت | تصادفی (متغیر تصادفی) |
| مشاهدات (معلوم) | تصادفی (نمونه تصادفی) | ثابت |
| مدل احتمال |
به این ترتیب از «توزیع پیشین» (Prior Distribution) به عنوان اطلاعات پیشین استفاده کرده و با استفاده از قضیه بیز تابع درستنمایی را به روزآوری میکنیم. بهتر است ابتدا نگاهی به قضیه یا قانون بیز داشته باشیم.
قضیه بیز برای دو پیشامد و و براساس احتمال شرطی آنها، به صورت زیر نوشته میشود.
این قضیه نشان میدهد، چگونه اطلاعات و دانش پیشین که براساس شواهد بدست آوردهایم امکان به روز رسانی تابع احتمال پسین را فراهم میکند. حال از این قضیه برای برآورد پارامترهای مدل رگرسیونی براساس تابع درستنمایی کمک میگیریم. در چنین وضعیت میتوانیم تابع توزیع پسین را برای پارامترهای مدل به صورت زیر بنویسیم.
رابطه ۱
حتی میتوان، رابطه تابع احتمال پسین را به صورت سادهتر نیز نوشت. این کار در رابطه زیر صورت گرفته است.
رابطه ۲
این رابطه از این لحاظ معنی دارد که مخرج کسر رابطه ۱ بستگی به پارامترها ندارد، پس میتوانیم در محاسبات به منظور حداکثرسازی تابع درستنمایی آن را کنار گذشته و از آن صرف نظر کنیم. رابطه ۲ نشان میدهد که توزیع پسین برای پارامترها به شرط دادهها، متناسب با حاصلضرب تابع درستنمایی است (که ما آن را نرمال فرض کردیم) در تابع احتمال پیشین پارامترها است (که باز هم آن را هم نرمال در نظر گرفتهایم). برای محاسبه تابع توزیع پیشین احتیاج به «توزیعهای حاشیهای» (Marginal Distribution) و «توزیع توام» (Joint Distribution) داریم که متاسفانه مشخص کردن آنها به راحتی امکانپذیر نیست. به این منظور از یک روش عددی به نام «نمونهگیری گیبز» (Gibbs Sampling) استفاده خواهیم کرد. این روش نوع خاصی از «زنجیره مارکف مونتکارلو» (Monte Carlo Markov Chain- MCMC) است که اجازه میدهد نمونههایی از توزیعهای چند متغیره به کمک توزیع شرطی ایجاد کرده و توزیع توام را برآورد کنیم. در ادامه مروری بر نمونهگیری گیبز خواهیم داشت.
نمونهگیری گیبز
تصور کنید که توزیع توام برای متغیر تصادفی به صورت زیر باشد.
هدف پیدا کردن توزیع حاشیه برای هر یک از متغیرهای تصادفی این توزیع توام است. اگر فرم توزیع احتمال این متغیرها مشخص نباشد، به سختی میتوان با انتگرالگیری و روش تحلیلی، توزیعهای حاشیهای را مشخص کرد. در این بین نمونهگیری و الگوریتم گیبز قادر به برآورد توزیعهای حاشیهای برحسب توزیع شرطی است.
ابتدا حدس اولیهای برای مقدارهای نمونه تصادفی تایی اختیار میکنیم که در اینجا آنها را در گام اولیه به صورت نامیدهایم.
در گام بعد، از توزیع متغیر اول به شرط بقیه متغیرها ( متغیر دیگر) نمونه تولید میکنیم. در حقیقت با توجه به موجود بودن توزیع شرطی این کار امکانپذیر است.
همین کار را در گام بعدی برای متغیر دوم انجام داده و از نمونه تولید شده قبلی که در گام پیشین تولید شده به همراه متغیرهای سوم به بعد استفاده میکنیم.
تکرار این گامها منجر به تولید نمونههای تصادفی از توزیعهای شرطی در مرحله اول میشود. همچنین با ادامه این مراحل در گامهای بعدی، الگوریتم نمونهگیری گیبز نمونهها را میسازد. به این ترتیب با این الگوریتم میتوانیم توزیعهای حاشیهای را بوسیله همگرایی توزیعهای شرطی بدست آوریم. فرض کنید این مراحل را به تعداد M بار تکرار کردهایم. میانگین نمونههای تولید شده از هر یک از توزیعهای شرطی میتواند میانگین توزیع پسین را نشان دهد. در تصویر زیر این مراحل را مشاهده میکنیم. در اینجا یک توزیع دو متغیره از و وجود دارد که احتیاج به توزیع حاشیهای هر یک داریم.
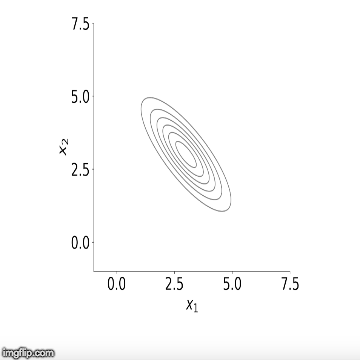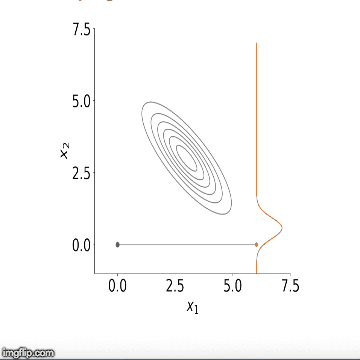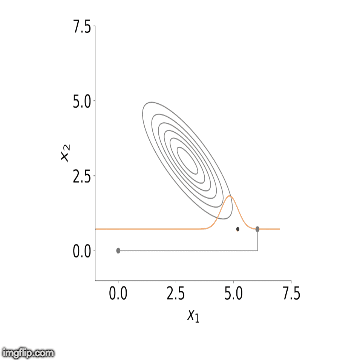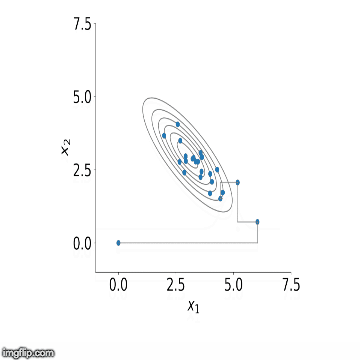
به خوبی دیده میشود که حتی با انتخاب نقطهای خارج از تکیهگاه توزیع حاشیهای، میتوانیم با تکرار مراحل برآورد مناسبی از ان ایجاد کنیم. در ادامه با استفاده از نمونهگیری گیبز و قضیه بیز سعی خواهیم کرد با مدل (AR(2 (اتورگرسیون مرتبه ۲) مدل مناسبی برای پیشبینی مقادیر درصد رشد GDP ارائه کنیم و در انتها نیز به کمک یک فاصله معتبر، پارامترها را محصور کنیم.
مدل سری زمانی (AR(2
مدل سری زمانی اتورگرسیو مرتبه ۲ به صورت زیر نوشته میشود. این مدل بیانگر ارتباط مقدار در زمان با دو مقدار قبلی یعنی و است.
مدل اتورگرسیو مرتبه ۲ - (AR(2
از طرفی میتوان این مدل را به صورت ماتریسی نیز بیان کرد. اگر ضرایب مدل اتورگرسیو را به صورت بردار در نظر بگیریم، خواهیم داشت.
همچنین در ادامه ماتریس را به شکل زیر نمایش میدهیم تا بتوانیم مدل ماتریسی را ایجاد کنیم.
به این ترتیب مدل اتورگرسیو را میتوان به فرم ماتریسی مدل رگرسیونی که در بالا به آن اشاره شد، بنویسیم.
کدهای برنامهنویسی در R
برای انجام پیشبینی و برآوردهای پارامترهای سری زمانی ابتدا دادهها را بارگذاری میکنیم. این اطلاعات در قالب فایل متنی از اینجا قابل دریافت است.
همانطور که دیده میشود مقدار تاخیر p=2 در مدل اتورگرسیو انتخاب شده است. البته این مدل به علت سادگی و البته کارایی انتخاب شده است. ولی میتوانید مقدار مناسب برای p را به کمک معیارهای ارزیابی مدل مانند AIC یا BIC انتخاب کنید. نحوه محاسبه معیار AIC در زبان برنامهنویسی محاسباتی R در نوشتار محاسبه معیار ارزیابی AIC در R — به زبان ساده شرح داده شده است. همچنین برای استفاده از معیار BIC نیز بهتر است به مطلب معیار ارزیابی BIC در مدل های احتمالی — از صفر تا صد را نیز مطالعه کنید.
در گام بعدی به معرفی ماتریس و بردار ضرایب خواهیم پرداخت. برای این کار درون کد از تابع regression_matrix استفاده کردهایم که دارای سه پارامتر است. این تابع، دادهها، مقدار تاخیر و مقدار منطقی برای مشخص کردن اینکه آیا مدل شامل مقدار ثابت () باشد یا خیر، را دریافت کرده و ماتریسی مانند مدل رگرسیونی برای مدل (AR(2 ایجاد میکند. همچنین تابع ar_companion_matrix نیز تابعی است که ماتریس ضرایب را به ماتریسی بدون مقدار ثابت تبدیل میکند.
در قطعه کد بعدی به تعریف تابع regression_matrix پرداختهایم و از لیست حاصل از قسمت قبل، تعداد سطرها و ماتریسها را استخراج خواهیم کرد. سپس براساس تحلیل بیزی، توزیع پیشین را مشخص میکنیم.
همانطور که دیده میشود، به عنوان توزیع پیشین برای بردار ضرایب از توزیع نرمال استفاده شده است. مشخص است که میانگین این توزیعها صفر و واریانس برابر با ۱ در نظر گفته شده است. به این ترتیب بردار زیر را به عنوان بردار پارامترها مشخص کردهایم.
همچنین برای واریانس نیز ماتریسی به شکل زیر در نظر گرفته شده است.
به عنوان تابع پیشین برای پارامتر واریانس از توزیع گامای معکوس (پیشین مزدوج) استفاده شده. این توزیع اغلب به عنوان توزیع پیشین واریانس به کار میرود زیرا تکیهگاه آن اعداد مثبت است که برای بیان توزیع احتمالی واریانس مناسب است. پارامترهای توزیع گامای معکوس به صورت زیر است.
در برنامه و کد نوشته شده مقدار $$T_0$=1$$
در کد بالا، ماتریسها و مقدارهای اولیه برای محور افقی و پیشبینیها آماده شدهاند. ماتریسی که به نام out ساختهایم برای نگهداری نمونههای تصادفی تولید شده است. از آنجایی که میخواهیم کار مدلسازی را ۱۵ هزار بار تکرار کنیم، این ماتریس دارای همین تعداد سطر است. توجه داشته باشید که مدل اتورگرسیون در برنامه به صورت زیر است.
برای پیشبینی مقدار در سه سال آینده احتیاج به دو مقدار پیشین داریم. به این ترتیب ماتریس دوم out1 باید ماتریسی با تعداد ستونهایی برابر با تعداد دورههای پیشبینی بعلاوه مقدار تاخیرها باشد که در اینجا برابر با ۱۴ خواهد بود. زیرا دورههای پیشبینی برحسب فصل است و قرار است سه سال را پیشبینی کنیم. در نتیجه p=3, n=4×۳=۱۲ و در نهایت تعداد ستونها ماتریس out1 برابر با ۱۲+۲=۱۴ خواهد بود.
پیادهسازی نمونهگیری گیبز
در ادامه به کد مربوط به پیادهسازی نمونهگیری گیبز خواهیم رسید.

هر چند این کد ممکن است مقداری پیچیده به نظر برسد ولی با کمی تامل و دقت میتوانید محاسبات را دنبال کنید.
ابتدا، باید مقدار رشد GDP () را مشخص کنیم. ماتریس که همان مقدارهای متغیر با تاخیر زمانی ۲ است را به همراه با یک ستون از مقدارها ۱ میسازیم. همچنین در این مرحله به همه اطلاعات پیشین (Prior) که قبلا مشخص کردهایم به همراه تعداد تکرارهای الگوریتم و دو ماتریس خروجی احتیاج داریم. حلقه اصلی تکرار جایی است که باید بیشترین توجه را به آن داشته باشیم. در اینجا همه محاسبات اصلی صورت میگیرد. دو متغیر M و V میانگین و واریانس توزیع نرمال پسین به شرط را تشکیل میدهند. به این ترتیب میانگین پارامتر برحسب توزیع پسین به صورت زیر محاسبه میشود.
همچنین واریانس پارامتر به شکل زیر بدست خواهد آمد.
اگر به جمله دوم در محاسبه میانگین برآوردهای توجه کنید، مشخص است که میتوانیم به جای از برآورد درستنمایی آن استفاده کنیم. در نتیجه رابطه زیر را خواهیم داشت.
این عبارت بیان میکند که همان میانگین وزنی حاصل از برآورد توزیع پیشین و برآورد حداکثر درستنمایی است. این دقیقا نشان میدهد که از هر دو منبع اطلاعاتی (اطلاعات مربوط به توزیع پیشین و دادهها) برای برآورد پارامتر جامعه استفاده شده است. حال به واریانس توزیع پیشین توجه کنید. اگر مقدار واریانس یعنی sigma0 را کوچک انتخاب کنیم انتظار داریم که که برآورد حاصل از توزیع پسین با دقت بیشتری حاصل شود و توزیع برآوردگر، واریانس کوچکی خواهد داشت. برعکس این حالت نیز وجود دارد که با انتخاب واریانس بزرگتر برای توزیع پیشین، واریانس توزیع پسین پارامتر نیز بزرگتر و در نتیجه دقت کمتری را ارائه خواهد داد.
باز به مسئله توزیع نرمال به عنوان توزیع پیشین میانگین برمیگردیم. برای آنکه بتوانیم از یک توزیع نرمال چند متغیره با میانگین و ماتریس واریانس نمونه تولید کنیم، بهتر است مطابق رابطه زیر نمونههایی مانند از توزیع نرمال استاندارد چند متغیره تولید و آنها را به نرمال چند متغیره با میانگین و تبدیل کنیم.
به نظر میرسد که فقط میانگین توزیع شرطی پسین را با حاصلضرب واریانس در مقدار تصادفی توزیع نرمال استاندارد جمع کردهایم. به این ترتیب از توزیع شرطی پسین ، نمونه تولید کردهایم. حال نمونههای تصادفی از را در اختیار داریم. به این ترتیب میتوانیم نمونه تصادفی برای را براساس «توزیع گامای معکوس» به شرط ایجاد کنیم. برای نمونهگیری از چنین توزیعی با درجه آزادی و پارامتر مقیاس کافی است که متغیر تصادفی با توزیع نرمال استاندارد به صورت انتخاب کنیم و تصحیح زیر را انجام دهیم.
در این حالت یک نمونه از «توزیع گامای معکوس» (Inverse Gamma Distribution) خواهد بود.
کد زیر به منظور تبدیل برآوردها به یک ماتریس برای پیشبینی نوشته شده است. چنین ماتریس را به نام «ماتریس کلاه» (Hat Matrix) میشناسند. اگر دوره سری زمانی ۱۲ ساله و مقدارهای پیشبینی مربوط به ۳ سال آینده باشند ماتریس با اندازه 12+3 خواهیم داشت. در گام احتیاج به مقدارهای واقعی یا برآوردهای گامهای و داریم زیرا مقدار تاخیر (Lag) را ۲ در نظر گرفتهایم. به این معنی که هر مقدار وابسته به دو مقدار قبلتر از خودش است. چنین مدلی به صورت زیر نوشته میشود.
در حالت کلی ما به یک ماتریس با ابعاد احتیاج داریم که بیانگر تعداد دورهها (مقدارهای مربوط به سری زمانی) است و نیز مقدار تاخیر (lag) در مدل AR را نشان میدهد. مدل پیشبینی به صورت (AR(2 در نظر گرفته و جمله خطا نیز با واریانس انتخابی مشخص شد.
حال میتوانیم به محاسباتی که توسط الگوریتم انجام شده نگاهی بیاندازیم. کدهایی که در زیر مشاهده میکنید به منظور استخراج بعضی از خصوصیات حاصل از اجرای الگوریتم روی دادههای سری زمانی به کار رفته است. به این ترتیب میانگینها برآورد حاصل برای هر یک از پارامترها محاسبه شده و نمودار فراوانی (هیستوگرام) آنها ترسیم شده است.
همانطور که دیده میشود ضرایب و پارامترهای مدل رگرسیونی AR به صورت زیر برآورد شدهاند.
در تصویرهای زیر توزیع هر یک از پارامترهای مدل را مشاهده میکنید. به ترتیب در نمودار اول، توزیع مقدار ثابت و در نمودار دوم و سوم توزیع پارامترهای و و در نمودار چهارم نیز توزیع برآورد واریانس جمله خطا نشان داده شده است.




گام بعدی، استفاده از برآورد پارامتر برای رسم مقدارهای پیشبینی شده است. همچنین نمایش فاصله معتبر برای پیشبینیها نیز از مواردی است که در ادامه به آن خواهیم پرداخت.
رسم نتایج حاصل از پیشبینی
براساس مدل بدست آمده در مراحل قبلی میخواهیم مقدار رشد GDP را برای سه سال آینده پیشبینی کنیم. توجه داشته باشید که در تحلیل بیزی قادر به نمایش حدودی برای مقدارهای پیشبینی هستیم که به مانند فاصله اطمینان برای مقدارهای آینده عمل میکند. این حدود را به نام «فاصله معتبر» (Credible Interval) میشناسیم. البته در اینجا منظورمان از فاصله معتبر دقیقا همان فاصله اطمینان نیست زیرا با دید فراوانیگراها منظور از فاصله اطمینان، حدودی است که اگر نمونهگیری را ۱۰۰ بار تکرار کنیم، انتظار داریم که مثلا ۹۵ فاصله شامل پارامتر باشند.
ولی در نگاه بیزی، پارامترهای مدل نیز متغیرهای تصادفی هستند و میتوانیم برای آنها نیز حدودی را برحسب احتمال رخداد در نظر بگیریم و بگویم که مثلا پارامتر با احتمال مثلا ۹۵٪ در یک فاصله یا بازه عددی قرار میگیرد. هر چند ممکن است این دو عبارت یک منظور را برسانند ولی با توجه به ماهیت پارامتر در هر یک از این رویکردها، شیوه بیان و تفسیر فاصله اطمینان و حدود پیشبینی یا فاصله معتبر، متفاوت خواهد بود.
کد زیر به منظور ترسیم حدود برای مقدارهای پیشبینی برای سه سال آینده نوشته شده است.
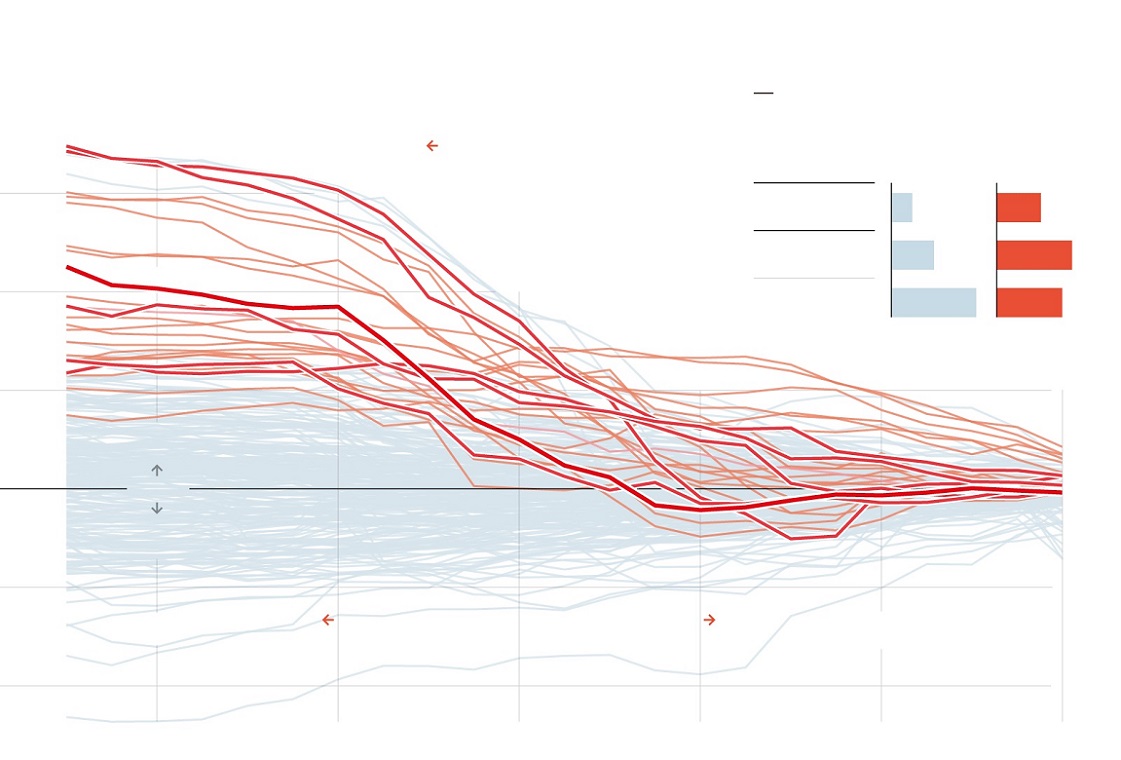
نتیجه اجرای این کد، نموداری است که در ادامه مشاهده میکنید. مشخص است که براساس سالهای ۲۰۱۷ تا ۲۰۲۰ حدود پیشبینی ناحیه با خطوط قرمز رنگ و مقدار پیشبینی با رنگ آبی در میان آنها دیده میشود. این ناحیه شامل صدکهای ۱۶ تا ۸۴ مقدار پیشبینی شده هستند. هر چند این نمودار میتواند بیانگر حدود پیشبینی باشد ولی در ادامه سعی میکنیم که نحوه نمایش را بهبود دهیم.

در این قسمت با استفاده از کتابخانه fanplot از بستههای زبان برنامه نویسی R، نموداری بهتری ترسیم کردهایم که تراکم نقاط پیشبینی را در بازه مورد نظر به شکل مناسبتری نمایش میدهد.
همانطور که دیده میشود، ناحیهای که با کادر خاکستری مشخص شده، ناحیه پیشبینی برای متغیر مستقل است. همچنین خطوط نارنجی که به صورت متراکم دیده میشوند، پیشبینی برای مقدار را نشان میدهند. توجه کنید که مقدارها این متغیر روی محور عمودی و سمت راست نمایش داده شدهاند. تراکم این نقاط در حول مرکز بیشتر و در دنبالهها کمتر هستند. البته همین موضوع را هم انتظار داشتیم.

خلاصه و نتیجهگیری
نتیجه پیش بینی ما بیانگر یک روند مثبت است. به نظر میرسد که متوسط رشد سالانه تا سال ۲۰۲۱ برابر با ۳٪ باشد. همچنین میزان ریسک برای رشد ۱٪ تا ۵٪ نیز تقریبا ۹۵٪ است. همچنین نمودار نشان میدهد که وجود رشد منفی بسیار بعید به نظر میرسد. که البته با توجه به سیاستهای توسعه اقتصادی امریکا و تاثیر آن در اقتصاد جهان، صحیح به نظر میرسد. همانطور که دیده میشود، طول فاصله اطمینان ۹۵ درصدی بزرگ به نظر میرسد و مقدار شاخص GDP را از ۱ تا ۵ شامل میشود. البته برای بالا بردن دقت و کاهش طول فاصله اطمینان میتوان از روشها و تکنیکها دیگر مانند Bayesian Var یا Dynamic Factor Model استفاده کرد. البته چنین مدلهایی دارای پیچیدگیهای خاص خود نیز هستند و برنامهنویسی و پیادهسازی آنها نیز احتیاج به زمان بیشتری دارد. به این ترتیب به نظر میرسد که استفاده از مدل AR بتواند توصیف مناسبی از تغییرات و پیشبینی سری زمانی GDP را ارائه کند.
استفاده از مدلهای سری زمانی (حتی با در نظر گرفتن مدل ساده مثل AR) باز هم نیاز به محاسبات و زمان زیادی برای پیادهسازی دارد ولی این موضوعی که برایمان اهمیت دارد، پیشبینی نسبتا دقیقی از آینده پدیده تصادفی و فرآیند تصادفی وابسته است که توسط مدل ایجاد شده، ارائه کردیم. در این متن با استفاده از زبان محاسبات آماری R، توانستیم پیچیدگیهای یک مدل سری زمانی را ساده کرده و پیشبینی مناسبی ارائه دهیم. با مطالعه کدهای نوشته شده میتوانیم، مبنای محاسبات و مدلسازی را بهتر درک کنیم. برای ایجاد مدل از توزیع پیشین و استنباط بیزی همچنین نمونهگیری گبیز استفاده کردیم تا مناسبترین مدل را ایجاد کنیم.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای پیشبینی و تحلیل سریهای زمانی
- آموزش تحلیل و پیشبینی سری های زمانی
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش متلب با نگرش تحلیل آماری، تحلیل سری های زمانی و داده های مکانی
- رگرسیون ستیغی (Ridge Regression) در پایتون — راهنمای کاربردی
- رگرسیون خطی چندگانه (Multiple Linear Regression) — به زبان ساده
^^











خیلی ممنون. دو جا اشتباه تایپ در معادله AR(2) به جای t-2 نوشته شده t-1.
با سلام خدمت شما؛
نکته بیان شده صحیح است و اصلاحات لازم در متن اعمال شد.
از همراهی و توجه شما سپاسگزاریم.