



یادگیری عمیق (Deep Learning) با پایتون – به زبان ساده
در این مطلب، مفهوم یادگیری عمیق و روش پیادهسازی آن با زبان برنامهنویسی پایتون آموزش داده شده است. دلیل اصلی نهفته در پس «یادگیری عمیق» (Deep Learning) این ایده است که «هوش مصنوعی» (Artificial Intelligence) باید از مغز انسان الهام بگیرد. این چشمانداز موجب سربرآوردن مفاهیم «شبکه عصبی» (Neural Network) شده است. مغز انسان دارای میلیاردها «نورون» (neuron) با دهها هزار اتصال میان آنها است. الگوریتم یادگیری عمیق، مغز انسان را در بسیاری از شرایط شبیهسازی میکند، از همین رو هم مغز و هم مدلهای یادگیری عمیق دارای گستره وسیعی از واحدهای محاسباتی (نورونها) هستند که به صورت منزوی (ایزوله) فوقالعاده «هوشمند» (Intelligent) نیستند، اما هنگامی که با یکدیگر تعامل دارند هوشمند میشوند.




«جفری اورست هینتون» (Geoffrey Everest Hinton)، دانشمند علوم کامپیوتر متولد بریتانیا است که بیشتر به دلیل پژوهشهایی که در زمینه «شبکههای عصبی مصنوعی» (Artificial Neural Networks) انجام داده شهرت دارد، او در این رابطه میگوید: «من فکر میکنم مردم نیاز دارند بدانند که یادگیری عمیق انجام کارها را - در پشت صحنه - بسیار بهتر میسازد. یادگیری عمیق در حال حاضر در جستوجوهای گوگل و جستوجوی تصاویر مورد استفاده قرار میگیرد و به شما این امکان را میدهد که عبارتی مانند «آغوش» را جستوجو کنید.»
نورونها
مبنای اساسی شبکههای عصبی، «نورونهای مصنوعی» (artificial neurons) هستند که از نورونهای مغز انسان تقلید میکنند. این نورونها، واحدهای محاسباتی ساده و قدرتمند دارای سیگنالهای ورودی وزنداری محسوب میشوند که سیگنال خروجی را با استفاده از یک تابع فعالسازی تولید میکنند. نورونها در چندین لایه در شبکه عصبی منتشر میشوند.
شبکههای عصبی مصنوعی چگونه کار میکنند؟
یادگیری عمیق دربرگیرنده شبکههای عصبی مصنوعی است که روی شبکههایی مشابه با آنچه در مغز انسان وجود دارد مدل شدهاند.
با جابهجایی داده در این «مِش مصنوعی» (Artificial Mesh)، هر لایه یک جنبه از دادهها را پردازش، دورافتادگیها را فیلتر، موجودیتهای مشابه را علامتگذاری و خروجی نهایی را تولید میکند.

لایه ورودی
«لایه ورودی» (Input layer) شامل نورونهایی است که کاری به جز دریافت ورودیها و پاس دادن آنها به دیگر لایهها انجام نمیدهند. تعداد لایهها در لایه ورودی باید مساوی «خصیصهها» (attributes) یا «ویژگیهای» (features) موجود در «مجموعه داده» (dataset) باشد.
لایه خروجی
«لایه خروجی» (Output Layer)، ویژگی پیشبینی شده است، این لایه اساسا به نوع مدلی که ساخته میشود بستگی دارد.
لایه پنهان
در میان لایه ورودی و خروجی «لایههای پنهان» (Hidden Layers) بسته به نوع مدل قرار دارند. لایههای پنهان شامل گستره وسیعی از نورونها میشوند. نورونها در لایه پنهان، «تبدیلها» (transformations) را پیش از پاس دادن ورودیها روی آنها اعمال میکنند. با آموزش دیدن شبکه، وزنها به روز رسانی میشوند تا پیشبینتر باشند.

وزن نورونها
«شبکههای عصبی نظارت شده پیشخور» (Feedforward supervised neural networks) از جمله اولین و موفقترین الگوریتمهای یادگیری به شمار میآید. به این الگوریتم «شبکههای عمیق» (Deep Networks)، «پرسپترون چند لایه» (Multi-layer Perceptron | MLP) یا به صورت سادهتر «شبکههای عصبی» (Neural Networks) نیز گفته میشود و معماری متداول آن با یک لایه پنهان نمایش داده میشود. هر نورون با وزنی به نورون دیگر مرتبط میشود. شبکه، به منظور تولید یک مقدار خروجی، ورودی را با فعالسازی نورونها پردازش میکند. به این کار «مسیر رو به جلو» (Forward Pass) در شبکه گفته میشود.

تابع فعالسازی در یادگیری عمیق
«تابع فعالسازی» (Activation Function)، «مجموع ورودی وزندار» را به خروجی نورون نگاشت میکند. به این تابع، بدین دلیل تابع فعالسازی/انتقال (transfer function) گفته میشود که آغازی که در آن نورون فعال میشود را کنترل کرده و سیگنال خروجی را قدرت میبخشد.
به بیان ریاضی داریم:
تابعهای فعالسازی زیادی وجود دارد که در میان آنها «واحد خطی یکسوسازی شده» (Rectified Linear Unit | ReLU)، «تانژانت هذلولوی» (tanh) و «SoftPlus» از پر استفادهترینها هستند. «تقلبنامهای» (Cheat Sheet) برای توابع فعالسازی در زیر آمده است.

بازگشت به عقب
مقدار پیشبینی شده شبکه عصبی با خروجی مورد انتظار مقایسه میشود و مقدار خطا با استفاده از تابع محاسبه میشود. این خطا بعدا در کل شبکه، یک لایه در واحد زمان، به عقب بازگشت داده میشود و وزنها مطابق با مقداری که در خطا مشارکت داشتهاند به روز رسانی خواهند شد. این ریاضیات هوشمندانه «الگوریتم بازگشت به عقب» (Back-Propagation algorithm) نامیده میشود.

این فرآیند برای همه نمونهها در دادههای آموزش (training data) تکرار خواهد شد. یک دور به روز رسانی شبکه برای مجموعه داده آموزش، «epoch» نامیده میشود. یک شبکه ممکن است برای دهها، صدها یا هزاران epoch آموزش ببیند.

تابع هزینه و گرادیان کاهشی
«تابع هزینه» (Cost Function) سنجهای برای آن است که مشخص شود یک شکبه عصبی برای مجموعه آموزش داده شده و خروجی مورد انتظار «چقدر خوب» عمل کرده است. این تابع همچنین بستگی به خصیصههایی مانند «وزنها» و «سوگیریها» (biases) دارد.
تابع هزینه تک مقداری است و بردار نیست، زیرا این تابع برای میزان خوب بودن عملکرد شبکه عصبی به عنوان یک کل امتیازدهی میکند. با استفاده از الگوریتم بهینهسازی گرادیان کاهشی، وزنها به تدریج بعد از هر epoch افزایش پیدا میکنند.
تابع هزینه سازگار
به بیان ریاضیاتی، «مجموع مربعات خطاها» (Sum of Squared Errors | SSE)، به صورت زیر محاسبه میشود:
مقدار و جهت به روز رسانی وزن با برداشتن یک گام در جهت مخالف گرادیان هزینه محاسبه میشود:
که در آن Δw یک بردار شامل وزنهای به روز رسانی شده برای هر ضریب وزن w است که به صورت زیر محاسبه میشود:
گرادیان کاهشی تا هنگامی که مشتق به کمینه خطا برسد محاسبه میشود و هر گام با سراشیبیِ شیب تعیین میشود (گرادیان).

پرسپترون چند لایه (انتشار رو به جلو)
این کلاس از شبکهها شامل لایههای چندگانه از نورونها، معمولا به صورت «پیشخور» (feed-forward) است (به صورت رو به جلو حرکت میکند). هر نورون در یک لایه دارای اتصالاتی به نورونهای موجود در لایههای متعاقب است. در بسیاری از کاربردها، واحدهای این شبکهها یک تابع سیگموئید یا ReLU (تابع واحد خطی یکسوسازی شده | Rectified Linear Activation) را به عنوان یک تابع فعالسازی اعمال میکنند.

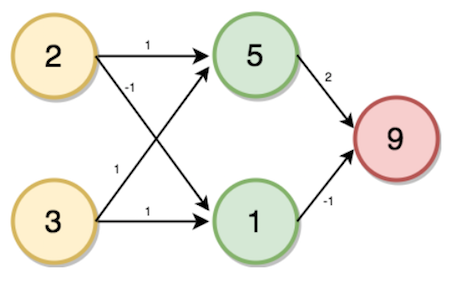
اکنون، مساله پیدا کردن تعداد تراکنشها برای حسابهای داده شده و اعضای خانواده به عنوان ورودی مفروض است. برای حل این مساله، ابتدا نیاز به آغاز کار با ساخت یک «شبکه عصبی انتشار رو به جلو» (forward propagation neural network) است. لایه ورودی تعداد اعضای خانواده و حسابها است. یک لایه پنهان وجود دارد و لایه خروجی تعداد تراکنشها محسوب میشود. وزنهای داده شده چنانکه در تصویر زیر نشان داده شده، لایه ورودی تا لایه پنهان با تعداد اعضای خانواده ۲ و ۳ حساب به عنوان ورودی است. اکنون، مقادیر لایه پنهان (i,j) و لایه خروجی (k) با استفاده از انتشار رو به جلو با انجام گامهایی که در ادامه آمده محاسبه میشوند.
فرآیند
- ضرب (فرآیند افزودن)
- ضرب داخلی (ورودیها × وزنها)
- انتشار پیشرو برای یک نقطه داده در هر زمان
- خروجی، پیشبینی برای آن نقطه داده در هر زمان است.

مقدار i از مقدار ورودی و وزنهای مربوط به نورون متصل محاسبه میشود.
i = (2 * 1) + (3 * 1)
→ i = 5
به طور مشابه داریم:
j = (2 * -1) + (3 * 1)
→ j = 1
K = (5 * 2) + (1 * -1)
→ k = 9

حل مساله پرسپترون چند لایه در پایتون
$python dl_multilayer_perceptron.py Enter the two values for input layers a = 3 b = 4 node 0_hidden: 7 node_1_hidden: 1 output layer : 13
استفاده از تابع فعالسازی
برای شبکه عصبی به منظور کسب بیشینه قدرت پیشبینی نیاز به اعمال یک تابع فعالسازی برای لایههای پنهان است. این تابع غیرخطی بودنها را ثبت میکند.
سپس، این موارد بر لایههای ورودی و لایههای پنهان با معادلاتی روی این مقادیر اعمال میشوند. در اینجا از تابع واحد یکسوسازی شده (ReLU) استفاده شده است.

$python dl_fp_activation.py Enter the two values for input layers a = 3 b = 4 44
توسعه اولین شبکه عصبی با Keras
«کِراس» (Keras) یک رابط برنامهنویسی نرمافزار کاربردی (Application Programming Interface | API) سطح بالای شبکه عصبی نوشته شده در پایتون و قادر به اجرا بر فراز کتابخانههای «تِنسورفلو» (TensorFlow) (+)، (جعبه ابزار شناختی مایکروسافت) (CNTK | Microsoft Cognitive Toolkit) (+) یا «ثینو» (Theano) (+) است.
برای نصب Keras روی دستگاه با استفاده از PIP، باید دستور زیر را اجرا کرد.
گامهایی برای پیادهسازی برنامه یادگیری عمیق در Keras
- بارگذاری دادهها
- تعریف کردن مدل
- کامپایل کردن مدل
- برازش (Fit) مدل
- ارزیابی مدل
- ترکیب کلیه گامها
توسعه مدل Keras ایجاد شده
لایههای کاملا متصل با استفاده از کلاس Dense تشریح شدند. میتوان تعداد نورونها را در لایه به عنوان اولین آرگومان، متد مقداردهی اولیه را به عنوان دومین آرگومان با عنوان init و تابع فعالسازی را با استفاده از آرگومان فعالسازی تعیین کرد. اکنون که مدل تعریف شد، میتوان آن را کامپایل کرد. کامپایل کردن مدل با استفاده از کتابخانههای موثر عددی تحت پوشش (که به آنها backend گفته میشود) مانند ثینو (Theano) یا تنسورفلو (TensorFlow) انجام میشود.
تا این لحظه مدل تعریف و مجموعه آن به منظور داشتن محاسبات موثر کامپایل شده است. اکنون زمان آن فرا رسیده تا مدل روی داده PIMA اجرا شود. میتوان مدل را بر مبنای دادهها با فراخوانی تابع ()fit آموزش و یا برازش داد. در ادامه، کد برنامه مذکور در KERAS آمده است.
$python keras_pima.py 768/768 [==============================] - 0s - loss: 0.6776 - acc: 0.6510 Epoch 2/150 768/768 [==============================] - 0s - loss: 0.6535 - acc: 0.6510 Epoch 3/150 768/768 [==============================] - 0s - loss: 0.6378 - acc: 0.6510 . . . . . Epoch 149/150 768/768 [==============================] - 0s - loss: 0.4666 - acc: 0.7786 Epoch 150/150 768/768 [==============================] - 0s - loss: 0.4634 - acc: 0.773432/768 [>.............................] - ETA: 0sacc: 77.73%
شبکه عصبی تا ۱۵۰ epoch آموزش داده میشود و مقدار صحیح را باز میگرداند.

اگر نوشته بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- گنجینه آموزشهای برنامه نویسی پایتون (Python)
- معرفی منابع آموزش ویدئویی هوش مصنوعی به زبان فارسی و انگلیس
^^







