شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
در آموزشهای قبلی مجله فرادرس، برخی از روشهای درونیابی مانند چندجملهای لاگرانژ و درونیابی اسپلاین را معرفی کردیم. در این آموزش، با روشی دیگر به نام «درون یابی هرمیت» (Hermite Interpolation) آشنا میشویم.
روش چندجملهای درونیاب هرمیت بسیار نزدیک به چندجملهای نیوتن است، بدین صورت که در هر دوی این روشها از تفاضلهای تقسیم شده استفاده میشود. البته چندجملهای درونیاب هرمیت را میتوان بدون استفاده از تفاضلهای تقسیم شده نیز محاسبه کرد. در این صورت از «قضیه باقیمانده چینی» (Chinese Remainder Theorem) استفاده میشود.
برخلاف درونیابی نیوتن، درون یابی هرمیت یک تابع را به n نقطه و تعداد m مشتق آنها تطبیق میدهد. این بدین معنی است که برخلاف درونیابی نیوتن که فقط به n مقدار اول نیاز دارد، تعداد n(m+1) مقدار زیر باید معلوم باشند:
چندجملهای به دست آمده ممکن است از درجه حداکثر n(m+1)−1 باشد، در حالی که حداکثر درجه چندجملهای نیوتن n−1 است. در حالت کلی، لازم نیست m یک مقدار ثابت باشد؛ یعنی تعدادی از نقاط ممکن است مشتقهای معلوم بیشتری نسبت به سایرین داشته باشند. در این حالت، چندجملهای منتجه ممکن است از درجه N−1 باشد که در آن، N تعداد نقاط نقاط دادهها است.
در ادامه، ابتدا یک حالت ساده را بررسی کرده، سپس درون یابی هرمیت را در حالت کلی مورد بررسی قرار میدهیم.
درون یابی هرمیت
اگر mمشتق اول تابع f(x) و نیز خود تابع در n+1 نقطه x0، x1، ... و xn معلوم باشند، یعنی یک مجموعه (n+1)(m+1)تایی از مقادیر yj(i)=f(i)(xj) داشته باشیم (j=0,...,n,i=0,...,m)، آنگاه میتوانیم یک چندجملهای درجه (n+1)(m+1)−1 را درونیابی کنیم:
ضرایب و جواب این دستگاه معادلات یکتا هستند. البته، این روش به دلیل پیچیدگی بالای محاسباتی O((mn)3) غیرعملی است.
در عمل، در این حالت، از درون یابی هرمیت میتوان استفاده کرد. ابتدا فرض میکنیم m=1 است و چندجملهای هرمیت را به عنوان یک ترکیب خطی از (n+1)(m+1)=2(n+1)چندجملهای اساسی یا پایه αi(x) و βi(x) از درجه 2n+1 نمایش میدهیم که در آن، i=0,...,n است:
H(x)=i=0∑nαi(x)f(xi)+i=0∑nβi(x)f′(xi)
برای آنکه H(x) در H(xj)=f(xj) و H′(xj)=f′(xj) برای j=0,...,n صدق کند، چندجملهایهای پایه باید در روابط زیر صدق کنند:
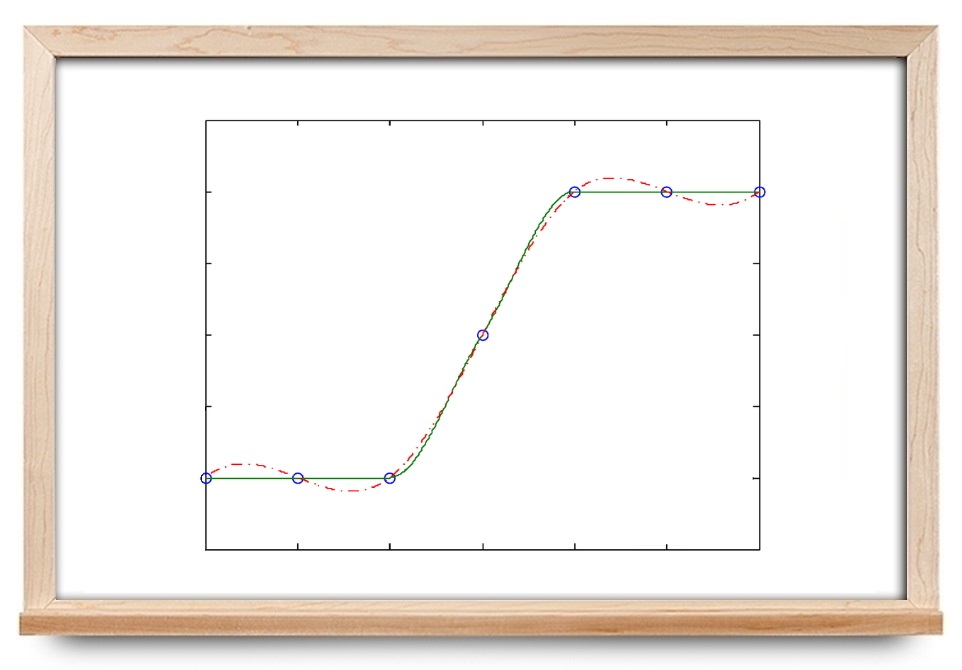
نتیجه درون یابی هرمیت تابع y=f(x)=xsin(2x+π/4)+1 در شکل زیر نشان داده شده است. همچنین، چندجملهایهای αi(x) و βi(x) برای i=0,...,3 رسم شدهاند. از آنجا که مشتق اول f′(xi) و مقدار تابع f(xi) در هر نقطه xi در دسترس هستند، میانیابی H(x) با تابع داده شده f(x) بسیار منطبق بوده (در شکل منطبق و یکسان هستند) و خطا ϵ=0.0040 است.
برنامه متلب مربوط به پیادهسازی روش درون یابی هرمیت به صورت زیر است:
در ادامه، حالتی را در نظر میگیریم که m>1 باشد. اکنون m+1 متغیر معلوم f(xi)، f′(xi)، ... و f(m)(xi) در هر یک از نقاط x0، ... و xn معلوم هستند. مطابق جدول زیر، مجموعه داده متغیر دیگر z را که شامل x0، ... و xn در هر m تکرار است، تعریف میکنیم:
با روش چندجملهای نیوتن میتوان تابع f(z) را با (n+1)(m+1) نقطه نمونه درونیابی کرد. برای مثال، اگر m=n=2 باشد، آنگاه چندجملهای درجه (2+1)(2+1)−1=8 را میتوان به صورت زیر به دست آورد:
میتوان تأیید کرد که در واقع، N8(i)(xj)=f(i)(xj) برای همه i=1,...,m و j=0,...,n برقرار است. مشابه روش چندجملهای نیوتن، ضرایب تفاضلهای تقسیم شده را میتوان به صورت بازگشتی به دست آورد (تنها با این تفاوت که m+1 تکرار در هر نقطه xi وجود دارد). تفاضل تقسیم شده به صورت زیر به دست میآید:
ضرایب تفاضل تقسیم شده در عبارت N8(x) بالا را میتوان به صورت بازگشتی در جدول زیر تولید کرد. این ضرایب، به عنوان عناصر قطری جدول نمایان میشوند.
مثال ۲
اکنون درون یابی هرمیت را برای تابع y=f(x)=xsin(2x+π/4)+1 انجام میدهیم. فرض میکنیم هر دو مشتق f′(xi) و f′′(xi) و نیز f(xi) در چهار نقطه در دسترس باشند. درون یابی هرمیت H(x) همراه با تابع f(x) در شکل زیر رسم شدهاند. همانطور که میبینیم، این دو بسیار شبیه هستند و خطای آنها ϵ=6.5×10−6 است.
کد متلب زیر، پیادهسازی این الگوریتم را نشان میدهد:
آرایه تفاضلهای تقسیم شده تولیدی با تابع DividedDifference2 در جدول زیر آورده شده است که در آن، درایههای قطری ضرایب چندجملهای هرمیت هستند.
مثال ۳
تابع f(x)=x8+1 را در نظر بگیرید. برای درون یابی هرمیت تابع و دو مشتق اول آن را در x∈{−1,0,1} محاسبه کرده و دادههای زیر را به دست میآوریم:
f′′(x)
f′(x)
f(x)
x
56
−8
2
−1
0
0
1
0
56
8
2
1
از آنجا که با دو مشتق سر و کار داریم، مجموعه {zi}={−1,−1,−1,0,0,0,1,1,1} را تشکیل میدهیم. جدول تفاضل تقسیم شده نیز به صورت زیر خواهد بود:
سید سراج حمیدی دانشآموخته مهندسی برق است و به ریاضیات و زبان و ادبیات فارسی علاقه دارد. او آموزشهای مهندسی برق، ریاضیات و ادبیات مجله فرادرس را مینویسد.
شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.























سلام ی سوال داشتم
چطور میتونیم ثابت کنیم که تعداد محاسبات درونیابی fft،
nlogn است؟