شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
در این مطلب، چگونگی انجام دسته بندی صدا با یادگیری عمیق بیان شده است. در این مقاله، ابتدا چشمانداز کلی پروژه ارائه و سپس، «مجموعه داده» (Data Set)، ابزارهای مورد استفاده و نتایج حاصل از انجام پروژه مورد بررسی قرار میگیرند. کلیه کدهای مورد استفاده برای این پروژه، در همین مطلب درج شدهاند.
دسته بندی صدا (+) با یادگیری عمیق و به طور خودکار، حوزهای در حال رشد با کاربردهای جهان واقعی متعدد است. در حالی که تحقیقات بسیار زیادی در زمینه فایلهای صوتی مانند صحبت کردن یا موسیقی انجام شده است، کار روی صدای محیط نسبتا نادر است.
به همین ترتیب، مشاهده پیشرفتهای اخیر در زمینه دستهبندی تصویر که در آن «شبکههای عصبی پیچشی» (Convolutional Neural Networks) برای دستهبندی تصاویر با صحت بالا مورد استفاده قرار میگیرند، این پرسش را به وجود میآورد که آیا این روشها در دیگر زمینهها مانند دستهبندی صوت نیز کاربرد دارند یا خیر. کاربردهای جهان واقعی زیادی برای آنچه در این مطلب آموزش داده میشود وجود دارد که در ادامه بیان شدهاند.
اندیسگذاری و بازیابی چند رسانهای مبتنی بر محتوا
کمک به ناشنوایان بریا انجام فعالیتهای روزمره
استفاده در کاربردهای خانههای هوشمند مانند امنیت ۳۶۰ درجه و قابلیتهای امنیتی
استفادههای صنعتی مانند نگهداری پیشبین
بیان مسأله
در ادامه، چگونگی اعمال روشهای یادگیری عمیق برای دستهبندی صداهای محیط، با تمرکز بر صداهای شهری خاص آموزش داده شده است. هنگامی که یک نمونه صوتی در فرمت قابل خواندن به وسیله کامپیوتر (مانند فایل wav.) با طول چند ثانیه داده میشود، هدف تشخیص محتویات آن بر اساس صداهای شهری، با امتیاز صحت دستهبندی متناظر است.
برای این مسئله، از یک مجموعه داده که Urbansound8K نامیده میشود، استفاده شده است. این مجموعه داده، حاوی ۸۷۳۲ فایل صوتی گزینش شده (کمتر از ۴ ثانیه) از صداهای شهری از ۱۰ کلاس است که عبارتند از:
تهویه کننده هوا
بوق ماشین
بازی کودکان
پارس سگ
حفاری
صدای موتور خودرو در حال سکون
شلیک تفنگ
جکامر (مته دستی)
آژیر
موسیقی خیابانی
نمونهای از این مجموعه داده به صورت قابل دانلود، از این مسیر [+] در دسترس است.
بررسی فایلهای صوتی
این گلچین صداها، فایلهای صوتی در فرمت wav. هستند. موجهای صدا با نمونهبرداری از آنها در بازههای گسسته که به آن نرخ نمونهبرداری (معمولا، نرخ نمونهبرداری برای فایلهای صوتی روی CD برابر با ۴۴/۱ KHz است، بدین معنا که ۴۴۱۰۰ بار در ثانیه نمونهها گرفته شدهاند) گفته میشود، دیجیتالی شدهاند.
هر نمونه، دامنه موج در یک بازه زمانی مشخص است که عمق بیت در آن، نشان میدهد که چه میزان جزئیات در نمونه وجود دارد؛ به این مورد، طیف پویای سیگنال نیز گفته میشود (معمولا ۱۶ بیت که به معنای آن است که یک نمونه طیفی بین ۶۵,۶۳۶ مقادیر دامنه است).
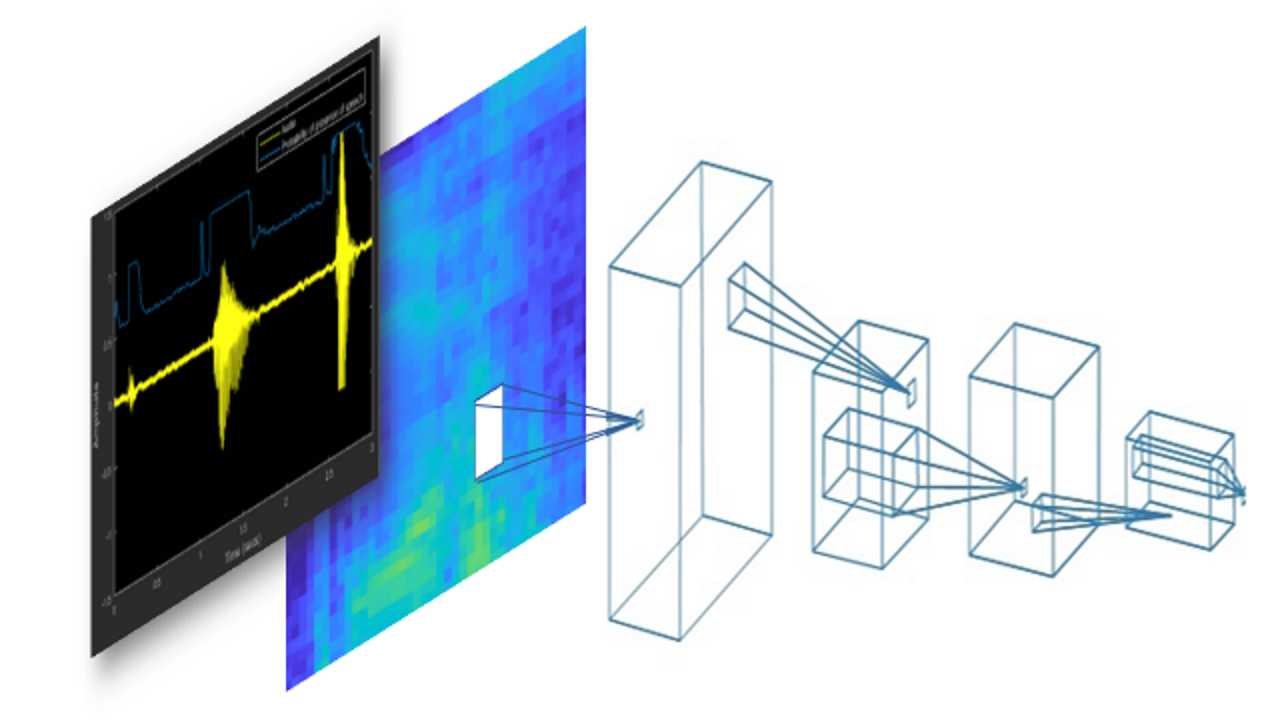
تصویر بالا نشان میدهد که چگونه یک قطعه صوت از شکل موج گرفته و به یک آرایه یک بُعدی یا بردار دامنه مقادیر تبدیل میشود.
اکتشاف داده
با یک بررسی بصری، میتوان مشاهده کرد که بصریسازی برخی از ویژگیها، کاری نیازمند کمی ترفند برای نمایش تفاوت برخی از کلاسها است. اساسا، شکل موج برای صداهای تکرار شونده برای تهویه کننده هوا، حفاری، موتور روشن خودرو در حال ثابت و جکامر دارای شکل مشابهی هستند.
سپس، بررسیهای عمیقتری برای استخراج برخی از خصوصیات فایلهای صوتی، شامل تعداد کانالهای صوتی، نرخ نمونهبرداری و عمیق بیت با استفاده از کد زیر انجام میشود.
در اینجا، میتوان مشاهده کرد که مجموعه داده دارای طیف وسیعی از خصوصیات صوتی متغیر است. همین امر موجب میشود تا پیش از استفاده از فایلها، نیاز به استانداردسازی آنها برای آموزش دادن مدل باشد.
کانالهای صوتی: اغلب نمونهها دارای دو کانال صوتی هستند (بدین معنا که استریو هستند) و برخی از فایلها تنها یک کانال دارند (مونو).
نرخ نمونهبرداری: طیف وسیعی از نرخ نمونهها وجود دارد که در سراسر نمونهها استفاده شده است (طیفی از ۹۶ کیلوهرتز تا ۸ کیلوهرتز).
عمق بیت: همچنین، طیفی از عمق بیت (عمق بیتی از ۴ بیت تا ۳۲ بیت) وجود دارد.
پیشپردازش دادهها
در بخش پیشین، ویژگیهای صوتی که در ادامه بیان شدهاند و نیاز به پیشپردازش دارند تا اطمینان حاصل شود که استحکام لازم را در کل مجموعه دارند یا خیر، مورد بررسی قرار گفتند.
«لیبروسا» (Librosa) یک بسته پایتون برای پردازش موسیقی و فایلهای صوتی است که توسط «بریان مکآفی» منتشر شده و به کاربر این امکان را میدهد تا فایلهای صوتی را در نوتبوک به عنوان آرایه «نامپای» (NumPy) برای تحلیل و دستکاری وارد کنند.
برای بخش عمده پیشپردازشها، امکان استفاده از تابع Librosa’s load() وجود دارد که به طور پیشفرض، نرخ نمونهبرداری را به 22.05 KHz تغییر میدهد، دادهها را نرمال میکند، بنابراین طیف مقادیر عمیق بیت بین ۱- و ۱ و کانالهای صوتی را به صورت مونو (Mono) مسطح میکند.
استخراج ویژگیها
گام بعدی، استخراج ویژگیهایی است که برای آموزش دادن مدل به آنها نیاز است. برای انجام این کار، یک ارائه بصری از هر نمونه صوتی ساخته میشود که به کاربر امکان شناسایی ویژگیها برای بصریسازی را با استفاده از روشهای مشابه مورد استفاده برای دستهبندی با صحت بالا فراهم میکند.
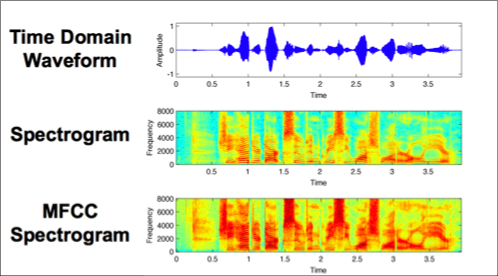
«طیفسنجها» (Spectrograms) روشهای مفیدی برای بصریسازی طیف فرکانسهای یک صدا و چگونگی تغییر آنها در طول یک بازه زمانی هستند. از روش مشابهی که با عنوان Mel-frequency cepstrum (سرنام آن MFCC است) شناخته شده است استفاده میشود.
تفاوت اصلی این دو آن است که طیفسنج از مقیاس فرکانس فضاگذاری شده خطی استفاده میکند (بنابراین، هر دسته فرکانس با مقدار هرتز یکسانی از هم جدا شدهاند)، در حالیکه MFCC از مقایس فرکانس شبه لگاریتمی استفاده میکند که بیشتر شبیه به سیستمی است که سیستم شنوایی انسان کار میکند.
تصویر زیر، سه ارائه بصری مختلف از موج صوتی را نشان میدهد که اولین آن ارائه دامنه زمانی است و نوسان را در طول زمان با یکدیگر مقایسه میکند. سپس، طیفسنجی است که نشان میدهد انرژی در باندهای فرکانسی مختلف در طول زمان تغییر میکند. در نهایت، یک MFCC را میتوان مشاهده کرد که بسیار شبیه به طیفسنج است، اما جزئیات قابل تمایز بیشتری دارد.
برای هر فایل صوتی در مجموعه داده، یک MFCC استخراج میشود (بدین معنا که یک ارائه تصویر برای هر نمونه صوتی وجود دارد) و در «دیتافریم» (Dataframe) کتابخانه «پانداس» (Pandas) با برچسبهای دستهبندی آن ارائه شدهاند. بدین منظور، از تابع Librosa’s mfcc استفاده کرد که MFCC را از دادههای صوتی سری زمانی تولید میکند.
تبدیل دادهها و برچسبها و سپس، تقسیم مجموعه داده
از sklearn.preprocessing.LabelEncoder برای رمزنگاری دادههای متنی دستهای به دادههای متنی قابل درک برای مدل استفاده شده است. سپس، از sklearn.model_selection.train_test_split برای تقسیم مجموعه داده به مجموعههای «تست» (Test) و «آموزش» (Train) استفاده میشود.
در اینجا، از مدل پی در پی استفاده شده است که با یک معماری مدل ساده که شامل چهار لایه پیچشی Conv2D است آغاز میشود و لایه نهایی خروجی یک لایه چگال خواهد بود. لایه خروجی، دارای ۱۰ گره است (num_labels) بدین معنا که با تعداد دستهبندیهای ممکن تطبیق دارد.
برای کامپایل کردن مدل، از سه پارامتر زیر استفاده میشود.
در اینجا، مدل آموزش داده میشود. با توجه به آنکه آموزش دادن یک مدل CCN ممکن است زمان زیادی ببرد، کار با تعداد کمی از «دورهها» (Epochs) و سایز دسته کم آغاز میشود. اگر در خروجیها مشاهده شد که مدل در حال همگرا شدن است، هر دو افزایش پیدا میکنند.
قطعه کد زیر، صحت مدل را روی دادههای تست و آموزش بررسی میکند.
نتایج
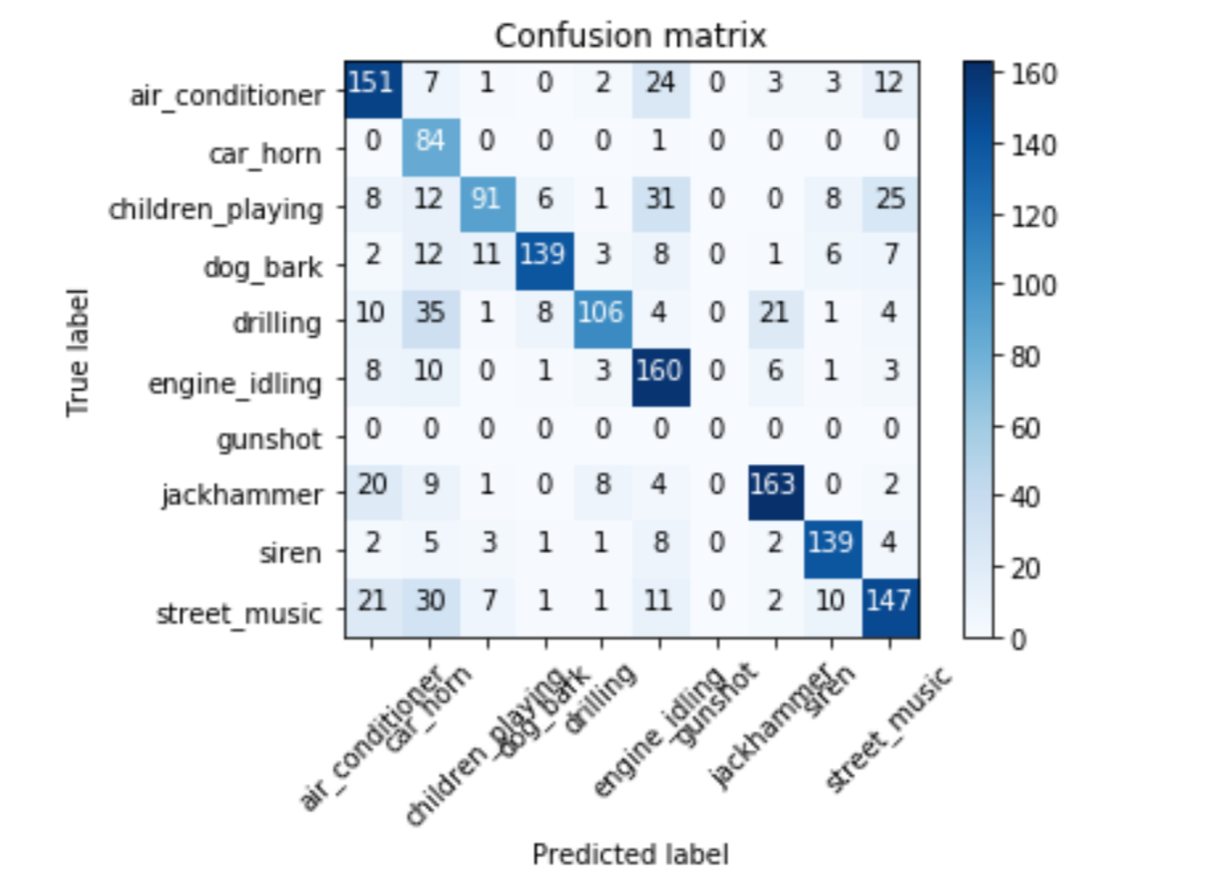
مدل آموزش دیده، صحت ٪98.19 و صحت تست ٪91.92 را به دست آورده است. کارایی بسیار خوب است و مدل به خوبی تعمیم پیدا کرده است و به نظر میرسد هنگامی که دادههای صوتی جدید روی آن تست میشوند، پیشبینی خوبی ارائه میکند.
ماتریس مجاورت اما چیز دیگری میگوید. در اینجا میتوان مشاهده کرد که مدل اغلب با زیرگروههای زیر در چالش بوده است.
تهویه هوا، جکامر، موسیقی خیابانی.
بوق ماشین، حفاری، موسیقی خیابانی
تهویه هوا، بازی کودکان و صدای موتور خودروی در حال کار در حالت سکون
تهویه هوا، بوق ماشین، بازی کودکان و موسیقی خیابانی
این نشان میدهد که این مسئله تفاوتهای جزئی با با ارزیابیهای اولیه انجام شده دارد و بینشی نسبت به ویژگیهایی که CNN برای انجام دستهبندی استخراج میکند، به دست میدهد. برای مثال، موسیقی خیابانی یکی از دستههایی است که اغلب به اشتباه دستهبندی شده و میتواند انواع گستردهای از نمونههای داخلی کلاس را داشته باشد.
گام بعدی
گام منطقی بعدی، مشاهده آن است که موارد بالا را چطور میتوان بر دادههای صوتی که به صورت بیدرنگ استریم میشوند و همچنین با استفاده از صداهای جهان واقعی، اعمال کرد.
صدا در جهان واقعی چالش آشفتهتری است؛ زیرا فرد نیاز به تطبیق صداهای پسزمینه گوناگون، سطح صداهای مختلف از صدای هدف و درستنمایی برای دورهها دارد.
انجام این کار در زمان واقعی، این چالش را نیز نشان میدهد که مدل باید با زمان تاخیر کم به خوبی محاسبات MFCC کار کند.
«الهام حصارکی»، فارغالتحصیل مقطع کارشناسی ارشد مهندسی فناوری اطلاعات، گرایش سیستمهای اطلاعات مدیریت است. او در زمینه هوش مصنوعی و دادهکاوی، به ویژه تحلیل شبکههای اجتماعی، فعالیت میکند.
شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.