



دسته بندی سبک های موسیقی با پایتون – راهنمای کاربردی
گوش فرا دادن به موسیقی یکی از فعالیتهای روزانه و مورد علاقه بسیاری از افراد است. ظهور پلتفرمهای «استریم» (Stream) موسیقی مانند «اسپاتیفای» (Spotify)، رنگ و بوی نویی به دنیای علاقمندان به موسیقی و به اشتراکگذاری آن بخشید. چنین سرویسهایی قابلیتها متعدد و جالب توجهی دارند که «دسته بندی سبک های موسیقی» یکی از آنها محسوب میشود. در این مطلب، به چگونگی دسته بندی سبک های موسیقی با پایتون پرداخته خواهد شد.




موسیقی همچون آینهای است که اطلاعات زیادی پیرامون شخصیت افراد (بر اساس نوع موسیقی که گوش میکنند، فارغ از اینکه آیا آن را دوست دارند یا نه) ارائه میکند. احتمالا بسیاری از افراد این جمله معروف اسپاتیفای (Spotify) را شنیدهاند که «شما همان چیزی هستید که استریم میکنید».
اسپاتیفای، با شبکهای که بالغ بر ۲۶ میلیارد دلار ارزش دارد در حال حاضر پلتفرم استریم موسیقی پیشرو محسوب میشود. این پلتفرم حاوی میلیونها آهنگ در پایگاه داده خود است و ادعا میکند که دارای یک امتیاز موسیقی صحیح (music score) برای هر شخص است.
سرویس «Spotify’s Discover Weekly» در حال حاضر محبوب یک نسل است. نیازی به گفتن نیست که Spotify سرمایهگذاریهای زیادی را در زمینه پژوهش برای بهبود روش یافتن و گوش دادن به موسیقی انجام داده است. «یادگیری ماشین» (Machine Learning) بخش اساسی پژوهشهای آنها است.
Spotify از «پردازش زبان طبیعی» (NLP | Natural Language Processing) گرفته تا «پالایش گروهی» (Collaborative Filtering) و «یادگیری عمیق» (Deep Learning) استفاده میکند. در سیستم دستهبندی موسیقی، آهنگها بر پایه امضای دیجیتال آنها که متشکل از فاکتورهایی مانند «گام» (tempo)، «آکوستیک» (acoustics)، «انرژی» (energy)، قابل رقص بودن و دیگر موارد است تحلیل میشوند.
اهداف
امروزه شرکتهایی مانند Spotify و Soundcloud از دستهبندی موسیقی برای ارائه پیشنهاد به مشتریان خود استفاده میکنند یا از این قابلیت برای ارائه یک محصول به مشتریان خود (برای مثال Shazam) بهره میبرند. روشهای یادگیری ماشین اثبات کردهاند که برای کاملا موفق بودن در استخراج الگوها از حجم انبوهی از دادهها استفاده میکنند.

اصول مشابهی در تحلیلهای موسیقی نیز اعمال میشود. در این مقاله، روش تحلیل سیگنالهای صوتی/تصویری در پایتون آموزش داده خواهد شد. سپس از آنچه آموزش داده شد برای دستهبندی کلیپهای صوتی در سبکهای گوناگون استفاده میشود.
پردازش صوت با پایتون
صدای ارائه شده به شکل یک سیگنال صوتی دارای پارامترهایی مانند «فرکانس» (Frequency)، «پهنای باند» (Bandwidth)، «دسیبل» (Decibel) و دیگر موارد است. یک سیگنال صوتی معمول را میتوان به عنوان تابعی از «دامنه» (Amplitude) و «زمان» (Time) تعریف کرد.
این صداها در فرمتهای گوناگونی موجود هستند و همین امر امکان خواندن و تحلیل آنها را برای کامپیوتر فراهم میکند. برخی از این فرمتها عبارتند از:
- فرمت mp3
- فرمت WMA (سرنامی برای Windows Media Audio)
- wav (یا Waveform Audio File)

کتابخانههای صوتی
پایتون دارای کتابخانههای خوبی برای پردازش صوت است که از این جمله میتوان به «لیبروسا» (Librosa) و «پایآدیو» (PyAudio) اشاره کرد. همچنین ماژولهای توکاری برای برخی از کارکردهای پایهای صوتی برای آن وجود دارد. در این مطلب از چندین کتابخانه برای «دریافت صوت» (acquisition) و «بازپخش» (playback) موسیقی استفاده میشود که هر یک در ادامه شرح داده شدهاند.
لیبروسا
«لیبروسا» (Librosa)، به طور کلی یک ماژول پایتون برای تحلیل سیگنالهای صوتی محسوب میشود که تمرکز آن بیشتر روی موسیقی است. این ماژول دارای قابلیتهایی برای ساخت سیستم «بازیابی اطلاعات موسیقی» (Music Information Retrieval | MIR) است. ماژول MIR به خوبی مستندسازی شده و دارای مثالها و راهنماییهای زیادی است.
نحوه نصب لیبروسا
برای بهرهمندی از قدرت «رمزگشایی صوتی» (دیکودینگ صوتی | audio-decoding) بیشتر، میتوان «ffmpeg» را نصب کرد که با «رمزگشاهای» (decoders | دیکودرهای) صوتی بسیاری همراه است.
IPython.display.Audio
IPython.display.Audio امکان بازپخش صوت را به طور مستقیم در «ژوپیتر نوتبوک» فراهم میکند.
نحوه بارگذاری یک فایل صوتی
قطعه کد بالا یک سری زمانی را به صورت آرایه «نامپای» (NumPy) با نرخ نمونهبرداری پیشفرض صدای «مونو» (Mono) یعنی 22KHZ باز میگرداند. این رفتار را میتوان با کد زیر تغییر داد:
قطعه کد بالا برای بازنمونهگیری در 44.1KHz است. برای غیر فعال کردن نمونهگیری میتوان کد زیر را وارد کرد.
نرخ نمونه تعداد نمونههای صوتی است که در ثانیه نگهداری میشوند که در Hz یا kHz اندازهگیری میشود.

پخش صوت
در ادامه از IPython.display.Audio برای پخش فایل صوتی استفاده میشود.
خروجی قطعه کد بالا، یک «ویجت» (widget) در «نوتبوک ژوپیتر» (Jupyter Notebook) به صورت زیر است.

این ویجت در اینجا کار نمیکند، ولی در نوتبوک آماده فعالیت است. اکنون، فایل صوتی مشابهی در SoundCloud بارگذاری میشود که میتوان با بهرهگیری از این لینک (+) به آن گوش سپرد. حتی میتوان از فرمت MP3 یا WMA برای مثالهای صوتی استفاده کرد.
بصریسازی صوتی
در ادامه به چگونگی بصریسازی سیگنالهای صوتی پرداخته خواهد شد.
Waveform
میتوان آرایه صوتی را با استفاده از librosa.display.waveplot ترسیم کرد.

در تصویر بالا، «پوشِ دامنه» (amplitude envelope) یک «شکل موج» (waveform) ترسیم شده است.
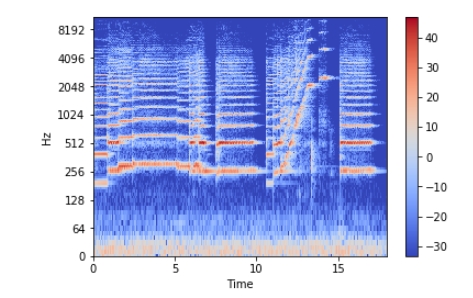
طیف نگار
«طیف نگار» (Spectrogram)، ارائهای بصری از طیف فرکانسهای صوتی یا دیگر سیگنالها در حالی است که با زمان تغییر میکنند. طیفنگار گاهی «سونوگراف» (sonograph)، «پرینت صدا» (voiceprint) و «صدانگار» (voicegram) نیز نامیده میشود.

هنگامی که دادهها در یک نمودار سهبُعدی نمایش داده میشوند، ممکن است نمودار «آبشاری» (waterfall) باشد. در آرایه دو بُعدی، محور اول فرکانس است، در حالیکه دومین محور زمان است. میتوان طیفنگار را با استفاده از librosa.display.specshow نشان داد.

محور عمودی فرکانس (از ۰ تا ۱۰ کیلوهرتز) و محور افقی زمان کلیپ را نشان میدهد. چنانکه مشهود است، همه «اعمال» (Actions) در پایین طیف نگار قرار میگیرند، بنابراین میتوان محور فرکانس را به محور لگاریتمی مبدل کرد.

نوشتن صوت
librosa.output.write_wav یک آرایه NumPy را به صورت فایل WAV ذخیره میکند.
ساخت یک سیگنال صوتی
اکنون باید یک سیگنال صوتی 220 هرتز ساخت. یک سیگنال صوتی یک آرایه numpy است، بنابراین ابتدا باید یک آرایه ساخت و سپس آن را به تابع صوتی پاس داد.
بنابراین، در این وهله اولین سیگنال صوتی (+) ساخته شد.
استخراج ویژگی
هر سیگنال صوتی شامل ویژگیهای بسیاری است. با این وجود، باید مشخصههایی که به مسالهای که هدف حل کردن آن است مرتبط هستند را استخراج کرد. فرآیند استخراج ویژگی برای استفاده از آنها در تحلیلها، استخراج ویژگی نامیده میشود. اکنون برخی از ویژگیهای سیگنالهای صوتی همراه با جزئیات مورد بررسی قرار میگیرد.
Zero Crossing Rate
zero crossing rate نرخ تغییر علامتها در طول یک سیگنال و در واقع نرخی است که در آن سیگنال از مثبت به منفی یا بالعکس تغییر میکند. این ویژگی به طور سنگین هم در «بازشناسی گفتار» (Speech Recognition) و هم در «بازیابی اطلاعات موسیقی» (Music Information Retrieval) مورد استفاده قرار میگیرد. ویژگی مذکور معمولا دارای مقداری بیشتر برای صداهای بسیار کوبهای است، مانند آنچه در موسیقی «متال» (metal) و «راک» (rock) وجود دارد. اکنون، zero crossing rate برای کلیپ صوتی مثال زده شده محاسبه میشود.


در این فایل صوتی 6 zero crossing وجود دارد. اکنون با استفاده از librosa اعتبارسنجی میشوند.
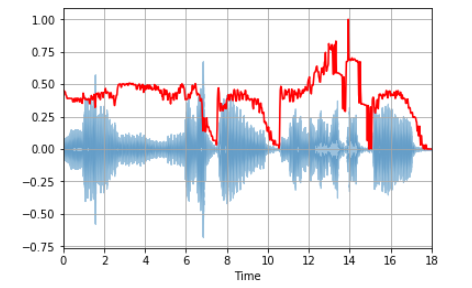
Spectral Centroid
این ویژگی نشان میدهد که centre of mass برای یک صدا در کجا قرار گرفته و به عنوان میانگین وزنی برای فرکانسهای موجود در صدا محاسبه میشود. اکنون، دو آهنگ در نظر گرفته میشوند، یکی از سبک «بلوز» (blues) و دیگری از سبک «متال» (metal) است.
در مقایسه با سبک موسیقی بلوز که در سراسر طولش یکسان است، موسیقی متال فرکانسهای بیشتری تا پایان دارد. بنابراین، «مرکزوار طیفی» (Spectral Centroid) برای موسیقی بلوز جایی نزدیک اواسط طیف آن است، در حالیکه برای موسیقی متال در انتهای آن قرار دارد. librosa.feature.spectral_centroid مرکزوار طیفی برای هر فریم در سیگنال را محاسبه میکند.

چنانچه در تصویر بالا مشهود است، رشدی در مرکزوار طیفی تا پایان وجود دارد.
Spectral Rolloff
این ویژگی اندازهای از شکل سیگنال است و فرکانسی زیر درصد معین شده از کل انرژی طیفی را نشان میدهد، برای مثال ۸۵٪. librosa.feature.spectral_rolloff فرکانس rolloff را برای هر فریم در یک سیگنال محاسبه میکند:

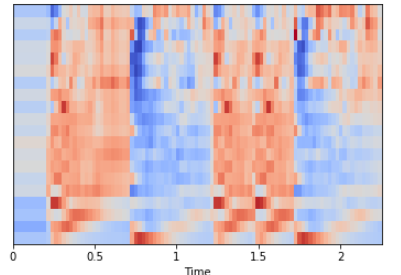
Mel-Frequency Cepstral Coefficients
(Mel frequency cepstral coefficients (MFCCs از یک سیگنال، مجموعهای کوچک از ویژگیها (معمولا حدود ۱۰ الی ۲۰) است که به طور خلاصه شکل کلی یک طیف را توصیف میکند. این ویژگی مشخصههای صدای انسانی را مدل میکند. در ادامه با یک موج حلقه ساده کار میشود.

librosa.feature.mfcc مقدار MFCC را در طول یک سیگنال صوتی محاسبه میکند.

در اینجا mfcc برابر با 20 MFCC در طول ۹۷ فریم محاسبه شده است. همچنین میتوان مقیاسدهی ویژگیها را به گونهای انجام داد که هر «بُعد ضریب» (coefficient dimension) دارای میانگین صفر و واریانس واحد باشد.

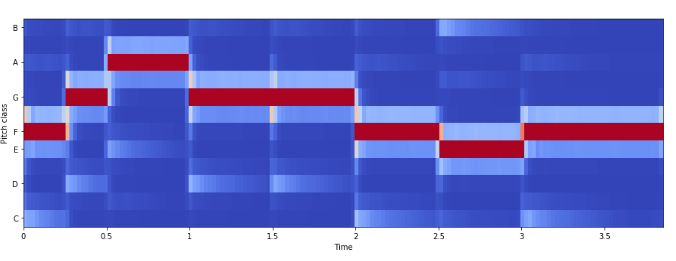
Chroma Frequencies
ویژگی Chroma Frequencies ارائهای قدرتمند و جالب توجه برای صدای موسیقی است که در آن کل طیف در ۱۲ «Bin» طرحریزی شده که نشانگر ۱۲ «نیمگام» (semitones) یا «کروما» (chroma) از اُکتاوهای موسیقی است.
librosa.feature.chroma_stft برای محاسبات مورد استفاده قرار میگیرد.

بررسی موردی: دستهبندی آهنگها به سبکهای گوناگون
پس از آنکه چشماندازی از سیگنالهای صوتی، ویژگیها و فرآیند استخراج ویژگی از آنها ایجاد شد، اکنون زمان آن رسیده که از مهارت جدید کسب شده برای حل یک مساله یادگیری ماشین استفاده شود.
هدف
در این بخش، سعی میشود تا «دستهبندی» (classifier) مدل شود که آهنگها را در سبکهای گوناگون دستهبندی کند. سناریویی فرض میشود که در آن، به دلایلی، دستهای از فایلهای MP3 که به طور تصادفی نامگذاری شدهاند روی دیسک سخت وجود دارند و فرض میشود حاوی موسیقی هستند. هدف، مرتبسازی این فایلها بر اساس سبک موسیقیشان در پوشههای مختلف مانند «جاز» (jazz)، «کلاسیک» (classical)، «کانتری» (country)، «پاپ» (rock»، (pop» (راک) و «متال» (metal) است.
مجموعه داده
از مجموعه داده محبوب «GITZAN» (+) برای این بررسی موردی استفاده میشود. این مجموعه داده در مقاله شناخته شده «دستهبندی سبک» (genre classification) با عنوان «دستهبندی سبکهای موسیقی از سیگنالهای صوتی» (Musical genre classification of audio signals) (+) که توسط «جی زنتکیس» (G. Tzanetakis) و «پی کوک» (P. Cook) در «IEEE Transactions on Audio and Speech Processing 2002» منتشر شد، مورد استفاده قرار گرفته است.
مجموعه داده مذکور شامل ۱۰۰۰ فایل صوتی است که هر یک ۳۰ ثانیه طول میکشند. همچنین، دربرگیرنده ۱۰ سبک موسیقی شامل «بلوز» (blues)، «کلاسیک» (classical)، «کانتری» (country)، «دیسکو» (disco)، «هیپهاپ» (hiphop)، «جاز» (jazz)، «رِگی» (reggae)، «راک» (rock)، «متال» (metal) و «پاپ» (pop) است. هر سبک شامل ۱۰۰ کلیپ صوتی میشود.
پیشپردازش دادهها
پیش از آموزش دادن مدل طبقهبندی، باید دادههای خام را از نمونههای صوتی به آرايهای معنادارتر مبدل کرد. کلیپهای صوتی نیاز به تبدیل شدن از فرمت au. به wav. برای سازگار شدن با ماژول wave پایتون برای خواندن فایلهای صوتی دارند. در اینجا از ماژول متنباز SoX برای تبدیل استفاده شده است.
دستهبندی
- انتخاب ویژگیها
اکنون، نیاز به استخراج اطلاعات معنادار از فایلهای صوتی وجود دارد. برای دستهبندی کلیپهای صوتی، ۵ ویژگی انتخاب خواهد شد که عبارتند از Mel-Frequency Cepstral Coefficients، مرکزوار طیفی، Zero Crossing Rate، فرکانس کروم و Roll-off طیفی. سپس، همه ویژگیها به یک فایل csv. الحاق میشوند، بدین شکل الگوریتم دستهبندی قابل استفاده میشود.
- دستهبندی
هنگامی که ویژگیها استخراج شدند، میتوان از الگوریتمهای دستهبندی موجود برای دستهبندی آهنگها در سبکهای مختلف استفاده کرد. همچنین، میتوان از تصاویر طیفنگار به طور مستقیم برای دستهبندی یا استخراج ویژگیها بهره برد و از مدلهای دستهبندی روی آنها استفاده کرد.
به طور کلی، آزمایشهای زیادی از جهت مدلها قابل انجام است. کاربر در انجام این آزمایشها و بهبود نتایج خود میتواند آزادانه عمل کند. با استفاده از یک مدل «شبکه عصبی پیچشی» (Convolutional Neural Network | CNN) (روی تصاویر طیفنگارها) صحت بهتری را فراهم کرده و ارزش امتحان کردن را دارد. در ادامه، کد لازم برای انجام این کار ارائه شده است.
ایمپورت کردن کتابخانهها
استخراج موسیقی و ویژگیها
از مجموعه داده سبکهای «GTZAN» برای دستهبندی استفاده شده است. این مجموعه داده شامل ۱۰ سبک موسیقی به شرح زیر هستند:
- بلوز
- کلاسیک
- کانتری
- دیسکو
- هیپهاپ
- جاز
- منال
- پاپ
- رگی
- راک
هر سبک شامل ۱۰۰ آهنگ است و کل مجموعه داده دارای ۱۰۰۰ آهنگ میشود.
استخراج طیفنگار برای هر آهنگ
همه فایلهای صوتی به طیفنگارهای مربوط به آنها تبدیل شدند. استخراج ویژگیها از این دادهها کار سادهای نیست.
- استخراج ویژگی از طیفنگار
در اینجا، ویژگیهای زیر از طیفنگار استخراج میشوند.
Mel-frequency cepstral coefficients (یا MFCC) (به تعداد ۲۰)
- مرکزوار طیفی
- Zero Crossing Rate
- فرکانس کروم
- Roll-off طیفی
نوشتن دادهها در فایل CSV
دادهها باید روی یک فایل CSV نوشته شوند.
دادهها اکنون به صورت یک فایل data.csv استخراج شدند.
تحلیل داده در Pandas
(1000, 28)
رمزنگاری برچسبها
مقیاسدهی ستون ویژگیها
تقسیم دادهها در مجموعههای آموزش و آزمون
800
200
array([-0.9149113 , 0.18294103, -1.10587131, -1.3875197 , -1.14640873, -0.97232926, -0.29174214, 1.20078936, -0.68458101, -0.55849017, -1.27056582, -0.88176926, -0.74844069, -0.40970382, 0.49685952, -1.12666045, 0.59501437, -0.39783853, 0.29327275, -0.72916871, 0.63015786, -0.91149976, 0.7743942 , -0.64790051, 0.42229852, -1.01449461])
دستهبندی با Keras
در ادامه کدهای مربوط به دستهبندی سبکهای موسیقی با Keras شامل ساخت شبکه و اعتبارسنجی آورده شده است.
ساخت شبکه
Epoch 1/20 800/800 [==============================] - 1s 811us/step - loss: 2.1289 - acc: 0.2400 Epoch 2/20 800/800 [==============================] - 0s 39us/step - loss: 1.7940 - acc: 0.4088 Epoch 3/20 800/800 [==============================] - 0s 37us/step - loss: 1.5437 - acc: 0.4450 Epoch 4/20 800/800 [==============================] - 0s 38us/step - loss: 1.3584 - acc: 0.5413 Epoch 5/20 800/800 [==============================] - 0s 38us/step - loss: 1.2220 - acc: 0.5750 Epoch 6/20 800/800 [==============================] - 0s 41us/step - loss: 1.1187 - acc: 0.6288 Epoch 7/20 800/800 [==============================] - 0s 37us/step - loss: 1.0326 - acc: 0.6550 Epoch 8/20 800/800 [==============================] - 0s 44us/step - loss: 0.9631 - acc: 0.6713 Epoch 9/20 800/800 [==============================] - 0s 47us/step - loss: 0.9143 - acc: 0.6913 Epoch 10/20 800/800 [==============================] - 0s 37us/step - loss: 0.8630 - acc: 0.7125 Epoch 11/20 800/800 [==============================] - 0s 36us/step - loss: 0.8095 - acc: 0.7263 Epoch 12/20 800/800 [==============================] - 0s 37us/step - loss: 0.7728 - acc: 0.7700 Epoch 13/20 800/800 [==============================] - 0s 36us/step - loss: 0.7433 - acc: 0.7563 Epoch 14/20 800/800 [==============================] - 0s 45us/step - loss: 0.7066 - acc: 0.7825 Epoch 15/20 800/800 [==============================] - 0s 43us/step - loss: 0.6718 - acc: 0.7787 Epoch 16/20 800/800 [==============================] - 0s 36us/step - loss: 0.6601 - acc: 0.7913 Epoch 17/20 800/800 [==============================] - 0s 36us/step - loss: 0.6242 - acc: 0.7963 Epoch 18/20 800/800 [==============================] - 0s 44us/step - loss: 0.5994 - acc: 0.8038 Epoch 19/20 800/800 [==============================] - 0s 42us/step - loss: 0.5715 - acc: 0.8125 Epoch 20/20 800/800 [==============================] - 0s 39us/step - loss: 0.5437 - acc: 0.8250
200/200 [==============================] - 0s 244us/step
test_acc: 0.68
«صحت» (accuracy) دادههای «آزمون» (Test) کمتر از دادههای «آموزش» (Train) است. این امر نشانهای از «بیشبرازش» (Overfitting) است.
اعتبارسنجی رویکرد
اکنون، ۲۰۰ نمونه در دادههای آموزش برای استفاده به عنوان مجموعه اعتبارسنجی، جدا میشود.
در حال حاضر، شبکه برای ۲۰ «دوره» (epoch) آموزش داده میشود.
Train on 600 samples, validate on 200 samples Epoch 1/30 600/600 [==============================] - 1s 1ms/step - loss: 2.3074 - acc: 0.0950 - val_loss: 2.1857 - val_acc: 0.2850 Epoch 2/30 600/600 [==============================] - 0s 65us/step - loss: 2.1126 - acc: 0.3783 - val_loss: 2.0936 - val_acc: 0.2400 Epoch 3/30 600/600 [==============================] - 0s 59us/step - loss: 1.9535 - acc: 0.3633 - val_loss: 1.9966 - val_acc: 0.2600 Epoch 4/30 600/600 [==============================] - 0s 58us/step - loss: 1.8082 - acc: 0.3833 - val_loss: 1.8713 - val_acc: 0.3250 Epoch 5/30 600/600 [==============================] - 0s 59us/step - loss: 1.6663 - acc: 0.4083 - val_loss: 1.7302 - val_acc: 0.3450 Epoch 6/30 600/600 [==============================] - 0s 52us/step - loss: 1.5329 - acc: 0.4550 - val_loss: 1.6233 - val_acc: 0.3700 Epoch 7/30 600/600 [==============================] - 0s 62us/step - loss: 1.4236 - acc: 0.4850 - val_loss: 1.5402 - val_acc: 0.3950 Epoch 8/30 600/600 [==============================] - 0s 57us/step - loss: 1.3250 - acc: 0.5117 - val_loss: 1.4655 - val_acc: 0.3800 Epoch 9/30 600/600 [==============================] - 0s 52us/step - loss: 1.2338 - acc: 0.5633 - val_loss: 1.3927 - val_acc: 0.4650 Epoch 10/30 600/600 [==============================] - 0s 61us/step - loss: 1.1577 - acc: 0.5983 - val_loss: 1.3338 - val_acc: 0.5500 Epoch 11/30 600/600 [==============================] - 0s 64us/step - loss: 1.0981 - acc: 0.6317 - val_loss: 1.3111 - val_acc: 0.5550 Epoch 12/30 600/600 [==============================] - 0s 52us/step - loss: 1.0529 - acc: 0.6517 - val_loss: 1.2696 - val_acc: 0.5400 Epoch 13/30 600/600 [==============================] - 0s 52us/step - loss: 0.9994 - acc: 0.6567 - val_loss: 1.2480 - val_acc: 0.5400 Epoch 14/30 600/600 [==============================] - 0s 65us/step - loss: 0.9673 - acc: 0.6633 - val_loss: 1.2384 - val_acc: 0.5700 Epoch 15/30 600/600 [==============================] - 0s 58us/step - loss: 0.9286 - acc: 0.6633 - val_loss: 1.1953 - val_acc: 0.5800 Epoch 16/30 600/600 [==============================] - 0s 59us/step - loss: 0.8849 - acc: 0.6783 - val_loss: 1.2000 - val_acc: 0.5550 Epoch 17/30 600/600 [==============================] - 0s 61us/step - loss: 0.8621 - acc: 0.6850 - val_loss: 1.1743 - val_acc: 0.5850 Epoch 18/30 600/600 [==============================] - 0s 61us/step - loss: 0.8195 - acc: 0.7150 - val_loss: 1.1609 - val_acc: 0.5750 Epoch 19/30 600/600 [==============================] - 0s 62us/step - loss: 0.7976 - acc: 0.7283 - val_loss: 1.1238 - val_acc: 0.6150 Epoch 20/30 600/600 [==============================] - 0s 63us/step - loss: 0.7660 - acc: 0.7650 - val_loss: 1.1604 - val_acc: 0.5850 Epoch 21/30 600/600 [==============================] - 0s 65us/step - loss: 0.7465 - acc: 0.7650 - val_loss: 1.1888 - val_acc: 0.5700 Epoch 22/30 600/600 [==============================] - 0s 65us/step - loss: 0.7099 - acc: 0.7517 - val_loss: 1.1563 - val_acc: 0.6050 Epoch 23/30 600/600 [==============================] - 0s 68us/step - loss: 0.6857 - acc: 0.7683 - val_loss: 1.0900 - val_acc: 0.6200 Epoch 24/30 600/600 [==============================] - 0s 67us/step - loss: 0.6597 - acc: 0.7850 - val_loss: 1.0872 - val_acc: 0.6300 Epoch 25/30 600/600 [==============================] - 0s 67us/step - loss: 0.6377 - acc: 0.7967 - val_loss: 1.1148 - val_acc: 0.6200 Epoch 26/30 600/600 [==============================] - 0s 64us/step - loss: 0.6070 - acc: 0.8200 - val_loss: 1.1397 - val_acc: 0.6150 Epoch 27/30 600/600 [==============================] - 0s 66us/step - loss: 0.5991 - acc: 0.8167 - val_loss: 1.1255 - val_acc: 0.6300 Epoch 28/30 600/600 [==============================] - 0s 62us/step - loss: 0.5656 - acc: 0.8333 - val_loss: 1.0955 - val_acc: 0.6350 Epoch 29/30 600/600 [==============================] - 0s 66us/step - loss: 0.5513 - acc: 0.8300 - val_loss: 1.1030 - val_acc: 0.6050 Epoch 30/30 600/600 [==============================] - 0s 56us/step - loss: 0.5498 - acc: 0.8233 - val_loss: 1.0869 - val_acc: 0.6250 200/200 [==============================] - 0s 65us/step
[1.2261371064186095, 0.65]
پیشبینی روی دادههای تست
(10,)
1.0
8
گام بعدی
دستهبندی سبکهای موسیقی یکی از شاخههای متعدد «بازیابی اطلاعات موسیقی» است. بدین شکل میتوان فعالیتهای دیگری را روی دادههای موسیقی مانند beat tracking، تولید موسیقی، «سیستمهای توصیهگر» (Recommender Systems)، جداسازی ترکهای صوتی و تشخیص آلت موسیقی انجام داد.

تحلیل موسیقی زمینهای متنوع و جذاب است. یک لحظه گوش دادن به یک موسیقی نشاندهنده یک لحظه کاربر است. پیدا کردن این لحظهها و توصیف آنها چالشی مهیج در زمینه «علم داده» (Data Science) است.
اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای تصویر و پردازش سیگنال
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای برنامهنویسی پایتون
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- آموزش برنامهنویسی R و نرمافزار R Studio
^^








