



فرا تحلیل و کاربردهای آن – از صفر تا صد
فرا تحلیل (Meta Analysis) یک روش تجزیه و تحلیل آماری است که از ترکیب نتایج متعدد آنالیزهای آماری حاصل میشود. مطالعات علمی با روش فرا تحلیل زمانی انجام میشود که چندین مطالعه علمی وجود داشته که همگی برحسب یک هدف یا بررسی وجود یک اثر (تیمار) صورت گرفته شده و بخواهیم نتایج و همچنین خطای آنها را با یکدیگر مقایسه و نتیجه جدید به عنوان برآیند نتایج قدیم، حاصل نماییم. در هر یک از روشهای تحلیلی، میزان خطای مشخصی توسط محقق گزارش شده است. در فرا تحلیل قرار است به کمک نتایج بدست آمده، خطای مورد مطالعه کاهش یافته و ترکیبی از همه تحقیقها حاصل شود. به همین علت این نوشتار را به موضوع فرا تحلیل و کاربردهای آن اختصاص دادهایم تا بهترین و کم خطاترین نتیجه ممکن حاصل شود.


برای آشنایی بیشتر با مفاهیم به کار رفته در این نوشتار بهتر است ابتدا نوشتارهای روش تحقیق چیست، روش تحقیق و اصول آماری — به زبان ساده و آشنایی با مقدمات آمار و کاربردهای آن — از صفر تا صد را مطالعه کنید. همچنین خواندن مطالب تعیین حجم نمونه در تحلیل های آماری — به زبان ساده و جامعه آماری — انواع داده و مقیاسهای آنها نیز خالی از لطف نیست.
فرا تحلیل و کاربردهای آن
در هر یک از تحقیقها و مطالعات فردی وجود خطا با توجه به نمونهگیری از جامعه آماری،دور از انتظار نیست. منشا این خطاها میتواند روشهای اندازهگیری، خطای نمونهگیری، عدم لحاظ شرطهای اولیه برای تحلیل و غیره باشد.
به این ترتیب در فرا تحلیل، به کمک روشهای آماری، سعی میشود که یک برآوردگر آمیخته از نتایج و مطالعات قبلی برای پارامترهای ناشناخته جامعه، استخراج و با حفظ خطای کل (یا کمتر از خطای مطالعات قبلی) ارائه شود. البته توجه داشته باشید که همه تحقیقاتی انفرادی باید در یک حوزه و براساس پارامتر یکسانی انجام شده باشند، در غیر اینصورت از آنها نباید در فرا تحلیل استفاده شود.
روشهای موجود برای فرا تحلیل، عملکردی شبیه محاسبه «میانگین وزنی» (Weighed Mean) دارند. به این معنی که نتایج حاصل از مطالعات فردی را مبنا قرار داده و از آنها یک میانگینگیری صورت میگیرد. تفاوت در روشهای فرا تحلیل، نحوه اختصاص وزنها یا میزان اهمیت هر یک از تحقیقات فردی در برآورد نهایی است.
علاوه بر ارائه تخمین مناسب و قابل قبول از پارامتر جامعه آماری، فرا تحلیل، توانایی پیدا کردن تضاد در نتایج حاصل از مطالعات مختلف و شناسایی الگوهایی در بین آنها به همراه کشف منشاء اختلافات را دارد. به همین منظور فرا تحلیل به عنوان ابزاری مناسب برای تلفیق و شناسایی تفاوتهای زمینههای مطالعاتی مختلف به کار میرود.
فواید اصلی این رویکرد، تجمیع اطلاعاتی است که منجر به ایجاد توان آماری بیشتر نسبت به مطالعات فردی میشود که برای تخمین نقطهای پارامتر جامعه صورت میگیرد.
با این حال، در انجام فرا تحلیل، یک محقق باید انتخابهایی را انجام دهد که میتواند بر نتایج آن تأثیر بگذارد. از جمله این موارد میتوان به فهرست زیر اشاره کرد.
- تصمیمگیری در مورد نحوه جستجوی مطالعات فردی
- تعیین تعداد و شیوه انتخاب آنها
- برخورد با دادههای ناقص (Incomplete Data) یا گمشده (Missing Data)
- بررسی روش تجزیه و تحلیل دادهها و توجه به گرایشات نسبت به انتشار یک مطالعه خاص
این عناوین را میتوان از مسائلی و موضوعاتی دانست که باید محقق در فرا تحلیل در نظر بگیرید. فرا تحلیلها اغلب، از مؤلفههای مهم یک روش بررسی منظم محسوب میشود. به عنوان مثال، ممکن است یک فرا تحلیل در چندین کارآزمایی بالینی یک معالجه پزشکی انجام شده تا به منظور درک بهتر چگونگی عملکرد درمان کمک کند.
«سازمان کاکران» (Cochran Collaboration) تعریف جالبی از فرا تحلیل ارائه کرده است، بطوری که فرا تحلیل را مرتبط با روشهای آماری میداند که شواهد را با یکدیگر ترکیب کرده و به صورت یک روش مطالعاتی سیستماتیک و کلی، نتایج جدیدی ایجاد میکند. البته در زمان ترکیب تحقیقها مورد استفاده، از تلفیق دادهها، تلفیق روشها و تلفیق خطاها نیز استفاده میشود.

ریشههای تاریخی فرا تحلیل را میتوان در مطالعات قرن 17 میلادی یافت ولی مقالهای که در سال 1904 توسط «کارل پیرسون» (Karl Pearson)، آمارشناس بزرگ انگلیسی در «مجله پزشکی بریتانیا» (British Medical Journal) منتشر شد که جمع آوری دادههای مربوط به چندین مطالعه از بیماری حصبه است. در این مقاله برای اولین بار است که از یک رویکرد فرا- تحلیلی برای تجمیع نتایج مطالعات بالینی مختلف استفاده شده است.
اولین فرا تحلیل از همه آزمایشهای و تحقیقات با موضوع یکسان، توسط محققان مستقل انجام شده است که تحت عنوان کتابی با نام «ادراک خارج از حس پس از ۶۰ سال» (Extrasensory Perception After Sixty Years) در دانشگاه دوک (Duke University) توسط استادان روانشناسی آن دانشگاه تالیف شد.
«جی جی پرات» (J. G. Pratt) و « جی بی راین» (J. B. Rhine) و همکارانشان مطالعات جامعی روی 145 گزارش در مورد آزمایشهای حس ششم (Extrasensory Perception) یا ESP انجام دادند که در بازه سالهای 1882 تا 1939 منتشر شده بودند که البته شامل یک تخمین از تأثیر مقالات منتشر نشده برای نتایج مطالعات نیز میشد.
اگر چه امروزه، تجزیه و تحلیل بطور گسترده ای در اپیدمیولوژی و پزشکی مبتنی بر شواهد و مطالعاتی موردی یا نمونهای به کار میرود ولی تا سال ۱۹۵۵ کاری صورت نگرفت.
در سال ۱۹۷۰ روشهای تحلیلی پیچیدهتر با شروع کارهای «جن وی. گلاس» (Gene V. Glass)، «فرانک ال. اشمیت» (Frank L. Schimidt) و «جان ای. هانتر» (John E. Hunter) مورد توجه قرا گرفت. اصطلاح "فرا تحلیل" در سال 1976 توسط آمارشناس آمریکای :جن وی. گلاس» ابداع شد. او در مقالهای که در این سال منتشر کرد نوشته است:
علاقه اصلی من در حال حاضر مربوط به چیزی است که ما به آن تحقیق فرا تحلیل میگوییم. هر چند این اصطلاح دارای مفهوم وسیعی است، اما دقیق و مناسب است. فرا تحلیل به تجزیه و تحلیل تحلیل ها اشاره دارد.
اگرچه این مقاله موجب شد تا وی به عنوان بنیانگذار مدرن روش فرا تحلیل شناخته شود، اما متدولوژی و روشی که او «فرا تحلیل» مینامد، چندین دهه قبل نیز به کار میٰرفته است.
تئوری و نظریههای آماری پیرامون فراتحلیل با کار «اینگرام اولکین» (Ingram Olkin)، «جان ای. هانتر» (John E. Hunter)، «نامباری اس. راجو» (Nambury S. Raju)، «هاریس کوپر» (Harris Cooper)، «لاری وی. هودجس» (Larry V. Hedges)، «جاکوب کوهن» (Jacob Cohen)، «توماس سی. چالمرس» (Thomas C. Chamlers)، «رابرت روزنتال» (Robert Rosenthal)، «فرانک ال. اشمیت» (Frank L. Schmidt) و «داگلاس جی. بوتن» (Douglas G. Bonnet) گسترش و به طور وسیعی به کار گرفته شد.

مزایای به کارگیری فرا تحلیل
از نظر مفهومی، فرا تحلیل از یک روش آماری برای ترکیب نتایج حاصل از مطالعات متعدد در تلاش برای افزایش توان (به موازات مطالعات فردی)، بهبود برآورد اندازه اثر (Effect Size) و یا برای حل عدم اطمینان در هنگام عدم توافق گزارش استفاده میکند. فرا تحلیل یک بررسی کلی آماری از نتایج حاصل از یک یا چند مطالعه منظم است که اساساً، میانگین وزنی از نتایج مطالعه شامل را تولید میکند.
این رویکرد چندین مزیت دارد، که در زیر به آنها اشاره شده است:
- نتایج را میتوان به جمعیت بیشتری تعمیم داد.
- با استفاده از دادههای بیشتر، دقت و صحت تخمینها میتواند بهبود یابد. این به نوبه خود، ممکن است توان آماری را برای کشف یک اثر افزایش دهد.
- ناسازگاری نتایج در طول مطالعات میتواند اندازهگیری و تجزیه و تحلیل شود. به عنوان مثال، ناسازگاری ممکن است از خطای نمونهگیری یا نتایج مطالعه (موارد خاص) تحت تأثیر اختلافات بین پروتکلهای مطالعاتی ایجاد شده باشند.
- آزمایش فرضیه را میتوان در برآوردهای خلاصه استفاده کرد.
- تعدیل و متعادل سازی نتایج حاصل از تحقیقات را میتوان برای توضیح تفاوت بین مطالعات گنجانید.
- وجود سوگیری (اریبی) مقالههای منتشر شده را میتوان مورد بررسی قرار داد.
مراحل انجام یک فرا تحلیل
فرا تحلیل یک بررسی و روش تحقیق منظم محسوب میشود، زیرا این امر امکان شناسایی و ارزیابی مهم کلیه شواهد مربوطه را فراهم میکند (در نتیجه خطر انحراف و اریبی در تخمینهای شاخصهای آماری را محدود میسازد).
مراحل کلی به شرح زیر است:
- تدوین سؤال تحقیق، به عنوان مثال استفاده از الگوی PICO (جمعیت، مداخله، مقایسه، پیامد) که مخفف عبارتهای Population, Intervention, Comparison, Outcome است.
- جستجوی در ادبیات موضوع.
- انتخاب مطالعات («معیارهای تداخل» - Incorporation Criteria)
- بر اساس معیارهای کیفی، به عنوان مثال، نیاز به تصادفی و بدون سوء گیری در یک مطالعه بالینی.
- انتخاب مطالعات خاص در مورد موضوعی مشخص، مانند درمان سرطان سینه.
- تصمیم در مورد اینکه آیا مطالعات منتشر نشده بر اثر تعصب و انتشار جهت دار صورت گرفته یا خیر.
- تصمیم در مورد اینکه کدام متغیرهای وابسته یا شاخصهای آماری مجاز یا مناسب هستند. به عنوان مثال، هنگام بررسی فرا تحلیل، دادههای حاصل از مطالعات صورت گفته که البته منتشر نیز شدهاند به صورت تجمیعی به شکل زیر هستند:
- تفاوتها (دادههای گسسته)
- میانگین (داده پیوسته)
- شاخص «چی هگز» (Hedges ' g) یک اندازه و معیار محبوب برای دادههای پیوسته است که به منظور از بین بردن اختلاف مقیاس بصورت استاندارد انجام میشود، اما تحت تاثیر معیار پراکندگی بین گروهها نیز هست. برای مثال که در آن بیانگر میانگین تیمار و نیز میانگین گروه کنترل را نشان میدهند. یک روش برای از بین بردن مقیاس در مقایسهها است به شرطی که واریانس آمیخته هر دو گروه باشد.
- انتخاب یک مدل فرا تحلیل، به عنوان مثال «تحلیل اثر ثابت» (Fixed Effect Model) یا فرا تحلیل اثر تصادفی (Random Effect Model)، از روشهای معمول در مدل فرا تحلیل محسوب میشوند.
- فرا تحلیل، از منابع ناهمگون و بین رشتهای بهرهگیری میکند. به عنوان مثال، استفاده از آنالیز زیر گروهی (Sungroup Analysis) یا «فرا رگرسیون» (Meta Regression) از روشهای مطرح در فرا تحلیل محسوب میشوند.
راهنمایی رسمی برای اجرای گزارش فرا تحلیلها در کتاب معروف و مرجع «كاكران» (Cochrane Handbook) ارائه شده است. برای دستورالعملهای گزارش، به مقاله «موارد گزارش شده ترجیحی برای بررسیهای سیستماتیک و فرا تحلیلها» (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) یا (PRISMA) با لینک (+) مراجعه کنید.

رویکردها روشها و فرضیات در فرا تحلیل
در ادامه روشهای مختلف فرا تحلیل را مورد بررسی قرار میدهیم. واضح است که این تکنیکها وابسته به محاسبات و تحلیلهای آماری هستند.
به طور کلی، دو نوع از شواهد را میتوان هنگام انجام یک فرا تحلیل متمایز کرد: «دادههای مجزای شرکتکنندگان» (Individual Participant Data) با نماد IPD و دادههای تجمیعی (Aggregate Data) با نماد AD. دادههای تجمیعی ممکن است بطور مستقیم یا غیرمستقیم جمع آوری شده باشند.
دادههای از نوع AD معمولاً در دسترس است (به عنوان مثال از ادبیات موضوع مورد تحقیق) و به طور معمول تخمینهای مختصر مانند «نسبت بخت» (Odd Ratio) یا «ریسک نسبی» (Relative Risk) را محاسبه و نشان میدهد. این مقدارها، میتوانند به طور مستقیم در مطالعات مشابه مفهومی، با استفاده از چندین رویکرد تحقیقی استخراج شوند.
از سوی دیگر، دادههای تجمیعی غیرمستقیم اثر دو تیمار را که در مقایسه با یک گروه کنترل مشابه در فرا تحلیل قرار گرفتهاند، اندازهگیری میکند. به عنوان مثال، اگر درمان A و درمان B به طور مستقیم در مقابل «دارو نما» (Placebo) در فرا تحلیلهای جداگانه مقایسه شوند، میتوانیم از ترکیب این دو نتیجه برای بدست آوردن تخمینی از تأثیر A در مقابل B در یک مقایسه غیرمستقیم بهره ببریم و مشخص کنیم اثر درمان A در مقابل دارونما با حذف اثر درمان B چگونه است.
مشاهدات و شواهد IPD نشانگر دادههای خام هستند که توسط مراکز مطالعه جمع آوری شدهاند. تمایز بین مراکز متفاوت، نیاز به روشهای فرا تحلیل مختلف را برای استفاده از این دادهها، ایجاد كرده است و منجر به ابداع تکنیکهای یک مرحلهای و دو مرحلهای شده است. در روشهای یک مرحلهای، IPD حاصل از همه مطالعات به طور همزمان در مدل سازی مورد استفاده قرار میگیرند. البته سهم هر بخش از دادهها با توجه به نوع مطالعه ممکن است متفاوت باشد. اما در روشهای دو مرحلهای ابتدا شاخصهای آمار توصیفی برای هر مطالعه محاسبه شده و سپس آمار کلی را به عنوان میانگین وزنی این شاخصها بدست می آورند. با تبدیل IPD به AD، میتوان از روشهای دو مرحله نیز استفاده كرد. این امر آنها را هنگام انتخاب فرا تحلیل به یک انتخاب جذاب تبدیل میکند. اگرچه به طور مرسوم اعتقاد بر این است که روشهای یک مرحلهای و دو مرحلهای نتایج مشابهی را به بار میآورند، اما مطالعات اخیر نشان دادهاند که ممکن است گهگاه این دو روش، منجر به نتیجهگیریهای مختلف شوند.
مدلهای آماری برای دادههای تجمیعی در فرا تحلیل
در ادامه به بعضی از موارد اشاره خواهیم کرد که برای دادههای تجمیعی باید مورد توجه قرار گیرد. به یاد دارید که هدف از فرا تحلیل، افزودن اعتبار بیشتر به نتایج یک تحقیق علمی است بطوری که بتواند خطای نمونهگیری و برآورد کمتری نسبت به هر یک از برآوردگرهای فرعی داشته باشد.
شواهد مستقیم: مدلهایی که فقط اثرات اصلی در مطاالعه را شامل میشوند
مدل اثرات ثابت
مدل «اثرات ثابت» (Fixed Effect)، میانگین وزنی یک سری از برآوردهای مطالعه را ارائه میدهد. معکوس واریانس تخمینها معمولاً به عنوان وزن مطالعه مورد استفاده قرار میگیرد، به طوری که مطالعات با حجم نمونهای بزرگتر تمایل دارند بیشتری از مطالعات با حجم کوچکتر در میانگین وزنی نقش داشته باشند. در نتیجه، هنگامی که مطالعات در یک فرا تحلیل توسط یک مطالعه با حجم نمونه بزرگ همراه میشود عملا نقش مطالعات با حجم کوچکتر را کمرنگ کرده یا از بین میبرد.
از همه مهمتر این که در مدل اثرات ثابت فرض میشود که همه مطالعات مربوط به یک جمعیت، از متغیر و تعاریف یکسانی استفاده میکنند. در حالیکه به عنوان مثال اثرات درمانی ممکن است با توجه به محل، میزان دوز دارو، شرایط مطالعه و ... متفاوت باشد. در عمل اثرات عوامل تصادفی در نظر گرفته نشده است.

مدل اثرات تصادفی
مدل رایج مورد استفاده در ترکیب تحقیق و مطالعات ناهمگن، مدل «اثرات تصادفی» (Random Effect) فرا تحلیل است. البته در این حالت هم از یک میانگین وزنی اندازه اثرات گروههای مطالعات استفاده میشود. وزنی که در این فرآیند برای هر تحقیق در محاسبه میانگین وزنی در فرا تحلیل با اثر تصادفی اعمال میشود، طی دو مرحله بدست میآید:
- مرحله 1: وزندهی با معکوس واریانس
- مرحله 2: وزندهی با استفاده از «مؤلفه واریانس اثر تصادفی» (Random Effects Variance Component) یا به اختصار REVC که به سادگی از میزان تغییرپذیری اندازه اثرات مطالعات مورد نظر، حاصل میشود.
این بدان معنی است که هر چه این اختلاف در اندازههای اثر بیشتر باشد، عدم وزنیدهی بیشتر شده و این این امر در نتیجه به میانگینگیری بدون وزن منجر میشود. در حالت دیگر، هنگامی که تمام اندازههای اثر مشابه باشند یا تغییرپذیری از خطای نمونهگیری تجاوز نمیکند، هیچ REVC استفاده نشده و فرا تحلیل اثرات تصادفی به سادگی پیش فرض فرا تحلیل اثرات ثابت را نتیجه میدهد و فقط به وزندهی با معکوس واریانس اکتفا میشود.
وسعت این تغییرات تنها به دو عامل بستگی دارد:
- ناهمگونی در دقت یا «خطای نمونهگیری» (Sampling Error)
- ناهمگونی در اندازه اثر (Effect Size)
از آنجا که هیچ یک از این عوامل به طور خودکار نشانگر اشکال در یک مطالعه بزرگ یا مطلوبیت یا قابلیت اطمینان بیشتر در یک مطالعه کوچکتر نیستند، توزیع مجدد وزنها، تحت مدل اثرات تصادفی، هیچ ارتباطی با آنچه که این مطالعات در واقع ارائه میدهند، ندارد. آنچه اهمیت دارد، در واقع، نمایش توزیع مجدد وزنها از مطالعات با حجم بزرگتر به کوچکتر است که به صورت معکوس افزایش مییابد، زیرا با این کار ناهمگنی افزایش مییابد تا اینکه در نهایت همه مطالعات دارای وزن برابر شده و توزیع مجدد جدیدی امکان پذیر نیست.
مسئله دیگر در مورد مدل اثرات تصادفی این است که متداولترین «فواصل اطمینان» (Confidence Interval)، در حالت تجمیعی، معمولاً احتمال پوشش خود را بالاتر از سطح اسمی () حفظ نمیکنند و ممکن است خطای آماری بیش از انتظار افزایش یابد که به طور بالقوه در نتیجهگیریهای آماری نامطلوب است.
البته برای غلبه بر این اشکال، چندین راهحل و روش اصلاحی، پیشنهاد شده است اما بحث همچنان ادامه دارد. نگرانی بیشتر این است که میانگین اثر تیمارها گاهی اوقات حتی در مقایسه با مدل اثر ثابت محافظه کارانهتر نیز میباشد و بنابراین در عمل گمراه کننده است.
یکی از راه حلهای پیشنهادی، ایجاد فاصله اطمینان پیش بینی در برآورد اثرات تصادفی برای نمایش کرانهای اثرات تصادفی در عمل است. اما فرضیه محاسبه چنین فاصله اطمینانی این است که آزمایشات و مطالعات موجود، دست کم همگن در نظر گرفته شوند و این شامل جمعیت و تیمارهای مقایسهای نیز میشود که در عمل غیر قابل دستیابی است.
روشی که بیشترین استفاده را برای برآورد واریانس مطالعات (REVC) دارد، رویکرد DL یا (DerSimonian-Laird) است. چندین تکنیک تکراری و البته از نظر محاسباتی، پر هزینه، برای محاسبه واریانس مطالعات وجود دارد، مانند «حداکثر تابع درستنمایی» (Maximum Likelihood)، «حداکثر درستنمایی مقید» (Restricted Maximum Likelihood) که مدلهای اثر تصادفی با استفاده از این روشها میتوانند اجرا شوند.
نکته: در نرمافزار محاسبات آماری Stata فرمان Metan از تخمینگر DL استفاده میکند. این روش پیشرفته، همچنین به صورت رایگان و آسان برای استفاده در افزونههای Microsoft Excel به نام MetaEasy به کار گرفته شده است.
بیشتر فرا تحلیلها بین 2 تا 4 مطالعه را شامل میشوند و چنین حجم مطالعاتی، اغلب برای تخمین دقیق ناهمگونی یا واریانس ناکافی است. بنابراین به نظر میرسد که در فرا تحلیلهای با اندازه مطالعه کوچک، اریبی واریانس از بین میرود در حالیکه چنین نیست. به این ترتیب این کار منجر به قبول فرض همگن به شکل نادرست میشود.
به طور کلی، به نظر میرسد ناهمگونی به طور مداوم در فرا تحلیلها و تجزیه و تحلیلهای حساسیت دست کم گرفته میشود در حالیکه این تغییرپذیری در سطح زیادی اثر گذار است. به این ترتیب، مدل اثرات تصادفی و بستههای نرم افزاری که در بالا ذکر شد مربوط به فرا تحلیلها با مطالعه کامل بوده و بخصوص برای محققهایی است که مایل به اجرای فرا تحلیل روی دادههای متفاوت از تیمارهای مختلف (IPD) هستند.

مدل IVhet
در دانشگاه كویینزلند (Queensland University) و دانشگاه كویت (Kuwait University)) عدهای از دانشمندان در حال ایجاد مدلی از اثرات تصادفی هستند که به IVhet مشهور است. روش IVhet براساس تابع شبه درستنمایی با واریانس معکوس عمل میکند. از این تکنیک در نرمافزار MeatXL که به صورت افزونههای قابل اجرا در اکسل به کار میرود، استفاده شده است. خوشبختانه این افزونه که برای اجرای فراتحلیل مناسب است، به صورت رایگان در اختیار کاربران قرار گرفته است تا به کمک آن قادر به ایجاد و تحلیل مدلهای اثرات تصادفی باشند.
یک مزیت بارز این مدل آن است که دو مشکل اصلی مدل اثرات تصادفی را برطرف میکند. اولین مزیت مدل IVhet این است که پوشش برای فاصله اطمینان در سطح اسمی (معمولاً 95٪) باقی میماند. این امر درست برخلاف مدل اثرات تصادفی ساده است که با افزایش ناهمگونی، میزان پوشش کاهش مییابد.
مزیت دوم این مدل IVhet، به کارگیری وزن میانگینها براساس معکوس واریانس مطالعات فردی است، برخلاف مدل RE که به مطالعات کوچک وزن بیشتری (و بنابراین مطالعات بزرگتر کمتر) می دهد که باعث افزایش ناهمگونی میشود. وقتی ناهمگونی بزرگ میشود، وزن مطالعه فردی تحت مدل RE برابر میشود و بنابراین مدل RE به جای میانگین وزنی، میانگین حسابی را محاسبه میکند. به این ترتیب این اثر جانبی که مدل RE ساده ایجاد میشوند، در مدل IVhet رخ نمیدهد.
بنابراین IVhet از تخمین مدل RE ساده در دو منظر متفاوت است:
- تخمینهای تجمیع شده در مدل IVhet وزن بیشتری به مطالعات با حجم بزرگتر میدهند در حالیکه در مدل ساده RE این موضوع بوسیله جریمه کردن براساس واریانس، تخمینها را دچار خطا کرده و اریبی به سمت مطالعات کوچکتر خواهد بود.
- فاصله اطمینان ایجاد شده توسط مدل IVhet با سطح پوشش واقعی (مورد انتظار) مطابقت دارد.
هر چند مدل RE یک روش جایگزین برای تجمیع دادههای مطالعات ارائه میدهد، اما نتایج تحلیلهای شبیه سازی، نشان میدهد که استفاده از یک مدل احتمال مشخصتر با فرضیات غیرقابل دسترس، مانند مدل RE، لزوماً نتایج بهتری را ارائه نمیدهد.
از طرفی میتوان نشان داد که مدل IVhet مشکلات مربوط به کمترین خطای آماری، پوشش ضعیف مربوط به فاصله اطمینان و افزایش MSE را نسبت به مدل اثرات تصادفی برطرف میکند، در نتیجه محققان در اغلب موارد از اجرای مدل اثرات تصادفی خودداری میکنند.

شواهد مستقیم: مدلهایی که اطلاعات اضافی را در بر میگیرند
در این قسمت به مدلهایی میپردازیم که براساس کیفیت (نه حجم نمونه یا بزرگی طرح مطالعاتی) توجه دارند. در نتیجه میتوان یک متغیر را به عنوان کیفیت هر طرح تحقیقاتی در نظر گرفت که از آن برای اجماع مطالعات موردی و فردی در فرا تحلیل استفاده شود.
مدل براساس کیفیت تحقیق
یک شیوه دیگر برای برخورد با فرا تحلیل، استفاده از کیفیت مطالعات و تحقیقها است. در چنین مدلهایی با استفاده از سهم واریانس با توجه به یک مؤلفه (کیفیت یک تحقیق)، نسبت به واریانس کل، خطای تصادفی مدلهای ترکیبی محاسبه میشود.
همچنین برای ایجاد وزنها نیز از واریانس مولفهای برحسب متغیرهایی که کیفیت مطالعه یا تحقیق را نشان میدهند، کمک گرفته میشود. در هر مدل فرا تحلیل با اثرات ثابت برای ایجاد وزن از این شیوه میتوان استفاده کرد. قدرت فرا تحلیل براساس متغیرهای نشان دهنده کیفیت برای هر مطالعه در این نکته نهفته است که چنین مدلی اجازه میدهد تا از شواهد روش شناختی موجود، بیش از اثرات تصادفی ذهنی استفاده شود و از این طریق شکاف بین روش تحقیق و آمار در تحقیقات بالینی از بین میرود.
برای انجام این کار ابتدا واریانس اریب محاسبه شده که بر اساس اطلاعات و دادههای طبقهبندی شده برحسب کیفیت مطالعات، حاصل شده است. از معکوس این واریانسها برای وزندار کردن نتایج مطالعات در میانگین وزنی استفاده میشود.
به این ترتیب اگر مطالعه و تحقیق ام دارای کیفیت مناسبی در مقابل دیگر مطالعات باشد، سهمی که به آن نسبت داده میشود بیشتر است. در نتیجه مطالعات با کیفیت نقش مهمتری در نتایج فرا تحلیل خواهد داشت.
از طرفی مطالعات مشابه نیز با توجه به همسان بودن، وزنی کاهشی خواهند داشت. به این ترتیب با توجه به اهمیت، تشابه و ضعیف بودن مطالعات و تحقیقات صورت گرفته در فرا تحلیل، وزنهای مختلف و متناسب به هر یک داده شده و نتیجه فرا تحلیل براساس آن برآورد میشود.
به عبارت دیگر، اگر مطالعه ام از کیفیت خوبی برخوردار باشد و سایر مطالعات كیفیت در سطح متوسط داشته باشند، بخشی از وزن تنظیم شده از نظر ریاضی برای وزن مطالعه ام توزیع میشود که مشخصا بیشتر از نسبت به اندازه اثر کلی مطالعات دیگر است. از آنجا که مطالعات از نظر کیفی به طور فزایندهای شبیه به هم میشوند، احتیاج به توزیع مجدد وزنها به تدریج کمتر میشود و این کار وقتی که کلیه مطالعات دارای کیفیت برابر باشند متوقف میشود.
در صورت کیفیت برابر، مدل اثرات کیفیت به صورت پیش فرض با مدل IVhet که در بخش قبلی معرفی شد، یکسان خواهد شد. ارزیابی اخیر از مدل اثرات کیفیت (با برخی به روز رسانیها) نشان میدهد که مدل ارزیابی کیفیت، عملکردی مناسبتر از مدل اثرات تصادفی دارد. این ارزیابی البته توسط معیار و شاخصهایی مانند اندازهگیری مقدار MSE (میانگین مربعات خطا) و واریانس واقعی تحت شبیه سازی صورت گرفته است. بنابراین این مدل جایگزین تفسیرهای غیرقابل توصیف از عوامل تصادفی است که در ادبیات موضوع تحقیق زیاد مورد استفاده است.
شواهد غیر مستقیم: روشهای فرا تحلیل شبکهای
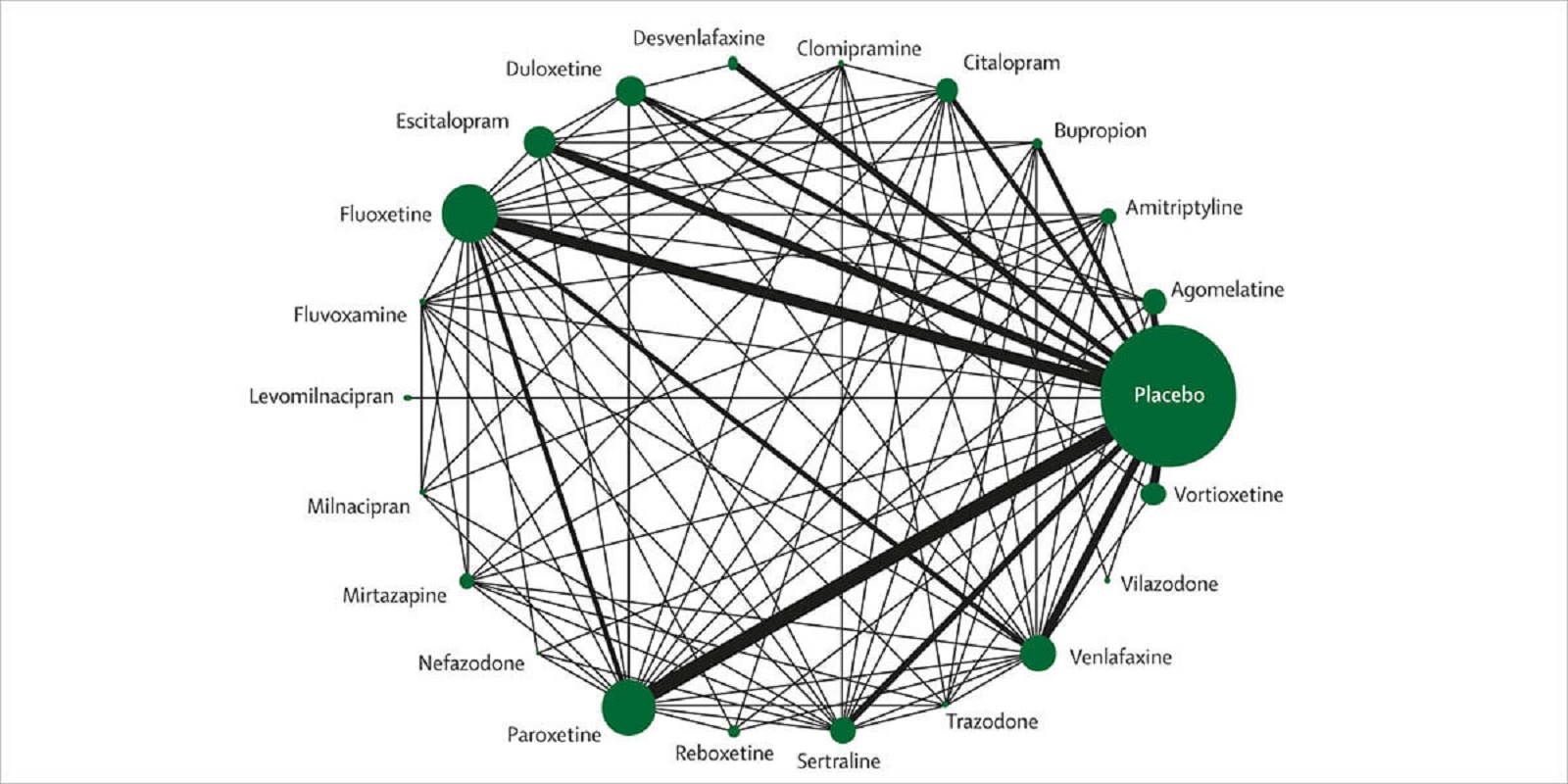
فرا تحلیل شبکه (Network Meta Analysis) به مقایسهها و تلفیق مطالعات به طور غیرمستقیم نگاه میکند. برای روشن شدن این موضوع به تصویر زیر توجه کنید.
در این حالت مشخص است که مطالعه A در رابطه با تحقیق C مورد بررسی قرار گرفته و C در رابطه با B مورد کاوش قرار گرفته است. با این حال، رابطه بین A و B فقط به صورت غیرمستقیم شناخته شده است و یک فرا تحلیل شبکهای به چنین شواهدی که به طور غیرمستقیم برقرار است نیز توجه میکند. این رابطهها ممکن است ناشی از تفاوت یا مشابهتها بین روشها و تیمارها، همچنین با استفاده از روش آماری متفاوت باشند.

روشهای فرا تحلیل مقایسه و بررسیهای غیرمستقیم که اغلب فرا تحلیل شبکه نامیده میشوند، به ویژه وقتی چندین تیمار به طور همزمان ارزیابی میشوند، عموماً از دو روش اصلی استفاده میکنند:
- روش بوکر (Bucher Method): در این روش یک مقایسه یا بررسی (یا به صورت تکراری) روی یک حلقه بسته از سه تیمار مختلف صورت میگیرد، به گونهای که یکی از آنها دارای ارتباطی با دو گونه دیگر است و گرهای است که شروع و پایان حلقه بررسی را تشکیل میدهد. بنابراین، چنین روشی به حداقل دو تحقیق (دو گره) احتیاج دارد. در صورتی که فقط دو گره وجود داشته باشند، آنها را مستقل در نظر میگیریم.
- روش جایگزین: این روش برای استفاده از مدل سازی آماری پیچیدهتر است که شامل آزمایشهای مختلف رابطهها و مقایسه همزمان بین تمامی تیمارهای رقیب هستند. این عملیات با استفاده از روشهای بیزی (Bayesian Methods)، مدلهای خطی مختلط (Mixed Linear Models) و رویکردهای رگرسیون متا (Meta Regression Analysis) اجرا میشوند.
چارچوب بیزی
مشخص کردن «مدل فرا تحلیل شبکه بیزی» (Bayesian network meta-analysis model) شامل نوشتن یک مدل نمودار مستقیم چرخشی (DAG) یا (Directed Acyclic Graph) برای نرم افزارهای هدف اصلی زنجیره مونت کارلو (MCMC) مانند WinBUGS است. علاوه بر این، توزیع پیشین، باید برای تعدادی از پارامترهای مشخص و دادهها نیز باید در یک قالب خاص عرضه شوند. همه این عوامل به کمک یکدیگر یک DAG، یک مدل سلسله مراتبی بیزی (Bayesian Hierarchical Model) را تشکیل میدهند.
برای پیچیدهتر کردن عملیات، به دلیل ماهیت تخمین MCMC، باید مقادیر شروع در زنجیره مونت کارلو، بزرگتر از تعداد زنجیره مستقل انتخاب شوند تا همگرایی قابل ارزیابی باشد. متاسفانه در حال حاضر، هیچ نرم افزاری وجود ندارد که بطور خودکار چنین مدلهایی را تولید کند، اگرچه ابزارهایی برای کمک به این فرآیند وجود دارد.
پیچیدگی رویکرد بیزی باعث محدودیت در استفاده از آن شده است. البته خودکار سازی این روش پیشنهاد شده است اما مستلزم دستیابی به دادههای ارتباطی بین گرهها در شبکه فرا تحلیل است که معمولا به سادگی در دسترس نیست. بعضی اوقات ادعاهای بزرگی برای توانایی ذاتی چارچوب بیزی در انجام فرا تحلیل شبکه و انعطاف پذیری بیشتر آن مطرح شده است. با این حال، انتخاب اجرای چارچوب استنتاج در فرا تحلیل بدون استفاده از استنباط بیزی یا برمبنای فراوانی، ممکن است نتایج مناسبتری نیز ارائه کنند که به واسطه پیچیدگی روشهای استنباطی حاصل نشود.
چارچوب چند متغیره مبتنی بر فراوانی
همانطور که گفته شد، استفاده از روشهای بیزی با محدودیتهایی همراه است که ممکن است به واسطه از چارچوب چند متغیره مبتنی بر فراوانی (Frequentist Multivariate Framework) از بین بروند. از طرف دیگر، روشهای چند متغیره مبتنی بر فراوانی، شامل تقریبها و فرضیاتی هستند که صریحاً بیان نشده یا شامل فرضیههایی هستند که قابل تأییدند. به عنوان مثال، بسته محاسبات آماری و فرا تحلیل mvmeta برای Stata فرا تحلیل شبکهای را در یک چارچوب مبتنی بر فراوانی انجام میدهد.
اما اگر هیچ مقایسهای مشترک در شبکه وجود نداشته باشد، باید این کار را با افزودن مجموعه داده مجازی با واریانس بالا انجام داد، که البته کاری کاملا دقیق و علمی نیست. این امر درست به معنی اجرای استنباط بیزی بدون اطلاع (یا با اطلاع جفری- Jeffry's Information) است.
موضوع دیگر استفاده از الگوی اثرات تصادفی در هر دو چارچوب برمبنای فراوانی و بیزی است. به تحلیلگران توصیه میشود که در تفسیر تحلیل اثرات تصادفی محتاط باشند، زیرا فقط یک اثر تصادفی برای آنها مجاز است در حالیکه اغلب بیش از یک اثر تصادفی در نظر گرفته میشود که پیشبینی و مدلسازی را بسیار سخت میکند. بنابراین به کارگیری مدلهای معرفی شده در بالا، به صورت اکید توصیه میشود.
چارچوب مدلسازی زوجی تعمیم یافته
رویکردی که از اواخر دهه 1990 مورد آزمایش واقع شده است، اجرای ترکیبی از سه تیمار درون یک حلقه بسته است. البته این روش در سالهای اخیر محبوبیت زیادی پیدا نکرده است زیرا با افزایش پیچیدگی شبکه، تعداد پردازشها به سرعت گسترده شده و پیچیدگی محاسبات زیاد میشوند.
البته در این زمینه، فعالیتها و روشهای جدیدی رو به گسترش است تا از آن به عنوان یک روش برتر نسبت به روشهای فراوانی و بیزی استفاده شود. اخیرا، اتوماسیون روش حلقه بسته سه تیماری توسط برخی محققان برای شبکههای پیچیده ساخته شده است که از آن به عنوان راهی برای در دسترس قرار دادن این تکنیک در جامعه تحقیقاتی یاد میشود.
در این روش، هر آزمایش را به دو مداخله یا تیمار، محدود میکند، همچنین الگویی نیز برای مقایسه بین زوجها نیز ارائه میشود: یک گره کنترل ثابت مختلف را میتوان در اجراهای مختلف تغییر داد. همچنین از روشهای فرا تحلیل قوی دیگری نیز میتوان استفاده کرد به طوری که از بسیاری از مشکلات برجسته در مورد تکنیکهای برمبنای فراوانی و یا بیزی نیز از بین میروند.
تحقیقات بیشتر در مورد این چهارچوب در حال شکلگیری است تا مشخص شود که آیا این واقعاً این روش از چارچوبهای مبتنی بر فراوانی چند متغیره یا درستنمایی بیزی برتر است یا خیر.

فرا تحلیل اصلاح شده
در این تکنیک، شکل دیگری از اطلاعات اضافی که حاصل از تنظیمات و هدف از فرا تحلیل است، در نظر گرفته میشود. اگر تنظیم هدف برای استفاده از نتایج فرا تحلیل شناخته شده باشد، میتوان از دادههای جدید برای متناسب کردن نتایج استفاده کرد و به این ترتیب "فرا تحلیل متناسب" تولید میشود.
همچنین از این تکنیک برای آزمایش دقت فرا تحلیل استفاده میکنند به این معنی که دانش تجربی از نرخ مثبت آزمون (مثلا در آزمونهای پزشکی) و موارد مرتبط با آن برای استخراج نواحی مختلف مانند دقت، صحت و بازیابی در منحنی «مشخصه عملکرد سیستم» (Receiver operating characteristic) استفاده میشود. این نواحی را به عنوان «مناطق قابل اجرا» (Applicable Region) میشناسیم. سپس مطالعات برای تنظیم هدف بر اساس مقایسه با این منطقهها انتخاب شده و تجمیع میشوند تا یک برآورد کلی را متناسب با تنظیمات هدف تهیه کنند.
اعتبارسنجی نتایج در فرا تحلیل
همانطور که در ابتدای متن گفته شد، برآورد فرا تحلیل، میانگین وزنی را در طول مطالعات نشان میدهد و هنگامی که ناهمگونی وجود دارد، ممکن است منجر به تخمین کلی شود که البته نماینده مطالعات فردی نیست.
ارزیابی کیفی مطالعات اولیه با استفاده از ابزارهای مستقل میتواند اریبی را کشف کند، اما اثر کل این سوگیریها را نمیتوان کاهش داد. اگرچه نتیجه فرا تحلیل را میتوان با یک مطالعه اولیه آینده نگر مستقل مقایسه کرد، اما چنین اعتبار خارجی (External Validation) اغلب غیر عملی است. این امر منجر به توسعه روشهایی شده است که شکلی خاص از اعتبار سنجی متقابل (Cross Validation) محسوب میشوند. این روش را گاهی اوقات به عنوان «اعتبار متقاطع داخلی-خارجی» (Internal-external Cross Validation) یا (IOCV) نیز مینامند.
در اینجا هر یک از k مطالعات مورد بررسی یک به یک حذف شده و با برآورد تجمیعی حاصل از جمع آوری مطالعات k-1 باقیمانده مقایسه میشوند. یک اعتبار سنجی کلی ، مبتنی بر «أماره اعتبار سنجی» (Validation Statistic) یا VN بر اساس IOCV، برای اندازه گیری روایی آماری نتایج فرا تحلیل، تهیه میشود. برای صحت و پیش بینی آزمون، به ویژه هنگامی که اثرات چند متغیره وجود دارد، رویکردهای دیگری که به دنبال تخمین خطای پیش بینی هستند نیز ارائه شده است.
متاسفانه فرا تحلیل روی چندین مطالعه کوچک نمیتواند به منزله اجرای یک بررسی و تحقیق بزرگ باشد. در حقیقت تجمیع مطالعات کوچک نتیجهای مشابه با یک مطالعه وسیع و گسترده را ندارد. از طرفی برخی معتقدند که ضعف دیگری این روش آن است که منابع و منشاء اریبی یا سوگیری تحقیقات در فرا تحلیل کنترل نمیشوند.
یک فرا تحلیل خوب نمیتواند برای طراحی ضعیف یا اریبی در مطالعات صورت گرفته، راه حلی ارائه دهد. این بدان معنی است که فقط مطالعات صحیح از نظر روش شناختی باید در یک فرا تحلیل قرار بگیرند. به این موضوع به اصطلاح «بهترین ترکیب شواهد» (Best Evidence Synthesis) گفته میشود.
همچنین فرا تحلیلهای که شامل تعداد زیادی مطالعات ضعیفتر هستند، متغیر پیش بینی کننده سطح مطالعه را اضافه کرده كه نشان دهنده کیفیت روش شناختی مطالعات برای بررسی تأثیر کیفیت تحقیق بر اندازه اثر (Effect Size) است. با این حال، برخی دیگر از محققین استدلال کردهاند كه یک رویکرد بهتر حفظ اطلاعات در مورد واریانس در نمونه مطالعه، کار با یک شبکه گسترده است در حالیکه معیارهای انتخاب روش شناختی، ذهنیت ناخواستهای را معرفی میکنند که هدف از اجرای فرا تحلیل را از یاد میبرد.
اریبی انتشارات - مشکل کشوی بایگانی
یکی دیگر از مشکلات احتمالی در فرا تحلیل، اتکا به مطالعات منتشر شده است که به دلیل سوگیری نشریات ممکن است نتایج اغراق آمیز ایجاد کند، زیرا مطالعاتی که نتایج منفی یا نتایج بدون اختلاف معنادار را نشان میدهند، کمتر منتشر میشوند. به عنوان مثال، اغلب شرکتهای داروسازی مطالعات منفی در مورد یک داروی خاص را پنهان میکنند و محققان ممکن است از مطالعات منتشر نشده مانند مطالعات پایاننامه یا چکیدههای کنفرانس که به انتشار نرسیدهاند در انجام فرا تحلیلها غافل شوند. این مشکلی به راحتی قابل حل نیست، زیرا نمیتوان دانست که چند مطالعات و تحقیقاتی گزارش نشدهاند.
این مسئله به نام مشکل کشوی پرونده (The File Drawer Problem) که با بایگانی کردن نتایج منفی یا غیر معنی دار در کشوی مرکز تحقیقاتی بوجود میآید، میتواند منجر به توزیع مغرضانه اندازه اثرات تیمارها شود. بنابراین یک مغالطه جدی در نرخ ریسک یا اثرات مطالعات در فرا تحلیل بوجود خواهد آمد. بطوری که در آن اهمیت مطالعات منتشر شده بیش از حد مورد انتظار، ارزیابی میشود و مطالعات دیگر که برای انتشار ارسال نشده و یا رد شدند را شامل نمیشود. این باید به طور جدی هنگام تفسیر نتایج حاصل از یک فرا تحلیل مورد بررسی قرار گیرد.
توزیع اندازه اثر را میتوان با یک نقشه قیف-مانند (Funnel Plot) مشاهده کرد که در رایجترین نسخه آن، یک نقشه پراکندگی خطای استاندارد در مقابل اندازه اثر است. در تصویر زیر یک نمونه از جنین نموداری را مشاهده میکنید.

این نمودار از این واقعیت استفاده میکند که مطالعات کوچکتر که البته خطاهای استاندارد بزرگتری نیز دارند، دارای پراکندگی بیشتری نسبت به اندازه اثر هستند که به منزله دقیقتر بودن آنها است. در مقابل مطالعات بزرگتر، پراکندگی کمتری دارند و نوک قیف را تشکیل میدهند. اگر بسیاری از مطالعات منفی منتشر نشده باشند، مطالعات مثبت باقی مانده، منجر به طرح قیفی میشود که در آن پایه به یک طرف خم شده است و عدم تقارن در طرح قیف ظاهر میشود. چنین وضعیتی را در تصویر زیر مشاهده میکنید.

در مقابل، هنگامی که تعصب با اریبی در انتشار مقالات وجود ندارد، تأثیر مطالعات کوچکتر دلیلی برای تمایل نمودار به یک طرف ندارد و بنابراین یک طرح قیف متقارن نتیجه رسم نمودار قیفی خواهد شد. این همچنین بدان معنی است که در صورت عدم وجود تعصب در انتشار، هیچ ارتباطی بین خطای استاندارد و اندازه اثر وجود نخواهد داشت. رابطه منفی یا مثبت بین خطای استاندارد و اندازه اثر حاکی از آن است که مطالعات کوچکتر که اثرات را در یک جهت مشاهده میکنند، احتمالاً بیشتر منتشر و یا برای انتشار ارسال میشوند.
جدای از طرح و نمای قیفی شکل، روشهای آماری برای دیگری نیز برای تشخیص سوگیری انتشار وجود دارد. به عنوان مثال، اثرات مطالعات کوچک (مطالعات مغرضانه کوچکتر)، که در آن اختلافات روش شناختی بین مطالعات کوچکتر و بزرگتر وجود دارد، ممکن است عدم تقارن در اندازه اثر را که شبیه به اریبی در انتشار است را ایجاد کند. با این حال، اثرات مطالعه کوچک ممکن است برای تفسیر فرا تحلیل به همان اندازه مشکل ساز باشد و ضروری است که محققان در زمینه فرا تحلیل بررسی منابع بالقوه سوگیری و اریبی را در نظر بگیرند.
برای کاهش مشکلات خطای مثبت کاذب (False Positive)، روش «تاندم» (Tandem) برای تجزیه و تحلیل تعصب انتشار پیشنهاد شده است. این روش از سه مرحله تشکیل شده است.
- گام یا مرحله اول: ابتدا شاخص N (مقدار عدم موفقت - Fail Safe) را که توسط «اروین» (Orwin) معرفی شده است را محاسبه میکند، تا بررسی شود که چه تعداد مطالعات باید به منظور فرا تحلیل اضافه شود تا خطای آزمون آماری را کاهش دهد. اگر این تعداد مطالعه بزرگتر از تعداد مطالعات مورد استفاده در فرا تحلیل باشد، این نشانه عدم وجود سوگیری در انتشار است، زیرا در این حالت، برای کاهش اندازه اثر، نیاز به مطالعات بیشتری هست.
- گام یا مرحله دوم: با «آزمون رگرسیون اٍگر» (Egger Regression test) که به بررسی شکل قیف-مانند و تقارن آن میپردازد مشخص میشود که آیا اریبی وجود دارد یا خیر. همانطور که قبلاً نیز گفته شد، یک قطعه قیف متقارن نشانه عدم وجود تعصب و اریبی در انتشار است ،زیرا اندازه اثر و اندازه نمونه به آن وابسته نیست.
- گام یا مرحله سوم: در انتها نیز میتوان به کمک روش اصلاح و پر کردن (Trim and Fill) اگر طرح قیف نامتقارن باشد، داده (مطالعات جدید) را وارد کرده و مراحل قبل را دوباره اجرا کرد تا اثر کشوی بایگانی از بین برود.
بیشتر مباحث مربوط به اریبی در انتشار بر روی شیوههای نشریاتی که به دنبال انتشار یافتههای آماری مهم هستند، تمرکز دارد. با این حال، شیوههای تحقیق مدرن و جدید، مانند اصلاح مدلهای آماری تا رسیدن به اختلاف معنیدار، ممکن است یافتههای آماری قابل توجهی را در حمایت از فرضیههای محققان در فرا تحلیل به دست آورد.
معمولا مطالعات علمی و تحقیقی وقتی منجر به تفاوت معنیدار آماری نشوند، گزارش نمیشوند. به عنوان مثال، آنها بعضی از آنها میتوانند بیانگر عدم اختلاف بین میانگین یک گروه با گروه دیگری از تیمارها باشند بدون آن كه اطلاعات دیگری ارائه دهند. به عنوان مثال فقط به یافته مقدار احتمال (P-Value) اکتفا میشود. محرومیت از یافتههای این مطالعات میتواند به وضعیتی مشابه مشکل کشوی بایگانی منجر شود. اما باید توجه داشت که گنجاندن آنها (با فرض اثرات تهی) در فرا تحلیل ممکن است اریبی را نیز به همراه داشته باشد.
مدل MetaNSUE که توسط «جاکویم رادوا» (Joaquim Radua) ایجاد شده است، نشان میدهد که محققان میتوانند این مطالعات را بطور نااریب در فرا تحلیل به کار گیرند. مراحل اجرای چنین مدلی به شرح زیر است:
- برآورد حداکثر درستنمایی مربوط به اثر فرا تحلیل (Meta Analysis Effect) و ناهمگونی بین مطالعات.
- مشکلات ناشی از جایگزینی مقادیر گمشده یا حذف نقاط دور افتاده.
- فرا تحلیلهای جداگانه برای هر مجموعه داده تجمیع شده.
- جمع آوری نتایج این فرا تحلیلها.
نقطه ضعف دیگری که در رویکرد آماری نهفته است عدم ارائه دقیقترین روش ترکیب نتایج در فرا تحلیل است. برای مثال هر یک از مدلهای ترکیبی نتایج، مانند مدلهای اثر ثابت، IVhet، مدل اثرات تصادفی یا اثرات شاخص کیفیت ممکن است در فرا تحلیلها به کار رود. اگرچه انتقاد نسبت به مدل اثرات تصادفی در حال افزایش است ولی باز هم از آن به شکل فزایندهای استفاده میشود. مشکل اصلی با رویکرد تأثیرات تصادفی این است که از نظریه آماری کلاسیک برای تولید یا محاسبه «برآوردگر سازگار» (compromise estimator) استفاده میکند که باعث میشود، اگر ناهمگونی در طول مطالعات بزرگ رخ داده باشد، وزن برآوردگرها در میانگین وزنی به مانند برآوردگر اصلی باشد و در صورت همگونی، وزنی برابر با معکوس واریانس برآوردگرها ارائه میدهد.
هر چند بیشتر روشهای شبیهسازی و مکانیسم تولید دادهها مشابه صورت میگیرند، ولی هیچ دلیلی وجود ندارد که فکر کنیم، مدل تحلیل و مکانیسم تولید داده (مدل) باید به شکل مشابه صورت بگیرد. بنابراین متاسفانه بسیاری از تحلیلها مورد بررسی در فرا تحلیل به شکل یکسان و با هدف مشابه اجرا نشدهاند.
مشکلات ناشی از اریب-محوری
مهمترین خطا در فرا تحلیل هنگامی اتفاق میافتد که شخص یا افرادی که فرا تحلیل را انجام میدهند، برنامهای برای تصویر یا شکستن یک قانون در زمینههای اقتصادی، سیاسی یا اجتماعی دارند. افرادی دارای این نوع برنامهها هستند به دلیل تعصب شخصی، دچار اریبی شده و از فرا تحلیل سوء استفاده میکنند. به عنوان مثال، محققانی که به این شیوه عمل میکنند بعضی از مطالعات را بدون دلیل علمی، مطلوب قلمداد کرده و آنهایی که مخالف اهدافش هستند را بدون اهمیت و بدون پشتوانه علمی مینامند.
علاوه بر این، نویسندگان مورد علاقه محقق فرا تحلیل، ممکن است خود به آنها مبلغی بپردازند که بتوانند از اهداف کلی سیاسی، اجتماعی و اقتصادی آنها به شیوههایی مانند انتخاب مجموعه دادههای مطلوب کوچک و عدم استفاده از مجموعه دادههای نامطلوب بزرگتر حمایت کنند. تأثیر چنین اریبی و تعصباتی بر نتایج حاصل از فرا تحلیل امکان پذیر است.
یک مطالعه 2011 که برای افشای تعارضات احتمالی منافع در مطالعات تحقیقاتی پایهای انجام شد و برای فرا تحلیلهای پزشکی مورد بررسی قرار گرفت ، 29 فرا تحلیل را مورد بررسی قرار داد و نشان داد که تضاد منافع در مطالعات زیر فرا تحلیل به ندرت افشا میشود. 29 فرا تحلیل شامل 11 مجله پزشکی عمومی، 15 مورد از مجلات پزشکی تخصصی و سه مورد از پایگاه داده بررسیهای سیستم کوکران بودند.
29 فرا تحلیل در کل 509 کار آزمایی کنترل شده تصادفی (RCT) به این ترتیب مرود بررسی قرار گرفت که از این تعداد، 318 RCT، منابع منابع مالی را گزارش دادهاند. از این جهت مشخص شد که 219 (69٪) مورد، بودجهای از صنعت برای انجام فرا تحلیل دریافت کردهاند. یعنی یک یا چند نویسنده که ارتباط مالی با صنعت داروسازی دارند در این فرا تحلیل نقش داشتهاند. از بین 509 مورد 132 مطالعه، نشانگر اختلافات منافع نویسنده با فرا تحلیل بودند و 91 مطالعه (69٪) فاش کردند كه یک یا چند نویسنده رابط اقتصادی با صنعت دارند. با این حال، اطلاعات به ندرت در فرا تحلیلها منعکس مشود. فقط دو (7٪) از مطالعات فرا تحلیل منابع بودجه را گزارش کردهاند که هیچ ارتباطی بین نویسنده و صنعت وجود نداشته است.
به عنوان مثال، در سال 1998، یك قاضی فدرال آمریكا دریافت كه آژانس حفاظت از محیط زیست آمریكا از فرایند فرا تحلیل سوء استفاده كرده است تا مطالعهای را انجام دهد كه ادعا میكند خطر ابتلا به سرطان برای افراد غیر سیگاری از دود دخانیات محیطی (ETS) وجود ندارد. به این ترتیب مشخص میشد که باید از ایجاد مکانهای مربوط به اتاق سیگار جلوگیری شود.

کاربرد فرا تحلیل در علم مدرن
فرا تحلیل آماری مدرن چیزی بیش از ترکیب اندازه اثرات مجموعه مطالعات با استفاده از میانگین وزنی انجام میدهد. یک فرا تحلیل میتواند آزمونی انجام دهد که مشخص کند آیا نتایج مطالعات، تنوع بیشتری نسبت به تنوع مورد انتظار به دلیل نمونهگیری تعداد مختلف شرکت کنندگان در تحقیق را نشان میدهد. علاوه بر این، ویژگیهای مطالعه مانند ابزار اندازهگیری مورد استفاده، نمونهگیری از جمعیت، یا جنبههایی از طراحی مطالعات و تحقیقات میتوانند به شکل تغییر کنند تا منجر به کاهش واریانس برآوردگر نهایی شود. البته مشخص است که چنین امری وابسته به ارائه مدلهای آماری است.
بنابراین برخی از ضعفهای روش شناختی در مطالعات میتوانند از نظر آماری اصلاح و در نتیجه به شکل صحیح مورد استفاده واقع شوند. کاربردهای دیگر روشهای فرا تحلیل شامل توسعه و اعتبارسنجی مدلهای پیش بینی است، جایی که ممکن است از فرا تحلیل برای ترکیب دادههای محققیان و دانشمندان از مراکز مختلف استفاده شده و یک ارزیابی عمومی برای مدلهای ارائه شده تعیین شود.
فرا تحلیل منجر به تغییر از رویکرد مطالعات تکی به مطالعات متعدد و تجمیعی میشود. به جای اهمیت دادن به تحقیقهای آماری و مطالعات فردی، به کارگیری از تجمیعسازی نظرات و تحقیقها در فرا تحلیل تاثیر نتایج و پیشبینیها را بیشتر میکند بطوری که این نوع رویکرد را میتوان «تفکر فرا-تحلیلی» (meta-analytic thinking) نامید. نتایج یک فرا تحلیل را میتوان در قالب یک نمودار درختی یا جنگلی (frost plot) نشان داد.
در فرا تحلیل، نتایج حاصل از مطالعات با استفاده از روشهای مختلف ترکیب میشوند. یک رویکرد که اغلب در فرا تحلیلهای مراقبتهای بهداشتی مورد استفاده قرار میگیرد، «روش واریانس معکوس» (inverse variance method) است.
اندازه متوسط اثر در تمام مطالعات به عنوان میانگین وزنی محاسبه میشود، بدین ترتیب وزنها با واریانس معکوس برآوردگر اثر هر مطالعه برابر است. در این حالت مطالعات بزرگتر با تنوع کمتر تصادفی نسبت به مطالعات کوچکتر وزن بیشتری به دست میآورند. سایر رویکردهای متداول شامل روش «مانتل-هنزل» ( Mantel–Haenszel method) و «روش پتو» (Peto Method) است.
از شیوههای دیگر میتوان به نقشه اختلاف علامتدار (Signed Difference Method) اشاره کرد که از آن برای بررسیهای مربوط به تفاوت فعالیت مغز با استفاده از دستگاههای تصویربرداری عصبی مانند fMRI ، VBM یا PET استفاده میشود. از روشهای مختلف فرا تحلیل برای بررسی دادههای با ابعاد بالا، مانند ریزآراییها برای درک بیان ژن نیز استفاده شده است. همچنین فرا تحلیل به منظور تجمیع و ایجاد یک روش برای شناسایی یا تعیین پروفایلهای بیان MicroRNA در سلول یا نوع بافت یا شرایط بیماری خاص یا برای بررسی تأثیر درمان استفاده شده است.
خلاصه و جمعبندی
در این نوشتار با مفهوم فرا تحلیل و کاربردهای آن بخصوص از جنبه آماری آشنا شدید. واضح است که با توجه به رشد تحقیق و پژوهش در حوزههای مختلف، راه کاری برای ترکیب نتایج حاصل از آنها ضروری است. به همین علت فرا تحلیل (Meta Analysis) امروزه در بیشتر دانشگاهها و مراکز تحقیقات صورت میگیرد. از طرفی فرا تحلیل سعی در کاهش خطای ترکیب از پژوهشها را هم به عهده دارد. در نتیجه، حاصل گزارشات فرا تحلیل دارای دقت مناسب نسبت به یک مطالعه یا پژوهش فردی دارد.
همچنین نقاط ضعف و مزایایی استفاده از فرا تحلیل نیز مورد اشاره قرار گرفت. به این ترتیب هنگام استفاده از تجمیع مطالعات و تحقیقها باید دقت شود که سوگیری یا اریبی در نتایج ایجاد نشود. به کارگیری فرا تحلیل بدون توجه به گستردگی موضوع تحقیقات و اندازه اثر یا واریانس برآوردگرهای ارائه شده در تحقیقات انفرادی ممکن است نتایج متناقضی ایجاد کند. بنابراین باید با توجه به اهمیت یا وزن هر یک از تحقیقات، نقش آنها را در محاسبه میانگین وزنی تعیین کرده و خطای برآودرگر حاصل را کمتر از هر یک از برآوردگرهای قبلی بدست آورد.











مطالب نظری بسیار خوبی نوشته بودید. اما بهتر بود این مراحل را نرم افزار cma هم آموزش می دادید. ممنون
سلام و وقت بخیر.متشکرم از وبلاگ مفیدتون. ممنون میشم در مورد فراتحلیلی که چند سالی هست امده است مطلب بگذاریدفرا تحلیل overview.
هر چه در نت جستجو کردم مطلبی پیدا نکردم متاسفانه و باید برای استادم مطلبی در این مورد بفرستم.