



درخت تصمیم در SPSS – راهنمای کاربردی
یکی از ابزارهای مهم و موثر در تصمیمگیری، درخت تصمیم (Decision Tree) است. این روش به منظور مدلسازی در مسائل یادگیری ماشین (Machine Learning) نیز به کار میرود. در این نوشتار به بررسی درخت تصمیم در SPSS خواهیم پرداخت. البته در ابتدا اصطلاحات و مفاهیم اولیه مربوط به درخت تصمیم را نیز مرور خواهیم کرد. همچنین برمبنای یک مجموعه داده از فایلهای آموزشی SPSS، نحوه ایجاد و ویرایش درخت تصمیم را اجرا و فرا خواهیم گرفت.


برای آشنایی بیشتر با درخت تصمیم و کاربردهای آن میتوانید مطلب همه چیز در مورد درخت تصمیم (Decision Tree) را مطالعه کنید. از آنجایی که یکی از کاربردهای درخت تصمیم در مدلسازی و رگرسیون خطی و لجستیک است، خواندن نوشتار رگرسیون خطی — مفهوم و محاسبات به زبان ساده و رگرسیون لجستیک (Logistic Regression) — مفاهیم، کاربردها و محاسبات در SPSS نیز خالی از لطف نیست.
درخت تصمیم در SPSS
درخت تصمیم ابزاری برای اتخاذ تصمیم مناسبتر است بطوری که شکل و ساختاری درختی (Tree Structure) یا سلسله مراتبی (Hierarchical) به تصمیمات و نتایج آنها میبخشد. ساختار این درخت میتواند برمبنای شانس و احتمال نیز باشد، بطوری که انتخاب هر تصمیم به طور تصادفی میتواند ریسک یا مزایایی به همراه داشته باشد.
گاهی اوقات برای نمایش گزارههای شرطی و نتایج حاصل از ترکیب آنها از درخت تصمیم نیز استفاده میشود. امروزه از درخت تصمیم برای نمایش عملیات سلسله مراتبی (Hierarchical Operators) و بخصوص تحلیل تصمیمات صورت گرفته برای رسیدن به هدف (Hierarchical Decision Making) استفاده میشود. به این ترتیب میتوان درخت تصمیم را یکی از ابزارهای مناسب در حوزه یادگیری ماشین و حتی مدیریت سطح بالا، در نظر گرفت.
درخت تصمیم شبیه یک نمودار گردش عملیات (Flow Chart) است که در آن هر گره (node) به صورت یک آزمایش (Experiment) در نظر گفته میشود. از طرفی هر شاخه نیز بیانگر نتایج حاصل از این آزمایش است. به این ترتیب برگهای هر شاخه نیز شامل شماره تصمیم اتخاذ شده یا برچسب کلاسبندی در خوشهبندی یا طبقهبندی خواهد بود. مسیری که از ریشه به برگها طی میشود، بیانگر قوانین طبقهبندی یا ردهبندی (Rules) است. این اجزا نیز هنگام ایجاد درخت تصمیم در SPSS نیز تولید میشوند و به خوبی قابل مشاهده هستند.
مفاهیم اولیه درخت تصمیم
همانطور که اشاره شد، درخت تصمیم دارای گرههای متفاوتی است که در ادامه با انواع آنها به عنوان ابزارهای اولیه رشد درخت تصمیم آشنا میشویم. در حقیقت یک درخت تصمیم از گرههای مختلفی تشکیل شده است. اتصال گرههای مختلف و البته با وظایف متفاوت، یک درخت تصمیم را تشکیل میدهد.
- گره (Node): گره ساختاری است که میتواند دارای یک ارزش یا مقدار خاص یا بیان یک شرط باشد.
- ریشه (Root): اولین و بالاترین گره در یک درخت تصمیم، ریشه نامیده میشود. بخشهای دیگر درخت تصمیم از ریشه آغاز و نشات میگیرند.
- والد (Parent): گرهای که دارای فرزند باشد. به این معنی که گرهای در سطح پایینتر به آن متصل است.
- فرزند (Child): گرهای است که به طور مستقیم به گره دیگری متصل است و در سطح پایینتری از گره والد قرار گرفته است.
- شاخه (Branch): شاخه، گرهای است که حداقل دارای یک فرزند (Child) است.
- ...
مفاهیم زیادی در مورد درختها وجود دارد که توضیح همه آنها ممکن است از حوصله این نوشتار خارج باشد. به این ترتیب در اینجا فقط به مواردی اشاره میکنیم که در این متن بیشتر مورد بحث قرار میگیرند.
با توجه به مفهومی که برای گره بیان شد، میتوان سه نوع عملکرد برای گره در درخت تصمیم در نظر گرفت. به این ترتیب گرهها (Node) میتواند یکی از سه نوع زیر باشند.
- گره تصمیم (Decision Node): این گرهها با علامت مربع در درخت تصمیم نشان داده میشوند.
- گره شانس (Chance Node): این گرهها در درخت تصمیم با علامت دایره مشخص میشوند.
- گره پایانی (Terminal Node): گرههای پایانی بیانگر روند تصمیمگیری در یک درخت تصمیم هستند و با علامت مثلث نشان داده میشوند.
در تصویر زیر یک نمونه از درخت تصمیم را مشاهده میکنید.

جهت درخت در تصویر بالا، از چپ به راست است به این معنی که ریشه آن در سمت چپ قرار گرفته و گره پایانی در سمت راست است. ممکن است درخت تصمیم دارای فرآیندهای متنوع و پیچیدهای باشد، در نتیجه رسم آن با دست تقریبا کاری غیرممکن خواهد بود. نرمافزارهای متعددی وجود دارند که به کمک آنها قادر به ترسیم درخت تصمیم هستیم. در این نوشتار به بررسی نحوه ترسیم درخت تصمیم و استفاده از آن در SPSS میپردازیم.
نکته: شیوه نمایش درختها در برنامههای رایانهای قدری با یکدیگر متفاوت هستند. از آنجایی که در این نوشتار به بررسی نحوه ایجاد درخت تصمیم در نرمافزار SPSS، پرداختهایم، تصویر ایجاد شده درخت تصمیم در SPSS ممکن است با با تصویر بالا قدری متفاوت باشد.
روشهای رشد درخت تصمیم
یکی دیگر از اصطلاحات به کار رفته در درخت تصمیم، مفهوم رشد درخت است. به این ترتیب با طی کردن یک مسیر از ریشه به هدف خواهیم رسید. این مسیر به عنوان نحوه رشد درخت در نظر گرفته میشود. به منظور توسعه و رشد درخت، تکنیکهای مختلفی وجود دارد که در ادامه به برخی از آنها اشاره میشود. توجه داشته باشید که درخت تصمیم در این متن به منظور تعیین ارتباط بین دو یا چند متغیر کمی و کیفی به کار رفته است. هر چند این مدل ارتباطی میتواند به صورت یک تحلیل رگرسیونی نیز ارائه شود ولی در اینجا مدل رگرسیونی را برای هر طبقه یا سطح از درخت تصمیم جداگانه در نظر میگیریم.
روش CHAID
در روش CHAID، که به «شناسایی اثرات متقابل خودکار کای ۲» (Chi-squared Automatic Interaction Detection) نیز شهرت دارد، در هر گام، متغیر پیشگویی که بیشترین میزان ارتباط با متغیر وابسته را دارد در مدل و درخت تصمیم به کار میرود. سطوح یا طبقههای هر متغیر پیشگو ممکن است در این حالت با یکدیگر ادغام شوند زیرا سطح معنیداری ممکن است در هر طبقه کمتر از مقدار مورد انتظار باشد. محاسبه آماره کای ۲ و محاسبه سطح معنیداری و رد فرض صفر در آزمون با سطح ، باعث ایجاد گره جدید خواهد شد. به این ترتیب شاخهها تولید شده و درخت تصمیم رشد میکند.
مشخص است که در این صورت با یک درخت برمبنای احتمال و محاسبات آماری مواجه هستیم.
روش جامع CHAID یا Exhaustive CHAID
یک شیوه دیگر برای رشد درخت میتواند به کارگیری تکنیک ترکیبی از CHAID باشد که در آن تمامی حالتهای مختلف ترکیب سطوح متغیرهای پیشگو در نظر گرفته شود. به همین علت آن را روش جامع CHAID مینامند. هر چند این شیوه ممکن است که زمان زیادی به خود اختصاص دهد ولی دقت آن بیشتر از روش CHAID است.
روش دستهبندی و درخت رگرسیون (CRT)
در روش CRT یا دستهبندی و درخت رگرسیون (Classification and Regression Trees)، دادهها به بخشهایی که برحسب متغیر پاسخ، متجانس هستند، تقسیم میشوند. گره پایانی (Terminal Node) برای همه مشاهداتی که دارای متغیر وابسته برابری هستند، گره خالص (Pure Node) نامیده شده و به این ترتیب گروهها یا دستهها تشکیل میشوند.
روش درخت آماری سریع، نااریب و کارا (QUEST)
روش QUEST یا درخت آماری سریع، نااریب و کارا (Quick, Unbiased, Efficient Statistical Tree) به نسبت روشهای دیگر سریعتر است و از اریبی (Bias) به نفع متغیری که دارای طبقههای بیشتری است، جلوگیری میکند. از این روش فقط در صورتی که متغیر وابسته با مقیاس اسمی (Nominal) باشد، میتوان استفاده کرد.
جدول زیر به مقایسه ویژگیهای این روشهای پرداخته است.
| ردیف | شرح | CHAID | CRT | QUEST |
| ۱ | برمبنای کای ۲ | بله | - | - |
| ۲ | جایزگزینی متغیرهای مستقل (پیشگو) | - | بله | بله |
| 3 | امکان هرس درخت | - | بله | بله |
| 4 | تفکیک گره چند راهه | بله | - | - |
| 5 | تفکیک گره دو دویی | - | بله | بله |
| 6 | متغیرهای تاثیرگذار | بله | بله | - |
| 7 | استفاده از احتمال پیشین | - | بله | بله |
| 8 | تابع هزینه بد ردهبندی | بله | بله | بله |
| 9 | محاسبه سریع | بله | - | بله |
نکته: در روش QUEST، برای متغیرهای مستقل با مقیاس اسمی (Nominal Measurement) از آماره کای ۲ استفاده میشود. همچنین در جدول بالا، خصوصیاتی که برای روش CHAID ذکر شده، برای روش جامع CHAID نیز وجود دارد.
کاربردهای درخت تصمیم
کارکردهای متفاوتی برای درخت تصمیم میتوان در نظر گرفت. در ادامه بعضی از این کاربردها و حوزههایی که استفاده از درخت تصمیم موثر واقع میشوند، معرفی خواهند شد.
- دستهبندی (Segmentation): شناسایی افرادی که شبیه اعضای گروههای خاصی هستند.
- طبقهبندی (Stratification): تقسیمبندی مشاهدات به چندین طبقه مثلا طبقهبندی مشتریان به گروههای کم ریسک، ریسک متوسط و پر خطر.
- پیشبینی (Prediction): ایجاد یا شناسایی قوانینی که به کمک آن قادر به پیشبینی رخداد یک پیشامد باشیم، برای مثال تشخیص اینکه با چه احتمالی، فرد قادر به پرداخت اقساط وام خانه یا خودرو نخواهد بود.
- کاهش بعد داده یا غربالگری متغیرها (Data reduction and variable screening): انتخاب یک زیر مجموعه مناسب از متغیرهای پیشگو که بیشترین رابطه را با متغیر وابسته داشته باشند و از طرفی از دست دادن اطلاعات در متغیرهای حذف شده، کمترین میزان خود را داشته باشد تا بتوان به یک مدل پویا بهینه دست یافت.
- شناسایی اثرات متقابل (Interaction Identification): شناسایی ارتباط بین متغیرهای کیفی (یا گروهها) و ایجاد یک مدل پارامتری برای بیان این ارتباطها.
- ادغام متغیرهای طبقهای یا طبقهای کردن متغیرهای کمی (Category merging and discreetize continuous variables): ترکیب و کدبندی متغیرهای پیشگو به متغیرهای طبقهای یا متغیرهای کمی به متغیرهای کیفی با کمترین میزان کاهش اطلاعات.
به منظور وضوح بیشتر به ذکر یک مثال میپردازیم.
مثال 1
فرض کنید یک بانک میخواهد کسانی که کارتهای اعتباری دریافت نمودهاند را برحسب متغیرهای مختلف، دستهبندی کند. این دستهها ممکن است برحسب رفتار مشترهای پیشین بانک صورت بگیرد. به این ترتیب قبل از اینکه مشتری جدیدی کارت اعتباری دریافت کند، بانک قادر است ریسک کارت اعتباری این فرد را حدس بزند. این کار با توجه به مقادیر متغیرهای پیشگو که از طریق فرمهای ثبت نام مشتریان قبلی دریافت کرده، صورت میگیرد.
به این ترتیب بانک قادر است مشتری جدید را براساس اطلاعاتی که در فرم تقاضا ثبت کرده، در یکی از گروههای پر خطر یا خوش حساب قرار دهد. این امر ریسک بانک را بسیار کاهش میدهد و از هزینههای آن میکاهد. به این ترتیب به کمک تحلیل درخت تصمیم، میتوان گروههایی متجانس تشکیل داد که دارای ریسک بالا یا ریسک کم در دریافت کارت اعتباری نزد بانک هستند.
همچنین به عنوان کارمند یا مدیریت بخش اعتبارات بانک، میتوانیم قوانینی ایجاد کنیم که براساس آنها، رفتار هر مشتری را از قبل پیشبینی کنیم. در این مطلب با توجه به محبوبیت نرمافزار SPSS با نحوه ترسیم چنین درختی در این نرمافزار آشنا خواهیم شد و سپس مثال ۱ را پی میگیریم.
ایجاد درخت تصمیم در SPSS
یکی از شیوههای دستهبندی (Classification)، استفاده از درخت تصمیم است. در نرمافزار SPSS نیز امکان تحلیل درخت تصمیم وجود دارد. به این ترتیب براساس یک یا دستهای از متغیرهای پیشگو (Predictors) میتوان مقادیر یک متغیر وابسته یا هدف (Target) را حدس زد.

هنگامی که میخواهید در SPSS یک درخت تصمیم ایجاد کنید باید موضوعاتی را در نظر بگیرید.
- دادهها باید بطور مناسب انتخاب شوند. متغیر مستقل و متغیر وابسته میتوانند کمی یا کیفی باشند ولی هر جا احتیاج به متغیر طبقهای یا ترتیبی دارید باید از مقیاس اندازهگیری از نوع اسمی (Nominal) یا ترتیبی (Ordinal) استفاده کنید.

- فراوانی نسبی یا وزن در درخت تصمیم به صورت گرد شده در SPSS به کار میرود. بنابراین اگر وزن مشاهداتی کمتر از 0٫۵ باشد، به طور خودکار وزن به صفر تغییر خواهد کرد و در نتیجه آن مشاهدات از تحلیل خارج خواهند شد.
- باید برای همه متغیرها طبقهای (اسمی و ترتیبی) برچسب مقادیر (Value Labels) در نظر بگیرد. اگر این کار را به درستی انجام ندهید ممکن است بسیاری از مشاهدات در تحلیل درخت تصمیم به کار نروند.
نکته: برای تغییر خصوصیات متغیرها و تعیین ویژگی مقیاس از دستور Define Variables Properties استفاده کنید.
پس از بررسی صحت ویژگیها گفته شده برای متغیرها، میتوانید درخت تصمیم را بسازید. به این منظور مراحل زیر را طی کنید.
- از فهرست Analyze گزینه Classify و دستور Tree را اجرا کنید.
- متغیر وابسته را در کادر مربوطه (Dependent Variable) قرار دهید.
- متغیر یا متغیرهای پیشگو را در کادر (Independent Variables) قرار دهید.
- نوع یا روش رشد درخت را یکی از حالات CHAID، CRT یا QUEST انتخاب کنید. این کار باید با توجه به ویژگیهایی که این روشها دارند، انجام شود.
- تنظیمات دیگر نظیر تعیین شکل خروجی (Output)، اعتبار سنجی (Validation) یا محدودیتهای مدل (Criteria) و همچنین نحوه ذخیره کردن (Save) نتایج دستورات را تعیین کنید.
- با فشردن دکمه OK خروجی در پنجره Output ظاهر میشود و با دوبار کلیک قادر به ویرایش درخت تصمیم در پنجره مخصوص Tree Editor خواهید بود.
مثال 2
این مثال مرتبط با مثال ۱ است. مجموعه داده tree_credit را در نظر بگیرید که در مجموعه دادههای آموزشی SPSS قرار دارند. البته میتوانید این فایل اطلاعاتی SPSS را با کلیک روی (+) با قالب فشرده دریافت کنید. در ادامه قسمتی از این مجموعه داده را مشاهده میکنید.
همانطور که مشخص است این مجموعه داده، شامل شش متغیر است. جدول زیر به بررسی خصوصیات این متغیرها پرداخته است. توجه داشته باشید که با توجه به ماهیت درخت تصمیم، متغیرهای طبقهای میتوانند به عنوان متغیر وابسته (Dependent) در نظر گرفته شوند.
| نام | مشخصات | ویژگی |
| Credit_rating | وضعیت اعتبار مشتری در بانک | اسمی (Nominal)- دو سطحی (Binary) با مقادیر Bad, Good- بدون مقدار گمشده (Missing Value) |
| Age | سن مشتری | مقیاس (Scale)- مقدار پیوسته (Continuous) |
| Income | سطح درآمدی | ترتیبی (Ordinal)- دارای سه سطح
1= Low , 2= Medium , 3= High. |
| Credit_cards | تعداد کارتهای اعتباری مشتری | اسمی (Nominal)- دو سطحی (Binary) با مقادیر
Less Than 5 = 1 , 5 or more = 2. |
| Education | سطح تحصیلات | اسمی (Nominal)- دو سطحی (Binary) با مقادیر
High School = 1, College =2. |
| Car_Loans | دفعات دریافت وام خودرو | اسمی (Nominal)- دو سطحی (Binary) با مقادیر
None or one = 1, More than 2 |
میخواهیم به واسطه متغیرهای سطح درآمدی و تعداد کارتهای اعتباری مشتری، وضعیت اعتبار مشتری در بانک را حدس بزنیم. در نتیجه اینجا، متغیر وابسته (Dependent Variable) همان Credit_rating است و متغیرهای مستقل (Independent) یا پیشگو هم، income و Credit_cards خواهند بود. تصویر زیر پنجره مربوط به تنظیم این پارامترها را نشان میدهد. واضح است که برچسب متغیرها (مانند Number of Credit cards) در ابتدا دیده میشود سپس نام متغیرها در داخل علامت براکت (مانند [Credit_cards]) قرار گرفته است.

نکته: چنانچه بخواهید یک یا بعضی از سطوح متغیر وابسته را از درخت تصمیم حذف کنید، از دکمه Categories استفاده کنید. در تصویر زیر محتویات این پنجره دیده میشود.

از آنجایی که برای این متغیر مقدار ۹۹ به عنوان مقدار گمشده (Missing) در نظر گرفته شده است، نرمافزار SPSS بطور خودکار این سطح از متغیر وابسته را از درخت تصمیم حذف کرده و در کادر Exclude قرار داده است. البته میتوانید خودتان به صورت دستی این کار را انجام دهید.

پس از فشردن دکمه OK خروجی به صورت زیر ظاهر خواهد شد. در قسمت ابتدایی خروجی، خلاصهای از مدل با نام Model Summary ظاهر میشود که شامل مواردی مانند، روش رشد درخت و اسامی متغیرهای وابسته و مستقل و همچنین تعداد شاخههای درخت است.

همانطور که مشاهده میکنید در بخش Specification شرایط ایجاد درخت که مطابق با تنظیمات پیشفرض SPSS است، ذکر شده. برای مثال حداقل تعداد مشاهدات در گرههای والد ۱۰۰ و در گرههای فرزند ۵۰ است. همچنین حداکثر عمق درخت نیز ۳ در نظر گرفته شده است.
پس از اجرای مدلسازی توسط درخت تصمیم، نتایج در این جدول در بخش Results، نمایش داده شده که شامل تعداد گرهها (Number of Nodes) بامقدار برابر با ۱۰ و تعداد گرههای پایانی (Terminal Nodes) برابر با ۶ است. عمق درخت که نشانگر تعداد گرهها از ریشه تا گرههای پایانی است نیز ۲ محاسبه شده است.
نمودار درختی (Tree Structure) نیز در ادامه خروجی ظاهر میشود. همانطور که دیده میشود، ابتدا متغیر وابسته Credit rating قرار گرفته که گره ریشه را تشکیل میدهد. همچنین متغیر Income Level به علت داشتن مقدار کای ۲ (Chi-square) بزرگتر نسبت به بقیه متغیرهای مستقل، به عنوان اولین گره (گره والد) انتخاب شده است. با توجه به اینکه این متغیر دارای سه سطح است، سه شاخه مختلف نیز ایجاد شده است. در گام بعدی متغیر تعداد کارتهای اعتباری (Credit_cards)، شاخهها را ایجاد کرده است و به عنوان گرههای والد شناخته شدهاند.

در هر سطر از این نمودار، مجموع مقادیر در قسمت Total در هر گره، با مجموع مشاهدات در هر دسته برابر است. برای مثال در شاخههایی که توسط گره Income بوجود آمده است، افرادی که در سطح درآمدی پایین (Low) هستند برابر با 553 بوده و افراد در سطح درآمد متوسط (Low,Medium) نیز 1134 نفر هستند. اگر این دو را با تعداد کسانی که در سطح درآمدی بیشتر از متوسط (>medium) قرار دارند جمع کنیم به همه مشاهدات یعنی 2464 خواهیم رسید. همانطور که مشخص است، در هر یک از این سطوح، درصد و تعداد افرادی که در گروه Bad یا Good قرار گرفتهاند، مشخص شده است.
در انتها نیز، ارزیابی مدل توسط محاسبه ریسک و درصد موفقیت ردهبندی (Classification) دیده میشود.

مشخص است که برآورد ریسک (خطای مدل) که در جدول Risk محاسبه شده، حدود ۲۲ درصد است. همچنین در بخش Classification نیز درصد موفقیت در ردهبندی دو طبقه Bad و Good دیده میشود. میزان موفقیت در نمونه موجود برای تشخیص رده Bad برابر با ۸۲٫۶ درصد و برای رده Good، تقریبا برابر با ۷۴٫۵ درصد است. در حقیقت میتوان جدول Classification را در اینجا به مانند یک ماتریس درهمریختگی (Confusion Matrix) در نظر گرفت. به کمک این جدول میتوان شاخصهای دیگر صحت عملکرد ردهبندی مانند صحت و حساسیت را هم محاسبه کرد.
اگر میخواهید قواعدی که برای استخراج درخت تصمیم استفاده شده را مشاهده کنید، لازم است در پنجره Decision Tree و با استفاده از دکمه Output و برگه Rules گزینه را فعال کنید.

نکته: اگر فقط از جنبه فراوانی به این نمودار نگاه کنیم، میتوانیم نتیجه آن را با یک جدول فراوانی یا توافقی (Contingency Table) سه طرفه (مانند Crosstabs) مقایسه کنیم. در زیر یک پنجره مربوط به پارامترهای جدول توافقی در SPSS را مشاهده میکنید که براساس مثال 1 ایجاد شده است.

در ادامه نتیجه اجرای جدول توافقی سه طرفه محاسبه شده توسط دستور Crosstabs را برحسب متغیرهای به کار رفته در مثال مشاهده میکنید. البته توجه داشته باشید که درصدها را برحسب سطر (Row) محاسبه کردهایم.

ویرایش درخت تصمیم در SPSS
همانطور که گفته شد، با دوبار کلیک بر روی درخت تصمیم، وارد پنجره ویرایش درخت (Tree Editor) خواهید شد.
امکاناتی که به صورت فهرستوار به آن اشاره میکنیم در این پنجره در اختیارتان قرار دارد.
- نمایش یا مختلف کردن شاخههای درخت.
- تنظیم نحوه نمایش محتویات گرهها مانند شاخصهای آماری.
- تغییر رنگ زمینه، حاشیه و قلم نوشتههای درون گره.
- تغییر تراز درخت.
- امکان انتخاب بعضی از مشاهدات به منظور انجام تحلیلهای بیشتر براساس گرههای انتخابی.
- ایجاد و ذخیرهسازی قواعد انتخاب یا امتیازدهی مشاهدات براساس گرههای انتخابی.
در تصویر زیر یک نمونه از پنجره ویرایش درخت تصمیم در SPSS را مشاهده میکنید.
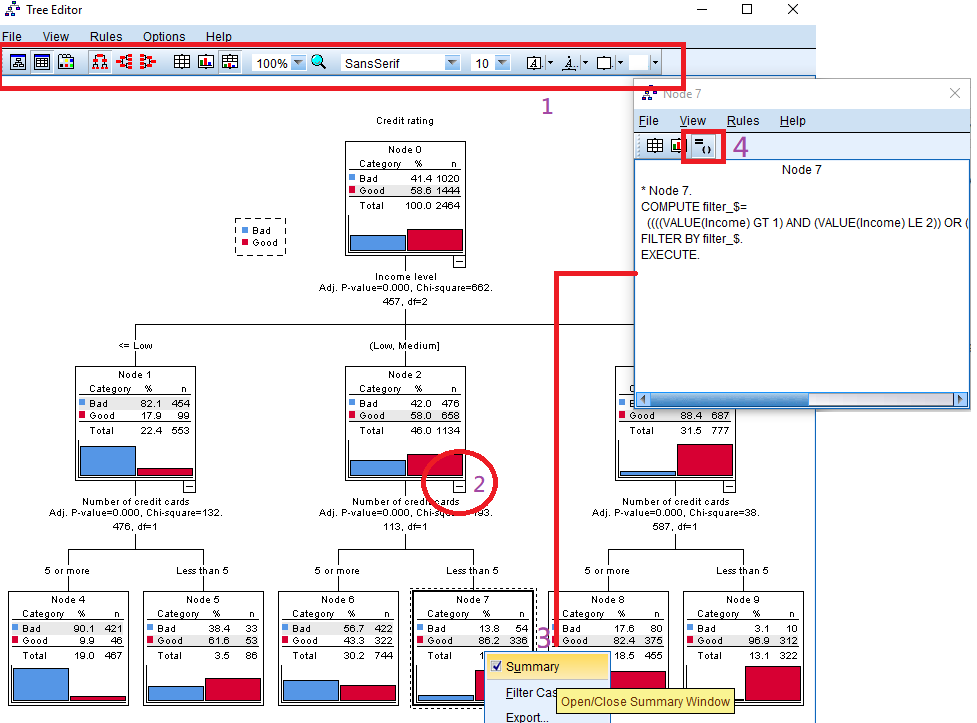
در بخش شماره ۱، گزینههایی برای تغییر درخت تصمیم در SPSS روی نوار ابزار، قرار گرفته است. البته نوار فهرست (Menu Bar) نیز دستورات را به صورت متنی ارائه میکند. با استفاده از علامت نیز که با شماره ۲ مشخص شده، میتوانید بخشی از خروجی درخت تصمیم را مخفی (Hide) یا ظاهر (View) کنید. اگر روی یک گره (Node) کلیک راست کنید، فهرستی از دستورات برای نمایش محتویات آن گره نمایش داده شده که با انتخاب گزینه Summary پنجره مربوط به خصوصیات آن گره را به صورت جداگانه خواهید دید. اگر میخواهید فرمول محاسباتی و قانون ایجاد آن گره را ببنید کافی است که با کلیک راست (با توجه به شماره ۳) روی گره، از پنجره ظاهر شده، گزینه شماره ۴ را مطابق تصویر انتخاب کنید. این کدها با توجه به کدنویسی زبان دستوری SPSS یعنی Syntax نمایش داده میشود.
نکته: یک روش دیگر برای ویرایش درخت، آن است که پس از انتخاب آن، از فهرست Edit و انتخاب گزینه Edit Content، پنجره Tree Editor را ظاهر کنید.
پیشبینی مقادیر برای مشاهدات جدید در درخت تصمیم
اگر لازم است مقدار متغیر پاسخ (وابسته) را برحسب مقادیر مشاهده شده برای متغیرهای پیشگو، بدست آورید، کافی است در پنجره Decision tree، دکمه Save را انتخاب کنید و گزینههای مربوطه را انتخاب کنید.

در تصویر بالا، با توجه به انتخابهای صورت گرفته، مقدار گره پایانی برای مشاهده مورد نظر (Terminal node number)، مقدار پیشبینی شده برای متغیر وابسته (Predict Value) و برآورد احتمال پیشبینی (Predicted probability) برای تعلق به هر گروه نیز آورده میشود. توجه داشته باشید که نتیجه حاصل از این انتخابها در پنجره ویرایشگر داده (Data Editor) ظاهر خواهد شد.
برای مثال فرض کنید که مقدار متغیر پاسخ را برای دو مشاهده آخر حذف کردهایم و میخواهیم به کمک درخت تصمیم، نتیجه حاصل از محاسبات را برای پیشبینی متغیر وابسته مشاهده کنیم. نتیجه اجرای درخت تصمیم با تنظیمات گفته شده، مطابق با تصویر زیر خواهد بود.
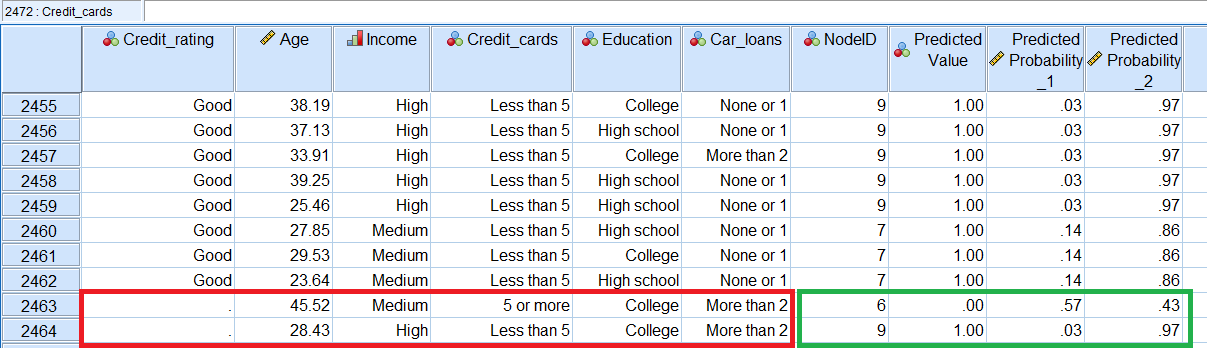
در کادر قرمز رنگ، متغیرهای مستقل دیده میشود و نتیجه ذخیرهسازی پیشبینیها در کادر سبز نمایش داده شده است. همانطور که مشاهده میکنید، مشاهده 2463 در گره شماره ۶ و 2464 در گره 9 قرار گرفته است. مقدار پیشبینی شده برای Credit_rating مشاهده 2463 نیز 0 (Bad) محاسبه و برای مشاهده 2464 تعلق به گروه 1 (Good) حاصل شده است. احتمال قرارگیری در گروه 0 نیز در ستون Predicted_probability_1 و احتمال قرارگیری در گروه 1 در ستون Predicted_Probability_2 دیده میشود.
جمعبندی و بررسی نتایج
در این نوشتار به بررسی درخت تصمیم (Decision Tree) و نحوه اجرای آن در SPSS آشنا شدیم. در این میان با روش CHAID یا «شناسایی اثرات متقابل خودکار کای ۲» (Chi-squared Automatic Interaction Detection) نیز آشنا شدیم و نحوه عملیات کردن این تکنیک را در SPSS فرا گرفتیم. در این میان خروجیهای حاصل از دستورات SPSS نیز مرور و مورد بررسی قرار گرفت.
اگر این مطلب برای شما مفید بوده است و علاقهمند به یادگیری بیشتر در این زمینه هستید، آموزشها و نوشتارهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای SPSS
- آموزش تکمیلی برنامهنویسی R و نرمافزار RStudio
- آنالیز واریانس (ANOVA) یک و دو طرفه در R — راهنمای کاربردی
- تحلیل واریانس (Anova) — مفاهیم و کاربردها
- تحلیل واریانس یک طرفه در پایتون — راهنمای گام به گام
^^











سلام خسته نباشین، چرا وقتی فایل داده رو باز میکنم، مقدار همه داده ها رو عددی نشون میده؟ مثلا income که توی تصویر مقادیر low, medium و .. داره، برام فقط عدد نشون میده..
ممنون میشم توضیح بدین
سلام من برای پایان نامه باید برای ارایه الگو از نرم افزار درخت تصمیم گیری باید استفاده کنم ولی بلد نیستم می خواستم ببینم کسی هست که بتونه کمکم کنه