



برآوردگر سازگار در آمار – به زبان ساده
«برآوردگر» (Estimator) و موضوع «برآوردیابی» (Estimation) در حوزه استنباط آماری، از مباحث مهم و البته کاربردی محسوب میشود. واضح و مشخص است که این بخش از آمار، با موضوعات برآمده از «آمار ریاضی» (Mathematical Statistics) مرتبط است. در این نوشتار به معرفی یکی از خصوصیات مفید برای هر برآوردگر میپردازیم که میتواند کلاسی از برآوردگرهای مفید ایجاد کند. برآوردگر سازگار در آمار، نوعی از برآوردگرهای دنبالهای است که با افزایش حجم نمونه به پارامتر جامعه نزدیک و نزدیکتر شده و اصطلاحاً به آن همگرا خواهد بود.
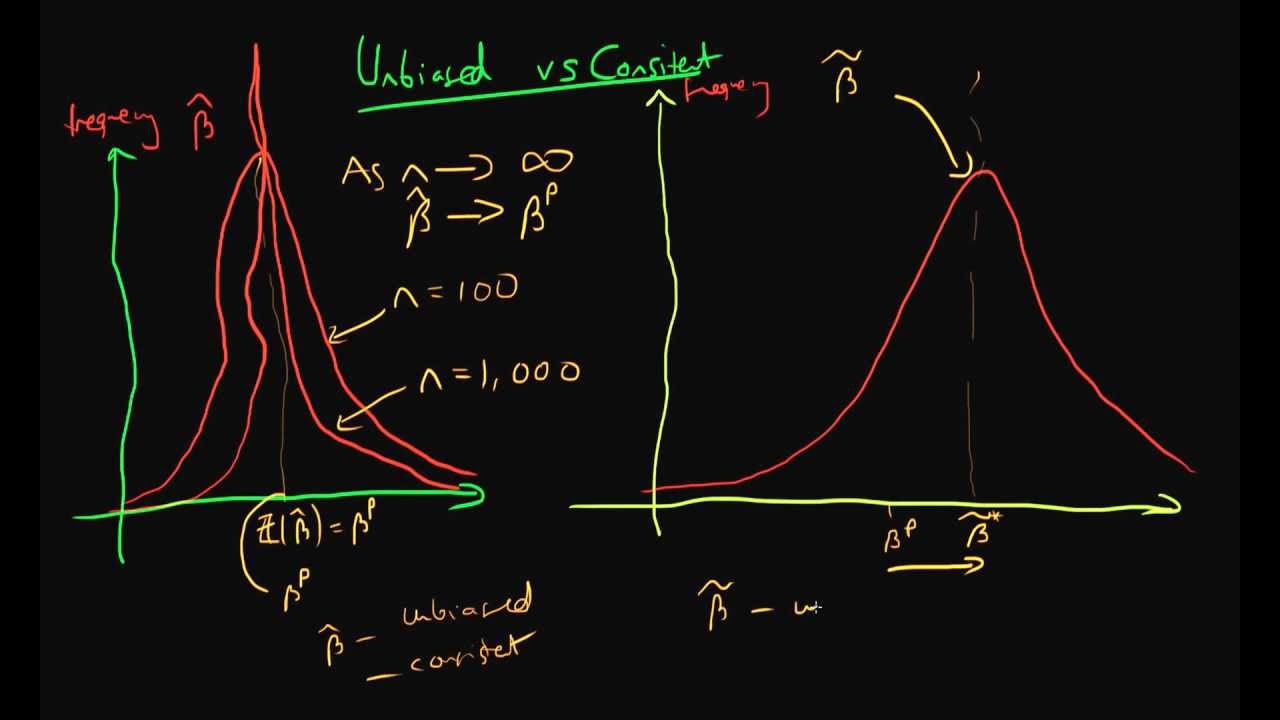


به عنوان مقدمه و آشنایی بیشتر با مباحث مربوط به این نوشتار، پیشنهاد میشود ابتدا مطالب برآوردگر اریب و نااریب — به زبان ساده و تابع درست نمایی (Likelihood Function) و کاربردهای آن — به زبان ساده را مطالعه کنید. همچنین خواندن استنباط و آزمون فرض آماری — مفاهیم و اصطلاحات و متغیر تصادفی، تابع احتمال و تابع توزیع احتمال نیز خالی از لطف نیست.
برآوردگر سازگار در آمار
نوع خاصی از برآوردگرها آماری، «برآوردگر سازگار» (Consistent Estimator) یا «برآوردگر مجانبی سازگار» (Asymptotically Consistent Estimator)، است که براساس یک قاعده خاص، مقدار پارامتر جامعه () را تخمین میزند.

در این بین هر چه تعداد مشاهدات یا نمونه تصادفی افزایش پیدا کند، میزان نزدیکی برآوردگر به مقدار پارامتر بیشتر خواهد شد و به اصطلاح برآوردگر سازگار به مقدار پارامتر «همگرا در احتمال» (Converges in Probability) خواهد بود.
در عمل، برآوردگر سازگار، به عنوان تابعی از نمونه تصادفی و البته تعداد آنها (مثلا ) مشخص میشود. به همین علت معمولا برآوردگرهای سازگار را با اندیس و به صورت دنبالهای از برآوردگرها مانند در نظر میگیرند، بطوری که حد تابع زمانی که تعداد نمونهها افزایش یابد، برابر با پارامتر خواهد بود.
البته موضوع همگرایی و نوع آن برای نشان دادن نزدیکی برآوردگر به پارامتر باید به شکل دقیقتری بیان شود که البته در ادامه متن به آن خواهیم پرداخت. به نظر میرسد این تعریف، ارتباطی با مفهوم اریبی و نااریبی برآوردگرها نیز دارد. در حقیقت برآوردگر سازگار، برآوردگری است که در حد و با افزایش تعداد نمونهها، نااریب (Unbiased) بوده و میزان اریبی آن صفر میشود.
نکته: اگر دنباله برآورگرهای همگرا به پارامتر نباشد، به آن «برآوردگر ناسازگار» (Inconsistent) میگویند.
تعریف برآوردگر سازگار در آمار
به طور رسمی، برآوردگر برای پارامتر را سازگار میگویند، اگر در احتمال (In Probablity) به پارامتر همگرا باشد.
این امر به این معنی است که توزیع دنباله برآوردگرها، به مقدار پارامتر نزدیک و نزدیکتر خواهد شد. بنابراین احتمال اینکه فاصله برآوردگر از پارامتر کمتر از هر مقدار دلخواهی باشد، برابر است با ۱. اگر یک برآوردگر سازگار برای باشد، آنگاه این موضوع را به بیان ریاضی به صورت زیر مینویسیم:
رابطه ۱
نکته: گاهی همگرایی در احتمال را برای برآورد سازگار به صورتهای دیگری نیز نشان میدهند که بعضی از آنها را در ادامه مشاهده میکنید. این نمادها، همگی به معنی برقراری و صادق بودن برآوردگر در رابطه ۱ هستند.
از آنجایی که پارامتر ، نامعلوم است، احتمال مربوط به رابطه ۱، باید برای همه اعضای فضای پارامتر نیز برقرار باشد. در نتیجه باید بوسیله یک تعریف دقیقتر، برآوردگر سازگار را معرفی کنیم.

تعریف برآوردگر سازگار برای همه اعضای فضای پارامتری
فرض کنید خانوادهای از توزیعهای (مدل پارامتری) بوده و نیز یک دنباله نامتناهی از نمونه تصادفی از توزیع باشد.
از طرفی دنباله برآوردگرهای را برای پارامتر در نظر بگیرید. آنگاه دنباله را «سازگار ضعیف» (Weakly Consistent) برای گوییم اگر رابطه زیر برقرار باشد.
رابطه ۲
همانطور که در رابطه ۲ مشاهده میکنید، برآوردگر برای به کار رفته است، چون در بعضی از مواقع لازم است تابعی از پارامتر را برآورد کنیم. به این ترتیب تعریف را برای هر تابعی از پارامتر، تعمیم دادهایم. اگر قرار باشد که فقط پارامتر توسط برآورد شود، کافی است را در نظر بگیریم.
نکته: اگر همگرایی برآوردگر به پارامتر به صورت «تقریبا مطمئن» (Almost Surely) باشد، برآوردگر را «سازگاری قوی» (Strong Consistent) گویند. در این حالت رابطه ۱ به صورت زیر در خواهد آمد.
رابطه ۳
در این حالت معمولا از نماد زیر برای نشان دادن سازگاری قوی استفاده میکنند. عبارت a.s مخفف Almost Surely یا «تقریبا مطمئن» است.
پیدا کردن برآوردگر سازگار در آمار
در این قسمت با استفاده از تعریفی که برای سازگاری طبق رابطه ۱، معرفی کردیم، نشان خواهیم داد که میانگین نمونهای، یک برآوردگر سازگار برای میانگین توزیع نرمال () است.
دنباله نمونه تصادفی از توزیع نرمال را در نظر بگیرید که در آن واریانس () معلوم و میانگین ( ) نامعلوم است. به منظور برآورد پارامتر از مشاهده اول ها استفاده کرده و برآوردگر را براساس رابطه زیر ایجاد میکنیم.
واضح است که ، تابع از نمونه تصادفی و تعداد آنها است، به این معنی که ثابت نیست. با توجه به خصوصیات توزیع نرمال، میدانیم که توزیع نمونهای آماره نیز نرمال خواهد بود.
پس باید مقدار احتمال زیر را برای سازگاری برآوردگر محاسبه کنیم.
با استفاده از استاندارد سازی (Standardize)، توزیع متغیر تصادفی (برآوردگر) را با یک تبدیل به توزیع نرمال استاندارد تغییر میدهیم.
در نتیجه داریم:
با توجه به نماد برای تابع توزیع تجمعی نرمال استاندارد، مقدار احتمال رابطه بالا برابر است با:
اگر از این احتمال برحسب حد بگیریم به رابطه زیر خواهیم رسید.
که همان رابطه ۱ را برای هر ثابت و مثبت، نشان میدهد. پس میانگین نمونهای برآوردگر سازگار برای میانگین جامعه توزیع نرمال () است.
ایجاد برآوردگر سازگار در آمار
سازگاری برآوردگر هم از نظر نمادگذاری و هم از نظر تعریف، با مفهوم همگرایی در احتمال (براساس رابطه ۱) نزدیک است. در نتیجه همه ابزارهایی که برای همگرایی در احتمال وجود دارد، برای برآوردگر سازگار نیز به کار خواهد رفت. به این ترتیب قضیهها و نامساویهایی که برمبنای احتمال وجود دارند، برای نشان دادن سازگاری برآوردگرها مورد استفاده قرار خواهند گرفت. در ادامه به بعضی از آنها خواهیم پرداخت.
استفاده از نامساوی مارکف و چبیشف
در نوشتارهای دیگر مجله فرادرس با نامساوی مارکف (Markov Inequality) و نامساوی چبیشف (Chebyshev Inequality) آشنا شدهاید و میدانیم که این نامساویها برای مقدار احتمال تجمعی یک متغیر تصادفی، کران بالا ارائه میدهند. در اینجا قصد داریم به کمک آنها، سازگاری یک برآوردگر را نشان دهیم.
نامساوی زیر را در نظر بگیرید.
رابطه ۴
اگر در اینجا تابع را قدر مطلق (Absolute Function) در نظر بگیریم، نامساوی مارکف و در صورتی که را تابع درجه دوم (Quadratic Function) انتخاب کنیم، نامساوی چبیشف حاصل میشود. بنابراین کافی است، طرف راست رابطه ۴ را براساس هر یک از این توابع، محاسبه کرده و نشان دهیم که این مقدار برابر با صفر است.
نکته: توجه داشته باشید که رابطه ۴، متمم مقدار احتمال مربوط به رابطه ۱ را محاسبه کرده است. پس باید طرف راست به جای ۱ با صفر برابر باشد.
قضیه نگاشت پیوسته
فرض کنید دنبالهای از متغیرهای تصادفی در اختیارمان هست. «قضیه نگاشت پیوسته» (Continuous Mapping Theorem)، بیان میکند که اگر دنباله به مثلا همگرا باشند، آنگاه تحت شرایطی، تابعی از این دنبالهها مثل ها هم به همان تابع از همگرایی ها یعنی همگرا خواهد بود.
حال با نگاه برآوردگر سازگار به قضیه نگاشت پیوسته، توجه میکنیم. اگر یک برآوردگر سازگار برای بوده و نیز تابعی حقیقی و پیوسته در باشد، آنگاه نیز برای سازگار است. این موضوع به بیان ریاضی به صورت زیر نوشته میشود.
نکته: شرط پیوستگی تابع در اینجا از اهمیت زیادی برخودار است و ممکن است بدون وجود این شرط، قضیه نگاشت پیوسته، برقرار نباشد.
قضیه اسلاتسکی
به کمک «قضیه اسلاتسکی» (Slutsky’s theorem)، بعضی از خواص جبری دنبالههای عددی به دنبالهای از متغیرهای تصادفی نیز نسبت داده میشود. به این ترتیب میتوان نشان داد که اگر دنباله متغیرهای تصادفی به و دنباله به مقدار ثابت در توزیع همگرا باشند، آنگاه روابط زیر براساس همگرایی در توزیع (In Distribution) نیز برقرار خواهند بود.
حال از این قضیه برای برآوردگر سازگار برای پارامتر استفاده میکنیم. و را دو دنباله از متغیرهای تصادفی در نظر بگیرید که برایشان داریم:
آنگاه روابط زیر نیز برقرار است.
نکته: نماد نشانگر «همگرایی در توزیع» (Convergence in Distribution) است به این معنی که حد تابع توزیع دنباله متغیرهای تصادفی به یک توزیع خاص میل میکند. توجه داشته باشید که اگر همگرایی در احتمال وجود داشته باشد، همگرایی در توزیع نیز بدست خواهد آمد ولی عکس آن همیشه درست نیست. در نتیجه هنگام استفاده از قضیه اسلاتسکی باید با دقت بیشتر و توجه به شرایط برقراری همگرایی در احتمال، عمل کنید.
قانون اعداد بزرگ
اغلب فرم صریح برای برآوردگر به صورت جمع یا تابعی از مجموع نمونههای تصادفی است. به این ترتیب استفاده از «قانون اعداد بزرگ» (Law of Large Numbers) که آن را به اختصار LLN میگویند نیز برای نشان دادن سازگاری برآوردگرها به کار میرود.
طبق قانون اعداد بزرگ برای یک دنباله از متغیرهای تصادفی تحت همتوزیعی و مستقل (iid) بودن، به شرط وجود امید ریاضی آنها ()، میتوان رابطه زیر را در نظر گرفت.
به این ترتیب برای دنباله برآوردگرهای هم که برآوردگر هستند، خواهیم داشت:
اریبی و ارتباط آن با برآوردگر سازگار در آمار
وجود «اُریبی» (Biased) برای یک برآوردگر در اکثر مواقع، عیب در نظر گرفته میشود و اغلب به دنبال یک برآوردگر نااُریب برای پارامتر مجهول جامعه هستیم. از طرفی سازگاری نیز به عنوان یک مزیت برای برآوردگر محسوب شده و علاقمند هستیم که برآوردگر نااریب، سازگار هم باشد.

در ادامه به این موضوع پرداخته و با استفاده از مثالهایی نشان میدهیم که ممکن است یک برآوردگر نااریب بوده ولی سازگار نباشد و برعکس برآوردگر اریبی پیدا کنیم که سازگار هم باشد. به همین دلیل، باید سازگاری و نااریبی را برای یک برآوردگر مورد تحقیق قرار دهیم.
برآوردگر نااریب ولی ناسازگار
در این قسمت، برآوردگری را معرفی میکنیم که در عین حال که نااریب است، ناسازگار هم است. مشاهدات مستقل و هم توزیع (iid) نمونه تصادفی را در نظر بگیرید. فرض کنید که برآوردگر همان باشد.
از آنجایی که ها، همتوزیع هستند پس توزیع نیز با آنها یکی است و برای امید ریاضی (Mathematical Expectation) آن هم داریم:
پس برآوردگر ، یک برآوردگر نااریب است. ولی این برآوردگر، سازگار نیست، زیرا به یک مقدار ثابت میل نمیکند. در نتیجه برآوردگر سازگار برای نخواهد بود.
البته در بیشتر موارد، برآوردگرهای نااریب، سازگار هم خواهند بود به شرطی که این برآوردگر به بستگی نداشته باشند.

برآوردگر اریب ولی سازگار
فرض کنید میانگین یک توزیع از طریق برآوردگر زیر حاصل شود. البته در نظر داشته باشد که یک برآوردگر نااریب برای است.
واضح است که یک برآوردگر اریب با مقدار اریبی است. از آنجایی که میزان ارایبی در صورتی که اگر به سمت بینهایت میل کند () برابر با صفر خواهد شد، پس نیز به میل کرده، در نتیجه سازگار است.
به عنوان یک مثال دیگر، به برآورد واریانس جامعه توسط واریانس نمونهای و انحراف معیار نمونهای میپردازیم. اگر واریانس نمونهای را به صورت زیر (بدون در نظر گرفتن ضریب اصلاح بسل - Bessel's Correction) در نظر بگیریم، خواهیم داشت:
قبلا نشان دادیم که این برآوردگر و جذر آن (انحراف معیار نمونهای) هر دو برآوردگرهای اریب (با اریبی منفی) هستند، زیرا:
ولی باید توجه داشت که این برآوردگر، سازگار هستند. مشخص است که با حد گرفتن از سمت چپ نامساوی بالا، زمانی که به سمت بینهایت میل کند، امید ریاضی برابر با خواهد بود. به این ترتیب هم برآوردگر نااریب و هم برآوردگر اریب برای واریانس جامعه، سازگار هستند.
این موضوع را با یک مثال دیگر به پایان میبریم. فرض کنید یک دنباله از برآوردگرهای با تابع احتمالی به فرم زیر باشد.
$$ \large {\displaystyle \Pr ( T_{n}) = { \begin{cases}1 - 1/n, &{\mbox{if }}\,T_{n} = \theta \\ \large 1/n,& {\mbox{if }}\,T_{n} = n \delta + \theta \end{cases}}} $$
واضح است که این برآوردگر دارای اریبی است.
رابطه بالا به بستگی نداشته و در صورتی که ، اریبی به سمت صفر میل نخواهد کرد. ولی از طرفی این برآوردگر سازگار است و داریم:

خلاصه و جمعبندی
در این نوشتار، با برآوردگر سازگار (Consistent Estimator) در آمار آشنا شدیم و با استفاده از چند مثال، کارایی چنین برآوردگرهایی را مشخص کردیم. در انتها نیز ارتباط نااریبی با سازگاری را مورد بررسی قرار دادیم. در این بین سازگاری ضعیف و سازگاری قوی را هم براساس همگرایی براساس احتمال (Convergence in Probability) یا تقریبا مطمئن (Almost Surely Convergence) مشخص کردیم.
اگر این مطلب برای شما مفید بوده است، مشاهده آموزشها و خواندن مطالب مرتبط با این موضوع که در ادامه آمدهاند، نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای ریاضی
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای آمار و احتمالات
- توزیعهای آماری — مجموعه مقالات جامع وبلاگ فرادرس
- متغیر تصادفی و توزیع برنولی — به زبان ساده
- توزیع نرمال یک و چند متغیره — مفاهیم و کاربردها
^^










