



نامساوی چبیشف و اثبات آن – از صفر تا صد
در نظریه احتمال، از نامساویهایی زیادی برای نشان دادن رابطه بین احتمالات و تعیین کرانهای آنها استفاده میشود. در این بین نامساوی چبیشف (Chebeshev Inequality) نقش مهمی در تعیین کران بالا برای احتمال یا تابع توزیع احتمال تجمعی یک متغیر تصادفی ایفا میکند.
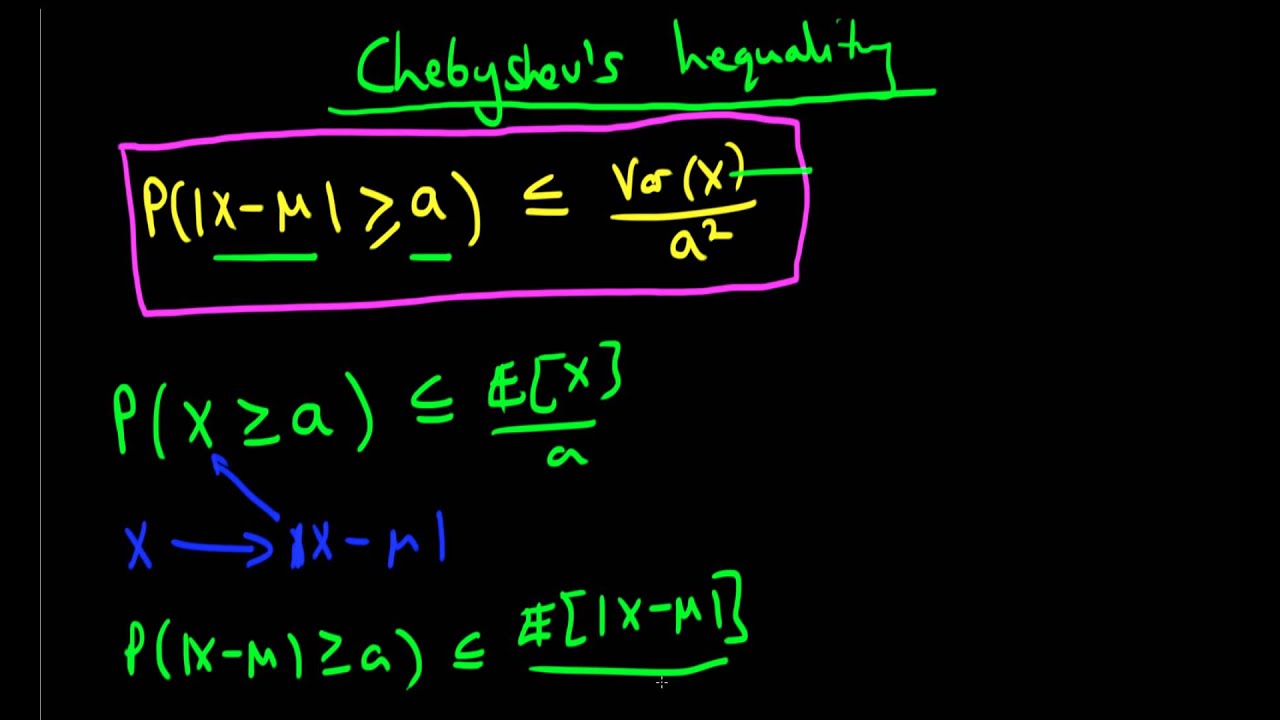


در نامساوی چبیشف، کران بالا بوسیله میانگین و واریانس متغیر تصادفی تعیین میشود. دیگر نامساویهای احتمالاتی مانند نامساوی مارکف (Markov inequality) و نامساوی هولدر (Holder Inequality) نیز برای محاسبه کرانهای تابع توزیع تجمعی یا امید ریاضی به کار میروند. در این نوشتار به نامساوی چبیشف و اثبات آن خواهیم پرداخت و با ذکر مثالهایی اهمیت استفاده از آن را مرور خواهیم کرد.
برای آشنایی با اصطلاحات به کار رفته در این نوشتار بهتر است مطالب امید ریاضی (Mathematical Expectation) — مفاهیم و کاربردها و متغیر تصادفی، تابع احتمال و تابع توزیع احتمال را بخوانید. همچنین خواندن نامساوی چبیشف – کاربرد در توزیعهای غیرنرمال (+) نیز خالی از لطف نیست.
نامساوی چبیشف و اثبات آن
نامساوی چبیشف براساس نام ابداع کننده آن یعنی «پافنوتی لوویچ چبیشف» (Pafnuty Lvovich Chebyshev) اسم گذاری شده است. این ریاضیدان روس، در سال 1867 نامساوی دوست و همکارش «ژول بینایمه» (Jules Bienayme) را که در سال 1853 معرفی شده بود، اثبات کرد.
البته بعدها، این نامساوی توسط مارکف که از شاگردان چبیشف بود، به شکل دیگری اثبات شد.

معمولا قضیه چبیشف به دو صورت یا شیوه بیان میشود، یک روش به صورت احتمالاتی (Probabilistic Statement) است و روش دیگر به کمک نظریه اندازه (Measure Theory) نامساوی چبیشف را مشخص میکند. در ادامه هر دو شیوه، ارائه شده و اثبات آنها نیز مطرح میشود. منظور از شیوه نظریه اندازه در نامساوی چبیشف آن است که اگر فضای احتمال را به فضای اندازهپذیر (Measurable Space) گسترش دهیم، باز هم قضیه چبیشف صادق خواهد بود.
قضیه نامساوی چبیشف با بیان احتمالاتی
فرض کنید متغیر تصادفی دارای امید ریاضی () و واریانس متناهی () باشد. در این صورت برای هر خواهیم داشت:
رابطه ۱
برای مثال فرض کنید که در نتیجه میتوان طبق نامساوی چبیشف گفت که احتمال اینکه مقداری از متغیر تصادفی خارج از بازه قرار گیرد از ۰٫۵ کمتر است.
نکته: در این قضیه مقدارهایی از مورد نظر است که از ۱ بزرگتر باشند زیرا برای مقدارهای این نامساوی امری بدیهی در احتمال محسوب میشود. زیرا مقدار احتمال برای هر پیشامد (یا متغیر تصادفی) کوچکتر یا مساوی با ۱ است. واضح است که برای مقادیر نسبت از یک بزرگتر خواهد بود.
جدول زیر براساس مقادیر مختلف شکل گرفته است که احتمال قرارگیری فاصله مقداری از میانگین را برحسب ضرایبی از نشان میدهد.

مقدار کران بالا (نامساوی چبیشف) و کران پایین (عکس نامساوی چبیشف) نیز دیده میشود. به این ترتیب ستون اول شامل مقادیر مختلف است و ستون دوم نیز (عکس نامساوی چبیشف) و ستون سوم نیز احتمال (نامساوی چبیشف) را نشان میدهد.
همانطور که مشاهده میکنید، احتمال اینکه مشاهدهای دارای فاصلهای بزرگتر از 5 انحراف معیار از میانگین باشد، حداکثر ۴٪ است و تقریبا در اکثر موارد، فاصله متغیر تصادفی از میانگین آن، کمتر از ۱۰ برابر انحرافمعیار است. در جدول این احتمال با مقدار 99٪ مشخص شده است.
مثال
فرض کنید مقالهای علمی را در یک مجله به تصادف انتخاب کردهایم. همچنین در نظر بگیرید که به طور متوسط در هر مقاله از این مجله علمی، ۱۰۰۰ کلمه و با واریانس ۲۰۰ کلمه وجود دارد. به این ترتیب میتوان احتمال اینکه مقاله انتخابی کمتر از ۶۰۰ یا بیش از ۱۴۰۰ کلمه باشد را کمتر از ۰٫25 در نظر گرفت. مشخص است که در نامساوی چبیشف بوده و در نتیجه محسوب شده است.
ولی توجه داشته باشید که اگر بدانیم توزیع کلمهها، از توزیع نرمال با میانگین ۱۰۰۰ و واریانس ۴۰،۰۰۰ باشد، آنگاه مقدار این احتمال برابر است با:
با مقایسه با کران حاصل از نامساوی چبیشف، مشخص است که این نامساوی، کران دقیقی ارائه نمیکند و بخصوص در زمانی که اطلاعاتی در مورد توزیع متغیر تصادفی داریم، فاصله زیادی بین کران بالا چبیشف و مقدار واقعی احتمال وجود دارد. البته همیشه مقدار این احتمال از کران چبیشف کوچکتر است. در ادامه به نمودارهایی خواهیم پرداخت که این امر را به خوبی نشان میدهند.
قضیه نامساوی چبیشف با نظریه اندازه
فضای اندازه را در نظر بگیرید. فرض کنید تابع تابعی با مقادیر حقیقی توسعه یافته (شامل بینهایت منفی و مثبت) باشد که روی اندازهپذیر است. آنگاه برای و خواهیم داشت:
رابطه ۲
حتی به طور کلی میتوان رابطه بالا را برای تابع یکنوای صعودی و نامنفی روی برد (Range) تابع نیز نوشت:
رابطه ۳
توجه داشته باشید که اگر در رابطه ۳ تابع به صورت باشد همان رابطه ۲ بدست میآید، به شرطی که باشد.
نکته: در اینجا منظور از ترکیب دو تابع و است.
اثبات نامساوی چبیشف با بیان احتمالاتی
برای نامساوی چبیشف با بیان احتمالاتی، اثباتهای مختلفی وجود دارد. برای مثال میتوان از نامساوی مارکف برای اثبات نامساوی چبیشف استفاده کرد. همچنین با در نظر گرفتن متغیر نشانگر نیز این نامساوی را میتوان اثبات کرد. حتی یک روش اثبات براساس متغیر تصادفی پیوسته نیز وجود دارد. در ادامه اثبات این نامساوی را به هر سه روش توضیح خواهیم داد.
اثبات بر اساس نامساوی مارکف
نامساوی مارکف برای متغیر تصادفی نامنفی به صورت زیر نوشته میشود.
حال متغیر تصادفی را به صورت زیر در نظر بگیرید.
به این ترتیب اگر باشد، نامساوی چبیشف به کمک نامساوی مارکف، برای متغیر تصادفی ، اثبات میشود زیرا مشخص است که احتمالات زیر معادل هستند.
$$\large \Pr \left( (X-\mu)^2<c^2\right)=\Pr(|X-\mu|<c)$$
نکته: توجه دارید که در اینجا و امید ریاضی و انحراف استاندار متغیر تصادفی هستند.
اثبات بر اساس متغیر نشانگر
پیشامد را در نظر بگیرید. متغیر تصادفی نشانگر را به صورت زیر تعریف میکنیم.
به این معنی که اگر پیشامد رخ دهد مقدار آن برابر با ۱ و در غیر اینصورت مقدار تابع نشانگر برابر با صفر خواهد بود. به این ترتیب طرف چپ نامساوی چبیشف را بازنویسی میکنیم.
همانطور که مشاهده میکنید، نامساوی به کار رفته در اثبات (سطر سوم) دارای دو ضعف عمده است که این امر باعث میشود کران نامساوی چبیشف از مقدار واقعی احتمال دور باشد و به اصطلاح، کران تیزی (Sharp) ایجاد نکند. این دو ضعف در ادامه بررسی میشوند.
- همانطور که در اثبات بالا مشاهده کردید اگر باشد، در نامساوی به جای به کار بردن مقدار ۰ برای تابع نشانگر از مقدار استفاده شده است که مقداری مثبت است و باعث افزایش مقدار امید ریاضی میشود.
- از طرفی اگر ، باز هم به جای استفاده از مقدار ۱ برای تابع نشانگر، مقدار به کار رفته که بزرگتر یا مساوی با ۱ است.
به همین علت، کران ایجاد شده توسط نامساوی چبیشف بسیار بزرگ است.
اثبات برای متغیر تصادفی پیوسته
در این قسمت فرض میکنیم که متغیر تصادفی ، پیوسته و دارای تابع چگالی احتمال و واریانس است. به این ترتیب مقدار احتمال آنکه متغیر تصادفی در بازه تا قرار گیرد به صورت زیر بدست میآید.
همینطور، واریانس این متغیر تصادفی نیز به شکل زیر قابل محاسبه است.
به این ترتیب از سمت چپ نامساوی چبیشف، اثبات را آغاز میکنیم.
به این ترتیب اثبات نامساوی چبیشف برای متغیر تصادفی پیوسته انجام میشود.
نکته: اگر در نامساوی چبیشف، را با جایگزین کنیم، رابطه زیر به دست خواهد آمد.
که بطور معادل به صورت زیر در میآید.
واضح است که بر این اساس، مقدار مثبت و حقیقی خواهد بود.
اثبات نامساوی چبیشف در نظریه اندازه
در مجموعه که به صورت تعریف شده است، را ثابت در نظر بگیرید. همچنین تابع نشانگر را روی مجموعه تعریف میکنیم. واضح است که برای هر تابع غیرنزولی و مثبت روی برد مانند رابطه زیر برقرار است.
در نتیجه طبق آنالیز ریاضی و مفهوم انتگرال ریمان استیلتیس (Riemann Stieltjes) خواهیم داشت:
حال دو طرف این نامساوی را به تابع که تابعی مثبت است، تقسیم میکنیم. در نتیجه جهت نامساوی تغییر نخواهد کرد.
نامساویهای دیگر بر مبنای نامساوی چبیشف
همانطور که دیدید، نامساوی چبیشف برمبنای احتمال دو طرفه و متقارن برحسب نوشته شده است. یعنی میتوان آن را به صورت زیر درآورد.
اگر بخواهیم نامساوی چبیشف را برای حالتی در نظر بگیریم که دو طرف نامساوی احتمال، قرینه نباشند باید به روش زیر محاسبات را انجام بدهیم.
فرض کنید تابع توزیع متغیر تصادفی ، نامعلوم بوده ولی مشخص باشد که متقارن است. برای مثال توزیع نرمال (Normal Distribution) یا توزیع کوشی (Cauchy Distribution) این وضعیت را دارند. به این معنی که . در این صورت میتوانیم نامساوی دیگری بر مبنای نامساوی چبیشف ایجاد کنیم.
برای هر دو عدد و که بینشان رابطه برقرار باشد، داریم:
اگر توزیع احتمال نامتقارن یا نامعلوم باشد، برای خواهیم داشت:
واضح است که امید ریاضی و نیز انحراف معیار متغیر تصادفی هستند.
تحقیق نامساوی چبیشف برای توزیع دو جملهای و نرمال
در ادامه به بررسی نامساوی چبیشف برای توزیع گسسته دو جملهای (Binomial Distribution) و پیوسته نرمال میپردازیم. همانطور که میدانید، باید برای هر دو حالت، ابتدا مقدار تابع بقا را محاسبه کنیم. همچنین با توجه به مقدار طرف راست نامساوی یعنی را بدست آوریم. در انتها نیز این دو مقدار را بوسیله یک نمودار با یکدیگر مقایسه میکنیم. البته واضح است که نمودار ترسیم شده از منحنی تابع بقا همیشه در پایین نمودار حاصل از طرف راست نامساوی چبیشف قرار خواهد گرفت.
کد زیر که به زبان محاسباتی R نوشته شده است، به بررسی این نامساوی برای توزیع دو جملهای با پارامترهای و پرداخته است. واضح است که مقدار از ۱ تا ۱۵ خواهد بود.

نکته: امید ریاضی و واریانس برای متغیر تصادفی دو جملهای به ترتیب برابر با و است.
این بار براساس توزیع نرمال این نمودار را ترسیم میکنیم. البته توجه داریم که میانگین توزیع از مقادیر کسر شدهاند. کد زیر به این منظور نوشته شده است.
نتیجه اجرای این برنامه، به صورت نموداری مطابق تصویر زیر خواهد بود.

همانطور که گفتیم، نامساوی چبیشف برای مقادیر اهمیت پیدا میکند. در نمودارهای ترسیم شده نیز دیده میشود که برای مقادیر کوچکتر از ۱، نامساوی چبیشف منحنی مناسبی ارائه نمیکند زیرا مقداری بزرگتر از ۱ داشته و دارای فاصله بسیار زیادی از مقدار واقعی احتمال است. به همین دلیل اغلب مقادیر بزرگتر از ۱ را برای در نظر میگیرند.
کاربردهای نامساوی چبیشف
برای نشان دادن کاربرد نامساوی چبیشف به دو مثال میپردازیم تا قدرت آن را در زمانی که از توزیع احتمال مقادیر یا جامعه آماری اطلاع نداریم، نشان دهیم.

مثال ۱
در نظر بگیرید که در حوزه سرمایهگذاری در بازار بورس نزدک (NASDAQ) و داوجونز (Dow Jones)، شاخص بازگشت سرمایه (ROI) را اندازهگیری کردهایم. اطلاعات مربوط به این دو شاخص به صورت زیر هستند.
با استفاده از نامساوی چبیشف با توجه به اینکه توزیع احتمالی این دادهها را نمیدانیم، میتوانیم میزان شباهت نمونه (مقدار احتمال) با میانگین را برحسب ضرایب مختلف انحراف معیار (به عنوان فاصله با میانگین) بدست آوریم.
برای مثال، طبق نامساوی چبیشف متوجه میشویم که حداکثر ۷۵ درصد از مشاهدات بیشتر از ۲ انحراف معیار از میانگین فاصله دارند. به این ترتیب این ناحیه براساس هر دو شاخص به صورت زیر در خواهد آمد.
با توجه به اینکه در بازار داو جونز این بازه کوچکتر است، در نتیجه شاخص بازگشت سرمایه در آن کم رونقتر است در عوض بازار نزدک از کارایی خوبی برخوردار است زیرا در اکثر مواقع نرخ بازگشت سرمایه مقدار بزرگتری از داو جونز دارد.
مثال ۲
همانطور که در توزیع نرمال میتوان دید، روابط زیر برقرار است:
و
همچنین
ولی برطبق نامساوی چبیشف مقدار حداقل احتمال برحسب ضریب به شکل زیر خواهد بود.
در نتیجه برای یک، دو و سه انحراف استاندارد فاصله از میانگین خواهیم داشت:
که امری بدیهی است و در ادامه
همانطور که میبینید این مقادیر با نتایج حاصل از توزیع نرمال تفاوت زیادی دارند. این امر نشانگر آن است که کرانهای حاصل از نامساوی چبیشف تیز نبوده و با مقدار واقعی فاصله دارند.
خلاصه و جمعبندی
در این نوشتار به بررسی نامساوی چبیشف و اثبات آن پرداختیم. در این بین کاربردهایی نیز از این نامساوی معرفی کردیم. هر چند زمانی که توزیع احتمالی برای متغیر تصادفی مشخص باشد، استفاده از نامساوی چبیشف، کران تیزی ارائه نمیکند ولی به عنوان یک روش در استنباط ناپارامتری، معیار مناسبی خواهد بود. البته نامساوییهایی دیگری نیز وجود دارند که نسبت به نامساوی چبیشف کرانهای بهتر و تیزتری را ارائه میدهند که در مطالب دیگر مجله فرادرس به آنها نیز خواهیم پرداخت.
در صورت علاقهمندی به مباحث مرتبط در زمینه ریاضی و آمار، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار و احتمالات
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای ریاضی
- توزیعهای آماری — مجموعه مقالات جامع وبلاگ فرادرس
- متغیر تصادفی و توزیع برنولی — به زبان ساده
- توزیع نرمال یک و چند متغیره — مفاهیم و کاربردها
^^










