



رگرسیون ستیغی (Ridge Regression) در پایتون – راهنمای کاربردی
در مباحث مربوط به رگرسیون چند گانه، تعیین تعداد متغیرهای مستقلی که باید در مدل به کار گرفته شوند، یک مشکل محسوب میشود. با افزایش تعداد متغیرها، بیشبرازش (Overfitting) رخ داده و با کاهش آنها نیز ممکن است با مسئله کمبرازش (Underfitting) مواجه شویم. در صورتی که مدل رگرسیونی دچار بیشبرازش شود، خطای آن برای برآورد مقدارهای جدید متغیر وابسته زیاد خواهد بود در حالیکه وجود متغیرهای کمتر از حد لازم در مدل (کمبرازش) واریانس مدل را افزایش میدهد. بنابراین با افزایش تعداد متغیرها مشکل همخطی و بیشبرازش ظاهر شده و با کاهش آنها، واریانس مدل افزایش خواهد یافت. یکی از روشهای غلبه بر این مسائل در رگرسیون چندگانه، استفاده از مدل «رگرسیون ستیغی» (Ridge Regression) است. از آنجایی که در زمانی که متغیرهای مدل، زیاد و یا همخطی چندگانه وجود داشته باشد، واریانس برآوردگرها متورم شده و به شکل قله (ستیغ) در میآید، از همین روی، این روش رگرسیونی که بر این مشکل غلبه میکند، رگرسیون ستیغی نامگذاری شده است.

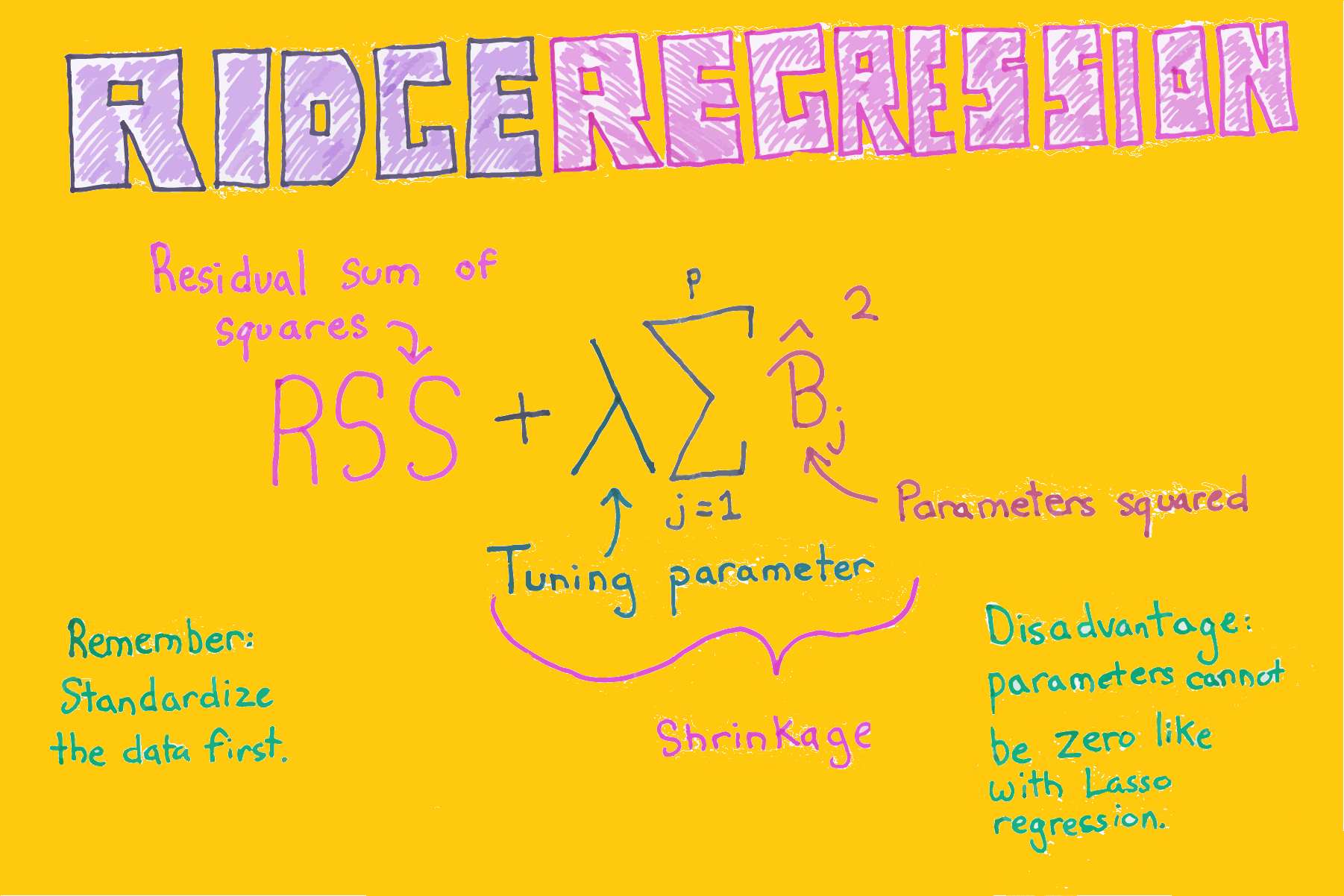


در مسئله رگرسیون خطی، از یک تابع خطا استفاده شده و سعی بر آن است که «مجموع مربعات خطا» (Sum of Square Error) را کمینه کنند. در رگرسیون ستیغی به کمک ترکیب تابع مجموع مربعات خطا و مقدار جریمه مرتبط با تعداد پارامترها، تابع جدیدی ساخته میشود که برای برآورد پارامترهای مدل رگرسیونی به کار میرود. حالت کلیتر این روش را به نام «قاعدهسازی تیکانوف» (Tikhonov Regularization) میشناسند. در این نوشتار به بررسی رگرسیون ستیغی پرداخته و شیوه محاسبه پارامترها را مرور خواهیم کرد. همچنین در انتها نیز با استفاده از زبان برنامه نویسی پایتون، با شیوه اجرای این روش رگرسیونی بیشتر آشنا خواهیم شد.
به منظور آگاهی بیشتر با شیوههای مختلف اجرای رگرسیون به مطلب آموزش رگرسیون — مجموعه مقالات جامع وبلاگ فرادرس مراجعه کنید. همچنین خواندن نوشتارهای رگرسیون خطی چندگانه (Multiple Linear Regression) — به زبان ساده و هم خطی در مدل رگرسیونی — به زبان ساده ضروری به نظر میرسد. در عین حال خواندن مطلب رگرسیون لاسو (Lasso Regression) — به زبان ساده نیز خالی از لطف نیست.
رگرسیون ستیغی (Ridge Regression)
قبل از آنکه به مبحث رگرسیون ستیغی بپردازیم، باید چند اصطلاح را در حوزه مربوط به رگرسیون خطی معرفی کنیم.
- متغیر مستقل: متغیری که به صورت مستقل (Independent) قابل اندازهگیری است و در مدل رگرسیونی به عنوان متغیر پیشگو، ویژگی و یا صفت به کار میرود.
- متغیر وابسته: متغیری که تغییرات آن وابسته (Dependent) به متغیرهای مستقل است. هدف از ایجاد مدل رگرسیونی، پیدا کردن رابطهای بین متغیرهای مستقل و وابسته است.
- مدل رگرسیونی: شکل رابطه ریاضی بین متغیرهای مستقل و وابسته را با توجه به الگوی احتمالی، مدل رگرسیونی مینامند.
- پارامترهای مدل رگرسیونی: در رابطه یا مدل رگرسیونی، برای هر متغیر مستقل، ضرایبی در نظر گرفته میشود که در تحلیل رگرسیونی باید برآورد شوند. معمولا این پارامترها را به صورت بردار نشان میدهند.
- همخطی: زمانی که متغیرهای مستقل با یکدیگر دارای ارتباط باشند بطوریکه ضریب همبستگی بین آنها از لحاظ آماری معنیدار باشد، مشکل یا مسئله همخطی (Colinearity) بوجود آمده است. در نتیجه اثر هر یک از متغیرها ممکن است در مدل رگرسیونی توسط متغیرهای دیگر برآورد شود. به این ترتیب برآوردگرها بسیار حساس شده و واریانس آنها نیز بزرگ خواهد شد.
- مجموع مربعات خطا (باقیماندهها)، RSS: مجموع اختلاف مقدارهای واقعی و پیشبینی شده توسط مدل رگرسیونی متغیر وابسته Residual Sum of Squares مینامند. مدلی که دارای کمترین میزان RSS باشد، مدل مناسبتری است.
- اریبی (Bais) برآوردگر: این شاخص نشان میدهد که پارامترهای مدل رگرسیونی چقدر به مقدار واقعی نزدیک یا دورند. اگر میزان اریبی زیاد باشد، نشان میدهد که به طور متوسط برآوردگرها از مقداری واقعی دور هستند و در صورت وجود نااریبی میتوان گفت که به طور متوسط برآورد پارامترها با مقدارهای واقعی مطابقت دارند. بنابراین نااریبی برای برآوردگرها از اهمیت زیادی برخوردار است.
- واریانس برآوردگر: ممکن است که متوسط برآوردگر به مقدار واقعی نزدیک باشد (نااریب باشد) ولی میزان پراکندگی آن نسبت به مقدار واقعی زیاد باشد. در این حالت واریانس برآوردگر زیاد است. واریانس را توسط میانگین مربعات خطا (MSE) اندازهگیری میکنند.
وجود اریبی یا واریانس زیاد برای برآوردگرهای مدل رگرسیونی از معایب آن مدل محسوب میشود که هر یک ممکن است به بیشبرازش یا کمبرازش منجر شوند. برای مشخص شدن این مفاهیم به تصویر زیر توجه کنید.

ساختار یک مدل رگرسیون خطی چندگانه به صورت زیر نوشته میشود.
همانطور که میدانید مقدار متغیر مستقل pام برای مشاهده iام است. از طرفی نیز باقیمانده برای مشاهده iام را نشان میدهد. در صورتی که بخواهیم مدل را به صورت برداری و ماتریسی نمایش دهیم، از شکل زیر استفاده خواهیم کرد.
مشخص است که در اینجا ماتریس متغیرهای مستقل و نیز بردار پارامترهای مدل رگرسیونی است. همچنین بیانگر بردار خطا یا همان باقیماندهها است. به این ترتیب میتوان مجموع مربعات خطا (یا مربع فاصله اقلیدسی) را به صورت زیر نشان داد.
در اینجا منظور از فاصله اقلیدسی است. در نتیجه مربع فاصله اقلیدسی را نشان میدهد.
همانطور که در دیگر نوشتارهای فرادرس با موضوع رگرسیون چندگانه و همخطی مطالعه کردهاید، میدانید که یکی از روشهای برآورد پارامترهای رگرسیون خطی، «کمینهسازی مجموع مربعات خطا» (Ordinary least Square) است که گاهی به اختصار OLS نامیده میشود. متاسفانه در این روش هر چه تعداد متغیرهای به کار رفته در رگرسیون چندگانه افزایش یابد، میزان خطا کاهش پیدا میکند ولی این امر منجر به بیشبرازش خواهد شد. از طرفی به کارگیری همه متغیرها در مدل مشکل همخطی را افزایش میدهد. بنابراین باید به دنبال روشی برای برآورد پارامترهای رگرسیونی بود که از بوجود آمدن چنین مشکلاتی جلوگیری کند.

برآورد پارامترها در روش OLS
اگر ملاک بهینهسازی در مدل رگرسیونی، کمترین مجموع مربعات خطا (RSS) باشد، مدل OLS بهترین برآوردها را ارائه خواهد داد. همانطور که در قبل اشاره شد، روش رگرسیون OLS، پارامترهای به شکلی برآورد میشوند که مربع فاصله اقلیدسی مقدار مشاهده شده از مقدار برآورده شده توسط مدل رگرسیونی حداقل ممکن شود. در این حالت برآورد پارامترها در مدل OLS بر اساس محاسبات زیر خواهد بود.
توجه داشته باشید که منظور از مقدارهایی از است که تابع مورد نظر را کمینه میکند.
ولی سوال این است که آیا مدل حاصل از روش OLS بهترین مدل است؟ مشخص است که مقدار RSS برای چنین مدلی کمتر از هر مدل دیگر است. ولی نمیتوان مطمئن بود که برای دادههایی حاصل از یک نمونه دیگر، مدل به خوبی عمل برازش را انجام دهد. لزوما مدل بدست آمده توسط OLS بهترین مدل برای پیشبینی مقدارهای متغیر وابسته که در ایجاد مدل به کار نرفتهاند، نخواهد بود. به این معنی که نمیتوان انتظار داشت که مدل با کمترین مجموع مربعات خطا، کمترین واریانس برای برآوردگرها را نیز داشته باشد. بنابراین باید راهی برای انتخاب تعداد مناسب برآوردگرها (متغیرهای مستقل) در نظر گرفت. در چنین حالتی است که روش رگرسیون ستیغی به کار میرود. مشخص است که برآوردگرهای حاصل از رگرسیون ستیغی نااریب نبوده ولی واریانس کوچکترین نسبت به روش OLS دارند.
برآورد پارامترها در روش ستیغی
برای برآورد کردن پارامترهای رگرسیونی در روش ستیغی، قیدی روی پارامترها گذاشته شده است. این قید به صورت زیر نوشته میشود.
این محدودیت، مشخص میکند که باید مجموع مربعات پارامترها از مقدار ثابت یا آستانهای کمتر باشند. این شرط را به صورت ماتریسی به صورت زیر نشان میدهیم.
حال این قید را نیز به روش OLS اضافه کرده و تابع هدف حاصل را ملاک برآورد پارامترهای مدل رگرسیون خطی قرار خواهیم داد. در نتیجه شیوه برآورد پارامترها به صورت زیر در خواهد آمد.
پارامتر در اینجا میزان جریمه (Penalty) نامیده میشود زیرا با توجه به افزایش تعداد پارامترها، مقدار RSS را افزایش میدهد. با تغییر مقدار و برآورد پارامترهای مدل، مدلی که کمترین مقدار مربع خطا (Mean Square Error) را داشته باشد، به عنوان مدل مناسب در نظر گرفته میشود.
پارامترهای حاصل از این روش، معمولا از روش OLS مناسبتر هستند بخصوص در هنگامی که هدف پیشبینی برای دادههایی باشد که در ایجاد مدل به کار نرفتهاند. برآورد پارامترهای مدل رگرسیون ستیغی به صورت زیر حاصل میشود.
نکته: مشخص است که اگر هیچ جریمهای برای مدل در نظر نگیریم و مقدار را صفر انتخاب کنیم، روش برآورد به شیوه OLS تبدیل خواهد شد. در نتیجه میتوان روش OLS را حالت خاصی از روش ستیغی در نظر گرفت.
در تعریف پارامترها در مدل ستیغی، میتوان دید که مقدار در مخرج کسر مربوط به پارامتر ظاهر میشود. به این ترتیب با افزایش میزان جریمه، مقدار پارامترها به صفر نزدیک میشوند ولی هرگز به صفر نمیرسند. به این ترتیب در روش ستیغی برای متغیرها کم اهمیت ضریب کوچک شده ولی هیچگاه صفر نمیشوند. به این شکل میتوان متغیرهای پراهمیت را در مدل حفظ و بقیه را نادیده گرفت.
تفسیر هندسی روش ستیغی
شاید نمایش روش ستیغی برای برآورد پارامترهای مدل رگرسیونی در درک کارایی آن کمک کند. فرض کنید در مدل رگرسیونی دو متغیر و حضور دارند که ضرایب (پارامترهای) هر یک و نامگذاری شدهاند. از آنجایی که در روش OLS با مربع فاصله اقلیدسی سروکار داریم، انتظار داریم که فضای پارامتری، نقاط هندسی را ایجاد کند که میزان RSS یا همان مجموع مربعات خطای آن ثابت باشد. پارامترهای و مکان هندسی نقاطی را روی یک دایره یا بیضی ایجاد میکنند که RSS یکسانی دارند. مشخص است که کمترین مقدار RSS در مرکز این دایره یا بیضی قرار میگیرد. در نتیجه مختصات این نقطه، حاصل برآوردگر OLS محسوب میشود.

حال جمله مربوط به جریمه را نیز در نظر بگیرد. این جمله به صورت مربع فاصله اقلیدسی برای پارامترهای و نوشته شده است که از نظر نقاط هندسی تشکیل یک دایره در مرکز مختصات را میدهد. هر چه مقدار تغییر کند اندازه این دایره نیز تغییر خواهد کرد.

از محل برخورد دایره آبی رنگ با بیضیهای سبز رنگ حاصل از روش OLS، برآوردگر ستیغی حاصل میشود. این محل برخورد نشان میدهد که برای مدل حاصل از رگرسیون ستیغی مقدار RSS ممکن است بزرگتر از مقدار حاصل از مدل OLS باشد. با تغییر پارامتر که اندازه دایره آبی را مشخص میکند، میتوان به نقطهای رسید که دارای کمترین میزان RSS روی دایره سبز باشد. به این ترتیب جواب بهینه به دست خواهد آمد.
البته برای پیدا کردن مقدار بهینه برای نیز میتوان از روشهای مختلف مانند اعتبار سنجی متقابل استفاده کرد. هرچه مقدار افزایش پیدا کند تعداد پارامترها کاهش پیدا خواهد کرد. با کاهش این مقدار نیز برآوردگرها به مقدار مشابه در روش OLS نزدیک میشوند ولی با افزایش میزان جریمه این ضرایب کاهش یافته میتوان آنها را نادیده گرفت. به این ترتیب بزرگی یا کوچکی مقدار میتواند روی تعداد پارامترها و مقدار آنها تاثیر گذار باشد. در ادامه به کمک زبان برنامه نویسی پایتون به بررسی مدل رگرسیونی ستیغی برای دادههای واقعی پرداخته و مقدار را مشخص میکنیم.
اجرای رگرسیون ستیغی در پایتون
در ادامه به بررسی رگرسیون ستیغی در پایتون خواهیم پرداخت. در این میان از بانک اطلاعاتی قیمت خانهها (Boston House Price) در کتابخانه استفاده خواهیم کرد.

کد زیر به منظور آماده سازی محیط برای اجرای رگرسیون ستیغی نوشته شده است.
حال که دادههای بارگذاری شدهاند، باید آنها را استاندارد کرد. از آنجایی که در رگرسیون ستیغی ضرایب مدل رگرسیونی براساس میزان جریمه تعیین میشوند، باید دادهها را استاندارد کرد تا جریمهها عادلانه باشند. به کد زیر دقت کنید. پس از استاندارد سازی بوسیله تابع scale، دادهها به دو بخش آموزشی (Train) و آزمایشی (Test) تفکیک شدهاند.
در اینجا برای تعیین مقدار آن را از ۰ تا ۱۹۹ تغییر داده و برآورد پارامترها را مشخص میکنیم.
حال مقدار پارامترها را با توجه به میزان برای متغیرهای مختلف ترسیم میکنیم. کد زیر به این منظور تهیه شده است. مشخص است که این نمودار براساس ridge_df که یک چهارچوب (DataFrame) متشکل از نتایج اجرای رگرسیون ستیغی است ترسیم شده است. البته توجه داشته باشید که در این نمودار فقط پنچ مشخصه یا متغیر مستقل (تعداد اتاق خواب (Room)، ناحیه مسکونی (Resident Zone)، دسترسی به بزرگراه (Highway Access)، نرخ جرم و جنایت (Crime Rate)، و مالیات (Tax)) که بیشترین ارتباط با متغیر وابسته را داشتهاند ترسیم شدهاند.
همانطور که در نمودار مشخص است، متغیر Room که تعداد اتاق خوابها را نشان میدهد بیشترین تاثیر را در تعیین قیمت خانه دارد. به همین دلیل خط قرمز که مربوط به این پارامتر است، به سمت صفر میل نمیکند. در مقابل متغیر Highway Access یا دسترسی به بزرگراه که با خط آبی مشخص شده، به سرعت به سمت صفر میل کرده است که نشان دهنده کم اهمیت بودن این متغیر در برآورد متغیر وابسته (قیمت خانه) است.

بقیه متغیرها نیز با توجه به خطچین سیاه رنگ که مقدار صفر را نشان میدهد، دارای اهمیتهای مختلف خواهند بود. به این ترتیب مشخص است که اگر بخواهیم کمترین واریانس را داشته باشیم (در حقیقت با بیشترین اریبی) باید مقدار افزایش یابد. در این حالت فقط متغیر Room در مدل رگرسیون ستیغی باقی میماند.
برای بررسی میزان MSE مدل نیز از کد زیر استفاده کردهایم، به این ترتیب با توجه به تعداد پارامترها یا در حقیقت مقدار ، کمترین MSE تعیین میشود. به خوبی دیده میشود که این میزان با توجه به مدل OLS که با خط سبز در نمودار مشخص است، کاملا تفاوت دارد.
نمودار حاصل از اجرای کد بالا به صورت زیر است. هر چه میزان افزایش یابد، مقدارهای روی محور افقی که نشان دهنده سادگی مدل است افزایش مییابد زیرا متغیرهای کمتری در مدل وجود خواهند داشت.

ابتدا با افزایش مقدار میزان MSE نیز کاهش مییابد ولی پس از رسیدن مقدار به مقدار مشخصی، مقدار MSE شروع به افزایش میکند. این امر نشان میدهد که در این نقطه، باید مقدار را انتخاب کرد.
نکته: همانطور که گفته شد، مدل OLS دارای برآوردگرهای نااریب است در حالیکه میبینیم خطای مدل با پارامترهای حاصل از رگرسیون ستیغی کمتر از مدل OLS نااریب است.
خلاصه و جمعبندی
در این نوشتار به بررسی رگرسیون ستیغی از جنبههای مختلف از جمله ریاضیاتی، هندسی و البته برنامه نویسی پرداختیم. مشخص شد که روش برآورد رگرسیون OLS میتواند حالت خاصی از رگرسیون ستیغی در نظر گرفته شود. همانطور که دیدید، تعیین مقدار مناسب برای پارامتر به راحتی میسر نیست و باید با سعی و خطا مقدار آن را جستجو کرد. در اینجا به کمک ترسیم نمودار MSE برحسب مقدار به جواب مناسب برای این مقدار رسیدیم. از ویژگیهایی مدل رگرسیون ستیغی و OLS میتوان به موارد زیر اشاره کرد.
- مدل رگرسیون OLS بهترین پیشبینی را برای دادههایی خواهد داشت که در ایجاد مدل سهیم هستند.
- مدل رگرسیون ستیغی به ویژگیهایی که مهمتر هستند وزن بیشتری میدهد.
- از مقدار یا MSE برای تعیین مقدار مناسب میتوان استفاده کرد.
- نقش هر یک از متغیرها در تعیین مقدار RSS متفاوت است. بنابراین هنگام استفاده از رگرسیون ستیغی ابتدا باید دادهها را استاندارد کرد.
اگر مطلب بالا برای شما مفید بوده است، احتمالاً آموزشهایی که در ادامه آمدهاند نیز برایتان کاربردی خواهند بود.
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش یادگیری ماشین
- مجموعه آموزشهای نرمافزارهای آماری
- بیش برازش (Overfitting)، کم برازش (Underfitting) و برازش مناسب — مفهوم و شناسایی
- ماشین بردار پشتیبان — به همراه کدنویسی پایتون و R
- رگرسیون خطی — مفهوم و محاسبات به زبان ساده
- رگرسیون خطی چندگانه (Multiple Linear Regression) — به زبان ساده
- آموزش رگرسیون — مجموعه مقالات جامع وبلاگ فرادرس
^^











سلام ols_pred کجا بدست اومده که در قسمت آخر استفاده کردین ؟
با سلام و احترام؛
صمیمانه از همراهی شما با مجله فرادرس و ارائه بازخورد سپاسگزاریم.
با توجه به اینکه موضوع اصلی این مطلب راجع به روش «ستیغی» بوده و تنها مقایسهای بین این روش و OLS صورت گرفته است، کدهای مربوط به برآورد پارامترها با روش OLS در این مطلب ارائه نشدهاند.
برای شما آرزوی سلامتی و موفقیت داریم.
سلام رگرسیون ریج در ایویز ی11 چطوری تخمین زده می شود و انحراف معیار ان چگونه محاسبه می شود
با سلام
دررگرسیون ریج λ بعنوان ضرایب تنظیم کننده یا جریمه مستقیما در ضرایب بتا ضرب می شود
مانند
y=β0+λβixi
یا بعنوان جمله جدید در تابع منظور می شود
مثل
y=β0+βixi+λβixi
متشکر
با سلام. با تشکر از سایت خوبتون. یه سوال داشتم، رگرسیون ستیغی (ridge regression) رو تو spss چجوری آنالیز می کنند؟
با سلام و تشکر بسیار فراوان، در مورد این نوع رگرسیون مطلب فارسی بجز سایت شما پیدا نکردم. یه سوال دارم توی نرم افزار Eviews که دانشجویان اقتصاد استفاده می کنند از کدام منو میشه برای براورد رگرسیون ستیغی استفاده کرد؟ آیا در روش پانل دیتا میشه از رگرسیون ستیغی استفاده کرد؟
سلام و درود
از اینکه همراه فرادرس هستید سپاسگزاریم!
در نسخههای جدید نرمافزار Eviews این امکان وجود دارد که با استفاده از افزونه Ridge، رگرسیون ستیغی را اجرا کنید. برای دریافت این افزونه بهتر است به آدرس زیر مراجعه کنید.
http://forums.eviews.com/viewtopic.php?t=2757
از اینکه نوشتارهای مجله فرادرس مورد توجه شما قرار گرفته است خوشحالیم!
شاد و موفق باشید.