


پیاده سازی سیستم های توصیه گر در پایتون – از صفر تا صد
«سیستم های توصیه گر» (Recommender | Recommendation Systems)، زیر مجموعهای از «سیستمهای فیلتر اطلاعات» (Information Filtering Systems) محسوب میشوند. هدف سیستم های توصیه گر، پیشنهاد مناسبترین آیتمها (داده، کالا، سرگرمی و سایر موارد) به کاربران است. در سیستم های توصیه گر، دادههای مرتبط با رفتار کاربران (در خرید کالا، دریافت دادهها، تماشای سرگرمی و سایر موارد) تحلیل و مدلسازی میشوند. سپس، از مدل تولید شده برای پیشبینی مناسبترین آیتم برای کاربران استفاده میشود. بیشترین استفاده سیستم های توصیه گر، در پیادهسازی کاربردهای تجاری (به ویژه، در حوزه محصولات و خدمات مصرفی کاربران) است.




افرادی که در شرکتهای تجاری بزرگ، مدیریت واحدهای بهینهسازی تجربه مشتریان و یا استراتژی محصولات تجاری را بر عهده دارند، بدون شک از سیستمهای توصیهگر محصولات، برای ارتقاء یا بهبود تجربه خرید مشتریان خود استفاده میکنند. امروزه، یکپارچهسازی سیستم های توصیه گر محصولات و خدمات با استراتژیهای تولید یا عرضه محصولات، به یکی از استانداردهای سازمانها و شرکتهای تجاری بزرگ و چند ملیتی، برای پیشی گرفتن از رقبا تبدیل شده است. این شرکتها، از سیستم های توصیه گر محصولات و خدمات برای «شخصیسازی» (Personalizing) محتوا و محصولات قابل پیشنهاد به کاربران استفاده میکنند.
سیستم های توصیه گر، یکی از شایعترین و قابل فهمترین کاربردهای «کلان داده» (Big Data)، «هوش مصنوعی» (Artificial Intelligence) و «یادگیری ماشین» (Machine Learning) محسوب میشوند. سیستم های توصیه گر در حوزههای مختلفی قابل استفاده هستند. از این دسته از سیستمها، برای تولید «لیست پخش» (Playlist) در سرویسهای فیلم و موسیقی نظیر «نتفلیکس» (Netflix) و «یوتیوب» (YouTube) استفاده میشود. همچنین، در سرویسهایی نظیر آمازون، برای پیشنهاد محصولات به کاربران و در پلتفرمهایی نظیر شبکههای اجتماعی، برای پیشنهاد محتوا به کاربران مورد استفاده قرار میگیرند. در این مطلب، یک سیستم توصیهگر، برای پیشنهاد کردن آیتمها و کالاهای خرید به کاربران پیادهسازی میشود.

چالشهای پیادهسازی سیستم های توصیه گر
با یک جستجوی ساده در اینترنت در مییابید که روشهای مختلفی برای پیادهسازی سیستم های توصیه گر مبتنی بر «دادههای رتبهبندی» (Rating Data) نظیر موسیقی و فیلم وجود دارد. مشکل بزرگی که سیستم های توصیه گر مبتنی بر دادههای رتبهبندی دارند این است که مدلهای تولید شده را نمیتوان برای استفاده در دیگر دامنههای کاربردی تعمیم داد؛ به ویژه، زمانی که دادههای این دامنههای کاربردی، «مقیاسنشده» (Non-Scaled Data) باشند.
دادههایی نظیر «دادههای فراوانی» (Frequency Data) و «دادههای خرید» (Purchase Data)، مقیاس نشده هستند. به عنوان نمونه، دادههای رتبهبندی در سرویسهای نظیر آمازون یا نتفلیکس، مقادیری بین (0 تا 5) یا (0 تا 10) هستند (امتیاز کاربران به کالا یا یک محصول سرگرمی)؛ با این حال، دادههای خرید، پیوسته و بدون «حد بالا» (Upper Bound) هستند.
مشکل دیگر برخی از سیستم های توصیه گر تحت وب این است که بدون ارزیابی مدل توصیهگر، پیشنهادهای تولید شده توسط سیستم را به کاربران ارائه میدهند. برای بسیاری از «مهندسان و دانشمندان داده» (Data Engineers and Scientists)، پیادهسازی سیستم های توصیه گر با استفاده از میلیونها داده، بدون ارزیابی مدل، کاری بسیار خطرناک است. همچنین، پیادهسازی سیستم های توصیه گر با هدف عرضه یا بهبود محصولات و عدم ارزیابی عملکرد آنها در شرایط جهان واقعی، بدون شک منجر به شکست خواهد شد.
اهداف پیادهسازی سیستم های توصیه گر
در این مطلب، سعی شده است تا تعدادی سیستم های توصیه گر برای دادههای خرید پیادهساری شوند. سیستمهای پیادهسازی شده روی دادههای مقیاسنشده آموزش میبینند. همچنین، سیستم های توصیه گر پیادهسازی شده ارزیابی میشوند تا عملکرد بهینه آنها در کاربردهای «جهان واقعی» (Real-Time) تضمین و بهترین مدل از بین آنها انتخاب شود. در نهایت از مدل آموزش دیده، برای پیشنهاد کردن محصولات و آیتمهای خرید جدید به کاربران استفاده میشود.
در این مطلب، از مدل «سیستم های توصیه گر مشارکتی» (Collaborative Recommender Systems) برای پیشنهاد محصولات جدید به کاربران و شخصیسازی تجربه خرید آنها استفاده میشود. همچنین، پیادهسازی گام به گام و با جزئیات این روش در زبان برنامهنویسی پایتون و بسته نرمافزاری یادگیری ماشین (Turicreate) پوشش داده خواهد شد. گامهای مورد نیاز برای پیادهسازی روش پیشنهادی عبارتند از:
- «تبدیل» (Transformation) و «نرمالسازی» (Normalization) دادهها.
- «آموزش» (Training) مدلهای توصیهگر پیادهسازی شده.
- «ارزیابی» (Evaluation) عملکرد مدلهای آموزش دیده.
- انتخاب مدل بهینه از میان مدلهای پیادهسازی شده.
بررسی اجمالی سناریوی خرید محصول
یک فروشگاه زنجیرهای عرضه محصولات را فرض کنید. این فروشگاه زنجیرههای، یک نرمافزار همراه جدید عرضه کرده است که به مشتریان خود اجازه میدهد بدون نیاز به حضور فیزیکی در فروشگاه، محصولات مورد نیاز خود را انتخاب و سفارش دهند. در چنین سناریویی، امکان استفاده از سیستم های توصیه گر محصولات وجود دارد.

به عبارت دیگر، نرمافزار همراه میتواند هنگامی که مشتریان، صفحه «سفارشات» (Orders) را باز میکنند، 10 محصول مشابه با سبد خرید آنها را انتخاب و به آنها پیشنهاد دهد. کاربران میتوانند با انتخاب محصولات مشابه، اقلامی را که مورد علاقه آنها است به سبد خرید اضافه کند. همچنین، این امکان برای کاربران فراهم شده است تا لیست پیشنهادات تولید شده بر مبنای تراکنشهای (خرید) یک کاربر خاص را جستجو و مشاهده کنند. در چنین حالتی:
- ورودی مسأله: «شناسه کاربری مشتری» (Customer ID)
- خروجی مسأله: لیست رتبهبندی شده از محصولاتی (Product IDs) که به احتمال زیاد، کاربران تمایل دارند به سبد خرید خود اضافه کنند.

پیادهسازی سیستم های توصیه گر خرید به مشتریان
در این بخش، مراحل گام به گام برای پیادهسازی یک سیستم توصیهگر، با جزئیات کامل شرح داده میشود.
وارد کردن بستههای نرمافزاری لازم برای پیادهسازی سیستم توصیهگر در پایتون
برای پیادهسازی سیستم های توصیه گر خرید در زبان برنامهنویسی پایتون، از چهار بسته نرمافزاری مهم استفاده شده است. این بستهها عبارتند از:
- بستههای نرمافزاری pandas و numpy: از این بستهها، برای «دستکاری عددی دادهها» (Numerical Data Manipulation) استفاده میشود.
- بسته نرمافزاری turicreate: برای انتخاب مدل یادگیری مناسب برای پیادهسازی سیستم های توصیه گر و ارزیابی آنها، از این بسته استفاده میشود.
- بسته نرمافزاری sklearn: از این بسته، برای تقسیم کردن دادهها به دو مجموعه «آموزش» (Train) و «تست» (Test) استفاده میشود.
با استفاده از قطعه کد زیر، بستههای ذکر شده در زبان برنامهنویسی پایتون، بارگیری و آماده استفاده میشوند:
بارگیری دادههای لازم برای آموزش و تست سیستم های توصیه گر
برای پیادهسازی سیستم های توصیه گر، از دو مجموعه داده با فرمت ساختاری (CSV.) استفاده میشود. مجموعه دادههای استفاده شده در این مطلب، از طریق این لینک یا این مخزن گیتهاب [+] قابل بارگیری هستند. مشخصات این مجموعه دادهها به شکل زیر هستند.
- مجموعه داده recommend_1.csv: این مجموعه داده، لیستی متشکل از تعداد 1000 شناسه مشتری را شامل میشود. از این لیست، برای نمایش پیشنهادات تولید شده بر مبنای تراکنشهای (خرید) یک کاربر، با شماره مشتری خاص استفاده میشود (customers).
- مجموعه داده trx_data.csv: این مجموعه داده، تراکنشهای کاربری (محصولات خریداری شده) را شامل میشود (transactions).
با استفاده از قطعه کد زیر، مجموعه دادههای ذکر شده در زبان برنامهنویسی پایتون، بارگیری میشوند:
با استفاده از قطعه کدهای زیر، ساختار مجموعه دادههای ذکر شده نمایش داده میشوند:


آمادهسازی دادهها
در این بخش، دادههای نمایش داده شده در بخش قبل به گونهای مرتبسازی میشوند که در آنها، لیست آیتمهای (خریدهای) موجود در ستون products مجموعه داده transactions، به تعدادی سطر شکسته میشوند؛ به طوری که هر سطر جدیدِ تولید شده، «شماره شناسه مشتری» (customerId)، «شناسه محصول خریداری شده» (productId) و «تعداد دفعات خرید محصول» (purchase_count) توسط کاربر را شامل خواهد شد. به عبارت دیگر، یک مجموعه دادهای جدید، با سه دسته اطلاعات (شماره شناسه مشتری، شناسه محصول خریداری و تعداد دفعات خرید محصول) تولید میشود. این مجموعه داده، مجموعه داده «اصلی» (Main) نامیده میشود. با استفاده از قطعه کد زیر، مجموعه داده transactions، به مجموعه داده اصلی تبدیل میشود:
با استفاده از قطعه کد زیر، ساختارِ مجموعه داده اصلی نمایش داده میشود:

در ادامه، علاوه بر مجموعه داده اصلی، دو مجموعه داده دیگر نیز تولید میشوند. هدف از تولید این دو مجموعه داده، مقایسه عملکرد سیستم روی نمایشهای مختلف تولید شده از دادههای خرید است. مشخصات این دو مجموعه داده به شرح زیر است:
- مجموعه داده جایگزین: این مجموعه داده، ساختاری شبیه به مجموعه داده اصلی دارد؛ با این تفاوت که، مقادیر موجود در ستون «تعداد دفعات خرید محصول»، با عدد 1 جایگزین میشوند (در مجموعه داده جایگزین، نام ستون purchase_count به purchase_dummy تغییر پیدا میکند). این مجموعه داده، تنها خریدن یک محصول توسط کاربران را نمایش میدهد و نه تعداد دفعات خرید.
- مجموعه داده اصلی نرمالسازی شده: این مجموعه داده نیز، ساختاری شبیه به مجموعه داده اصلی دارد؛ با این تفاوت که، در ستون « تعداد دفعات خرید محصول» به جای تعداد واقعی دفعات خرید، مقدار نرمال شده تعداد دفعات خرید (مقداری بین 0 و 1) جایگزین میشود (در مجموعه داده اصلی نرمال شده، نام ستون purchase_count به scaled_purchase_freq تغییر پیدا میکند). به عبارت دیگر، نمونهها بر اساس تعداد دفعات خرید، نرمالسازی میشوند.
تولید مجموعه داده جایگزین
در مجموعه داده جایگزین، تنها خریداری شدن یا نشدن یک محصول لحاظ میشود و نه تعداد دفعات خرید آن. یکی از دلایل ایجاد این مجموعه داده، مشاهدات انجام شده از رفتار خرید مشتریان است. این مشاهدات نشان میدهند «مشتریانی که یک محصول یکسان را (به تعداد دفعات متفاوت) خرید میکنند، ممکن است سلیقه خرید یکسانی داشته باشند». با استفاده از قطعه کد زیر، مجموعه داده جایگزین تولید میشود:
تولید مجموعه داده اصلی نرمالسازی شده
برای نرمالسازی مقادیر موجود در ستون purchase_count به ازاء تمامی مشتریان، ابتدا لازم است تا ماتریس user-item با استفاده از مجموعه داده اصلی ساخته شود.



گامهای بالا (برای تولید ماتریس user-item) را میتوان توسط تابعی به شکل زیر با هم ترکیب کرد.
در این بخش، مقادیر موجود در ستون purchase_count، توسط مقادیری بین 0 تا 1 نرمالسازی میشوند (مقدار یک، بیانگر بیشترین تعداد دفعات خرید برای یک آیتم و مقدار صفر نیز، بیانگر تعداد دفعات خرید برابر صفر برای آن آیتم است).
در این مطلب، مجموعه داده اصلی با نام (purchase_count)، مجموعه داده جایگزین با نام (purchase_dummy) و مجموعه داده اصلی نرمالسازی شده با نام (scaled_purchase_count) نیز شناخته میشوند.
تقسیمبندی سه مجموعه داده تولید شده به مجموعه دادههای آموزشی و تست
تقسیمبندی دادهها به دو دسته آموزشی و تست، یکی از مهمترین گامهای ارزیابی یک «مدل پیشبینی» (Predicting Model) محسوب میشود. معمولا بخش بزرگتری از مجموعه داده برای آموزش مدل و بخش کوچکتر باقیمانده برای تست آن مورد استفاده قرار میگیرد. در این مطلب، 80 درصد دادهها برای آموزش سیستم توصیهگر و 20 درصد باقیمانده، برای تست آن به کار میروند. از دادههای آموزشی برای آموزش مدل پیشبینی و از دادههای تست برای ارزیابی عملکرد مدل استفاده میشود. با استفاده از قطعه کد زیر، تابع لازم برای تقسیمبندی دادهها تعریف میشود:
پس از تعریف تابع بالا، از طریق قطعه کد زیر میتوان هر کدام از مجموعه دادههای «اصلی»، «جایگزین» و «اصلی نرمالسازی شده» را به دو دسته آموزشی و تست تقسیمبندی کرد.
تعریف مدل پیشبینی برای سیستم های توصیه گر با استفاده از بسته Turicreate
پیش از اینکه روشهای توصیهگر پیشرفته نظیر توصیهگیر مشارکتی را برای پیشنهاد آیتم به مشتریان پیادهسازی کنیم، بهتر است که مدل «پایه» یا «خط مبنا» (Baseline) پیادهسازی کنیم تا بتوانیم عملکرد سیستم توصیهگر پیشرفته را با مدل پایه مقایسه کنیم. در این بخش، دو دسته مدل توصیه گر پیادهسازی شدهاند:
- مدل توصیهگر پایه به نام «مدل محبوبیت» (Popularity Model)
- سیستم توصیهگر پیشرفته به نام «توصیهگیر مشارکتی» (Collaborative Recommender)
پیش از پیادهسازی سیستم های توصیه گر ذکر شده، متغیرهای لازم برای پیادهسازی آنها از طریق قطعه کد زیر تعریف میشوند:
ویژگی مهم بسته Turicreate در زبان پایتون، سادگی تعریف مدلهای یادگیری لازم برای پیادهسازی سیستم های توصیه گر است. با استفاده از تابع زیر، روشهای توصیهگر پایه و پیشرفته، پیادهسازی و فراخوانی میشوند.
پیادهسازی و آموزش «مدل محبوبیت» به عنوان توصیهگر پایه
مدل محبوبیت از محبوبترین آیتمها (محصولات) در بین مشتریان، برای پیشنهاد دادن آیتمهای جدید به مشتریان استفاده میکند. این آیتمها، پر فروشترین محصولات در بین تمامی مشتریان ثبت شده در سیستم هستند. برای آموزش مدل محبوبیت، از دادههای آموزشی در مجموعه دادههای «اصلی»، «جایگزین» و «اصلی نرمالسازی شده» استفاده میشود.
آموزش مدل محبوبیت با استفاده از مجموعه داده «اصلی»:

آموزش مدل محبوبیت با استفاده از مجموعه داده «جایگزین»:

آموزش مدل محبوبیت با استفاده از مجموعه داده «اصلی نرمالسازی شده»:

نتایج به دست آمده برای مدل محبوبیت
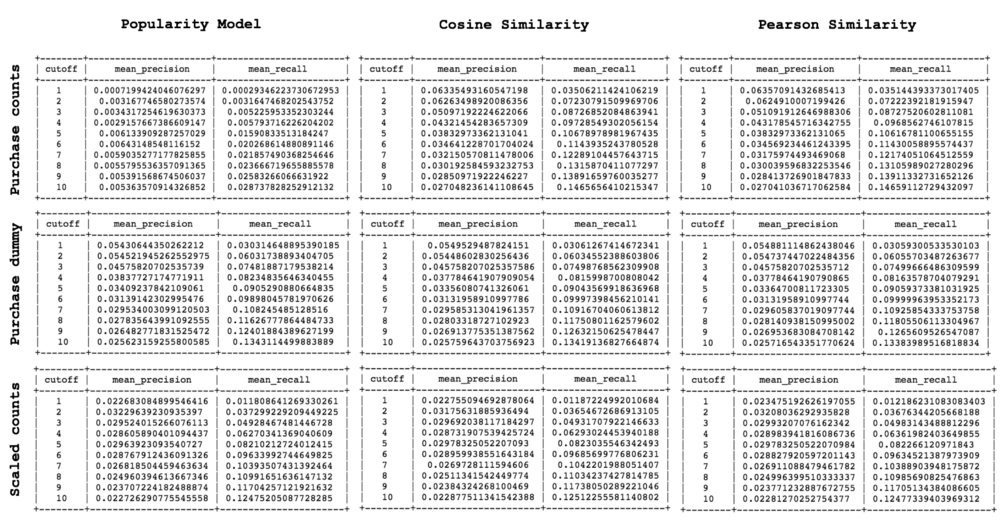
- پس از تولید مدلها، آیتمهای پیشنهادی با استفاده از امتیازات به دست آمده از مدل محبوبیت، پیشبینی میشوند. همان طور که در جداول بالا مشهود است، به ازاری هر کدام از 1000 مشتری موجود در مجموعه دادهها، 10 آیتم پیشنهادی، به ترتیب نزولی و به همراه امتیاز آنها پیشبینی شده است (در جداول بالا، پیشبینیهای انجام شده برای سه کاربر با شناسه 1533، 20400 و 19750 نمایش داده شده است).
- در نتایج تولید شده، مدلهای آموزش دیده شده روی مجموعه دادههای مختلف، آیتمهای متفاوتی را به کاربران پیشنهاد میکنند ولی در هر مدل، آیتمهای پیشنهاد داده شده به همه کاربران یکسان است. دلیل این امر این است که مدل محبوبیت، از محبوبترین آیتمها (محصولات) در بین مشتریان، برای پیشنهاد دادن آیتمها به همه کاربران استفاده میکند.
پیادهسازی و آموزش «مدل توصیهگر مشارکتی»
در سیستمهای فیلتر مشارکتی اطلاعات، آیتمها بر اساس اینکه مشتریان مشابه، چه آیتمهایی (محصولات) را خریداری میکنند، پیشنهاد میشوند. فرض کنید مشتری 1 و مشتری 2 محصولات مشابهی خریداری کرده باشند؛ به عنوان نمونه، مشتری 1، آیتمهای x و y و z را خریداری و مشتری 2، آیتمهای x و y. در چنین حالتی، سیستم توصیهگر مشارکتی، آیتم z را به مشتری دوم نیز پیشنهاد میدهد.
روش توصیهگر مشارکتی
برای تعریف مشابهت میان کاربران، مراحل زیر طی میشوند:
- ابتدا یک ماتریس user-item تولید میشود. در این ماتریس، مقادیر اندیسها (سطرها)، شناسههای یکتای مشتریان و مقادیر ستونها، شناسه یکتای محصولات را نمایش میدهند.
- در مرحله بعد، ماتریس «شباهت آیتم به آیتم» (Item-to-Item Similarity) محاسبه میشود. هدف اصلی تولید این ماتریس، مشخص کردن میزان شباهت یک محصول به محصول دیگر است. برای محاسبه شباهت میان محصولات، میتوان از روشهایی نظیر «شباهت کسینوسی» (Cosine Similarity) و «همبستگی پیرسون» (Pearson Correlation) استفاده کرد.
- برای محاسبه شباهت میان محصولات X و Y، تمامی مشتریانی که محصولات X و Y را خریداری کردهاند مشخص میشوند. فرض کنید مشتری 1 و 2، هر دو این محصولات را خریداری کرده باشند.
- سپس، دو «بردار آیتم» (Item-Vector) به نامهای V1 و V2 در «فضای کاربری» (User Space) مشتری (1 و 2) تولید میشود. مشابهت/همبستگی میان این دو بردار، از طریق روش مشابهت کسینوسی و یا همبستگی پیرسون محاسبه میشود (هر چه مقدار محاسبه شده به 1 نزدیکتر باشد، مشابهت دو بردار بیشتر است).
- سپس، به ازاء هر مشتری، احتمال خریدن یک محصول (و یا تعداد دفعات احتمالی خرید)، برای تمامی محصولاتی که مشتری خریداری نکرده است، محاسبه میشود.
مدل توصیهگر مشارکتی مبتنی بر مشابهت کسینوسی
در این روش، مشابهت میان دو بردار از طریق محاسبه کسینوس زاویه بین بردار متناظر با آیتم A و B به دست میآید. مشابهت کسینوسی از طریق رابطه زیر به دست میآید:
هر چقدر که دو بردار در فضای کاربری به هم نزدیکتر باشند، زاویه میان آنها کمتر و در نتیجه، مشابهت کسینوسی آنها بیشتر میشود. برای آموزش مدل توصیهگر مشارکتی مبتنی بر مشابهت کسینوسی، از مجموعه آموزشی در مجموعه دادههای «اصلی»، «جایگزین» و «اصلی نرمال شده» استفاده میشود.
آموزش مدل توصیهگر مشارکتی مبتنی بر مشابهت کسینوسی با استفاده از مجموعه داده «اصلی»:

آموزش مدل توصیهگر مشارکتی مبتنی بر مشابهت کسینوسی با استفاده از مجموعه داده «جایگزین»:

آموزش مدل توصیهگر مشارکتی مبتنی بر مشابهت کسینوسی با استفاده از مجموعه داده «اصلی نرمالسازی شده»:

مدل توصیهگر مشارکتی مبتنی بر همبستگی پیرسون
در این روش، مشابهت میان دو بردار از طریق محاسبه «ضریب پیرسون» (Pearson Coefficient) میان دو بردار بهدست میآید. همبستگی پیرسون از طریق رابطه زیر به دست میآید:
برای آموزش مدل توصیهگر مشارکتی مبتنی بر همبستگی پیرسون، از مجموعه آموزشی در مجموعه دادههای «اصلی»، «جایگزین» و «اصلی نرمال شده» استفاده میشود.
آموزش مدل توصیهگر مشارکتی مبتنی بر همبستگی پیرسون با استفاده از مجموعه داده «اصلی»:

آموزش مدل توصیهگر مشارکتی مبتنی بر همبستگی پیرسون با استفاده از مجموعه داده «جایگزین»:

آموزش مدل توصیهگر مشارکتی مبتنی بر همبستگی پیرسون با استفاده از مجموعه داده «اصلی نرمالسازی شده»:

ارزیابی سیستم های توصیه گر پیادهسازی شده
برای ارزیابی عملکرد سیستم های توصیه گر پیادهسازی شده، از معیارهایی نظیر «خطای ریشه میانگین مربعها» (Root Mean Squared Errors)، «دقت» (Precision) و «صحت» (Recall) استفاده میشود.
معیار خطای ریشه میانگین مربعها
این معیار، خطای مقادیر پیشبینی شده را محاسبه میکند. هر چه قدر مقدار خطای ریشه میانگین مربعها کمتر باشد، پیشبینیهای تولید شده بهتر خواهند بود.
معیار صحت
این معیار مشخص میکند که چند درصد از محصولاتی که مشتری خریداری میکند، در واقع به او پیشنهاد شده است. به عنوان نمونه، اگر مشتری 5 محصول را خریداری کند و سیستم توصیهگر، سه عدد از این محصولات را به او پیشنهاد داده باشد، میزان صحت این سیستم برابر 0٫6 خواهد بود.
معیار دقت
این معیار مشخص میکند که از بین تمامی محصولات پیشنهاد شده، چه تعدادی از آنها مورد علاقه مشتری بوده است. به عنوان نمونه، اگر پنج محصول به مشتری پیشنهاد شوند و او، چهار عدد از این محصولات را خریداری کند، میزان دقت سیستم برابر 0٫۸ خواهد بود.
ابتدا، متغیرهای لازم برای ارزیابی مدلهای توصیهگر پیادهسازی شده از طریق قطعه کد زیر تعریف میشوند:
با استفاده از قطعه کد زیر، عملکرد سیستم های توصیه گر پیادهسازی شده ارزیابی و با یکدیگر مقایسه میشوند:
نتایج ارزیابی عملکرد روشهای توصیهگر پیادهسازی شده
- ارزیابی عملکرد با توجه به معیار خطای ریشه میانگین مربعها

- ارزیابی عملکرد با توجه به معیارهای دقت و صحت
نتایج به دست آمده از ارزیابی
- ارزیابی نتایج «مدل محبوبیت» در برابر مدلهای «توصیهگر مشارکتی»: همانطور که در نتایج بالا قابل مشاهده است، مدلهای توصیهگر مشارکتی، نتایج بهتری نسبت به مدل محبوبیت روی دادههای مجموعه داده «اصلی» تولید کردهاند. نکته مهم در مورد نتایج تولید شده این است که مدل محبوبیت، نتایج شخصیسازی شده در اختیار کاربران قرار نمیدهد و یک لیست از آیتمهای پیشنهادی را در اختیار تمامی کاربران قرار میدهد.
- ارزیابی نتایج بر مبنای معیار دقت و صحت: با توجه به نتایج به دست آمده، میتوان دریافت که دادههای موجود در مجموعه داده «جایگزین»، سبب تولید آیتمهای پیشنهادی بهتری نسبت به دیگر دادهها میشوند. همچنین، میزان خطای ریشه میانگین مربعها در مدلهای آموزش دیده روی مجموعه دادههای «اصلی»، «جایگزین» و «اصلی نرمال شده»، تقریبا برابر است.
- ارزیابی نتایج بر مبنای معیار خطای ریشه میانگین مربعها: با توجه به نتایج نمایش داده شده، از آنجایی که میزان خطای ریشه میانگین مربعها، در روش توصیهگیر مشارکتی مبتنی بر همبستگی پیرسون بالاتر از روش مبتنی بر شباهت کسینوسی است، در نتیجه، مدل نهایی توصیهگر، مدل مبتنی بر شباهت کسینوسی خواهد بود.
در نهایت، مدل توصیهگر مشارکتی مبتنی بر شباهت کسینوسی که روی مجموعه داده «جایگزین» آموزش دیده است، به عنوان مدل نهایی برای تولید آیتمهای پیشنهادی به مشتریان انتخاب میشود.
مدل توصیهگر نهایی
در انتها، دو تابع دیگر معرفی خواهد شد؛ یکی از این توابع، وظیفه تولید خروجیهای سیستم توصیهگر در قالب فایل (CSV.) و دیگری، وظیفه نمایش لیست پیشنهادات تولید شده بر مبنای تراکنشهای (خرید) یک کاربر خاص را دارد. در ابتدا لازم است تا مدل انتخابی، با استفاده از دادههای آموزشی مجموعه داده «جایگزین» آموزش ببیند. سپس، مدل آموزش دیده روی دادههای تست ارزیابی شود.
تولید خروجیهای سیستم توصیهگر در قالب فایل (CSV.)
ابتدا، فرمت کنونی خروجی سیستم پیشنهادی با استفاده از کد زیر نمایش داده میشود.

سپس، از تابع زیر برای تولید خروجی مطلوب در قالب فایل (CSV.) استفاده میشود.
با فراخوانی تابع بالا و برابر با True کردن مقدار پارامتر print_csv، خروجی مدل توصیهگر پیشنهادی در قالب فایل (CSV.) ذخیره خواهد شد.

تابع تولید پیشنهاد برای مشتریان با استفاده از شناسه یکتا آنها
در نهایت، با استفاده از تابع زیر و با داشتن شماره شناسه یکتای مشتریان، لیستی از آیتمهای پیشنهادی برای مشتریان تولید و در خروجی نمایش داده میشوند.


کدهای جایگزین برای پیادهسازی مدل توصیهگر مشارکتی مبتنی بر شباهت کسینوسی (آموزش دیده روی مجموعه داده «جایگزین») در ادامه آمده است. این کد، با کدهای ارائه شده در این مطلب تفاوت دارند. در این کد، از بسته Turicreate، برای پیادهسازی و ارزیابی مدل توصیهگر پیشنهادی استفاده نشده است. شایان توجه است که کدهای ارائه شده در مطلب (کدهایی که از بسته Turicreate استفاده کردهاند)، بهینهتر و سریعتر از این کد هستند.
جمعبندی
در این مطلب، گامهای مرحله به مرحله برای تولید سیستمهای توصیهگیر در زبان برنامهنویسی پایتون شرح داده شدهاند. همچنین، روشهای توصیهگر مشارکتی مبتنی بر مشابهت کسینوسی و همبستگی پیرسون، پیادهسازی شدند و ارزیابی و مقایسه عملکرد آنها با مدل توصیهگر پایه در دستور کار قرار گرفت.

مدلهای پیادهسازی شده، روی سه مجموعه داده «اصلی»، «جایگزین» و «اصلی نرمال شده» آموزش و تست شدند. نتایج ارزیابی نشان میدهد که مدل توصیهگر مشارکتی مبتنی بر شباهت کسینوسی که روی مجموعه داده «جایگزین» آموزش دیده است، بهترین آیتمهای پیشنهادی را برای مشتریان تولید میکند.
اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- آموزش اصول و روشهای داده کاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- روشهای متنکاوی — راهنمای کاربردی
- متنکاوی (Text Mining) — به زبان ساده
- ساخت سیستم توصیهگر (Recommender System) فیلم با پایتون — راهنمای جامع و ساده
^^








سلام. ماژول turicreate رو نمیشناسه توی گوگل کولب. چطور میشه نصبش کرد؟ ممنون
سلام وقت بخیر
من دانشجوی دکتری رشته مدیریت فناوری اطلاعات هستم و پایان نامه من در خصوص سیستم های توصیه گر آیتم محور است که در آن از خوشه بندی فازی استفاده می شود می خواستم بپرسم برای اجرای پایان نامه ام از متلب باید استفاده کنم یا پایتون؟؟
ممکن است در انجام پایان نامه ام به من کمک کنید البته با دریافت حق الزحمه
سلام وقت بخیر
ببخشید من paython 2.7.18 را نصب کردم اما این کدها در آن error می دهد می شه راهنمایی کنید باید از کجا شروع کنم؟
البته من از قسمت IDLE استفاده کردم
با سلام هنگام اجرای بخش تست و آموزش، با خطای زیر مواجه میشوم، لطفا راهنمایی کنید علت چیست مرسی
module ‘turicreate’ has no attribute ‘SFrame’
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزاریم. بر اساس خطا، خصیصه SFrame در جایی مورد استفاده قرار گرفته است، در حالی که در ماژول «turicreate» وجود ندارد. احتمالا در پیادهسازی کد بر اساس مقاله، اشتباهی انجام شده و یا نیاز به انجام تغییراتی در کد متناسب با پیادهسازی جدید آن در سیستم خودتان هستید.
خیلی عالی بود ممنون
ba salam
ein kod naghese faile paython mishe bezarid??????