



مهندسی ویژگی چیست؟ – Feature Engineering به زبان ساده
در بیشتر اوقات و هنگامی که قصد طراحی مدلهای یادگیری ماشین را داریم، دادهها فاقد نظم و ترتیب مشخصی هستند. دادههایی که پیش از پاکسازی و پیشپردازش قابل استفاده نبوده و همینجاست که نیاز ما به «مهندسی ویژگی» (Feature Engineering) نمایان میشود. فرایندی که به اطلاعات مورد نیاز مسئله نظم و ترتیب میدهد. در این مطلب از مجله فرادرس یاد میگیریم مهندسی ویژگی چیست و چرا موفقیت هر نوع از مدل یادگیری ماشین به کاربرد انواع تکنیکهای مهندسی ویژگی وابسته است.
- یاد خواهید گرفت اهمیت مهندسی ویژگی در پروژههای دادهمحور چیست.
- میآموزید چگونه دادههای خام را برای مدلهای ML آماده کنید.
- شناخت روشهای انتخاب و تبدیل ویژگیها را بهدست میآورید.
- یاد میگیرید Outlierها و Missing Values را اصولی مدیریت کنید.
- با تکنیکهای کدگذاری دستهای و تبدیل متغیر آشنا میشوید.
- توانایی کار با ابزارهای مهم Feature Engineering را پیدا میکنید.




در این مطلب، ابتدا یاد میگیریم مهندسی ویژگی چیست و چه اهمیتی دارد. سپس با انواع تکنیکهای مهندسی ویژگی و چگونگی پیادهسازی هر کدام آشنا میشویم و در انتهای این مطلب از مجله فرادرس، به بررسی مزایا و همچنین معرفی تعدادی از ابزارهای رایج و کاربردی در این حوزه میپردازیم.
مفهوم مهندسی ویژگی چیست؟
همه الگوریتمهای یادگیری ماشین از تعدادی داده ورودی برای تولید خروجی متناسب بهره میبرند. دادههای ورودی ویژگیهای بسیاری را شامل میشوند که ممکن است بهخاطر فرمتی که دارند، قابل استفاده مستقیم برای مدل یادگیری ماشین نباشند. این نمونه دادهها را ابتدا باید پردازش کرد و در اینجا «مهندسی ویژگی» (Feature Engineering) بهکار میآید. بهطور کلی هدف از مهندسی ویژگی را میتوان در دو مورد زیر خلاصه کرد:

- آمادهسازی دیتاست یا مجموعهداده ورودی به نحوی که مورد استفاده مدل یا الگوریتم یادگیری ماشین باشد.
- بهبود عملکرد مدلهای یادگیری ماشین.

برای درک راحتتر میتوانیم مهندسی ویژگی را هنر انتخاب ویژگیهای مهم و تبدیل آنها به موجودیتهایی ارتقا یافته و متناسب با نیازهای مدل یادگیری تصور کنیم. مهندسی ویژگی دربرگیرنده تکنیکهای فراوانی مانند انتخاب ویژگیهای مرتبط، مدیریت دادههای گمشده، «کدگذاری» (Encoding) و نرمالسازی داده است. فرایند مهندسی ویژگی از ضرورت بالایی برخوردار بوده و نقش مهمی در تعیین خروجی مدل ایفا میکند. برای آنکه از بهینه بودن عملکرد الگوریتم یادگیری خود مطمئن شویم، بسیار اهمیت دارد که ویژگیهای ورودی را به شکل کارآمدی مهندسی کنیم.
چرا مهندسی ویژگی اهمیت دارد؟
بهمنظور آشنایی با میزان زمانبر بودن هر کدام از مراحل اجرایی در پروژههای یادگیری ماشین، توجه شما را به نمودار زیر جلب میکنیم:
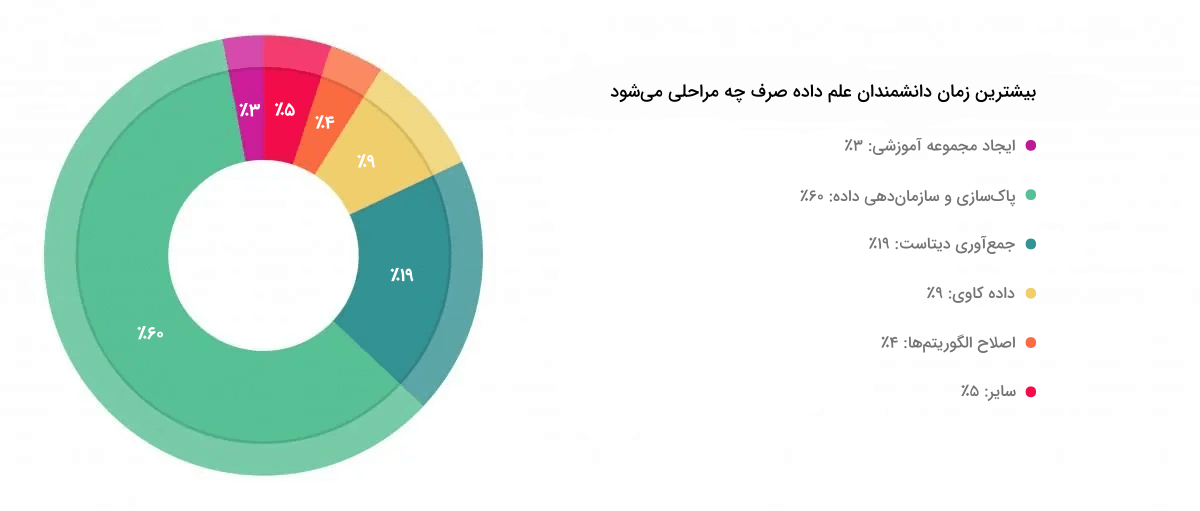
نمودار دایرهای فوق شامل نتایجی است که از نظرسنجی طراحی شده توسط نشریه «فوربز» (Forbes) بهدست آمده است. همانطور که به وضوح از آمار و ارقام مشخص است، یکی از وظایف اصلی هر دانشمند داده، پاکسازی و پردازش دادههای خام است. موضوعی که گاهی تا ۸۰ درصد از زمان متخصصان علم داده را به خود اختصاص میدهد. از همین جهت، مهندسی ویژگی با مرتبسازی و پردازش مناسب، دادهها را برای آموزش دادن مدلهای یادگیری ماشین و تولید خروجیهای متناظر آماده میکند.

برای درک بهتر اهمیت مهندسی ویژگی، بهتر است ابتدا با نحوه جمعآوری دادهها آشنا شویم. در بیشتر موارد، دادههایی که تحلیلگران با آنها سر و کار دارند، از منابعی با دسترسی آزاد و همچنین وسیع مانند فضای وب، نظرسنجیها یا نقد و بررسیها جمعآوری شدهاند. اطلاعات پردازش نشدهای که با عنوان دادههای خام شناخته میشوند. در میان این دادهها ممکن است مقادیر گمشده، ورودیهای نادرست و «نمونههای پرت» (Outliers) وجود داشته باشند. اگر بهطور مستقیم، یعنی بدون هیچگونه پردازشی از این دادهها برای آموزش مدل استفاده کنیم، بسیار بعید است به نتایج مورد انتظار و دلخواه خود برسیم. به همین خاطر، مهندسی ویژگی نقش موثری در تعیین عملکرد مدلهای یادگیری دارد.
یادگیری انتخاب ویژگی در داده کاوی با فرادرس

اگر تا اینجا همراه مطلب بوده باشید، بهخوبی میدانید که مهندسی ویژگی یکی از مهمترین بخشها در پردازش و آمادهسازی داده برای کاربردهایی همچون داده کاوی و هوش مصنوعی است. این فرایند شامل انتخاب، استخراج و ایجاد ویژگیهای مناسب از دادههای خام برای بهبود عملکرد الگوریتمهای یادگیری ماشین میشود. از همین جهت، انتخاب ویژگی یکی از تکنیکهای کلیدی در مهندسی ویژگی محسوب میگردد.
در پروژههای حقیقی داده کاوی اغلب با تعداد زیادی ویژگی یا متغیر مواجه هستیم که ممکن است همه آنها برای مدل یادگیری مفید نباشند. به عنوان مثال شاید برخی ویژگیها اطلاعات تکراری یا غیر مرتبطی ارائه دهند که نه تنها باعث افزایش پیچیدگی مدل شده، بلکه میتوانند دقت و کارایی آن را نیز کاهش دهند. با توجه به اهمیت این موضوع، مجموعه فرادرس دوره ویژهای را تحت عنوان فیلم آموزش مبانی انتخاب ویژگی در داده کاوی تهیه کرده است که با مراجعه به لینک زیر میتوانید از آن بهره ببرید:
معرفی انواع تکنیک های مهندسی ویژگی
پس از پاسخ دادن به پرسش مهندسی ویژگی چیست، حال زمان آن رسیده است تا در این بخش با انواع تکنیکهای مهندسی ویژگی و نحوه پیادهسازی آنها آشنا شویم. ما برای این کار از زبان برنامه نویسی پایتون و دو کتابخانه Pandas و Numpy کمک میگیریم. ابتدا کتابخانه Pandas را با اجرای دستور زیر در محیط «خط فرمان» (Command Line) نصب میکنیم:
pip install pandasسپس همین روند را اینبار برای کتابخانه Numpy تکرار میکنیم:
pip install numpyحالا که ابزارهای مورد نیاز خود را در اختیار داریم، میتوانیم به شرح برخی از رایجترین تکنیکهای مهندسی ویژگی برای پردازش داده بپردازیم. پس از معرفی این تکنیکها، هر کدام را همراه با کاربردهای آن، بهصورت جداگانه و عمیقتر بررسی میکنیم. بهطور کلی تکنیکهای مهندسی ویژگی را میتوان به پنج گروه زیر تقسیم کرد:
- جایگذاری دادههای گمشده
- کدگذاری طبقهبندی شده
- تبدیل متغیر
- مهندسی نمونههای پرت
- مهندسی ویژگی زمان و تاریخ

در ادامه هر کدام از تکنیکهای فوق را بهصورت جداگانه مورد بررسی قرار میدهیم.
جایگذاری داده های گمشده
در مطالب مربوط به علم داده و بهطور کلی داده کاوی، هر زمان از «ویژگی» (Feature) صحبت میشود در واقع منظورمان همان ستونهای دیتاست است. امکان دارد میان ویژگیهای ورودی برخی مقادیر یا دادههای گمشده وجود داشته باشد. مانند زمانی که برای یک موجودیت خاص اطلاعاتی وارد نمیشود. مشکل دادههای گمشده بسیار رایج بوده و از آنجا که در اغلب دیتاستها نیز دیده میشود، اجتناب از آن راهحل مناسبی نیست. تنها زمانی متوجه تاثیر دادههای گمشده میشوید که از دیتاستی با این مشکل برای آموزش مدلهای یادگیری ماشین استفاده کنید و به تجزیه و تحلیل نتایج بهدست آمده بپردازید. برای یادگیری بیشتر در مورد روشهای پیشپردازش داده، میتوانید فیلم آموزش تجزیه و تحلیل دادهها با پایتون فرادرس که لینک آن در ادامه قرار داده شده است را مشاهده کنید:

اما منظور از جایگذاری، در واقع همان تعویض یا جایگزین کردن نمونههای گمشده با تخمین آماری حاصل از مقادیر گمشده است. بدین شکل میتوانیم دادههای مجموعه آموزشی را تکمیل کرده و از آن برای پیشبینی در هر مدل یا الگوریتمی بهره ببریم. تکنیکهای مختلفی برای جایگذاری دادههای گمشده وجود دارد که در فهرست زیر به چند مورد از آنها اشاره شده است:
- «تحلیل حالت کامل» (Complete Case Analysis)
- «جایگذاری میانگین» (Mean Imputation)، «جایگذاری میانه» (Median Imputation) و «جایگذاری نما» (Mode Imputation)
- «نشانگر مقادیر گمشده» (Missing Value Indicator)
در ادامه این بخش و حالا که یاد گرفتیم منظور از جایگذاری دادههای گمشده در مهندسی ویژگی چیست، توضیح کاملتری از تکنیکهای جایگذاری ارائه میدهیم.
روش تحلیل حالت کامل
در واقع روش «تحلیل حالت کامل» (Complete Case Analysis) به تجزیه و تحلیل مشاهداتی در مجموعهداده اشاره دارد که مقدار گمشدهای ندارند. یا به بیان سادهتر، تمامی ویژگیهایی که بخشی از اطلاعات آنها گمشده است را نادیده میگیرد. اما این روش تنها زمانی کارساز است که تعداد دادههای گمشده محدود باشد. در غیر اینصورت حجم دیتاست بهطرز چشمگیری کاهش یافته و در عمل دیگر قابل استفاده نخواهد بود. به همین خاطر و از آنجا که بخش عظیمی از اغلب دیتاستهای کاربردی را دادههای گمشده فرا گرفتهاند، بهکارگیری روش تحلیل حالت کامل چندان پیشنهاد نمیشود. مگر آنکه تعداد نمونههای گمشده زیاد نباشد.

بهتر است در عمل و با بهرهگیری از دیتاست مشهور «تایتانیک» (Titanic) که شامل اطلاعت مسافران کشتی تایتانیک است، روش تحلیل حالت کامل را پیادهسازی کنیم و بیشتر با نحوه کارکرد آن آشنا شویم. برای شروع و با اجرای قطعه کد زیر، دیتاست Titanic را در متغیری با همین نام ذخیره میکنیم و برای آنکه دیتاست اصلی بدون تغییر باقی بماند، نمونهای کپیبرداری شده از آن را در متغیری با نام titanic_dfبارگذاری میکنیم:
با توجه به این موضوع که بسیاری از دادههای دیتاست Titanic ناقص هستند و ۷۷ درصد از ستونی مانند Cabin را مقادیر گمشده تشکیل میدهند، حذف جایگاههای خالی باعث کاهش شدید اندازه دیتاست میشود. قطعه کد زیر درصد ویژگیهایی که فاقد مقدار گمشده هستند را نتیجه میدهد:
خروجی مانند زیر است:
total passengers with values in all variables: 183
total passengers in the Titanic: 891
percentage of data without missing values: 0.2053872053872054همانطور که ملاحظه میکنید، تنها اطلاعت ۲۰ درصد از کل مسافران کامل است. از همین جهت، روش تحلیل حالت کامل نمیتواند گزینه مناسبی برای این دیتاست باشد.
جایگذاری میانگین، میانه و نما
مقادیر گمشده را میتوان با مقدار میانگین، میانه و یا نما مربوط به کل نمونههای یک ستون یا ویژگی جایگزین کرد. روشی بسیار رایج در مسابقات و هر مسئلهای که با مشکل دادههای گمشده مواجه است. زمانی استفاده از این تکنیک پیشنهاد میشود که علاوهبر تعداد کم، الگوی گمشدگی دادهها نیز تصادفی باشد. برای جایگذاری مقادیر ستون Age در دو مجموعه آموزشی و آزمون مانند زیر عمل میکنیم:
خروجی اجرای قطعه کد فوق مانند زیر است:
0مقدار خروجی ۰، نشاندهنده این است که ویژگی Age دیگر مقدار خالی یا Null ندارد. توجه داشته باشید که عمل جایگذاری ابتدا باید نسبت به مجموعه آموزشی و سپس مجموعه آزمون انجام شود. به این صورت که تمامی دادههای گمشده در مجموعه آموزشی و آزمون فقط با مقادیر استخراج شده از مجموعه آموزشی جایگزین میشوند. رویکردی که احتمال وقوع مشکل بیشبرازش را کاهش میدهد.
نشانگر مقادیر گمشده
در این تکنیک برای به نمایش گذاشتن موقعیت وجود یا عدم وجود یک نمونه داده، از یک متغیر دودویی استفاده میشود. به این شکل که اگر نمونه داده موجود نباشد یا به اصطلاح گم شده باشد، متغیر دودویی مقدار ۱ و در غیر اینصورت مقدار ۰ را به خود میگیرد. اما هنوز نیاز به جایگذاری مقادیر گمشده داریم که برای این منظور از روش جایگذاری میانگین یا میانه کمک میگیریم. با ترکیب این دو روش، ابتدا مقادیر گمشده مشخص و سپس جایگذاری میشوند. اجرای قطعه کد زیر، ستونی با عنوان Age_NA در هر دو مجموعه آموزشی و آزمون برای نشانهگذاری مقادیر گمشده ایجاد میکند:
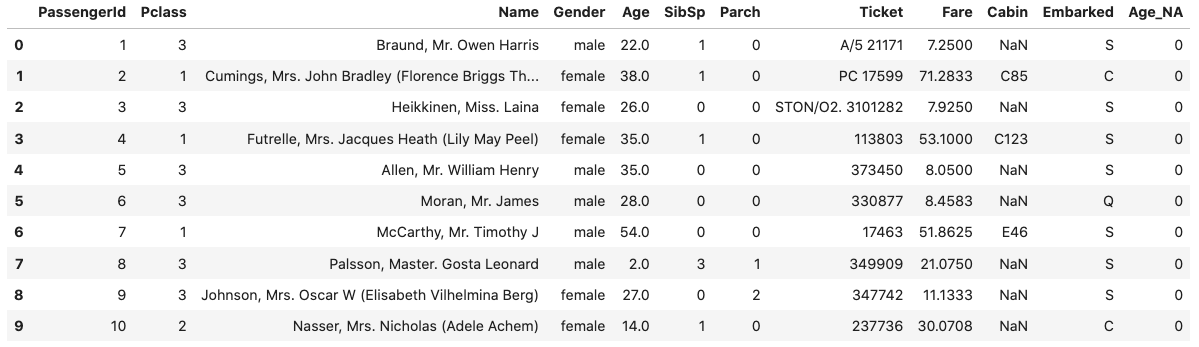
در تصویر زیر، خروجی حاصل از پنج سطر اول دیتاست را مشاهده میکنید:

با فراخوانی دو متد meanو median، مقدار میانگین و میانه ویژگی Age را بهدست میآوریم:
خروجی مانند زیر است:
(29.36158249158249, 28.0)حالا و از آنجا که تفاوتی چندانی در مقدار میانگین و میانه مشاهده نمیشود، از معیار میانه برای انجام عمل جایگذاری استفاده میکنیم:
جدول زیر ده سطر اول دیتاست را پس از جایگذاری نشان میدهد:
کدگذاری طبقه بندی شده
دادههای طبقهبندی شده، نمونههایی هستند که تعداد محدودی از مقادیر را میپذیرند. به عنوان مثال ستون Gender یا جنسیت با دو مقدار «مرد» (Male) و «زن» (Female) یا ستون مدل ماشین با مقادیری همچون «هوندا» (Honda) و «تویوتا» (Toyota) از جمله متغیرهای طبقهبندی شده بهحساب میآیند. اگر توجه داشته باشید، تعداد مقادیری که چنین ویژگیهایی میتوانند اتخاذ کنند محدود است. اگر ورودی مدل یادگیری، دیتاستی با متغیرهای طبقهبندی شده باشد، در خروجی خطا دریافت میکنید. به همین جهت باید ابتدا با بهرهگیری از تکنیکهای کدگذاری طبقهبندی شده که در فهرست زیر به برخی از آنها اشاره شده است، دادههای طبقهبندی شده را به فرم دیگری تبدیل یا به اصطلاح کدگذاری کنید:

- «کدگذاری وان هات» (One Hot Encoding | OHE)
- کدگذاری ترتیبی
- کدگذاری شمارش و تکرار
- کدگذاری هدف یا میانگین

حالا که یاد گرفتیم منظور از روش کدگذاری در مهندسی ویژگی چیست، در ادامه شرح کاملتری از تکنیکهای فوق ارائه میدهیم.
کدگذاری وان هات
از «کدگذاری وان هات» (One Hot Encoding | OHE) به عنوان روشی رایج برای کدگذاری متغیرهای طبقهبندی شده یاد میشود. در این روش برای هر دسته یا کلاس، متغیر دودویی مجزایی ایجاد میشود. اگر داده مربوط به هر کلاس موجود باشد، متغیر دودویی مقدار ۱ و در غیر اینصورت مقداری برابر با ۰ خواهد داشت. هر متغیر جدید را «متغیر مجازی» (Dummy Variable) یا متغیر دودویی مینامند. به عنوان مثال برای متغیر طبقهبندی شده Gender یا همان جنسیت با دو کلاس Male و Female، دو متغیر دودویی ساخته میشود. اگر جنسیت از نوع مذکر باشد مقدار متغیر دودویی Male مساوی ۱ و متغیر Female برابر با ۰ خواهد بود. و اگر جنسیت فرد، مونث باشد اینبار مقدار متغیر دودویی Female مساوی ۱ و متغیر Male برابر با ۰ میشود. قطعه کد زیر نحوه اعمال تکنیک کدگذاری وان هات را بر روی ویژگی Gender در دیتاست Titanic نشان میدهد:
نتیجه جدولی مانند زیر است:

همانطور که مشاهده میکنید، برای نمایش ویژگی طبقهبندی شده Gender تنها به ۱ متغیر مجازی نیاز است. در نتیجه با بسط این قضیه نتیجه میگیریم که برای n دسته یا گروه، تنها به n -1 متغیر مجازی یا دودویی نیاز داریم و بهراحتی میتوانیم یکی از آنها را مانند زیر حذف کنیم:
خروجی، یک جدول تک ستونه مانند زیر خواهد بود:

کدگذاری ترتیبی
منظور از واژه ترتیبی مشخص است و در اینجا نیز به متغیرهای طبقهبندی شدهای با مقادیر مرتب شده اشاره دارد. به عنوان مثال، نمرات امتحانی دانشآموزان نوعی ویژگی ترتیبی است. ویژگی که دامنه آن از ۰ تا ۲۰ متغیر است. در قطعه کد زیر ابتدا لیستی از سه شهر پاریس، توکیو و آمستردام ایجاد میکنیم و سپس با استفاده از کلاس LabelEncoderکتابخانه Scikit-learn، معادل مرتب شده لیست را برمیگردانیم:
خروجی مانند زیر است:
['tokyo', 'tokyo', 'paris']کدگذاری شمارش و تکرار
در این نوع از کدگذاری یعنی روش شمارش و تکرار، مقدار اولیه هر دسته یا گروه با تعداد دفعات تکرار آن در دیتاست جابهجا میشود. این جابهجایی را میتوان با درصد تکرار هر نمونه مشاهده شده در دیتاست نیز انجام داد. به عنوان مثال اگر ۳۰ مورد از افراد مرد باشند، ویژگی مرد یا Male با عدد ۳۰ یا ۰/۳ قابل تعویض است. کدگذاری شمارش و تکرار بهویژه در مسابقات علم داده طرفدار بسیاری داشته و در واقع نشاندهنده تعداد دفعاتی است که هر برچسب یا گروه در دیتاست مشاهده شده است.
کدگذاری هدف یا میانگین
طی فرایند کدگذاری هدف که گاهی با عنوان کدگذاری میانگین نیز شناخته میشود، بهجای برچسب ویژگیها، مقدار میانگین متغیر هدف را قرار میدهیم. فرض کنید ویژگی طبقهبندی شدهای با نام شهر یا City داریم و میخواهیم پیشبینی کنیم که آیا بر اساس تبلیغی که انجام شده، مشتریها تلویزیون را خریداری میکنند یا خیر. اگر ۳۰ درصد از ساکنین شهر لندن تلویزیون را خریداری کنند، برچسب لندن یا London را با عدد ۰/۳ جایگزین میکنیم. به این شکل دیگر صرفنظر از متغیر هدف، اطلاعات ارزشمندی بهدست آمده و فضای کمتری نیز اشغال میشود. با این حال، دقت داشته باشید که استفاده از این تکنیک ممکن است به مشکل بیشبرازش منتهی شود.

در قطعه کد زیر مثالی از پیادهسازی کدگذاری هدف یا میانگین را ملاحظه میکنید که در آن ابتدا دیتاستی شامل نام ۴ اتومبیل با عناوین C1 تا C4 ایجاد و متغیر هدف با مقادیر دودویی به نمایش گذاشته شده است:
نتیجه اجرای این پیادهسازی مانند نمونه است:

در ادامه و ابتدا مانند زیر، متغیر هدف را با تعداد تکرار هر نمونه جایگزین میکنیم:
خروجی مانند زیر است:

همچنین جایگذاری متغیر هدف با مقدار میانگین مانند زیر انجام میشود:
پس از جایگذاری متغیر هدف با مقدار میانگین نتیجهای مانند نمونه حاصل میشود:

در انتها و برای درک بهتر، ستونی با عنوان Target ایجاد کرده و مقادیر متغیر هدف را نیز نشان میدهیم:
خروجی نهایی جدولی مانند زیر است:

تبدیل متغیر
الگوریتمهای یادگیری ماشین مانند رگرسیون خطی و لجستیک توزیع متغیرهای را از نوع نرمال فرض میکنند. گاهی میتوان برای متغیری که توزیع نرمال ندارد، تبدیل ریاضیاتی با توزیع گاوسی پیدا کرد. اغلب، دیتاستهایی با توزیع گاوسی باعث بهبود عملکرد الگوریتم یادگیری ماشین میشوند. به عنوان برخی از رایجترین اتبدیلات آماری میتوان به موارد زیر اشاره کرد:
- تبدیل لگاریتمی
- تبدیل ریشه دوم
- «تبدیل متقابل» (Reciprocal Transformation)
- تبدیل نمایی
بهتر است حالا که میدانیم مهندسی ویژگی چیست و روش تبدیل متغیر چگونه کار میکند، تکنیکهای عنوان شده در فهرست فوق را بر روی دیتاست Titanic اعمال کنیم. برای این کار ابتدا به بارگذاری ویژگیهای عددی دیتاست میپردازیم:
خروجی به شرح زیر است:

در قدم اول باید جای خالی مقادیر گمشده را پر کنیم. به همین منظور از نمونههای تصادفی برای جایگذاری کمک میگیریم:
سپس برای مصورسازی توزیع متغیرِ سن یا همان Age از دو نمودار هیستوگرام و «چندک چندک» (Q-Q) استفاده میکنیم:
پس از اجرای قطعه کد بالا، دو نمودار زیر حاصل میشود. در سمت راست نمودار Q-Q و در سمت چپ تصویر نمودار هیستوگرام ترسیم شده است:
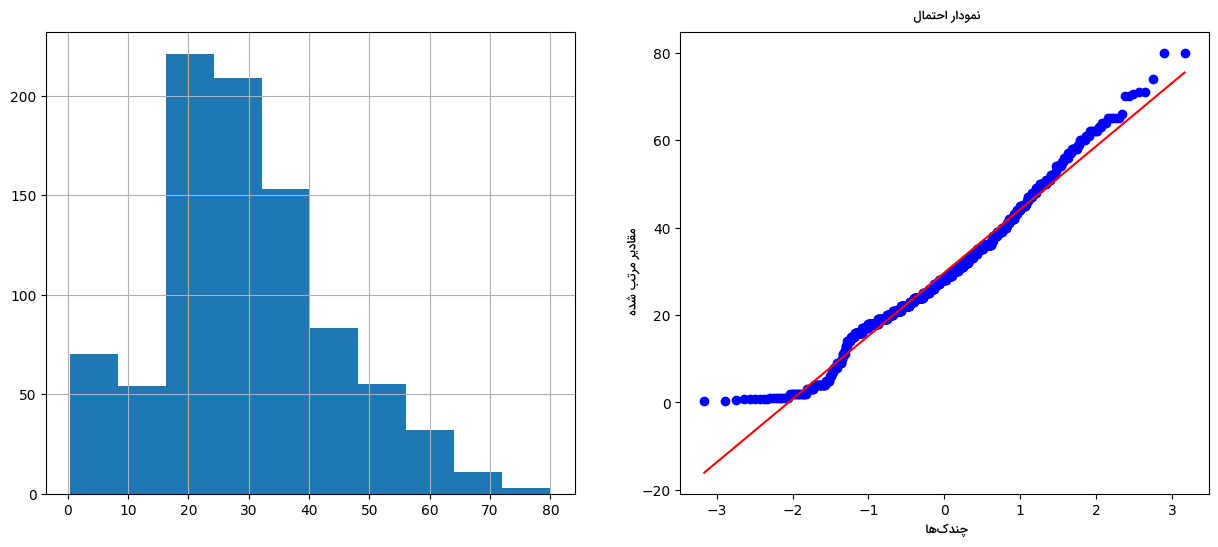
همانطور که ملاحظه میکنید، ویژگی Age توزیع به نسبت نرمالی دارد. همچنی کمی انحراف را در سمت چپ هیستوگرام شاهد هستیم. در ادامه این بخش از مطلب مجله فرادرس، چهار نوع تکنیک تبدیل متغیر که در ابتدا به آنها اشاره شد را بر روی متغیر Age پیادهسازی و نتایج بهدست آمده را با یکدیگر مقایسه میکنیم.
تبدیل لگاریتمی
برای پیادهسازی روش تبدیل لگاریتمی مانند نمونه عمل میکنیم:

دو نمودار بهدست آمده از ویژگی Age مانند زیر خواهد بود:
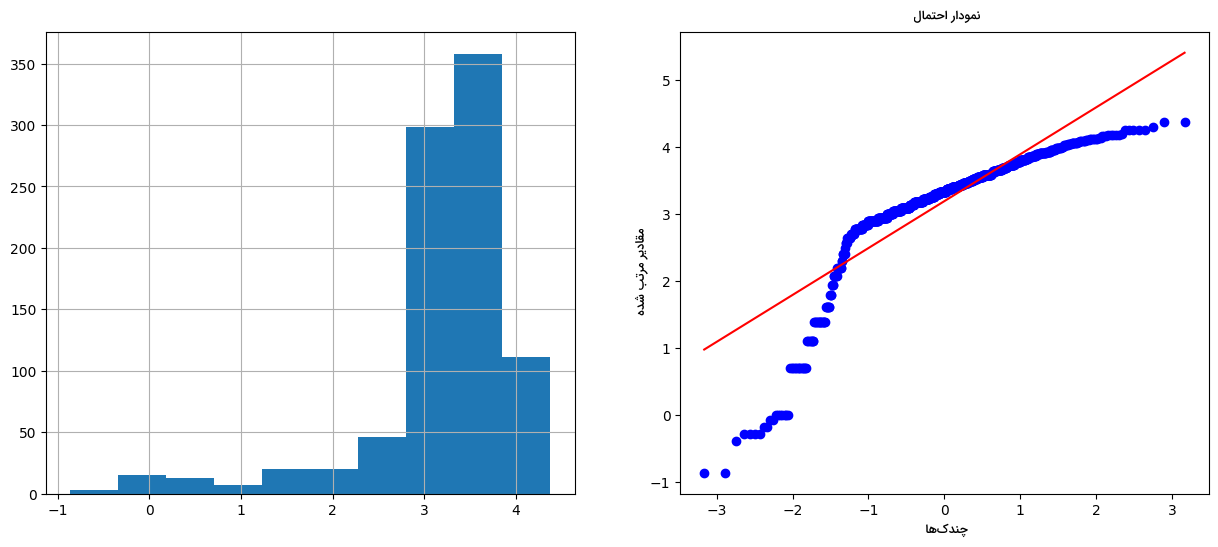
مشاهده میکنید که تبدیل لگاریتمی نتوانسته توزیع ویژگی Age را به گاوسی تغییر دهد.
تبدیل ریشه دوم
در قطعه کد زیر نحوه اعمال روش تبدیل ریشه دوم بر ویژگی Age شرح داده شده است:
خروجی مانند زیر است:
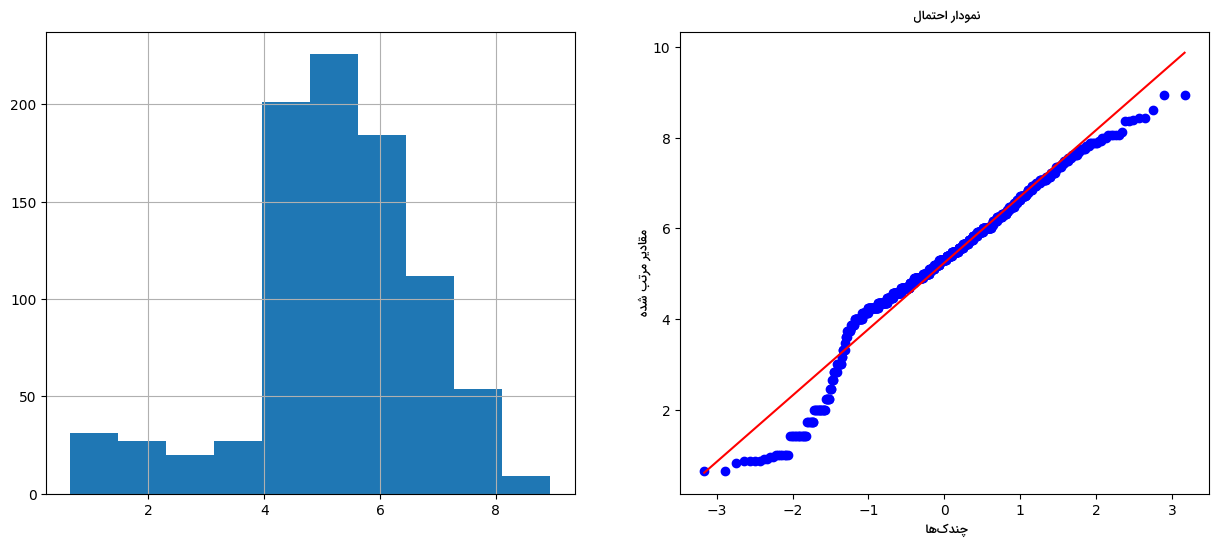
نتیجه کمی بهتر از تبدیل لگاریتمی بوده اما توزیع متغیر همچنان به فرم گاوسی در نیامده است.
تبدیل متقابل
پیادهسازی تکنیک «تبدیل متقابل» (Reciprocal Transformation) مانند زیر انجام میشود:
توزیع نهایی به شکل زیر است:
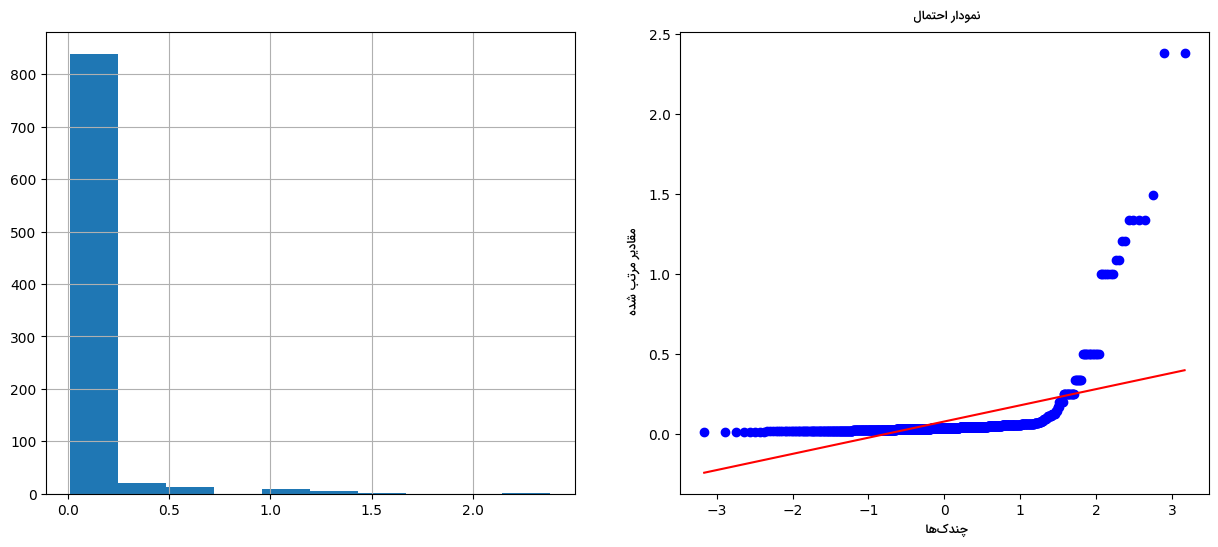
با توجه به نتایج بهدست آمده، بدیهی است که این نوع از تبدیل نیز نتوانسته توزیع ویژگی Age را به نرمال تغییر دهد.
تبدیل نمایی
برای اعمال روش تبدیل نمایی بر ویژگی Age مانند نمونه عمل میکنیم:
در خروجی، نمودارهایی مانند زیر ترسیم میشود:
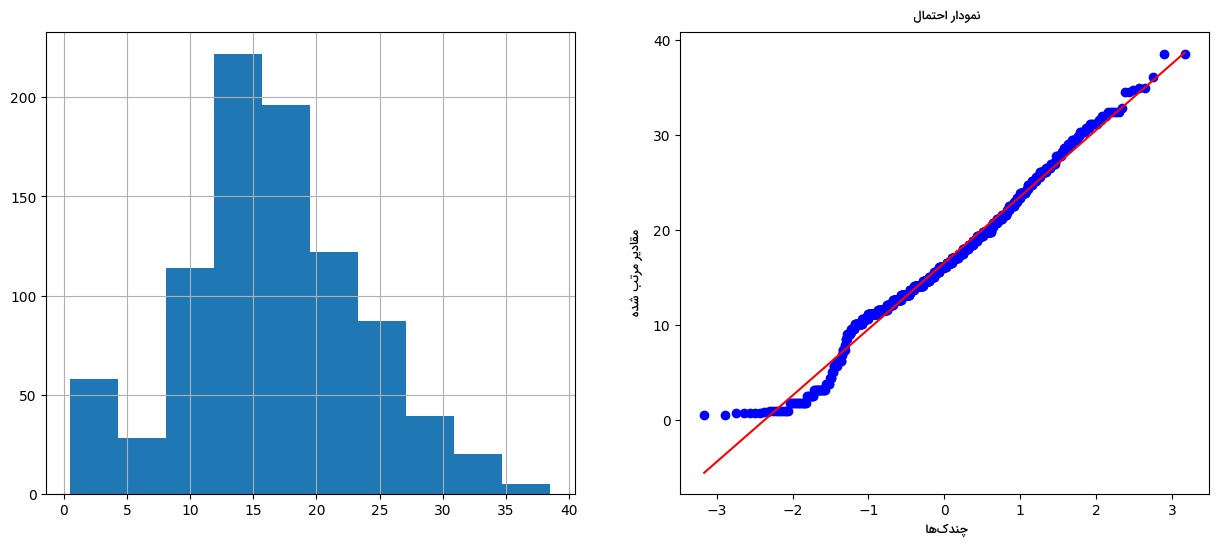
همانطور که مشاهده میکنید، این نوع از تبدیل، بهترین نتیجه را از میان سه روش دیگر ارائه و توزیع متغیر مورد نظر را به نرمال تغییر داده است.
مهندسی نمونه های پرت
در ادامه پاسخ دادن به پرسش مهندسی ویژگی چیست و بررسی انواع تکنیکهای مختلف آن، این بخش را به معرفی روش مهندسی نمونههای پرت اختصاص میدهیم. نمونههای پرت به دادههایی گفته میشود که مقدار به مراتب بیشتر یا کمتری نسبت به سایر دادهها دارند. برخی از تکنیکهای مدیریت نمونههای پرت به شرح زیر است:

- حذف نمونههای پرت.
- در نظر گرفتن نمونههای پرت به عنوان مقادیر گمشده.
- محدودسازی نمونههای پرت.

برای شناسایی نمونههای پرت در توزیع گاوسی، تنها کافیست نگاهی به دادههای خارج از میانگین که سه برابر از انحراف معیار فاصله دارند بیندازیم. اما اگر توزیع از نوع گاوسی یا نرمال نباشد، میتوانیم در عوض از «چندکها» (Quantiles) و «دامنه میان چارکی» (Interquartile Range | IQR) استفاده کنیم. در بخش زیر فرمول محاسبه دامنه میان چارکی آورده شده است:
حد بالا مانند زیر محاسبه میشود:
همچنین برای محاسبه حد پایین مطابق با فرمول زیر عمل میکنیم:
در نهایت میتوان نتیجه گرفت که نمونههای پرت جایی خارج از دو حد بالا و پایین قرار دارند. مجله فرادرس مطلب جامعتری را درباره مفاهیم آماری مانند صدک و چارک آماده کرده است که میتوانید با مراجعه به لینک زیر آن را مطالعه کنید:
حدف نمونه های پرت
همانگونه که از نام آن مشخص است، در رویکرد حذف نمونههای پرت، این قبیل از نمونه دادهها را از دیتاست حذف میکنیم. اگر تعداد دادههای پرت زیاد نباشد، حذف آنها چندان تاثیری بر دیتاست نمیگذارد. اما اگر نمونههای پرت در چندین متغیر پراکنده باشند و از تکنیک حذف استفاده کنیم، امکان دارد بخش بزرگی از دیتاست از دست برود. نکتهای که باید هنگام بهرهگیری از این تکنیک بهخاطر داشته باشید.
نمونه های پرت به عنوان مقادیر گمشده
به عنوان یک راهحل دیگر میتوان با نمونههای پرت مانند مقادیر گمشده برخورد کرد. اما باید در نظر داشت که مقادیر گمشده نیازمند جایگذاری هستند که تکنیکهای مرتبط با جایگذاری را در بخشهای پیشین شرح دادهایم.
محدودسازی نمونه های پرت
در این رویکرد، حد بالا و پایین با مقداری از پیش تعریف شده محدود میشوند. مقداری که از توزیع متغیر قابل نتیجهگیری است. اگر متغیری بهطور نرمال توزیع شده باشد، حد بالا و پایین مقادیر را میتوان در بازه میانگین و با فاصله سه برابری از انحراف معیار تعریف کرد. در غیر اینصورت باید از معیارهایی مانند دامنه میان چارکی استفاده کنیم.
مهندسی ویژگی زمان و تاریخ
دادههای مرتبط با زمان و تاریخ نوع خاصی از متغیرهای طبقهبندی شده هستند که با پردازش مناسب، اثرگذاری دیتاست را بهطور چشمگیری افزایش میدهند. ماه، سال، ساعت و دقیقه تنها بخشی از اطلاعات قابل استخراج از تاریخ هستند. برای آشنایی با نحوه پیادهسازی تکنیک مهندسی ویژگی زمان و تاریخ از دیتاست Lending Club موجود در وبسایت Kaggle که شامل اطلاعات افراد بدهکار بانکی است استفاده میکنیم. در اولین قدم و از آنجا که تنها به ویژگیهای زمانی نیاز داریم، دو ستون issue_d و last_pymnt_d را از دیتاست جدا و در متغیری با نام dataذخیره میکنیم:
جدول دو ستونی بهدست آمده مانند زیر است:

حالا و چون دادهها به فرم رشته یا String هستند، آنها را به فرمت DateTime که مخصوص «دادههای سری زمانی» (Time Series Data) است تبدیل میکنیم:
دو ستون دیگر با عناوین issue_dt و last_pymnt_dt به جدول اضافه شده و خروجی مانند زیر خواهد بود:

سپس قسمت ماه را از تاریخ جدا کرده و در ستون مجزایی با نام issue_dt_month ذخیره میکنیم:
خروجی مانند زیر است:

در بخش بعد، سه ماهه مربوط به هر نمونه را از تاریخ جدا کرده و در ستونی با عنوان issue_dt_quarter نمایش میدهیم:
با اجرای قطعه کد فوق جدولی مانند زیر حاصل میشود:

حالا میخواهیم بدانیم تاریخ عنوان شده چندمین روز در هفته جاری است و به همین خاطر از ویژگی dayofweekبرای نمایش این اطلاعات استفاده میکنیم:
جدول زیر نتیجه فراخوانی تابع headبر روی دیتاست تغییر یافته است:

سپس و در آخرین قدم، عنوان روز در هفته جاری را نیز از تاریخ استخراج کرده و در ستونی مجزا با نام issue_dt_dayofweek_name نمایش میدهیم:
خروجی مانند زیر خواهد بود:

مثالهایی که به آنها اشاره شد تنها چند مورد از توابعی هستند که میتوانید بر دادههای سری زمانی اعمال کنید. چنین تغییراتی اغلب باعث افزایش کارآمدی دادهها و در نهایت تولید خروجی با کیفیت از مدلهای یادگیری ماشین میشود.
مزایای مهندسی ویژگی چیست؟
حالا که بهخوبی یاد گرفتیم مهندسی ویژگی چیست و چگونه پیادهسازی میشود، در این بخش شرح مختصری از مزایای مهندسی ویژگی ارائه میدهیم. برخی از این مزایا عبارتاند از:

- بهبود کارایی و اثربخشی مدل.
- ارائه الگوریتمهایی که بهراحتی جهت حرکت دادهها را یاد گرفته و به اصطلاح بر آنها برازش میشوند.
- سادهسازی کار الگوریتمها برای شناسایی الگوهای موجود در داده.
- افزایش سطح انعطافپذیری ویژگیها.

شاید در نگاه اول، پاکسازی حجم زیادی از دادههای خام، بدون ساختار و بهم ریخته دشوار بهنظر برسد. از همین جهت و پس از آنکه به پرسش مهندسی ویژگی چیست پاسخ دادیم، در ادامه این مطلب از مجله فرادرس، یاد میگیریم چه ابزارهایی کار ما را برای آمادهسازی دادهها و بهطور خاص مهندسی ویژگی راحت میسازند.
ابزار های مهندسی ویژگی چیست؟
تا اینجا بهخوبی میدانیم منظور از مهندسی ویژگی چیست و چگونه میتوانیم دیتاستهای خود را با استفاده از ابزارهایی مانند زبان برنامه نویسی پایتون پردازش کنیم. با این حال، ابزارهای بسیاری هستند که به خودکارسازی فرایند مهندسی ویژگی مشهور بوده و قابلیت تولید حجم زیادی از ویژگیها را در مسائل مختلف دارند. در ادامه این بخش، نگاه دقیقتری به چند مورد از این ابزارها میاندازیم. برای آشنایی بیشتر با ابزارهای مورد استفاده در این حوزه، میتوانید فیلم آموزش رایگان ابزارهای داده کاوی فرادرس که لینک آن در بخش زیر قرار گرفته است را مشاهده کنید:


۱. FeatureTools
از FeatureTools به عنوان فریمورکی رایج برای خودکارسازی فرایند مهندسی ویژگی یاد میشود. این ابزار عملکرد بسیار خوبی در تبدیل دادههای زمانی و رابطهای به ماتریسهای متناظر برای الگوریتمهای یادگیری ماشین از خود نشان داده است. همچنین فریمورک FeatureTools با بسیاری از ابزارهای مربوط به داده کاوی مانند کتابخانه Pandas یکپارچه بوده و سرعت ایجاد ویژگیها را افزایش میدهد.
۲. AutoFeat
ابزار AutoFeat فرایند مهندسی و انتخاب ویژگی را در مدلهای خطی تسهیل میکند. از جلمه مزایای AutoFeat میتوان به قابلیت تغییر واحد متغیرهای ورودی برای جلوگیری از ایجاد ناهماهنگی اشاره کرد.
۳. TsFresh
کتابخانه TsFresh تحت زبان برنامه نویسی پایتون در دسترس است. بهرهگیری از ابزار TsFresh محاسبه و ایجاد حجم زیادی از ویژگیهای سری زمانی را ممکن میسازد. همچنین این کتابخانه شامل توابعی است که با استفاده از آنها میتوان شدت تاثیرگذاری ویژگیها را در مسائل رگرسیون و طبقهبندی ارزیابی کرد.
۴. OneBM
ابزار OneBM در تعامل مستقیم با جداول پایگاه داده قرار دارد. ادغام جداول، تشخیص نوع دادهها و همچنین اتخاذ روشهای پردازشی معین برای انواع دادهها از جمله ویژگیهای این ابزار محسوب میشود.
۵. ExploreKit
با الهام از ایده شکلگیری ویژگیهای پیچیده از اطلاعات پایه و اولیه، ابزار ExploreKit ابتدا الگوهای رایج موجود را شناسایی و در ویژگیها تغییر ایجاد میکند. در این ابزار، بهجای گزینش از میان تمامی ویژگیها که ممکن است هزینهبر باشد، ابتدا ویژگیها ردهبندی شده و سپس تنها منتخبها بهکار گرفته میشوند.
راه سریع برای یادگیری داده کاوی و یادگیری ماشین

تمرکز بر موضوع کلیدی مهندسی ویژگی نقطه شروع خوبی برای ورود به دنیای داده کاوی و یادگیری ماشین است. همانطور که در این مطلب از مجله فرادرس خواندیم، مهندسی ویژگی شامل تکنیکهای گوناگونی برای انتخاب، استخراج و ساخت ویژگیهای مناسب از دادههای خام است. تسلط بر این مهارت، شما را قادر میسازد تا دادههایی با کیفیت بالا برای مدلهای یادگیری ماشین خود آماده کنید.
با این حال، داده کاوی تنها به مهندسی ویژگی خلاصه نشده و موضوعات گستردهتری را دربرمیگیرد. پس از آمادهسازی داده و مهندسی ویژگی، گام بعدی انتخاب و آموزش مدلهای یادگیری ماشین مناسب است. این مدلها شامل الگوریتمهای رگرسیون، طبقهبندی، خوشهبندی و دیگر روشهای پیشبینی هستند. بهدلیل اهمیت این موضوع و برای آنکه بتوانید به شکل اصولی و همزمان سریع با مبانی داده کاوی و یادگیری ماشین در پروژههای حقیقی آشنا شوید، پلتفرم فرادرس دورههای جامعی را از مبتدی تا حرفهای در قالب فیلمهای آموزشی آماده کرده است که مشاهده آنها را به ترتیبی که در ادامه آورده شده به شما پیشنهاد میکنیم:
- فیلم آموزش تجزیه و تحلیل و آماده سازی داده ها با پایتون فرادرس
- فیلم آموزش ریاضی برای یادگیری ماشین فرادرس
- فیلم آموزش پانداس pandas برای تحلیل اطلاعات در پایتون فرادرس
- فیلم آموزش یادگیری ماشین و پیاده سازی در پایتون فرادرس - بخش یکم
- فیلم آموزش یادگیری ماشین و پیاده سازی در پایتون فرادرس - بخش دوم
جمعبندی
در جهان امروز که دادهها نقش محوری در تصمیمگیریها و فرایندهای تجاری ایفا میکنند، مهندسی ویژگی مرحلهای حیاتی و تعیینکننده در موفقیت سیستمهای هوشمند بهشمار میرود. در این مطلب از مجله فرادرس سعی کردیم تا به پرسش مهندسی ویژگی چیست پاسخ دهیم و توضیح جامعی از نحوه پیادهسازی تکنیکهای مختلف آن بر روی دیتاستهای کاربردی ارائه دهیم. فرایندی که بسیار در بهبود دقت و کارآمدی مدلهای یادگیری ماشین موثر خواهد بود.







