شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
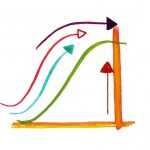
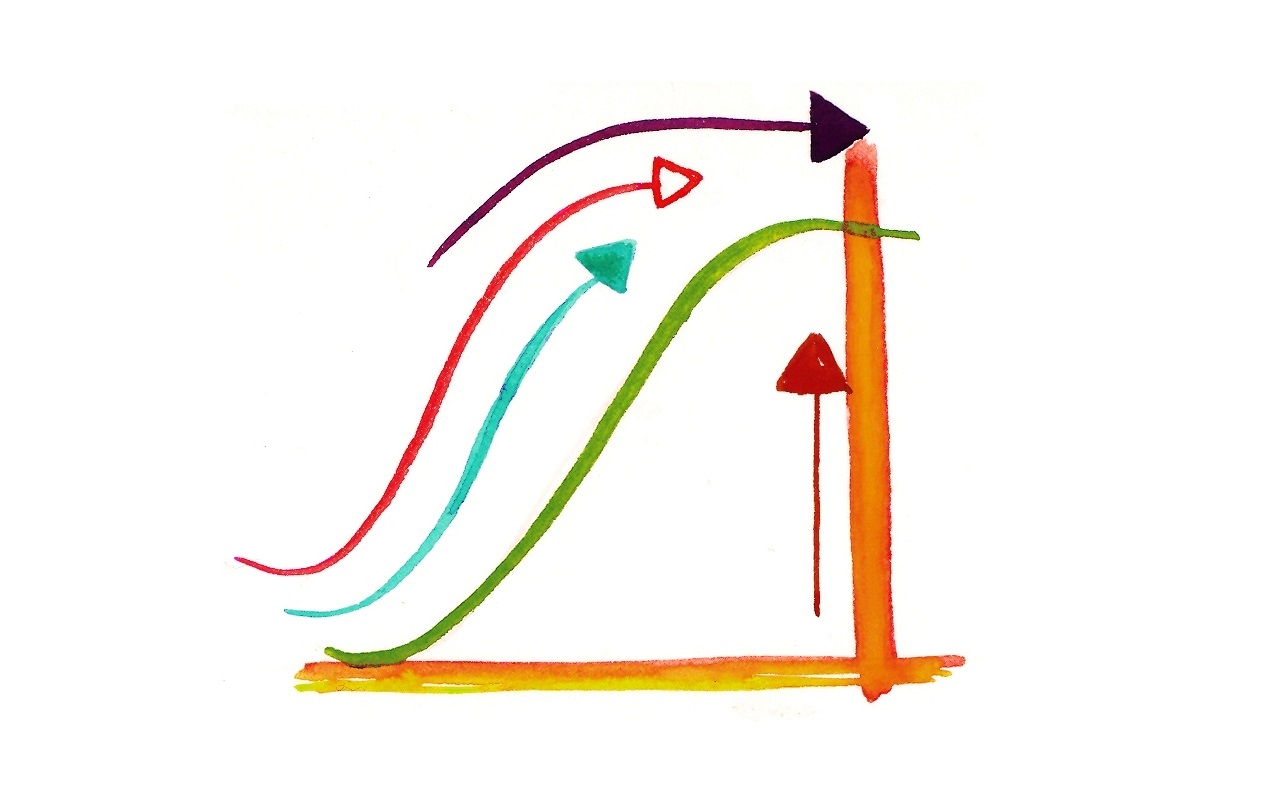
همیشه کسب مهارت و تخصص در یک زمینه جدید مقداری زمان خواهد برد. منحنی یادگیری نموداری است که در آن، رابطه تعداد تلاشهای یک فرد برای یادگیری یک کار خاص را با سطح عملکرد او در انجام آن کار نشان میدهد. در این آموزش، مدل فرایند یادگیری را با استفاده از یک معادله دیفرانسیل به دست میآوریم.
ابتدا، تابع یادگیری قابل اندازهگیری L(t) را معرفی میکنیم. این تابع، برای مثال، ممکن است بهرهوری نیروی کار فعلی را توصیف کند. فرض کنید Lmax حداکثر مقدار قابل دسترس L(t) باشد. در بسیاری از موارد، استفاده از یک قاعده سرانگشتی برای محاسبات کارساز خواهد بود: سرعت یادگیری متناسب با حجم موارد باقیمانده (یاد گرفته نشده) است.
پس از حذف لگاریتمها، جواب عمومی به فرم زیر به دست میآید:
Lmax–L=Ce–kt.
ثابت C را میتوان از شرایط اولیه L(t=0)=M به دست آورد؛ یعنی C=Lmax–M. در نتیجه، منحنی یادگیری با فرمول زیر توصیف میشود:
L(t)=Lmax−(Lmax–M)e–kt.
پارامتر M در عبارت بالا، سطح اولیه دانش یا مهارت را نشان میدهد. در سادهترین حالت، میتوان فرض کرد M=0. پارامتر دیگر k سرعت بالا رفتن نمودار است. منحنیهای یادگیری به ازای مقادیر مختلف M و k، به ترتیب، در شکلهای ۱ و ۲ نشان داده شدهاند.
شکل ۱شکل ۲
همانطور که میبینیم، سطح یادگیری L در همه موارد در ابتدای فرایند افزایش مییابد، و پس از آن نرخ یادگیری با رسیدن سطح یادگیری L به حداکثر مقدار Lmax کاهش مییابد.
مثالهای منحنی یادگیری
در این بخش دو مثال را از منحنی یادگیری بیان میکنیم.
به طور معمول، یک نسخهخوان در داروخانه باید ۱۰۰۰ نسخه را در روز بررسی کند. فرض کنید یک نسخهخوان جدید در داروخانهای استخدام شده و در هفته اول قادر است ۱۰۰ نسخه را در روز بررسی کند. تعداد نسخههایی را به دست آورید که او میتواند در هفته دوم بررسی کند.
حل: با قرار دادن سطح مهارت اولیه برابر با صفر (M=0)، میتوانیم فرایند یادگیری را به صورت زیر توصیف کنیم:
فرض کنید یک خبر از یک رسانه جمعی بر اساس منحنی یادگیری پخش میشود. درصد اولیه جمعیتی که باید از این اخبار مطلع شوند باید چقدر باشد تا این خبر در هفته اول به ۵۰ درصد جمعیت و در هفته دوم به ۹۰ درصد آنها برسد؟
حل: اخبار با قانون زیر پخش میشود:
L(t)=Lmax–Me–kt.
دو نقطه از این منحنی معلوم هستند: در هفته t=1 و در هفته t=4. بنابراین، میتوانیم دو معادله زیر را بنویسیم:
سید سراج حمیدی دانشآموخته مهندسی برق است و به ریاضیات و زبان و ادبیات فارسی علاقه دارد. او آموزشهای مهندسی برق، ریاضیات و ادبیات مجله فرادرس را مینویسد.
شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.