شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
در آموزشهای قبلی مجله فرادرس با فیلتر کالمن آشنا شدیم. فیلتر کالمن معادل مشاهدهگر برای رگولاتورهای مرتبه دوم خطی است و به همین دلیل تخمینگر مرتبه دوم خطی نیز نامیده میشود. در این آموزش، ضمن بیان مختصر مفاهیم، با پیادهسازی فیلتر کالمن در متلب آشنا خواهیم شد.
از آنجایی که تخمین با استفاده از فیلتر کالمن با اندازهگیری و انتشار حالت گره خورده است، درک پیادهسازی گسسته آن سادهتر است. سیستم زیر را در نظر بگیرید:
که در آن، wk نامعینی دینامیک سیستم است که به عنوان یک فرایند گاوسی با کوواریانسE(wkwkT)=Q نمایش داده شده است. متغیرهای حالت Xk نیز با فرایندهای دو به دو گوسی مستقل با کوواریانس Pk مدل میشوند. شرایط اولیه نیز حالت X(0)=X0 و کوواریانس P0 هستند.
اندازهگیری به صورت زیر تقریب زده شده است:
Yk=CXk+Duk+vk
که در آن، vk نامعینی در اندازهگیری با کواریانس E(vkvkT)=R است.
۱. انتشار حالت
دینامیک سیستم به صورت زیر بیان میشود:
Xk+1=AXk+Buk+Fwk
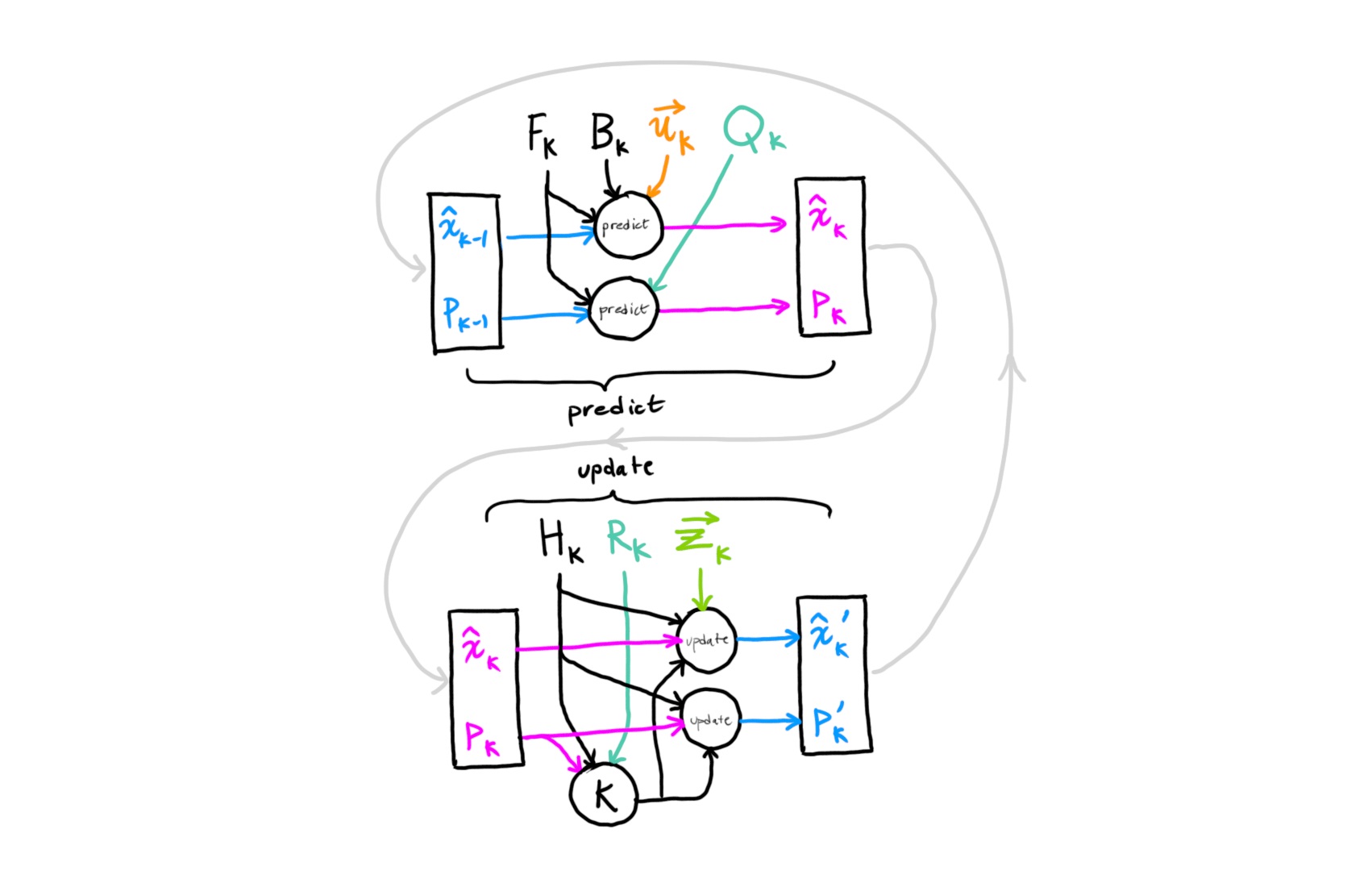
برای جداسازی تخمینهای حالت قبل و بعد از اندازهگیری، موارد زیر را تعریف میکنیم:
Xk∣k به عنوان تخمین بعد از اندازهگیری در گام k
Xk+1∣k به عنوان تخمین حالت بعد از دنبال کردن دینامیک سیستم
بنابراین، مقدار بعدی قابل انتظار حالت به صورت زیر خواهد بود:
E(Xk+1∣k)=AE(Xk∣k)+BE(uk)+E(Fwk)
X^k+1∣k=AX^k∣k+Buk
خطای بین تخمین حالت و امید ریاضی، قبل از اندازهگیری به صورت زیر نمایش داده میشود:
Xk+1∣k−X^k+1∣k=AXk∣k+Buk+Fwk−(AXˉk∣k+Buk)
ek+1∣k=Xk+1∣k−Xˉk+1∣k=Aek∣k+Fwk
بنابراین، کوواریانس حالت قبل از اندازهگیری برابر خواهد بود با:
یعنی تخمین حالت بر اساس خطای بین اندازهگیری واقعی و اندازهگیری چشمداشتی تخمین حالت بهروز میشود. هدف، یافتن Kk+1 به گونهای است که اختلاف بین حالت واقعی و تخمین آن کمینه شود.
میخواهیم بهرهای را به گونهای انتخاب کنیم که خطای بین تخمین حالت پسین (عقبی) و حالت واقعی را کمینه کند.
از آنجایی که اثر ماتریس کوواریانس خطای بین تخمین حالت و به روز رسانی اندازهگیری است، بنابراین، ماتریس بهرهای که ماتریس کوواریانس را کمینه میکند، جواب بهینه است. با مشتقگیری نسبت به بهره، داریم:
ابتدا فیلتر کالمن را برای تخمین حالتها در سادهترین مورد که یک فرایند و اندازهگیری قطعی داریم، اعمال میکنیم. سیستم زیر را در نظر بگیرید:
X¨=u
که اندازهگیری y=X است. میخواهیم یک مشاهدهگر را به گونهای تشکیل دهیم که X^→X.
سیستم را به صورت زیر تقریب میزنیم:
X1(t+1)X2(t+1)=X1(t)+δtX2=δtu
اندازهگیری به صورت زیر تقریب زده میشود:
y=X+v
که در آن، v یک فرایند گاوسی با میانگین صفر و واریانس10−8 است. توجه کنید از آنجایی که سیستم قطعی است، از یک مقدار بسیار کوچک کوواریانس اندازهگیری R استفاده میکنیم. برنامه زیر، پیادهسازی فیلتر کالمن در متلب را برای تخمین حالت نشان میدهد. از آنجایی که کواریانس حالتها را از قبل نمیدانیم، در ابتدا فرض میکنیم یک ماتریس واحد باشد. حالتها در یک تکرار تخمین زده میشوند و خطا سریعاً به صفر میل میکند.
مثال ۲
از فیلتر کالمن میتوان برای تخمین پارامتر نیز استفاده کرد. سیستم دینامیکی زیر را در نظر بگیرید:
X1˙X2˙=X2+α=u
که در آن، α پارامتری نامعلوم است. تنها اندازهگیری y=X1+v را داریم که در آن، v یک فرایند گاوسی با واریانس R=0.1 است. میتوانیم از فیلتر کالمن استفاده کرده و پارامتر نامعلوم را تخمین بزنیم. ابتدا یک حالت جدید به سیستم اضافه میکنیم که خودش یک پارامتر است. همچنین دینامیکی را معرفی میکنیم که مشتق آن برابر با صفر است. از آنجایی که پارامتر را به صورت دقیق نمیدانیم، یک جمله نویز به دینامیک سیستم اضافه میکنیم تا نامعینی در مدل لحاظ شود.
در معادلات بالا، w(t) یک فرایند گاوسی با کوواریانس 10−4 است. معادلات بالا را میتوان به فرم زیر نوشت:
Xt+1=AXt+But+Fwt
که در آن:
A=100δt00δt00,B=0δt0,F=001
در ابتدا، کوواریانس حالت را نمیدانیم، بنابراین تقریب آن را ۱ در نظر میگیریم. البته، اندازهگیری دقیق کوواریانس برای تخمین حالت لازم است. بنابراین، شبیهسازی را یک بار برای تخمین کوواریانس اجرا میکنیم و دوباره آن را اجرا کرده و این فرایند را تکرار میکنیم. با تکرار چندباره این فرایند (معمولاً دو بار)، یک تخمین مناسب از پارامتر نامعلوم خواهیم داشت.
مثال ۳
همانطور که گفتیم، از فیلتر کالمن میتوان برای تخمین پارامتر استفاده کرد. باز هم سیستم زیر را در نظر بگیرید:
X1˙X2˙=X2+α=u
که در آن، α پارامتری نامعلوم است. اندازهگیریهای y1=X1+v1 و y2=X2+v2 نیز در دسترس هستند، که در آنها v1 و v2 فرایندهای گوسی با واریانسهای R1=0.1 و R2=0.1 هستند. میتوانیم از فیلتر کالمن استفاده کنیم و پارامتر نامعلوم را تخمین بزنیم:
که در آن، w(t) یک فرایند گوسی با کوواریانس 10−4 است. مانند مثال قبل، شبیهسازی را یک بار برای تخمین کوواریانس اجرا کرده و سپس فرایند را دوباره تکرار میکنیم. با تکرار چندباره این فرایند (معمولاً دو بار)، به یک تخمین مناسب برای پارامتر نامعلوم میرسیم.
فیلتر کالمن پیوسته
فیلتر کالمن-بوسی (Kalman-Bucy Filter) معادل پیوستهزمان فیلتر کالمن است. استخراج و تحلیل فیلتر کالمن برای سیستمهای پیوستهزمان دشوار است، زیرا اندازهگیری و حالتها متغیرهایی پیوستهاند و بهروزرسانی پیشین و پسین به صورت شفاف تعریف نشدهاند. با این حال، با گسستهسازی فیلتر پیوسته و میل دادن زمان گسستهسازی به صفر، معادلات فیلتر کالمن به دست میآیند. در ادامه، این روش را توضیح میدهیم.
فرض کنید دینامیک سیستم به صورت زیر است:
X˙=AX+Bu+Fw
که در آن، w یک فرایند گاوسی با میانگین صفر و کوواریانس Q است و اندازهگیری به صورت زیر بیان میشود:
y=CX+Du+v
فیلتر تخمین زننده حالت از دو معادله دیفرانسیل تشکیل شده است:
لازم به ذکر است که در مورد پیوسته فیلتر کالمن، کوواریانس خطای اندازهگیری و کوواریانس پیشین، هر دو، R هستند. علاوه بر این، در محاسبات بهره مشاهدهگر معکوس ماتریس کوواریانس نویز R به کار میرود. بنابراین، اگر دو سنسور داشته باشیم که یکی بسیار نویزدار و دیگری بسیار دقیق باشد، فیلتر کالمن مقدار بیشتری را روی سنسور دقیق قرار میدهد؛ یعنی سنسوری که نویز پایینتری دارد، سهم بیشتری در بهروزرسانی خواهد داشت. دقت کنید که معادله فوق، مشابه معادله ریکاتی است که در رگولاتور مرتبه دوم خطی به دست میآید و میتوانیم آن را با تکنیکی مشابه حل آن حل کنیم. در مورد خاص زمان بینهایت، معادله ریکاتی به صورت زیر در خواهد آمد:
0=AP+PAT+FQFT−PCTRCP
معادله بالا مشابه معادله ریکاتی جبری است که در آن، به جای A و B، ماتریسهای AT و CT قرار دارند و میتوان آن را با دستور "care" در متلب حل کرد.
فیلتر کالمن در متلب (پیوسته)
در این بخش، چند مثال از پیادهسازی فیلتر کالمن در متلب (پیوسته) را ارائه خواهیم کرد.
مثال ۴
سیستمی با معادله x¨=u را در نظر بگیرید که تنها موقعیت آن اندازهگیری میشود. میخواهیم با فرض اینکه کوواریانس نویز اندازهگیری واحد بوده و برابر با کوواریانس فرایند است، یک فیلتر کالمن پیوسته برای سیستم ارائه کنیم. برای این منظور، از دستور متلب برای حل معادله ریکاتی استفاده شده است.
مثال ۵
سیستم مثال قبل، یعنی x¨=u را در نظر بگیرید که اکنون دو سنسور برای اندازهگیری موقعیت دارد: یکی بسیار دقیق (با کوواریانس ۰٫۰۱) و دیگری غیردقیق (با کوواریانس ۱). با فرض اینکه کواریانس فرایند یک ماتریس یکه است، یک فیلتر کالمن برای سیستم ارائه میکنیم. با استفاده از دستور "care" در متلب میتوان برای حل معادله ریکاتی استفاده کرد. بهرههایی که از معادله ریکاتی حالت ماندگار به دست میآید به صورت زیر است:
Kk=[0.10900.099510.89569.9504]
ماتریس بهره فیلتر کالمن اهمیت بیشتری به دادههای سنسور دقیقتر میدهد.
کنترل گاوسی درجه دو خطی
کنترل گاوسی درجه دوم خطی یک رویکرد کنترلی است که از رگولاتور درجه دوم خطی (LQR) برای کنترل و برای فیلتر کالمن به منظور تخمین استفاده میکند. با توجه به اصل تفکیک تخمین و کنترل، میتوانیم مشاهدهگر و کنترلکننده را بدون اثرگذاری روی هم به صورت جداگانه طراحی کنیم. برنامه زیر، یک رگولاتور خطی مرتبه دوم برای کنترل و فیلتر کالمن پیوسته را با استفاده از دستور "care" متلب ارائه میدهد.
جمعبندی
فیلترهای کالمن کاربردهای فراوانی در کنترل و پردازش سیگنال دارند. این فیلترها رؤیتگرهای مشابه رگولاتورهای مرتبه دوم خطی هستند و میتوان با استفاده از همان عبارات و با جایگزینی ماتریس سیستم با ترانهادهاش، و جایگزینی ماتریس ورودی با ترانهاده ماتریس اندازهگیری آنها را به دست آورد. فیلترهای کالمن وقتی در فرایندها و اندازهگیریهایی به کار میروند که مبتنی بر توزیع گاوسیاند، بهینه هستند. فیلترهای کالمن را میتوان برای سیستمهای غیرخطی نیز بیان کرد.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
سید سراج حمیدی دانشآموخته مهندسی برق است و به ریاضیات و زبان و ادبیات فارسی علاقه دارد. او آموزشهای مهندسی برق، ریاضیات و ادبیات مجله فرادرس را مینویسد.
۴ دیدگاه برای «فیلتر کالمن در متلب – راهنمای کاربردی»
سید علی عرفانی
سلام. از توضیحتان ممنونم. آیا ممکن است دربارۀ پیاده سازی فیلتر کالمن در ورژن های جدید برنامۀ متلب (که دارای دستور آمادۀ کالمن هستند.)، توضیح بفرمایید. آیا می توان داده های حسگر را به عنوان بردار کنترلی وارد مسأله کرد؟
بسیار ممنون، عرفانی
مهدیه یوسفی
با سلام؛
از دستور kalman میتوان برای طراحی فیلتر استفاده کرد: [kalmanf,L,Mx,Z]=kalman(sys,Q,R);
با تشکر از همراهی شما با مجله فرادرس
شریعت
سلام برای شبیه سازی الگوریتم فیلتر کالمن با استفاده از نرم افزار متلب راهنمایی میخوام
حیدری
سلام توضیحات وبرنامه عالی،
یسوال من پروژه ایی دارم با فیلترکالمن برای تخمین سطح توسط مقادیر توان و فلو خروجی که همان سطح هست به چه صورت ازین برنامه هاتون استفاده کنم (بصورت گسسته)؟همه داده هارو دارم R.Q. ماتریسهایa,b,c,d
شما در حال مطالعه نسخه آفلاین یکی از مطالب «مجله فرادرس» هستید. لطفاً توجه داشته باشید، ممکن است برخی از قابلیتهای تعاملی مطالب، مانند امکان پاسخ به پرسشهای چهار گزینهای و مشاهده جواب صحیح آنها، نمایش نتیجه آزمونها، پاسخ تشریحی سوالات، پخش فایلهای صوتی و تصویری و غیره، در این نسخه در دسترس نباشند. برای دسترسی به نسخه آنلاین مطلب، استفاده از کلیه امکانات آن و داشتن تجربه کاربری بهتر اینجا کلیک کنید.
























سلام. از توضیحتان ممنونم. آیا ممکن است دربارۀ پیاده سازی فیلتر کالمن در ورژن های جدید برنامۀ متلب (که دارای دستور آمادۀ کالمن هستند.)، توضیح بفرمایید. آیا می توان داده های حسگر را به عنوان بردار کنترلی وارد مسأله کرد؟
بسیار ممنون، عرفانی
با سلام؛
از دستور kalman میتوان برای طراحی فیلتر استفاده کرد:
[kalmanf,L,Mx,Z]=kalman(sys,Q,R);
با تشکر از همراهی شما با مجله فرادرس
سلام برای شبیه سازی الگوریتم فیلتر کالمن با استفاده از نرم افزار متلب راهنمایی میخوام
سلام توضیحات وبرنامه عالی،
یسوال من پروژه ایی دارم با فیلترکالمن برای تخمین سطح توسط مقادیر توان و فلو خروجی که همان سطح هست به چه صورت ازین برنامه هاتون استفاده کنم (بصورت گسسته)؟همه داده هارو دارم R.Q. ماتریسهایa,b,c,d