



ترنسفورمر در یادگیری عمیق چیست؟ – Transformer به زبان ساده
همزمان با رشد و تکامل مدلهای «ترنسفورمر» (Transformer)، حوزه یادگیری عمیق شاهد پیشرفت چشمگیری بوده است. این معماری نوآورانه نه تنها باعث تحول اصول «پردازش زبان طبیعی» (NLP) شده بلکه کاربرد هوش مصنوعی را به مسائل گوناگونی گسترش میدهد. در حقیقت مدلهای ترنسفورمر نوع خاصی از شبکههای عصبی بهشمار میروند که توسط شرکتهای بزرگی همچون OpenAI مورد استفاده قرار گرفتهاند و همین موضوع باعث شده تا محبوبیت زیادی بهدست آورند. در این مطلب از مجله فرادرس با مفهوم و ساختار ترنسفورمر در یادگیری عمیق آشنا میشویم و به معرفی برخی از رایجترین مدلهای ترنسفورمر میپردازیم. ساختاری که الهام بخش بسیاری از دانشمندان علم داده و علاقهمندان به این حوزه بوده است.
- ترنسفورمر و کاربرد آن در یادگیری عمیق را میآموزید.
- با تاریخچه شکلگیری مدل ترنسفورمر آشنا میشوید.
- تفاوت ترنسفورمر با مدلهای RNN مانند LSTM را تشخیص میدهید.
- میتوانید ساختار رمزگذار و رمزگشا در ترنسفورمر را تحلیل کنید.
- با مدلهای کاربردی ترنسفورمر مانند BERT و GPT آشنا میشوید.
- مقایسه ترنسفورمر با لایههای بازگشتی و پیچشی را میآموزید.




در این مطلب ابتدا یاد میگیریم ترنسفورمر چیست و به معرفی ساختار مدلهای ترنسفورمر در یادگیری عمیق میپردازیم. سپس با چند نمونه کاربردی و همچنین نحوه ارزیابی این مدلها آشنا میشویم و در انتها مقایسهای میان ترنسفورمر با دو ساختار رایج دیگر انجام میدهیم.
ترنسفورمر چیست؟
منشاء طراحی و توسعه ترنسفورمرها را میتوان در تلاش برای حل مسئله «تبدیل توالی» (Sequence Transduction) یا «ترجمه ماشینی» (Machine Translation) جستجو کرد. به بیان سادهتر، کاربرد ترنسفورمر در یادگیری عمیق به تبدیل یک توالی یا دنباله ورودی به یک دنباله خروجی خلاصه میشود و همین تبدیل است که موجب شده تا چنین ساختارهایی را «ترنسفورمر» بنامیم. در ادامه این بخش بیشتر با مدلهای معروف به ترنسفومر و تاریخچه شکلگیری آنها آشنا میشویم. برای یادگیری بیشتر درباره یادگیری عمیق، میتوانید فیلم آموزش مبانی یادگیری عمیق فرادرس را که لینک آن در ادامه آورده شده است مشاهده کنید:

مدل ترنسفورمر در یادگیری عمیق چیست؟
مدل ترنسفورمر یک شبکه عصبی است که از محتوای دادههای ترتیبی یاد گرفته و مطابق با آن، دادههای جدیدی تولید میکند. در واقع، ترنسفورمر نوعی مدل هوش مصنوعی است که با تحلیل الگوهای موجود در دادههای متنی، چگونگی نگارش متون به زبان انسان را یاد گرفته و نمونههای جدیدی تولید کند. از ترنسفورمرها به عنوان پیشرفتهترین مدلهای NLP که از ساختار «رمزگذار-رمزگشا» (Encoder-decoder) پیروی میکنند یاد میشود. اما برخلاف ساختارهای مشابه که از «شبکههای عصبی بازگشتی» (RNN) برای استخراج اطلاعات ترتیبی استفاده میکنند، ترنسفورمرها فاقد قابلیت بازگشتی هستند. این ساختارها بهگونهای طراحی شدهاند که بتوانند ورودی را با تحلیل ارتباط میان بخشهای مختلف آن درک کنند. مدلهای ترنسفورمر برای انجام این کار تنها بر نوعی تکنیک ریاضیاتی به نام مکانیزم «توجه» یا Attention متکی هستند.

تاریخچه شکلگیری
ایده مدلهای ترنسفورمر اولین بار در سال ۲۰۱۷ و در مقالهای با عنوان Attention is All You Need از شرکت گوگل مطرح شد و از آن زمان به عنوان یکی از تاثیرگذارترین نوآوریهای حوزه یادگیری ماشین شناخته میشود. این مفهوم پیشگامانه نه تنها یک پیشرفت نظری بوده بلکه بهطور عملی و در بسته نرمافزاری Tensor2Tensor کتابخانه TensorFlow نیز پیادهسازی شده است. در ادامه گروه تحقیقاتی NLP دانشگاه هاروارد، راهنمایی برای پیادهسازی مقاله با استفاده از کتابخانه PyTorch در زبان برنامهنویسی پایتون ارائه داد.
مدل معرفی شده را میتوان سرآغاز توسعه مدلهای زبانی بزرگ مانند BERT نامید. در سال ۲۰۱۸ این تحول و توسعه به نقطه عطفی در حوزه NLP تبدیل شده بود و سال ۲۰۲۰، محققان شرکت OpenAI مدل زبانی GPT-3 را معرفی کردند. کاربران همان هفتههای اول، مدل GPT-3 را در زمینههای متنوعی مانند هنر، برنامهنویسی و موسیقی به چالش کشیدند. در سال ۲۰۲۱، پژوهشگران دانشگاه استنفورد در مقالهای این نوآوریها را «مدلهای پایه» (Foundation Models) نامگذاری کردند که بیانگر نقش اساسی آنها در بازتعریف مفهوم هوش مصنوعی است. تمرکز این پژوهش بر تشریح نقش مدلهای ترنسفورمر در گسترش مرزهای هوش مصنوعی است که فرصتهای تازهای را در این حوزه به ارمغان آوردهاند.
از مدل های RNN مانند LSTM به ترنسفورمر ها
پیش از معرفی مدل ترنسفورمر در یادگیری عمیق، از مدلهای بازگشتی یا RNN برای مدیریت دادههای ترتیبی استفاده میشد. در حالی که مدل RNN شباهت زیادی با شبکه عصبی «پیشخور» (Feedforward) داشته اما، ورودی را بهصورت ترتیبی پردازش میکند. ترنسفورمر در یادگیری عمیق از ساختار رمزگذار-رمزگشا مدلهای بازگشتی الهام گرفته است. با این تفاوت که بهجای بهرهگیری از یه چرخه بازگشتی، هر مدل ترنسفورمر بر اساس مکانیزم Attention فعالیت میکند.

ترنسفورمرها نه تنها عملکرد RNN را بهبود بخشیده بلکه چارچوب جدیدی را برای حل مسائل مختلف مانند خلاصهسازی متون، «توصیف تصاویر» (Image Captioning) و بازشناسی گفتار ارائه دادند. بهطور کلی میتوان ناکارآمدی RNN را در پردازش زبان طبیعی یا NLP به دو مورد زیر خلاصه کرد:
- پردازش دادههای ورودی بهصورت متوالی و یکی پس از دیگری انجام میشود. این نوع از فرایند بازگشتی استفادهای از «واحدهای پردازش گرافیکی» (GPUs) مدرن که بهمنظور انجام محاسبات موازی طراحی شدهاند نداشته و در نتیجه فرایند آموزش مدل با سرعت پایینی انجام میشود.
- هنگامی که بخشهای مختلف ورودی از یکدیگر جدا باشند، کارایی این مدلها کاهش مییابد. زیرا دادههای ورودی از هر لایه شبکه عبور کرده و هرچه این زنجیره طولانیتر باشد، احتمال فراموش شدن و تغییر اطلاعات نیز افزایش مییابد.
با عبور از شبکههای بازگشتی مانند LSTM و استفاده از مدلهای ترنسفورمر در یادگیری عمیق و بهویژه NLP، دیگر با چنین مشکلاتی مواجه نبوده و مزایایی همچون موارد زیر از مکانیزم Attention حاصل میشود:
- توجه و تمرکز بر کلمات، فارغ از فاصله آنها به یکدیگر.
- بهبود سرعت عملکرد.
از همین جهت ترنسفورمر به نوعی نسخه پیشرفتهتر RNN محسوب میشود. حالا که بهخوبی میدانیم ترنسفورمر چیست، در ادامه به بررسی اجمالی ساختار ترنسفورمر در یادگیری عمیق میپردازیم.
آموزش یادگیری عمیق با فرادرس

ترنسفورمر یکی از مهمترین پیشرفتها در حوزه یادگیری عمیق در سالهای اخیر بوده است. این معماری نوآورانه، انقلابی در پردازش زبان طبیعی ایجاد کرد و بهسرعت به سایر حوزههای هوش مصنوعی نیز گسترش یافت. ترنسفورمرها با بهرهگیری از مکانیسم توجه، قادر به پردازش موازی دادهها هستند. امری که منجر به افزایش قابل توجه سرعت و کارایی در مقایسه با معماریهای قبلی مانند شبکههای عصبی بازگشتی شده است. این قابلیت به ترنسفورمرها اجازه میدهد تا ارتباطات پیچیده و ترتیبی را در دادهها بهتر درک کنند.
با توجه به اهمیت و گستردگی کاربرد ترنسفورمرها، یادگیری این معماری برای متخصصان هوش مصنوعی ضروری است. اگر مایل به یادگیری عملی و کاربردی ترنسفورمرها و یادگیری عمیق هستند، مجموعه فیلمهای آموزش یادگیری عمیق فرادرس از سطح مقدماتی تا پیشرفته پاسخگو نیاز شما خواهد بود. برای مشاهده این مجموعه آموزشی روی لینک زیر کلیک کنید:
ساختار ترنسفورمر در یادگیری عمیق
همانطور که در ابتدا مطلب نیز به آن اشاره شد، اولین کاربرد ترنسفورمر در ترجمه ماشینی و تبدیل توالی ورودی به توالی خروجی بوده است. اولین مدلی که برای درک ورودی و محاسبه خروجی نیازی به بهرهگیری از شبکه RNN یا محاسبات «کانولوشن» نداشته و بر اساس روشی بهنام «خودنگرش» (Self-Attention) عمل میکند. حفظ ساختار رمزگذار-رمزگشا را میتوان ویژگی اصلی ترنسفورمرها عنوان کرد. اگر در مسئله ترجمه زبانی، ترنسفورمر را مانند یک جعبه سیاه در نظر بگیرید، ورودی در قالب جملهای به یک زبان دریافت و خروجی به زبان دیگر ارائه میشود.


اگر کمی عمیقتر شویم، خواهیم دید که این جعبه سیاه از دو قسمت اصلی تشکیل شده است:
- بخش رمزگذار ورودی را دریافت کرده و به شکل ماتریس، خروجی میدهد. برای مثال جمله انگلیسی ?How are you نقش ورودی را دارد.
- خروجی بخش رمزگذار وارد رمزگشا شده و خروجی جدیدی تولید میشود. در مثال ما، خروجی عبارت «چطور هستید؟» است.

با این حال، رمزگذار و رمزگشا در حقیقت پشتهای از چندین لایه با تعداد یکسان هستند. در تمام این لایهها، بخش رمزگذار ساختار یکسانی داشته و داده ورودی از همه آنها عبور میکند. همچنین ساختار قسمتهای مختلف رمزگشا یکسان بوده و داده ورودی از آخرین رمزگذار و لایه قبلی تامین میشود. ساختار اصلی متشکل از ۶ رمزگذار و ۶ رمزگشا است که بنا به نیاز میتوانیم تعداد لایهها را نیز تغییر دهیم.

پس از آنکه دید اولیهای از ساختار ترنسفورمر در یادگیری عمیق بهدست آوردیم، در ادامه بیشتر با نحوه کارکرد دو بخش رمزگذار و رمزگشا آشنا میشویم.
ساختار رمزگذار
رمزگذار بخشی مهم و اساسی در معماری ترنسفور است. هدف از این ساختار در تبدیل توکنهای ورودی به موجودیتهای دارای مفهوم خلاصه میشود. برخلاف مدلهای قدیمیتر که هر توکن بهصورت مجزا پردازش میشد، ساختار رمزگذار در ترنسفورمر، محتوای هر توکن را با حفظ انسجام دنباله ورودی استخراج میکند.
در تصویر زیر شاهد چیدمان کلی بخش رمزگذار هستید:

در ادامه هر کدام از مراحل ساختار رمزگذار را به تفکیک شرح میدهیم.
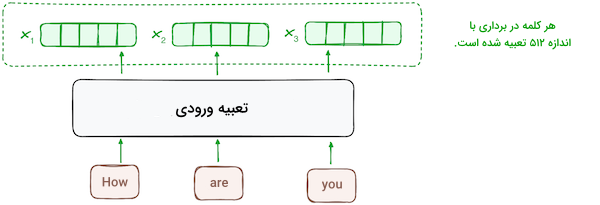
مرحله ۱ - تعبیه ورودی
فرایند «تعبیه» (Embedding) یا ساخت بردار، تنها در پایینترین یا اولین لایه رمزگذار اتفاق میافتد. رمزگذار با استفاده از لایههای تعبیه شده، توکنهای ورودی یا همان کلمات را به بردارهای متناظر تبدیل میکند. این لایهها، محتوای ورودی را استخراج و از هر کدام یک بردار عددی تشکیل میدهند. سپس همه رمزگذارها لیستی شامل بردارها با اندازه ۵۱۲ دریافت میکنند. ورودی اولین لایه رمزگذار، همان کلمات تعبیه شده به شکل بردار هستند اما ورودی سایر رمزگذارها، خروجی رمزگذاری است که در سطحی پایینتر از آنها قرار دارد.
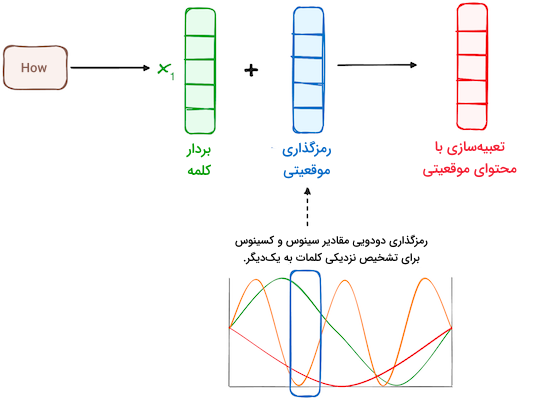
مرحله ۲ - رمزگذاری موقعیتی
ترنسفورمرها فاقد مکانیزم بازگشتی همچون RNN هستند و در عوض از «رمزگذاری موقعیتی» (Positional Encoding) برای جمعآوری اطلاعات درباره موقعیت هر توکن در دنباله استفاده میکنند. به این شکل موقعیت هر کلمه در جمله بهدست میآید. از همین جهت، پژوهشگران توسعه ترکیبی از توابع سینوسی و کسینوسی را برای ساخت بردارهای موقعیتی پیشنهاد میدهند. با انجام این کار میتوان رمزگذاری موقعیتی را برای جملات با طول مختلف بهکار گرفت.
در این رویکرد، هر بُعد از طریق دو معیار فراوانی و انحراف موج با مقادیری در بازه ۱- تا ۱، موقعیتهای مختلف را به نمایش میگذارد.
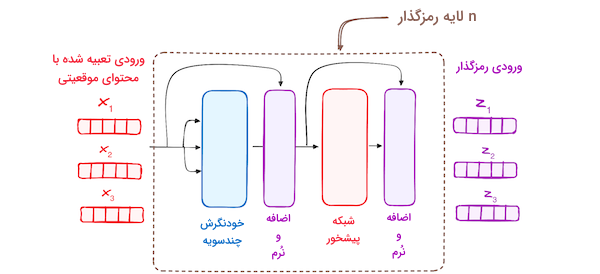
مرحله ۳ - پشته لایه های رمزگذار
رمزگذار در مدل ترنسفورمر شامل پشتهای از لایههای یکسان است. تعداد این لایهها در مدل ترنسفورمر اصلی به ۶ عدد میرسد. لایه رمزگذار تمام دنبالههای ورودی را به توصیف پیوسته و چکیدهای تبدیل میکند که دربرگیرنده اطلاعات آموخته شده از کل دنباله است. این لایه از دو بخش زیر تشکیل میشود:
- مکانزیم توجه «چندسویه» (Multi-headed).
- شبکه «تمام متصل» (Fully Connected).
همچنین این لایه نیز به زیرلایههای دیگری متصل است که پس از هر کدام یک لایه نرمالسازی قرار گرفته است.
مرحله ۱.۳ - مکانیزم توجه چندسویه
مکانیزم توجه «چندسویه» (Multi-Headed) در رمزگذار از حالت ویژهای از مکانیزم توجه به نام «خودنگرش» (Self-Attention) بهره میبرد. این روش مدل را قادر میسازد تا هر کلمه ورودی را با سایر کلمات مرتبط سازد. به عنوان مثال در عبارت ?How are you، مدل ارتباط میان دو کلمه are و you را یاد میگیرد. با پردازش هر توکن ورودی، این سازوکار به رمزگذار اجازه میدهد تا بر بخشهای مختلفی از دنباله ورودی متمرکز شود. امتیاز توجه، مطابق با معیارهای زیر محاسبه میشود:
- هر کوئری در حقیقت برداری بیانگر یک کلمه خاص یا توکنی از دنباله ورودی در مکانیزم توجه است.
- هر کلید نیز برداری متناظر با یک کلمه یا توکن ورودی در مکانیز توجه است.
- هر مقدار با کلیدی در ارتباط است و در شکلگیری خروجی لایه توجه نقش دارد. وقتی کوئری با کلید همخوان باشد، یعنی امتیاز توجه بالا بوده و مقدار متناظر در خروجی آشکار میشود.
مدل با بهرهگیری از اولین واحد خودنگرش، میتواند اطلاعات متنی را از دنباله ورودی استخراج کند. بهجای اجرا یک تابع توجه، کوئریها، کلیدها و مقادیر به شکل خطی و h مرتبه تخمین زده میشوند. برای هر نسخه از این سه مقدار، مکانیزم توجه بهطور موازی اجرا شده و خروجی h بعُدی بهدست میآید. جزییات این ساختار را در تصویر زیر مشاهده میکنید:
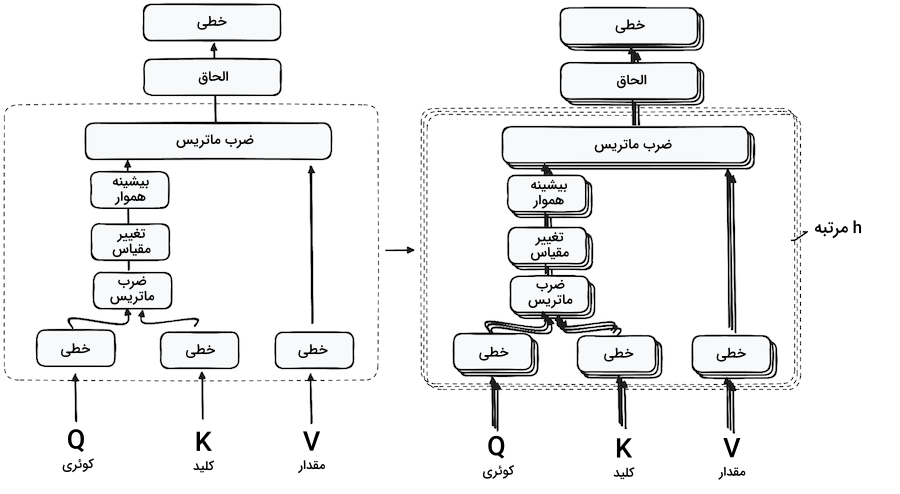
ضرب ماتریس - ضرب داخلی کوئری و کلید
همزمان با گذر بردارهای کوئری، کلید و مقدار از یک لایه خطی، ضرب داخلی بین کوئریها و کلیدها اجرا شده و «ماتریس امتیاز» (Score Matrix) ساخته میشود. ماتریس امتیاز میزان اهمیت هر کلمه برای سایر کلمات را مشخص میکند. بنابراین به هر کلمه امتیازی اختصاص مییابد که بیانگر ارتباط آن با دیگر کلمات در بازه زمانی یکسان است. این فرایند، کوئریها را به کلیدهای متناظر نگاشت میکند.
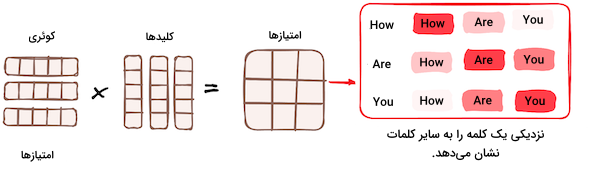
کاهش اندازه امتیاز های توجه
سپس با تقسیم بر جذر اندازه بردارهای کوئری و کلید، از ابعاد امتیازها کاسته میشود. با پیادهسازی این مرحله، مقادیر گرادیان پایدارتری بهدست میآیند.

اعمال تابع بیشینه هموار بر امتیاز ها
در ادامه و برای بهدست آوردن مقادیر وزنی، یک تابع «بیشینه هموار» (Softmax) بر تمام امتیازها اعمال میشود. نتایج به شکل مقادیر احتمالاتی بوده و از ۰ تا ۱ متغیر هستند. با افزودن به اهمیت امتیازهای بالاتر و کاهش ارزش امتیازهای پایین، تابع بیشینه هموار توانایی مدل را برای تشخیص کلمات مهم ارتقاء میدهد.

ترکیب نتایج تابع بیشینه هموار با بردار مقادیر
در این مرحله، مقادیر وزنی بهدست آمده از تابع بیشینه هموار در بردار خروجی ضرب میشوند. طی این فرایند، تنها کلماتی با امتیاز بالا حفظ شده و بردار خروجی حاصل، برای پردازش بیشتر وارد یک لایه خطی میشود.

به خاطر دارید که پیش از شروع این فرایندها، ابتدا کوئریها، کلیدها و مقادیر را h مرتبه تقسیم کردیم. روندی با عنوان خودنگرش یا Self-Attention، که در هر یک از مراحل جزئیتر که سویه یا Head نام دارند نیز تکرار میشود. هر سویه مستقل کار میکند و تداعیگر خروجی منحصربهفردی است. خروجی نهایی از یک لایه خطی عبور کرده و به این صورت، عملکرد نهایی مدل مورد ارزیابی قرار میگیرد. اهمیت این رویکرد به تنوع مراحل یادگیری در بخشهای مختلف و درک چند جانبه مدل رمزگذار است.
مرحله ۲.۳ - نرمال سازی و اتصالات باقیمانده
پس از هر زیرلایه در لایه رمزگذار، یک مرحله نرمالسازی قرار دارد. همچنین برای رفع مشکل «محوشدگی گرادیان»، خروجی هر زیرلایه به ورودی آن اضافه میشود. فرایندی که بعد از شبکه عصبی پیشخور نیز تکرار میشود.

مرحله ۳.۳ - شبکه عصبی پیشخور
بهمنظور اصلاح نهایی، خروجی نرمال شده از یک شبکه عصبی پیشخور «نقطهای» (Pointwise) عبور میکند. این شبکه متشکل از دو لایه خطی با تابع فعالسازی ReLU است. خروجی طی یک چرخه تکرار با ورودی شبکه نقطهای ادغام میشود. مانند مراحل قبل، در اینجا نیز یک لایه نرمالسازی در انتها قرار گرفته تا مقادیر بهدست آمده با سایر خروجیها هماهنگ باشند.

مرحله ۴ - خروجی رمزگذار
خروجی لایه رمزگذار پایانی را مجموعهای از بردارها تشکیل میدهند که هر کدام شامل بخشی از اطلاعات پردازش شده تا این مرحله هستند. از این خروجی به عنوان ورودی بخش رمزگشا استفاده میشود. مجموع مراحل اجرا شده در بخش رمزگذار، بخش بعدی یعنی رمزگشا را قادر میسازد تا بر قسمتهای مهم عبارت ورودی تمرکز کند. این فرایند را مانند ساخت برجی تصور کنید که در آن n لایه رمزگذار بر روی هم قرار میگیرند. هر لایه میتواند جنبه متفاوتی را از ورودی فرا بگیرد. سلسله مراتبی که نه تنها باعث ادراکی چندجانبه شده بلکه به شکل چشمگیری توانایی پیشبینی شبکه ترنسفورمر را بهبود میبخشد.
ساختار رمزگشا
وظیفه بخش رمزگشا چیزی نیست جز ایجاد توالی متنی. در ساختار رمزگشا، زیرلایههای مشابهی با رمزگذار مشاهده میشود. بهطور دقیقتر، رمزگشا متشکل از دو لایه توجه چندسویه، یک لایه پیشخور نقطهای و لایههای نرمالسازی پس از هر زیرلایه است.

عملکرد قسمتهای مختلف رمزگشا با لایههای رمزگذار چندان تفاوتی ندارد. بهجز آنکه در رمزگشا، هدف هر لایه توجه چندسویه با دیگری متفاوت است. بخش پایانی فرایند رمزگشا شامل یک لایه خطی است که نقش «دستهبند» (Classifier) را داشته و همراه با یک تابع بیشینه هموار، احتمال رخداد کلمات مختلف را محاسبه میکند. ساختار رمزگشا مدلهای ترنسفورمر در یادگیری عمیق به گونهای طراحی شده است که خروجی را قدم به قدم و با رمزگشایی از اطلاعات رمزگذاری شده تولید کند.
توجه داشته باشید که شیوه کارکرد بخش رمزگشا به نوعی خودهمبسته بوده و با یک توکن آغاز میشود. ساختاری که به شیوه هوشمندانه از خروجیهای تولید شده پیشین، در کنار خروجی رمزگذار به عنوان ورودی استفاده میکند. فعالیت رمزگشا با ایجاد توکنی که نشاندهنده انتهای خروجی است به پایان میرسد.
مرحله ۱ - تعبیه خروجی
مانند آنچه در رمزگذار اتفاق میافتد، در اینجا نیز ورودی از یک لایه تعبیه شده عبور میکند.
مرحله ۲ - رمزگذاری موقعیتی
در ادامه و مجدد مانند رمزگذار، ورودی از لایه رمزگذاری موقعیتی عبور میکند. روندی که برای تولید بردارهایی شامل موقعیت توکنها طراحی شده است. سپس این بردارها نقش ورودی را در لایه توجه چندسویه ایفا کرده و امتیاز توجه با دقت بالایی محاسبه میشود.
مرحله ۳ - پشته لایه های رمزگشا
ساختار رمزگشا متشکل از ۶ لایه انباشته شده است. هر لایه از سه بخش کوچکتری که در ادامه به آنها اشاره میکنیم تشکیل شده است.
مرحله ۱.۳ - مکانیزم خودنگرش پوششی
رویکردی شبیه به مکانیز خودنگرش در رمزگذار که با یک تفاوت اصلی همراه است. در ساختار رمزگشا، موقعیت هر توکن نقشی در موقعیت توکن بعدی نداشته و هر کلمه مستقل در نظر گرفته میشود. به عنوان مثال بسیار مهم است که کلمه you نقشی در محاسبه امتیاز توکن are نداشته باشد.

این فرایند اطمینان حاصل میکند که پیشبینیهای مربوط به یک موقعیت خاص، تنها به خروجیهای پیش از آن وابسته باشند.
مرحله ۲.۳ - توجه چندسویه رمزگذار-رمزگشا یا توجه متقابل
در دومین لایه توجه چندسویه، شاهد تعاملی ویژه میان بخشهای مختلف رمزگذار و رمزگشا هستیم. به این صورت که خروجی رمزگذار نقش کوئریها و همچنین کلیدها را داشته و مقادیر نیز همان خروجی اولین لایه توجه رمزگشا هستند. در نتیجه نوع ورودی رمزگذار و رمزگشا یکسان بوده و رمزگشا بهتر میتواند بخشهای مهم را از ورودی رمزگذار شناسایی کند. سپس و برای پردازش بیشتر، خروجی این لایه وارد یک لایه پیشخور نقطهای میشود.

کوئریهای مختص به این زیرلایه از لایه رمزگشا و کلیدها و مقادیر از خروجی رمزگذار تامین میشوند. طی این فرایند، ادغام اطلاعات حاصل از رمزگذار و رمزگشا صورت میگیرد.
مرحله ۳.۳ - شبکه عصبی پیشخور
مشابه با رمزگذار، هر لایه رمزگشا نیز شامل لایه تمام متصلی است که بهطور مجزا و یکسان بر هر توکن اعمال میشود.

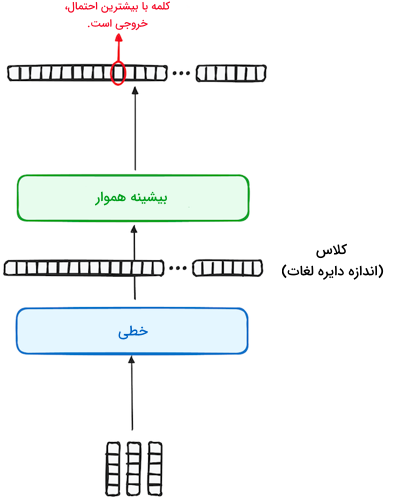
مرحله ۴ - دسته بند خطی و تابع بیشینه هموار برای تولید خروجی
سفر دادههای ورودی به مدل ترنسفورمر با گذر از یک لایه خطی که مانند دستهبند عمل میکند به پایان میرسد. اندازه این دستهبند با تعداد کل کلاسهای مسئله یا همان تعداد کلمات برابر است. به عنوان مثال در مسئلهای با ۱۰۰۰ کلاس یا کلمه مختلف، خروجی دستهبند، آرایهای متشکل از ۱۰۰۰ نمونه خواهد بود. سپس این خروجی وارد یک لایه بیشینه هموار شده و به برداری با دامنه متغیر از ۰ تا ۱ تغییر پیدا میکند. بالاترین این احتمالات، همان کلیدی است که به کلمه پیشبینی شده بعدی مدل در جمله اشاره دارد.
نرمال سازی و اتصالات باقیمانده
پس از هر زیر لایه (خودنگرش پوششی، توجه رمزگذار-رمزگشا، شبکه پیشخور) یک مرحله نرمالسازی انجام میشود و خروجی یک لایه به ورودی لایه دیگر متصل است.
خروجی رمزگشا
همانطور که پیشتر نیز اشاره شد، خروجی لایه آخر، دنبالهایست که با گذر از یک لایه خطی و تابع بیشینه هموار، مجموعهای از احتمالات را برای کلمات پیشبینی میکند. ساختار رمزگشا به این شکل است که خروجیهای جدید مدام به لیست دادههای ورودی اضافه شده و فرایند رمزگشایی ادامه مییابد. این چرخه تا زمانی تکرار میشود که مدل ترنسفورمر، توکنی را به عنوان سیگنال پایان کار پیشبینی کند. توکن پایانی، اغلب احتمالی بالاتری نسبت به سایر توکنها دارد.
به خاطر داشته باشید که رمزگشا محدود به یک لایه نیست و امکان دارد از n لایه انباشته که هر کدام ورودی خود را از بخش رمزگذار و لایههای پیشین میگیرند تشکیل شده باشد. از طریق این معماری لایه به لایه، مدل ترنسفورمر میتواند الگوهای مختلف را با دقت بیشتری نسبت به سایر روشها شناسایی کند. ساختار نهایی ترنسفورمر به شکل زیر است:
مدل های ترنسفورمر کاربردی
پس از تعریف و آشنایی با ساختار ترنسفورمر در یادگیری عمیق، در این بخش از مطلب مجله فرادرس، مدلهای ترنسفورمری را معرفی میکنیم که اغلب توسط سازمانهای بزرگ توسعه یافته و بسیار مورد استفاده قرار گرفتهاند.
BERT
شرکت گوگل در سال ۲۰۱۸ با معرفی «فریمورک» پردازش زبان طبیعی و متنباز BERT، تحولی در حوزه NLP رقم زد. قابلیت آموزش دو طرفه این فریمورک باعث شد تا مدلها، پیشبینی دقیقتری از کلمات بعدی در جملات ارائه دهند. در نتیجه BERT با درک محتوای دو طرف یک کلمه، توانست عملکرد بهتری نسبت به مدلهای پیشین در کاربردهایی همچون پرسش و پاسخ و درک زبانهای مبهم از خود بهجا بگذارد. فریمورک BERT از ترنسفورمرها برای اتصال عناصر ورودی و خروجی به یکدیگر بهره میبرد.

از آنجا که BERT با محتوا ویکیپدیا آموزش دیده است، بسیار برای مسائل مختلف NLP کاربرد داشته و قرار است برای نمایش دقیقتر کوئریها، با موتور جستجو گوگل ادغام شود. این نوآوری را میتوان سرآغاز رقابت برای توسعه مدلهای پیشرفته زبانی دانست.
LaMDA
عنوان LaMDA مخفف عبارت Language Model for Dialogue Applications یا «مدل زبانی برای کاربردهای مکالمه»، یک مدل مبتنیبر ترنسفورمر در یادگیری عمیق است که توسط شرکت گوگل و بهطور ویژه برای کاربردهای مکالمهمحور در سال ۲۰۲۱ معرفی شده است. هدف از طراحی این مدل را میتوان در تولید پاسخهای طبیعی و نزدیکتر به زبان انسان برای بهبود تجربه کاربر در نرمافزارهای مختلف خلاصه کرد.

طراحی LaMDA بهگونهایست که میتواند به گستره وسیعی از موضوعات پاسخ دهد و در کاربردهای متنوعی مانند چتباتها، دستیار مجازی و دیگری سیستمهای هوشمند تعاملی که پویایی مکالمه حائز اهمیت است بهکار گرفته شود. این تمرکز بر درک و پاسخ به مکالمات، مدل LaMDA را به تحولی قابل توجه در زمینه پردازش زبان طبیعی و ارتباطات مبتنیبر هوش مصنوعی تبدیل کرده است.
GPT و ChatGPT
توسعه یافته توسط شرکت OpenAI، دو مدل مولد GPT و ChatGPT به تواناییشان در تولید متون منسجم و از نظر مفهومی مرتبط شناخته میشوند. اولین مدل یعنی GPT-1 در سال ۲۰۱۸ و در ادامه مدل GPT-3 که یکی از تاثیرگذارترین مدلهای زبانی حال حاضر جهان است در سال ۲۰۲۰ معرفی و عرضه شد. مهارت این مدلها دامنه متنوعی از کاربردها را همچون تولید محتوا، مکالمه و ترجمه زبانی شامل میشود. معماری GPT به نحوی است که مدل را قادر میسازد، محتوایی بسیار شبیه به متن انسان تولید کند و در کاربردهایی مانند نگارش خلاقانه، خدمات مشتری و دستیار برنامهنویس بهکار گرفته شود. مدل ChatGPT نسخهای بهینه شده برای مکالمات متنی است و با تولید متون بسیار نزدیک به زبان انسان، کارکرد سیستمهایی مانند چتباتها و دستیارهای مجازی را بهبود بخشیده است.

سایر مدل ها
دامنه مدلهای پایه بهویژه مدلهای ترنسفورمر در یادگیری عمیق به سرعت در حال گسترش است. در تحقیقی، تعداد این مدلها به ۵۰ مورد تخمین زده شده و در گزارشی دیگر از دانشگاه استنفورد، تعداد ۳۰ مدل ترنسفورمر شناسایی شدهاند که نشاندهنده سرعت رشد بالا این حوزه است. استارتاپ NLP Cloud بخشی از برنامه تحقیقاتی شرکت NVIDIA است که به تنهایی ۲۵ مدل زبانی بزرگ و تبلیغاتی را برای صنایعی همچون خطوط هواپیمایی و داروخانهها توسعه داده است. جریان گستردهای برای طراحی و عرضه مدلهای متنباز، تحت پلتفرمهایی مانند Hugging Face در حال رشد و پیشرفت است. همچنین برای هر زمینه خاص از NLP، مدلهای ترنسفورمر متعددی توسعه یافتهاند که تنوع و کارایی مدلها را در کاربردهای مختلف نشان میدهد.
شاخص ها و عملکرد
ارزیابی و سنجش عملکرد مدلهای ترنسفورمر در یادگیری عمیق و NLP، رویکردی هدفمند برای سنجش کارایی محسوب میشود. متناسب با نوع مسئله، روشها و منابع مختلفی برای اینکار وجود دارد که در این بخش به معرفی چند نمونه از آنها میپردازیم. همچنین اگر میخواهید بهطور کاربردی نحوه پیادهسازی مسائل NLP را یاد بگیرید، مشاهده فیلم آموزش پردازش زبان طبیعی فرادرس را از طریق لینک زیر به شما پیشنهاد میدهیم:


ترجمه ماشینی
در کاربرد ترجمه ماشینی میتوان از دیتاستهای استانداردی مانند WMT برای آموزش مدل یادگیری ماشین استفاده کرد. معیارهایی مانند BLEU، METEOR، TER و chrF ابزارهایی برای اندازهگیری دقت و کارایی بهشمار میروند. همچنین بهکار گرفتن سیستم در زمینههای مختلفی مانند اخبار، ادبیات و متون فنی باعث گسترش دامنه کارایی میشود.
شاخص های QA
برای ارزیابی مدلهای پرسش و پاسخ یا QA از دیتاستهایی همچون SQuAD، Natural Questions یا TriviaQA بهره میبریم. هر کدام از این دیتاستها مانند نوعی بازی با قواعد مختص به خود است. برای مثال در دیتاست SQuAD هدف، پیدا کردن پاسخ در متن است و دو دیتاست دیگر مانند امتحانی با پرسشهای پراکنده هستند. برای سنجش عملکرد این مدلها از معیارهای «صحت»، «بازیابی» و «امتیاز F1» کمک میگیریم. در مجله فرادرس مطلب اختصاصی در مورد انواع معیارهای ارزیابی منتشر شده است که از طریق لینک زیر قابل دسترسی است:
شاخص های NLI
هنگام مواجه با «استنتاج زبان طبیعی» (Natural Language Inference | NLI) از دیتاستهایی مانند SNLI، MultiNLI و ANLI استفاده میشود. این دیتاستها شبیه به کتابخانههای بزرگی از انواع زبانها و موارد خاص هستند که با کمک آنها میتوانیم عملکرد مدلها را نسبت به جملات مختلف ارزیابی کنیم. از جمله این موارد خاص میتوان به زمانی که یک کلمه به عبارات پیش از خود مرتبط بوده یا درک کلماتی مانند not، all و some اشاره کرد.
مقایسه ترنسفورمر با دیگر ساختار ها
مقایسه شبکههای عصبی بازگشتی (RNN) و پیچشی (CNN) با ترنسفورمر در یادگیری عمیق بسیار رایج است. این دو شبکه عصبی مزایا و معیابی داشته و هر کدام برای نوع خاصی از پردازش داده طراحی شده است. در ادامه این بخش، بیشتر درباره لایههای بازگشتی و پیچشی توضیح میدهیم.
لایه های بازگشتی
لایههای بازگشتی در واقع زیربنای شبکههای عصبی بازگشتی یا RNN هستند و در مدیریت دادههای ترتیبی کاربرد دارند. نقطه قوت این معماری را میتوان توانایی بالا آن در اجرای عملیاتهای ترتیبی برای مسائلی مانند پردازش زبان یا تحلیل دادههای سری زمانی دانست. در لایههای بازگشتی، خروجی مرحله قبل مجدد به عنوان ورودی لایه بعدی وارد شبکه میشود. مکانیزمی که شبکه عصبی را قادر میسازد تا اطلاعات گذشته را بهخاطر سپرده و بتواند درک جامعی از محتوا جمله بهدست آورد.
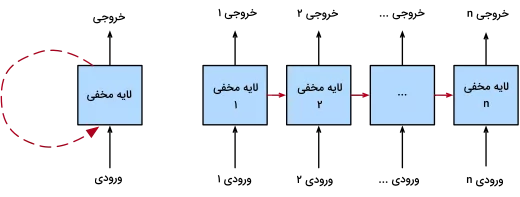
همانطور که پیشتر اشاره شد، فرایندهای ترتیبی دو نتیجه زیر را دربر دارند:
- با توجه به اینکه هر مرحله به مرحله قبل خود وابسته است، امکان دارد زمان آموزش طولانی شده و پردازش موازی را با چالش روبهرو کند.
- از آنجا که اغلب، طول شبکه زیاد است، وقوع مشکل محوشدگی گرادیان رواج داشته و کارایی مدل در یادگیری از لایههای اولیه کاهش مییابد.
بنابر ساختار بازگشتی، تفاوت قابل توجهی میان مدلهای ترنسفورمر در یادگیری عمیق با لایههای بازگشتی وجود دارد و لایه توجه در ترنسفورمر، راهحلی برای هر دو مشکل عنوان شده در فهرست بالاست که این رویکرد را برای کاربرد NLP مناسب میسازد.
لایه های پیچشی
از طرف دیگر، لایههای پیچشی اجزاء سازنده شبکههای عصبی پیچشی یا CNN هستند و به کارآمدی در پردازش دادههای فضایی مانند تصاویر شناخته میشوند. این لایهها از مجموعه فیلتر یا کرنلها برای پویش تصاویر ورودی و استخراج ویژگیها استفاده میکنند. اندازه این فیلترها قابل تغییر است و شبکه میتواند ویژگیهای کوچک یا بزرگتری را در مسئله مورد بررسی قرار دهد. در حالی که لایههای پیچشی قابلیت بالایی در کشف الگوهای فضایی دارند، همچنان قادر به پردازش و درک ترتیب اطلاعات متوالی نیستند.
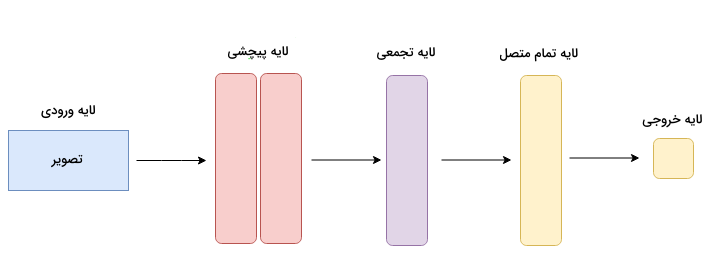
به همین خاطر کاربرد شبکههای عصبی پیچشی و ترنسفورمرها متفاوت است. با توجه به کارایی بالا در پردازش اطلاعات فضایی، عمده کاربرد CNN در بینایی کامپیوتر است و توانایی درک دنباله اطلاعات متنی باعث میشود، ترنسفورمرها گزینه مناسبی برای انتخاب در حوزه NLP باشند.
اگرچه ترنسفورمرها تحول عظیمی در یادگیری عمیق ایجاد کردهاند، اما شبکههای عصبی بازگشتی (RNN) و پیچشی (CNN) همچنان نقش مهمی در بسیاری از کاربردها ایفا میکنند. شبکههای RNN برای پردازش دادههای متوالی مانند متن و سریهای زمانی طراحی شدهاند. این شبکهها با حفظ اطلاعات در حافظه داخلی خود، قادر به مدلسازی وابستگیهای طولانیمدت در دادهها هستند. از سوی دیگر، شبکههای CNN در پردازش دادههایی مانند تصاویر برتری دارند. این شبکهها با استفاده از فیلترهای کانولوشنی، میتوانند ویژگیهای مکانی را از دادهها استخراج کنند.
اگر قصد دارید بهصورت حرفهای و جامع، نحوه طراحی و کار با شبکههای RNN و CNN را یاد بگیرید، میتوانید به لینکهای زیر مراجعه کرده و از فیلمهای آموزشی فرادرس که با دو زبان برنامهنویسی پایتون و متلب ارائه شدهاند بهرهمند شوید:
- فیلم آموزش مقدماتی شبکه عصبی LSTM و دستهبندی Sequence در متلب فرادرس
- فیلم آموزش پیادهسازی شبکه عصبی کانولوشنی CNN با تنسورفلو TensorFlow فرادرس
جمعبندی
معرفی ترنسفورمر تحولی بسیار بزرگ در هوش مصنوعی و بهویژه پردازش زبان طبیعی بوده است. مدلهایی که با مدیریت و پردازش دقیق دادههای ترتیبی از طریق مکانیزم خودنگرش، توانستند از روشهای قدیمی مانند RNN پیشی بگیرند. در این مطلب از مجله فرادرس با مفهوم ترنسفورمر در یادگیری عمیق و همچنین ساختار آن که از دو بخش کلی رمزگذار و رمزگشا تشکیل شده است آشنا شدیم. توسعه مدلهای ترنسفورمر همچنان ادامه داشته و روزبهروز، پیشرفتهای بیشتری را در حوزه هوش مصنوعی رقم میزنند.









مفید بود و روان