



آموزش تقسیم داده در یادگیری ماشین با پایتون – راهنمای کاربردی
عملیات تفکیک داده (تقسیم داده | Data Spliting) اغلب در یادگیری ماشین برای جداسازی دادهها به سه مجموعه آموزشی (Training Set)، آزمایشی (Test Set) و مجموعه اعتبارسنجی (Validation Set) مورد استفاده قرار میگیرد. در این مقاله به آموزش تقسیم داده در یادگیری ماشین با پایتون پرداخته شده است.
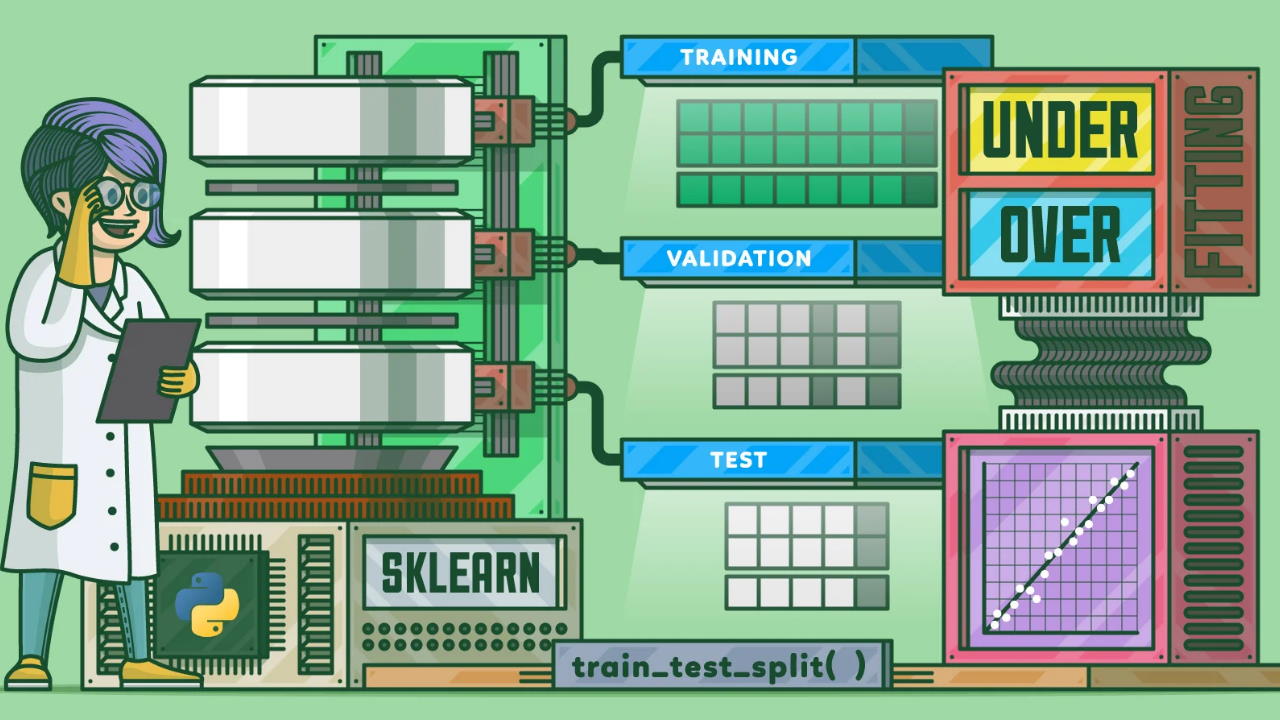


تقسیم داده در یادگیری ماشین چیست؟
جداسازی و تفکیک دادهها (تقسیم دادهها) به دادههای آموزشی و دادههای آزمایشی (Train-Test Split) روشی برای سنجش کیفیت عملکرد یک الگوریتم یادگیری ماشین به حساب میآید. از تفکیک داده میتوان برای مسائل دستهبندی (Classification) یا رگرسیون (Regression) استفاده کرد و به طور کلی این رویکرد در هر نوع الگوریتم یادگیری نظارت شدهای کاربرد دارد.
فرآیند تفکیک دادهها ، تقسیم یک مجموعه داده به دو یا سه زیرمجموعه را شامل میشود. در این بخش به برخی از مفاهیم مهم در هوش مصنوعی و یادگیری ماشین اشاره شد. به همین سبب برخی از مقالات مرتبط با این مفاهیم در ادامه معرفی شدهاند.
- مقالههای پیشنهادی:
چرا داده در یادگیری ماشین اهمیت دارد؟
در علم یادگیری ماشین، دادهها بسیار اهمیت دارند و به نوعی سوختِ کار به حساب میآیند. اهمیت داده در یادگیری ماشین به دو دلیل است:
- مدل برای یادگیری به داده نیاز دارد، به طوری که میتوان گفت: "کار مدل، استخراج و استفاده از علم موجود در دادهها است."
- برای سنجش مدل، نیاز به داده داریم، زیرا ممکن است مدل نتوانسته باشد به خوبی اطلاعات موجود در دادهها را استخراج کند.

آموزش تقسیم داده در یادگیری ماشین با پایتون
برای بخش اول فرآیند یادگیری ماشین، از دادههای آموزشی (Train) استفاده میشود و برای پایش (Monitoring) و بعضاً قطع کردن یادگیری مدل، میتوان از دادههای اعتبارسنجی (Validation) استفاده کرد. برای بخش دوم این فرآیند نیز از دادههای آزمایشی (Test) استفاده میشود. از بین این 3 دسته داده، میتوان دادههای Validation را استفاده نکرد؛ هرچند وجود آنها به تنظیم بهتر برخی از اَبَرپارامترها (Hyperparameters) کمک شایانی میکند.
فراخوانی کتابخانه های مورد نیاز برای تقسیم داده در یادگیری ماشین با پایتون
اکنون وارد محیط پایتون شده و ابتدا باید کتابخانههای مورد نیاز را فراخوانی کرد:
کتابخانه Numpy برای کار با آرایهها و بخش انتخاب مدل (Model Selection) در کتابخانه Sklearn یا همان کتابخانه Scikit-Learn برای تقسیم دادهها مورد نیاز است.

بارگذاری دادهها برای پیادهسازی پروژه تقسیم داده در یادگیری ماشین با پایتون
حال برای تقسیم دادهها نیاز به داده وجود دارد؛ برای این پروژه مجموعه داده IRIS مورد استفاده قرار گرفته است.
برای بارگذاری دادههای IRIS هم از کتابخانهی Sklearn به صورت زیر استفاده میشود:
به این ترتیب، دادههای مورد نیاز وارد محیط برنامه نویسی میشوند.
تقسیم دادههای آیریس به دو مجموعه Train و Test در پایتون
اگر تنها نیاز به دادههای Train و Test وجود داشته باشد، میتوان به صورت زیر عمل کرد:
در نتیجه اجرای خط کد فوق، 70 درصد دادهها برای آموزش و 30 درصد آنها برای آزمایش تخصیص داده خواهند شد؛ این فرآیند به صورت تصادفی اتفاق خواهد افتاد اما، X هر داده با ِY همان داده متناظر باقی خواهد ماند.

تقسیم دادهها به دو مجموعه Train و Test در پایتون به شکل قابل بازتولید
باید توجه داشت که این کد در هر بار اجرا، دادهها را به روشهای متفاوتی تقسیم میکند و برنامه به شکل یکسان قابل بازتولید (Reproducible) نخواهد بود و اگر نیاز باشد، میتوان Ransom State را به صورت زیر تنظیم کرد:
به این ترتیب، در هر بار اجرا، دادهها به یک روش یکسانی تقسیم خواهند شد. باید توجه داشت که ترتیب خروجیهای تابع train_test_split ابتدا برای Xها و سپس برای Yها است و در مرحلهی بعد نیز اولویت با دادههای Train خواهد بود.
بررسی ابعاد داده برای تقسیم داده ها در یادگیری ماشین با پایتون
حالا میتوان ابعاد دادهها را بررسی کرد:
خروجی به صورت زیر است:
X.shape = (150, 4) -- Y.shape = (150,) trX.shape = (105, 4) -- trY.shape = (105,) teX.shape = (45, 4) -- teY.shape = (45,)
بنابراین هم نسبت دادهها و هم اندازه اولین بُعد دادهها رعایت شده است. اما اگر قصد انجام اعتبارسنجی یا همان Validation هم روی دادهها وجود داشته باشد، باید کمی متفاوتتر عمل کرد.
تفکیک داده برای اعتبارسنجی در یادگیری ماشین با پایتون چگونه انجام میشود؟
ابتدا میتوان دادههای Train (دادههای آموزشی) را جدا کرد و سپس در مرحله بعد جداسازی دادههای اعتبارسنجی را از دادههای آزمایشی انجام داد:
در این بخش، ۷۰ درصد دادهها در ابتدا برای آموزش جدا شدهاند و باقیمانده آنها در متغیرهای X2 و Y2 ذخیره میشوند.
نسبت داده ها برای تقسیم دادههای تست و Validation به صورت مساوی
حال میتوان X2 و Y2 را به صورت 1:1 بین دادههای آزمایشی و دادههای اعتبارسنجی تقسیم کرد؛ نسبتهای نهایی به صورت زیر خواهند بود:
باید توجه داشت که در تابع دوم مقدار train_size اندازه اولین مجموعه خروجی تابع را نشان میدهد که در این کد برابر با مجموعه اعتبارسنجی شده است. حال دوباره میتوان ابعاد دادهها را بررسی کرد:
خروجی به صورت زیر خواهد بود:
X.shape = (150, 4) -- Y.shape = (150,) trX.shape = (105, 4) -- trY.shape = (105,) vaX.shape = (22, 4) -- vaY.shape = (22,) teX.shape = (23, 4) -- teY.shape = (23,)
طراحی تابع تقسیم داده در پایتون
حال میتوان تابعی طراحی کرد که همین عملیات را انجام دهد و کارهای کدنویسی را تسهیل کند. برای انجام این کار، ابتدا در ورودی، دادهها و اندازه مجموعههای Train و Validation دریافت میشوند::
باید توجه داشت که لازم است جنس دادهها از نوع آرایههای n-بعدی Numpy باشد و اندازه هر مجموعه نیز عددی اعشاری و از 0 تا 1 خواهد بود. حال باید دادههای Train را جدا کرد:
سپس نیاز است دادههای Validation و Test جدا شوند. برای این کار ابتدا باید اندازه دادههای Test را یافت:
حال میتوان دادههای بخش دوم را تقسیم کرد:
به این ترتیب، هر سه مجموعه داده از هم جدا میشوند.

۷. تعیین شکل خروجی تابع تقسیم داده در پایتون
حال میتوان خروجی تابع را تعریف کرد؛ اما از آن جایی که 6 آرایه در خروجی دریافت میشود و ممکن است در هنگام استفاده باعث بروز خطاهایی شود، از نوع داده دیکشنری در پایتون استفاده شده است:
به این ترتیب، میتوان با استفاده از کلیدها به هر آرایه دسترسی داشت.
۸. شکل نهایی تابع تقسیم داده در یادگیری ماشین با پایتون
حال دیکشنری حاصل در خروجی بازگردانده میشود و تابع شکل نهایی زیر را به خود میگیرد:
حال میتوان این تابع را به شکل زیر فراخوانی و استفاده کرد:
آرایهها نیز به این شکل در دسترس خواهند بود:
به این ترتیب، احتمال خطا نیز پایین خواهد آمد.
افزودن ویژگیهایی برای بهبود قابلیت تنظیم تابع تقسیم داده در پایتون
تابع تا اینجا کامل است، اما باید تعدادی ویژگی به آن اضافه شود تا رفتار آن قابل تنظیمتر باشد. اولین مورد، تنظیم Random State در ورودی و استفاده از آن برای تقسیم دادهها است. دومین مورد نیز کنترل کردن سایز Train و Validation است. پس از اصلاح این دو مورد، تابع ما شکل زیر را به خود میگیرد:
باید توجه داشت که برای RS مقدار پیشفرض None قرار داده شده است، زیرا امکان دارد تحت شرایطی، قصد Fix کردن Random State وجود نداشته باشد. برای ایجاد پیام خطا در مورد اندازه دادهها نیز از assert استفاده میشود و برای مثال اگر تابع به اشتباه به شکل زیر فراخوانی شود، خطا رخ خواهد داد:
خطای مربوطه به صورت زیر خواهد بود:
Exception has occurred: AssertionError Train Size + Validation Size Must be Smaller Than 1
به این ترتیب، تابع تقسیم داده در یادگیری ماشین با پایتون کامل شد و میتوان در پروژههای خود از آن استفاده کرد. حال در بخش انتهایی این مقاله به معرفی دورههای آموزشی مرتبط با آموزش تقسیم داده در یادگیری ماشین با پایتون پرداخته شده است.

جمعبندی
در این مقاله نحوه تقسیم داده در یادگیری ماشین با پایتون آموزش داده شد. تابعی برای تقسیم داده در پایتون ساخته شده است که میتوان از آن در پروژههای یادگیری ماشین خود استفاده کرد. میتوان برحسب نیاز خود، تابع ساخته شده را تغییر داد و آن را با نیاز خود سازگار ساخت. برای تمرین کدنویسی بیشتر، میتوان همین تابع را با استفاده از کتابخانهی Numpy و نوع داده لیست در پایتون پیادهسازی کرد.








عالی بود ممنون
با سلام، خیلی ممنون از همراهی شما.