



متن کاوی با پایتون در توییتر – راهنمای جامع و کاربردی
در این مطلب، روش انجام متن کاوی با پایتون در توییتر، همراه با ارائه یک مثال کامل، مورد بررسی قرار گرفته است.




متن کاوی با پایتون در توییتر
«متنکاوی» (Text Mining) یکی از کاربردهای «پردازش زبان طبیعی» (Natural Language Processing) و یک روش تحلیلی برای دادههای متنی به منظور کسب اطلاعات مناسب از آنها است. در سالهای اخیر، متنکاوی توجهات زیادی را به خود جلب کرده است. دلیل این امر، افزایش دادههای متنی دیجیتال در صفحات وب، پروژههای گوگل مانند «گوگل بوک» (Google Books) و «گوگل انگرام» (Google ngram)، خدمات شبکههای اجتماعی مانند «توییتر» (Twitter) و دیگر موارد است.
دادههای توییتر منبعی غنی از اطلاعات هستند که میتوان از آنها برای کسب اطلاعات در موارد گوناگون مانند یافتن موضوعات داغ مرتبط با یک کلیدواژه، سنجش و تحلیل عواطف پیرامون یک برند، گردآوری بازخوردها پیرامون یک محصول یا سرویس جدید استفاده کرد. در این راهنما، از دادههای توییتر برای مقایسه محبوبیت ۳ زبان برنامهنویسی «پایتون» (Python)، «جاوا اسکریپت» (Java Script) و «روبی» (Ruby) و آموزشهای مورد استفاده توسط افراد برای یادگیری این زبانها، استفاده شده است. در اولین بخش از این مطلب، چگونگی اتصال به «رابط برنامهنویسی کاربردی استریم توییتر» (Twitter Streaming API) و چگونگی دریافت دادههای توییتر پرداخته میشود. در بخش دوم از این راهنما، چگونگی ساختاردهی به دادهها برای انجام تحلیلها و در بخش آخر، چگونگی فیلتر کردن دادهها برای استخراج لینکها از توییتها استفاده شده است.
برای انجام آنچه بیان شد، از دادههای دو روز توییتر استفاده شده است. از این دادهها، ۶۴۴ لینک به آموزشهای پایتون، ۴۱۳ لینک به آموزشهای جاوا اسکریپت و ۱۳۶ لینک به آموزشهای روبی بازیابی شده است. بر این اساس، میتوان گفت که محبوبیت پایتون، در زمان انجام پروژه، ۱/۵ برابر بیشتر از جاوا اسکریپت و ۴ برابر بیشتر از روبی بوده است.

۱. دریافت دادههای روبی با استفاده از Twitter Streaming API
API مخفف Application Programming Interface یا همان رابط برنامهنویسی کاربردی است. API ابزاری است که با برنامههای کامپیوتری و سرویسهای وب به سادگی تعامل میکند. بسیاری از ارائهدهندگان خدمات وب، رابطهای برنامهنویسی کاربردی را برای توسعهدهندگان به منظور فراهم کردن امکان تعامل به خدمات آنها و دسترسی به دادهها به شیوه برنامهنویسی (Programmatic) ارائه میکنند.

در این مطلب، از Twitter Streaming API برای دانلود توییتهای مرتبط با سه کلیدواژه «javascript» ،«python» و «ruby» استفاده شده است.
گام اول: دریافت کلیدهای رابط برنامهنویسی کاربردی توییتر
به منظور دسترسی داشتن به Twitter Streaming API نیاز به چهار تکه اطلاعات از توییتر است. این چهار تکه اطلاعات عبارت هستند از: کلید API (یا همان API Key)، راز API (یا همان API Secret)، توکن دسترسی (Access Token) و «رمز توکن دسترسی» (Access Token Secret). برای به دست آوردن این چهار تکه اطلاعات، باید گامهای زیر را انجام داد.
- یک اکانت توییتر باید ساخته شود. افرادی که در حال حاضر توییتر دارند، نیاز به انجام این کار ندارند.
- به این صفحه [+] رفته و با اطلاعات اکانت توییتر مورد نظر، ورود (Log In) انجام شود.
- روی گزینه «Create New App» کلیک شود.
- فرم موجود تکمیل، با شرایط و قواعد موافقت و روی گزینه «Create your Twitter application» کلیک شود.
- در صفحه بعد، روی سربرگ «API keys» کلیک و «API key» و «API secret» کپی شوند.
- روی صفحه به پایین اسکرول و روی گزینه «Create my access token» کلیک شود. سپس، «Access token» و «Access token secret» کپی شوند.
گام دوم: اتصال به Twitter Streaming APIو دانلود دادهها
در اینجا از کتابخانه زبان برنامهنویسی پایتون به نام «Tweepy» برای اتصال به Twitter Streaming API و دانلود دادهها استفاده شده است. بنابراین، مخاطبانی که Tweepy را پیش از این نصب نکردهاند، برای انجام مراحلی که در ادامه بیان شده است، ابتدا باید آن را دانلود و نصب کنند.
سپس، باید فایلی به نام twitter_streaming.py ساخته شود. پس از آن، باید کد زیر را در آن فایل کپی کرد. همچنین، باید اطمینان حاصل کرد که اطلاعات اعتباری در consumer_key ،access_token_secret ،access_token و consumer_secret وارد شوند.
در صورت اجرای این برنامه از ترمینال با استفاده از دستور python twitter_streaming.py، خروجی زیر به کاربر نمایش داده خواهد شد.

این برنامه را میتوان با فشردن کلیدهای ترکیبی Ctrl-C متوقف کرد. هدف ثبت این دادهها در یک فایل است که بعدا برای تحلیلها مورد استفاده قرار میگیرد. این کار را میتوان با پایپ کردن خروجی به یک فایل با استفاده از دستور زیر انجام داد.
برنامه برای دو روز اجرا شده است (از ۲۰۱۴/۰۷/۱۵ تا ۲۰۱۴/۰۷/۱۷) تا نمونه دادههای معناداری حاصل شوند. سایز فایل حاصل شده، ۲۴۲ مگابایت است.
۲. مطالعه و درک دادهها
دادههای ذخیره شده در twitter_data.txt در فرمت JSON هستند. JSON سرنامی برای «JavaScript Object Notation» است. این فرمت، خواندن دادهها را برای انسانها و تجزیه آن را برای ماشینها، آسان میکند.
در ادامه، مثالی از یک توئیت در فرمت JSON داده شده است. میتوان مشاهده کرد که توئیت علاوه بر متن اصلی حاوی اطلاعات افزوده است؛ این اطلاعات، در این مثال، به صورت زیر هستند:
"Yaayyy I learned some JavaScript today! #thatwasntsohard #yesitwas #stoptalkingtoyourself #hashbrown #hashtag"
{"created_at":"Tue Jul 15 14:19:30 +0000 2014","id":489051636304990208,"id_str":"489051636304990208","text":"Yaayyy I learned some JavaScript today! #thatwasntsohard #yesitwas #stoptalkingtoyourself #hashbrown #hashtag","source":"\u003ca href=\"http:\/\/twitter.com\/download\/iphone\" rel=\"nofollow\"\u003eTwitter for iPhone\u003c\/a\u003e","truncated":false,"in_reply_to_status_id":null,"in_reply_to_status_id_str":null,"in_reply_to_user_id":null,"in_reply_to_user_id_str":null,"in_reply_to_screen_name":null,"user":{"id":2301702187,"id_str":"2301702187","name":"Toni Barlettano","screen_name":"itsmetonib","location":"Greater NYC Area","url":"http:\/\/www.tonib.me","description":"So Full of Art | \nToni Barlettano Creative Media + Design","protected":false,"followers_count":8,"friends_count":25,"listed_count":0,"created_at":"Mon Jan 20 16:49:46 +0000 2014","favourites_count":6,"utc_offset":null,"time_zone":null,"geo_enabled":false,"verified":false,"statuses_count":20,"lang":"en","contributors_enabled":false,"is_translator":false,"is_translation_enabled":false,"profile_background_color":"C0DEED","profile_background_image_url":"http:\/\/abs.twimg.com\/images\/themes\/theme1\/bg.png","profile_background_image_url_https":"https:\/\/abs.twimg.com\/images\/themes\/theme1\/bg.png","profile_background_tile":false,"profile_image_url":"http:\/\/pbs.twimg.com\/profile_images\/425313048320958464\/Z2GcderW_normal.jpeg","profile_image_url_https":"https:\/\/pbs.twimg.com\/profile_images\/425313048320958464\/Z2GcderW_normal.jpeg","profile_link_color":"0084B4","profile_sidebar_border_color":"C0DEED","profile_sidebar_fill_color":"DDEEF6","profile_text_color":"333333","profile_use_background_image":true,"default_profile":true,"default_profile_image":false,"following":null,"follow_request_sent":null,"notifications":null},"geo":null,"coordinates":null,"place":null,"contributors":null,"retweet_count":0,"favorite_count":0,"entities":{"hashtags":[{"text":"thatwasntsohard","indices":[40,56]},{"text":"yesitwas","indices":[57,66]},{"text":"stoptalkingtoyourself","indices":[67,89]},{"text":"hashbrown","indices":[90,100]},{"text":"hashtag","indices":[101,109]}],"symbols":[],"urls":[],"user_mentions":[]},"favorited":false,"retweeted":false,"filter_level":"medium","lang":"en"}
در ادامه این مطلب، از چهار کتابخانه پایتون استفاده خواهد شد. این کتابخانهها عبارتند از json برای تجزیه دادهها، «پانداس» (Pandas) برای دستکاری دادهها، «متپلاتلیب» (Matplotlib) برای ساخت نمودارها و re برای عبارات با قاعده. کتابخانههای json و re به طور پیشفرض در پایتون نصب هستند. اما در صورتی که پانداس و متپلاتلیب پیش از این توسط کاربر نصب نشدهاند، برای ادامه این پروژه، باید آنها را نصب کرد. اکنون، کار ابتدا با بارگذاری json و پانداس با استفاده از دستور زیر آغاز میشود.
سپس، دادهها در یک آرایه که tweets نامیده میشود، خوانده میشوند.
میتوان تعداد توییتها را با استفاده از دستور زیر، چاپ کرد. برای مجموعه دادهای که در این مطلب استفاده شده است، تعداد توییتها برابر با ۷۱۲۳۸ است.
سپس، دادههای توییتها در دیتافریم پانداس ساختاردهی میشوند تا دستکاری آنها آسانتر شود. کار با ساخت یک دیتافریم خالی به نام tweets با استفاده از دستور زیر، آغاز میشود.
سپس، سه ستون به دیتافریم tweets اضافه میشود که lang ،text و country نامیده میشوند. ستون text حاوی توییت، lang حاوی زبانی که توییت به آن نوشته شده و country، کشوری است که توییت از آن ارسال شده است.
سپس، دو نمودار ساخته میشود. نمودار اول ۵ زبان برتری که توییتها به آنها نوشته شده است و زبان دوم، ۵ کشور برتری که توییتها از آنها ارسال شده است را نشان میدهد.


۳. کاوش توییتها
هدف اصلی در این پروژه متنکاوی، مقایسه محبوبیت زبانهای برنامهنویسی پایتون، روبی و جاوا اسکریپت و بازیابی لینک آموزشهای برنامهنویسی داده شده است. این کار در سه گام انجام میشود.
- به دیتافریم tweets تگهایی به منظور فراهم کردن امکان دستکاری راحتتر دادهها، اضافه میشود.
- توئیتهایی که کلیدواژههای «pogramming» یا «tutorial» را دارند، هدف قرار میگیرند.
- استخراج لینکها از توئیتهای مرتبط انجام میشود.
گام اول: افزودن تگهای پایتون، روبی و جاوا اسکریپت
ابتدا، تابعی ساخته میشود که بررسی میکند آیا یک کلیدواژه در یک متن وجود دارد یا خیر. این کار با استفاده از «عبارات با قاعده» (Regular Expressions) انجام میشود. پایتون یک کتابخانه برای عبارات با قاعده به نام re دارد. این کار با وارد کردن (ایمپورت | Import) این کتابخانه انجام میشود.
سپس، تابعی ساخته میشود که word_in_text(word, text) نامیده میشود. این تابع در صورتی که word در text پیدا شود، True است؛ در غیر این صورت، مقدار False را باز میگرداند.
سپس، سه ستون به دیتافریم tweets اضافه میشود.
میتوان تعداد توییتها را برای هر زبان برنامهنویسی با استفاده از قطعه کد زیر محاسبه کرد.
این قطعه کد، موارد زیر را در خروجی باز میگرداند.
21839 for python, 16154 for javascript and 31410 for ruby
میتوان یک نمودار مقایسهای ساده را با اجرای قطعه کد زیر، ترسیم کرد.

نمودار بالا نشان میدهد که کلیدواژه ruby، محبوبترین است و پس از آن، python و سپس javascript قرار دارد. اگرچه، دیتافریم tweets حاوی اطلاعاتی پیرامون همه توییتهایی است که حاوی یکی از سه کلیدواژه هستند و اطلاعات را به زبانهای برنامهنویسی محدود نمیکند. برای مثال، توئیتهای زیادی وجود دارند که حاوی کلیدواژه ruby هستند و مرتبط با رسوایی سیاسی به نام Rubygate است. در بخش بعدی، توئیتها فیلتر میشوند و تحلیلها برای انجام مقایسههای صحیحتر، دوباره اجرا میشود.
گام دوم: هدفگیری توییتهای مرتبط
در اینجا، قصد آن است که توییتهایی که مرتبط با زبانهای برنامهنویسی هستند هدف قرار داده شوند. چنین توییتهایی معمولا یکی از دو کلیدواژه «programming» یا «tutorial» را در خود دارند. در اینجا دو ستون جدید برای دیتافریم tweets ساخته میشود که در آن ستونها، این اطلاعات اضافه میشوند.
یک ستون افزوده به نام relevant نیز ساخته میشود که در صورتی که توییتها حاوی کلیدواژههای «programming» و یا «tutorial» باشند، مقدار True و در غیر این صورت، مقدار False به خود میگیرد.
میتوان شمار توییتهای مرتبط را با اجرای دستور زیر، در خروجی چاپ کرد.
قطعه کد بالا، ۸۷۱ را در ستون programming، عدد ۵۱۱ را در ستون tutorial و ۱۳۵۶ را در ستون relevant، باز میگرداند. اکنون، میتوان محبوبیت زبانهای برنامهنویسی را با اجرای دستور زیر مقایسه کرد.
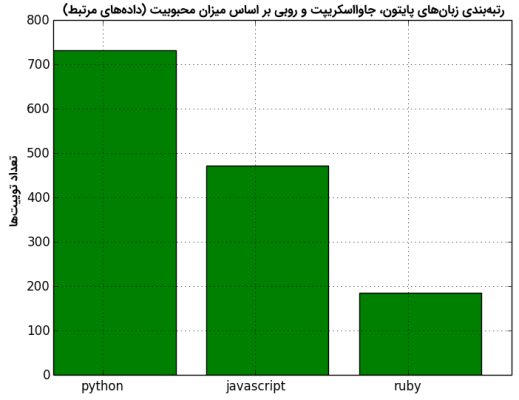
پایتون، محبوبترین زبان با ۷۳۲ مورد است. پس از پایتون، جاوا اسکریپت با ۴۷۳ مورد و در نهایت، روبی با ۱۸۵ مورد قرار دارد. میتوان نمودار مقایسه این موارد را با استفاده از دستور زیر، ترسیم کرد.

استخراج لینکها از توییتهای مرتبط
اکنون که توییتهای مرتبط استخراج شدند، هدف بازیابی لینکهای مربوط به آموزشهای برنامهنویسی است. کار با ساخت تابعی آغاز میشود که از عبارات با قاعده برای بازیابی لینکهایی از متن که با «http://» یا «https://» شروع میشوند استفاده میکند.
این تابع، در صورتی که url پیدا شود آن را باز میگرداند و در غیر این صورت، یک رشته خالی باز میگرداند.
سپس، یک ستون به نام link به دیتافریم tweets اضافه میشود. این ستون حاوی اطلاعات url است.
سپس، یک دیتافریم جدید به نام tweets_relevant_with_link ساخته میشود. این دیتافریم یک زیرمجموعه از دیتافریم tweets و حاوی همه توییتهای مرتبطی است که دارای لینک هستند.
اکنون میتوان همه لینکها را برای javascript ،python و ruby، با اجرای دستور زیر، چاپ کرد.
با اجرای قطعه کد بالا، ۶۴۴ لینک برای پایتون، ۴۱۳ لینک برای جاوا اسکریپت و ۱۳۶ مورد برای پایتون یافت شده است.
جمعبندی
در این راهنما، روشهای گوناگونی برای متن کاوی با پایتون در توییتر مورد استفاده قرار گرفتند. کدهای مورد استفاده در این مطلب را میتوان برای انجام تحلیلهای عمیقتر و سازگارسازی آنها با مسائل دیگر، ویرایش کرد.

اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای داده کاوی و یادگیری ماشین
- آموزش اصول و روشهای داده کاوی (Data Mining)
- مجموعه آموزشهای هوش مصنوعی
- تقلبنامه (Cheat Sheet) تولباکس تحلیل متن در متلب — راهنمای کاربردی
- روشهای متنکاوی — راهنمای کاربردی
- پیش پردازش متن در پایتون — راهنمای جامع
- آموزش پردازش زبان طبیعی پروژه محور — راهنمای کاربردی
^^








سلام
تشکر از محتوای آموزش خوب و مفیدتون.
موضوع پایان نامه من در خصوص متن کاوی هستش ، لطف اگه در این زمینه میتونید کمک کنید ایمیل بزنید. ممنون
سلام وقت بخیر
من جدیدا از توئیتر api گرفتم . فرمت api عوض شده و بجای دو token یکی تحت عنوان bearer token داده.
کد رو چطوری باید عوض کنم؟
ممنون میشم راهنمایی کنین
سلام
من از توییتر درخواست api کردم، اما چیزی که به من داده سه بخشه
Api key
Api secret key
Bearer token
چیکار باید کنم؟
شما گفتین 4 بخشه
لطفا راهنمایی کنین
ممنونم
با سلام؛
از همراهی شما با مجله فرادرس سپاسگزاریم. نرمافزارها در طول زمان به روز رسانی میشوند و تغییر میکنند و از این رو سایر کدهایی که برای کار با آنها نوشته میشوند نیز گاه نیازمند اصلاح و به روز رسانی هستند. API توئیتر نیز احتمالا از زمان نگارش این مطلب به بعد، دچار تغییراتی شده است که این مورد نیز از آن جمله است. در این راستا، شما باید کد را متناسب با API جدید بنویسید و سایر تغییرات احتمالی را نیز در آن اعمال کنید.