



آماره بسنده (Sufficient Statistic) و بسنده مینیمال – به زبان ساده
در تئوری آمار، موضوع برآوردیابی از اهمیت خاصی برخوردار است. منظور از برآوردیابی، بدست آوردن تابعی از نمونه تصادفی است که بتوان به کمک آن پارامتر جامعه را مشخص کرد. به نظر میرسد برای رسیدن به این منظور آماره نباید تابعی از پارامتر باشد. در این حالت فرض کنید تابعی از نمونه تصادفی n تایی باشد، علاقمند هستیم که این آماره بتواند بیشترین اطلاعات را در مورد پارامتر مجهول جامعه در اختیارمان قرار دهد، بطوری که هر آماره دیگر، قادر به ارائه این میزان اطلاعات در مورد پارامتر نباشد. چنین تابعی از نمونه تصادفی را به عنوان «آماره بسنده» (Sufficient Statistic) میشناسیم.




به نظر میرسد بهترین پاسخ برای چنین وضعیتی میتواند خود نمونه تصادفی باشد. ولی در بعضی از مواقع میتوان توابعی دیگر مانند حاصل جمع یا میانگین نمونه تصادفی را هم به عنوان آماره بسنده برای پارامتر جامعه در نظر گرفت. به این ترتیب این آمارهها میزان اطلاعات یکسانی از پارامتر جامعه در خود دارند. همانطور که مشخص شد، آماره بسنده یکتا نیست و ممکن است آمارهها مختلفی پیدا کرد که در مورد پارامتر، اطلاعات یکسانی داشته باشند. به این منظور به دنبال آماره بسندهای هستیم که بتواند همه آمارههای بسنده دیگر را تحت پوشش قرار دهد. چنین آمارهای را «آماره بسنده مینیمال» (Minimal Sufficient Statistic) مینامیم.
در این نوشتار به معرفی و بررسی خصوصیات آماره بسنده و بسنده مینیمال خواهیم پرداخت و البته دستورالعملهایی به منظور شناسایی آن ارائه خواهیم داد. به کمک آماره بسنده و بسنده مینیمال میتوان ابعاد یک مسئله استنباط آماری را کوچک کرد و مثلا از میانگین به جای کل نمونه تصادفی برای برآورد پارامتر یا انجام آزمون فرض استفاده کرد. برای مطالعه بیشتر در زمینه برآوردگرها و برآوردگرهای فاصلهای به مطلبهای تابع درستنمایی (Likelihood Function) و کاربردهای آن — به زبان ساده و فاصله اطمینان (Confidence Interval) — به زبان ساده مراجعه کنید. البته خواندن نوشتار آزمون های فرض و استنباط آماری — مفاهیم و اصطلاحات نیز خالی از لطف نیست.
آماره بسنده (Sufficient Statistic)
اگر یک نمونه تصادفی مستقل و هم توزیع با توجه به پارامتر ثابت ولی ناشناخته باشد، آماره بسنده را به صورت نشان داده که تابعی از نمونه تصادفی محسوب شده و شامل بیشترین اطلاعاتی است که برای برآورد پارامتر لازم است.
مفهوم و تعریف اولیه برای آماره بسنده توسط دانشمند بزرگ آمار «رونالد فیشر» (Ronald Fisher) در سال ۱۹۲۰ ارائه شد. این تعریف بعدها به عنوان یک مبنا برای شناسایی آمارههای مناسب به منظور برآورد پارامتر نامعلوم جامعه بدل شد. در ادامه پژوهشهای فیشر، قضیههایی که برمبنای آماره بسنده ساخته شده (مانند قضیه Rao-Blackwell)، روشهایی برای ایجاد بهترین برآوردگرها (با کمترین واریانس) در کلاس برآوردگرهای نااریب معرفی شد که همه مرهون تحقیقات فیشر در این زمینه بودند.

تعریف رسمی آماره بسنده
با توجه به اطلاعاتی که از احتمال شرطی یا توزیع شرطی در دیگر مطالب فرادرس داریم، میتوانیم تعریف رسمی برای آماره بسنده را به صورت زیر بیان کنیم.
آماره بسنده برای پارامتر است اگر توزیع احتمال نمونه تصادفی به شرط آماره مستقل از پارامتر باشد.
این گزاره نشان میدهد که اگر آماره بسنده در اختیارمان باشد، برای محاسبه تابع احتمال نمونه تصادفی دیگر احتیاجی به پارامتر نیست و اطلاعاتی که در خود دارد میتواند جایگزین پارامتر برای محاسبه احتمال شود.
مثال 1
فرض کنید و دو متغیر تصادفی (یک نمونه دو تایی) از توزیع برنولی با پارامتر باشند. در این صورت مشاهدات ما از این دو متغیر تصادفی به صورت زوج مرتب و به شکل زیر نوشته میشوند.
فرض کنید در این میان آماره بسنده باشد. باید مطابق تعریفی که از آماره بسنده داشتیم تابع احتمال شرطی نمونه تصادفی به شرط شامل پارامتر نباشد. میدانیم مجموع دو متغیر تصادفی برنولی مستقل و هم توزیع (با پارامتر ) دارای توزیع دو جملهای با پارامترهای 2 و است.
بنابراین میتوان تابع احتمال آنها را به صورت زیر نمایش داد.
حال احتمال شرطی نمونه تصادفی را به شرط آماره بسنده محاسبه میکنیم.
همانطور که میبینید این احتمال شبیه تابع درستنمایی است که برحسب آماره بسنده شرطی شده است. اطلاع دارید که تابع درستنمایی نیز از ابتکارات و ابداعات دانشمند بزرگ «رونالد فیشر» است. در ادامه محاسبات مربوط به رابطه بالا را پی میگیریم.
همانطور که دیده میشود، تابع احتمال شرطی وابسته به پارامتر نیست. بنابراین به درستی به عنوان آماره بسنده انتخاب شده است.
قضیه فاکتورگیری فیشر-نیمن (Fisher-Neyman Factorization Theorem)
فرض کنید نمونهای تصادفی مستقل و هم توزیع با پارامتر باشند. میتوان نشان داد که توزیع توام این نمونه تصادفی برحسب آماره بسنده به صورت زیر قابل تفکیک است:
در رابطه بالا تابعی از نمونه تصادفی است که شامل پارامتر جامعه نیست و از طرفی دیگر تابعی نامنفی از نمونه تصادفی و پارامتر جامعه است.
به این ترتیب میتوان گفت که تابع احتمال را میتوان به دو بخش تقسیم کرد. بخشی که فقط وابسته به نمونه تصادفی یعنی است و بخشی که به صورت ترکیبی از نمونه تصادفی و پارامتر جامعه است. در اینجا آماره بسنده نامیده میشود. این قضیه با نام تفکیک یا «فاکتورگیری فیشر-نیمن» (Fisher-Neyman Factorization Theorem) معروف است.
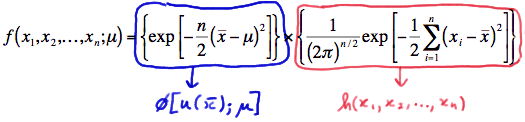
با توجه به این قضیه مشخص است که نمونه تصادفی خود یک آماره بسنده محسوب میشود. در بیشتر مواقع برای پیدا کردن آماره بسنده از این قضیه استفاده میشود زیرا تعریف ارائه شده برای آماره بسنده، روشی برای پیدا کردن آن مشخص نمیکند و فقط شرایطی که یک آماره را بسنده میکند، در تعریف مطرح شده است.
نکته: اگر آماره بسنده باشد، به راحتی با استفاده از این قضیه میتوان نشان داد به ازاء مقدار ثابت غیر صفر ، هر تابعی مثل نیز آماره بسنده است. بنابراین آماره بسنده یکتا نیست. ولی میدانیم مقدار اطلاعاتی که و در مورد پارامتر به همراه دارند یکسان است. در غیر اینصورت آماره بسنده محسوب نمیشدند.
مثال 2
فرض کنید میخواهیم برای توزیع نمایی با پارامتر ، آماره بسنده پیدا کنیم. به این منظور نمونه تصادفی n تایی به صورت تهیه کردهایم. طبق قضیه فاکتورگیری فیشر- نیمن عمل میکنیم.
از آنجایی که این نمونه تصادفی مستقل و هم توزیع (iid) هستند میتوانیم آنها را به صورت نشان دهیم. با توجه به تابع احتمال این متغیرهای تصادفی، توزیع احتمال توام (همزمان) آنها به صورت زیر نوشته میشود.
حال میتوانید طبق قضیه فاکتورگیری توابع و را به صورت زیر در نظر گرفت.
مشخص است که فقط به نمونه تصادفی و نیز به پارامتر و نمونه تصادفی از طریق وابسته است، بنابراین میتوان آماره بسنده را در نظر گرفت.
مثال 3
فرض کنید نمونه تصادفی مستقل و همتوزیع از نرمال با میانگین نامعلوم و واریانس معلوم باشند. نشان میدهیم که میانگین نمونهای، آماره بسنده برای میانگین جامعه محسوب میشود.
توزیع توام این نمونه تصادفی را با توجه به توزیع نرمال به صورت زیر مینویسیم. طی مراحلی که در ادامه قابل مشاهده است، از قضیه فاکتورگیری به این نتیجه میرسیم که میانگین نمونهای، آماره بسنده برای میانگین جامعه است.
با توجه به رابطه میتوان محاسبات قبل را به صورتی که در ادامه قابل مشاهده است سادهتر کرد.
بنابراین تابع و به صورت زیر نوشته خواهند شد.
به این ترتیب مشخص است که تابع از طریق به نمونه تصادفی مرتبط است. بنابراین میانگین نمونهای ، آماره بسنده برای پارامتر میانگین جامعه محسوب میشود.
آماره بسنده مینیمال
همانطور که در مطالب قبل گفته شد، آماره بسنده یکتا نیست. بنا به تعریف، آماره بسندهای که تابعی از همه آمارههای بسنده باشد، بسنده مینیمال (Minimal Sufficient) نامیده میشود. به این ترتیب میتوان آماره بسنده مینیمال را به نوعی موثرترین آماره بسنده برای پارامتر جامعه در نظر گرفت که عین اینکه بیشترین اطلاعات را به همراه دارد، از همه آمارههای بسنده نیز خلاصهتر و سادهتر است.

به طور رسمی آماره بسنده مینیمال را به صورت زیر تعریف میکنند.
آماره بسنده را بسنده مینیمال مینامند اگر برای هر آماره بسنده دیگر مثل و تابع دلخواه داشته باشیم:
برای مشخص کردن آماره بسنده از قضیه فاکتورگیری فیشر استفاده میکنیم. به این ترتیب اگر آماره بسنده مینیمال باشد باید در رابطه زیر به صورت دو طرفه برقرار باشد.
این رابطه به این معنی است که اگر نسبت توابع توزیع توام دو نمونه تصادفی و بستگی به پارامتر نداشته باشد، بتوان نتیجه گرفت که آماره بسنده برای هر دو نمونه تصادفی یکسان است و البته برعکس. با این کار میتوان بررسی کرد آیا یک آماره بسنده، میتواند بسنده مینیمال هم باشد یا خیر. این روش به نام قضیه «لهمن-شفه» (Lehmann–Scheffé theorem) معروف است.


به منظور روشنتر شدن موضوع به بررسی دو مثال میپردازیم.
مثال 4
فرض کنید و دو متغیر تصادفی (یک نمونه دو تایی) از توزیع برنولی با پارامتر باشند. در این صورت میانگین این دو آماره بسنده مینیمال است.
برای نشان دادن این موضوع کمی به عقب برمیگردیم. مطابق با مثال ۱ میدانیم مجموع این دو متغیر تصادفی، آماره بسنده است. برای سنجش صحت گزاره مثال ۴، کافی است نشان دهیم رابطه بالا برای این آماره بسنده برقرار است و میتوان آن را به عنوان آماره بسنده مینیمال در نظر گرفت. با توجه به مثال ۱، تابع احتمال توام این نمونه تصادفی به صورت زیر است.
با توجه به تعریف ارائه شده برای آماره بسنده مینیمال،اگر و دو نمونه تصادفی دیگر باشند خواهیم داشت:
برای آنکه طرف راست این تساوی به پارامتر بستگی نداشته باشد باید باشد و اگر این تساوی برقرار باشد، نسبت بالا به بستگی ندارد. بنابراین مجموع این دو متغیر تصادفی آماره بسنده مینیمال است.
نکته: آماره بسنده مینیمال نیز یکتا نیست. ولی اگر دو آماره بسنده مینیمال برای پارامتر جامعه () وجود داشته باشد، مطمئن هستیم که بینشان یک تابع یا رابطه یک به یک برقرار است. به این ترتیب میتوان میانگین این دو متغیر تصادفی () را هم به عنوان آماره بسنده مینیمال در نظر گرفت.
مثال ۵
فرض کنید نمونه تصادفی مستقل و همتوزیع از نرمال با میانگین نامعلوم و واریانس معلوم باشند. نشان میدهیم که میانگین نمونهای، آماره بسنده مینیمال برای میانگین جامعه محسوب میشود.
مطابق با مثال ۳ میدانیم که تابع چگالی احتمال توام این نمونه تصادفی به صورت زیر نوشته میشود.
حال اگر نمونه تصادفی دیگری مانند در نظر بگیریم با استفاده از قضیه لهمن-شفه خواهیم داشت:
برای آنکه این نسبت به پارامتر بستگی نداشته باشد باید داشته باشیم:
در نتیجه آماره بسنده مینیمال است.
نکته: اغلب آماره بسندهای که از طریق فاکتورگیری فیشر ساخته میشود، بسنده مینیمال نیز هست.
اگر به فراگیری مباحث مشابه مطلب بالا علاقهمند هستید، آموزشهایی که در ادامه آمدهاند نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش آمار و احتمال مهندسی
- مجموعه آموزشهای نرمافزارهای آماری
- توزیع نرمال یک و چند متغیره — مفاهیم و کاربردها
- متغیر تصادفی و توزیع دو جملهای — به زبان ساده
- احتمال شرطی (Conditional Probability) — اصول و شیوه محاسبه
^^











عالی
توضیحات واقعا عالیه /دمتون گرم
ممنون از سایت خوبتون