



ساخت تابع پایتون برای پاکسازی داده ها – راهنمای کاربردی
در این مطلب، چگونگی ساخت تابع پایتون برای پاکسازی داده ها شرح داده شده است. «تحلیل اکتشافی دادهها» (Exploratory Data Analysis | EDA) و «پاکسازی دادهها» (Data Cleaning) دو گام اساسی پیش از آغاز توسعه یک مدل «یادگیری ماشین» (Machine Learning) محسوب میشوند. این دو گام، به ویژه برای افرادی که تازه در حال کسب تجربه در این زمینهها هستند، کاری بسیار زمانبر به شمار میآید.



ساخت تابع پایتون برای پاکسازی داده ها
تحلیل اکتشافی دادهها و پاکسازی دادهها، معمولا یک فرایند خطی و تک مرحلهای نیست. گاهی کاربر مجبور میشود که بارها به بخشهای پیشین برود و مجموعه داده مورد استفاده برای تحلیل را ویرایش کند. یک راهکار برای سرعت بخشیدن به این فرایند، بازیابی برخی از کدهایی است که فرد ممکن است طی فرایند پاکسازی دادهها و تحلیل داده اکتشافی، چندین و چند بار از آنها استفاده کند.
به همین دلیل است که باید توابعی برای خودکارسازی فرایند تکرار شونده تحلیل داده اکتشافی و پاکسازی دادهها ساخته شوند. دیگر مزیت استفاده از توابع برای فرایندهای بیان شده، حذف ناسازگاری ایجاد شده در نتایج به دلیل تفاوتهایی است که به طور تصادفی در کدها ایجاد شدهاند. در این مطلب، توابع پایتونی معرفی و ساخته شدهاند که برای کارهای تحلیل اکتشافی دادهها و پاکسازی دادهها قابل استفاده هستند. کتابخانهای که حاوی همه این توابع است را میتوان از مخزن [+] کلون کرد.
توابعی برای مدیریت مقادیر ناموجود یا گمشده
یک گام مهم در تحلیل اکتشافی دادهها، وارسی مقادیر ناموجود یا گمشده (Missing Values) و بررسی این است که آیا الگوی خاصی در مقادیر ناموجود وجود دارد؟ همچنین، باید تصمیمی پیرامون چگونگی مواجهه با این دادهها اتخاذ شود.

اولین تابعی که در اینجا وجود دارد، برای دادن یک ایده کلی پیرامون تعداد کل و درصد دادهها در هر ستون است.
پس از وارسی اولیه، میتوان تصمیم گرفت که آیا نیاز است بررسی نزدیکتری روی ستونهای حاوی مقادیر از دست رفته انجام شود یا خیر. با تعیین آستانه برای درصد مقادیر ناموجود، تابعی که در ادامه میآید یک لیست از ستونهای حاوی مقادیر ناموجود را که تعداد مقادیر ناموجود آنها بیشتر از آستانه است، ارائه میکند.
راهکارهای زیادی برای مواجهه با این مقادیر ناموجود وجود دارد. اگر کاربر تصمیم بگیرد که ستونهای حاوی مقادیر ناموجود زیاد را حذف کند (فراتر از آستانهای که تعریف میکند)، میتواند از تابعی که در ادامه آمده است برای انجام این کار استفاده کند.
def drop_columns_w_many_nans(df, missing_percent):
'''
Takes df, missing percentage
Drops the columns whose missing value is bigger than missing percentage
Returns df
'''
series = view_columns_w_many_nans(df, missing_percent=missing_percent)
list_of_cols = series.index.to_list()
df.drop(columns=list_of_cols)
print(list_of_cols)
return df
اگرچه، نقاط ضعف زیادی متوجه حذف کامل مقادیر ناموجود از مجموعه داده است؛ از جمله این موارد میتوان به کاهش قدرت آماری اشاره کرد. اگر کاربر تصمیم بگیرد که مقادیر ناموجود را جایگزین کند، میتواند از راهکارهای گوناگون موجود برای این کار را استفاده و احتمال آسیب زدن به دادهها و خروجی نهایی را کاهش دهد.
توابع بصریسازی دادهها
مغز انسان در شناسایی الگوها بسیار عالی عمل میکند و به همین دلیل است که بصریسازی دادهها در طول فرایند تحلیل اکتشافی دادهها و شناسایی الگوها میتواند سودمند باشد. برای مثال، «بافتنگارها» (Histograms) میتوانند تحلیل توزیع دادهها را آسانتر کنند. «نمودار جعبهای» (Boxplot) ابزار خوبی برای شناسایی دورافتادگیها است. «نمودار نقطهای» (Scatter Plot) هنگامی که بحث از بررسی همبستگی بین دو متغیر میشود، گزینه بسیار مناسبی است. کتابخانههای پایتون «متپلاتلیب» (Matplotlib) و «سیبورن» (Seaborn) از مهمترین، مفیدترین و کاربردیترین کتابخانهها در بحث بصریسازی دادهها محسوب میشوند.
اگرچه، ساخت نمودارهای جدا برای هر متغیر، میتواند کاری خسته کننده باشد؛ به ویژه هنگامی که تعداد زیادی از ویژگیها وجود دارند. در این بخش، به بررسی توابعی برای ساخت یک گروه از نمودارها پرداخته میشود که میتوانند به کاربر برای زدن چند نشان با یک تیر، کمک بسیار زیادی کنند. در این راستا، معمولا نگاهی به توزیع ستونها با مقادیر عددی انداخته میشود. تابعی که در ادامه آمده است، یک گروه از نمودارها را برای همه ستونهای عددی در مجموعه داده میسازد.
خروجی کامل به صورت زیر خواهد بود.

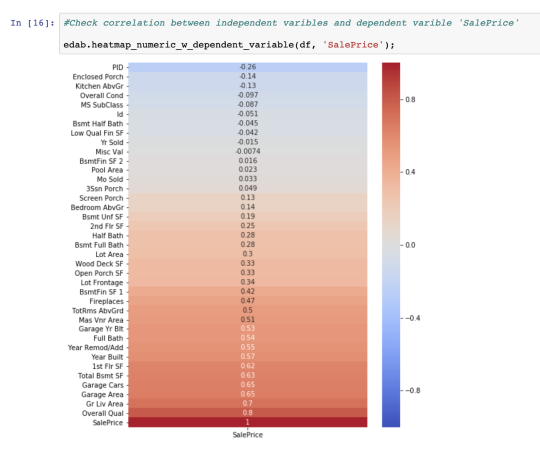
دیگر ابزار بصریسازی مفید، «نقشه حرارتی» (Heatmap) است. نقشههای حرارتی برای بررسی همبستگی بین متغیرهای مستقل و غیر مستقل بسیار مناسب است. اغلب اوقات، نمودارهای گرمایشی در صورت وجود تعداد متغیرهای بسیار زیاد، ممکن است شلوغ و به هم ریخته به نظر بیایند. یک راهکار برای جلوگیری از این موضوع، ساخت نقشه گرمایشی برای متغیر وابسته (هدف) و متغیرهای و مسقل (ویژگیها) است. تابع ارائه شده در زیر، میتواند به کاربر برای انجام این کار کمک شایان توجهی کند.

توابعی برای تغییر انواع دادهها
حصول اطمینان از اینکه ویژگیها دارای نوع داده (Data Type) درستی هستند، یک گام مهم در فرایند تحلیل اکتشافی دادهها و پاکسازی دادهها محسوب میشود. این کار معمولا انجام میشود، زیرا که متد read_csv(). انواع دادهها را به صورتی متفاوت از فایل دادههای اصلی تفسیر میکند.
خواندن دیکشنری دادهها میتواند در این راستا بسیار کمک کننده و شفاف کننده مسأله باشد. علاوه بر آن، اگر کاربر در صدد انجام مهندسی ویژگیها باشد، نیاز به تغییر انواع دادهها وجود دارد. دو تابع زیر، دست به دست هم برای تبدیل ویژگیهای دستهای به عددی (طبقهای) یاریگر هستند. اولین تابع، برای خروجی دادن یک تابع است؛ برای مثال، تبدیل کننده (Transformer) هر str در لیست را به یک int تبدیل میکند که در آن، int اندیس آن عنصر در لیست است.
دومین تابع، دارای دو بخش است. اولین بخش، یک دیکشنری به شکل زیر را دریافت میکند.
با استفاده از تابع قبلی که پیش از این تعریف شده است، دیکشنری به چیزی شبیه به زیر تبدیل میشود.
دومین بخش از این تابع از متد map(). برای نگاشت هر تابع مبدل به یک چارچوب داده (دیتافریم) استفاده میکند. شایان ذکر است که یک کپی از چارچوب داده اصلی، در طول این تابع ساخته میشود.

اگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- آموزش هوش مصنوعی
- مجموعه آموزشهای برنامه نویسی پایتون (Python)
- داده کاوی (Data Mining) — از صفر تا صد
- یادگیری علم داده (Data Science) با پایتون — از صفر تا صد
- معرفی منابع جهت آموزش یادگیری عمیق (Deep Learning) — راهنمای کامل
^^








