


سیستم توصیه گر قیمت با پایتون – راهنمای کاربردی
Mercari، بزرگترین برنامه کاربردی فروشگاهی مبتنی بر جامعه در ژاپن است. کاربران این سیستم از یک مشکل عمیق رنج میبردند. مساله موجود از این قرار بود که فروشندگان وقتی جنسی را برای فروش قرار میدادند نمیدانستند چگونه قیمتگذاری کنند. بنابراین، سازندگان فروشگاه مایل بودند به فروشندگان داخل فروشگاه برای محصولات گوناگون پیشنهاد قیمت بدهند، اما این کار به این دلیل که فروشندگان این امکان را داشتند که هر نوع محصول و یا بستههای محصولاتی را عرضه کنند کار سختی محسوب میشد. در این پروژه یادگیری ماشین، آموزش ساخت یک مدل یادگیری ماشین ارائه خواهد شد که به طور خودکار قیمت مناسبی را برای محصولات پیشنهاد میدهد. در راستای ساخت سیستم توصیه گر قیمت با پایتون، اطلاعات زیر فراهم شدهاند:




- train_id: شناسه () فهرستها
- name: عنوان لیستها
- item_condition_id : شرایطی که محصول بر اساس آن توسط فروشنده عرضه شده
- category_name: دسته فهرستها
- brand_name: نام برند
- price: قیمتی که یک محصول برای آن به فروش میرسد. این متغیر هدفی است که مدل یادگیری ماشین معرفی شده در این مطلب آن را پیشبینی خواهد کرد.
- shipping: عدد ۱ اگر هزینه حمل و نقل توسط فروشنده و ۰ اگر این مبلغ توسط فروشنده پرداخت شده باشد.
- item_description: توصیف کامل محصول
شایان ذکر است که پیشتر، آموزش «ساخت سیستم توصیه گر (Recommender System) فیلم با پایتون — راهنمای جامع و ساده» نیز در وبلاگ فرادرس منتشر شده است.
تحلیل داده اکتشافی
مجموعه داده مورد استفاده در اینجا را میتوان از وبسایت «کَگِل» (Kaggle) (+) دانلود کرد. برای اعتبارسنجی نتایج، صرفا نیاز به train.tsv است. کار با قطعه کد زیر آغاز میشود.
به طور تصادفی دادهها به مجموعههای «آموزش» (train) و «آزمون» (test) تقسیم میشوند. از مجموعه داده آموزش فقط برای «تحلیل داده اکتشافی» (Exploratory Data Analysis | EDA) استفاده میشود.
((1185866, 8), (296669, 8))

قیمت

قیمت محصولات دارای «چولگی» (Skewness) به چپ است و در واقع حجم انبوهی از محصولات بین ۱۰ تا ۲۰ قیمتگذاری شدهاند. این در حالی است که گرانترین محصول در سال ۲۰۰۹ قیمتگذاری شده، بنابراین، اکنون تبدیل سوابق روی قیمتها انجام خواهد شد.

حمل و نقل
قیمت بیش از ٪۵۵ محصولات توسط خریداران پرداخت میشود.

حمل و نقل چطور با قیمت ارتباط پیدا میکند؟
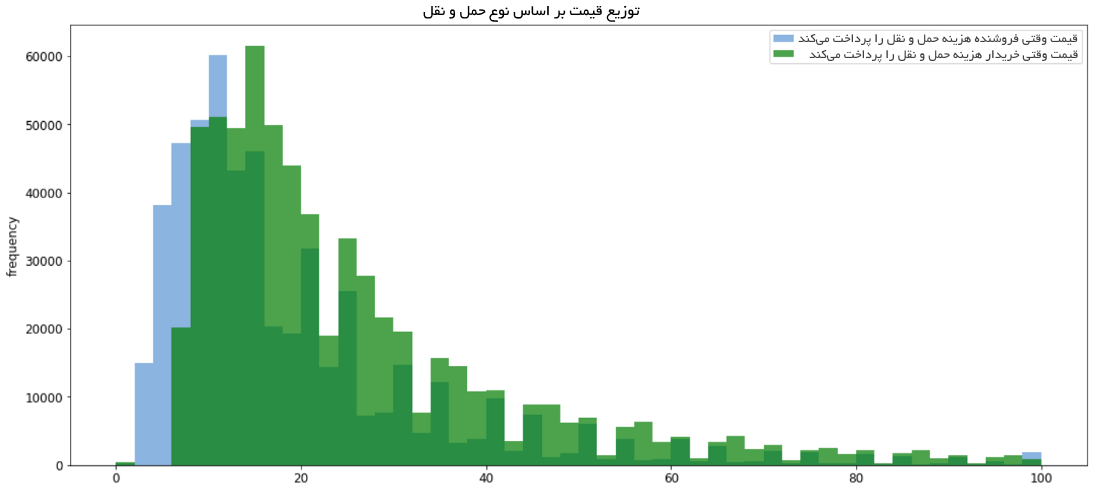
- در صورتی که فروشنده هزینه حمل و نقل را پرداخت کند، قیمت میانگین برابر با ۲۲.۵۸ است.
- در صورتی که خریدار هزینه حمل و نقل را پرداخت کند، قیمت میانگین برابر با ۳۰.۱۱ است.
پس از تبدیل سوابق، مجددا مقایسه قیمت انجام خواهد شد.
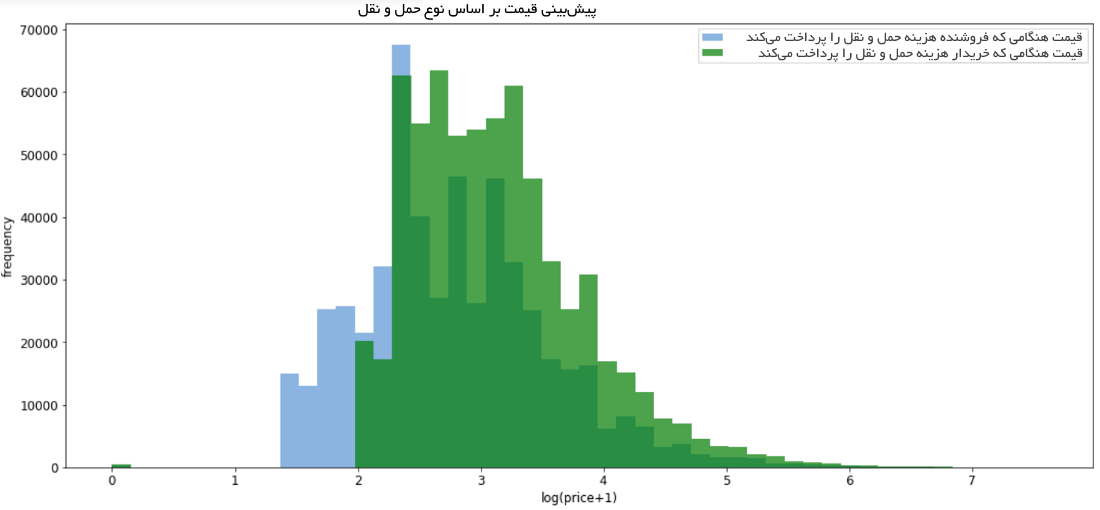
واضح است که قیمت میانگین هنگامی که خریدار هزینه حملونقل را پرداخت میکند بالاتر است.
نام دسته
۱۲۶۵ مقدار یکتا در ستون نام دسته وجود دارد.

۱۰ نام دسته متداول:

شرایط محصول در مقایسه با قیمت

به نظر میرسد که قیمت میانگین بین هر یک از IDهای شرایط متفاوت است. پس از تحلیل داده اکتشافی بالا، از همه این ویژگی برای ساخت مدل استفاده خواهد شد.
LightGBM
LightGBM یک «چارچوب گرادیان تقویتی» (Gradient Boosting Framework) با بهرهگیری از پروژه DMTK مایکروسافت است که از الگوریتمهای یادگیری مبتنی بر درخت استفاده میکند.
این الگوریتم با هدف توزیع شده و موثر بودن، همراه با مزایای زیر، طراحی شده است.
- سرعت آموزش و کارایی بالاتر
- استفاده کمتر از حافظه
- صحت بهتر
- یادگیری موازی و با پشتیبانی از GPU
- دارای توانایی مدیریت دادههای بزرگ
بنابراین، در ادامه از این چارچوب استفاده خواهد شد.
تنظیمات کلی مدل سیستم توصیه گر قیمت
«مقادیر ناموجود» (missing values) در ستونها وجود دارد و بنابراین نیاز به اصلاح آنها است.
۵۰۳۸ محصول وجود دارد که دارای اسم دسته (category name) نیستند.
۵۰۶۳۷۰ محصول وجود دارد که نام بِرند ندارند.
۳ محصول وجود دارد که توضیحات ندارند.
تابع کمککننده برای LightGBM:
سطرهایی که در آن قیمت برابر با صفر است حذف میشوند.
دادههای آموزش و دادههای تست جدید ادغام میشوند.
آمادهسازی برای آموزش
ستونهای نام دسته و نام بردار شمارش میشوند.
ستون TF-IDF بردار item_description.
ستون دودویی برچسبهای brand_name.
ساخت «متغیرهای مجازی» برای ستونهای item_condition_id و shipping.
ساخت ماتریس خلوت ادغام شده.
حذف ویژگیها با فرکانس سَنَد => ۱.
جداسازی دادههای آموزش و آزمون از sparse merge.
ساخت مجموعه داده برای lightgbm.
تعیین پارامترها به عنوان dict.
- استفاده از «رگرسیون» (regression) به دلیل آنکه مساله موجود مساله رگرسیون است.
- استفاده از «RMSE» به عنوان سنجه به دلیل اینکه مساله موجود رگرسیون است.
- “num_leaves”=100 به دلیل اینکه دادههای موجود نسبتا بزرگ هستند.
- استفاده از «“num_leaves”=100» برای اجتناب از «بیش برازش» (Overfitting)
- استفاده از max_depth برای اجتناب از بیش برازش
- استفاده از «verbosity» برای کنترل سطح verbosity در LightGBM (داریم ۰>: Fatal)
- «learning_rate» تاثیر هر درخت در خروجی نهایی را تعیین میکند.
آغاز آموزش
آموزش دادن یک مدل نیازمند یک لیست پارامتر و مجموعه داده است و مدتی نیز به طول میانجامد.
پیشبینی
ارزیابی
rmse پیشبینی برابر است با: 0.46164222941613137
کد منبع کامل این پروژه در گیتهاب (+) موجود است.
اگر مطلب بالا برای شما مفید بوده، آموزشهای زیر نیز به شما پیشنهاد میشود:
- مجموعه آموزشهای آمار، احتمالات و دادهکاوی
- مجموعه آموزشهای یادگیری ماشین و بازشناسی الگو
- مجموعه آموزشهای برنامهنویسی پایتون
- مجموعه آموزشهای هوش محاسباتی
- مجموعه آموزشهای شبکههای عصبی مصنوعی
- آموزش برنامهنویسی R و نرمافزار R Studio
- مجموعه آموزشهای برنامه نویسی متلب (MATLAB)
^^








